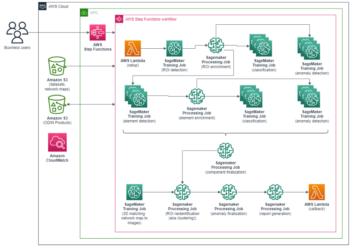
I computervision er semantisk segmentering opgaven med at klassificere hver pixel i et billede med en klasse fra et kendt sæt etiketter, således at pixels med samme etiket deler visse egenskaber. Det genererer en segmenteringsmaske af inputbillederne. For eksempel viser de følgende billeder en segmenteringsmaske af cat etiket.
 |
 |
I november 2018, Amazon SageMaker annoncerede lanceringen af SageMaker semantiske segmenteringsalgoritme. Med denne algoritme kan du træne dine modeller med et offentligt datasæt eller dit eget datasæt. Populære billedsegmenteringsdatasæt inkluderer Common Objects in Context (COCO)-datasættet og PASCAL Visual Object Classes (PASCAL VOC), men klasserne af deres etiketter er begrænsede, og du vil måske træne en model på målobjekter, der ikke er inkluderet i offentlige datasæt. I dette tilfælde kan du bruge Amazon SageMaker Ground Truth at mærke dit eget datasæt.
I dette indlæg demonstrerer jeg følgende løsninger:
- Brug af Ground Truth til at mærke et semantisk segmenteringsdatasæt
- At transformere resultaterne fra Ground Truth til det krævede inputformat for SageMaker indbyggede semantiske segmenteringsalgoritme
- Brug af den semantiske segmenteringsalgoritme til at træne en model og udføre inferens
Semantisk segmenteringsdatamærkning
For at bygge en maskinlæringsmodel til semantisk segmentering skal vi mærke et datasæt på pixelniveau. Ground Truth giver dig mulighed for at bruge menneskelige annotatorer igennem Amazon Mechanical Turk, tredjepartsleverandører eller din egen private arbejdsstyrke. For at lære mere om arbejdsstyrker, se Opret og administrer arbejdsstyrker. Hvis du ikke ønsker at styre mærkningspersonalet på egen hånd, Amazon SageMaker Ground Truth Plus er en anden fantastisk mulighed som en ny nøglefærdig datamærkningstjeneste, der giver dig mulighed for hurtigt at skabe træningsdatasæt af høj kvalitet og reducerer omkostningerne med op til 40 %. Til dette indlæg viser jeg dig, hvordan du manuelt mærker datasættet med Ground Truth auto-segment-funktionen og crowdsource-mærkning med en Mechanical Turk-arbejdsstyrke.
Manuel mærkning med Ground Truth
I december 2019 tilføjede Ground Truth en automatisk segmenteringsfunktion til den semantiske segmenteringsmærkningsbrugergrænseflade for at øge mærkningsgennemstrømningen og forbedre nøjagtigheden. For mere information, se Auto-segmentering af objekter, når der udføres semantisk segmenteringsmærkning med Amazon SageMaker Ground Truth. Med denne nye funktion kan du accelerere din mærkningsproces på segmenteringsopgaver. I stedet for at tegne en tætsiddende polygon eller bruge penselværktøjet til at fange et objekt i et billede, tegner du kun fire punkter: øverst, nederst, længst til venstre og længst til højre på objektet. Ground Truth tager disse fire punkter som input og bruger algoritmen Deep Extreme Cut (DEXTR) til at producere en tætsiddende maske omkring objektet. For en selvstudie, der bruger Ground Truth til billedsemantisk segmenteringsmærkning, se Billedsemantisk segmentering. Det følgende er et eksempel på, hvordan autosegmenteringsværktøjet genererer en segmenteringsmaske automatisk, efter du har valgt de fire yderpunkter for et objekt.


