Unternehmen haben sich dafür entschieden, Data Lakes darauf aufzubauen Amazon Simple Storage-Service (Amazon S3) seit vielen Jahren. Ein Data Lake ist die beliebteste Wahl für Organisationen, um alle ihre Organisationsdaten zu speichern, die von verschiedenen Teams, über Geschäftsbereiche, aus allen verschiedenen Formaten und sogar über die Historie hinweg generiert wurden. Entsprechend eine Studie, sieht das durchschnittliche Unternehmen, dass das Volumen seiner Daten mit einer Rate von über 50 % pro Jahr wächst, und verwaltet normalerweise durchschnittlich 33 einzelne Datenquellen für die Analyse.
Teams versuchen oft, Tausende von Jobs aus relationalen Datenbanken mit demselben Muster zum Extrahieren, Transformieren und Laden (ETL) zu replizieren. Es ist sehr aufwendig, die Job-Zustände zu pflegen und diese einzelnen Jobs einzuplanen. Dieser Ansatz hilft den Teams, Tabellen mit wenigen Änderungen hinzuzufügen und den Auftragsstatus mit minimalem Aufwand beizubehalten. Dies kann zu einer enormen Verbesserung des Entwicklungszeitplans und einer einfachen Nachverfolgung der Jobs führen.
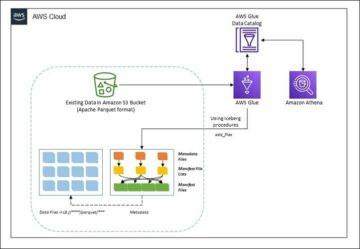
In diesem Beitrag zeigen wir Ihnen, wie Sie alle Ihre relationalen Datenspeicher auf einfache Weise mit einem einzigen ETL-Job mit Apache Iceberg und automatisiert in einen transaktionalen Data Lake replizieren können AWS-Kleber.
Lösungsarchitektur
Data Lakes sind normalerweise organisiert Verwendung separater S3-Buckets für drei Datenschichten: die Rohschicht mit Daten in ihrer ursprünglichen Form, die Staging-Schicht mit verarbeiteten Zwischendaten, die für den Verbrauch optimiert sind, und die Analyseschicht mit aggregierten Daten für bestimmte Anwendungsfälle. In der Rohschicht werden Tabellen normalerweise basierend auf ihren Datenquellen organisiert, während Tabellen in der Staging-Schicht basierend auf den Geschäftsdomänen organisiert werden, zu denen sie gehören.
Dieser Beitrag bietet eine AWS CloudFormation Vorlage, die einen AWS Glue-Auftrag bereitstellt, der einen Amazon S3-Pfad für eine Datenquelle der Data Lake-Rohschicht liest und die Daten in Apache Iceberg-Tabellen auf der Staging-Schicht aufnimmt AWS Glue-Unterstützung für Data Lake-Frameworks. Der Job erwartet, dass Tabellen in der Rohschicht so strukturiert sind AWS-Datenbankmigrationsservice (AWS DMS) nimmt sie auf: Schema, dann Tabelle, dann Datendateien.
Diese Lösung verwendet AWS Systems Manager-Parameterspeicher für die Tabellenkonfiguration. Sie sollten diesen Parameter ändern, indem Sie die Tabellen angeben, die Sie verarbeiten möchten, und wie, einschließlich Informationen wie Primärschlüssel, Partitionen und der zugeordneten Geschäftsdomäne. Der Job verwendet diese Informationen, um automatisch eine Datenbank (falls noch nicht vorhanden) für jede Geschäftsdomäne zu erstellen, die Iceberg-Tabellen zu erstellen und das Laden der Daten durchzuführen.
Schließlich können wir verwenden Amazonas Athena um die Daten in den Iceberg-Tabellen abzufragen.
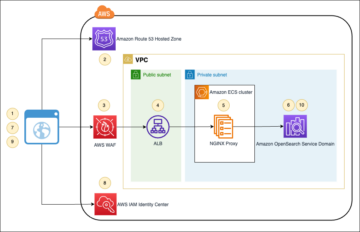
Das folgende Diagramm veranschaulicht diese Architektur.

Diese Implementierung hat die folgenden Überlegungen:
- Alle Tabellen aus der Datenquelle müssen einen Primärschlüssel haben, um mit dieser Lösung repliziert zu werden. Der Primärschlüssel kann eine einzelne Spalte oder ein zusammengesetzter Schlüssel mit mehr als einer Spalte sein.
- Wenn der Data Lake Tabellen enthält, die keine Upserts benötigen oder keinen Primärschlüssel haben, können Sie sie aus der Parameterkonfiguration ausschließen und herkömmliche ETL-Prozesse implementieren, um sie in den Data Lake aufzunehmen. Das ist außerhalb des Rahmens dieses Beitrags.
- Wenn zusätzliche Datenquellen aufgenommen werden müssen, können Sie mehrere CloudFormation-Stacks bereitstellen, einen für jede Datenquelle.
- Der AWS Glue-Auftrag ist darauf ausgelegt, Daten in zwei Phasen zu verarbeiten: das anfängliche Laden, das ausgeführt wird, nachdem AWS DMS die vollständige Ladeaufgabe abgeschlossen hat, und das inkrementelle Laden, das nach einem Zeitplan ausgeführt wird, der von AWS DMS erfasste CDC-Dateien (Change Data Capture) anwendet. Die inkrementelle Verarbeitung wird mit einem durchgeführt AWS Glue-Job-Lesezeichen.
Es gibt neun Schritte, um dieses Tutorial abzuschließen:
- Richten Sie einen Quellendpunkt für AWS DMS ein.
- Stellen Sie die Lösung mit AWS CloudFormation bereit.
- Überprüfen Sie die AWS DMS-Replikationsaufgabe.
- Fügen Sie optional Berechtigungen für die Verschlüsselung und Entschlüsselung hinzu oder AWS Lake-Formation.
- Überprüfen Sie die Tabellenkonfiguration im Parameter Store.
