Jeden Tag verarbeiten und analysieren Amazon-Geräte Milliarden von Transaktionen von globalen Versand-, Bestands-, Kapazitäts-, Angebots-, Verkaufs-, Marketing-, Hersteller- und Kundendienstteams. Diese Daten werden bei der Beschaffung von Gerätebeständen verwendet, um die Anforderungen von Amazon-Kunden zu erfüllen. Da die Datenmengen Jahr für Jahr eine zweistellige prozentuale Wachstumsrate aufweisen und die COVID-Pandemie die globale Logistik im Jahr 2021 stören wird, wird es immer wichtiger, Daten zu skalieren und nahezu in Echtzeit zu generieren.
Dieser Beitrag zeigt Ihnen, wie wir zu einem serverlosen Data Lake auf AWS migriert sind, der Daten automatisch aus mehreren Quellen und unterschiedlichen Formaten nutzt. Darüber hinaus schuf es weitere Möglichkeiten für unsere Datenwissenschaftler und Ingenieure, KI- und maschinelle Lerndienste (ML) zu nutzen, um kontinuierlich Daten zuzuführen und zu analysieren.
Herausforderungen und Designprobleme
Unsere Legacy-Architektur wird hauptsächlich verwendet Amazon Elastic Compute-Cloud (Amazon EC2), um die Daten aus verschiedenen internen heterogenen Datenquellen und REST-APIs mit der Kombination von zu extrahieren Amazon Simple Storage-Service (Amazon S3), um die Daten zu laden und Amazon RedShift zur weiteren Analyse und Generierung der Bestellungen.
Wir haben festgestellt, dass dieser Ansatz zu einigen Mängeln führte und daher Verbesserungen in den folgenden Bereichen vorangetrieben hat:
- Entwicklergeschwindigkeit – Aufgrund der fehlenden Vereinheitlichung und Entdeckung von Schemas, die die Hauptgründe für Laufzeitfehler sind, verbrachten Entwickler oft Zeit damit, sich mit Betriebs- und Wartungsproblemen zu befassen.
- Skalierbarkeit – Die meisten dieser Datensätze werden weltweit geteilt. Daher müssen wir beim Abfragen der Daten die Skalierungsgrenzen einhalten.
- Minimale Wartung der Infrastruktur – Der aktuelle Prozess umfasst je nach Datenquelle mehrere Berechnungen. Daher ist die Reduzierung der Infrastrukturwartung von entscheidender Bedeutung.
- Reaktionsfähigkeit auf Datenquellenänderungen – Unser aktuelles System erhält Daten aus verschiedenen heterogenen Datenspeichern und Diensten. Alle Aktualisierungen dieser Dienste erfordern monatelange Entwicklungszyklen. Die Antwortzeiten für diese Datenquellen sind für unsere wichtigsten Stakeholder von entscheidender Bedeutung. Daher müssen wir einen datengesteuerten Ansatz verfolgen, um eine Hochleistungsarchitektur auszuwählen.
- Speicherung und Redundanz – Aufgrund der heterogenen Datenspeicher und Modelle war es eine Herausforderung, die unterschiedlichen Datensätze von verschiedenen Business-Stakeholder-Teams zu speichern. Daher bietet die Versionierung zusammen mit inkrementellen und differentiellen Daten zum Vergleichen eine bemerkenswerte Möglichkeit, optimiertere Pläne zu generieren
- Flüchtling und Zugänglichkeit – Aufgrund der unbeständigen Natur der Logistik müssen einige Teams von Geschäftsbeteiligten die Daten bei Bedarf analysieren und den optimalen Plan für die Bestellungen nahezu in Echtzeit erstellen. Dies führt dazu, dass die Daten sowohl abgefragt als auch gepusht werden müssen, um nahezu in Echtzeit darauf zuzugreifen und sie zu analysieren.
