Heute nutzen Hunderttausende von Kunden Data Lakes für Analysen und maschinelles Lernen. Dateningenieure müssen diese Daten jedoch bereinigen und aufbereiten, bevor sie verwendet werden können. Die zugrunde liegenden Daten müssen genau und aktuell sein, damit der Kunde sichere Geschäftsentscheidungen treffen kann. Andernfalls verlieren Datenkonsumenten das Vertrauen in die Daten und treffen suboptimale oder falsche Entscheidungen. Es ist eine gängige Aufgabe für Dateningenieure zu bewerten, ob die Daten korrekt und aktuell sind oder nicht. Heute gibt es verschiedene Datenqualitätstools. Gängige Datenqualitätstools erfordern jedoch normalerweise manuelle Prozesse zur Überwachung der Datenqualität.
AWS Glue Data Quality ist eine Vorschaufunktion von AWS-Kleber das die Datenqualität misst und überwacht Amazon Simple Storage-Service (Amazon S3) Data Lakes und in AWS Glue-Aufträgen zum Extrahieren, Transformieren und Laden (ETL). Dies ist eine offene Vorschaufunktion, daher ist sie in Ihrem Konto bereits aktiviert verfügbaren Regionen. Sie können die Datenqualitätsprüfungen in der AWS Glue Studio-Konsole einfach definieren und messen, ohne Codes schreiben zu müssen. Es vereinfacht Ihre Erfahrung bei der Verwaltung der Datenqualität.
Dieser Beitrag ist Teil 2 einer Serie mit vier Beiträgen, in der erklärt wird, wie AWS Glue Data Quality funktioniert. Schauen Sie sich den vorherigen Beitrag in dieser Serie an:
In diesem Beitrag zeigen wir, wie Sie einen AWS Glue-Job erstellen, der die Datenqualität einer Datenpipeline misst und überwacht. Wir zeigen auch, wie auf der Grundlage der Datenqualitätsergebnisse Maßnahmen ergriffen werden können.
Lösungsüberblick
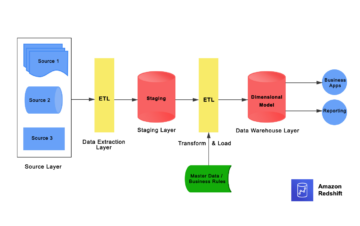
Betrachten wir einen beispielhaften Anwendungsfall, in dem ein Dateningenieur eine Datenpipeline erstellen muss, um die Daten aus einer Rohzone in eine kuratierte Zone in einem Data Lake aufzunehmen. Als Data Engineer ist eine Ihrer Hauptaufgaben – neben dem Extrahieren, Transformieren und Laden von Daten – die Validierung der Datenqualität. Durch die frühzeitige Identifizierung von Datenqualitätsproblemen können Sie verhindern, dass fehlerhafte Daten in der kuratierten Zone abgelegt werden, und mühsame Vorfälle mit Datenkorruption vermeiden.
In diesem Beitrag erfahren Sie, wie Sie die Einrichtung ganz einfach vornehmen eingebaut und Original Datenvalidierungsprüfungen in Ihrem AWS Glue-Auftrag, um zu verhindern, dass fehlerhafte Daten die nachgelagerten hochwertigen Daten beschädigen.
Der für diesen Beitrag verwendete Datensatz ist synthetisch generiert; Der folgende Screenshot zeigt ein Beispiel der Daten.

Einrichten von Ressourcen mit AWS CloudFormation
Dieser Beitrag enthält eine AWS CloudFormation Vorlage für eine schnelle Einrichtung. Sie können es überprüfen und an Ihre Bedürfnisse anpassen.
Die CloudFormation-Vorlage generiert die folgenden Ressourcen:
- Ein Amazon Simple Storage Service (Amazon S3)-Bucket (
gluedataqualitystudio-*). - Die folgenden Präfixe und Objekte im S3-Bucket:
datalake/raw/customer/customer.csvdatalake/curated/customer/scripts/sparkHistoryLogs/temporary/
- AWS Identity and Access Management and (IAM) Benutzer, Rollen und Richtlinien. Die IAM-Rolle (
GlueDataQualityStudio-*) hat die Berechtigung zum Lesen und Schreiben aus dem S3-Bucket. - AWS Lambda Funktionen und IAM-Richtlinien, die von diesen Funktionen benötigt werden, um diesen Stack zu erstellen und zu löschen.
