In modernen Datenarchitekturen werden Datensätze unternehmensweit kombiniert, indem eine Vielzahl speziell entwickelter Dienste verwendet werden, um Erkenntnisse zu gewinnen. Infolgedessen wird Data Governance zu einer Schlüsselkomponente für Datenkonsumenten und -produzenten, um zu wissen, dass ihre datengesteuerten Entscheidungen auf vertrauenswürdigen und genauen Datensätzen basieren. Ein Aspekt der Data Governance ist die Datenherkunft, die den Datenfluss auf seinem Weg durch verschiedene Systeme erfasst und es den Verbrauchern ermöglicht, zu verstehen, wie ein Datensatz abgeleitet wurde.
Um die Datenherkunft konsistent über verschiedene Analysedienste hinweg zu erfassen, müssen Sie ein gemeinsames Herkunftsmodell und eine robuste Auftragsorchestrierung verwenden, die in der Lage ist, verschiedene Datenflüsse miteinander zu verknüpfen. Eine mögliche Lösung ist Open Source OpenLineage Projekt. Es bietet ein technologieunabhängiges Metadatenmodell zur Erfassung der Datenherkunft und lässt sich in weit verbreitete Tools integrieren. Für die Job-Orchestrierung lässt es sich in Apache Airflow integrieren, das Sie bequem über den Managed Service auf AWS ausführen können Von Amazon verwaltete Workflows für Apache Airflow (Amazon MWAA). OpenLineage stellt ein Plugin für Apache Airflow bereit, aus dem die Datenherkunft extrahiert wird Gerichtete azyklische Graphen (DAGs).
In diesem Beitrag zeigen wir, wie Sie mit OpenLineage mit Data Lineage auf AWS beginnen. Wir bieten eine Schritt-für-Schritt-Konfigurationsanleitung für das openlineage-airflow-Plugin auf Amazon MWAA. Außerdem teilen wir uns ein AWS Cloud-Entwicklungskit (AWS CDK)-Projekt, das eine vorkonfigurierte Demoumgebung bereitstellt, um OpenLineage aus erster Hand zu evaluieren und zu erleben.
OpenLineage auf Apache Airflow
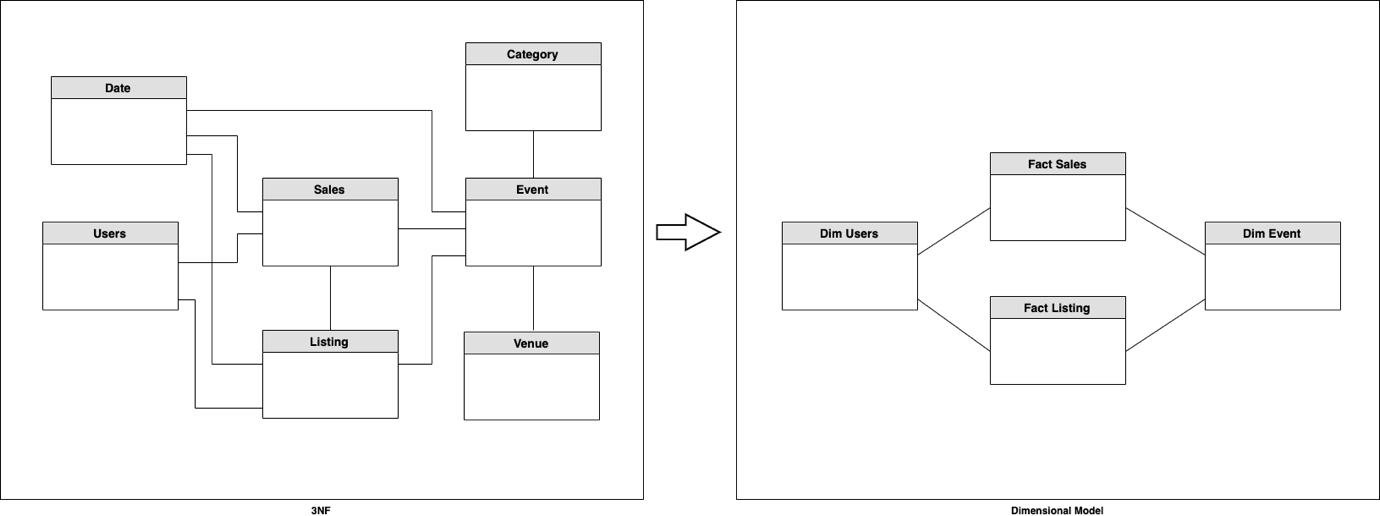
Im folgenden Beispiel wandelt Airflow OLTP-Daten in ein Sternschema um Amazon Redshift ohne Server.