Umsetzungsstrategie
Basierend auf diesen Anforderungen änderten wir unsere Strategien und begannen, jedes Problem zu analysieren, um die Lösung zu finden. In architektonischer Hinsicht haben wir uns für ein serverloses Modell entschieden, und die Aktionslinie Data Lake Architecture bezieht sich auf alle architektonischen Lücken und herausfordernden Funktionen, die wir als Teil der Verbesserungen ermittelt haben. Aus betrieblicher Sicht haben wir ein neues Modell der gemeinsamen Verantwortung für die Datenerfassung entwickelt AWS-Kleber anstelle von internen Diensten (REST-APIs), die auf Amazon EC2 entwickelt wurden, um die Daten zu extrahieren. Wir haben auch verwendet AWS Lambda zur Datenverarbeitung. Dann haben wir gewählt Amazonas Athena wie unser Abfrageservice. Um die Entwicklungsgeschwindigkeit für unsere Datenkonsumenten weiter zu optimieren und zu verbessern, haben wir hinzugefügt Amazon DynamoDB als Metadatenspeicher für verschiedene Datenquellen, die im Data Lake landen. Diese beiden Entscheidungen trieben alle von uns getroffenen Design- und Implementierungsentscheidungen voran.
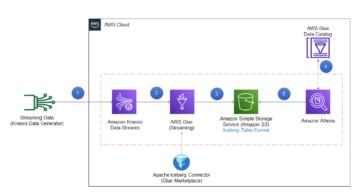
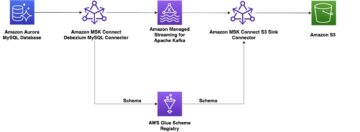
Das folgende Diagramm veranschaulicht die Architektur

In den folgenden Abschnitten betrachten wir jede Komponente in der Architektur im Detail, während wir uns durch den Prozessablauf bewegen.
AWS Glue für ETL
Um die Kundennachfrage zu erfüllen und gleichzeitig den Umfang der Datenquellen neuer Unternehmen zu unterstützen, war es für uns entscheidend, ein hohes Maß an Agilität, Skalierbarkeit und Reaktionsfähigkeit bei der Abfrage verschiedener Datenquellen zu haben.
AWS Glue ist ein serverloser Datenintegrationsservice, der es Analytics-Benutzern erleichtert, Daten aus mehreren Quellen zu entdecken, vorzubereiten, zu verschieben und zu integrieren. Sie können es für Analysen, ML und Anwendungsentwicklung verwenden. Es enthält auch zusätzliche Produktivitäts- und DataOps-Tools zum Erstellen, Ausführen von Jobs und Implementieren von Geschäftsabläufen.
Mit AWS Glue können Sie mehr als 70 verschiedene Datenquellen entdecken und sich mit ihnen verbinden und Ihre Daten in einem zentralisierten Datenkatalog verwalten. Sie können Pipelines zum Extrahieren, Transformieren und Laden (ETL) visuell erstellen, ausführen und überwachen, um Daten in Ihre Data Lakes zu laden. Außerdem können Sie mit Athena sofort katalogisierte Daten suchen und abfragen. Amazon EMR und Amazon Redshift-Spektrum.
AWS Glue hat es uns leicht gemacht, eine Verbindung zu den Daten in verschiedenen Datenspeichern herzustellen, die Daten nach Bedarf zu bearbeiten und zu bereinigen und die Daten für eine einheitliche Ansicht in einen von AWS bereitgestellten Speicher zu laden. AWS Glue-Jobs können geplant oder bei Bedarf aufgerufen werden, um Daten aus der Ressource des Clients und aus dem Data Lake zu extrahieren.
Einige Verantwortlichkeiten dieser Jobs sind wie folgt:
- Extrahieren und Konvertieren einer Quellentität in eine Datenentität
- Reichern Sie die Daten an, um Jahr, Monat und Tag für eine bessere Katalogisierung zu enthalten, und fügen Sie eine Snapshot-ID für eine bessere Abfrage hinzu
- Führen Sie eine Eingabevalidierung und Pfadgenerierung für Amazon S3 durch
- Ordnen Sie die akkreditierten Metadaten basierend auf dem Quellsystem zu
Das Abfragen von REST-APIs von internen Diensten ist eine unserer zentralen Herausforderungen, und angesichts der minimalen Infrastruktur wollten wir sie in diesem Projekt verwenden. AWS Glue Konnektoren halfen uns dabei, die Anforderung und das Ziel einzuhalten. Um Daten von REST-APIs und anderen Datenquellen abzufragen, haben wir PySpark- und JDBC-Module verwendet.