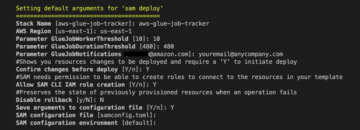
Führen Sie die folgenden Schritte aus, um Ihre Ressourcen zu erstellen:
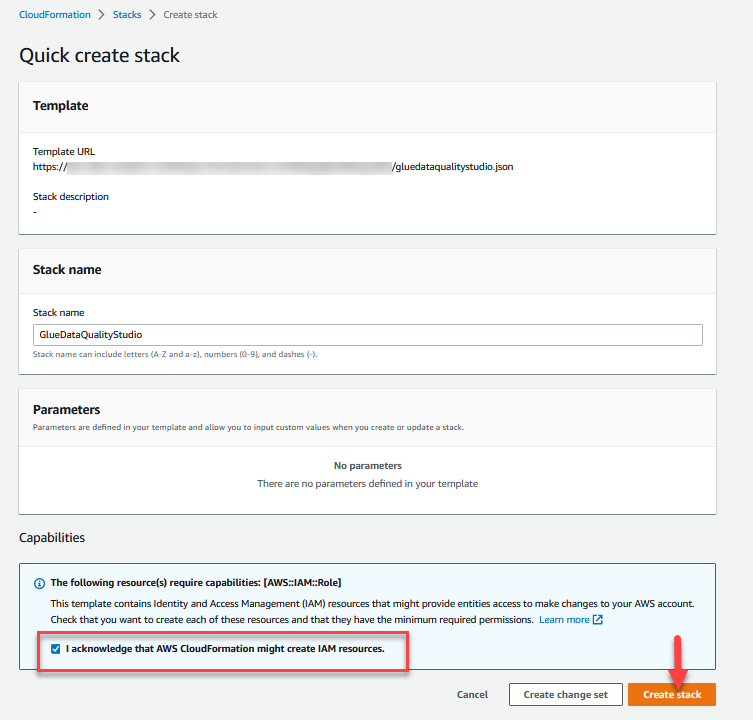
- Melden Sie sich bei der an AWS CloudFormation-Konsole der
us-east-1Region. - Auswählen
Stack starten:

- Auswählen Ich erkenne an, dass AWS CloudFormation möglicherweise IAM-Ressourcen erstellt.
- Auswählen Stapel erstellen und warten Sie, bis der Stack-Erstellungsschritt abgeschlossen ist.
Implementieren Sie die Lösung
Führen Sie die folgenden Schritte aus, um mit der Konfiguration Ihrer Lösung zu beginnen:
- Auf dem AWS Glue Studio-Konsole, wählen Jobs im Navigationsbereich.
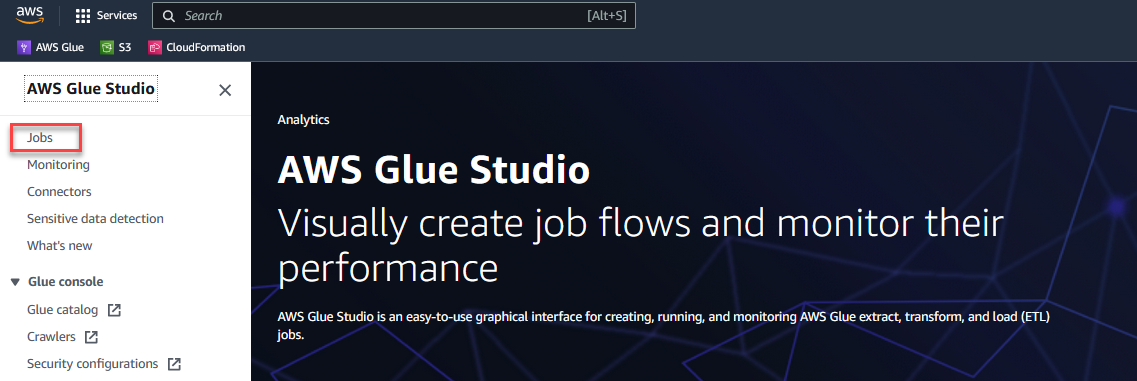
- Auswählen Visuell mit einer leeren Leinwand und wählen Sie Erstellen.
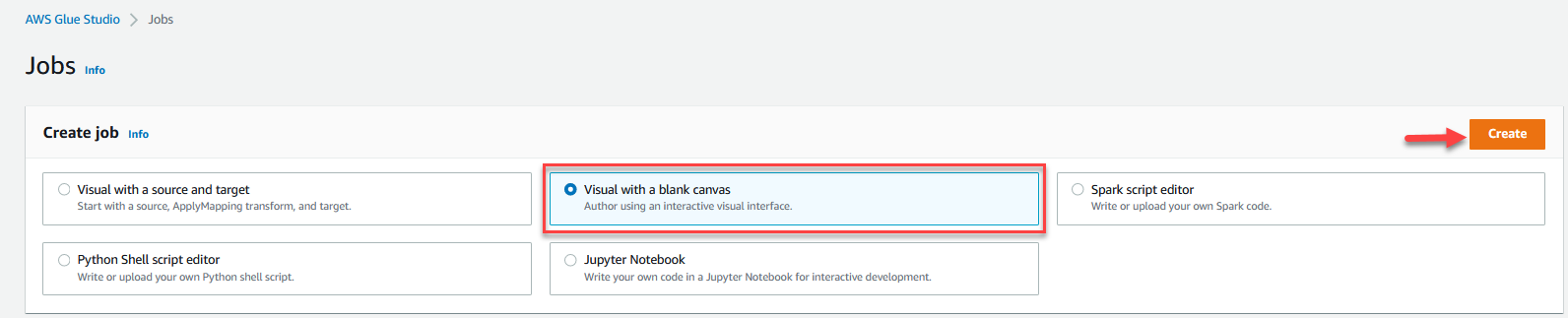
- Wähle die Job Details Registerkarte, um den Job zu konfigurieren.
