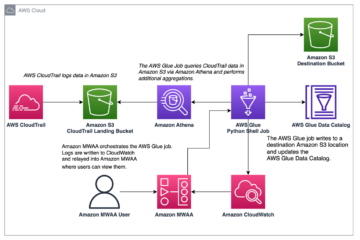
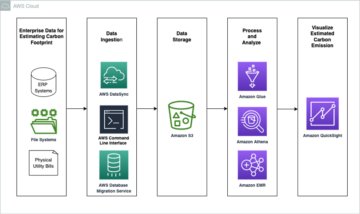
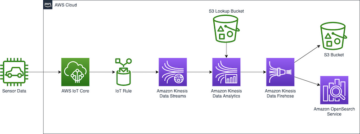
Data Governance ist die Sammlung von Richtlinien, Prozessen und Systemen, die Organisationen verwenden, um die Qualität und den angemessenen Umgang mit ihren Daten während ihres gesamten Lebenszyklus sicherzustellen, um Geschäftswert zu generieren. Data Governance steht für Kunden immer mehr im Vordergrund, da sie Daten als eines ihrer wichtigsten Vermögenswerte betrachten. Eine effektive Data Governance ermöglicht eine bessere Entscheidungsfindung, indem die Datenqualität verbessert, die Kosten für die Datenverwaltung gesenkt und ein sicherer Zugriff auf Daten für Stakeholder gewährleistet wird. Darüber hinaus ist Data Governance erforderlich, um ein zunehmend komplexes regulatorisches Umfeld mit Datenschutz (wie GDPR und CCPA) und Vorschriften zur Datenresidenz (wie in der EU, Russland und China) einzuhalten.
Für AWS-Kunden verbessert eine effektive Data Governance die Entscheidungsfindung, erhöht die geschäftliche Agilität, bietet einen Wettbewerbsvorteil und verringert das Risiko von Bußgeldern aufgrund der Nichteinhaltung gesetzlicher Verpflichtungen. Wir verstehen die einzigartige Gelegenheit, unseren Kunden eine umfassende End-to-End-Data-Governance-Lösung anzubieten, die nahtlos in unser Serviceportfolio integriert ist, und AWS Lake-Formation und dem AWS Glue-Datenkatalog sind der Schlüssel zur Lösung dieser Herausforderungen.
In diesem Beitrag freuen wir uns, die Funktionen zusammenzufassen, die die Teams von AWS Glue Data Catalog, AWS Glue Crawler und Lake Formation im Jahr 2022 bereitgestellt haben. Wir haben einige der wichtigsten Vorträge und Lösungen zu Data Governance, Data Mesh und modernen Daten gesammelt Architektur, die in AWS re:Invent 2022 veröffentlicht und präsentiert wird, und einige Data-Lake-Lösungen, die von Kunden und AWS-Partnern zum einfachen Nachschlagen erstellt wurden. Egal, ob Sie ein Datenplattformersteller, Dateningenieur, Datenwissenschaftler oder ein Technologieführer sind, der sich für Data Lake-Lösungen interessiert, dieser Beitrag ist für Sie.
Um mehr darüber zu erfahren, wie Kunden Daten sichern und mit Lake Formation teilen, empfehlen wir, sich eingehender mit GoDaddy zu befassen dezentrales Datennetz, Novo Nordisks Moderne Datenarchitektur, und JPMorgans Verbesserungen an deren Verbunddatensee, eine geregelte Data-Mesh-Implementierung mit Lake Formation. Außerdem können Sie in Starburst erfahren, wie AWS-Partner sich in Lake Formation integriert haben, um Kunden beim Aufbau einzigartiger Data Lakes zu unterstützen Data-Mesh-Lösung, Informaticas automatisierte Datenfreigabelösung, Ahanas Presto-Integration mit Lake Formation, Aufsteigender Brauch Daten-Governance-System, wie PBS verwendet maschinelles Lernen auf ihren Data Lakes, und wie hc1 bereitstellt personalisierte Gesundheitseinblicke für Kunden.
