Einleitung
Die One-Class Support Vector Machine (SVM) ist eine Variante der traditionellen SVM. Es ist speziell auf die Erkennung von Anomalien zugeschnitten. Ihr primäres Ziel ist es, Fälle zu lokalisieren, die deutlich vom Standard abweichen. Anders als herkömmliche Maschinelles lernen Bei Modellen mit Fokus auf Binär- oder Mehrklassenklassifizierung ist die Einklassen-SVM auf die Erkennung von Ausreißern oder Neuheiten in Datensätzen spezialisiert. In diesem Artikel erfahren Sie, wie sich die One-Class Support Vector Machine (SVM) von der herkömmlichen SVM unterscheidet. Außerdem erfahren Sie, wie OC-SVM funktioniert und wie Sie es implementieren. Sie erfahren auch etwas über seine Hyperparameter.
Lernziele
- Anomalien verstehen
- Erfahren Sie mehr über One-Class-SVM
- Verstehen Sie, wie es sich von der herkömmlichen Support Vector Machine (SVM) unterscheidet.
- Hyperparameter von OC-SVM in Sklearn
- So erkennen Sie Anomalien mithilfe von OC-SVM
- Anwendungsfälle von One-Class-SVM
Inhaltsverzeichnis
Anomalien verstehen
Anomalien sind Beobachtungen oder Vorkommnisse, die erheblich vom normalen Verhalten eines Datensatzes abweichen. Diese Abweichungen können sich in verschiedenen Formen manifestieren, beispielsweise als Ausreißer, Rauschen, Fehler oder unerwartete Muster. Anomalien sind oft faszinierend, weil sie wertvolle Erkenntnisse liefern können. Sie könnten Erkenntnisse liefern, etwa zur Identifizierung betrügerischer Transaktionen, zur Erkennung von Gerätefehlfunktionen oder zur Aufdeckung neuartiger Phänomene. Die Ausreißer- und Neuheitserkennung identifiziert Anomalien und abnormale oder ungewöhnliche Beobachtungen.
Lesen Sie auch: Ein umfassender Leitfaden zur Erkennung von Anomalien
Eine Klassen-SVM
Einführung in Support Vector Machines (SVMs)
Support Vector Machines (SVMs) sind ein beliebter überwachter Lernalgorithmus für Klassifikations- und Regressionsaufgaben. SVMs funktionieren, indem sie die optimale Hyperebene finden, die verschiedene Klassen im Feature-Space trennt und gleichzeitig den Abstand zwischen ihnen maximiert. Diese Hyperebene basiert auf einer Teilmenge von Trainingsdatenpunkten, die als Unterstützungsvektoren bezeichnet werden.
Einklassen-SVM vs. traditionelle SVM
- Einklassen-SVMs stellen eine Variante des herkömmlichen SVM-Algorithmus dar, der hauptsächlich für Aufgaben zur Erkennung von Ausreißern und Neuheiten eingesetzt wird. Im Gegensatz zu herkömmlichen SVMs, die binäre Klassifizierungsaufgaben übernehmen, trainiert One-Class SVM ausschließlich auf Datenpunkten einer einzelnen Klasse, der sogenannten Zielklasse. Ziel einer Ein-Klassen-SVM ist es, eine Grenz- oder Entscheidungsfunktion zu erlernen, die die Zielklasse im Merkmalsraum kapselt und so das normale Verhalten der Daten effektiv modelliert.
- Traditionelle SVMs zielen darauf ab, eine Entscheidungsgrenze zu finden, die den Spielraum zwischen verschiedenen Klassen maximiert und so eine optimale Klassifizierung neuer Datenpunkte ermöglicht. Andererseits versucht One-Class SVM, eine Grenze zu finden, die die Zielklasse einschließt und gleichzeitig das Risiko minimiert, dass Ausreißer oder neuartige Instanzen außerhalb dieser Grenze eingeschlossen werden.
- Herkömmliche SVMs erfordern gekennzeichnete Daten mit Instanzen aus mehreren Klassen, wodurch sie für überwachte Klassifizierungsaufgaben geeignet sind. Im Gegensatz dazu ermöglicht eine One-Class-SVM den Einsatz in Szenarien, in denen nur Daten aus der Zielklasse verfügbar sind, wodurch sie sich gut für unbeaufsichtigte Anomalieerkennungs- und Neuheitserkennungsaufgaben eignet.
Erfahren Sie mehr: Einklassenklassifizierung mithilfe von Support-Vektor-Maschinen
Beide unterscheiden sich in ihren Soft-Margin-Formulierungen und der Art und Weise, wie sie sie verwenden:
(Der weiche Rand in SVM wird verwendet, um ein gewisses Maß an Fehlklassifizierung zu ermöglichen.)
Ein-Klassen-SVM zielt darauf ab, eine Hyperebene mit maximalem Spielraum innerhalb des Merkmalsraums zu entdecken, indem die zugeordneten Daten vom Ursprung getrennt werden. Auf einem Datensatz Dn = {x1, . . . , xn} mit xi ∈ X (xi ist ein Merkmal) und n Dimensionen:
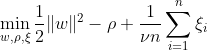
Diese Gleichung stellt die ursprüngliche Problemformulierung für OC-SVM dar, wobei w die trennende Hyperebene, ρ der Versatz vom Ursprung und ξi Slack-Variablen sind. Sie erlauben einen weichen Spielraum, bestrafen jedoch Verstöße ξi. Ein Hyperparameter ν ∈ (0, 1] steuert die Wirkung der Slack-Variablen und sollte je nach Bedarf angepasst werden. Das Ziel besteht darin, die Norm von w zu minimieren und gleichzeitig Abweichungen von der Marge zu bestrafen. Darüber hinaus ermöglicht dies einen Bruchteil der Daten innerhalb des Randes oder auf der falschen Seite der Hyperebene liegen.