- Führen Sie das anfängliche Laden der Daten durch.
- Führen Sie ein inkrementelles Laden von Daten durch.
- Überwachen Sie die Tabellenaufnahme.
- Planen Sie das inkrementelle Laden von Batchdaten.
Voraussetzungen:
Bevor Sie mit diesem Tutorial beginnen, sollten Sie bereits mit Iceberg vertraut sein. Wenn dies nicht der Fall ist, können Sie beginnen, indem Sie eine einzelne Tabelle replizieren, indem Sie den Anweisungen in folgen Implementieren Sie einen CDC-basierten UPSERT in einem Data Lake mit Apache Iceberg und AWS Glue. Richten Sie außerdem Folgendes ein:
Richten Sie einen Quellendpunkt für AWS DMS ein
Bevor wir unsere AWS DMS-Aufgabe erstellen, müssen wir einen Quellendpunkt einrichten, um eine Verbindung zur Quelldatenbank herzustellen:
- Wählen Sie in der AWS DMS-Konsole aus Endpunkte im Navigationsbereich.
- Auswählen Endpunkt erstellen.
- Wenn Ihre Datenbank auf Amazon RDS ausgeführt wird, wählen Sie Wählen Sie die RDS-DB-Instanz aus, und wählen Sie dann die Instanz aus der Liste aus. Wählen Sie andernfalls die Quell-Engine aus und geben Sie die Verbindungsinformationen entweder durch an AWS Secrets Manager oder manuell.
- Aussichten für Endpunktkennung, geben Sie einen Namen für den Endpunkt ein; zum Beispiel source-postgresql.
- Auswählen Endpunkt erstellen.
Stellen Sie die Lösung mit AWS CloudFormation bereit
Erstellen Sie mithilfe der bereitgestellten Vorlage einen CloudFormation-Stack. Führen Sie die folgenden Schritte aus:
- Auswählen
Stapel starten:

- Auswählen Weiter.
- Geben Sie einen Stack-Namen an, z
transactionaldl-postgresql. - Geben Sie die erforderlichen Parameter ein:
- DMSS3EndpointIAMRoleARN – Der IAM-Rollen-ARN für AWS DMS zum Schreiben von Daten in Amazon S3.
- ReplicationInstanceArn – Der AWS DMS-Replikations-Instance-ARN.
- S3BucketStage – Der Name des vorhandenen Buckets, der für die Staging-Schicht des Data Lake verwendet wird.
- S3BucketGlue – Der Name des vorhandenen S3-Buckets zum Speichern von AWS Glue-Skripten.
- S3BucketRaw – Der Name des vorhandenen Buckets, der für die Rohschicht des Data Lake verwendet wird.
- SourceEndpointArn – Der AWS DMS-Endpunkt-ARN, den Sie zuvor erstellt haben.
- Quellenname – Die willkürliche Kennung der zu replizierenden Datenquelle (z. B.
postgres). Dies wird verwendet, um den S3-Pfad des Data Lake (Rohschicht) zu definieren, in dem Daten gespeichert werden.
- Ändern Sie die folgenden Parameter nicht:
- QuelleS3BucketBlog – Der Bucket-Name, in dem das bereitgestellte AWS Glue-Skript gespeichert ist.
- SourceS3BucketPrefix – Der Bucket-Präfixname, in dem das bereitgestellte AWS Glue-Skript gespeichert ist.
- Auswählen Weiter zweimal.
- Auswählen Ich erkenne an, dass AWS CloudFormation möglicherweise IAM-Ressourcen mit benutzerdefinierten Namen erstellt.
- Auswählen Stapel erstellen.
Nach ungefähr 5 Minuten wird der CloudFormation-Stack bereitgestellt.
Überprüfen Sie die AWS DMS-Replikationsaufgabe
Die AWS CloudFormation-Bereitstellung hat einen AWS DMS-Zielendpunkt für Sie erstellt. Aufgrund von zwei spezifischen Endpunkteinstellungen werden die Daten so aufgenommen, wie wir sie auf Amazon S3 benötigen.
- Wählen Sie in der AWS DMS-Konsole aus Endpunkte im Navigationsbereich.
- Suchen Sie nach dem Endpunkt, der mit beginnt, und wählen Sie ihn aus
dmsIcebergs3endpoint. - Überprüfen Sie die Endpunkteinstellungen:
DataFormatwird angegeben alsparquet.TimestampColumnNamefügt die Spalte hinzulast_update_timemit dem Erstellungsdatum der Datensätze auf Amazon S3.

Die Bereitstellung erstellt auch eine AWS DMS-Replikationsaufgabe, die mit beginnt dmsicebergtask.
- Auswählen Replikationsaufgaben im Navigationsbereich und suchen Sie nach der Aufgabe.
Sie werden sehen, dass die Aufgabentyp ist markiert als Volllast, laufende Replikation. AWS DMS führt ein anfängliches vollständiges Laden vorhandener Daten durch und erstellt dann inkrementelle Dateien mit Änderungen, die an der Quelldatenbank vorgenommen werden.
Auf dem Zuordnungsregeln Registerkarte gibt es zwei Arten von Regeln:
- Eine Auswahlregel mit dem Namen des Quellschemas und der Tabellen, die aus der Quelldatenbank aufgenommen werden. Standardmäßig wird die in den Voraussetzungen bereitgestellte Beispieldatenbank verwendet.
dms_sample, und alle Tabellen mit dem Schlüsselwort %. - Zwei Transformationsregeln, die in den Zieldateien auf Amazon S3 den Schemanamen und den Tabellennamen als Spalten enthalten. Dies wird von unserem AWS Glue-Job verwendet, um zu wissen, welchen Tabellen die Dateien im Data Lake entsprechen.
Um mehr darüber zu erfahren, wie Sie dies für Ihre eigenen Datenquellen anpassen können, beziehen Sie sich auf Auswahlregeln und Aktionen.

Lassen Sie uns einige Konfigurationen ändern, um unsere Aufgabenvorbereitung abzuschließen.
