Datenintegrationsprozesse profitieren wie jede andere Software von automatisierten Tests. Es ist jedoch selten, ein Datenpipeline-Projekt mit einem geeigneten Satz automatisierter Tests zu finden. Selbst wenn ein Projekt viele Tests hat, sind sie oft unstrukturiert, kommunizieren ihren Zweck nicht und sind schwer durchzuführen.
Ein Merkmal von Datenpipeline Entwicklung ist die häufige Veröffentlichung qualitativ hochwertiger Daten, um Benutzerfeedback und Akzeptanz zu gewinnen. Am Ende jeder Iteration der Datenpipeline wird erwartet, dass die Daten für die nächste Phase von hoher Qualität sind.
Automatisiertes Testen ist für das Integrationstesten von Datenpipelines unerlässlich. Manuelles Testen ist in stark iterativen und adaptiven Entwicklungsumgebungen unpraktisch.
Hauptprobleme beim manuellen Testen von Daten
Erstens dauert es zu lange und ist ein entscheidendes Hindernis für die häufige Lieferung von Pipelines. Teams, die sich hauptsächlich auf manuelles Testen verlassen, verschieben das Testen auf dedizierte Testperioden, wodurch sich Fehler ansammeln können.
Zweitens ist das manuelle Testen der Datenpipeline für Regressionstests nicht ausreichend reproduzierbar.
Die Automatisierung der Datenpipeline-Tests erfordert eine anfängliche Planung und kontinuierliche Sorgfalt, aber sobald die technischen Teams die Automatisierung übernehmen, ist der Erfolg des Projekts sicherer.
Varianten von Datenpipelines
- Extrahieren, Transformieren und Laden (ETL)
- Extrahieren, Laden und Transformieren (ELT)
- Data Lake, Data Warehouse-Pipelines
- Echtzeit-Pipelines
- Pipelines für maschinelles Lernen
Datenpipeline-Komponenten für die Prüfung der Testautomatisierung
Datenpipelines bestehen aus mehreren Komponenten, die jeweils für eine bestimmte Aufgabe zuständig sind. Zu den Elementen einer Datenpipeline gehören:
- Datenquellen: Die Herkunft der Daten
- Datenaufnahme: Der Prozess des Sammelns von Daten aus der Datenquelle
- Datentransformation: Der Prozess der Umwandlung der gesammelten Daten in ein Format, das für weitere Analysen verwendet werden kann
- Datenüberprüfungen/-validierungen: Der Prozess, um sicherzustellen, dass die Daten korrekt und konsistent sind
- Datenspeicher: Der Prozess der Speicherung der transformierten und validierten Daten in einem Data Warehouse oder Data Lake
- Datenanalyse: Der Prozess der Analyse der gespeicherten Daten, um Muster, Trends und Erkenntnisse zu identifizieren
Best Practices für die Automatisierung von Daten-Pipeline-Tests
Was und wann automatisiert werden soll (oder sogar, ob Sie Automatisierung benötigen), sind entscheidende Entscheidungen für das Test- (oder Entwicklungs-) Team. Die Auswahl geeigneter Produkteigenschaften für die Automatisierung bestimmt maßgeblich den Erfolg der Automatisierung.
Zu den Best Practices bei der Automatisierung von Tests für eine Datenpipeline gehören:
- Definieren Sie klare und spezifische Testziele: Bevor Sie mit dem Testen beginnen, ist es wichtig zu definieren, was Sie durch das Testen erreichen möchten. Auf diese Weise können Sie effektive und effiziente Tests erstellen, die wertvolle Erkenntnisse liefern.
- Testen Sie alle Workflows der Datenpipeline: Eine Datenpipeline besteht normalerweise aus mehreren Komponenten: Datenaufnahme, -verarbeitung, -transformation und -speicherung. Es ist wichtig, jede Komponente zu testen, um den ordnungsgemäßen und reibungslosen Datenfluss durch die Pipeline sicherzustellen.