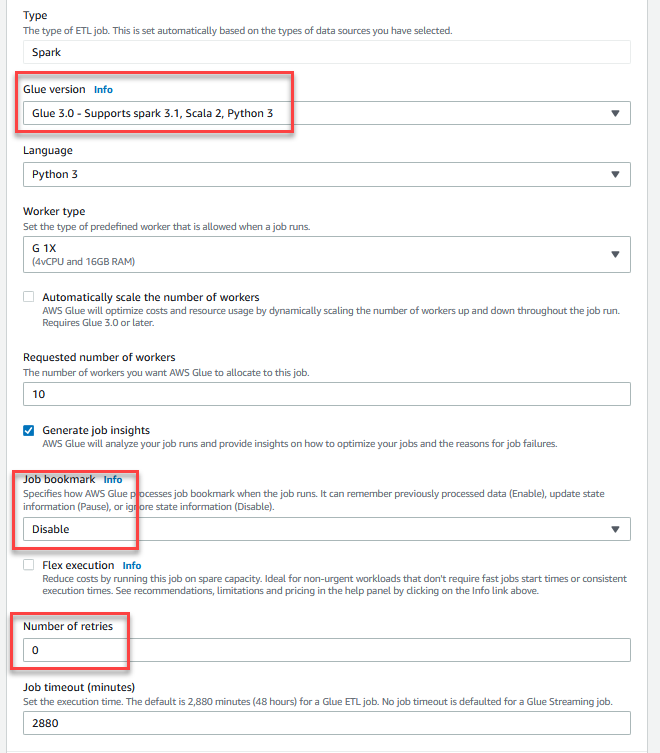
- Aussichten für Name und Vorname, eingeben
GlueDataQualityStudio. - Aussichten für IAM-Rolle, wählen Sie die Rolle beginnend mit
GlueDataQualityStudio-*. - Aussichten für Klebeversion, wählen Kleber 3.0.
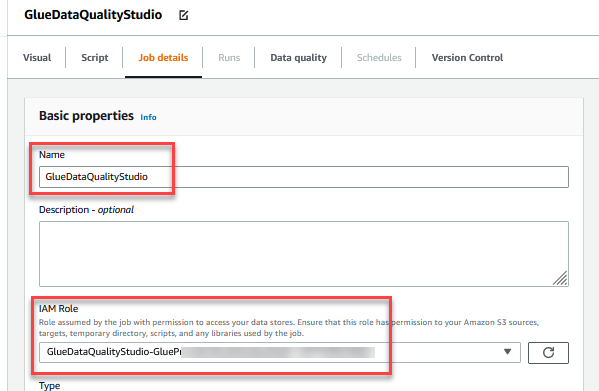
- Aussichten für Job Lesezeichen, wählen Deaktivieren. Dadurch können Sie diesen Job mehrmals mit demselben Eingabe-Dataset ausführen.
- Aussichten für Anzahl der Wiederholungen, eingeben
0.
- Im Erweiterte Eigenschaften Geben Sie im Abschnitt den S3-Bucket an, der von der CloudFormation-Vorlage erstellt wurde (beginnend mit
gluedataqualitystudio-*).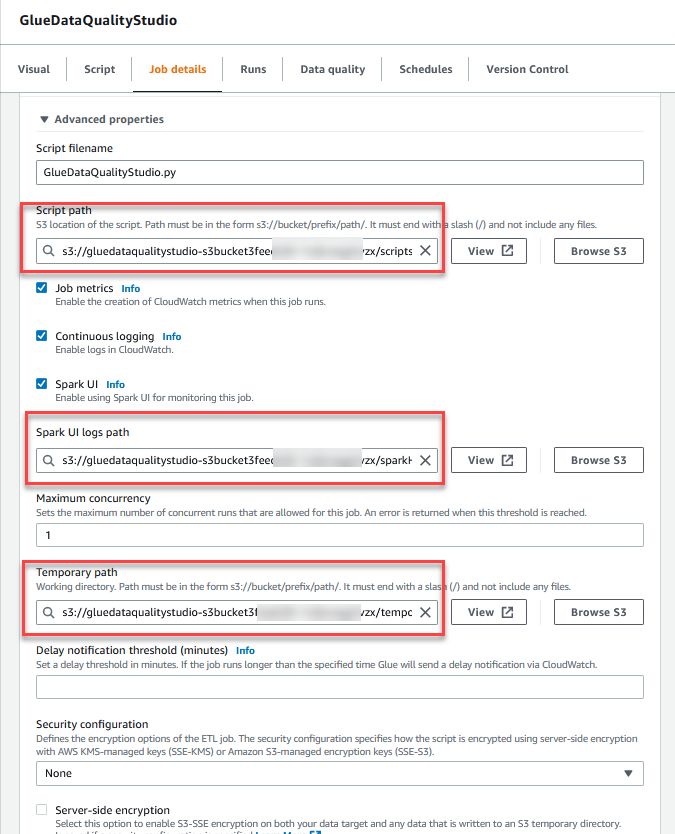
- Auswählen
Speichern.
- Nachdem der Auftrag gespeichert wurde, wählen Sie die visuell Registerkarte und auf der Quelle Menü, wählen Sie Amazon S3.