- Auf dem Aktionen Menü, wählen Sie Ändern.
- Im Aufgabeneinstellungen Abschnitt, unter Beenden Sie die Aufgabe, nachdem der vollständige Ladevorgang abgeschlossen ist, wählen Beenden Sie den Vorgang, nachdem Sie zwischengespeicherte Änderungen angewendet haben.
Auf diese Weise können wir das anfängliche Laden und die inkrementelle Dateigenerierung als zwei verschiedene Schritte steuern. Wir verwenden diesen zweistufigen Ansatz, um den AWS Glue-Job einmal pro Schritt auszuführen.
- Der Aufgabenprotokolle, wählen Aktivieren Sie CloudWatch-Protokolle.
- Auswählen Speichern.
- Warten Sie etwa 1 Minute, bis der Status der Datenbankmigrationsaufgabe als angezeigt wird Bereit.
Fügen Sie Berechtigungen für die Verschlüsselung und Entschlüsselung oder Lake Formation hinzu
Optional können Sie Berechtigungen für die Verschlüsselung und Entschlüsselung oder Lake Formation hinzufügen.
Fügen Sie Verschlüsselungs- und Entschlüsselungsberechtigungen hinzu
Wenn Ihre für die Raw- und Stage-Layer verwendeten S3-Buckets mit verschlüsselt sind AWS-Schlüsselverwaltungsservice (AWS KMS) kundenverwaltete Schlüssel müssen Sie Berechtigungen hinzufügen, damit der AWS Glue-Auftrag auf die Daten zugreifen kann:
Fügen Sie Lake Formation-Berechtigungen hinzu
Wenn Sie Berechtigungen mit Lake Formation verwalten, müssen Sie Ihrem AWS Glue-Auftrag erlauben, die Datenbanken und Tabellen Ihrer Domäne über die IAM-Rolle zu erstellen GlueJobRole.
- Erteilen Sie Berechtigungen zum Erstellen von Datenbanken (Anweisungen finden Sie unter Erstellen einer Datenbank).
- Erteilen Sie SUPER-Berechtigungen für die
defaultDatenbank. - Erteilen Sie Berechtigungen für die Datenspeicherung.
- Wenn Sie Datenbanken manuell erstellen, erteilen Sie allen Datenbanken Berechtigungen zum Erstellen von Tabellen. Beziehen auf Erteilen von Tabellenberechtigungen mithilfe der Lake Formation-Konsole und der benannten Ressourcenmethode or Gewähren von Data Catalog-Berechtigungen mithilfe der LF-TBAC-Methode nach Ihrem Anwendungsfall.
Stellen Sie nach Abschluss des späteren Schritts zum erstmaligen Laden der Daten sicher, dass Sie auch Berechtigungen für Verbraucher zum Abfragen der Tabellen hinzufügen. Die Jobrolle wird zum Eigentümer aller erstellten Tabellen, und der Data Lake-Administrator kann dann Berechtigungen für zusätzliche Benutzer erteilen.
Überprüfen Sie die Tabellenkonfiguration in Parameter Store
Der AWS Glue-Job, der die Datenaufnahme in Iceberg-Tabellen durchführt, verwendet die in Parameter Store bereitgestellte Tabellenspezifikation. Führen Sie die folgenden Schritte aus, um den automatisch für Sie konfigurierten Parameterspeicher zu überprüfen. Ändern Sie bei Bedarf nach Ihren eigenen Bedürfnissen.
- Wählen Sie in der Parameter Store-Konsole aus Meine Parameter im Navigationsbereich.
Der CloudFormation-Stack hat zwei Parameter erstellt:
iceberg-configfür Jobkonfigurationeniceberg-tablesfür die Tabellenkonfiguration
- Wählen Sie den Parameter Eisberg-Tische.
Die JSON-Struktur enthält Informationen, die AWS Glue verwendet, um Daten zu lesen und die Iceberg-Tabellen in der Zieldomäne zu schreiben:
- Ein Objekt pro Tisch – Der Name des Objekts wird aus dem Schemanamen, einem Punkt und dem Tabellennamen gebildet; Zum Beispiel,
schema.table. - Primärschlüssel – Dies sollte für jede Quelltabelle angegeben werden. Sie können eine einzelne Spalte oder eine durch Kommas getrennte Liste von Spalten (ohne Leerzeichen) angeben.
- partitionCols – Dies partitioniert optional Spalten für Zieltabellen. Wenn Sie keine partitionierten Tabellen erstellen möchten, geben Sie eine leere Zeichenfolge an. Geben Sie andernfalls eine einzelne Spalte oder eine durch Kommas getrennte Liste der zu verwendenden Spalten an (ohne Leerzeichen).
- Wenn Sie Ihre eigene Datenquelle verwenden möchten, verwenden Sie den folgenden JSON-Code und ersetzen Sie den Text in GROSSBUCHSTABEN aus der bereitgestellten Vorlage. Wenn Sie die bereitgestellte Beispieldatenquelle verwenden, behalten Sie die Standardeinstellungen bei:
{ "SCHEMA_NAME.TABLE_NAME_1": { "primaryKey": "ONLY_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "" }, "SCHEMA_NAME.TABLE_NAME_2": { "primaryKey": "FIRST_PRIMARY_KEY,SECOND_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "PARTITION_COLUMN_ONE,PARTITION_COLUMN_TWO" }
}- Auswählen Änderungen speichern.
Führen Sie das anfängliche Laden der Daten durch
Nachdem die erforderliche Konfiguration abgeschlossen ist, nehmen wir die Anfangsdaten auf. Dieser Schritt umfasst drei Teile: Aufnahme der Daten aus der relationalen Quelldatenbank in die Rohschicht des Data Lake, Erstellung der Iceberg-Tabellen auf der Staging-Schicht des Data Lake und Überprüfung der Ergebnisse mit Athena.