- Verwenden Sie glaubwürdige Testdaten: Beim Testen einer Datenpipeline ist es wichtig, realistische Daten zu verwenden, die reale Szenarien nachahmen. Dies hilft dabei, Probleme zu identifizieren, die beim Umgang mit unterschiedlichen Datentypen auftreten können.
- Automatisieren Sie mit effektiven Tools: Dies kann mithilfe von Testframeworks und -tools erreicht werden.
- Überwachen Sie die Pipeline regelmäßig: Auch nach Abschluss der Tests ist es wichtig, die Pipeline regelmäßig zu überwachen, um sicherzustellen, dass sie wie vorgesehen funktioniert. Dies hilft dabei, Probleme zu identifizieren, bevor sie zu kritischen Problemen werden.
- Beteiligte einbeziehen: Beziehen Sie Stakeholder wie Datenanalysten, Dateningenieure und Geschäftsanwender in den Testprozess ein. Dadurch wird sichergestellt, dass die Tests für alle Beteiligten relevant und wertvoll sind.
- Dokumentation pflegen: Es ist wichtig, Dokumente aufzubewahren, die die Tests, Testfälle und Testergebnisse beschreiben. Dadurch wird sichergestellt, dass die Tests im Laufe der Zeit repliziert und gewartet werden können.
Vorsichtig sein; Die Automatisierung der Änderung instabiler Merkmale sollte vermieden werden. Heutzutage kann kein bekanntes Geschäftstool oder eine Reihe von Methoden/Prozessen als vollständiger End-to-End-Test der Datenpipeline angesehen werden.
Berücksichtigen Sie Ihre Testautomatisierungsziele
Die Automatisierung von Datenpipeline-Tests wird beschrieben als die Verwendung von Tools zur Steuerung 1) der Testausführung, 2) Vergleiche der tatsächlichen Ergebnisse mit den vorhergesagten Ergebnissen und 3) die Einrichtung von Testvorbedingungen und anderen Teststeuerungs- und Testberichtsfunktionen.
Im Allgemeinen umfasst die Testautomatisierung die Automatisierung eines bestehenden manuellen Prozesses, der einen formalen Testprozess verwendet.
Obwohl manuelle Datenpipelinetests viele Datenfehler aufdecken können, sind sie mühsam und zeitaufwändig. Darüber hinaus kann manuelles Testen bei der Erkennung bestimmter Fehler unwirksam sein.
Die Automatisierung der Datenpipeline umfasst die Entwicklung von Testprogrammen, die andernfalls manuell durchgeführt werden müssten. Sobald die Tests automatisiert sind, können sie schnell wiederholt werden. Dies ist häufig die kostengünstigste Methode für eine Datenpipeline, die eine lange Lebensdauer haben kann. Selbst geringfügige Korrekturen oder Verbesserungen während der Lebensdauer der Pipeline können dazu führen, dass Funktionen, die zuvor funktioniert haben, nicht mehr funktionieren.
Die Integration automatisierter Tests in die Entwicklung von Datenpipelines stellt eine einzigartige Reihe von Herausforderungen dar. Gegenwärtige automatisierte Softwareentwicklungs-Testwerkzeuge sind nicht ohne weiteres an Datenbank- und Datenpipeline-Projekte anpassbar.
Die große Vielfalt an Datenpipeline-Architekturen verkompliziert diese Herausforderungen weiter, da sie mehrere Datenbanken umfassen, die eine spezielle Codierung für Datenextraktion, Transformationen, Laden, Datenbereinigung, Datenaggregation und Datenanreicherung.
Tools zur Testautomatisierung können teuer sein und werden normalerweise zusammen mit manuellen Tests verwendet. Sie können jedoch auf lange Sicht kostengünstig werden, insbesondere wenn sie wiederholt in Regressionstests verwendet werden.