Nach dem Staging und Vorbereiten der Quelldaten von Amazon Simple Storage-Service (Amazon S3) werden schließlich Fakten- und Dimensionstabellen erstellt. Dazu orchestriert Airflow die Ausführung von SQL-Anweisungen, die Tabellen auf Redshift Serverless erstellen und füllen.
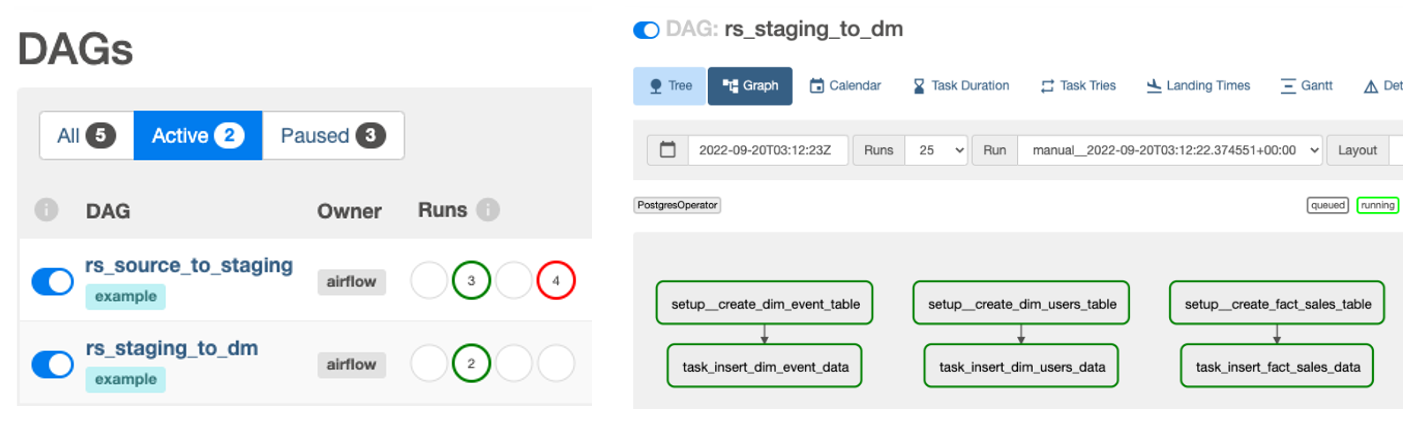
Das Openlineage-Airflow-Plugin sammelt Metadaten über die Erstellung von Datensätzen und Abhängigkeiten zwischen ihnen. Dies ermöglicht es uns, von einem arbeitsplatzzentrierten Ansatz von Airflow zu einem datensatzzentrierten Ansatz überzugehen und die Beobachtbarkeit von Arbeitsabläufen zu verbessern.