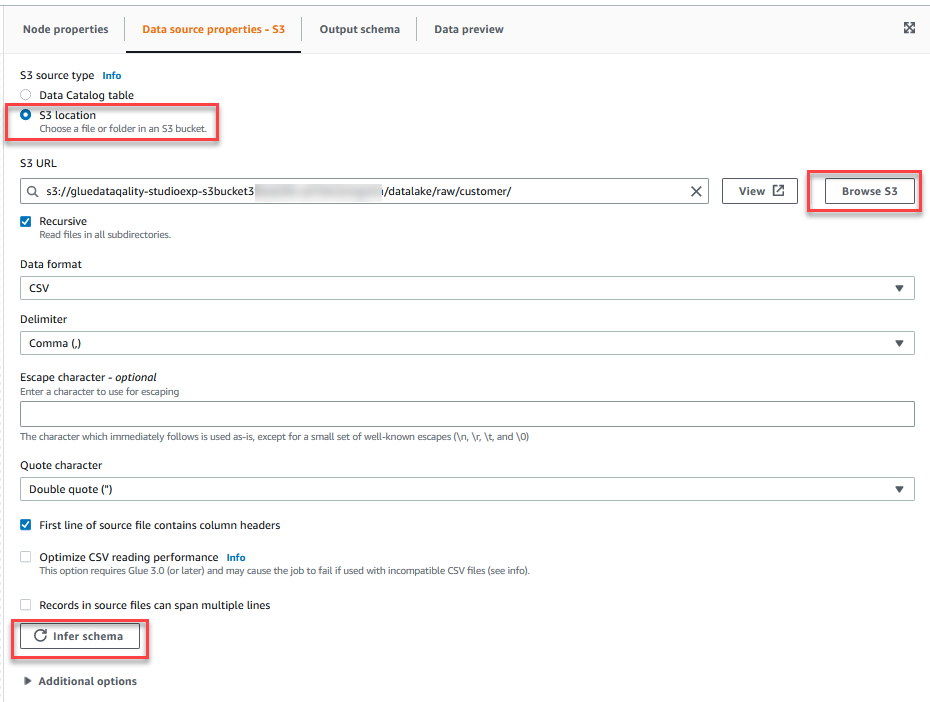
- Auf dem Datenquelleneigenschaften - S3 Registerkarte, für S3-QuellentypWählen S3 Standort.
- Auswählen
Durchsuchen Sie S3 und navigieren Sie zu Präfix
/datalake/raw/customer/im S3-Bucket beginnend mitgluedataqualitystudio-*. - Auswählen
Schema ableiten.
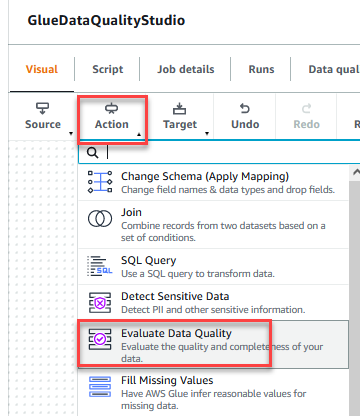
- Auf dem Action Menü, wählen Sie Bewerten Sie die Datenqualität.
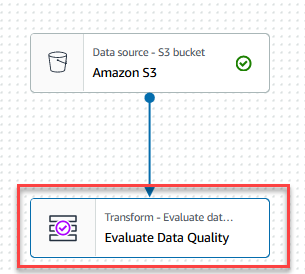
- Wähle die Bewerten Sie die Datenqualität Knoten.
Auf dem Transformieren können Sie nun mit dem Erstellen von Datenqualitätsregeln beginnen. Die erste Regel, die Sie erstellen, besteht darin, zu prüfen, obCustomer_IDist eindeutig und nicht null mit derisPrimaryKeyRegel. - Auf dem Regeltypen Registerkarte der DQDL-Regelgenerator, suchen Sie nach
isprimarykeyund wählen Sie das Pluszeichen.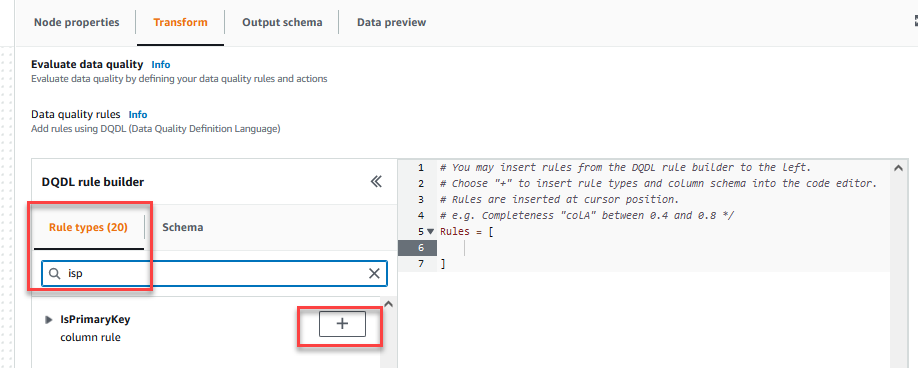
- Auf dem Schema Registerkarte der DQDL-Regelgenerator, wählen Sie das Pluszeichen neben aus
Customer_ID. - Löschen Sie im Regeleditor
id.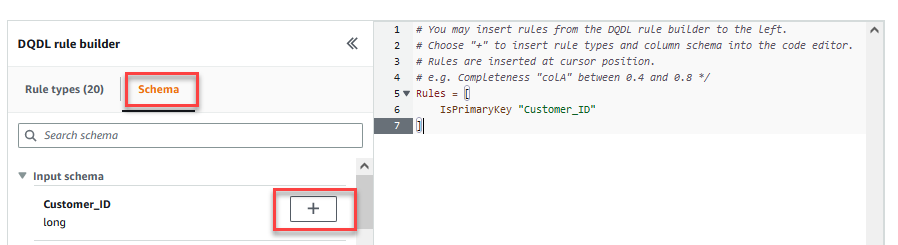
Die nächste Regel, die wir hinzufügen, prüft, ob dieFirst_NameSpaltenwert ist für alle Zeilen vorhanden. - Sie können die Datenqualitätsregeln auch direkt im Regeleditor eingeben. Fügen Sie ein Komma (,) hinzu und geben Sie ein
IsComplete "First_Name",nach der ersten Regel.