Häufige Kandidaten für die Testautomatisierung
- Testen von BI-Berichten
- Geschäftliche, behördliche Compliance
- Datenaggregationsverarbeitung
- Datenbereinigung und Archivierung
- Datenqualitätstests
- Datenabgleich (z. B. Quelle zu Ziel)
- Datentransformationen
- Dimensionstabellendaten werden geladen
- End-to-End-Tests
- ETL, ELT Validierungs- und Verifizierungstests
- Faktentabellendaten werden geladen
- Überprüfung des Ladens von Dateien/Daten
- Inkrementelle Belastungstests
- Belastungs- und Skalierbarkeitstests
- Fehlende Dateien, Aufzeichnungen, Felder
- Leistungstest
- Referenzielle Integrität
- Regressionstests
- Sicherheitstests
- Testen und Profilieren von Quelldaten
- Staging, ODS-Datenvalidierungen
- Einheiten-, Integrations- und Regressionstests
Die Automatisierung dieser Tests kann aufgrund der Komplexität der Verarbeitung und der Anzahl der zu überprüfenden Quellen und Ziele erforderlich sein.
Bei den meisten Projekten sind Datenpipeline-Testprozesse darauf ausgelegt, die Datenqualität zu überprüfen und zu implementieren.
Die Vielzahl der heute verfügbaren Datentypen stellt Herausforderungen beim Testen dar
Heutzutage ist eine Vielzahl von Datentypen verfügbar, die von traditionellen strukturierten Datentypen wie Text, Zahlen und Datumsangaben bis hin zu unstrukturierten Datentypen wie Audio, Bildern und Video reichen. Darüber hinaus werden verschiedene Arten von halbstrukturierten Daten wie XML und JSON in der Webentwicklung und beim Datenaustausch häufig verwendet.
Mit dem Aufkommen des Internets der Dinge (IoT) gab es eine Explosion verschiedener Datentypen, darunter Sensordaten, Standortdaten und Kommunikationsdaten von Maschine zu Maschine. Da diese Datentypen extrahiert und transformiert werden, kann das Testen ohne geeignete Tools komplizierter werden. Dies hat zu neuen Datenverwaltungstechnologien und Analysetechniken wie Stream Processing, Edge Computing und Echtzeitanalysen geführt.
Abbildung 1 zeigt Beispiele für heute weit verbreitete Datentypen. Die große Anzahl stellt Herausforderungen dar, wenn man testet, ob erforderliche Transformationen korrekt durchgeführt werden. Datenexperten müssen sich daher mit einer breiten Palette von Datentypen auskennen und anpassungsfähig sein, um neue Trends und Technologien zu testen.
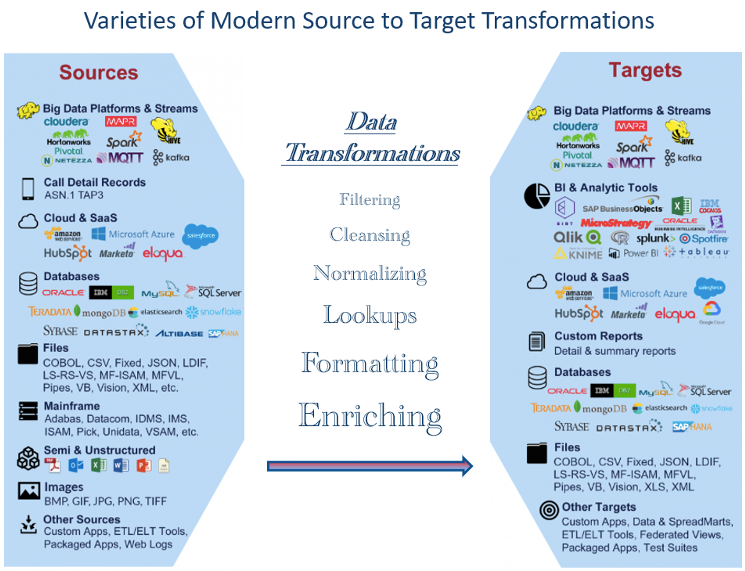
Evaluieren Sie Pipeline-Komponenten für mögliche automatisierte Tests
Ein Schlüsselelement agiler und anderer moderner Entwicklungen ist das automatisierte Testen. Wir können dieses Bewusstsein auf die Datenpipeline anwenden.