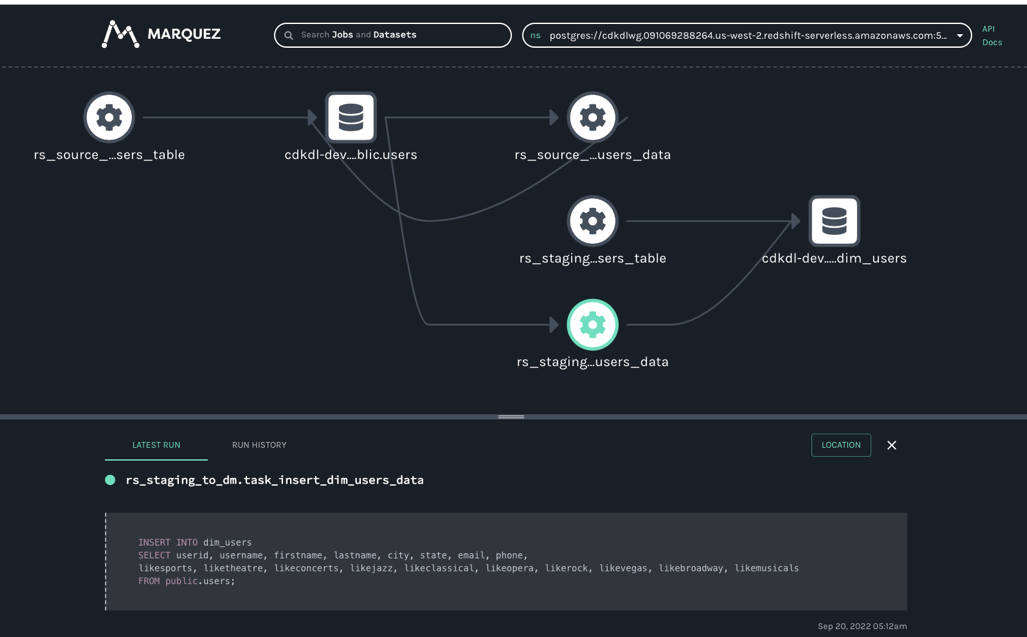
Der folgende Screenshot zeigt Teile der erfassten Abstammung für das vorherige Beispiel. Es wird in angezeigt Marquez, ein Open-Source-Metadatendienst zur Erfassung und Visualisierung der Datenherkunft mit Unterstützung für den OpenLineage-Standard. In Marquez können Sie die Upstream-Datensätze und -Transformationen analysieren, die schließlich die Benutzerdimensionstabelle auf der rechten Seite erstellen.
Das Beispiel in diesem Beitrag basiert auf SQL und Amazon RedShift. OpenLineage unterstützt auch andere Transformations-Engines und Datenspeicher wie Apache Spark und dbt.
Lösungsüberblick
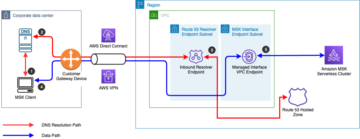
Das folgende Diagramm zeigt das AWS-Setup, das zum Erfassen der Datenherkunft mit OpenLineage erforderlich ist.
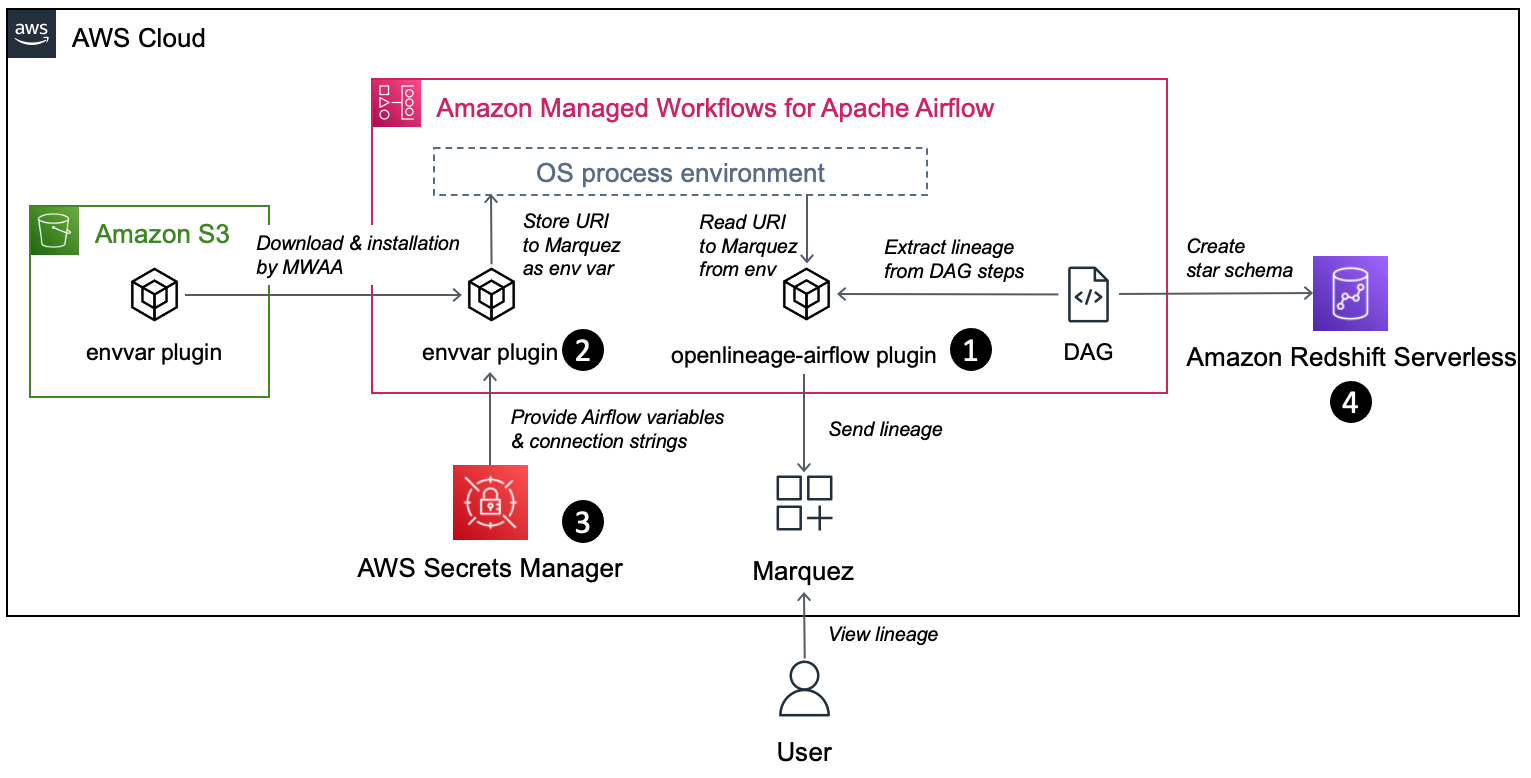
Der Workflow umfasst die folgenden Komponenten:
- Das openlineage-airflow-Plugin wird auf Airflow als konfiguriert Abstammungs-Backend. Metadaten zu den DAG-Ausführungen werden vom Airflow-Core an das Plug-in übergeben, das sie in das OpenLineage-Format konvertiert und an einen externen Metadatenspeicher sendet. In unserem Demo-Setup verwenden wir Marquez als Metadatenspeicher.
