Amazon EMR er glad for at kunne annoncere integration med Amazon Simple Storage Service (Amazon S3) Access Grants, der forenkler Amazon S3-tilladelsesadministration og giver dig mulighed for at håndhæve granulær adgang i stor skala. Med denne integration kan du skalere jobbaseret Amazon S3-adgang til Apache Spark-job på tværs af alle Amazon EMR-implementeringsmuligheder og gennemtvinge granulær Amazon S3-adgang for at opnå en bedre sikkerhedsstilling.
I dette indlæg vil vi gennemgå et par forskellige scenarier for, hvordan man bruger Amazon S3 Access Grants. Før vi går i gang med at gå gennem Amazon EMR- og Amazon S3 Access Grants-integrationen, opsætter og konfigurerer vi S3 Access Grants. Så bruger vi AWS CloudFormation skabelon nedenfor for at oprette en Amazon EMR på Amazon Elastic Compute Cloud (Amazon EC2) Cluster, en EMR-serverløs applikation og to forskellige jobroller.
Efter opsætningen kører vi et par scenarier for, hvordan du kan bruge Amazon EMR med S3 Access Grants. Først kører vi et batchjob på EMR på Amazon EC2 for at importere CSV-data og konvertere til Parket. For det andet bruger vi Amazon EMR Studio med en interaktiv EMR-serverløs applikation til at analysere dataene. Til sidst viser vi, hvordan du konfigurerer adgang på tværs af konti til Amazon S3 Access Grants. Mange kunder bruger forskellige konti på tværs af deres organisation og endda uden for deres organisation til at dele data. Amazon S3 Access Grants gør det nemt at give adgang på tværs af konti til dine data, selv når du filtrerer efter forskellige præfikser.
Udover dette indlæg kan du lære mere om Amazon S3 Access Grants fra Skalering af dataadgang med Amazon S3 Access Grants.
Forudsætninger
Før du starter AWS CloudFormation-stakken, skal du sikre dig, at du har følgende:
- En AWS-konto, der giver adgang til AWS-tjenester
- Den seneste version af AWS Command Line Interface (AWS CLI)
- En AWS identitets- og adgangsstyring (AWS IAM) bruger med en adgangsnøgle og hemmelig nøgle til at konfigurere AWS CLI og tilladelser til at oprette en IAM-rolle, IAM-politikker og stakke i AWS CloudFormation
- En anden AWS-konto, hvis du ønsker at teste funktionaliteten på tværs af konti
Går igennem
Opret ressourcer med AWS CloudFormation
For at bruge Amazon S3 Access Grants skal du bruge en klynge med Amazon EMR 6.15.0 eller nyere. For mere information, se dokumentationen for brug af Amazon S3 Access Grants med en Amazon EMR-klynge, en Amazon EMR på EKS-klyngeOg en Amazon EMR Serverløs applikation. I forbindelse med dette indlæg antager vi, at du har to forskellige typer brugere af dataadgang i din organisation – analytikere med læse- og skriveadgang til dataene i bøtten og forretningsanalytikere med skrivebeskyttet adgang. Vi vil bruge to forskellige AWS IAM-roller, men du kan også forbinde din egen identitetsudbyder direkte til IAM Identity Center, hvis du vil.
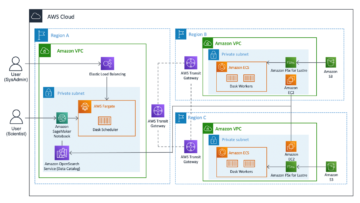
Her er arkitekturen for denne første del. AWS CloudFormation-stakken opretter følgende AWS-ressourcer:
- En Virtual Private Cloud (VPC) stak med private og offentlige undernet til brug med EMR Studio, rutetabeller og Network Address Translation (NAT) gateway.
- En Amazon S3-spand til EMR-artefakter som logfiler, Spark-kode og Jupyter-notesbøger.
- En Amazon S3-bøtte med eksempeldata til brug med S3 Access Grants.
- En Amazon EMR-klynge konfigureret til at bruge runtime roller og S3 Access Grants.