Als Nächstes fügen Sie eine benutzerdefinierte Regel hinzu, um zu überprüfen, dass keine Zeile ohne existiertTelephoneorEmail. - Geben Sie die folgende benutzerdefinierte Regel in den Regeleditor ein:

Die Funktion „Datenqualität bewerten“ bietet Aktionen zum Verwalten des Ergebnisses eines Jobs basierend auf den Ergebnissen der Jobqualität. - Wählen Sie für diesen Beitrag Job fehlschlagen, wenn die Datenqualität fehlschlägt und wählen Sie Job fehlschlagen, ohne das Ziel zu laden technische Daten Aktionen. In dem Ausgabeeinstellung für die Datenqualität Wählen Sie im Abschnitt Durchsuchen Sie S3 und navigieren Sie zu Präfix
dqresultsim S3-Bucket beginnend mitgluedataqualitystudio-*.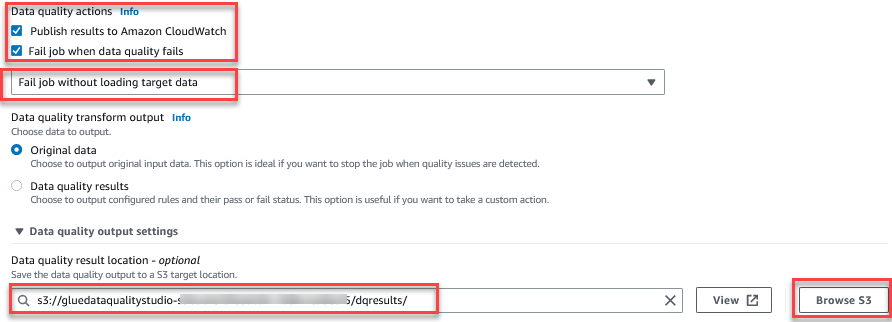
- Auf dem Target Menü, wählen Sie Amazon S3.
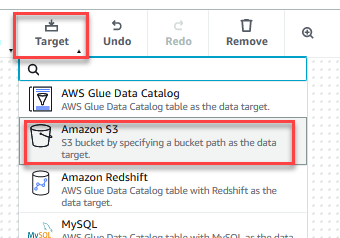
- Wähle die Datenziel – S3-Bucket Knoten.
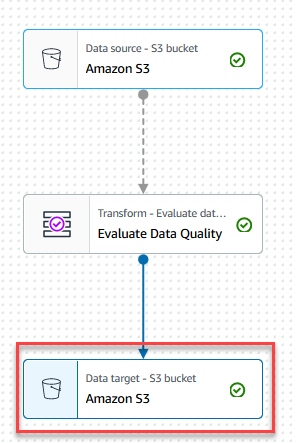
- Auf dem Datenzieleigenschaften - S3 Registerkarte, für Format, wählen ParkettUnd für Komprimierungsart, wählen Bissig.
- Aussichten für S3-Zielort, wählen Durchsuchen Sie S3 und navigieren Sie zum Präfix
/datalake/curated/customer/im S3-Bucket beginnend mitgluedataqualitystudio-*.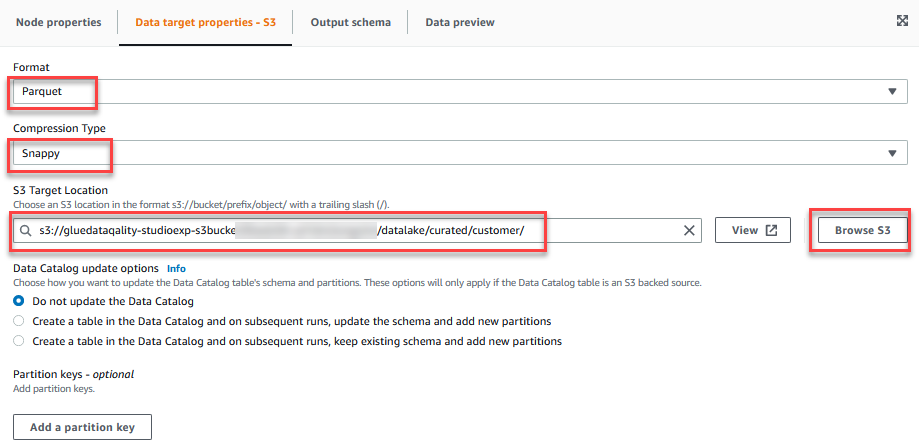
- Auswählen
Speichern, Dann wählen Führen Sie.