Ein wesentlicher Aspekt beim Testen von Datenpipelines ist, dass die Anzahl der durchgeführten Tests weiter zunehmen wird, um zusätzliche Funktionalität und Wartung zu überprüfen. Figur 2 zeigt viele Bereiche, in denen Testautomatisierung in einer Datenpipeline angewendet werden kann.
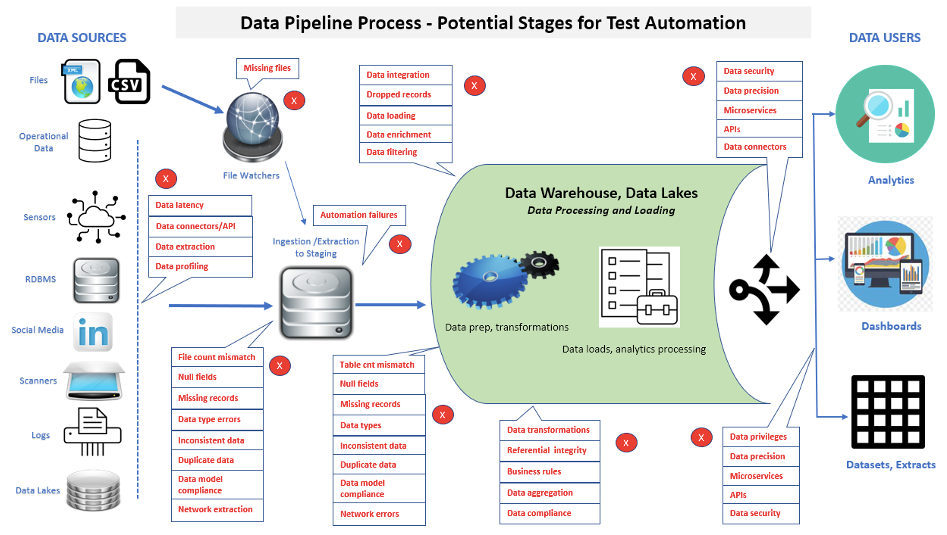
Bei der Implementierung von Testautomatisierung können Daten von Quellschichten über die Datenpipeline-Verarbeitung bis hin zu Ladevorgängen in der Datenpipeline und schließlich zu den Front-End-Anwendungen oder -Berichten verfolgt werden. Angenommen, in einer Front-End-Anwendung oder einem Bericht werden beschädigte Daten gefunden. In diesem Fall kann die Ausführung automatisierter Suiten dazu beitragen, schneller festzustellen, ob einzelne Probleme in Datenquellen, einem Datenpipelineprozess, einer neu geladenen Datenpipeline-Datenbank/einem Data Mart oder Business Intelligence-/Analyseberichten liegen.
Ein Schwerpunkt auf der schnellen Identifizierung von Daten- und Leistungsproblemen in komplexen Datenpipeline-Architekturen bietet ein Schlüsselwerkzeug zur Förderung der Entwicklungseffizienz, zur Verkürzung von Build-Zyklen und zur Erfüllung der Ziele der Freigabekriterien.
Bestimmen Sie die Kategorien der zu automatisierenden Tests
Der Trick besteht darin, zu bestimmen, was automatisiert werden soll und wie mit jeder Aufgabe umzugehen ist. Bei der Automatisierung von Tests sollten eine Reihe von Fragen berücksichtigt werden, z. B.:
- Wie hoch sind die Kosten für die Automatisierung der Tests?
- Wer ist für die Testautomatisierung verantwortlich (z. B. Dev., QA, Data Engineers)?