- En Amazon EMR-serverløs applikation konfigureret til at bruge S3 Access Grants.
- Et Amazon EMR Studio, hvor brugere kan logge på og oprette notesbøger med EMR Serverless-applikationen.
- To AWS IAM-roller, vi vil bruge til vores EMR-jobkørsel: en til Amazon EC2 med skriveadgang og en anden til serverløs med læseadgang.
- Én AWS IAM-rolle, der vil blive brugt af S3 Access Grants til at få adgang til bucket-data (dvs. den rolle, der skal bruges ved registrering af en lokation med S3 Access Grants. S3 Access Grants bruger denne rolle til at oprette midlertidige legitimationsoplysninger).
For at komme i gang skal du udføre følgende trin:
- Vælg Start stak:

- Accepter standardindstillingerne og vælg Jeg anerkender, at denne skabelon kan skabe IAM-ressourcer.
AWS CloudFormation-stakken tager cirka 10-15 minutter at fuldføre. Når stakken er færdig, skal du gå til fanen output, hvor du vil finde information, der er nødvendig for de følgende trin.
Opret Amazon S3 Access Grants-ressourcer
Først skal vi oprette en Amazon S3 Access Grants-ressource på vores konto. Vi opretter en S3 Access Grants-instans, en S3 Access Grants-placering, der refererer til vores data-bucket, der er oprettet af AWS CloudFormation-stakken, og som kun er tilgængelig for vores data-bucket AWS IAM-rolle, og giver forskellige niveauer af adgang til vores læser- og skribentroller.

For at oprette de nødvendige S3 Access Grants-ressourcer skal du bruge følgende AWS CLI-kommandoer som administrativ bruger og erstatte et hvilket som helst af felterne mellem pilene med outputtet fra din CloudFormation-stak.
Dernæst opretter vi en ny S3 Access Grants-placering. Hvad er en placering? Amazon S3 Access Grants fungerer ved at sælge AWS IAM-legitimationsoplysninger med adgang til et bestemt S3-præfiks. En S3 Access Grants-placering vil blive knyttet til en AWS IAM-rolle, hvorfra disse midlertidige sessioner vil blive oprettet.
I vores tilfælde vil vi omfange AWS IAM-rollen til den bucket, der er oprettet med vores AWS CloudFormation-stak, og give adgang til den data bucket-rolle, der er oprettet af stakken. Gå til fanen output for at finde de værdier, der skal erstattes med følgende kodestykke:
Bemærk AccessGrantsLocationId værdi i svaret. Det skal vi bruge til de næste trin, hvor vi gennemgår oprettelsen af de nødvendige S3 Access Grants for at begrænse læse- og skriveadgang til din bucket.
- For læse/skrive-brugeren, brug
s3-control create-access-grantfor at tillade READWRITE-adgang til "output/*"-præfikset: - For den læste bruger, brug
s3control create-access-grantigen for kun at tillade LÆSE-adgang til det samme præfiks:
Demo Scenario 1: Amazon EMR på EC2 Spark Job til at generere parketdata
Nu hvor vi har sat vores Amazon EMR-miljøer op og givet adgang til vores roller via S3 Access Grants, er det vigtigt at bemærke, at de to AWS IAM-roller for vores EMR-klynge og EMR Serverless-applikation har en IAM-politik, der kun tillader adgang til vores EMR artefakter spand. De har ingen IAM-adgang til vores S3-dataindsamling og bruger i stedet S3 Access Grants til at hente kortvarige legitimationsoplysninger, der er scoped til bucket og præfiks. Specifikt tildeles rollerne s3:GetDataAccess og s3:GetDataAccessGrantsInstanceForPrefix tilladelser til at anmode om adgang via den specifikke S3 Access Grants-instans, der er oprettet i vores region. Dette giver dig mulighed for nemt at administrere din S3-adgang ét sted på en meget omfattende og detaljeret måde, der forbedrer din sikkerhedsstilling. Ved at kombinere S3 Access Grants med jobroller på EMR på Amazon Elastic Kubernetes Service (Amazon EX) og EMR Serverless samt runtime roller for Amazon EMR-trin begyndende med EMR 6.7.0 kan du nemt administrere adgangskontrol for individuelle job eller forespørgsler. S3 Access Grants er tilgængelige på EMR 6.15.0 og nyere. Lad os først køre et Spark-job på EMR på EC2 som vores analyseingeniør for at konvertere nogle prøvedata til Parket.