 Sie können die Jobausführungsdetails auf der Registerkarte Ausführungen anzeigen. In unserem Beispiel schlägt der Job mit der Fehlermeldung „AssertionError: The job failed due to failed DQ rules for node: .“
Sie können die Jobausführungsdetails auf der Registerkarte Ausführungen anzeigen. In unserem Beispiel schlägt der Job mit der Fehlermeldung „AssertionError: The job failed due to failed DQ rules for node: .“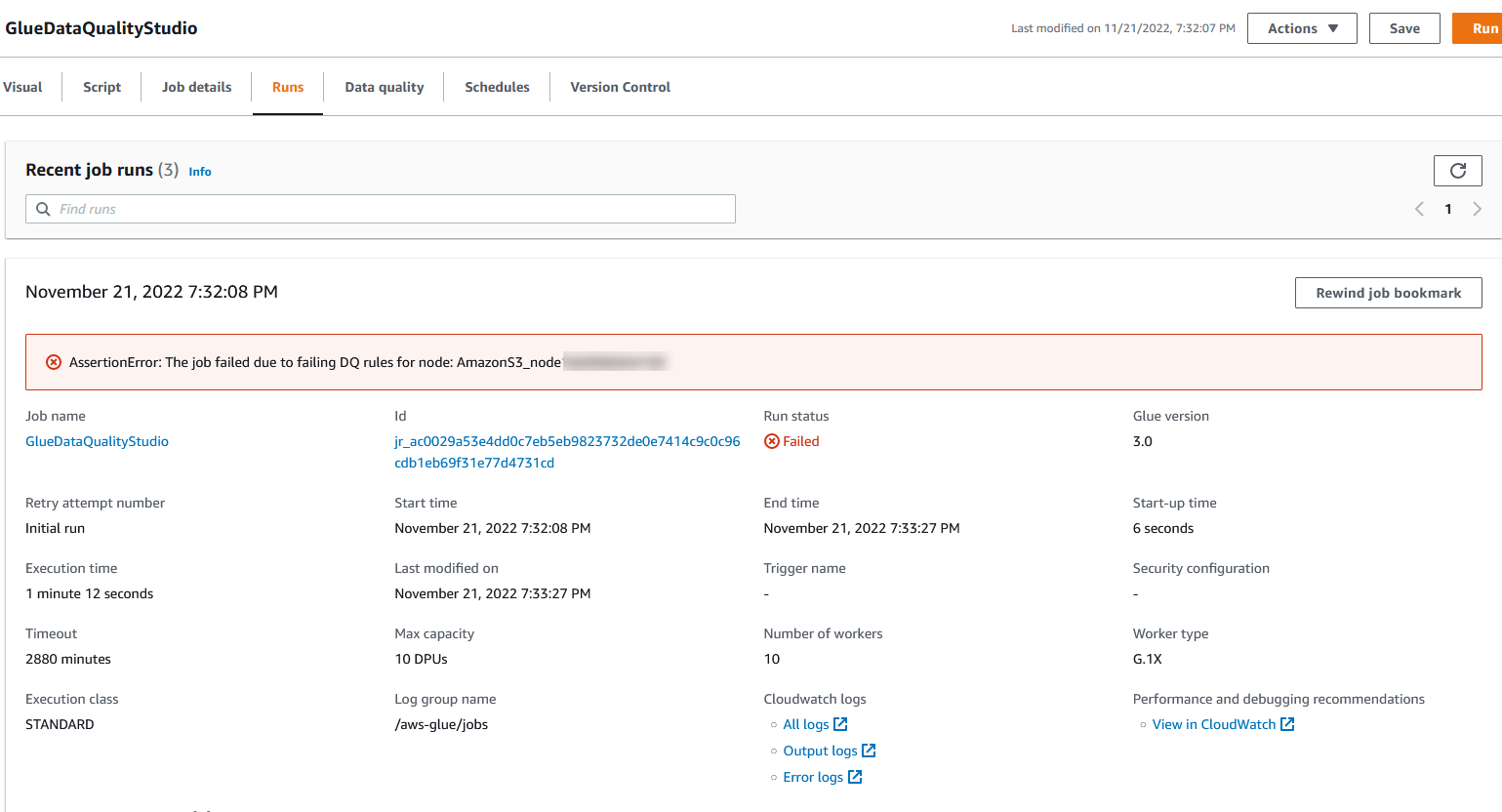 Sie können das Datenqualitätsergebnis auf der Registerkarte Datenqualität überprüfen. In unserem Beispiel ist die benutzerdefinierte Datenqualitätsvalidierung fehlgeschlagen, weil eine der Zeilen im Dataset keine hatte
Sie können das Datenqualitätsergebnis auf der Registerkarte Datenqualität überprüfen. In unserem Beispiel ist die benutzerdefinierte Datenqualitätsvalidierung fehlgeschlagen, weil eine der Zeilen im Dataset keine hatte TelephoneorEmailWert. Datenqualitätsergebnisse auswerten wird auch im JSON-Format in den S3-Bucket geschrieben, basierend auf dem Datenqualitätsergebnis-Positionsparameter des Knotens.