AWS Glue unterstützt eine Vielzahl von Verbindungstypen. Weitere Einzelheiten finden Sie unter Verbindungstypen und Optionen für ETL in AWS Glue.
S3-Schaufel als Landezone
Wir haben einen S3-Bucket als unmittelbare Landezone der extrahierten Daten verwendet, die weiter verarbeitet und optimiert werden.
Lambda als AWS Glue ETL-Trigger
Wir haben S3-Ereignisbenachrichtigungen im S3-Bucket aktiviert, um Lambda auszulösen, das unsere Daten weiter partitioniert. Die Daten werden nach InputDataSetName, Year, Month und Date partitioniert. Jeder Abfrageprozessor, der auf diesen Daten ausgeführt wird, scannt nur eine Teilmenge der Daten, um eine bessere Kosten- und Leistungsoptimierung zu erzielen. Unsere Daten können in verschiedenen Formaten wie CSV, JSON und Parquet gespeichert werden.
Die Rohdaten sind für die meisten unserer Anwendungsfälle nicht ideal, um den optimalen Plan zu generieren, da sie häufig Duplikate oder falsche Datentypen aufweisen. Am wichtigsten ist, dass die Daten in mehreren Formaten vorliegen, aber wir haben die Daten schnell geändert und erhebliche Verbesserungen der Abfrageleistung durch die Verwendung des Parquet-Formats festgestellt. Hier haben wir einen der Leistungstipps in verwendet Top 10 Tipps zur Leistungsoptimierung für Amazon Athena.
AWS Glue-Jobs für ETL
Wir wollten eine bessere Datentrennung und Zugänglichkeit, also haben wir uns für einen anderen S3-Bucket entschieden, um die Leistung weiter zu verbessern. Wir haben dieselben AWS Glue-Jobs verwendet, um die Daten weiter zu transformieren und in den erforderlichen S3-Bucket und einen Teil der extrahierten Metadaten in DynamoDB zu laden.
DynamoDB als Metadatenspeicher
Jetzt, da wir die Daten haben, werden sie von verschiedenen Geschäftsbeteiligten weiter genutzt. Damit bleiben zwei Fragen offen: Welche Quelldaten befinden sich auf dem Data Lake und in welcher Version. Wir haben uns für DynamoDB als unseren Metadatenspeicher entschieden, der den Verbrauchern die neuesten Details liefert, um die Daten effektiv abzufragen. Jeder Datensatz in unserem System wird eindeutig durch eine Snapshot-ID identifiziert, die wir in unserem Metadatenspeicher durchsuchen können. Clients greifen mit APIs auf diesen Datenspeicher zu.
Amazon S3 als Data Lake
Für eine bessere Datenqualität haben wir die angereicherten Daten mit demselben AWS Glue-Job in einen anderen S3-Bucket extrahiert.
AWS Glue-Crawler
Crawler sind die „geheime Zutat“, die es uns ermöglicht, auf Schemaänderungen zu reagieren. Während des gesamten Prozesses haben wir uns dafür entschieden, jeden Schritt so schemaagnostisch wie möglich zu gestalten, sodass alle Schemaänderungen durchfließen können, bis sie AWS Glue erreichen. Mit einem Crawler könnten wir die agnostischen Änderungen am Schema beibehalten. Dies half uns, die Daten von Amazon S3 automatisch zu crawlen und das Schema und die Tabellen zu generieren.
AWS Glue-Datenkatalog
Der Datenkatalog hat uns geholfen, den Katalog als Index für den Standort, das Schema und die Laufzeitmetriken der Daten in Amazon S3 zu verwalten. Informationen im Datenkatalog werden als Metadatentabellen gespeichert, wobei jede Tabelle einen einzelnen Datenspeicher angibt.