Nehmen Sie Daten in die Rohschicht des Data Lake auf
Führen Sie die folgenden Schritte aus, um Daten aus der relationalen Datenquelle (PostgreSQL, wenn Sie das bereitgestellte Beispiel verwenden) in unseren Transaktionsdatensee mit Iceberg aufzunehmen:
- Wählen Sie in der AWS DMS-Konsole aus Datenbankmigrationsaufgaben im Navigationsbereich.
- Wählen Sie die von Ihnen erstellte Replikationsaufgabe und auf der Aktionen Menü, wählen Sie Neustart/Fortsetzen.
- Warten Sie etwa 5 Minuten, bis die Replikationsaufgabe abgeschlossen ist. Sie können die aufgenommenen Tabellen auf dem überwachen Statistiken Registerkarte der Replikationsaufgabe.

Nach einigen Minuten endet die Aufgabe mit der Nachricht Volllast fertig.
- Wählen Sie in der Amazon S3-Konsole den Bucket aus, den Sie als Raw-Layer definiert haben.
Unter dem auf AWS DMS definierten S3-Präfix (z. B. postgres), sollten Sie eine Ordnerhierarchie mit der folgenden Struktur sehen:
- Schema
- Tabellenname
LOAD00000001.parquetLOAD0000000N.parquet
- Tabellenname

Wenn Ihr S3-Bucket leer ist, überprüfen Sie ihn Fehlerbehebung bei Migrationsaufgaben in AWS Database Migration Service bevor Sie den AWS Glue-Auftrag ausführen.
Erstellen und übernehmen Sie Daten in Iceberg-Tabellen
Bevor Sie den Job ausführen, navigieren wir durch das Skript des AWS Glue-Jobs, das als Teil des CloudFormation-Stacks bereitgestellt wird, um sein Verhalten zu verstehen.
- Wählen Sie in der AWS Glue Studio-Konsole Jobs im Navigationsbereich.
- Suchen Sie nach dem Job, der mit beginnt
IcebergJob-und ein Suffix Ihres CloudFormation-Stack-Namens (z. B.IcebergJob-transactionaldl-postgresql). - Wählen Sie den Beruf.

Das Auftragsskript erhält die benötigte Konfiguration aus Parameter Store. Die Funktion getConfigFromSSM() gibt auftragsbezogene Konfigurationen wie Quell- und Ziel-Buckets zurück, aus denen die Daten gelesen und geschrieben werden müssen. Die Variable ssmparam_table_values enthalten tabellenbezogene Informationen wie Datendomäne, Tabellenname, Partitionsspalten und Primärschlüssel der Tabellen, die aufgenommen werden müssen. Siehe den folgenden Python-Code:
# Main application
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'stackName'])
SSM_PARAMETER_NAME = f"{args['stackName']}-iceberg-config"
SSM_TABLE_PARAMETER_NAME = f"{args['stackName']}-iceberg-tables" # Parameters for job
rawS3BucketName, rawBucketPrefix, stageS3BucketName, warehouse_path = getConfigFromSSM(SSM_PARAMETER_NAME)
ssm_param_table_values = json.loads(ssmClient.get_parameter(Name = SSM_TABLE_PARAMETER_NAME)['Parameter']['Value'])
dropColumnList = ['db','table_name', 'schema_name','Op', 'last_update_time', 'max_op_date']Das Skript verwendet einen willkürlichen Katalognamen für Iceberg, der als my_catalog definiert ist. Dies wird im AWS Glue-Datenkatalog mithilfe von Spark-Konfigurationen implementiert, sodass eine SQL-Operation, die auf my_catalog verweist, auf den Datenkatalog angewendet wird. Siehe folgenden Code:
catalog_name = 'my_catalog'
errored_table_list = [] # Iceberg configuration
spark = SparkSession.builder .config('spark.sql.warehouse.dir', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') .config(f'spark.sql.catalog.{catalog_name}.warehouse', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}.catalog-impl', 'org.apache.iceberg.aws.glue.GlueCatalog') .config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.aws.s3.S3FileIO') .config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') .getOrCreate()
Das Skript durchläuft die in Parameter Store definierten Tabellen und führt die Logik aus, um zu erkennen, ob die Tabelle vorhanden ist und ob es sich bei den eingehenden Daten um ein anfängliches Laden oder ein Upsert handelt:
# Iteration over tables stored on Parameter Store
for key in ssm_param_table_values: # Get table data isTableExists = False schemaName, tableName = key.split('.') logger.info(f'Processing table : {tableName}')Das initialLoadRecordsSparkSQL() Die Funktion lädt Anfangsdaten, wenn in den S3-Dateien keine Operationsspalte vorhanden ist. AWS DMS fügt diese Spalte nur Parquet-Datendateien hinzu, die von der kontinuierlichen Replikation (CDC) erstellt wurden. Das Laden der Daten erfolgt über den Befehl INSERT INTO mit SparkSQL. Siehe folgenden Code:
sqltemp = Template(""" INSERT INTO $catalog_name.$dbName.$tableName ($insertTableColumnList) SELECT $insertTableColumnList FROM insertTable $partitionStrSQL """)
SQLQUERY = sqltemp.substitute( catalog_name = catalog_name, dbName = dbName, tableName = tableName, insertTableColumnList = insertTableColumnList[ : -1], partitionStrSQL = partitionStrSQL) logger.info(f'****SQL QUERY IS : {SQLQUERY}')
spark.sql(SQLQUERY)
Jetzt führen wir den AWS Glue-Job aus, um die Anfangsdaten in die Iceberg-Tabellen aufzunehmen. Der CloudFormation-Stack fügt die --datalake-formats -Parameter und fügen Sie dem Job die erforderlichen Iceberg-Bibliotheken hinzu.
- Auswählen Job ausführen.
- Auswählen Job läuft um den Status zu überwachen. Warten Sie, bis der Status lautet Ausführung erfolgreich.
Überprüfen Sie die geladenen Daten
Führen Sie die folgenden Schritte aus, um zu bestätigen, dass der Job die Daten wie erwartet verarbeitet hat:
- Wählen Sie auf der Athena-Konsole Abfrageeditor im Navigationsbereich.