Sie können überprüfen, wie Lake Formation von Kunden zum Bauen verwendet wird Moderne Datenarchitekturen in den folgenden re:Invent 2022 Vorträgen:
Das Team von Lake Formation hat auf Kundenfeedback gehört und Verbesserungen in den Bereichen kontoübergreifende Data Governance, Erweiterung der Quelle von Data Lakes, Ermöglichung einer einheitlichen Data Governance eines Geschäftsdatenkatalogs, Ermöglichung eines sicheren Datenaustauschs zwischen Unternehmen und vorgenommen Erweiterung des Abdeckungsbereichs für feinkörnige Zugangskontrollen Amazon RedShift. Im Rest dieses Beitrags freuen wir uns, die Fortschritte zu teilen, die wir im Jahr 2022 gemacht haben.
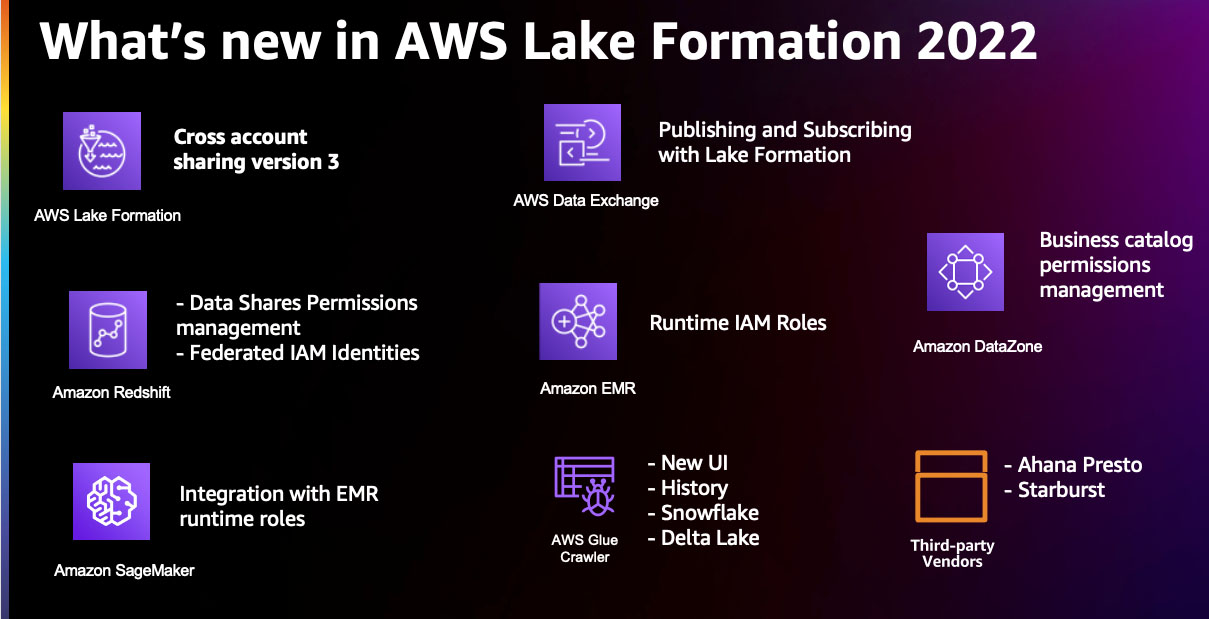
Verbesserung der kontoübergreifenden Governance
Lake Formation bietet die Grundlage für Kunden, um Daten über Konten innerhalb ihrer Organisation auszutauschen. Sie können AWS Glue Data Catalog-Ressourcen für freigeben AWS Identity and Access Management and (IAM)-Prinzipale innerhalb eines Kontos sowie andere AWS-Konten mithilfe von zwei Methoden. Die erste Methode wird Named-Resource-Methode genannt, bei der Benutzer die Namen von Datenbanken und Tabellen auswählen und den Typ der gemeinsam zu nutzenden Berechtigungen auswählen können. Die zweite Methode verwendet LF-Tags, bei denen Benutzer LF-Tags erstellen und Datenbanken und Tabellen zuordnen und IAM-Principals mithilfe von LF-Tag-Richtlinien und -Ausdrücken Berechtigungen erteilen können.