Athena für SQL-Abfragen
Athena ist ein interaktiver Abfragedienst, der die Analyse von Daten in Amazon S3 mit Standard-SQL erleichtert. Athena ist serverlos, sodass keine Infrastruktur verwaltet werden muss und Sie nur für die von Ihnen ausgeführten Abfragen bezahlen. Wir betrachteten die Betriebsstabilität und die Erhöhung der Entwicklergeschwindigkeit als unsere wichtigsten Verbesserungsfaktoren.
Wir haben den Prozess zur Abfrage von Athena weiter optimiert, sodass Benutzer die Werte und Abfragen einfügen können, um Daten aus Athena abzurufen, indem sie Folgendes erstellen:
- An AWS Cloud-Entwicklungskit (AWS CDK)-Vorlage zum Erstellen einer Athena-Infrastruktur und AWS Identity and Access Management and (IAM)-Rollen für den Zugriff auf Data Lake S3-Buckets und den Data Catalog von jedem Konto aus
- Eine Bibliothek, damit der Client eine IAM-Rolle, eine Abfrage, ein Datenformat und einen Ausgabespeicherort bereitstellen kann, um eine Athena-Abfrage zu starten und den Status und das Ergebnis der Abfrage abzurufen, die im Bucket seiner Wahl ausgeführt wird.
Das Abfragen von Athena ist ein zweistufiger Prozess:
- Abfrageausführung starten – Dadurch wird der Abfragelauf gestartet und die Lauf-ID abgerufen. Benutzer können den Ausgabespeicherort angeben, an dem die Ausgabe der Abfrage gespeichert wird.
- GetQueryExecution – Dadurch wird der Abfragestatus abgerufen, da die Ausführung asynchron ist. Bei Erfolg können Sie die Ausgabe in einer S3-Datei oder via abfragen API.
Die Hilfsmethode zum Starten der Abfrageausführung und zum Abrufen des Ergebnisses befindet sich in der Bibliothek.
Data Lake-Metadatendienst
Dieser Dienst wurde speziell entwickelt und interagiert mit DynamoDB, um die Metadaten (Dataset-Name, Snapshot-ID, Partitionszeichenfolge, Zeitstempel und S3-Link der Daten) in Form einer REST-API abzurufen. Wenn das Schema erkannt wird, verwenden Clients Athena als ihren Abfrageprozessor, um die Daten abzufragen.
Da alle Datensätze mit einer Snapshot-ID partitioniert sind, führt die Join-Abfrage nicht zu einem vollständigen Tabellen-Scan, sondern nur zu einem Partitions-Scan auf Amazon S3. Wir haben Athena als unseren Abfrageprozessor verwendet, weil es einfach ist, unsere Abfrageinfrastruktur nicht zu verwalten. Wenn wir später das Gefühl haben, dass wir etwas mehr brauchen, können wir entweder Redshift Spectrum oder Amazon EMR verwenden.
Zusammenfassung
Die Teams von Amazon Devices entdeckten einen erheblichen Mehrwert durch den Wechsel zu einer Data Lake-Architektur mit AWS Glue, die es mehreren globalen Geschäftsbeteiligten ermöglichte, Daten auf produktivere Weise aufzunehmen. Auf diese Weise konnten die Teams den optimalen Plan für die Bestellung von Geräten erstellen, indem sie die verschiedenen Datensätze nahezu in Echtzeit mit entsprechender Geschäftslogik analysierten, um die Probleme der Lieferkette, Nachfrage und Prognose zu lösen.
Aus operativer Sicht hat sich die Investition bereits ausgezahlt:
- Es standardisierte unsere Erfassungs-, Speicher- und Abrufmechanismen und spart so Onboarding-Zeit. Vor der Implementierung dieses Systems dauerte das Onboarding eines Datensatzes 1 Monat. Aufgrund unserer neuen Architektur konnten wir 15 neue Datensätze in weniger als 2 Monaten integrieren, was unsere Agilität um 70 % verbesserte.
- Es beseitigte Skalierungsengpässe und schuf ein homogenes System, das schnell auf Tausende von Läufen skaliert werden kann.
- Die Lösung fügte Schema- und Datenqualitätsvalidierung hinzu, bevor Eingaben akzeptiert und abgelehnt wurden, wenn Verstöße gegen die Datenqualität entdeckt wurden.