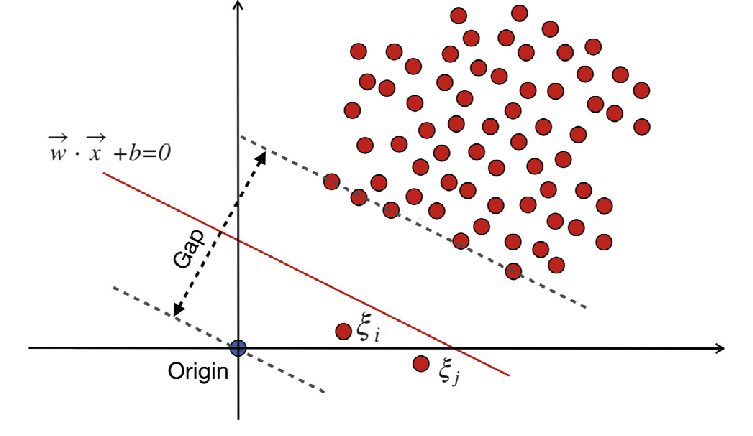
WX + b =0 ist die Entscheidungsgrenze und die Slack-Variablen bestrafen Abweichungen.
Traditional-Support Vector Machines (SVM)
Traditional-Support Vector Machines (SVM) verwenden die Soft-Margin-Formulierung für Fehlklassifizierungsfehler. Oder sie verwenden Datenpunkte, die innerhalb des Spielraums oder auf der falschen Seite der Entscheidungsgrenze liegen.
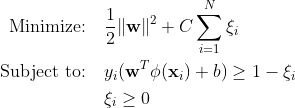
Wo:
w ist der Gewichtsvektor.
b ist der Bias-Term.
ξi sind Slack-Variablen, die eine Soft-Margin-Optimierung ermöglichen.
C ist der Regularisierungsparameter, der den Kompromiss zwischen der Maximierung der Marge und der Minimierung des Klassifizierungsfehlers steuert.
ϕ(xi) repräsentiert die Feature-Mapping-Funktion.
In der traditionellen SVM integriert eine überwachte Lernmethode, die zur Trennung auf Klassenbezeichnungen basiert, Slack-Variablen, um ein bestimmtes Maß an Fehlklassifizierung zu ermöglichen. Das Hauptziel von SVM besteht darin, Datenpunkte verschiedener Klassen mithilfe der Entscheidungsgrenze WX + b = 0 zu trennen. Der Wert von Slack-Variablen variiert je nach Position der Datenpunkte: Sie werden auf 0 gesetzt, wenn sich die Datenpunkte außerhalb der Ränder befinden. Wenn sich der Datenpunkt innerhalb des Randes befindet, liegen die Slack-Variablen zwischen 0 und 1 und erstrecken sich über den gegenüberliegenden Rand hinaus, wenn sie größer als 1 sind.
Sowohl herkömmliche SVMs als auch One-Class-SVMs mit Soft-Margin-Formulierungen zielen darauf ab, die Norm des Gewichtsvektors zu minimieren. Dennoch unterscheiden sie sich in ihren Zielen und in der Art und Weise, wie sie mit Fehlklassifizierungsfehlern oder Abweichungen von der Entscheidungsgrenze umgehen. Herkömmliche SVMs optimieren die Klassifizierungsgenauigkeit, um eine Überanpassung zu vermeiden, während sich Ein-Klassen-SVMs auf die Modellierung der Zielklasse und die Kontrolle des Anteils von Ausreißern oder neuartigen Instanzen konzentrieren.
Lesen Sie auch: Der AZ-Leitfaden zur Unterstützung von Vector Machine
Wichtige Hyperparameter in Ein-Klassen-SVM
- naja: Dies ist ein entscheidender Hyperparameter in One-Class SVM, der den Anteil der zulässigen Ausreißer steuert. Es legt eine Obergrenze für den Anteil der Trainingsfehler und eine Untergrenze für den Anteil der Unterstützungsvektoren fest. Er liegt typischerweise zwischen 0 und 1, wobei niedrigere Werte eine strengere Marge implizieren und möglicherweise weniger Ausreißer erfassen, während höhere Werte freizügiger sind. Der Standardwert ist 0.5.
- Kern: Die Kernelfunktion bestimmt die Art der Entscheidungsgrenze, die die SVM verwendet. Zu den gängigen Optionen gehören „linear“, „rbf“ (Gaußsche radiale Basisfunktion), „Poly“ (Polynom) und „Sigmoid“. Der „rbf“-Kernel wird häufig verwendet, da er komplexe nichtlineare Zusammenhänge effektiv erfassen kann.
- Gamma: Dies ist ein Parameter für nichtlineare Hyperebenen. Es definiert, wie viel Einfluss ein einzelnes Trainingsbeispiel hat. Je größer der Gammawert, desto näher müssen andere Beispiele sein, um betroffen zu sein. Dieser Parameter ist spezifisch für den RBF-Kernel und wird normalerweise auf „auto“ gesetzt, was standardmäßig 1 / n_features ist.
