Einleitung
Wenn es um die GesichtserkennungForscher erweitern ständig die Grenzen der Genauigkeit und Skalierbarkeit. Eine erhebliche Herausforderung entsteht jedoch durch das exponentielle Wachstum von Identitäten bei gleichzeitig begrenzter Kapazität des GPU-Speichers. Frühere Studien konzentrierten sich hauptsächlich auf die Verfeinerung von Verlustfunktionen für Netzwerke zur Extraktion von Gesichtsmerkmalen, wobei Softmax-basierte Verlustfunktionen Fortschritte bei der Gesichtserkennungsleistung vorantreiben. Dennoch hat es sich als immer schwieriger erwiesen, die zunehmende Diskrepanz zwischen der steigenden Anzahl von Identitäten und den Einschränkungen des GPU-Speichers zu überbrücken. In diesem Artikel werden wir Strategien für die Gesichtserkennung im großen Maßstab mit partiellem FC untersuchen.

Lernziele
- Entdecken Sie die Herausforderungen, die der Softmax-Verlust bei der groß angelegten Gesichtserkennung mit sich bringt, wie etwa Rechenaufwand und Identitätsvolumen.
- Entdecken Sie die Partial Fully Connected (PFC)-Schicht, die den Speicher und die Berechnung bei Gesichtserkennungsaufgaben optimiert, einschließlich ihrer Vor- und Nachteile sowie Anwendungen.
- Implementieren Sie Partial FC in Gesichtserkennungsprojekten mit praktischen Tipps, Codeausschnitten und Ressourcen.
Dieser Artikel wurde als Teil des veröffentlicht Data Science-Blogathon.
Inhaltsverzeichnis
Was ist ein Softmax-Engpass?
Der Softmax-Verlust und seine Varianten wurden weithin als Ziele für Gesichtserkennungsaufgaben übernommen. Diese Funktionen führen während der Multiplikation zwischen den Einbettungsmerkmalen und der linearen Transformationsmatrix globale Feature-Klasse-Vergleiche durch.
Wenn es jedoch um eine große Anzahl von Identitäten im Trainingssatz geht, übersteigen die Kosten für die Speicherung und Berechnung der endgültigen linearen Matrix oft die Möglichkeiten der aktuellen GPU-Hardware. Dies kann zu Trainingsausfällen führen.
Bisherige Beschleunigungsversuche
Forscher haben verschiedene Techniken untersucht, um diesen Engpass zu beseitigen. Jedes hat seine eigenen Kompromisse und Einschränkungen.
HF-softmax verwendet einen dynamischen Auswahlprozess für aktive Klassenzentren innerhalb jedes Mini-Batches. Diese Auswahl wird durch die Erstellung eines zufälligen Hash-Waldes im Einbettungsraum erleichtert, der das Abrufen ungefährer nächstgelegener Klassenzentren basierend auf Merkmalen ermöglicht. Es ist jedoch wichtig zu beachten, dass es wichtig ist, alle Klassenzentren im RAM zu speichern und den Rechenaufwand für den Funktionsabruf nicht zu übersehen.
Andererseits unterteilt die Softmax-Dissektion den Softmax-Verlust in klasseninterne und klassenübergreifende Ziele und reduziert so redundante Berechnungen für die klassenübergreifende Komponente. Obwohl dieser Ansatz lobenswert ist, ist seine Anpassungsfähigkeit und Vielseitigkeit begrenzt, da er nur auf bestimmte Softmax-basierte Verlustfunktionen anwendbar ist.
Beide Methoden basieren auf dem Prinzip der Datenparallelität beim Multi-GPU-Training. Trotz des Versuchs, die Softmax-Verlustfunktion mit einer Teilmenge von Klassenzentren zu approximieren, verursachen sie immer noch erhebliche Kommunikationskosten zwischen GPUs für die Gradientenmittelung und die SGD-Synchronisierung. Darüber hinaus wird die Auswahl der Klassenzentren durch die Speicherkapazität der einzelnen GPUs eingeschränkt, was deren Skalierbarkeit weiter einschränkt.
Modellparallel: Ein Schritt in die richtige Richtung
Die ArcFace-Verlustfunktion führte Modellparallelität ein, die die Softmax-Gewichtsmatrix auf verschiedene GPUs aufteilt und den Softmax-Verlust der gesamten Klasse mit minimalem Kommunikationsaufwand berechnet. Mit diesem Ansatz wurden 1 Million Identitäten mithilfe von acht GPUs auf einem einzigen Computer erfolgreich trainiert.