Crowdsourcing-mærkning med en Mechanical Turk-arbejdsstyrke
Hvis du har et stort datasæt, og du ikke selv ønsker at mærke hundredvis eller tusindvis af billeder manuelt, kan du bruge Mechanical Turk, som giver en on-demand, skalerbar, menneskelig arbejdsstyrke til at udføre opgaver, som mennesker kan gøre bedre end computere. Mechanical Turk-software formaliserer jobtilbud til de tusindvis af arbejdere, der er villige til at udføre stykvis arbejde, når det passer dem. Softwaren henter også det udførte arbejde og kompilerer det for dig, rekvirenten, som betaler (kun) arbejderne for tilfredsstillende arbejde. For at komme i gang med Mechanical Turk, se Introduktion til Amazon Mechanical Turk.
Opret et etiketteringsjob
Det følgende er et eksempel på et Mechanical Turk-mærkningsjob for et havskildpaddedatasæt. Havskildpaddedatasættet er fra Kaggle-konkurrencen Ansigtsgenkendelse af havskildpadder, og jeg udvalgte 300 billeder af datasættet til demonstrationsformål. Havskildpadder er ikke en almindelig klasse i offentlige datasæt, så den kan repræsentere en situation, der kræver mærkning af et massivt datasæt.
- Vælg på SageMaker-konsollen Mærkningsjob i navigationsruden.
- Vælg Opret etiketteringsjob.
- Indtast et navn til dit job.
- Til Opsætning af inputdata, Vælg Automatiseret dataopsætning.
Dette genererer et manifest af inputdata. - Til S3-placering for inputdatasæt, skal du indtaste stien til datasættet.

- Til Opgavekategori, vælg Billede.
- Til Opgavevalg, Vælg Semantisk segmentering.

- Til Arbejdertyper, Vælg Amazon Mechanical Turk.
- Konfigurer dine indstillinger for opgavetimeout, opgaveudløbstid og pris pr. opgave.

- Tilføj en etiket (for dette indlæg,
sea turtle), og giv mærkningsinstruktioner. - Vælg Opret.

Når du har konfigureret etiketteringsjobbet, kan du kontrollere etiketteringsforløbet på SageMaker-konsollen. Når det er markeret som fuldført, kan du vælge jobbet for at kontrollere resultaterne og bruge dem til de næste trin.

Datasæt transformation
Når du har fået output fra Ground Truth, kan du bruge SageMaker indbyggede algoritmer til at træne en model på dette datasæt. Først skal du forberede det mærkede datasæt som den anmodede inputgrænseflade til SageMaker semantiske segmenteringsalgoritme.
Anmodede inputdatakanaler
SageMaker semantisk segmentering forventer, at dit træningsdatasæt bliver gemt på Amazon Simple Storage Service (Amazon S3). Datasættet i Amazon S3 forventes at blive præsenteret i to kanaler, en for train og én for validation, ved hjælp af fire mapper, to til billeder og to til annoteringer. Annoteringer forventes at være ukomprimerede PNG-billeder. Datasættet kan også have et etiketkort, der beskriver, hvordan annoteringstilknytningerne etableres. Hvis ikke, bruger algoritmen en standard. Til slutning accepterer et slutpunkt billeder med en image/jpeg indholdstype. Følgende er den nødvendige struktur for datakanalerne:
Hvert JPG-billede i tog- og valideringsmapperne har et tilsvarende PNG-etiketbillede med samme navn i train_annotation , validation_annotation mapper. Denne navngivningskonvention hjælper algoritmen med at forbinde en etiket med dens tilsvarende billede under træning. Toget, train_annotation, validering og validation_annotation kanaler er obligatoriske. Annoteringerne er enkeltkanals PNG-billeder. Formatet fungerer, så længe metadataene (tilstandene) i billedet hjælper algoritmen med at læse annotationsbillederne til et enkelt-kanals 8-bit usigneret heltal.
Output fra Ground Truth-mærkningsjobbet
De output, der genereres fra Ground Truth-mærkningsjobbet, har følgende mappestruktur:
Segmenteringsmaskerne gemmes i s3://turtle2022/labelturtles/annotations/consolidated-annotation/output. Hvert annotationsbillede er en .png-fil opkaldt efter indekset for kildebilledet og det tidspunkt, hvor denne billedmærkning blev fuldført. Følgende er for eksempel kildebilledet (Image_1.jpg) og dets segmenteringsmaske genereret af Mechanical Turk-arbejdsstyrken (0_2022-02-10T17:41:04.724225.png). Bemærk, at maskens indeks er anderledes end nummeret i kildebilledets navn.
 |
 |
Udgangsmanifestet fra mærkningsjobbet er i /manifests/output/output.manifest fil. Det er en JSON-fil, og hver linje registrerer en mapping mellem kildebilledet og dets etiket og andre metadata. Følgende JSON-linje registrerer en mapping mellem det viste kildebillede og dets annotering:
Kildebilledet hedder Image_1.jpg, og annotationens navn er 0_2022-02-10T17:41: 04.724225.png. For at forberede dataene som de påkrævede datakanalformater af SageMaker semantiske segmenteringsalgoritme, skal vi ændre annotationsnavnet, så det har samme navn som kilde-JPG-billederne. Og vi skal også opdele datasættet i train , validation mapper til kildebilleder og annoteringerne.
Transform output fra et Ground Truth-mærkningsjob til det ønskede inputformat
For at transformere outputtet skal du udføre følgende trin:
- Download alle filerne fra mærkningsjobbet fra Amazon S3 til en lokal mappe:
- Læs manifestfilen, og skift navnene på annoteringen til de samme navne som kildebillederne:
- Opdel tog- og valideringsdatasættene:
- Lav en mappe i det krævede format til de semantiske segmenteringsalgoritmes datakanaler:
- Flyt tog- og valideringsbillederne og deres annoteringer til de oprettede mapper.
- Brug følgende kode til billeder:
- Brug følgende kode til annoteringer:
- Upload tog- og valideringsdatasæt og deres annotationsdatasæt til Amazon S3:
SageMaker semantisk segmenteringsmodel træning
I dette afsnit gennemgår vi trinene for at træne din semantiske segmenteringsmodel.
Følg eksemplet på notesbogen og opsæt datakanaler
Du kan følge instruktionerne i Semantisk segmenteringsalgoritme er nu tilgængelig i Amazon SageMaker at implementere den semantiske segmenteringsalgoritme til dit mærkede datasæt. Denne prøve notesbog viser et ende-til-ende eksempel, der introducerer algoritmen. I notesbogen lærer du, hvordan du træner og hoster en semantisk segmenteringsmodel ved hjælp af det fuldt konvolutionerende netværk (FCN) algoritme ved hjælp af Pascal VOC datasæt til træning. Fordi jeg ikke planlægger at træne en model fra Pascal VOC-datasættet, sprang jeg trin 3 (dataforberedelse) over i denne notesbog. I stedet skabte jeg direkte train_channel, train_annotation_channe, validation_channelog validation_annotation_channel ved at bruge de S3-steder, hvor jeg gemte mine billeder og anmærkninger:
Juster hyperparametre for dit eget datasæt i SageMaker estimator
Jeg fulgte notesbogen og oprettede et SageMaker-estimatorobjekt (ss_estimator) for at træne min segmenteringsalgoritme. En ting, vi skal tilpasse til det nye datasæt, er i ss_estimator.set_hyperparameters: vi skal ændres num_classes=21 til num_classes=2 (turtle , background), og jeg ændrede mig også epochs=10 til epochs=30 fordi 10 kun er til demoformål. Så brugte jeg p3.2xlarge-instansen til modeltræning ved indstilling instance_type="ml.p3.2xlarge". Træningen gennemførte på 8 minutter. Det bedste MIoU (Mean Intersection over Union) på 0.846 opnås ved epoke 11 med en pix_acc (procenten af pixels i dit billede, der er klassificeret korrekt) på 0.925, hvilket er et ret godt resultat for dette lille datasæt.
Modelslutningsresultater
Jeg hostede modellen på en lavpris ml.c5.xlarge-instans:
Til sidst forberedte jeg et testsæt med 10 skildpaddebilleder for at se resultatet af den trænede segmenteringsmodel:
Følgende billeder viser resultaterne.