- Welche Testwerkzeuge sollten verwendet werden (z. B. Open Source, Anbieter)?
- Werden die ausgewählten Tools alle Erwartungen erfüllen?
- Wie werden die Testergebnisse mitgeteilt?
- Wer interpretiert die Testergebnisse?
- Wie werden die Testskripte gepflegt?
- Wie organisieren wir die Skripte für einen einfachen und genauen Zugriff?
Abbildung 3 zeigt Beispiele für Zeitdauern (für Testausführung, Fehleridentifizierung und Berichterstellung) für manuelle vs. automatisierte Testfälle aus einer tatsächlichen Projekterfahrung.
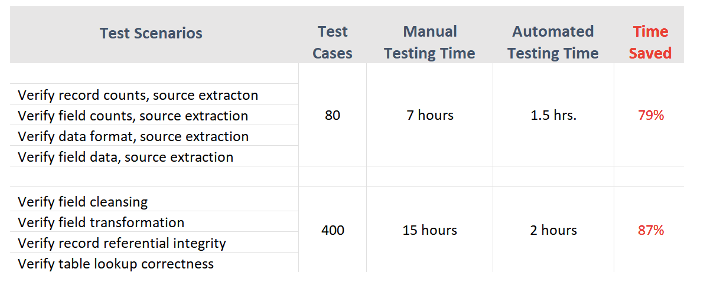
Das automatisierte Testen von Datenpipelines zielt darauf ab, die kritischsten Funktionen zum Laden einer Datenpipeline abzudecken – Synchronisierung und Abgleich von Quell- und Zieldaten.
Vorteile und Grenzen des automatisierten Testens
Herausforderungen der Testautomatisierung
- Berichtstest: Testen von Business Intelligence oder Analyseberichten durch Automatisierung
- Datenkomplexität: Das Testen von Datenpipelines umfasst häufig komplexe Datenstrukturen und -transformationen, deren Automatisierung schwierig sein kann und spezielles Fachwissen erfordert.
- Pipeline-Komplexität: Datenpipelines können komplex sein und mehrere Verarbeitungsphasen umfassen, deren Testen und Debuggen schwierig sein kann. Darüber hinaus können Änderungen an einem Teil der Pipeline unbeabsichtigte Folgen nachgelagert haben.
Vorteile der Testautomatisierung
- Führt Testfälle schneller aus: Automatisierung kann die Implementierung von Testszenarien beschleunigen.
- Erstellt eine wiederverwendbare Testsuite: Sobald die Testskripte mit den Automatisierungstools ausgeführt wurden, können sie zum einfachen Abrufen und Wiederverwenden gesichert werden.
- Erleichtert die Testberichterstattung: Ein interessantes Merkmal vieler automatisierter Tools ist ihre Fähigkeit, Berichte und Testdateien zu erstellen. Diese Funktionen stellen den Datenstatus genau dar, identifizieren Mängel eindeutig und werden bei Compliance-Audits verwendet.
- Reduziert Personal- und Nacharbeitskosten: Die Zeit, die für manuelles Testen oder erneutes Testen nach der Fehlerkorrektur aufgewendet wird, kann für andere Initiativen innerhalb der IT-Abteilung aufgewendet werden.
Mögliche Einschränkungen
- Kann das manuelle Testen nicht vollständig ersetzen: Obwohl die Automatisierung für verschiedene Anwendungen und Testfälle verwendet werden kann, es kann das manuelle Testen nicht vollständig ersetzen. Es wird immer noch komplizierte Testfälle geben, bei denen die Automatisierung nicht alles erfasst, und für Benutzerakzeptanztests müssen Endbenutzer Tests oft manuell durchführen. Daher ist die richtige Kombination aus automatisierten und manuellen Tests im Prozess von entscheidender Bedeutung.
