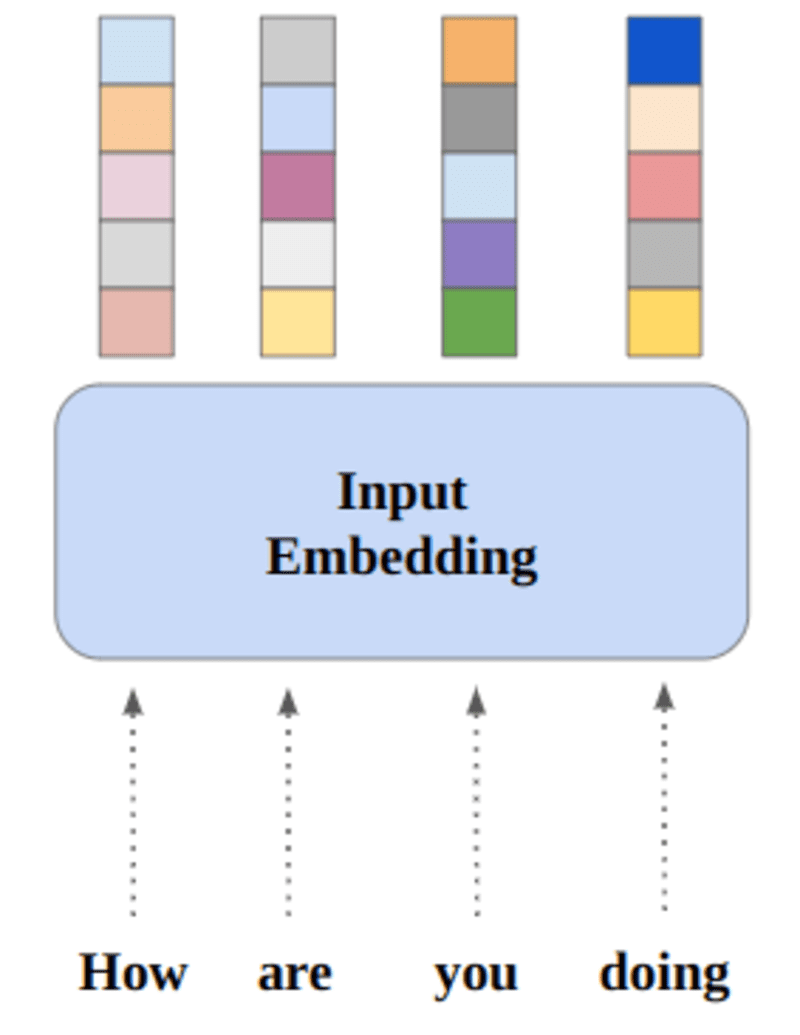
Neuronale Netze lernen durch Zahlen, sodass jedes Wort Vektoren zugeordnet wird, um ein bestimmtes Wort darzustellen. Die Einbettungsschicht kann man sich als Nachschlagetabelle vorstellen, die Worteinbettungen speichert und sie unter Verwendung von Indizes abruft.
Wörter, die dieselbe Bedeutung haben, sind in Bezug auf euklidische Distanz/Kosinus-Ähnlichkeit ähnlich. Beispielsweise sind in der folgenden Wortdarstellung „Samstag“, „Sonntag“ und „Montag“ mit demselben Konzept verbunden, sodass wir sehen können, dass die Wörter ähnlich resultieren.

Die Bestimmung der Position des Wortes Warum müssen wir die Position des Wortes bestimmen? Da der Transformer-Encoder keine Wiederholung wie rekurrente neuronale Netze hat, müssen wir einige Informationen über die Positionen in die Eingabeeinbettungen hinzufügen. Dies erfolgt über eine Positionscodierung. Die Autoren des Papiers verwendeten die folgenden Funktionen, um die Position eines Wortes zu modellieren.
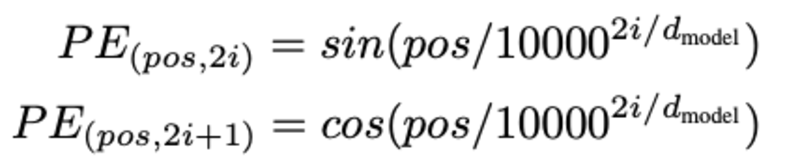
Wir werden versuchen, die Positionscodierung zu erklären.