Datenqualitätsergebnisse auswerten wird auch im JSON-Format in den S3-Bucket geschrieben, basierend auf dem Datenqualitätsergebnis-Positionsparameter des Knotens. - Navigieren
dqresultsPräfix unter dem S3-Bucket beginnendgluedataqualitystudio-*. Sie werden sehen, dass das Datenqualitätsergebnis nach Datum partitioniert ist.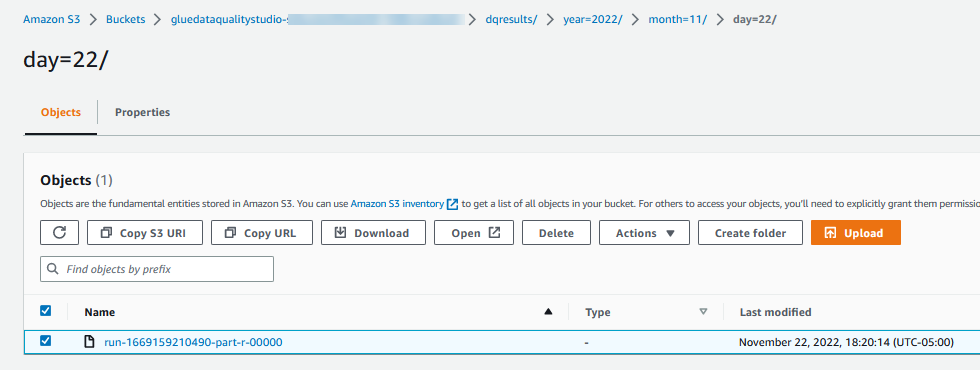
Das Folgende ist die Ausgabe der JSON-Datei. Sie können diese Dateiausgabe verwenden, um benutzerdefinierte Dashboards zur Datenqualitätsvisualisierung zu erstellen.

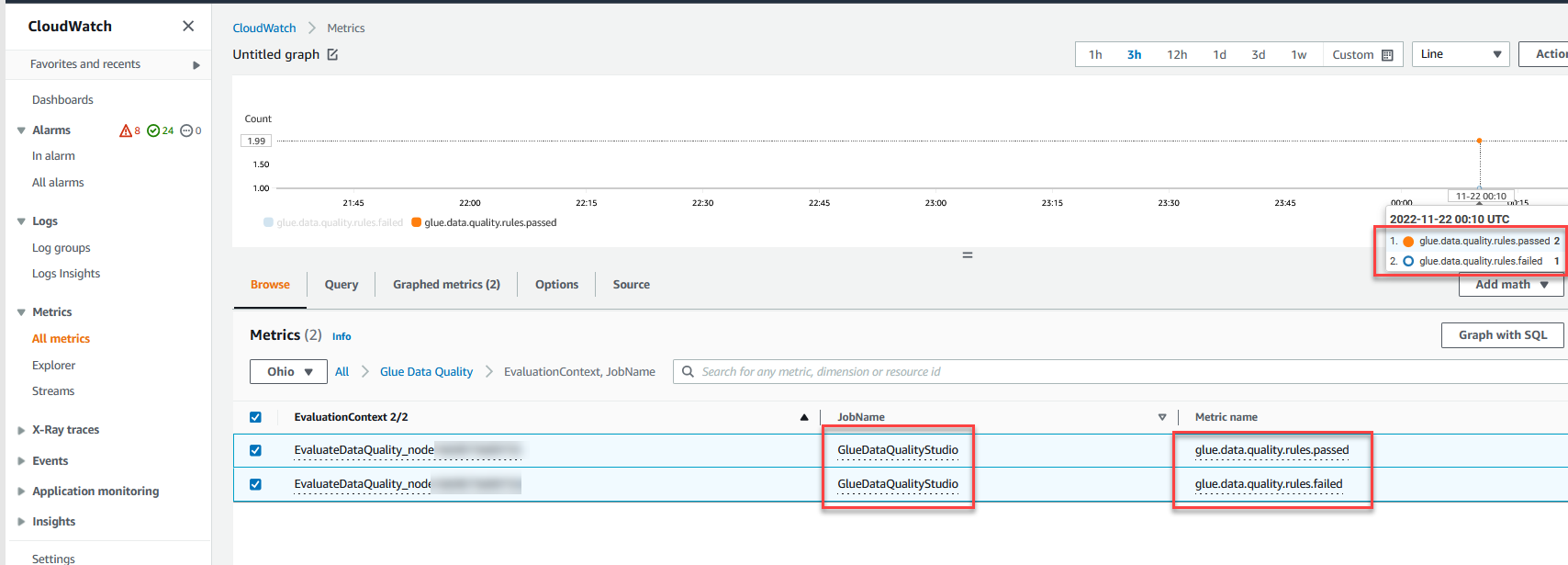
Sie können die auch überwachen Bewerten Sie die Datenqualität Knoten durch Amazon CloudWatch Metriken und stellen Sie Alarme ein, um Benachrichtigungen über Datenqualitätsergebnisse zu senden. Weitere Informationen zum Einrichten von CloudWatch-Alarmen finden Sie unter Verwenden von Amazon CloudWatch-Alarmen.
Aufräumen
Um zukünftige Gebühren zu vermeiden und ungenutzte Rollen und Richtlinien zu bereinigen, löschen Sie die von Ihnen erstellten Ressourcen:
- Löschen Sie die
GlueDataQualityStudioJob, den Sie im Rahmen dieses Beitrags erstellt haben. - Löschen Sie in der AWS CloudFormation-Konsole die
GlueDataQualityStudioStapel.
Zusammenfassung
AWS Glue Data Quality bietet eine einfache Möglichkeit, die Datenqualität Ihrer ETL-Pipeline zu messen und zu überwachen. In diesem Beitrag haben Sie gelernt, wie Sie auf der Grundlage der Datenqualitätsergebnisse die erforderlichen Maßnahmen ergreifen, was Ihnen hilft, hohe Datenstandards aufrechtzuerhalten und sichere Geschäftsentscheidungen zu treffen.