- Verify
AwsDataCatalogist als Datenquelle ausgewählt. - Der Datenbase, wählen Sie die Datendomäne aus, die Sie untersuchen möchten, basierend auf der Konfiguration, die Sie im Parameterspeicher definiert haben. Wenn Sie die bereitgestellte Beispieldatenbank verwenden, verwenden Sie
sports.
Der Tabellen und Ansichten, können wir die Liste der Tabellen sehen, die vom AWS Glue-Job erstellt wurden.
- Wählen Sie das Optionsmenü (drei Punkte) neben dem ersten Tabellennamen und wählen Sie dann Vorschaudaten.
Sie können die in Iceberg-Tabellen geladenen Daten sehen. 
Führen Sie ein inkrementelles Laden von Daten durch
Jetzt beginnen wir damit, Änderungen aus unserer relationalen Datenbank zu erfassen und sie auf den transaktionalen Data Lake anzuwenden. Dieser Schritt ist ebenfalls in drei Teile unterteilt: Erfassen der Änderungen, Anwenden auf die Iceberg-Tabellen und Überprüfen der Ergebnisse.
Erfassen Sie Änderungen aus der relationalen Datenbank
Aufgrund der von uns angegebenen Konfiguration wurde die Replikationsaufgabe nach dem Ausführen der vollständigen Ladephase angehalten. Jetzt starten wir den Task erneut, um inkrementelle Dateien mit Änderungen in die Rohschicht des Data Lake einzufügen.
- Wählen Sie in der AWS DMS-Konsole die zuvor erstellte und ausgeführte Aufgabe aus.
- Auf dem Aktionen Menü, wählen Sie Lebenslauf.
- Auswählen Aufgabe starten um mit der Erfassung von Änderungen zu beginnen.
- Um die Erstellung neuer Dateien im Data Lake auszulösen, führen Sie mithilfe Ihres bevorzugten Datenbankverwaltungstools Einfügungen, Aktualisierungen oder Löschungen in den Tabellen Ihrer Quelldatenbank durch. Wenn Sie die bereitgestellte Beispieldatenbank verwenden, können Sie die folgenden SQL-Befehle ausführen:
UPDATE dms_sample.nfl_stadium_data_upd
SET seatin_capacity=93703
WHERE team = 'Los Angeles Rams' and sport_location_id = '31'; update dms_sample.mlb_data set bats = 'R'
where mlb_id=506560 and bats='L'; update dms_sample.sporting_event set start_date = current_date where id=11 and sold_out=0;
- Wählen Sie auf der Detailseite der AWS DMS-Aufgabe die aus Tabellenstatistik Registerkarte, um die erfassten Änderungen anzuzeigen.

- Öffnen Sie die Rohschicht des Data Lake, um eine neue Datei zu finden, die die inkrementellen Änderungen im Präfix jeder Tabelle enthält, beispielsweise unter der
sporting_eventPräfix.
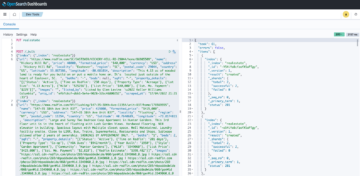
Der Datensatz mit Änderungen für die sporting_event Tabelle sieht wie im folgenden Screenshot aus.

Beachten Sie die Op Spalte am Anfang mit einem Update gekennzeichnet (U). Außerdem ist der zweite Datums-/Uhrzeitwert die Steuerspalte, die von AWS DMS mit dem Zeitpunkt hinzugefügt wurde, zu dem die Änderung erfasst wurde.

Wenden Sie mit AWS Glue Änderungen auf die Iceberg-Tabellen an
Jetzt führen wir den AWS Glue-Job erneut aus, und er verarbeitet automatisch nur die neuen inkrementellen Dateien, da das Job-Lesezeichen aktiviert ist. Sehen wir uns an, wie es funktioniert.
Das dedupCDCRecords() Die Funktion führt eine Deduplizierung von Daten durch, da mehrere Änderungen an einer einzelnen Datensatz-ID in derselben Datendatei auf Amazon S3 erfasst werden könnten. Die Deduplizierung wird basierend auf der durchgeführt last_update_time Spalte, die von AWS DMS hinzugefügt wurde und den Zeitstempel angibt, wann die Änderung erfasst wurde. Siehe den folgenden Python-Code:
def dedupCDCRecords(inputDf, keylist): IDWindowDF = Window.partitionBy(*keylist).orderBy(inputDf.last_update_time).rangeBetween(-sys.maxsize, sys.maxsize) inputDFWithTS = inputDf.withColumn('max_op_date', max(inputDf.last_update_time).over(IDWindowDF)) NewInsertsDF = inputDFWithTS.filter('last_update_time=max_op_date').filter("op='I'") UpdateDeleteDf = inputDFWithTS.filter('last_update_time=max_op_date').filter("op IN ('U','D')") finalInputDF = NewInsertsDF.unionAll(UpdateDeleteDf) return finalInputDFIn Zeile 99 wird die upsertRecordsSparkSQL() -Funktion führt den Upsert auf ähnliche Weise wie beim anfänglichen Laden durch, diesmal jedoch mit einem SQL MERGE-Befehl.
Überprüfen Sie die angewendeten Änderungen
Öffnen Sie die Athena-Konsole und führen Sie eine Abfrage aus, die die geänderten Datensätze in der Quelldatenbank auswählt. Wenn Sie die bereitgestellte Beispieldatenbank verwenden, verwenden Sie eine der folgenden SQL-Abfragen:
SELECT * FROM "sports"."nfl_stadiu_data_upd"
WHERE team = 'Los Angeles Rams' and sport_location_id = 31
LIMIT 1;

Überwachen Sie die Tabellenaufnahme
Das AWS Glue-Auftragsskript ist mit simple Python-Ausnahmebehandlung um Fehler während der Verarbeitung einer bestimmten Tabelle abzufangen. Das Job-Lesezeichen wird gespeichert, nachdem jede Tabelle die Verarbeitung erfolgreich abgeschlossen hat, um eine erneute Verarbeitung von Tabellen zu vermeiden, wenn die Jobausführung für die Tabellen mit Fehlern wiederholt wird.