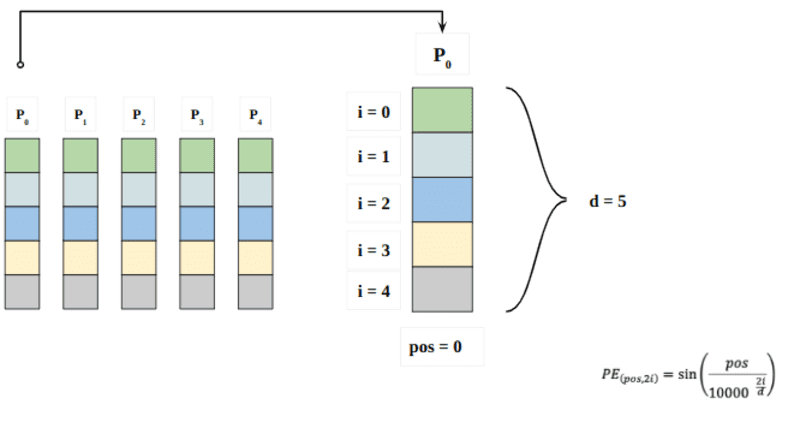
Hier bezieht sich „pos“ auf die Position des „Wortes“ in der Sequenz. P0 bezieht sich auf die Positionseinbettung des ersten Wortes; „d“ bedeutet die Größe der Wort-/Token-Einbettung. In diesem Beispiel ist d=5. Schließlich bezieht sich „i“ auf jede der 5 einzelnen Dimensionen der Einbettung (dh 0, 1,2,3,4)
Wenn „i“ in der obigen Gleichung variiert, erhalten Sie eine Reihe von Kurven mit unterschiedlichen Frequenzen. Ablesen der Positionseinbettungswerte gegen verschiedene Frequenzen, was unterschiedliche Werte bei verschiedenen Einbettungsdimensionen für P0 und P4 ergibt.
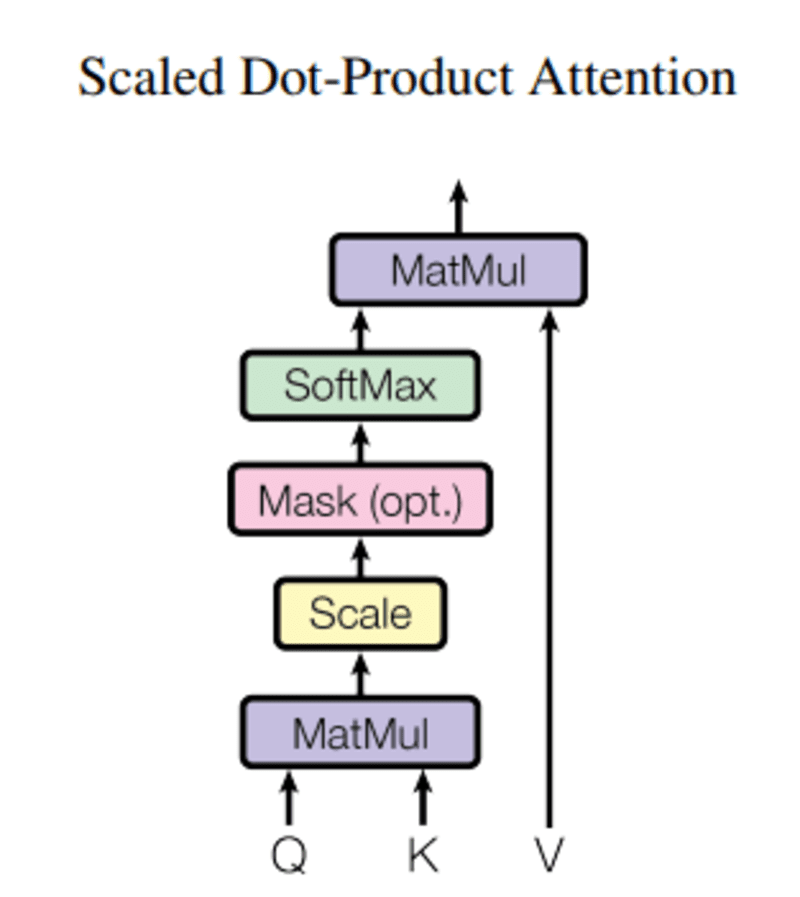
In diesem Abfrage, Q stellt ein Vektorwort dar, das Schlüssel k sind alle anderen Wörter im Satz, und Wert v stellt den Vektor des Wortes dar.
Der Zweck der Aufmerksamkeit besteht darin, die Bedeutung des Schlüsselbegriffs im Vergleich zum Suchbegriff zu berechnen, der sich auf dieselbe Person/Sache oder denselben Begriff bezieht.
In unserem Fall ist V gleich Q.
Der Aufmerksamkeitsmechanismus gibt uns die Bedeutung des Wortes in einem Satz.