Der modellparallele Ansatz unterteilt die Softmax-Gewichtsmatrix W ∈ R (d×C) in k Untermatrizen w der Größe d × (C/k), wobei d die Dimension des Einbettungsmerkmals und C die Anzahl der Klassen ist. Jede Submatrix wi wird dann auf der i-ten GPU platziert.
Um die endgültigen Softmax-Ausgaben zu berechnen, berechnet jede GPU unabhängig den Zähler e^((wi)T * X), wobei X das Eingabemerkmal ist. Der Nenner ∑ j=1 bis C e^((wj)T *
Dieser Ansatz reduziert die Kommunikation zwischen GPUs im Vergleich zur naiven Datenparallelität erheblich, da nur die lokalen Summen anstelle der Gradienten für die gesamte Gewichtsmatrix W kommuniziert werden müssen.
Weitere Informationen zur Arcface-Verlustfunktion finden Sie in meinem vorherigen Blog(ArcFace-Verlustfunktion für Deep Face Recognition), in dem ich ausführlich erklärt habe.
Speichergrenzen von Model Parallel
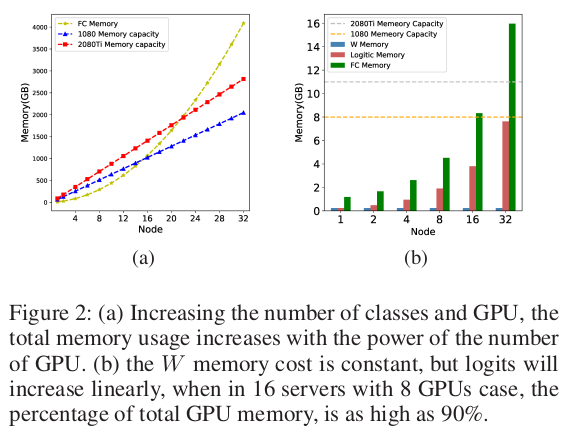
Während Modellparallelität die Speicherbelastung durch die Speicherung der Gewichtsmatrix W verringert, führt sie zu einem neuen Engpass – der Speicherung vorhergesagter Logits.
Die vorhergesagten Logits sind Zwischenwerte, die während des Vorwärtsdurchlaufs berechnet werden, und ihre Speicheranforderungen skalieren mit der Gesamtstapelgröße über alle GPUs hinweg. Mit steigender Anzahl an Identitäten und GPUs kann der Speicherverbrauch für die Speicherung von Protokollen schnell die GPU-Speicherkapazität übersteigen.
Diese Einschränkung schränkt die Skalierbarkeit des modellparallelen Ansatzes ein, selbst bei einer zunehmenden Anzahl von GPUs.
Wir stellen Partial FC vor
Um die Einschränkungen bisheriger Ansätze zu überwinden, schlagen die Autoren des „Partial FC“-Papiers eine bahnbrechende Lösung vor!
Teilweise FC (vollständig verbunden)
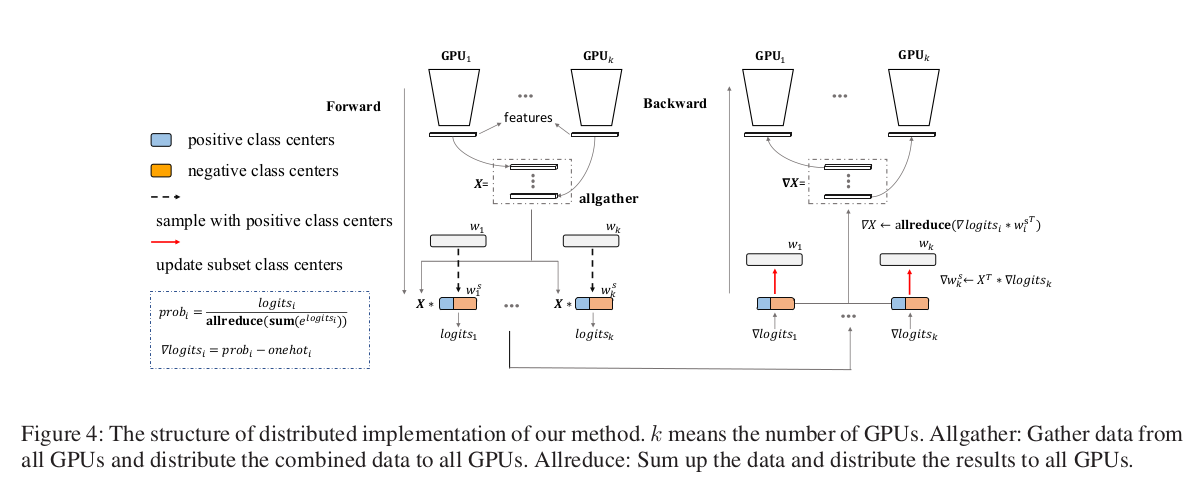
Partial FC führt einen Softmax-Approximationsalgorithmus ein, der modernste Genauigkeit aufrechterhalten kann und dabei nur einen Bruchteil (z. B. 10 %) der Klassenzentren verwendet. Durch die sorgfältige Auswahl einer Untergruppe von Klassenzentren während des Trainings können die Speicher- und Rechenanforderungen erheblich reduziert werden. Dies wird das Training von Gesichtserkennungsmodellen mit einer beispiellosen Anzahl von Identitäten weiter ermöglichen.