Im November 2022 stellte Lake Formation Version 3 seiner Cross-Account-Sharing-Funktion. Mit dieser neuen Version können Benutzer von Lake Formation Katalogressourcen mithilfe von LF-Tags auf der teilen AWS-Organisationen eben. Die gemeinsame Nutzung von Daten mithilfe von LF-Tags hilft bei der Skalierung von Berechtigungen und reduziert den Verwaltungsaufwand für Data-Lake-Ersteller. Die kontoübergreifende Freigabe Version 3 ermöglicht es Ihnen auch, Ressourcen für bestimmte IAM-Prinzipale in anderen Konten freizugeben, wodurch Dateneigentümer die Kontrolle darüber erhalten, wer auf ihre Daten in anderen Konten zugreifen kann. Schließlich haben wir den Aufwand für das Schreiben und Verwalten von Data Catalog-Ressourcenrichtlinien beseitigt, indem wir eingeführt haben AWS-Ressourcenzugriffsmanager (AWS RAM) lädt mit LF-Tags-basierten Richtlinien in Version 3 der kontoübergreifenden Freigabe ein. Wir empfehlen Ihnen, dies weiter zu erkunden Kontoübergreifende gemeinsame Nutzung in Lake Formation.
Erweitern der Lake Formation-Berechtigungen auf neue Daten
Bis re:Invent 2022 stellte Lake Formation die Berechtigungsverwaltung für IAM-Prinzipale für Data Catalog-Ressourcen mit zugrunde liegenden Daten hauptsächlich bereit Amazon Simple Storage-Service (Amazon S3). Auf der re:Invent 2022 haben wir vorgestellt Lake Formation-Berechtigungsverwaltung für Amazon Redshift-Datenfreigaben im Vorschaumodus. Amazon Redshift ist ein vollständig verwalteter Data Warehouse-Service im Petabyte-Bereich in der AWS Cloud. Die Datenfreigabefunktion ermöglicht es Dateneigentümern, Datenbanken, Tabellen und Ansichten in einem Amazon Redshift-Cluster zu gruppieren und mit anderen Amazon Redshift-Clustern innerhalb oder zwischen AWS-Konten zu teilen. Die gemeinsame Nutzung von Daten reduziert die Notwendigkeit, mehrere Kopien derselben Daten in verschiedenen Data Warehouses aufzubewahren, um die geschäftliche Entscheidungsfindung im gesamten Unternehmen zu beschleunigen. Lake Formation verbessert die gemeinsame Nutzung von Daten innerhalb von Amazon Redshift-Datenfreigaben weiter, indem es eine differenzierte Zugriffskontrolle auf Tabellen und Ansichten bietet.
Weitere Einzelheiten zu dieser Funktion finden Sie unter Von AWS Lake Formation verwaltete Redshift-Datenfreigaben (Vorschau) und Wie Redshift Data Share von Lake Formation verwaltet werden kann.