Segmenteringsmaskerne for havskildpadderne ser nøjagtige ud, og jeg er glad for dette resultat, trænet på et datasæt på 300 billeder mærket af Mechanical Turk-arbejdere. Du kan også udforske andre tilgængelige netværk som f.eks pyramide-scene-parsing netværk (PSP) or DeepLab-V3 i eksempelnotesbogen med dit datasæt.
Ryd op
Slet slutpunktet, når du er færdig med det for at undgå at pådrage dig fortsatte omkostninger:
Konklusion
I dette indlæg viste jeg, hvordan man tilpasser semantisk segmenteringsdatamærkning og modeltræning ved hjælp af SageMaker. For det første kan du konfigurere et etiketteringsjob med autosegmenteringsværktøjet eller bruge en Mechanical Turk-arbejdsstyrke (såvel som andre muligheder). Hvis du har mere end 5,000 objekter, kan du også bruge automatiseret datamærkning. Derefter transformerer du output fra dit Ground Truth-mærkningsjob til de nødvendige inputformater til SageMaker indbyggede semantisk segmenteringstræning. Derefter kan du bruge en accelereret beregningsinstans (såsom p2 eller p3) til at træne en semantisk segmenteringsmodel med følgende notesbog og implementer modellen til en mere omkostningseffektiv instans (såsom ml.c5.xlarge). Til sidst kan du gennemgå slutningsresultaterne på dit testdatasæt med et par linjer kode.
Kom godt i gang med SageMaker semantisk segmentering datamærkning , model træning med dit yndlingsdatasæt!
Om forfatteren
 Kara Yang er dataforsker i AWS Professional Services. Hun brænder for at hjælpe kunder med at nå deres forretningsmål med AWS cloud-tjenester. Hun har hjulpet organisationer med at bygge ML-løsninger på tværs af flere industrier såsom fremstilling, bilindustri, miljømæssig bæredygtighed og rumfart.
Kara Yang er dataforsker i AWS Professional Services. Hun brænder for at hjælpe kunder med at nå deres forretningsmål med AWS cloud-tjenester. Hun har hjulpet organisationer med at bygge ML-løsninger på tværs af flere industrier såsom fremstilling, bilindustri, miljømæssig bæredygtighed og rumfart.
- Coinsmart. Europas bedste Bitcoin og Crypto Exchange.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. FRI ADGANG.
- CryptoHawk. Altcoin radar. Gratis prøveversion.
- Kilde: https://aws.amazon.com/blogs/machine-learning/semantic-segmentation-data-labeling-and-model-training-using-amazon-sagemaker/
- '
- "
- 000
- 10
- 100
- 11
- 2019
- a
- Om
- fremskynde
- accelereret
- præcis
- opnå
- opnået
- tværs
- tilføjet
- Luftfart
- algoritme
- algoritmer
- Alle
- Amazon
- annoncerede
- En anden
- omkring
- Associate
- Automatiseret
- automatisk
- automotive
- til rådighed
- AWS
- baggrund
- fordi
- BEDSTE
- Bedre
- mellem
- bygge
- indbygget
- virksomhed
- fange
- tilfælde
- vis
- lave om
- kanaler
- Vælg
- klasse
- klasser
- klassificeret
- Cloud
- cloud-tjenester
- kode
- Fælles
- konkurrence
- fuldføre
- computer
- computere
- computing
- tillid
- Konsol
- indhold
- bekvemmelighed
- Tilsvarende
- omkostningseffektiv
- Omkostninger
- skabe
- oprettet
- Kunder
- tilpasse
- data
- dataforsker
- dyb
- demonstrere
- indsætte
- forskellige
- direkte
- tegning
- i løbet af
- hver
- muliggør
- ende til ende
- Endpoint
- Indtast
- miljømæssige
- etableret
- eksempel
- Undtagen
- forventet
- forventer
- udforske
- ekstrem
- Ansigtet
- Feature
- Fornavn
- følger
- efter
- format
- fra
- genereret
- Mål
- godt
- grå
- stor
- Gem
- hjulpet
- hjælpe
- hjælper
- høj kvalitet
- hostede
- Hvordan
- How To
- HTTPS
- menneskelig
- Mennesker
- Hundreder
- billede
- billeder
- gennemføre
- Forbedre
- omfatter
- medtaget
- Forøg
- indeks
- industrier
- oplysninger
- indgang
- instans
- grænseflade
- vejkryds
- indføre
- IT
- Job
- Karriere
- kendt
- etiket
- mærkning
- Etiketter
- stor
- lancere
- LÆR
- læring
- Niveau
- Limited
- Line (linje)
- linjer
- Liste
- lokale
- placering
- placeringer
- Lang
- Se
- maskine
- machine learning
- administrere
- obligatorisk
- manuelt
- Produktion
- kort
- kortlægning
- maske
- Masker
- massive
- mekanisk
- måske
- ML
- model
- modeller
- mere
- flere
- navne
- navngivning
- Navigation
- netværk
- net
- næste
- notesbog
- nummer
- Tilbud
- Option
- Indstillinger
- organisationer
- Andet
- egen
- lidenskabelige
- procent
- udfører
- punkter
- Polygon
- Populær
- Forbered
- smuk
- pris
- private
- behandle
- producere
- professionel
- give
- giver
- offentlige
- formål
- hurtigt
- RE
- optegnelser
- repræsentere
- påkrævet
- Kræver
- Resultater
- gennemgå
- samme
- skalerbar
- Videnskabsmand
- HAV
- segmentering
- valgt
- tjeneste
- Tjenester
- sæt
- indstilling
- Del
- Vis
- vist
- Simpelt
- Situationen
- lille
- So
- Software
- Løsninger
- delt
- påbegyndt
- opbevaring
- Bæredygtighed
- mål
- opgaver
- hold
- prøve
- The Source
- ting
- tredjepart
- tusinder
- Gennem
- kapacitet
- tid
- værktøj
- Tog
- Kurser
- Transform
- union
- brug
- validering
- leverandører
- vision
- WHO
- Arbejde
- arbejdere
- Workforce
- virker
- Din