Das AWS-Befehlszeilenschnittstelle (AWS CLI) bietet a get-job-bookmark Befehl für AWS Glue, der Einblick in den Status des Lesezeichens für jede verarbeitete Tabelle bietet.
- Wählen Sie in der AWS Glue Studio-Konsole den ETL-Job aus.
- Wähle die Job läuft und kopieren Sie die Auftragsausführungs-ID.
- Führen Sie den folgenden Befehl auf einem für die AWS CLI authentifizierten Terminal aus und ersetzen Sie
<GLUE_JOB_RUN_ID>in Zeile 1 mit dem kopierten Wert. Wenn Ihr CloudFormation-Stack nicht benannt isttransactionaldl-postgresql, geben Sie den Namen Ihres Jobs in Zeile 2 des Skripts an:
jobrun=<GLUE_JOB_RUN_ID>
jobname=IcebergJob-transactionaldl-postgresql
aws glue get-job-bookmark --job-name jobname --run-id $jobrunWenn in dieser Lösung eine Tabellenverarbeitung eine Ausnahme verursacht, schlägt der AWS Glue-Job gemäß dieser Logik nicht fehl. Stattdessen wird die Tabelle einem Array hinzugefügt, das nach Abschluss des Auftrags gedruckt wird. In einem solchen Szenario wird der Job als fehlgeschlagen markiert, nachdem er versucht hat, die restlichen Tabellen zu verarbeiten, die in der Rohdatenquelle erkannt wurden. Auf diese Weise müssen Tabellen ohne Fehler nicht warten, bis der Benutzer das Problem in den widersprüchlichen Tabellen identifiziert und löst. Der Benutzer kann mithilfe des AWS Glue-Auftragsausführungsstatus schnell Auftragsausführungen erkennen, bei denen Probleme aufgetreten sind, und anhand der CloudWatch-Protokolle für die Auftragsausführung ermitteln, welche spezifischen Tabellen das Problem verursachen.
- Das Jobskript implementiert diese Funktion mit dem folgenden Python-Code:
# Performed for every table try: # Table processing logic except Exception as e: logger.info(f'There is an issue with table: {tableName}') logger.info(f'The exception is : {e}') errored_table_list.append(tableName) continue job.commit()
if (len(errored_table_list)): logger.info('Total number of errored tables are ',len(errored_table_list)) logger.info('Tables that failed during processing are ', *errored_table_list, sep=', ') raise Exception(f'***** Some tables failed to process.')Der folgende Screenshot zeigt, wie die CloudWatch-Protokolle nach Tabellen suchen, die Fehler bei der Verarbeitung verursachen.

Abgestimmt auf die AWS Well-Architected Framework Data Analytics Lens Praktiken können Sie ausgefeiltere Kontrollmechanismen anpassen, um Stakeholder zu identifizieren und zu benachrichtigen, wenn Fehler in den Datenpipelines auftreten. Sie können beispielsweise eine verwenden Amazon DynamoDB Steuertabelle, um alle Tabellen und Jobläufe mit Fehlern zu speichern oder zu verwenden Amazon Simple Notification Service (Amazon SNS) zu Senden Sie Warnungen an die Betreiber wenn bestimmte Kriterien erfüllt sind.
Planen Sie das inkrementelle Laden von Batchdaten
Der CloudFormation-Stack stellt eine bereit Amazon EventBridge Regel (standardmäßig deaktiviert), die die Ausführung des AWS Glue-Auftrags nach einem Zeitplan auslösen kann. Führen Sie die folgenden Schritte aus, um Ihren eigenen Zeitplan bereitzustellen und die Regel zu aktivieren:
- Wählen Sie in der EventBridge-Konsole aus Regeln im Navigationsbereich.
- Suchen Sie nach der Regel, der der Name Ihres CloudFormation-Stacks vorangestellt ist, gefolgt von
JobTrigger(zum Beispiel,transactionaldl-postgresql-JobTrigger-randomvalue). - Wählen Sie die Regel.
- Der Veranstaltungskalender, wählen Bearbeiten.
Der Standardzeitplan ist so konfiguriert, dass er stündlich ausgelöst wird.
- Geben Sie den Zeitplan an, nach dem Sie den Job ausführen möchten.
- Zusätzlich können Sie eine verwenden EventBridge-Cron-Ausdruck durch die Auswahl Ein feinkörniger Zeitplan.

- Wenn Sie mit dem Einrichten des Cron-Ausdrucks fertig sind, wählen Sie aus Weiter dreimal, und schließlich wählen Regel aktualisieren um Änderungen zu speichern.
Die Regel wird standardmäßig deaktiviert erstellt, damit Sie zuerst den anfänglichen Datenladevorgang ausführen können.
- Aktivieren Sie die Regel, indem Sie wählen Ermöglichen.
Sie können die Verwendung Netzwerk Performance Registerkarte, um Regelaufrufe anzuzeigen, oder direkt auf AWS Glue Auftragsausführung Details.
Zusammenfassung
Nach der Bereitstellung dieser Lösung haben Sie die Aufnahme Ihrer Tabellen in einer einzigen relationalen Datenquelle automatisiert. Unternehmen, die einen Data Lake als zentrale Datenplattform verwenden, müssen in der Regel mehrere, manchmal sogar Dutzende von Datenquellen verwalten. Außerdem erfordern immer mehr Anwendungsfälle, dass Unternehmen Transaktionsfunktionen für den Data Lake implementieren. Sie können diese Lösung verwenden, um die Einführung solcher Funktionen in all Ihren relationalen Datenquellen zu beschleunigen, um neue Geschäftsanwendungsfälle zu ermöglichen und den Implementierungsprozess zu automatisieren, um mehr Wert aus Ihren Daten zu ziehen.