Amazon EMR ist eine verwaltete Clusterplattform zum Ausführen von Big-Data-Anwendungen mit Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi und Presto im großen Maßstab. Sie können Amazon EMR verwenden, um Batch- und Stream-Verarbeitungsanalyseaufträge auf Ihren S3-Data Lakes auszuführen. Beginnend mit der Amazon EMR-Version 6.7.0 haben wir eingeführt Lake Formation-Berechtigungsverwaltung für eine Laufzeit-IAM-Rolle Wird mit der EMR Steps API verwendet. Mit dieser Funktion können Sie Apache Spark- und Apache Hive-Anwendungen über die EMR Steps-API an einen EMR-Cluster übermitteln, die Berechtigungen auf Tabellen- und Spaltenebene mithilfe von Lake Formation für diese IAM-Rolle erzwingt, die die Anwendung übermittelt. Diese Lake Formation-Integration mit Amazon EMR ermöglicht es Ihnen, einen EMR-Cluster für mehrere Benutzer in einer Organisation mit unterschiedlichen Berechtigungen freizugeben, indem Sie Ihre Anwendungen durch eine Laufzeit-IAM-Rolle isolieren. Wir empfehlen Ihnen, diese Funktion im Lake Formation Workshop zu überprüfen Integration mit Amazon EMR mithilfe von Laufzeitrollen. Um einen Anwendungsfall zu untersuchen, siehe Einführung von Laufzeitrollen für Amazon EMR-Schritte: Verwenden Sie IAM-Rollen und AWS Lake Formation für die Zugriffskontrolle mit Amazon EMR.
Amazon SageMaker-Studio ist eine vollständig integrierte Entwicklungsumgebung (IDE) für maschinelles Lernen (ML), mit der Datenwissenschaftler und Entwickler Daten zum Erstellen, Trainieren, Optimieren und Bereitstellen von Modellen vorbereiten können. Studio bietet eine native Integration mit Amazon EMR, sodass Data Scientists und Data Engineers interaktiv Daten im Petabyte-Maßstab unter Verwendung von Open-Source-Frameworks wie Apache Spark, Presto und Hive mit Studio-Notebooks vorbereiten können. Mit der Veröffentlichung von Lake Formation-Berechtigungsverwaltung für eine Laufzeit-IAM-Rolle, unterstützt Studio jetzt den Zugriff auf Tabellen- und Spaltenebene mit Lake Formation. Wenn Benutzer von Studio-Notebooks aus eine Verbindung zu EMR-Clustern herstellen, können sie die IAM-Rolle (als Laufzeit-IAM-Rolle), mit denen sie sich verbinden möchten. Wenn der Datenzugriff von Lake Formation verwaltet wird, können Benutzer Berechtigungen auf Tabellen- und Spaltenebene erzwingen, indem sie Richtlinien verwenden, die der Laufzeitrolle zugeordnet sind. Weitere Einzelheiten finden Sie unter Wenden Sie fein abgestufte Datenzugriffskontrollen mit AWS Lake Formation und Amazon EMR von Amazon SageMaker Studio an.
Erfassen und katalogisieren Sie unterschiedliche Daten
Ein robustes Data-Governance-Modell umfasst Daten aus den vielen Datenquellen eines Unternehmens und Methoden zum Ermitteln und Katalogisieren dieser unterschiedlichen Datenbestände. AWS Glue-Crawler bieten die Möglichkeit, Daten aus Quellen wie Amazon S3, Amazon Redshift und NoSQL-Datenbanken zu erkennen und den AWS Glue-Datenkatalog zu füllen.
Im Jahr 2022 haben wir gestartet AWS Glue-Crawler-Unterstützung für Snowflake und AWS Glue-Crawler-Unterstützung für Delta-Lake-Tabellen. Diese Integrationen ermöglichen es AWS Glue-Crawlern, Data Catalog-Tabellen basierend auf diesen beliebten Datenquellen zu erstellen und zu aktualisieren. Dadurch ist es noch einfacher, ETL-Aufträge (Extract, Transform, Load) mit AWS Glue basierend auf diesen Data Catalog-Tabellen als Quellen und Ziele zu erstellen.