- Das openlineage-airflow-Plugin erhält seine Konfiguration von Umgebungsvariablen. Um diese Variablen auf Amazon MWAA zu füllen, wird ein benutzerdefiniertes Airflow-Plugin verwendet. Zunächst liest das Plugin Quellwerte aus AWS Secrets Manager. Dann erstellt es Umgebungsvariablen.
- Secrets Manager ist als konfiguriert Geheimnisse Backend. Normalerweise wird diese Art von Konfiguration in der nativen Metadaten-Datenbank von Airflow gespeichert. Dieser Ansatz hat jedoch Einschränkungen. Bei mehreren Airflow-Umgebungen müssen Sie beispielsweise Anmeldeinformationen in mehreren Umgebungen nachverfolgen und speichern, und zum Aktualisieren von Anmeldeinformationen müssen Sie alle Umgebungen aktualisieren. Mit einem Secrets-Backend können Sie die Konfiguration zentralisieren.
- Zu Demonstrationszwecken erfassen wir die Datenherkunft aus einer Datenpipeline, die ein Sternschema in Redshift Serverless erstellt.
In den folgenden Abschnitten führen wir Sie durch die Schritte zur End-to-End-Konfiguration.
Installieren Sie das openlineage-airflow-Plugin
Geben Sie die folgende Abhängigkeit in der an requirements.txt Datei der Amazon MWAA-Umgebung. Beachten Sie, dass die neueste Airflow-Version, die derzeit auf Amazon MWAA verfügbar ist, 2.4.3 ist; Verwenden Sie für diesen Beitrag die kompatible Version 0.19.2 des Plugins:
Weitere Einzelheiten zum Installieren von Python-Abhängigkeiten auf Amazon MWAA finden Sie unter Installieren von Python-Abhängigkeiten.