- Kernel-Parameter (Grad, Coef0): Diese Parameter gelten für Polynom- und Sigmoidkerne. „Grad“ ist der Grad der polynomialen Kernelfunktion und „coef0“ ist der unabhängige Term in der Kernelfunktion. Um eine optimale Leistung zu erzielen, kann eine Optimierung dieser Parameter erforderlich sein.
- Tol: Dies ist das Abbruchkriterium. Der Algorithmus stoppt, wenn die Dualitätslücke kleiner als die Toleranz ist. Es handelt sich um einen Parameter, der die Toleranz für das Stoppkriterium steuert.
Funktionsprinzip der Ein-Klassen-SVM
Kernelfunktionen in einer Ein-Klassen-SVM
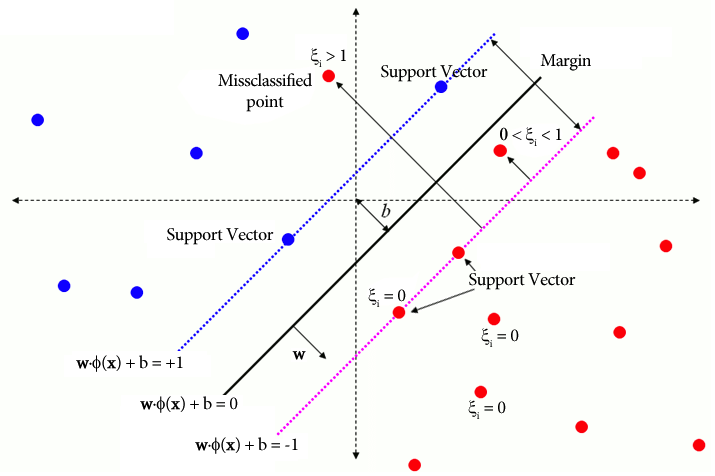
Kernelfunktionen spielen in One-Class-SVM eine entscheidende Rolle, indem sie es dem Algorithmus ermöglichen, in höherdimensionalen Merkmalsräumen zu arbeiten, ohne die Transformationen explizit zu berechnen. In One-Class-SVM werden wie in herkömmlichen SVMs Kernelfunktionen verwendet, um die Ähnlichkeit zwischen Datenpunktpaaren im Eingaberaum zu messen. Zu den gängigen Kernelfunktionen, die in One-Class-SVM verwendet werden, gehören Gauß-Kernel (RBF), Polynom- und Sigmoid-Kernel. Diese Kernel bilden den ursprünglichen Eingaberaum in einen höherdimensionalen Raum ab, in dem Datenpunkte linear trennbar werden oder deutlichere Muster aufweisen, was das Lernen erleichtert. Durch Auswahl einer geeigneten Kernelfunktion und Optimierung ihrer Parameter kann One-Class SVM komplexe Beziehungen und nichtlineare Strukturen in den Daten effektiv erfassen und so Anomalien oder Ausreißer besser erkennen.
In Fällen, in denen die Daten nicht linear trennbar sind, beispielsweise bei komplexen oder überlappenden Mustern, können Support Vector Machines (SVMs) einen Radial Basis Function (RBF)-Kernel verwenden, um Ausreißer effektiv vom Rest der Daten zu trennen. Der RBF-Kernel wandelt die Eingabedaten in einen höherdimensionalen Merkmalsraum um, der besser getrennt werden kann.
Margin- und Support-Vektoren
Das Konzept der Margen- und Unterstützungsvektoren in One-Class-SVM ähnelt dem in herkömmlichen SVMs. Der Spielraum bezieht sich auf den Bereich zwischen der Entscheidungsgrenze (Hyperebene) und den nächstgelegenen Datenpunkten jeder Klasse. In One-Class-SVM stellt der Rand den Bereich dar, in dem die meisten Datenpunkte der Zielklasse liegen. Die Maximierung der Marge ist für One-Class-SVM von entscheidender Bedeutung, da sie dabei hilft, neue Datenpunkte gut zu verallgemeinern und die Robustheit des Modells verbessert. Unterstützungsvektoren sind die Datenpunkte, die auf oder innerhalb des Randes liegen und zur Definition der Entscheidungsgrenze beitragen.
In der One-Class-SVM sind Unterstützungsvektoren die Datenpunkte der Zielklasse, die der Entscheidungsgrenze am nächsten liegen. Diese Unterstützungsvektoren spielen eine wichtige Rolle bei der Bestimmung der Form und Ausrichtung der Entscheidungsgrenze und damit bei der Gesamtleistung des One-Class-SVM-Modells. Durch die Identifizierung der Unterstützungsvektoren lernt One-Class SVM effektiv die Darstellung der Zielklasse im Merkmalsraum und erstellt eine Entscheidungsgrenze, die die meisten Datenpunkte einschließt und gleichzeitig das Risiko der Einbeziehung von Ausreißern oder neuartigen Instanzen minimiert.
Wie können Anomalien mithilfe von One-Class-SVM erkannt werden?