Die Magie von Partial FC
Der Schlüssel zur Magie von Partial FC liegt in der Art und Weise, wie es die Klassenzentren für jede Iteration auswählt. Es werden zwei Strategien vorgeschlagen:
- Völlig zufällig: Zur Berechnung des Verlusts und zur Aktualisierung der Gewichte wird eine zufällige Teilmenge (r %) der Klassenzentren ausgewählt. Dies kann alle positiven Klassenzentren in dieser Iteration umfassen oder auch nicht.
- Positiv plus zufällig negativ (PPRN): Eine Teilmenge (r %) der Klassenzentren wird ausgewählt, dieses Mal umfasst sie jedoch alle positiven Klassenzentren und zufällig ausgewählten negativen Klassenzentren.
Den Untersuchungen zufolge übertrifft PPRN den vollständig zufälligen Ansatz, insbesondere bei niedrigeren Stichprobenraten. Dies liegt daran, dass PPRN sicherstellt, dass die Gradienten sowohl die Richtung lernen, in die die Stichprobe von negativen Zentren weggeschoben wird, als auch das Clustering-Ziel innerhalb der Klasse.
Durch die Aufteilung der Softmax-Gewichtsmatrix auf mehrere GPUs und die Partitionierung der Eingabebeispiele auf diese GPUs stellt Partial FC sicher, dass jede GPU nur eine Teilmenge der Identitäten verarbeitet. Dieser geniale Ansatz beseitigt nicht nur den Speicherengpass, sondern minimiert auch die kostspielige Kommunikation zwischen GPUs, die für die Gradientensynchronisierung erforderlich ist.
Vorteile von Partial FC
- Durch die zufällige Auswahl negativer Klassenzentren ist Partial FC weniger von Etikettenrauschen oder Konflikten zwischen Klassen betroffen.
- Bei Long-Tail-Verteilungen, bei denen einige Klassen deutlich weniger Stichproben haben als andere, vermeidet Partial FC eine übermäßige Aktualisierung der weniger häufigen Klassen, was zu einer besseren Leistung führt.
- Partial FC kann über 10 Millionen Identitäten mit nur 8 GPUs trainieren, während ArcFace mit der gleichen GPU-Anzahl nur 1 Million Identitäten verarbeiten kann.
Nachteile von Partial FC
- Die Wahl einer geeigneten Abtastrate (r%) ist entscheidend für die Aufrechterhaltung von Genauigkeit und Effizienz. Eine zu niedrige Rate kann die Leistung beeinträchtigen, während eine zu hohe Rate die Speicher- und Rechenvorteile zunichte machen kann.
- Der Zufallsstichprobenprozess kann zu Rauschen führen, das bei unsachgemäßer Handhabung möglicherweise die Leistung des Modells beeinträchtigen könnte.
Die Kraft der partiellen FC entfesseln
Partial FC ist einfach zu verwenden. Das Papier enthält klare Anweisungen und Code zum Hinzufügen zu Ihren Projekten. Darüber hinaus haben sie einen riesigen, hochwertigen Datensatz (Glint360K) veröffentlicht, um Ihre Modelle mit Partial FC zu trainieren. Mit diesen Tools kann jeder die Leistungsfähigkeit der umfassenden Gesichtserkennung nutzen.
def sample(self, labels, index_positive):
with torch.no_grad():
positive = torch.unique(labels[index_positive], sorted=True).cuda()
if self.num_sample - positive.size(0) >= 0:
perm = torch.rand(size=[self.num_local]).cuda()
perm[positive] = 2.0
index = torch.topk(perm, k=self.num_sample)[1].cuda()
index = index.sort()[0].cuda()
else:
index = positive
self.weight_index = index
labels[index_positive] = torch.searchsorted(index, labels[index_positive])
return self.weight[self.weight_index]Der bereitgestellte Codeblock kann Partial FC in Python implementieren. Als Referenz können Sie meine erkunden Quelle, bezogen auf das Insight Face Repository.