Im Jahr 2022 wurde die Benutzeroberfläche der AWS Glue-Crawler neu gestaltet, um eine bessere Benutzererfahrung zu bieten. Eine der wichtigsten Verbesserungen im Rahmen dieser Überarbeitung sind die besseren Einblicke in die Geschichte des AWS Glue-Crawlers. Die Benutzeroberfläche des Crawlerverlaufs bietet eine einfache Ansicht von Crawlerläufen, Zeitplänen, Datenquellen und Tags. Für jeden Crawl bietet der Crawler-Verlauf eine Zusammenfassung der Änderungen im Datenbankschema oder der Amazon S3-Partitionsänderungen. Der Crawler-Verlauf bietet auch detaillierte Informationen zu den DPU-Stunden und reduziert den Zeitaufwand für die Analyse und das Debugging von Crawler-Operationen und -Kosten. Informationen zu den neuen Funktionen, die der Crawler-Benutzeroberfläche hinzugefügt wurden, finden Sie unter Richten Sie AWS Glue-Crawler mithilfe der erweiterten AWS Glue-Benutzeroberfläche und des Crawler-Verlaufs ein und überwachen Sie sie.
Im Jahr 2022 haben wir auch die Unterstützung für Crawler basierend auf Amazon S3-Ereignisbenachrichtigungen erweitert, um Katalogtabellen zu unterstützen. Mit dieser Funktion kann inkrementelles Crawlen von Datenpipelines auf den geplanten AWS Glue-Crawler ausgelagert werden, wodurch Crawls auf inkrementelle S3-Ereignisse reduziert werden. Weitere Informationen finden Sie unter Erstellen Sie inkrementelle Crawls von Data Lakes mit vorhandenen Glue-Katalogtabellen.
Mehr Möglichkeiten, Daten über den Data Lake hinaus zu teilen
Während der re:Invent 2022 haben wir eine Vorschau auf angekündigt AWS Data Exchange für AWS Lake Formation, eine neue Funktion, mit der Datenabonnenten Datasets von Drittanbietern finden und abonnieren können, die direkt über Lake Formation verwaltet werden. Bis jetzt, AWS-Datenaustausch Abonnenten könnten auf Datensätze von Drittanbietern zugreifen, indem sie die Dateien der Anbieter in ihre eigenen S3-Buckets exportieren und die APIs der Anbieter aufrufen Amazon API-Gateway, oder Abfragen der Amazon Redshift-Datenfreigaben von Herstellern aus ihrem Amazon Redshift-Cluster. Mit der neuen Lake Formation-Integration kuratieren Datenanbieter AWS Data Exchange-Datensätze mithilfe von Lake Formation-Tags. Datenabonnenten können die mit diesen Tags verknüpften Datenbanken und Tabellen abfragen und durchsuchen, genau wie jede andere AWS Glue Data Catalog-Ressource. Organisationen können ressourcenbasierte Lake Formation-Berechtigungen anwenden, um die lizenzierten Datasets innerhalb desselben Kontos oder über mehrere Konten hinweg gemeinsam zu nutzen AWS-Lizenzmanager. AWS Data Exchange for Lake Formation rationalisiert die Datenlizenzierung und -freigabe, indem es das Onboarding von Daten beschleunigt, die Menge an ETL reduziert, die Endbenutzer für den Zugriff auf Daten von Drittanbietern benötigen, und die Governance und Zugriffskontrollen für Daten von Drittanbietern zentralisiert.
Auf der re:Invent 2022 haben wir das auch angekündigt Amazon DataZone, ein neuer Datenverwaltungsservice, mit dem Sie Daten, die in AWS, On-Premises und Drittanbieterquellen gespeichert sind, schneller und einfacher katalogisieren, entdecken, freigeben und verwalten können. Amazon DataZone ist ein Geschäftsdatenkatalog-Service, der die technischen Metadaten im AWS Glue-Datenkatalog ergänzt. Amazon DataZone ist in die Berechtigungsverwaltung von Lake Formation integriert, sodass Sie den Zugriff auf Ihre Daten effektiv verwalten und steuern und prüfen können, wer auf welche Daten zu welchem Zweck zugreift. Mit dem Publisher-Subscriber-Modell von Amazon DataZone können Datenbestände über Regionen hinweg geteilt und abgerufen werden. Weitere Einzelheiten zum Dienst und seinen Funktionen finden Sie unter Häufig gestellte Fragen zu Amazon DataZone und re:Invent-Start.