Erkennen von Anomalien mithilfe einer Ein-Klassen-SVM (Support Vector Machine) durch Techniken zur Erkennung von Neuheiten und Ausreißern:
Ausreißererkennung
Dabei geht es darum, Beobachtungen in den Trainingsdaten zu identifizieren, die deutlich vom Rest abweichen und oft als Ausreißer bezeichnet werden. Schätzer für Ausreißererkennung Ziel ist es, die Bereiche anzupassen, in denen die Trainingsdaten am stärksten konzentriert sind, und dabei diese abweichenden Beobachtungen außer Acht zu lassen.
from sklearn.svm import OneClassSVM
from sklearn.datasets import load_wine
import matplotlib.pyplot as plt
import matplotlib.lines as mlines
from sklearn.inspection import DecisionBoundaryDisplay
# Load data
X = load_wine()["data"][:, [6, 9]] # "banana"-shaped
# Define estimators (One-Class SVM)
estimators_hard_margin = {
"Hard Margin OCSVM": OneClassSVM(nu=0.01, gamma=0.35), # Very small nu for hard margin
}
estimators_soft_margin = {
"Soft Margin OCSVM": OneClassSVM(nu=0.25, gamma=0.35), # Nu between 0 and 1 for soft margin
}
# Plotting setup
fig, axs = plt.subplots(1, 2, figsize=(12, 5))
colors = ["tab:blue", "tab:orange", "tab:red"]
legend_lines = []
# Hard Margin OCSVM
ax = axs[0]
for color, (name, estimator) in zip(colors, estimators_hard_margin.items()):
estimator.fit(X)
DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
levels=[0],
colors=color,
ax=ax,
)
legend_lines.append(mlines.Line2D([], [], color=color, label=name))
ax.scatter(X[:, 0], X[:, 1], color="black")
ax.legend(handles=legend_lines, loc="upper center")
ax.set(
xlabel="flavanoids",
ylabel="color_intensity",
title="Hard Margin Outlier detection (wine recognition)",
)
# Soft Margin OCSVM
ax = axs[1]
legend_lines = []
for color, (name, estimator) in zip(colors, estimators_soft_margin.items()):
estimator.fit(X)
DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
levels=[0],
colors=color,
ax=ax,
)
legend_lines.append(mlines.Line2D([], [], color=color, label=name))
ax.scatter(X[:, 0], X[:, 1], color="black")
ax.legend(handles=legend_lines, loc="upper center")
ax.set(
xlabel="flavanoids",
ylabel="color_intensity",
title="Soft Margin Outlier detection (wine recognition)",
)
plt.tight_layout()
plt.show()

Mithilfe der Diagramme können wir die Leistung der One-Class-SVM-Modelle bei der Erkennung von Ausreißern im Wine-Datensatz visuell überprüfen.
Durch den Vergleich der Ergebnisse von One-Class-SVM-Modellen mit hartem und weichem Rand können wir beobachten, wie sich die Wahl der Randeinstellung (Nu-Parameter) auf die Ausreißererkennung auswirkt.
Das Hard-Margin-Modell mit einem sehr kleinen nu-Wert (0.01) führt wahrscheinlich zu einer konservativeren Entscheidungsgrenze. Die Mehrzahl der Datenpunkte werden eng umschlossen und möglicherweise weniger Punkte als Ausreißer klassifiziert.
Umgekehrt führt das Soft-Marge-Modell mit einem größeren Nu-Wert (0.35) wahrscheinlich zu einer flexibleren Entscheidungsgrenze. Dies ermöglicht einen größeren Spielraum und ermöglicht möglicherweise die Erfassung von mehr Ausreißern.
Neuheitserkennung