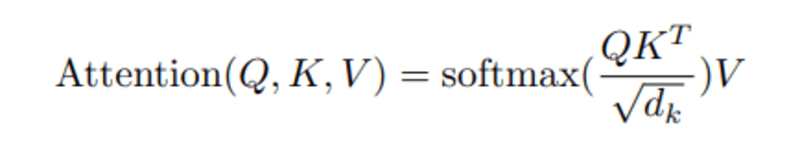
Wenn wir das normalisierte Punktprodukt zwischen der Abfrage und den Schlüsseln berechnen, erhalten wir einen Tensor, der die relative Bedeutung jedes anderen Wortes für die Abfrage darstellt.
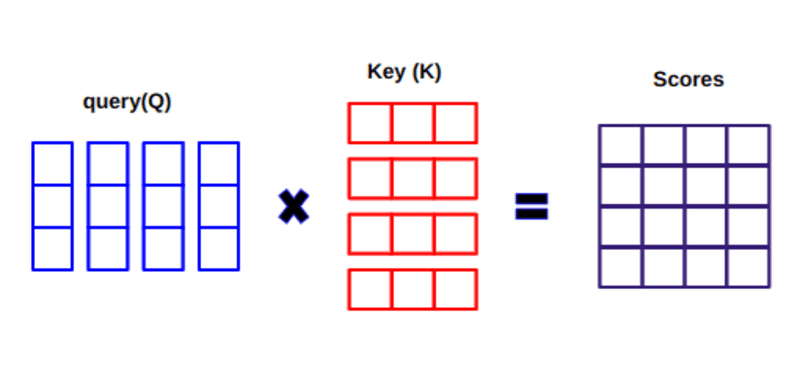
Bei der Berechnung des Punktprodukts zwischen Q und KT versuchen wir zu schätzen, wie die Vektoren (dh Wörter zwischen Abfrage und Schlüsseln) ausgerichtet sind, und geben eine Gewichtung für jedes Wort im Satz zurück.
Dann normalisieren wir das Ergebnis zum Quadrat von d_k und Die Softmax-Funktion normalisiert die Terme und skaliert sie zwischen 0 und 1 neu.
Schließlich multiplizieren wir das Ergebnis (dh Gewichte) mit dem Wert (dh alle Wörter), um die Bedeutung nicht relevanter Wörter zu reduzieren und uns nur auf die wichtigsten Wörter zu konzentrieren.
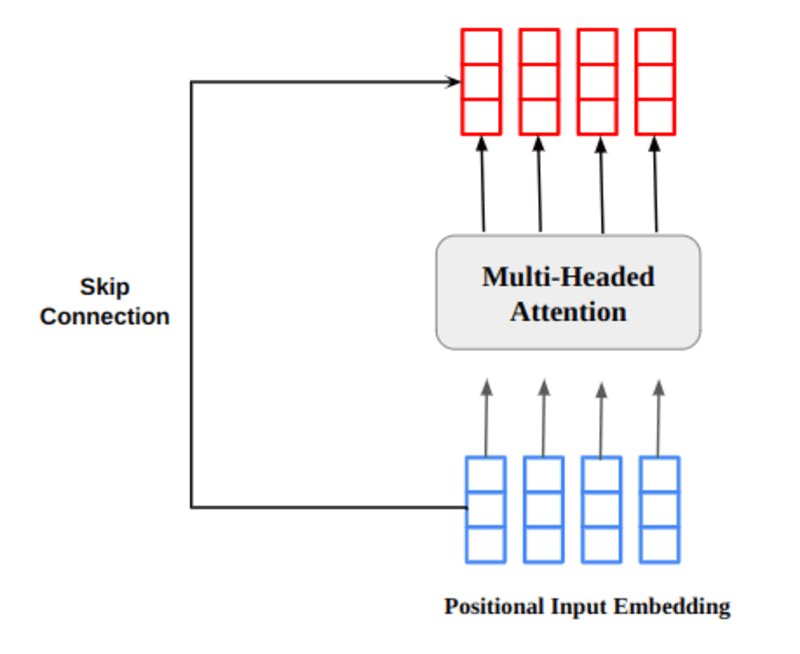
Der mehrköpfige Aufmerksamkeitsausgabevektor wird zu der ursprünglichen positionellen Eingabeeinbettung hinzugefügt. Dies wird als Restverbindung/Sprungverbindung bezeichnet. Die Ausgabe der Restverbindung durchläuft die Schichtnormalisierung. Die normalisierte Restausgabe wird zur weiteren Verarbeitung durch ein punktweises Feed-Forward-Netzwerk geleitet.
Die Maske ist eine Matrix, die dieselbe Größe wie die Aufmerksamkeitswerte hat und mit Werten von Nullen und negativen Unendlichkeiten gefüllt ist.