Zusammenfassung
Daten verändern jeden Bereich und jedes Unternehmen. Da Daten jedoch schneller wachsen, als die meisten Unternehmen nachverfolgen können, ist das Sammeln, Sichern und Wertschöpfen dieser Daten eine Herausforderung. Eine moderne Datenstrategie kann Ihnen helfen, mit Daten bessere Geschäftsergebnisse zu erzielen. AWS bietet die umfassendste Reihe von Services für die End-to-End-Datenreise, um Ihnen dabei zu helfen, den Wert Ihrer Daten zu erschließen und sie in Erkenntnisse umzuwandeln.
Bei AWS arbeiten wir rückwärts von den Kundenanforderungen. Das Team von Lake Formation hat hart daran gearbeitet, die in diesem Beitrag beschriebenen Funktionen bereitzustellen, und wir laden Sie ein, sie sich anzusehen. Mit unserem kontinuierlichen Fokus auf Erfindungen hoffen wir, eine Schlüsselrolle dabei zu spielen, Organisationen in die Lage zu versetzen, neue Data-Governance-Modelle zu entwickeln, mit denen Sie blitzschnell mehr geschäftlichen Nutzen erzielen können.
Sie können mit Lake Formation beginnen, indem Sie unsere erkunden Hands-On-Workshop Module u Erste-Schritte-Tutorials. Wir freuen uns darauf, von Ihnen, unseren Kunden, zu Ihren Data Lake- und Data Governance-Anwendungsfällen zu hören. Bitte wenden Sie sich über Ihr AWS-Kontoteam an uns und teilen Sie Ihre Kommentare mit.
Über die Autoren
 Jason Berkowitz ist Senior Product Manager bei AWS Lake Formation. Er hat einen Hintergrund in maschinellem Lernen und Data-Lake-Architekturen. Er hilft Kunden dabei, datengetrieben zu werden.
Jason Berkowitz ist Senior Product Manager bei AWS Lake Formation. Er hat einen Hintergrund in maschinellem Lernen und Data-Lake-Architekturen. Er hilft Kunden dabei, datengetrieben zu werden.
 Aarthi Srinivasan ist Senior Big Data Architect bei AWS Lake Formation. Sie entwickelt gerne Data-Lake-Lösungen für AWS-Kunden und -Partner. Wenn sie nicht an der Tastatur sitzt, erforscht sie die neuesten Wissenschafts- und Technologietrends und verbringt Zeit mit ihrer Familie.
Aarthi Srinivasan ist Senior Big Data Architect bei AWS Lake Formation. Sie entwickelt gerne Data-Lake-Lösungen für AWS-Kunden und -Partner. Wenn sie nicht an der Tastatur sitzt, erforscht sie die neuesten Wissenschafts- und Technologietrends und verbringt Zeit mit ihrer Familie.
 Leonardo Gomez ist Senior Analytics Specialist Solutions Architect bei AWS. Er lebt in Toronto, Kanada, und verfügt über mehr als ein Jahrzehnt Erfahrung im Datenmanagement, wo er Kunden auf der ganzen Welt dabei hilft, ihre geschäftlichen und technischen Anforderungen zu erfüllen.