- Werkzeugkosten: Kommerzielle Testwerkzeuge können je nach Größe und Funktionalität teuer sein. Oberflächlich betrachtet kann ein Unternehmen dies als unnötige Kosten ansehen. Allein die Wiederverwendung kann es jedoch schnell zu einer Bereicherung machen.
- Kosten der Ausbildung: Tester sollten nicht nur in der Programmierung, sondern auch in der Planung automatisierter Tests geschult werden. Automatisierte Tools können kompliziert zu bedienen sein und erfordern möglicherweise eine Benutzerschulung.
- Die Automatisierung erfordert Planung, Vorbereitung und dedizierte Ressourcen: Der Erfolg des automatisierten Testens hängt hauptsächlich von präzisen Testanforderungen und der sorgfältigen Entwicklung von Testfällen ab, bevor das Testen beginnt. Leider ist die Entwicklung von Testfällen immer noch hauptsächlich ein manueller Prozess. Da jede Organisation und jede Datenpipelineanwendung einzigartig sein kann, erstellen viele automatisierte Testtools keine Testfälle.
Erste Schritte mit der Datenpipeline-Testautomatisierung
Nicht alle Datenpipelinetests sind für die Automatisierung geeignet. Bewerten Sie die oben genannten Situationen, um festzustellen, welche Arten von Automatisierung Ihrem Testprozess zugute kommen würden und wie viel erforderlich ist. Bewerten Sie Ihre Testanforderungen und identifizieren Sie Effizienzgewinne, die durch automatisiertes Testen erzielt werden können. Datenpipeline-Teams, die Regressionstests viel Zeit widmen, werden am meisten profitieren.
Entwickeln Sie einen Business Case für automatisiertes Testen. Die IT muss zunächst Argumente liefern, um dem Unternehmen den Wert zu vermitteln.
Bewerten Sie die Optionen. Nachdem Sie den aktuellen Stand und die Anforderungen innerhalb der IT-Abteilung bewertet haben, bestimmen Sie, welche Tools zu den Testprozessen und -umgebungen der Organisation passen. Zu den Optionen können Anbieter, Open Source, interne oder eine Mischung aus Tools gehören.
Schlussfolgerungen
Da die Testautomatisierung schnell zu einer wesentlichen Alternative zum manuellen Testen geworden ist, suchen immer mehr Unternehmen nach Tools und Strategien, um die Automatisierung erfolgreich zu implementieren. Dies hat zu einem erheblichen Wachstum von Testautomatisierungstools auf Basis von Appium, Selenium, Katalon Studio und vielen anderen geführt. Allerdings müssen die Datenpipeline- und Dateningenieure, BI- und Qualitätssicherungsteams über die richtigen Programmierkenntnisse verfügen, um diese Automatisierungstools vollständig nutzen zu können.
Viele IT-Experten prognostizieren, dass die Wissenskluft zwischen Testern und Entwicklern kontinuierlich reduziert werden muss und wird. Automatisierte Tools zum Testen von Datenpipelines können den Zeitaufwand für das Testen von Code im Vergleich zu herkömmlichen manuellen Methoden erheblich reduzieren.