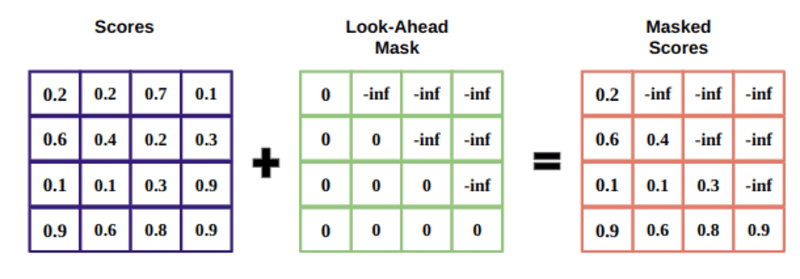
Der Grund für die Maske ist, dass die negativen Unendlichkeiten Null werden, sobald Sie den Softmax der maskierten Punktzahlen nehmen, wodurch null Aufmerksamkeitspunktzahlen für zukünftige Token übrig bleiben.
Dies weist das Modell an, sich nicht auf diese Wörter zu konzentrieren.
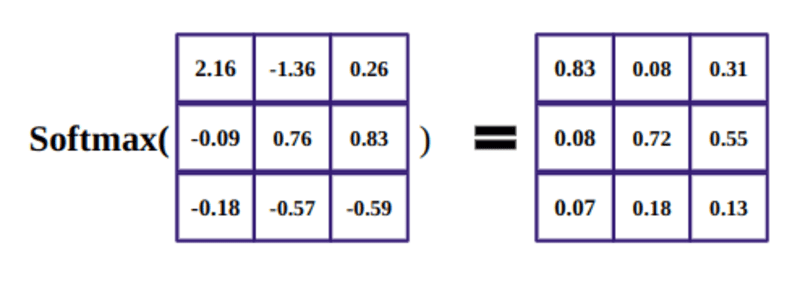
Der Zweck der Softmax-Funktion besteht darin, reelle Zahlen (positiv und negativ) zu erfassen und sie in positive Zahlen umzuwandeln, die sich zu 1 summieren.
Ravikumar Naduwin ist damit beschäftigt, NLP-Aufgaben mit PyTorch zu erstellen und zu verstehen.
Original. Mit Genehmigung erneut veröffentlicht.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://www.kdnuggets.com/2023/01/concepts-know-getting-transformer.html?utm_source=rss&utm_medium=rss&utm_campaign=concepts-you-should-know-before-getting-into-transformer
- 1
- a
- Über uns
- oben
- hinzugefügt
- gegen
- ausgerichtet
- Alle
- und
- damit verbundenen
- Aufmerksamkeit
- Autoren
- weil
- Bevor
- unten
- zwischen
- Building
- Haufen
- namens
- Häuser
- Menu
- verglichen
- Berechnen
- Computing
- konzept
- Konzepte
- Verbindung
- Bestimmen
- Festlegung
- anders
- Größe
- DOT
- jeder
- schätzen
- Beispiel
- Erklären
- gefüllt
- Endlich
- Vorname
- Setzen Sie mit Achtsamkeit
- Folgende
- Funktion
- Funktionen
- weiter
- Zukunft
- bekommen
- bekommen
- GitHub
- gibt
- Unterstützung
- Goes
- greifen
- Ultraschall
- HTTPS
- Bedeutung
- wichtig
- in
- Indizes
- Krankengymnastik
- Information
- Eingabe
- KDnuggets
- Wesentliche
- Tasten
- Wissen
- Schicht
- LERNEN
- Verlassen
- Nachschlagen
- Maske"
- Matrix
- Bedeutung
- Mittel
- Mechanismus
- Modell
- vor allem warme
- Need
- Negativ
- Netzwerk
- Netzwerke
- Neural
- Neuronale Netze
- Nlp
- Zahlen
- Original
- Andere
- Papier
- besondere
- Bestanden
- Erlaubnis
- Plato
- Datenintelligenz von Plato
- PlatoData
- Position
- für einige Positionen
- positiv
- Verarbeitung
- Produkt
- Zweck
- setzen
- Pytorch
- Lesebrillen
- echt
- Grund
- Wiederholung
- Veteran
- bezieht sich
- bezogene
- vertreten
- Darstellung
- representiert
- Folge
- was zu
- Rückkehr
- gleich
- Satz
- Reihenfolge
- sollte
- ähnlich
- Größe
- So
- einige
- Kariert
- Läden
- Tabelle
- Nehmen
- und Aufgaben
- erzählt
- AGB
- Das
- dachte
- Durch
- zu
- Tokens
- Transformer
- WENDE
- Verständnis
- us
- Wert
- Werte
- Gewicht
- welche
- werden wir
- Word
- Worte
- Zephyrnet
- Null