- Es erleichterte das Abrufen von Datensätzen und unterstützte gleichzeitig zukünftige Simulationen und Backtester-Anwendungsfälle, die versionierte Eingaben erfordern. Dadurch wird das Starten und Testen von Modellen einfacher.
- Die Lösung schuf eine gemeinsame Infrastruktur, die problemlos auf andere Teams in DIAL erweitert werden kann, die ähnliche Probleme mit Anwendungsfällen für Datenaufnahme, -speicherung und -abruf haben.
- Unsere Betriebskosten sind um fast 90 % gesunken.
- Auf diesen Data Lake können unsere Data Scientists und Ingenieure effizient zugreifen, um andere Analysen durchzuführen und einen vorausschauenden Ansatz als zukünftige Möglichkeit zu haben, genaue Pläne für die Bestellungen zu erstellen.
Die Schritte in diesem Beitrag können Ihnen dabei helfen, den Aufbau einer ähnlichen modernen Datenstrategie mithilfe von AWS-verwalteten Services zu planen, um Daten aus verschiedenen Quellen aufzunehmen, automatisch Metadatenkataloge zu erstellen, Daten nahtlos zwischen dem Data Lake und dem Data Warehouse auszutauschen und Warnungen für das Ereignis zu erstellen eines orchestrierten Daten-Workflow-Fehlers.
Über die Autoren
 Avinash Kolluri ist Senior Solutions Architect bei AWS. Er arbeitet mit Amazon Alexa und Devices, um moderne verteilte Lösungen zu entwerfen und zu entwerfen. Seine Leidenschaft ist es, kostengünstige und hochgradig skalierbare Lösungen auf AWS zu entwickeln. In seiner Freizeit kocht er gerne Fusionsrezepte und reist.
Avinash Kolluri ist Senior Solutions Architect bei AWS. Er arbeitet mit Amazon Alexa und Devices, um moderne verteilte Lösungen zu entwerfen und zu entwerfen. Seine Leidenschaft ist es, kostengünstige und hochgradig skalierbare Lösungen auf AWS zu entwickeln. In seiner Freizeit kocht er gerne Fusionsrezepte und reist.
 Vipul Verma ist Senior Software Engineer bei Amazon.com. Er ist seit 2015 bei Amazon und löst reale Herausforderungen durch Technologien, die das Leben von Amazon-Kunden direkt beeinflussen und verbessern. In seiner Freizeit wandert er gerne.
Vipul Verma ist Senior Software Engineer bei Amazon.com. Er ist seit 2015 bei Amazon und löst reale Herausforderungen durch Technologien, die das Leben von Amazon-Kunden direkt beeinflussen und verbessern. In seiner Freizeit wandert er gerne.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/how-amazon-devices-scaled-and-optimized-real-time-demand-and-supply-forecasts-using-serverless-analytics/
- 1
- 10
- 100
- 2021
- 70
- a
- Fähigkeit
- Fähig
- Zugang
- Zugriff
- Zugänglichkeit
- akkreditiert
- genau
- über
- Action
- hinzugefügt
- Zusätzliche
- AI
- Alexa
- Alle
- erlaubt
- bereits
- Amazon
- Amazonas alexa
- Amazon EC2
- Amazon EMR
- Amazon.com
- Analyse
- Analytik
- analysieren
- Analyse
- und
- Ein anderer
- Bienen
- APIs
- Anwendung
- Anwendungsentwicklung
- Ansatz
- angemessen
- architektonisch
- Architektur
- Bereiche
- Authoring
- Im Prinzip so, wie Sie es von Google Maps kennen.