Da die Fähigkeiten zur Entwicklung von Datenpipelines weiter zunehmen, steigt auch der Bedarf an umfassenderen und moderneren automatisierten Datentests.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://www.dataversity.net/best-practices-in-data-pipeline-test-automation/
- :Ist
- $UP
- 1
- a
- Fähigkeit
- oben
- Akzeptanz
- Zugang
- Akkumulieren
- genau
- genau
- Erreichen
- erreicht
- hinzugefügt
- Zusatz
- zusätzlich
- adoptieren
- Advent
- Nach der
- Anhäufung
- agil
- Ziel
- Alle
- Zulassen
- allein
- Alternative
- Obwohl
- Analyse
- Business Analysten
- Analytisch
- Analytische
- Analytik
- Analyse
- und
- Anwendung
- Anwendungen
- angewandt
- Jetzt bewerben
- angemessen
- SIND
- Bereiche
- AS
- Aussehen
- Beurteilung
- Vermögenswert
- Versicherung
- gesichert
- At
- Audio-
- Audits
- automatisieren
- Automatisiert
- automatisieren
- Automation
- verfügbar
- vermieden
- Bewusstsein
- unterstützt
- basierend
- Grundlage
- BE
- weil
- werden
- Bevor
- Anfang
- Nutzen
- BESTE
- Best Practices
- zwischen
- Break
- breit
- Bugs
- bauen
- Geschäft
- Business Intelligence
- Unternehmen
- CAN
- Kandidaten
- kann keine
- Fähigkeiten
- Erfassung
- vorsichtig
- Häuser
- Fälle
- Kategorien
- Verursachen
- sicher
- Herausforderungen
- herausfordernd
- Änderungen
- Ändern
- Merkmal
- Charakteristik
- aus der Ferne überprüfen
- gewählt
- klar
- Code
- Programmierung
- Das Sammeln
- Kombination
- mit uns kommunizieren,
- Kommunikation
- verglichen
- abschließen
- uneingeschränkt
- Komplex
- Komplexität
- Compliance
- kompliziert
- Komponente
- Komponenten
- umfassend
- Computing
- Folgen
- erheblich
- betrachtet
- fortsetzen
- kontinuierlich
- ständig
- Smartgeräte App
- konventionellen
- korrekt
- Kosten
- kostengünstiger
- Kosten
- Abdeckung
- erstellen
- glaubwürdig
- Kriterien
- kritischem
- wichtig
- Strom
- Aktuellen Zustand
- Zyklen
- technische Daten
- Datumsanreicherung
- Data Exchange
- Datenmanagement
- Datenqualität
- Data Warehouse
- Datenbase
- Datenbanken
- DATENVERSITÄT
- Datum
- Entscheidungen
- gewidmet
- Lieferanten
- Abteilung
- abhängig
- Abhängig
- beschrieben
- entworfen
- Bestimmen
- entschlossen
- Festlegung
- Entwickler
- Entwickler
- Entwicklung
- Entwicklung
- Entwicklungen
- anders
- Fleiß
- Displays
- Dokumentation
- Unterlagen
- Dabei
- e
- jeder
- Früher
- Einfache
- Edge
- Edge-Computing
- Effektiv
- Wirkungsgrade
- Effizienz
- effizient
- Element
- Elemente
- aufstrebenden
- Betonung
- End-to-End
- Ingenieure
- gewährleisten
- Umgebungen
- insbesondere
- essential
- bewerten
- Sogar
- Jedes
- alles
- Beispiele
- Austausch-
- Ausführung
- vorhandenen
- Erwartungen
- erwartet
- teuer
- ERFAHRUNGEN
- Expertise
- Experten
- Extraktion
- beschleunigt
- Merkmal
- Eigenschaften
- Feedback
- Abbildung
- Mappen
- Endlich
- Suche nach
- Vorname
- Mängel
- Fluss
- Aussichten für
- formal
- Format
- gefunden
- Gerüste
- häufig
- für
- voll
- Funktionalität
- Funktionen
- weiter
- Gewinnen
- Gewinne
- Lücke
- der Regierung
- Wachstum
- Griff
- Handling
- hart
- Haben
- mit
- Hilfe
- High
- hochwertige
- hoch
- Ultraschall
- Hilfe
- aber
- HTTPS
- Login
- identifizieren
- Bilder
- implementieren
- Implementierung