Til dette skal du bruge prøvekoden, der er angivet i converter.py. Download filen og kopier den til EMR_ARTIFACTS_BUCKET oprettet af AWS CloudFormation-stakken. Vi indsender vores job med ReadWrite AWS IAM-rollen. Bemærk, at for EMR-klyngen har vi konfigureret S3 Access Grants til at falde tilbage til IAM-rollen, hvis adgang ikke leveres af S3 Access Grants. Det DATA_WRITER_ROLE har læseadgang til EMR-artefakter-bøtten gennem en IAM-politik, så den kan læse vores script. Som før skal du erstatte alle værdierne med <> symboler fra Udgange fanen på din CloudFormation-stak.
Når jobbet er færdigt, skulle vi se nogle parketdata s3://<DATA_BUCKET>/output/weather-data/. Du kan se status for jobbet i Steps fanebladet af EMR konsol.
Demo Scenario 2: EMR Studio med en interaktiv EMR-serverløs applikation til at analysere data
Lad os nu gå videre og logge ind på EMR Studio og oprette forbindelse til din EMR Serverless-applikation med ReadOnly-runtime-rollen for at analysere dataene fra scenario 1. Først skal vi aktivere det interaktive slutpunkt på din Serverless-applikation.
- Vælg EMRStudioURL i Fanen Udgange af din AWS CloudFormation-stak.
- Type Applikationer under Serverless afsnit i venstre side.

- Vælg EMRBlog ansøgning, derefter Handling dropdown, og Configure.
- Udvid Interaktivt slutpunkt afsnit og sørg for det Aktiver interaktivt slutpunkt er kontrolleret.

- Rul ned og klik Konfigurer applikation for at gemme dine ændringer.
- Tilbage på siden Applikationer skal du vælge EMRBlog ansøgning, derefter Start ansøgning .
Opret derefter et nyt arbejdsområde i vores Studio.
- Vælg arbejdsområder i venstre side, derefter Skab arbejdsrum .
- Indtast et arbejdsområdenavn, forlad de resterende standardindstillinger, og vælg Opret arbejdsområde.
- Efter oprettelse af arbejdsområdet bør det starte i en ny fane om et par sekunder.
Tilslut nu dit Workspace til din EMR Serverless-applikation.
- Vælg EMR Compute knap i venstre side som vist i følgende kode.
- Vælg EMR-serverløs som beregningstype.
- Vælg den EMRBlog applikation og runtime-rollen, der starter med EMRBlog.
- Vælg Vedhæft. Vinduet opdateres, og du kan åbne en ny PySpark notesbog og følg med nedenfor. For at udføre koden selv, download AccessGrantsReadOnly.ipynb notesbog og upload det til dit arbejdsområde ved hjælp af Upload filer knappen i filbrowseren.

Lad os læse dataene hurtigt.

Vi laver en simpel optælling (*):

Du kan også se, at hvis vi forsøger at skrive data ind i outputplaceringen, får vi en Amazon S3-fejl.

Mens du også kan give lignende adgang via AWS IAM-politikker, kan Amazon S3 Access Grants være nyttige i situationer, hvor din organisation er vokset fra administrationen af adgang via IAM, ønsker at kortlægge S3 Access Grants til IAM Identity Center principper eller roller, eller tidligere har brugt EMR Filsystem (EMRFS) rolletilknytninger. S3 Access Grants-legitimationsoplysninger er også midlertidige og giver mere sikker adgang til dine data. Derudover, som vist nedenfor, drager adgang på tværs af konti også fordel af enkelheden ved S3 Access Grants.