Andererseits wenden wir es an, wenn die Trainingsdaten frei von Ausreißern sind und das Ziel darin besteht, festzustellen, ob eine neue Beobachtung selten ist, sich also stark von bekannten Beobachtungen unterscheidet. Diese neueste Beobachtung wird hier als Neuheit bezeichnet.
import numpy as np
from sklearn import svm
# Generate train data
np.random.seed(30)
X = 0.3 * np.random.randn(100, 2)
X_train = np.r_[X + 2, X - 2]
# Generate some regular novel observations
X = 0.3 * np.random.randn(20, 2)
X_test = np.r_[X + 2, X - 2]
# Generate some abnormal novel observations
X_outliers = np.random.uniform(low=-4, high=4, size=(20, 2))
# fit the model
clf = svm.OneClassSVM(nu=0.1, kernel="rbf", gamma=0.1)
clf.fit(X_train)
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
y_pred_outliers = clf.predict(X_outliers)
n_error_train = y_pred_train[y_pred_train == -1].size
n_error_test = y_pred_test[y_pred_test == -1].size
n_error_outliers = y_pred_outliers[y_pred_outliers == 1].size
import matplotlib.font_manager
import matplotlib.lines as mlines
import matplotlib.pyplot as plt
from sklearn.inspection import DecisionBoundaryDisplay
_, ax = plt.subplots()
# generate grid for the boundary display
xx, yy = np.meshgrid(np.linspace(-5, 5, 10), np.linspace(-5, 5, 10))
X = np.concatenate([xx.reshape(-1, 1), yy.reshape(-1, 1)], axis=1)
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
plot_method="contourf",
ax=ax,
cmap="PuBu",
)
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
plot_method="contourf",
ax=ax,
levels=[0, 10000],
colors="palevioletred",
)
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
plot_method="contour",
ax=ax,
levels=[0],
colors="darkred",
linewidths=2,
)
s = 40
b1 = ax.scatter(X_train[:, 0], X_train[:, 1], c="white", s=s, edgecolors="k")
b2 = ax.scatter(X_test[:, 0], X_test[:, 1], c="blueviolet", s=s, edgecolors="k")
c = ax.scatter(X_outliers[:, 0], X_outliers[:, 1], c="gold", s=s, edgecolors="k")
plt.legend(
[mlines.Line2D([], [], color="darkred"), b1, b2, c],
[
"learned frontier",
"training observations",
"new regular observations",
"new abnormal observations",
],
loc="upper left",
prop=matplotlib.font_manager.FontProperties(size=11),
)
ax.set(
xlabel=(
f"error train: {n_error_train}/200 ; errors novel regular: {n_error_test}/40 ;"
f" errors novel abnormal: {n_error_outliers}/40"
),
title="Novelty Detection",
xlim=(-5, 5),
ylim=(-5, 5),
)
plt.show()
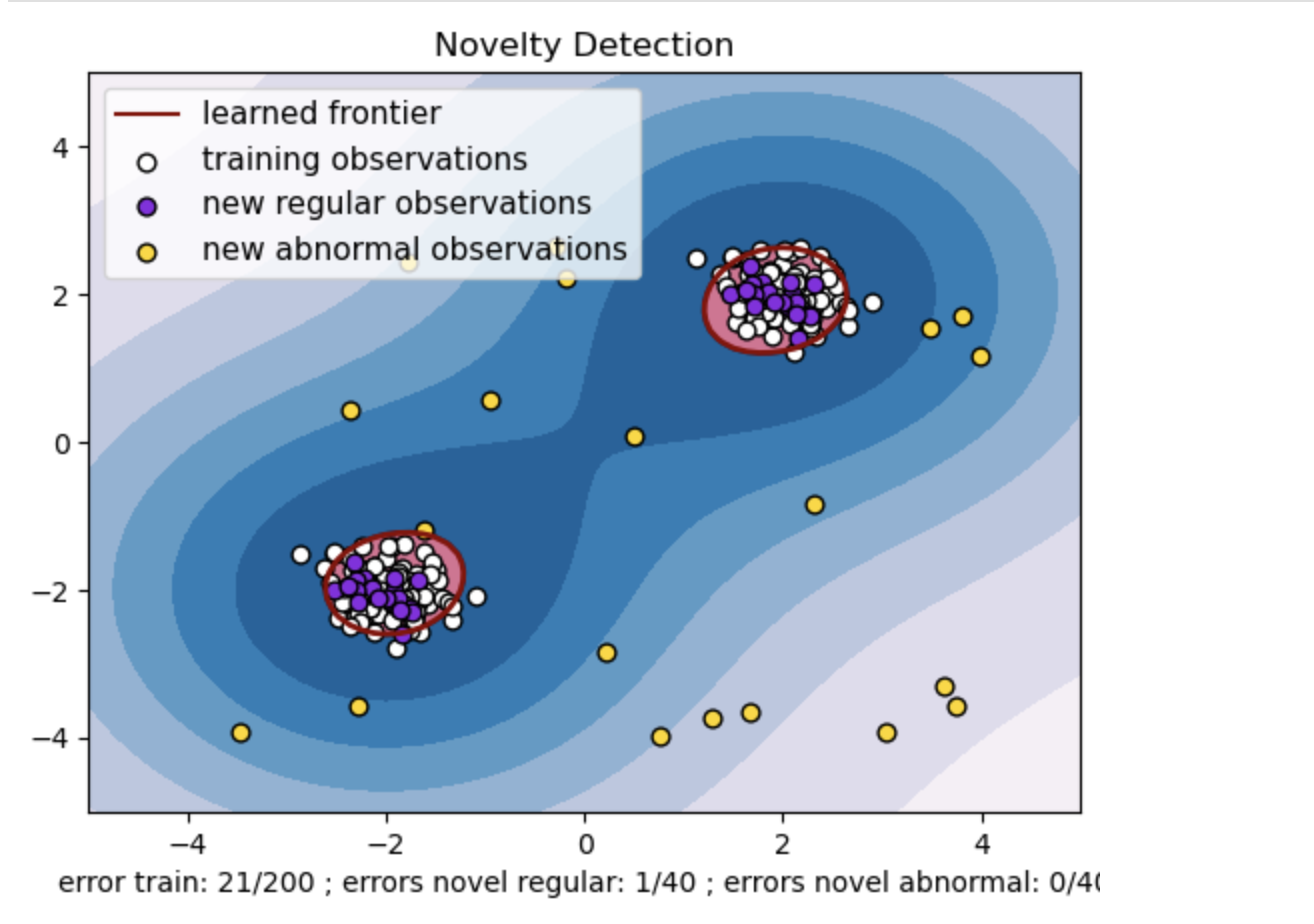
- Generieren Sie einen synthetischen Datensatz mit zwei Clustern von Datenpunkten. Generieren Sie dazu diese mit einer Normalverteilung um zwei verschiedene Zentren: (2, 2) und (-2, -2) für Trainings- und Testdaten. Generieren Sie zufällig zwanzig Datenpunkte gleichmäßig innerhalb eines quadratischen Bereichs im Bereich von -4 bis 4 entlang beider Dimensionen. Diese Datenpunkte stellen abnormale Beobachtungen oder Ausreißer dar, die erheblich vom normalen Verhalten abweichen, das in den Zug- und Testdaten beobachtet wird.
- Die gelernte Grenze bezieht sich auf die vom Ein-Klassen-SVM-Modell gelernte Entscheidungsgrenze. Diese Grenze trennt die Bereiche des Merkmalsraums, in denen das Modell Datenpunkte als normal betrachtet, von den Ausreißern.