Zusammenfassung
Partial FC ist ein Game-Changer in der Gesichtserkennung. Damit können Sie Modelle mit viel mehr Identitäten als je zuvor trainieren. Diese Technik überdenkt die Skalierung von Modellen und bringt Speicher, Geschwindigkeit und Genauigkeit in Einklang. Mit Partial FC ist die Zukunft der groß angelegten Gesichtserkennung erstaunlich! Behalten Sie Partial FC im Auge, es wird das Feld revolutionieren.
Key Take Away
- Partial FC behebt den Softmax-Engpass bei der Gesichtserkennung durch Optimierung von Speicher und Berechnung.
- Partial FC wählt Teilmengen von Klassenzentren für das Training aus und steigert so die Skalierbarkeit und Robustheit.
- Zu den Vorteilen gehören Robustheit gegenüber Rauschen und Konflikten sowie eine enorme Skalierbarkeit auf bis zu 10 Millionen Identitäten.
- Zu den Nachteilen gehören eine sorgfältige Auswahl der Abtastrate und die mögliche Einführung von Rauschen.
- Die Implementierung von Partial FC umfasst die Partitionierung von Softmax-Gewichten auf GPUs und die Auswahl von Teilmengen für das Training.
- Codeausschnitte wie die bereitgestellte Funktion „sample()“ ermöglichen eine einfache Implementierung von Partial FC.
- Partial FC definiert die Gesichtserkennung im großen Maßstab neu und bietet beispiellose Skalierbarkeit und Genauigkeit.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.analyticsvidhya.com/blog/2024/03/guide-to-face-recognition-at-massive-scale-with-partial-fc/
- :hast
- :Ist
- :nicht
- :Wo
- 10 Mio. US$
- $UP
- 1
- 10
- 10m
- 2%
- 8
- a
- Beschleunigung
- Genauigkeit
- über
- aktiv
- Anpassungsfähigkeit
- hinzufügen
- zusätzlich
- angenommen
- Fortschritte
- beeinflussen
- betroffen
- gegen
- Algorithmus
- Alle
- lindern
- ebenfalls
- an
- Analytik
- Analytics-Vidhya
- und
- jemand
- anwendbar
- Anwendungen
- Ansatz
- Ansätze
- angemessen
- ungefähr
- SIND
- entsteht
- Artikel
- AS
- At
- versuchen
- Versuche
- Autoren
- Mittelung
- vermeidet
- ein Weg
- Balancing
- basierend
- BE
- weil
- war
- Bevor
- Vorteile
- Besser
- zwischen
- Blockieren
- Blogathon
- Stärkung
- beide
- Engpass
- Grenzen
- Überbrückung
- Last
- aber
- by
- Berechnen
- berechnet
- Berechnung
- CAN
- Fähigkeiten
- Kapazität
- vorsichtig
- vorsichtig
- Centers
- challenges
- Herausforderungen
- herausfordernd
- gewählt
- Klasse
- Unterricht
- klar
- Clustering
- Code
- kommt
- lobenswert
- mitgeteilt
- Kommunizieren
- Kommunikation
- verglichen
- Vergleiche
- uneingeschränkt
- Komponente
- Berechnung
- rechnerisch
- Berechnungen
- Berechnen
- berechnet
- Computing
- Konflikte
- Sie
- Nachteile
- ständig
- eingeschränkt
- Baugewerbe
- Verbrauch
- Kosten
- teuer werden
- Kosten
- könnte
- zählen
- wichtig
- Strom
- technische Daten
- Behandlung
- tief
- Trotz
- Detail
- Details
- anders
- Abmessungen
- Richtung
- Diskretion
- Ungleichheit
- Ausschüttungen
- teilt
- erledigt
- Fahren
- im
- dynamisch
- e
- jeder
- Einfache
- Effizienz
- acht
- sonst
- Einbettung
- beschäftigt
- ermöglichen
- ermöglichen
- sorgt
- Ganz
- eskalierenden
- insbesondere
- essential
- Sogar
- ÜBERHAUPT
- überschreiten
- übersteigt
- erklärt
- ERKUNDEN
- Erkundet
- exponentiell
- Exponentielles Wachstum
- Extraktion
- Auge
- Gesicht
- Gesichtserkennung
- Gesichts-
- erleichtert