Konfigurieren Sie für Airflow < 2.3 das Herkunfts-Backend des Plugins durch die folgenden Konfigurationsüberschreibungen in der Amazon MWAA-Umgebung und laden Sie es sofort beim Start von Airflow, indem Sie Lazy Load von Plugins deaktivieren:
Weitere Informationen zu Konfigurationsüberschreibungen finden Sie unter Übersicht über die Konfigurationsoptionen.
Konfigurieren Sie das Secrets Manager-Backend mit Amazon MWAA
Die Verwendung von Secrets Manager als Secrets-Backend für Amazon MWAA ist unkompliziert. Stellen Sie zuerst die Ausführungsrolle von Amazon MWAA mit Leseberechtigung für Secrets Manager bereit. Sie können die folgende Richtlinienvorlage als Ausgangspunkt verwenden:
Zweitens konfigurieren Sie Secrets Manager als Backend in Amazon MWAA durch die folgenden Konfigurationsüberschreibungen:
Weitere Informationen zum Konfigurieren eines Secrets-Backends in Amazon MWAA finden Sie unter Konfigurieren einer Apache Airflow-Verbindung mit einem Secrets Manager-Secret machen Verschieben Sie Ihre Apache Airflow-Verbindungen und -Variablen zu AWS Secrets Manager.
Stellen Sie ein benutzerdefiniertes envvar-Plugin für Amazon MWAA bereit
Apache Airflow verfügt über einen integrierten Plugin-Manager, über den es mit benutzerdefinierten Funktionen erweitert werden kann. In unserem Fall besteht diese Funktionalität darin, OpenLineage-spezifische Umgebungsvariablen basierend auf Werten in Secrets Manager zu füllen. Amazon MWAA erlaubt nativ Umgebungsvariablen mit dem Präfix AIRFLOW__, aber das openlineage-airflow-Plugin erwartet das Präfix OPENLINEAGE__.
Der folgende Python-Code wird im Plugin verwendet. Wir gehen davon aus, dass die Datei aufgerufen wird envvar_plugin.py:
Amazon MWAA verfügt über einen Mechanismus zum Installieren eines Plugins über ein ZIP-Archiv. Sie komprimieren Ihren Code, laden das Archiv in einen S3-Bucket hoch und übergeben die URL der Datei an Amazon MWAA:
Hochladen plugins.zip zu einem S3-Bucket und konfigurieren Sie die URL in Amazon MWAA. Der folgende Screenshot zeigt die Konfiguration über die Amazon MWAA-Konsole.

Weitere Informationen zum Installieren benutzerdefinierter Plugins auf Amazon MWAA finden Sie unter Erstellen eines benutzerdefinierten Plugins, das Laufzeitumgebungsvariablen generiert.
Konnektivität zwischen dem openlineage-airflow-Plug-in und Marquez konfigurieren
Speichern Sie als letzten Schritt die URL zu Marquez im Secrets Manager. Erstellen Sie dazu ein Geheimnis namens airflow/variables/OPENLINEAGE_URL mit Wert <protocol>://<hostname/ip>:<port> (zum Beispiel, https://marquez.mysite.com:5000).

Falls Sie Marquez auf AWS hochfahren müssen, haben Sie mehrere Optionen zum Hosten, einschließlich der Ausführung Amazon Elastic Kubernetes-Service (Amazon EKS) oder Amazon Elastic Compute-Cloud (Amazon EC2). Beziehen auf Ausführen von Marquez auf AWS oder sehen Sie sich unsere Infrastrukturvorlage im nächsten Abschnitt an, um Marquez auf AWS bereitzustellen.
Stellen Sie mit einer AWS CDK-basierten Lösungsvorlage bereit
Angenommen, Sie möchten eine Demo-Infrastruktur für alle oben genannten Punkte in einem Schritt einrichten, können Sie die verwenden folgende Vorlage basierend auf dem AWS CDK.
Die Vorlage hat die folgenden Voraussetzungen:
Führen Sie die folgenden Schritte aus, um die Vorlage bereitzustellen:
- Klonen Sie das GitHub-Repository und installieren Sie Python-Abhängigkeiten. Bootstrap des AWS CDK Falls erforderlich.