- Der Farbverlauf von Blau zu Weiß in den Konturen stellt die unterschiedlichen Grade an Konfidenz oder Gewissheit dar, die das One-Class-SVM-Modell verschiedenen Regionen im Merkmalsraum zuweist, wobei dunklere Schattierungen eine höhere Konfidenz bei der Klassifizierung von Datenpunkten als „normal“ anzeigen. Dunkelblau zeigt Regionen an, die gemäß der Entscheidungsfunktion des Modells einen starken Hinweis darauf haben, dass sie „normal“ sind. Wenn die Farbe in der Kontur heller wird, ist das Modell weniger sicher, Datenpunkte als „normal“ zu klassifizieren.
- Das Diagramm stellt visuell dar, wie das Ein-Klassen-SVM-Modell zwischen regulären und abnormalen Beobachtungen unterscheiden kann. Die erlernte Entscheidungsgrenze trennt die Bereiche normaler und abnormaler Beobachtungen. Ein Klassen-SVM zur Neuheitserkennung beweist seine Wirksamkeit bei der Identifizierung abnormaler Beobachtungen in einem bestimmten Datensatz.
Für nu=0.5:
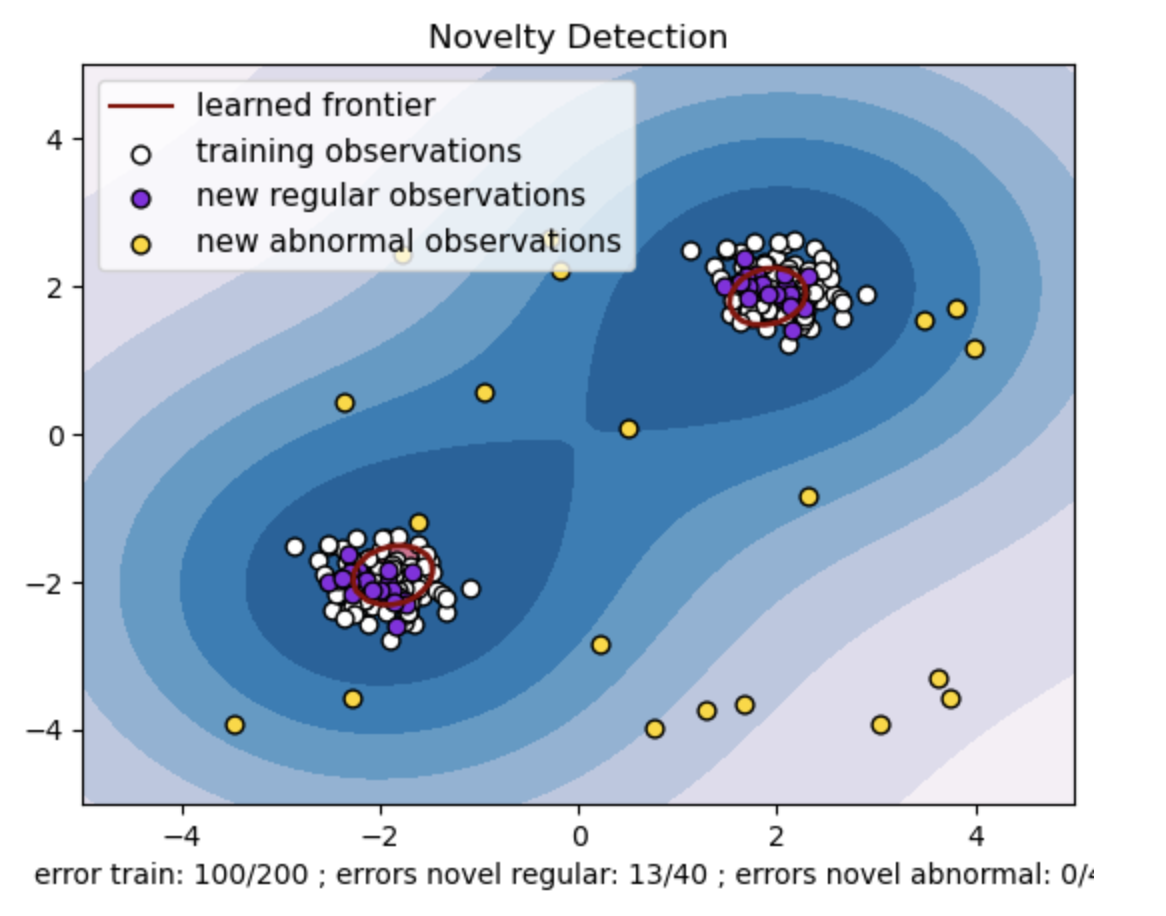
Der „nu“-Wert in der Ein-Klassen-SVM spielt eine entscheidende Rolle bei der Steuerung des Anteils der vom Modell tolerierten Ausreißer. Es wirkt sich direkt auf die Fähigkeit des Modells aus, Anomalien zu erkennen, und beeinflusst somit die Vorhersage. Wir können sehen, dass das Modell eine Fehlklassifizierung von 100 Trainingspunkten zulässt. Ein niedrigerer Wert von nu impliziert eine strengere Einschränkung des zulässigen Anteils an Ausreißern. Die Wahl von nu beeinflusst die Leistung des Modells bei der Erkennung von Anomalien. Es erfordert außerdem eine sorgfältige Abstimmung auf der Grundlage der spezifischen Anforderungen der Anwendung und der Eigenschaften des Datensatzes.