Demo Scenario 3 – Adgang på tværs af konti
Et af de andre mere almindelige adgangsmønstre er adgang til data på tværs af konti. Dette mønster er blevet mere og mere almindeligt med fremkomsten af data mesh, hvor dataproducenter og forbrugere er decentraliseret på tværs af forskellige AWS-konti.
Tidligere krævede adgang på tværs af konti opsætning af komplekse påtagelige handlinger på tværs af konti og udbydere af brugerdefinerede legitimationsoplysninger, når du konfigurerer dit Spark-job. Med S3 Access Grants behøver vi kun at gøre følgende:
- Opret en Amazon EMR-jobrolle og klynge i en anden dataforbrugerkonto
- Dataproducentkontoen giver adgang til dataforbrugerkontoen med en ny instansressourcepolitik
- Dataproducentkontoen opretter en adgangsbevilling til rollen som dataforbrugerjob
Og det er det! Hvis du har en anden konto ved hånden, skal du gå videre og implementere denne AWS CloudFormation-stak i dataforbrugerkontoen for at oprette en ny EMR-serverløs applikation og jobrolle. Hvis ikke, så følg bare med nedenfor. AWS CloudFormation-stakken skulle være færdig på under et minut. Lad os derefter gå videre og give vores dataforbruger adgang til S3 Access Grants-forekomsten på vores dataproducentkonto.
- udskifte
<DATA_PRODUCER_ACCOUNT_ID>,<DATA_CONSUMER_ACCOUNT_ID>med de relevante 12-cifrede AWS-konto-id'er. - Du skal muligvis også ændre regionen i kommandoen og politikken.
- Og giv derefter READ-adgang til outputmappen til vores EMR Serverless-jobrolle i dataforbrugerkontoen.
Nu hvor vi har gjort det, kan vi læse data på dataforbrugerkontoen fra bøtten på dataproducentkontoen. Vi kører bare en simpel COUNT(*) en gang til. Udskift <APPLICATION_ID>, <DATA_CONSUMER_JOB_ROLE>og <DATA_CONSUMER_LOG_BUCKET> med værdierne fra fanen Outputs på AWS CloudFormation-stakken oprettet på din anden konto.
Og udskift <DATA_PRODUCER_BUCKET> med bøtten fra din første konto.
Vent på, at jobbet når en fuldført tilstand, og hent derefter stdout-loggen fra din spand, og udskift <APPLICATION_ID>, <JOB_RUN_ID> fra jobbet ovenfor, og <DATA_CONSUMER_LOG_BUCKET>.
Hvis du er på en unix-baseret maskine og har pistol installeret, så kan du bruge følgende kommando som din administrative bruger.
Bemærk, at denne kommando kun bruger AWS IAM-rollepolitikker, ikke Amazon S3 Access Grants.
Ellers kan du bruge få-dashboard-for-job-run kommandoen, og åbn den resulterende URL i din browser for at se Driver stdout-logfilerne på fanen Executors i Spark UI.
Gøre rent
For at undgå at pådrage sig fremtidige omkostninger til eksemplerressourcer i dine AWS-konti, skal du sørge for at tage følgende trin:
- Du skal manuelt slette Amazon EMR Studio-arbejdsområdet, der er oprettet i den første del af indlægget
- Tøm Amazon S3-bøtterne, der er oprettet af AWS CloudFormation-stakkene
- Sørg for, at du sletter Amazon S3 Access Grants, ressourcepolitikker og S3 Access Grants-placering oprettet i trinene ovenfor ved hjælp af
delete-access-grant,delete-access-grants-instance-resource-policy,delete-access-grants-locationogdelete-access-grants-instancekommandoer. - Slet AWS CloudFormation Stacks oprettet i hver konto
Sammenligning med AWS IAM Role Mapping
I 2018 introducerede EMR EMRFS-rollekortlægning som en måde at give godkendelse på lagerniveau ved at konfigurere EMRFS med flere IAM-roller. Selvom rolletilknytningen var effektiv, krævede det at administrere brugere eller grupper lokalt på din EMR-klynge ud over at vedligeholde tilknytningerne mellem disse identiteter og deres tilsvarende IAM-roller. I kombination med runtime roller på EMR på EC2 og jobroller for EMR på EKS , EMR-serverløs, er det nu nemmere at give adgang til dine data på S3 direkte til den relevante rektor på jobbasis.