Über die Autoren
 Luis Gerardo Baeza ist Big Data Architect im Amazon Web Services (AWS) Data Lab. Er verfügt über 12 Jahre Erfahrung in der Unterstützung von Organisationen im Gesundheits-, Finanz- und Bildungssektor bei der Einführung von Unternehmensarchitekturprogrammen, Cloud-Computing und Datenanalysefunktionen. Luis hilft derzeit Organisationen in ganz Lateinamerika, strategische Dateninitiativen zu beschleunigen.
Luis Gerardo Baeza ist Big Data Architect im Amazon Web Services (AWS) Data Lab. Er verfügt über 12 Jahre Erfahrung in der Unterstützung von Organisationen im Gesundheits-, Finanz- und Bildungssektor bei der Einführung von Unternehmensarchitekturprogrammen, Cloud-Computing und Datenanalysefunktionen. Luis hilft derzeit Organisationen in ganz Lateinamerika, strategische Dateninitiativen zu beschleunigen.
 SaiKiran Reddy Aenugu ist Datenarchitekt im Amazon Web Services (AWS) Data Lab. Er verfügt über 10 Jahre Erfahrung in der Implementierung von Datenlade-, Transformations- und Visualisierungsprozessen. SaiKiran unterstützt derzeit Organisationen in Nordamerika bei der Einführung moderner Datenarchitekturen wie Data Lakes und Data Mesh. Er verfügt über Erfahrung in den Bereichen Einzelhandel, Fluggesellschaften und Finanzen.
SaiKiran Reddy Aenugu ist Datenarchitekt im Amazon Web Services (AWS) Data Lab. Er verfügt über 10 Jahre Erfahrung in der Implementierung von Datenlade-, Transformations- und Visualisierungsprozessen. SaiKiran unterstützt derzeit Organisationen in Nordamerika bei der Einführung moderner Datenarchitekturen wie Data Lakes und Data Mesh. Er verfügt über Erfahrung in den Bereichen Einzelhandel, Fluggesellschaften und Finanzen.
 Narendra Merla ist Datenarchitekt im Amazon Web Services (AWS) Data Lab. Er verfügt über 12 Jahre Erfahrung in der Entwicklung und Produktion von Echtzeit- und Batch-orientierten Datenpipelines und dem Aufbau von Data Lakes sowohl in Cloud- als auch in On-Premises-Umgebungen. Narendra hilft derzeit Organisationen in Nordamerika beim Aufbau und Design robuster Datenarchitekturen und verfügt über Erfahrung in den Bereichen Telekommunikation und Finanzen.
Narendra Merla ist Datenarchitekt im Amazon Web Services (AWS) Data Lab. Er verfügt über 12 Jahre Erfahrung in der Entwicklung und Produktion von Echtzeit- und Batch-orientierten Datenpipelines und dem Aufbau von Data Lakes sowohl in Cloud- als auch in On-Premises-Umgebungen. Narendra hilft derzeit Organisationen in Nordamerika beim Aufbau und Design robuster Datenarchitekturen und verfügt über Erfahrung in den Bereichen Telekommunikation und Finanzen.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/automate-replication-of-relational-sources-into-a-transactional-data-lake-with-apache-iceberg-and-aws-glue/
- 1
- 10
- 100
- 102
- 107
- 7
- a
- Über uns
- beschleunigen
- Zugang
- Nach
- anerkennen
- über
- automatisch
- hinzugefügt
- Zusätzliche
- zusätzlich
- Fügt
- Administrator
- Verwaltung
- adoptieren
- Adoption
- Nach der
- Fluggesellschaft
- Alle
- bereits
- Amazon
- Amazonas Athena
- Amazon RDS
- Amazon Web Services
- Amazon Web Services (AWS)
- Amerika
- Analyse
- Analytik
- und
- Angeles
- Apache
- erscheinen
- Anwendung
- angewandt
- Anwendung
- Ansatz
- ca.
- Architektur
- Feld
- damit verbundenen
- authentifiziert
- automatisieren
- Automatisiert
- Im Prinzip so, wie Sie es von Google Maps kennen.
- automatisieren
- durchschnittlich
- vermeiden
- AWS
- AWS CloudFormation
- AWS-Kleber
- basierend
- Fledermäuse
- weil
- werden
- Bevor
- Anfang
- Big
- Big Data
- bauen
- Baumeister
- Building
- Geschäft
- Kann bekommen
- Fähigkeiten
- Mützen
- Erfassung
- Capturing
- Häuser
- Fälle
- Katalog
- Ringen
- Verursachen
- Ursachen
- verursacht
- CDC
- Hauptgeschäftsstelle
- sicher
- Übernehmen
- Änderungen
- Wahl
- Auswählen
- Auswahl
- gewählt
- Cloud
- Cloud Computing
- Code
- Kolonne
- Spalten
- Unternehmen
- abschließen
- Computing
- Konfiguration
- Konfigurationen
- Schichtannahme
- Widersprüchlich
- Vernetz Dich
- Verbindung
- Überlegungen
- Konsul (Console)
- KUNDEN
- Verbrauch
- enthält
- fortsetzen
- kontinuierlich
- Smartgeräte App
- könnte
- erstellen
- erstellt
- schafft
- Erstellen
- Schaffung
- Kriterien
- Zur Zeit
- Original
- Kunde
- anpassen
- technische Daten
- Datenanalyse
- Datensee
- Datenplattform
- Datenbase
- Datenbanken
- Datum
- Standard
- definiert
- einsetzen
- Einsatz
- Bereitstellen
- Einsatz
- setzt ein
- Design
- entworfen
- Entwerfen
- Details
- erkannt
- Entwicklung
- anders
- Direkt