Für Gamma=0.5 und nu=0.5

In einer SVM einer Klasse stellt der Gamma-Hyperparameter den Kernelkoeffizienten für den Kernel „rbf“ dar. Dieser Hyperparameter beeinflusst die Form der Entscheidungsgrenze und beeinflusst folglich die Vorhersageleistung des Modells.
Wenn Gamma hoch ist, beschränkt ein einzelnes Trainingsbeispiel seinen Einfluss auf seine unmittelbare Umgebung. Dadurch entsteht eine stärker lokalisierte Entscheidungsgrenze. Daher müssen Datenpunkte näher an den Unterstützungsvektoren liegen, um zur gleichen Klasse zu gehören.
Zusammenfassung
Der Einsatz von One-Class-SVM zur Anomalieerkennung sowie die Ausreißer- und Neuheitserkennung bietet eine robuste Lösung für verschiedene Domänen. Dies ist in Szenarien hilfreich, in denen gekennzeichnete Anomaliedaten knapp oder nicht verfügbar sind. Dies macht es besonders wertvoll für reale Anwendungen, bei denen Anomalien selten sind und es schwierig ist, sie explizit zu definieren. Seine Anwendungsfälle erstrecken sich auf verschiedene Bereiche wie Cybersicherheit und Fehlerdiagnose, in denen Anomalien Konsequenzen haben. Obwohl One-Class-SVM zahlreiche Vorteile bietet, ist es notwendig, die Hyperparameter entsprechend den Daten festzulegen, um bessere Ergebnisse zu erzielen, was manchmal mühsam sein kann.
Häufig gestellte Fragen
A. Ein-Klassen-SVM erstellt eine Hyperebene (oder eine Hypersphäre in höheren Dimensionen), die die normalen Datenpunkte einkapselt. Diese Hyperebene ist so positioniert, dass der Abstand zwischen den Normaldaten und der Entscheidungsgrenze maximiert wird. Datenpunkte werden während des Tests oder der Schlussfolgerung als normal (innerhalb der Grenze) oder als Anomalien (außerhalb der Grenze) klassifiziert.
A. Eine SVM mit einer Klasse ist vorteilhaft, da sie keine gekennzeichneten Daten für Anomalien während des Trainings erfordert. Es kann aus einem Datensatz lernen, der nur reguläre Instanzen enthält, wodurch es für Szenarien geeignet ist, in denen Anomalien selten sind und es schwierig ist, gekennzeichnete Beispiele für das Training zu erhalten.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.analyticsvidhya.com/blog/2024/03/one-class-svm-for-anomaly-detection/
- :hast
- :Ist
- :nicht
- :Wo
- 01
- 1
- 10
- 100
- 10000
- 12
- 2%
- 20
- 25
- 30
- 35%
- 4
- 40
- 5
- 6
- 9
- a
- Fähigkeit
- abnorme
- Über uns
- Nach
- Genauigkeit
- Erreichen
- über
- Bereinigt
- vorteilhaft
- Vorteilen
- betroffen
- wirkt
- Ziel
- Ziel
- Algorithmus
- erlauben
- erlaubt
- Zulassen
- erlaubt
- entlang
- ebenfalls
- an
- und
- Anomalieerkennung
- Anwendung
- Anwendungen
- Jetzt bewerben
- angemessen
- SIND
- Bereiche
- um
- Artikel
- AS
- gefragt
- verfügbar
- vermeiden
- AXS
- b
- Banane
- basierend
- Grundlage
- BE
- weil
- werden
- wird
- Verhalten
- Sein
- gehörend
- Vorteile
- Besser
- zwischen
- Beyond
- vorspannen
- binär
- Schwarz
- Blau
- beide
- gebunden
- aber
- by
- namens
- CAN
- Erfassung
- Capturing
- vorsichtig
- Fälle
- Center
- Centers
- sicher
- Sicherheit
- herausfordernd
- Charakteristik
- Wahl
- Entscheidungen
- Auswahl
- Klasse
- Unterricht
- Einstufung
- eingestuft
- Klassifikator
- CLF
- näher
- Am nächsten
- Farbe
- gemeinsam
- Vergleich
- Komplex
- umfassend
- Computing
- Konzentriert
- konzept
- Vertrauen
- Folgen
- Folglich
- konservativ
- überlegt
- Einschränkung
- Konstrukte
- mit
- Kontrast
- beitragen
- Regelung
- Steuerung
- konventionellen
- schafft
- wichtig
- Internet-Sicherheit
- Dunkel
- dunkler
- technische Daten
- Datenpunkte
- Datensätze
- Behandlung
- Entscheidung
- Standard
- defaults
- definieren
- Definiert
- Definition
- Grad
- Abhängig
- entdecken
- erkannt
- Erkennung
- Entdeckung
- Bestimmen
- entschlossen
- Festlegung
- abweichen
- Diagnose
- abweichen
- anders
- Größe
- Direkt
- entdeckt,
- Display
- Missachtung
- deutlich
- unterscheiden
- Verteilung
- verschieden
- do
- die
- Domains
- im
- e
- jeder
- bewirken
- effektiv
- Wirksamkeit
- beschäftigt