Konklusion
I dette indlæg viste vi dig, hvordan du konfigurerer og bruger Amazon S3 Access Grants med Amazon EMR for nemt at administrere dataadgang for dine Amazon EMR-arbejdsbelastninger. Med S3 Access Grants og EMR kan du nemt konfigurere adgang til data på S3 til IAM-identiteter eller ved at bruge dit firmakatalog i IAM Identity Center som din identitetskilde. S3 Access Grants understøttes på tværs af EMR på EC2, EMR på EKS og EMR Serverless fra og med EMR release 6.15.0.
For at lære mere, se S3 Access Grants , EMR dokumentation og stil gerne spørgsmål i kommentarerne!
Om forfatteren
 Damon Cortesi er Principal Developer Advocate hos Amazon Web Services. Han bygger værktøjer og indhold for at gøre livet lettere for dataingeniører. Når han ikke arbejder hårdt, bygger han stadig datapipelines og deler logs i sin fritid.
Damon Cortesi er Principal Developer Advocate hos Amazon Web Services. Han bygger værktøjer og indhold for at gøre livet lettere for dataingeniører. Når han ikke arbejder hårdt, bygger han stadig datapipelines og deler logs i sin fritid.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/use-amazon-emr-with-s3-access-grants-to-scale-spark-access-to-amazon-s3/
- :har
- :er
- :ikke
- :hvor
- $OP
- 1
- 10
- 100
- 107
- 11
- 1232
- 15 %
- 20
- 2018
- 500
- 7
- 8
- a
- Om
- over
- adgang
- adgangsstyring
- Adgang til data
- tilgængelig
- Adgang
- Konto
- Konti
- anerkende
- tværs
- Handling
- aktioner
- Desuden
- adresse
- administrative
- fortaler
- igen
- forude
- Alle
- tillade
- tillader
- sammen
- også
- Amazon
- Amazon EC2
- Amazon Elastic Kubernetes Service
- Amazon EMR
- Amazon Web Services
- an
- Analytikere
- analytics
- analysere
- ,
- Annoncere
- En anden
- enhver
- Apache
- Apache Spark
- Anvendelse
- applikationer
- cirka
- arkitektur
- ER
- AS
- spørg
- forbundet
- antage
- At
- tilladelse
- til rådighed
- undgå
- AWS
- AWS CloudFormation
- tilbage
- grundlag
- BE
- bliver
- før
- Begyndelse
- jf. nedenstående
- fordele
- Bedre
- mellem
- browser
- bygger
- virksomhed
- men
- .