- Aktualisieren Sie den Wert für die Variable
EXTERNAL_IPinconstants.pyan Ihre ausgehende IP für die Verbindung zum Internet:Dadurch werden Sicherheitsgruppen konfiguriert, sodass Sie auf Marquez zugreifen, andere Clients jedoch blockieren können.
constants.pybefindet sich im Stammordner des geklonten Repositorys. - Stellen Sie den VPC_S3-Stack bereit, um eine neue VPC für diese Lösung sowie die Sicherheitsgruppen bereitzustellen, die von den verschiedenen Komponenten verwendet werden:
Es erstellt einen neuen S3-Bucket und lädt die Quell-Rohdaten basierend auf hoch KREUZEN SIE AN Musterdatenbank. Dieser dient als Landebereich aus der OLTP-Datenbank. Wir müssen dann die Metadaten dieser Dateien durch eine analysieren AWS-Kleber Crawler, der die native Integration zwischen Amazon Redshift und dem S3 Data Lake erleichtert.
- Stellen Sie den Herkunftsstapel bereit, um eine EC2-Instance zu erstellen, die Marquez hostet:
Greifen Sie über auf die Web-Benutzeroberfläche von Marquez zu
https://{ec2.public_dns_name}:3000/. Diese URL ist auch als Teil der AWS CDK-Ausgaben für den Herkunftsstapel verfügbar. - Stellen Sie den Amazon Redshift-Stack bereit, um einen Redshift Serverless-Endpunkt zu erstellen:
- Stellen Sie den Amazon MWAA-Stack bereit, um eine Amazon MWAA-Umgebung zu erstellen:
Sie können auf die Amazon MWAA-Benutzeroberfläche über die in der AWS CDK-Ausgabe angegebene URL.
Testen Sie eine Beispieldatenpipeline
Auf Amazon MWAA können Sie eine beispielhaft bereitgestellte Datenpipeline sehen, die aus zwei DAGs besteht. Es baut ein Sternschema auf TICKIT-Beispieldatenbank. Ein DAG ist für das Laden von Daten aus dem S3 Data Lake in eine Staging-Schicht von Amazon Redshift verantwortlich; Der zweite DAG lädt Daten aus der Staging-Schicht in das dimensionale Modell.
Öffnen Sie die Amazon MWAA-Benutzeroberfläche über die URL, die Sie in den Bereitstellungsschritten erhalten haben, und starten Sie die folgenden DAGs: rs_source_to_staging machen rs_staging_to_dm. Als Teil des Laufs werden die Abstammungsmetadaten an Marquez gesendet.
Nachdem der DAG ausgeführt wurde, öffnen Sie die Marquez-URL, die Sie in den Bereitstellungsschritten erhalten haben. In Marquez finden Sie die Abstammungsmetadaten für das berechnete Sternschema und zugehörige Datenbestände auf Amazon Redshift.
Aufräumen
Löschen Sie die AWS CDK-Stacks, um laufende Gebühren für die von Ihnen erstellten Ressourcen zu vermeiden. Führen Sie den folgenden Befehl im Projektverzeichnis aws-mwaa-openlineage aus, damit alle Ressourcen nicht bereitgestellt werden:
Zusammenfassung
In diesem Beitrag haben wir Ihnen gezeigt, wie Sie die Datenherkunft mit OpenLineage auf Amazon MWAA automatisieren. Als Teil davon haben wir behandelt, wie das openlineage-airflow-Plug-in auf Amazon MWAA installiert und konfiguriert wird. Darüber hinaus haben wir eine gebrauchsfertige Infrastrukturvorlage für eine vollständige Demoumgebung bereitgestellt.
Wir empfehlen Ihnen, zu erkunden, was mit OpenLineage noch erreicht werden kann. Ein Job-Orchestrator wie Apache Airflow ist nur ein Teil einer Datenplattform und nicht alle möglichen Datenherkünfte können darauf erfasst werden. Wir empfehlen, die Integration von OpenLineage mit anderen Plattformen wie Apache Spark oder dbt zu erkunden. Weitere Informationen finden Sie unter Integration.
Außerdem empfehlen wir Ihnen den Besuch der AWS Big Data-Blog für weitere nützliche Blog-Beiträge zu Amazon MWAA und Data Governance auf AWS.