- kapselt
- End-to-End
- Gleichung
- Ausrüstung
- Fehler
- Fehler
- Äther (ETH)
- Beispiel
- Beispiele
- ausschließlich
- zeigen
- explizit
- erweitern
- Verlängerung
- erleichtern
- Fallen
- faszinierend
- Fehler
- Merkmal
- Weniger
- Feige
- Finden Sie
- Suche nach
- passen
- flexibel
- Setzen Sie mit Achtsamkeit
- konzentriert
- Aussichten für
- Formen
- Formulierung
- Formulierungen
- Fraktion
- betrügerisch
- Frei
- für
- Grenze
- Funktion
- Funktionen
- weiter
- Lücke
- erzeugen
- Erzeugung
- bekommen
- gegeben
- Kundenziele
- Gold
- mehr
- Gitter
- Guide
- Pflege
- Griff
- hart
- Haben
- hilft
- hier
- High
- höher
- Ultraschall
- Hilfe
- aber
- HTTPS
- i
- identifizieren
- Identifizierung
- if
- unmittelbar
- implementieren
- impliziert
- implizieren
- importieren
- verbessert
- Verbesserung
- in
- das
- Einschließlich
- beinhaltet
- unabhängig
- zeigt
- Anzeige
- Indikation
- beeinflussen
- Eingabe
- innerhalb
- Einblicke
- Instanzen
- in
- beinhaltet
- IT
- SEINE
- jpg
- bekannt
- Etiketten
- größer
- neueste
- LERNEN
- gelernt
- lernen
- lernt
- links
- weniger
- Niveau
- Lüge
- Feuerzeug
- wahrscheinlich
- Grenzen
- linear
- Linien
- Belastung
- located
- Standorte
- senken
- Maschine
- Maschinen
- Mehrheit
- Making
- Störungen
- Karte
- Mapping
- Marge
- Margen
- Matplotlib
- max-width
- Maximieren
- maximiert
- Maximierung
- maximal
- Kann..
- messen
- Methode
- könnte
- minimieren
- minimieren
- Modell
- Modellieren
- für
- mehr
- vor allem warme
- viel
- mehrere
- sollen
- Name
- notwendig,
- Need
- Neu
- Lärm
- normal
- vor allem
- Roman
- Neuheit
- und viele
- zahlreiche vorteile
- numpig
- Ziel
- Beobachtung
- Beobachtungen
- beobachten
- beobachtet
- erhalten
- of
- Angebote
- Offset
- vorgenommen,
- on
- einzige
- betreiben
- gegenüber
- optimal
- Optimierung
- Optimieren
- or
- Orange
- Origin
- Original
- Andere
- Ausreißer
- aussen
- Gesamt-
- Paare
- Parameter
- Parameter
- besonders
- Muster
- Leistung
- Plato
- Datenintelligenz von Plato
- PlatoData
- Play
- spielt
- Grundstück
- Points
- Punkte
- Polynom
- positioniert
- möglicherweise
- Prognose
- prädiktive
- Geschenke
- in erster Linie
- primär
- Prinzip
- Aufgabenstellung:
- Anteil
- Beweist
- die
- zufällig
- Angebot
- Bereiche
- Bereich
- RARE
- Rbf
- Lesen Sie mehr
- realen Welt
- Anerkennung
- Rot
- bezieht sich
- Region
- Regionen
- Regression
- regulär
- Beziehungen
- verlässt sich
- vertreten
- Darstellung
- representiert
- erfordern
- Voraussetzungen:
- erfordert
- wohnt
- REST
- Die Ergebnisse
- Risiko
- robust
- Robustheit
- Rollen
- s
- gleich
- Knapp
- Szenarien
- sehen
- Sucht
- getrennte
- Trennung
- kompensieren
- Sets
- Einstellung
- Setup
- Form
- sollte
- Seite
- signifikant
- bedeutend
- ähnlich
- Single
- Größe
- locker
- klein
- kleinere
- SOFT
- Lösung
- einige
- manchmal
- Raumfahrt
- Räume
- spezialisiert
- spezifisch
- speziell
- quadratisch
- Standard
- Immer noch
- Einstellung
- Stoppt
- strengeren
- stark
- Strukturen
- so
- geeignet
- Aufsicht
- überwachtes Lernen
- Support
- sicher
- synthetisch
- zugeschnitten
- Target
- und Aufgaben
- Techniken
- langweilig
- Begriff
- Test
- Testen
- als
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- ihr
- Sie
- deswegen
- Diese
- vom Nutzer definierten
- fehlen uns die Worte.
- Durch
- So
- dicht
- zu
- Toleranz
- toleriert
- traditionell
- Training
- Ausbildung
- schult Ehrenamtliche
- Transaktionen
- Transformationen
- Transformationen
- Abstimmung
- zwanzig
- XNUMX
- tippe
- typisch
- nicht verfügbar
- Ungewöhnlich
- verstehen
- Unerwartet
- nicht wie
- us
- -
- benutzt
- verwendet
- Verwendung von
- wertvoll
- Wert
- Werte
- Variable
- Variablen
- Variante
- verschiedene
- Variieren
- Vektor
- Vektoren
- sehr
- Verstöße
- visuell
- vs
- W
- Weg..
- we
- Gewicht
- GUT
- Was
- wann
- ob
- welche
- während
- Weiß
- breiter
- werden wir
- WEIN
- mit
- .
- ohne
- Arbeiten
- Werk
- Falsch
- X
- xi
- U
- Zephyrnet