- by
- CAN
- tilfælde
- center
- lave om
- Ændringer
- afkrydset
- Vælg
- klik
- kunde
- Cloud
- Cluster
- kode
- kombination
- kombinerer
- Fælles
- fuldføre
- Afsluttet
- komplekse
- Compute
- konfigureret
- konfigurering
- Tilslut
- forbruger
- Forbrugere
- indhold
- fortsæt
- kontrol
- konvertere
- Corporate
- Tilsvarende
- Omkostninger
- skabe
- oprettet
- skaber
- Oprettelse af
- Legitimationsoplysninger
- skik
- Kunder
- data
- dataadgang
- decentral
- Standard
- defaults
- indsætte
- implementering
- Udvikler
- forskellige
- direkte
- do
- dokumentation
- færdig
- ned
- downloade
- driver
- e
- hver
- lettere
- nemt
- let
- effekt
- Effektiv
- fremkomsten
- muliggøre
- Endpoint
- håndhæve
- ingeniør
- Ingeniører
- Forbedrer
- sikre
- miljøer
- fejl
- Ether (ETH)
- Endog
- eksempler
- udføre
- Fall
- Mode
- føler sig
- få
- Fields
- File (Felt)
- Filer
- filtrering
- Endelig
- Finde
- slut
- Fornavn
- følger
- efter
- Til
- Gratis
- fra
- fremtiden
- gateway
- generere
- få
- Giv
- Go
- gå
- fik
- indrømme
- bevilget
- tilskud
- kornet
- gruppe
- Gruppens
- praktisk
- Hård Ost
- Have
- he
- hjælpe
- stærkt
- hans
- Hive
- Hvordan
- How To
- HTML
- HTTPS
- i
- IAM
- ID
- identiteter
- Identity
- identitets- og adgangsstyring
- id'er
- if
- importere
- vigtigt
- in
- stigende
- individuel
- oplysninger
- installeret
- instans
- i stedet
- integration
- interaktiv
- grænseflade
- ind
- introduceret
- IT
- Job
- Karriere
- jpg
- lige
- Nøgle
- Kubernetes
- senere
- seneste
- lancere
- LÆR
- Forlade
- niveauer
- ligesom
- GRÆNSE
- Line (linje)
- Lives
- lokalt
- placering
- log
- Logge på
- maskine
- opretholdelse
- lave
- administrere
- ledelse
- styring
- manuelt
- mange
- kort
- kortlægning
- Kan..
- mesh
- minut
- minutter
- mere
- flere
- skal
- navn
- nødvendig
- Behov
- netværk
- Ny
- næste
- ingen
- Bemærk
- notesbog
- notesbøger
- nu
- of
- on
- engang
- ONE
- kun
- åbent
- Indstillinger
- or
- ordrer
- organisation
- Andet
- vores
- output
- udgange
- uden for
- egen
- side
- del
- særlig
- Mønster
- mønstre
- tilladelse
- Tilladelser
- Place
- plato
- Platon Data Intelligence
- PlatoData
- tilfreds
- politikker
- politik
- Indlæg
- tidligere
- Main
- skoleledere
- private
- producent
- Producenter
- give
- forudsat
- udbyder
- udbydere
- giver
- leverer
- offentlige
- formål
- forespørgsler
- Spørgsmål
- Hurtig
- nå
- Læs
- Læser
- refererer
- region
- registrering
- frigive
- relevant
- resterende
- erstatte
- anmode
- påkrævet
- ressource
- Ressourcer
- svar
- resulterer
- roller
- roller
- R
- Kør
- løber
- runtime
- samme
- Gem
- Scale
- scenarie
- scenarier
- rækkevidde
- script
- Anden
- sekunder
- Secret
- Sektion
- sikker
- sikkerhed
- se
- Vælg
- Serverless
- tjeneste
- Tjenester
- sessioner
- sæt
- indstilling
- setup
- Del
- bør
- Vis
- viste
- vist
- side
- lignende
- Simpelt
- enkelhed
- forenkler
- situationer
- uddrag
- So
- nogle
- Kilde
- Spark
- specifikke
- specifikt
- splits
- SQL
- stable
- Stakke
- påbegyndt
- Starter
- starter
- Tilstand
- Statement
- Status
- Steps
- Stadig
- opbevaring
- Studio
- indsende
- undernet
- succes
- Understøttet
- sikker
- systemet
- Tag
- tager
- skabelon
- midlertidig
- prøve
- at
- deres
- derefter
- Disse
- de
- denne
- dem
- Gennem
- tid
- til
- værktøjer
- Oversættelse
- prøv
- to
- typen
- typer
- ui
- under
- URL
- brug
- anvendte
- nyttigt
- Bruger
- brugere
- bruger
- ved brug af
- udnytte
- værdi
- Værdier
- udgave
- via
- Specifikation
- Virtual
- gå
- gå
- ønsker
- Vej..
- we
- Vejr
- web
- webservices
- GODT
- Hvad
- Hvad er
- hvornår
- som
- mens
- vilje
- vindue
- ønsker
- med
- Arbejde
- virker
- skriver
- forfatter
- yaml
- år
- dig
- Din
- dig selv
- zephyrnet