Leonardo Gomez ist Senior Analytics Specialist Solutions Architect bei AWS. Er lebt in Toronto, Kanada, und verfügt über mehr als ein Jahrzehnt Erfahrung im Datenmanagement, wo er Kunden auf der ganzen Welt dabei hilft, ihre geschäftlichen und technischen Anforderungen zu erfüllen.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/aws-lake-formation-2022-year-in-review/
- 100
- 116
- 2022
- 7
- a
- Fähigkeit
- Fähig
- Über uns
- beschleunigen
- beschleunigend
- Zugang
- Zugriff auf Daten
- Zugriff
- Zugriff
- Konto
- Trading Konten
- über
- hinzugefügt
- Zusatz
- Zusätzliche
- Adresse
- Administrator
- Vorteil
- erlaubt
- Amazon
- Amazon EMR
- Amazon Sage Maker
- Betrag
- Analytik
- Analyse
- und
- angekündigt
- Apache
- Apache Funken
- Bienen
- APIs
- Anwendung
- Anwendungen
- Jetzt bewerben
- angemessen
- Architektur
- Bereich
- Bereiche
- um
- Details
- Partnerschaftsräte
- damit verbundenen
- Prüfung
- AWS
- AWS-Kleber
- AWS Lake-Formation
- AWS re: Invent
- Hintergrund
- basierend
- werden
- Besser
- Beyond
- Big
- Big Data
- bauen
- Baumeister
- Bauherren
- Building
- erbaut
- Geschäft
- Business-to-Business
- namens
- Aufruf
- Kann bekommen
- Kanada
- Fähigkeiten
- Häuser
- Fälle
- Katalog
- CCPA
- Herausforderungen
- herausfordernd
- Änderungen
- aus der Ferne überprüfen
- China
- Auswählen
- Cloud
- Cluster
- Das Sammeln
- Sammlung
- Bemerkungen
- Unternehmen
- wettbewerbsfähig
- abschließen
- Komplex
- umfassend
- Vernetz Dich
- weiter
- Smartgeräte App
- Steuerung
- Kosten
- könnte
- Berichterstattung
- Crawler
- erstellen
- Original
- Kunde
- Kunden
- technische Daten
- Datenzugriff
- Dateningenieur
- Data Exchange
- Datensee
- Datenmanagement
- Datenplattform
- Datenschutz
- Datenqualität
- Datenwissenschaftler
- Datenübertragung
- Datenstrategie
- Data Warehouse
- Data Warehouse
- datengesteuerte
- Datenbase
- Datenbanken
- Datensätze
- Jahrzehnte
- Decision Making
- tiefer
- Übergeben
- geliefert
- Delta
- Bereitstellen
- beschrieben
- detailliert
- Details
- Entwickler
- Entwicklung
- anders
- Direkt
- entdeckt,
- jeder
- einfacher
- Effektiv
- effektiv
- Empowerment
- ermöglicht
- ermöglichen
- ermutigen
- End-to-End
- Ingenieur
- Ingenieure
- verbesserte
- Verbessert
- gewährleisten
- Gewährleistung
- Arbeitsumfeld
- Äther (ETH)
- EU
- Sogar
- Event
- Veranstaltungen
- Jedes
- Austausch-
- aufgeregt
- vorhandenen
- Ausbau
- ERFAHRUNGEN
- ERKUNDEN
- Möglichkeiten sondieren
- Ausdrücke
- Extrakt
- Familie
- beschleunigt
- Merkmal
- Eigenschaften
- Feedback
- wenige
- Feld
- Mappen
- Finden Sie
- Ende
- Vorname
- Setzen Sie mit Achtsamkeit
- Folgende
- Ausbildung
- vorwärts
- Foundation
- Gerüste
- für
- voll
- Funktionsumfang
- weiter
- DSGVO
- Erzeugung
- bekommen
- bekommen
- Globus
- gehen
- Governance
- gewähren
- mehr
- Gruppe an
- persönlichem Wachstum
- Handling
- glücklich
- hart
- Gesundheit
- Hörtests
- Hilfe
- Unternehmen
- hilft
- Geschichte
- Bienenstock
- ein Geschenk
- STUNDEN
- Ultraschall
- aber
- HTML
- HTTPS