- Ausfälle
- fc
- Merkmal
- Eigenschaften
- Weniger
- Feld
- Finale
- endlich
- Vorname
- konzentriert
- Aussichten für
- Wald
- vorwärts
- Fraktion
- häufig
- für
- voll
- Funktion
- Funktionen
- weiter
- Zukunft
- Game-Changer
- Sammlung
- gibt
- Global
- Go
- gehen
- GPU
- GPUs
- Steigungen
- bahnbrechend
- Wachstum
- Guide
- Pflege
- Griff
- behandelt
- Hardware
- Hash-
- Haben
- High
- hochwertige
- Ultraschall
- Hilfe
- aber
- HTTPS
- i
- Identitäten
- Identitätsschutz
- if
- implementieren
- Implementierung
- in
- das
- Dazu gehören
- Einschließlich
- Erhöhung
- zunehmend
- zunehmend
- unabhängig
- Index
- Krankengymnastik
- Information
- Eingabe
- Einblick
- beantragen müssen
- Anleitung
- Mittel
- in
- einführen
- eingeführt
- Stellt vor
- Einleitung
- beteiligen
- beinhaltet
- IT
- Iteration
- SEINE
- jpg
- nur
- Behalten
- Wesentliche
- Label
- Etiketten
- großflächig
- Schicht
- führenden
- LERNEN
- weniger
- Lasst uns
- liegt
- Gefällt mir
- Einschränkung
- Einschränkungen
- Limitiert
- Grenzen
- linear
- aus einer regionalen
- Verlust
- Sneaker
- senken
- Maschine
- Magie
- halten
- Aufrechterhaltung
- um
- massiv
- Matrix
- max-width
- Kann..
- Medien
- Memory
- Methoden
- Million
- minimal
- minimiert
- Modell
- für
- mehr
- mehrere
- Multiplikation
- my
- naiv
- Need
- Negativ
- Netzwerke
- dennoch
- Neu
- Lärm
- beachten
- Anzahl
- Ziel
- of
- bieten
- vorgenommen,
- on
- einzige
- betreiben
- Optimierung
- or
- Andere
- Anders
- Übertrifft
- Ausgänge
- übrig
- Überwinden
- oben
- besitzen
- Besitz
- Papier
- Parallel
- Teil
- Teil-
- passieren
- Leistung
- platziert
- Plato
- Datenintelligenz von Plato
- PlatoData
- Bitte
- erfahren
- gestellt
- positiv
- Potenzial
- möglicherweise
- Werkzeuge
- Praktisch
- vorhergesagt
- früher
- in erster Linie
- Prinzip
- Prozessdefinierung
- anpassen
- Projekte
- richtig
- bietet
- vorgeschlage
- PROS
- zuverlässig
- vorausgesetzt
- veröffentlicht
- Push
- Schieben
- Python
- schnell
- R
- RAM
- zufällig
- Bewerten
- Honorar
- Anerkennung
- reduziert
- Reduzierung
- redundant
- Referenz
- Verfeinerung
- freigegeben
- Quelle
- falls angefordert
- Voraussetzungen:
- erfordert
- Forschungsprojekte
- Forscher
- Downloads
- einschränkend
- Folge
- Abruf
- Rückkehr
- revolutionieren
- Recht
- Robustheit
- gleich
- Sample
- Skalierbarkeit
- Skalieren
- Wissenschaft
- ausgewählt
- Auswahl
- Auswahl
- SELF
- kompensieren
- SGD
- gezeigt
- signifikant
- bedeutend
- Single
- Größe
- einige
- bezogen
- Raumfahrt
- spezifisch
- Geschwindigkeit
- State-of-the-art
- Schritt
- Immer noch
- storage
- Speicherung
- Strategien
- Es wurden Studien
- Erfolgreich
- Summe
- Summen
- Synchronisation
- angehen
- und Aufgaben
- Technik
- Techniken
- als
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- Die Zukunft
- ihr
- dann
- damit
- Diese
- vom Nutzer definierten
- fehlen uns die Worte.
- Durch
- Zeit
- Tipps
- zu
- auch
- Werkzeuge
- Fackel
- Gesamt
- Training
- trainiert
- Ausbildung
- Transformation
- XNUMX
- öffnen
- beispiellos
- Aktualisierung
- -
- benutzt
- Verwendung von
- Werte
- Varianten
- verschiedene
- Vielseitigkeit
- Volumen
- W
- wurde
- Weg..
- we
- Gewicht
- wann
- welche
- während
- weit
- werden wir
- mit
- .
- X
- U
- Ihr
- Zephyrnet