Über die Autoren
 Stefan sagte ist Senior Solutions Architect und arbeitet mit Digital Native Businesses zusammen. Seine Interessengebiete sind Datenanalyse, Datenplattformen und Cloud-natives Software-Engineering.
Stefan sagte ist Senior Solutions Architect und arbeitet mit Digital Native Businesses zusammen. Seine Interessengebiete sind Datenanalyse, Datenplattformen und Cloud-natives Software-Engineering.
 Vishwanatha Nayak ist Senior Solutions Architect bei AWS. Er arbeitet mit großen Unternehmenskunden zusammen und hilft ihnen dabei, sichere, kostengünstige und zuverlässige moderne Datenplattformen mit der AWS-Cloud zu entwerfen und aufzubauen. Er hat eine Leidenschaft für Technologie und teilt sein Wissen gerne in Blogposts und Twitch-Sessions.
Vishwanatha Nayak ist Senior Solutions Architect bei AWS. Er arbeitet mit großen Unternehmenskunden zusammen und hilft ihnen dabei, sichere, kostengünstige und zuverlässige moderne Datenplattformen mit der AWS-Cloud zu entwerfen und aufzubauen. Er hat eine Leidenschaft für Technologie und teilt sein Wissen gerne in Blogposts und Twitch-Sessions.
 Paul Villena ist ein Analytik-Lösungsarchitekt mit Erfahrung im Aufbau moderner Daten- und Analyselösungen zur Steigerung des Geschäftswerts. Er arbeitet mit Kunden zusammen, um ihnen zu helfen, die Leistungsfähigkeit der Cloud zu nutzen. Seine Interessengebiete sind Infrastructure-as-Code, serverlose Technologien und Codierung in Python.
Paul Villena ist ein Analytik-Lösungsarchitekt mit Erfahrung im Aufbau moderner Daten- und Analyselösungen zur Steigerung des Geschäftswerts. Er arbeitet mit Kunden zusammen, um ihnen zu helfen, die Leistungsfähigkeit der Cloud zu nutzen. Seine Interessengebiete sind Infrastructure-as-Code, serverlose Technologien und Codierung in Python.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/automate-data-lineage-on-amazon-mwaa-with-openlineage/
- 1
- 10
- 100
- 7
- a
- Fähig
- Über uns
- oben
- Zugang
- genau
- erreicht
- über
- Action
- azyklisch
- zusätzlich
- Alle
- erlaubt
- Amazon
- Amazon EC2
- Analytische
- Analytik
- analysieren
- machen
- Apache
- Apache Funken
- Ansatz
- Archiv
- Bereich
- Bereiche
- Aussehen
- Details
- automatisieren
- verfügbar
- AWS
- Backend
- basierend
- wird
- zwischen
- Big
- Big Data
- Blockieren
- Blog
- Blog-Beiträge
- bauen
- Building
- baut
- eingebaut
- Geschäft
- Unternehmen
- namens
- Erfassung
- Captures
- Capturing
- Häuser
- CD
- Gebühren
- aus der Ferne überprüfen
- Klasse
- Kunden
- Cloud
- Code
- Programmierung
- sammeln
- Sammlung
- sammelt
- COM
- kombiniert
- gemeinsam
- kompatibel
- abschließen
- Komponente
- Komponenten
- Berechnen
- Konfiguration
- Sich zusammenschliessen
- Verbindung
- Verbindungen
- Konnektivität
- Konsul (Console)
- KUNDEN
- Kernbereich
- kostengünstiger
- bedeckt
- Crawler
- erstellen
- erstellt
- schafft
- Schaffung
- Referenzen
- Zur Zeit
- Original
- Kunden
- TAG
- technische Daten
- Datenanalyse
- Datensee
- Datenplattform
- datengesteuerte
- Datenbase
- Datensätze
- Entscheidungen
- gewidmet
- Demo
- Abhängigkeit
- einsetzen