- IAM
- Identitätsschutz
- Implementierung
- wichtig
- Verbesserungen
- verbessert
- Verbesserung
- in
- In anderen
- Dazu gehören
- Einschließlich
- Steigert
- zunehmend
- Info
- Information
- Einblick
- Einblicke
- integriert
- Integration
- Integrationen
- interessiert
- eingeführt
- Einführung
- einladen
- IT
- Jobs
- Reise
- Behalten
- Wesentliche
- See
- neueste
- ins Leben gerufen
- Führer
- LERNEN
- lernen
- Niveau
- Lizenz
- Zugelassen
- Lizenzierung
- Blitz
- Lichtgeschwindigkeit
- Belastung
- aussehen
- Maschine
- Maschinelles Lernen
- gemacht
- Main
- MACHT
- Making
- verwalten
- verwaltet
- Management
- Manager
- viele
- Metadaten
- Methode
- Methoden
- ML
- Model
- Modell
- für
- modern
- Module
- Überwachen
- mehr
- vor allem warme
- mehrere
- Namen
- nativen
- Need
- Bedürfnisse
- Neu
- neue Funktion
- Laptops
- Benachrichtigungen
- November
- Neu
- Verbindlichkeiten
- bieten
- Angebote
- Einsteigen
- EINEM
- Open-Source-
- Einkauf & Prozesse
- Gelegenheit
- Organisation
- Organisationen
- Andere
- besitzen
- Besitzer
- Teil
- PBS
- Erlaubnis
- Berechtigungen
- Petabyte
- Plattform
- Plato
- Datenintelligenz von Plato
- PlatoData
- Play
- Bitte
- Politik durchzulesen
- Beliebt
- Mappe
- möglich
- Post
- Danach
- vorgeführt
- Vorspann
- in erster Linie
- Datenschutz
- anpassen
- Verarbeitung
- Produkt
- Produkt-Manager
- Fortschritt
- die
- vorausgesetzt
- Anbieter
- bietet
- Bereitstellung
- veröffentlicht
- Zweck
- Qualität
- RAM
- RE
- erkennen
- empfehlen
- reduziert
- Reduzierung
- Regionen
- Vorschriften
- Regulierungsbehörden
- Release
- Entfernt
- falls angefordert
- Voraussetzungen:
- Ressourcen
- Downloads
- REST
- Überprüfen
- Risiko
- robust
- Rollen
- Rollen
- Führen Sie
- Russland
- sagemaker
- gleich
- Skalieren
- vorgesehen
- Wissenschaft
- Wissenschaft und Technologie
- Wissenschaftler
- Wissenschaftler
- nahtlos
- Zweite
- Verbindung
- Sicherung
- Senior
- Leistungen
- kompensieren
- Teilen
- von Locals geführtes
- Shares
- ,,teilen"
- Einfacher
- So
- Lösung
- Lösungen
- Auflösung
- einige
- Quelle
- Quellen
- Spark
- Spezialist
- spezifisch
- Geschwindigkeit
- verbrachte
- Stakeholder
- Starburst
- begonnen
- Beginnen Sie
- Shritte
- storage
- gelagert
- Strategie
- Strom
- Studio Adressen
- abschicken
- Abonnieren
- weltweit
- so
- zusammenfassen
- ZUSAMMENFASSUNG
- Support
- Unterstützt
- Systeme und Techniken
- Gespräche
- Ziele
- Team
- Teams
- Technische
- Technologie
- Das
- Die Quelle
- ihr
- Ding
- basierte Online-to-Offline-Werbezuordnungen von anderen gab.
- Durch
- während
- Zeit
- zu
- toronto
- aufnehmen
- verfolgen sind
- Ausbildung
- Transformieren
- Transformieren
- Trends
- WENDE
- ui
- zugrunde liegen,
- verstehen
- einheitlich
- einzigartiges
- öffnen
- Aktualisierung
- -
- Anwendungsfall
- Mitglied
- Benutzererfahrung
- Nutzer
- Wert
- Version
- Anzeigen
- Ansichten
- Warehouse
- Wege
- Was
- ob
- WHO
- .
- Arbeiten
- gearbeitet
- Werkstatt
- Workshops
- Schreiben
- Jahr
- Ihr
- Youtube
- Zephyrnet