- behindert
- geteilt
- Tut nicht
- Domain
- Domains
- Nicht
- im
- jeder
- Früher
- leicht
- Bildungswesen
- Anstrengung
- entweder
- ermöglichen
- freigegeben
- verschlüsselt
- Verschlüsselung
- Endpunkt
- Motor
- Enter
- Unternehmen
- Umgebungen
- Fehler
- Äther (ETH)
- Sogar
- Jedes
- Beispiel
- übersteigt
- Außer
- Ausnahme
- vorhandenen
- existiert
- erwartet
- erwartet
- ERFAHRUNGEN
- ERKUNDEN
- Erweiterungen
- Extrakt
- Gescheitert
- vertraut
- Fashion
- Merkmal
- wenige
- Reichen Sie das
- Mappen
- Endlich
- Finanzen
- Revolution
- Finden Sie
- Fertig
- Vorname
- gefolgt
- Folgende
- Für Verbraucher
- unten stehende Formular
- Ausbildung
- Unser Ansatz
- für
- voller
- Funktion
- erzeugt
- Generation
- bekommen
- gewähren
- für Balkonkraftwerke Reduzierung
- persönlichem Wachstum
- Griff
- Gesundheitswesen
- Unternehmen
- hilft
- Hierarchie
- Geschichte
- Halten
- Ultraschall
- Hilfe
- HTML
- HTTPS
- riesig
- IAM
- identifiziert
- Kennzeichnung
- identifiziert
- identifizieren
- implementieren
- Implementierung
- umgesetzt
- Umsetzung
- implementiert
- Verbesserung
- in
- das
- Dazu gehören
- Einschließlich
- Eingehende
- zeigt
- Krankengymnastik
- Information
- Anfangs-
- Initiativen
- Einsätze
- Einblick
- Instanz
- beantragen müssen
- Anleitung
- Mittel
- Problem
- Probleme
- IT
- Iteration
- Job
- Jobs
- JSON
- Behalten
- Wesentliche
- Tasten
- Wissen
- Labor
- See
- Lateinisch
- Lateinamerika
- Schicht
- Lagen
- führen
- LERNEN
- Bibliotheken
- LIMIT
- Line
- Liste
- Belastung
- Laden
- Belastungen
- Standorte
- aussehen
- SIEHT AUS
- die
- Los Angeles
- Los
- Main
- unterhält
- um
- verwaltet
- Management
- Manager
- flächendeckende Gesundheitsprogramme
- manuell
- viele
- Mapping
- markiert
- MENÜ
- Merge
- Nachricht
- könnte
- Migration
- Minimum
- Minute
- Minuten
- modern
- ändern
- Überwachen
- Überwachung
- mehr
- vor allem warme
- Am beliebtesten
- mehrere
- Name
- Namens
- Namen
- Navigieren
- Navigation
- Need
- erforderlich
- Bedürfnisse
- Neu
- weiter
- Norden
- Nordamerika
- Benachrichtigung
- Anzahl
- Objekt
- Objekte
- EINEM
- laufend
- OP
- Betrieb
- optimiert
- Optionen
- organisatorisch
- Organisationen
- Organisiert
- Original
- Andernfalls
- aussen
- besitzen
- Eigentümer
- Brot
- Parameter
- Parameter
- Teil
- Teile
- Weg
- Schnittmuster
- ausführen
- Durchführung
- führt
- Zeit
- Berechtigungen
- Phase
- Plattform
- Plato
- Datenintelligenz von Plato
- PlatoData
- Beliebt
- Post
- Postgresql
- Praktiken
- bevorzugt
- Voraussetzungen
- Gegenwart
- primär
- Aufgabenstellung:
- Prozessdefinierung
- anpassen
- Verarbeitung
- Produziert
- Programme
- die
- vorausgesetzt
- bietet
- Python
- schnell
- erhöhen
- Bewerten
- Roh
- Rohdaten
- Lesen Sie mehr
- Echtzeit
- Rekord
- Aufzeichnungen
- ersetzen
- repliziert
- Replikation
- erfordern
- falls angefordert
- Ressourcen
- Downloads
- REST
- Die Ergebnisse
- Einzelhandel
- Rückkehr
- Rückgabe
- Überprüfen
- robust
- Rollen
- Regel
- Ohne eine erfahrene Medienplanung zur Festlegung von Regeln und Strategien beschleunigt der programmatische Medieneinkauf einfach die Rate der verschwenderischen Ausgaben.
- Führen Sie
- Laufen
- gleich
- Speichern
- Szenario
- Zeitplan
- Umfang
- Skripte
- Suche
- Zweite
- Sektoren
- Sehen
- ausgewählt
- Auswahl
- Auswahl
- getrennte
- Leistungen
- kompensieren
- Einstellung
- Einstellungen
- sollte
- erklären
- Konzerte
- ähnlich
- Einfacher
- da
- Single
- So
- Lösung
- Löst
- einige
- anspruchsvoll
- Quelle
- Quellen
- Räume
- Spark
- spezifisch
- Spezifikation
- angegeben
- Sports
- SQL
- Stapel
- Stacks
- Stufe
- Stakeholder
- Anfang
- begonnen
- Beginnen Sie
- beginnt
- Staaten
- Statistiken
- Status
- Schritt
- Shritte
- gestoppt
- Lagerung
- speichern
- gelagert
- Läden
- Strategisch
- Struktur
- strukturierte
- Studio Adressen
- Erfolgreich
- so
- Super
- Support
- Systeme und Techniken
- Tabelle
- Target
- Aufgabe
- und Aufgaben
- Team
- Teams
- Telekom
- Vorlage
- Terminal
- Das
- Die Quelle
- ihr
- Tausende
- nach drei
- Durch
- Zeit
- Timeline
- mal
- Zeitstempel
- zu
- Werkzeug
- Top
- Gesamt
- Tracking
- traditionell
- Transaktion
- Transformieren
- Transformation
- auslösen
- Lernprogramm
- Typen
- für
- verstehen
- einzigartiges
- Aktualisierung
- Updates
- -
- Anwendungsfall
- Mitglied
- Nutzer
- gewöhnlich
- Wert
- verifizieren
- Anzeigen
- Visualisierung
- Volumen
- warten
- Warehouse
- Netz
- Web-Services
- welche
- werden wir
- .
- ohne
- Werk
- schreiben
- geschrieben
- YAML
- Jahr
- Jahr
- Ihr
- Zephyrnet