- Umsetzung
- wichtig
- in
- das
- Einschließlich
- Erhöhung
- Steigert
- Krankengymnastik
- Anfangs-
- Initiativen
- Integration
- Intelligenz
- interessant
- intern
- Internet
- Internet der Dinge
- beteiligen
- beinhaltet
- iot
- Probleme
- IT
- Iteration
- JSON
- Wesentliche
- Wissen
- bekannt
- See
- weitgehend
- Lagen
- lernen
- geführt
- Lebensdauer
- Lebensdauer
- Gefällt mir
- Einschränkungen
- Belastung
- Laden
- Belastungen
- located
- Standorte
- Lang
- suchen
- Wartung
- um
- Management
- manuell
- manuell
- viele
- max-width
- Triff
- Treffen
- Methode
- Methoden
- Moll
- modern
- Überwachen
- mehr
- vor allem warme
- mehrere
- notwendig,
- Need
- erforderlich
- Bedürfnisse
- Neu
- weiter
- Anzahl
- Zahlen
- of
- on
- EINEM
- XNUMXh geöffnet
- Open-Source-
- Optionen
- Organisation
- Origin
- Andere
- Anders
- Andernfalls
- Teil
- Muster
- ausführen
- Leistung
- Zeiträume
- Phase
- Pipeline
- Planung
- Plato
- Datenintelligenz von Plato
- PlatoData
- möglich
- Praktiken
- präzise
- vorhergesagt
- Geschenke
- in erster Linie
- Probleme
- Prozessdefinierung
- anpassen
- Verarbeitung
- produziert
- Produkt
- Profis
- Programmierung
- Programme
- Projekt
- Projekte
- Die Förderung der
- ordnungsgemäße
- die
- bietet
- Zweck
- F&A
- Qualität
- Fragen
- schnell
- Angebot
- Bereich
- schnell
- schnell
- RARE
- realen Welt
- Echtzeit
- realistisch
- Versöhnung
- Aufzeichnungen
- Veteran
- Regression
- regulär
- regelmäßig
- Release
- relevant
- verlassen
- wiederholt
- WIEDERHOLT
- ersetzen
- repliziert
- berichten
- Berichtet
- Reporting
- Meldungen
- vertreten
- representiert
- erfordern
- falls angefordert
- Voraussetzungen:
- erfordert
- Downloads
- für ihren Verlust verantwortlich.
- Folge
- Die Ergebnisse
- wiederverwendbar
- zeigen
- Führen Sie
- Skalierbarkeit
- Szenarien
- Planung
- Skripte
- Auswahl
- kompensieren
- Setup
- mehrere
- sollte
- Konzerte
- signifikant
- bedeutend
- Umstände
- Größe
- Fähigkeiten
- So
- Software
- Software-Entwicklung
- Quelle
- Quellen
- besondere
- spezialisiert
- spezifisch
- Geschwindigkeit
- verbrachte
- Personaldiensleister
- Stufen
- Stakeholder
- Anfang
- begonnen
- Bundesstaat
- Status
- Immer noch
- storage
- gelagert
- Strategien
- Strom
- strukturierte
- Studio Adressen
- Erfolg
- Erfolgreich
- so
- geeignet
- Suite
- Oberfläche
- Synchronisation
- Tabelle
- nimmt
- Target
- Ziele
- Aufgabe
- Team
- Teams
- Technische
- Techniken
- Technologies
- Test
- Testen
- Tests
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- ihr
- deswegen
- Diese
- Durch
- Zeit
- Zeitaufwendig
- zu
- heute
- auch
- Werkzeug
- Werkzeuge
- traditionell
- trainiert
- Ausbildung
- Transformieren
- Transformation
- Transformationen
- verwandelt
- Transformieren
- Trends
- Typen
- einzigartiges
- -
- Mitglied
- Nutzer
- gewöhnlich
- validiert
- Bestätigung
- wertvoll
- Wert
- Vielfalt
- verschiedene
- riesig
- Verkäufer
- Anbieter
- Verification
- verified
- überprüfen
- Video
- Anzeigen
- lebenswichtig
- vs
- Warehouse
- Netz
- Web-Entwicklung
- Was
- ob
- welche
- WHO
- breit
- weit
- werden wir
- mit
- .
- ohne
- Workflows
- arbeiten,
- würde
- XML
- Ihr
- Zephyrnet