- Einsatz
- Einsatz
- setzt ein
- Abgeleitet
- Design
- zerstören
- Details
- Entwicklung
- anders
- digital
- Abmessungen
- verschieden
- Antrieb
- bewirken
- ermutigen
- End-to-End
- Endpunkt
- Entwicklung
- Motor (en)
- Unternehmen
- Unternehmenskunden
- Arbeitsumfeld
- Umgebungen
- Äther (ETH)
- Auswerten
- schließlich
- Beispiel
- Ausführung
- erwartet
- erleben
- Expertise
- ERKUNDEN
- Möglichkeiten sondieren
- extern
- KONZENTRAT
- erleichtert
- Reichen Sie das
- Mappen
- Finden Sie
- Vorname
- Fluss
- Fließt
- Folgende
- Format
- gefunden
- für
- Funktionalität
- erzeugt
- bekommen
- GitHub
- Goes
- Governance
- Graph
- Gruppen
- Guide
- Geschirr
- Hilfe
- Unternehmen
- Gastgeber
- Ultraschall
- Hilfe
- aber
- HTML
- HTTPS
- sofort
- importieren
- Verbesserung
- in
- Dazu gehören
- Einschließlich
- Information
- Infrastruktur
- Einblicke
- installieren
- Installieren
- Instanz
- Integriert
- Integration
- Interesse
- Interessen
- Internet
- IP
- IT
- Job
- Wesentliche
- Wissen
- Wissen
- Kubernetes
- See
- Landung
- grosse
- Nachname
- neueste
- starten
- Schicht
- Einschränkungen
- Belastung
- Laden
- Belastungen
- verwaltet
- Manager
- Mechanismus
- Metadaten
- Modell
- für
- modern
- mehr
- schlauer bewegen
- mehrere
- Name
- nativen
- Need
- Neu
- weiter
- erhalten
- EINEM
- laufend
- XNUMXh geöffnet
- Open-Source-
- Optionen
- Orchesterbearbeitung
- Auftrag
- Organisation
- OS
- Andere
- Überblick
- Teil
- Teile
- Bestanden
- leidenschaftlich
- Erlaubnis
- Stück
- Pipeline
- Plattform
- Plattformen
- Plato
- Datenintelligenz von Plato
- PlatoData
- Plugin
- Plugins
- Points
- Datenschutzrichtlinien
- möglich
- Post
- BLOG-POSTS
- Werkzeuge
- Vorbereitung
- Voraussetzungen
- früher
- Producers
- Projekt
- die
- vorausgesetzt
- bietet
- Bereitstellung
- Zwecke
- Python
- Roh
- Rohdaten
- Lesen Sie mehr
- erhält
- empfehlen
- bezogene
- zuverlässig
- Quelle
- falls angefordert
- Voraussetzungen:
- erfordert
- Ressourcen
- Downloads
- für ihren Verlust verantwortlich.
- Folge
- robust
- Rollen
- Wurzel
- Führen Sie
- Laufen
- Zweite
- Die Geheime
- Abschnitt
- Abschnitte
- Verbindung
- Sicherheitdienst
- Senior
- Serverlos
- dient
- Dienstleistungen
- Sessions
- kompensieren
- Setup
- Teilen
- ,,teilen"
- erklären
- Konzerte
- Einfacher
- So
- Software
- Softwareentwicklung
- Lösung
- Lösungen
- Quelle
- Spark
- Wirbelsäule ... zu unterstützen.
- SQL
- Stapel
- Stacks
- Aufführung
- Standard
- Star
- Anfang
- begonnen
- Beginnen Sie
- Erklärung
- Aussagen
- Schritt
- Shritte
- Lagerung
- speichern
- gelagert
- Läden
- einfach
- so
- Support
- Unterstützt
- Systeme und Techniken
- Tabelle
- Technologies
- Technologie
- Vorlage
- Das
- Die Quelle
- ihr
- Durch
- KRAWATTE
- zu
- gemeinsam
- Werkzeuge
- Top
- verfolgen sind
- Transformation
- Transformationen
- vertraut
- Twitch
- typisch
- ui
- verstehen
- öffnen
- Aktualisierung
- Aktualisierung
- URL
- us
- -
- Mitglied
- Wert
- Werte
- Vielfalt
- verschiedene
- Version
- Visualisierung
- Netz
- Was
- welche
- weit
- Arbeitsablauf.
- Workflows
- Werk
- Ihr
- Zephyrnet
- PLZ