Um mehr über AWS Glue Data Quality zu erfahren, sehen Sie sich die Dokumentation an:
Über die Autoren
 Deenbandhu Prasad ist Senior Analytics Specialist bei AWS und spezialisiert auf Big-Data-Services. Er unterstützt Kunden leidenschaftlich gerne beim Aufbau einer modernen Datenarchitektur in der AWS Cloud. Er hat Kunden jeder Größe bei der Implementierung von Datenmanagement-, Data Warehouse- und Data Lake-Lösungen unterstützt.
Deenbandhu Prasad ist Senior Analytics Specialist bei AWS und spezialisiert auf Big-Data-Services. Er unterstützt Kunden leidenschaftlich gerne beim Aufbau einer modernen Datenarchitektur in der AWS Cloud. Er hat Kunden jeder Größe bei der Implementierung von Datenmanagement-, Data Warehouse- und Data Lake-Lösungen unterstützt.
 Yannis Mentekidis ist Senior Software Development Engineer im AWS Glue-Team.
Yannis Mentekidis ist Senior Software Development Engineer im AWS Glue-Team.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/getting-started-with-aws-glue-data-quality-for-etl-pipelines/
- 1
- 100
- 7
- a
- Über uns
- Zugang
- Konto
- genau
- anerkennen
- Action
- Aktionen
- Nach der
- Alle
- erlaubt
- bereits
- Amazon
- Analytik
- und
- Architektur
- AWS
- AWS CloudFormation
- AWS-Kleber
- Badewanne
- schlechte Daten
- basierend
- weil
- Bevor
- Big
- Big Data
- bauen
- Building
- Geschäft
- Häuser
- Gebühren
- aus der Ferne überprüfen
- Schecks
- Auswählen
- Cloud
- Kolonne
- gemeinsam
- abschließen
- zuversichtlich
- Geht davon
- Konsul (Console)
- KUNDEN
- Korruption
- erstellen
- erstellt
- Schaffung
- kuratiert
- Original
- Kunde
- Kunden
- anpassen
- technische Daten
- Datensee
- Datenmanagement
- Datum
- Entscheidungen
- Details
- Entwicklung
- Direkt
- Dokumentation
- leicht
- Herausgeber
- Ingenieur
- Ingenieure
- Enter
- Fehler
- Äther (ETH)
- bewerten
- Beispiel
- existiert
- ERFAHRUNGEN
- Erklären
- Extrakt
- Gescheitert
- scheitert
- Merkmal
- Reichen Sie das
- Vorname
- Folgende
- Format
- für
- Funktionen
- Zukunft
- erzeugt
- erzeugt
- bekommen
- dazu beigetragen,
- Unternehmen
- hilft
- High
- hochwertige
- Ultraschall
- Hilfe
- aber
- HTML
- HTTPS
- hunderte
- Identifizierung
- Identitätsschutz
- implementieren
- in
- Dazu gehören
- Eingabe
- Probleme
- IT
- Job
- Jobs
- JSON
- Wesentliche
- See
- LERNEN
- gelernt
- lernen
- Belastung
- Laden
- Standorte
- verlieren
- Maschine
- Maschinelles Lernen
- halten
- um
- verwalten
- Management
- flächendeckende Gesundheitsprogramme
- manuell
- messen
- Maßnahmen
- MENÜ
- Nachricht
- Metrik
- könnte
- modern
- Überwachen
- Monitore
- mehr
- mehrere
- Navigieren
- Navigation
- notwendig,
- Bedürfnisse
- weiter
- Knoten
- Benachrichtigungen
- Objekte
- Angebote
- EINEM
- XNUMXh geöffnet
- Andernfalls
- Brot
- Parameter
- Teil
- leidenschaftlich
- Erlaubnis
- Pipeline
- Platzierung
- Plato
- Datenintelligenz von Plato
- PlatoData
- erfahren
- Politik durchzulesen
- Post
- Danach
- Gegenwart
- verhindern
- Vorspann
- früher
- primär
- anpassen
- immobilien
- die
- bietet
- Qualität
- Direkt
- Roh
- Lesen Sie mehr
- kürzlich
- Region
- erfordern
- falls angefordert
- Downloads
- Folge
- Die Ergebnisse
- Überprüfen
- Rollen
- Rollen
- REIHE
- Regel
- Ohne eine erfahrene Medienplanung zur Festlegung von Regeln und Strategien beschleunigt der programmatische Medieneinkauf einfach die Rate der verschwenderischen Ausgaben.
- Führen Sie
- gleich
- Suche
- Abschnitt
- Modellreihe
- Leistungen
- kompensieren
- Einstellung
- Setup
- erklären
- Konzerte
- Schild
- Einfacher
- Größen
- So
- Software
- Software-Entwicklung
- Lösung
- Lösungen
- Quelle
- Spezialist
- spezialisieren
- Stapel
- Normen
- Anfang
- begonnen
- Beginnen Sie
- Schritt
- Shritte
- storage
- Studio Adressen
- Anzug
- synthetisch
- Nehmen
- Target
- Aufgabe
- Team
- Vorlage
- Das
- Tausende
- Durch
- mal
- zu
- heute
- Werkzeuge
- Transformieren
- Transformieren
- Vertrauen
- für
- zugrunde liegen,
- einzigartiges
- ungenutzt
- -
- Anwendungsfall
- Nutzer
- gewöhnlich
- BESTÄTIGEN
- Bestätigung
- Wert
- verschiedene
- Anzeigen
- Visualisierung
- warten
- ob
- welche
- werden wir
- ohne
- Werk
- schreiben
- Schreiben
- geschrieben
- Ihr
- Zephyrnet