- AWS
- AWS-Kleber
- Zurück
- basierend
- weil
- Bevor
- Besser
- zwischen
- Milliarden
- bauen
- erbaut
- Geschäft
- namens
- Kapazität
- Fälle
- Katalog
- Kataloge
- zentralisierte
- Kette
- Herausforderungen
- herausfordernd
- Änderungen
- Wahl
- wählten
- Auftraggeber
- Kunden
- Cloud
- COM
- Kombination
- gemeinsam
- vergleichen
- Komponente
- Berechnen
- Vernetz Dich
- Verbindung
- betrachtet
- Berücksichtigung
- verbrauchen
- KUNDEN
- ständig
- Kochen
- Kernbereich
- Kosten
- kostengünstiger
- Kosten
- könnte
- Covid
- Crawler
- erstellen
- erstellt
- Erstellen
- kritischem
- Strom
- Original
- Kunde
- Kundenservice
- Kunden
- Zyklen
- technische Daten
- Datenintegration
- Datensee
- Datenverarbeitung
- Datenqualität
- Datenstrategie
- Data Warehouse
- datengesteuerte
- Datensätze
- Datum
- Tag
- Behandlung
- Entscheidung
- Entscheidungen
- Grad
- Demand
- Anforderungen
- Abhängig
- Design
- entworfen
- Detail
- Details
- entschlossen
- entwickelt
- Entwickler:in / Unternehmen
- Entwickler
- Entwicklung
- Geräte
- anders
- Direkt
- entdeckt,
- entdeckt
- Entdeckung
- verteilt
- verschieden
- Tut nicht
- Duplikate
- jeder
- leicht
- effektiv
- effizient
- entweder
- freigegeben
- ermöglicht
- Ingenieur
- Ingenieure
- angereichert
- Einheit
- Äther (ETH)
- Event
- Jedes
- Extrakt
- Extrahieren Sie die Daten
- Faktoren
- Scheitern
- Gefallen
- Eigenschaften
- wenige
- Reichen Sie das
- Fluss
- Folgende
- folgt
- Prognose
- unten stehende Formular
- Format
- gefunden
- für
- voller
- weiter
- Außerdem
- Verschmelzung
- Zukunft
- Gewinne
- erzeugen
- Erzeugung
- Generation
- bekommen
- bekommen
- Global
- globales Geschäft
- Globus
- Kundenziele
- Wachstum
- mit
- Hilfe
- dazu beigetragen,
- hier
- High
- Hohe Leistungsfähigkeit
- hoch
- Wandern
- Ultraschall
- HTML
- HTTPS
- IAM
- ideal
- identifiziert
- identifizieren
- Identitätsschutz
- unmittelbar
- sofort
- Impact der HXNUMXO Observatorien
- Implementierung
- Umsetzung
- zu unterstützen,
- verbessert
- Verbesserung
- Verbesserungen
- in
- das
- Dazu gehören
- zunehmend
- Index
- Information
- Infrastruktur
- Varianten des Eingangssignals:
- beantragen müssen
- integrieren
- Integration
- interaktive
- interagiert
- intern
- Stellt vor
- Inventar
- Investition
- Problem
- Probleme
- IT
- Job
- Jobs
- join
- JSON
- Wesentliche
- Mangel
- See
- Landung
- neueste
- Start
- lernen
- Legacy
- Bibliothek
- Lebensdauer
- Grenzen
- Line
- LINK
- Belastung
- Standorte
- Logistik
- aussehen
- Maschine
- Maschinelles Lernen
- gemacht
- halten
- Wartung
- um
- MACHT
- verwalten
- flächendeckende Gesundheitsprogramme
- Marketing
- Triff
- Metadaten
- Methode
- Metrik
- minimal
- ML
- Modell
- für
- modern
- geändert
- Module
- Überwachen
- Monat
- Monat
- mehr
- vor allem warme
- schlauer bewegen
- ziehen um
- mehrere
- Name
- Natur
- Need
- erforderlich
- Neu
- Benachrichtigungen
- Onboard
- Einsteigen
- EINEM
- die
- Betriebs-
- Entwicklungsmöglichkeiten
- Gelegenheit
- optimal
- Optimierung
- Optimieren
- optimiert
- Optionen
- Bestellungen
- Andere
- Pandemie
- Teil
- Leidenschaft & KREATIVITÄT
- Weg
- AUFMERKSAMKEIT
- Prozentsatz
- ausführen
- Leistung
- Perspektive
- Ort
- Plan
- Pläne
- Plato
- Datenintelligenz von Plato
- PlatoData
- möglich
- Post
- Danach
- in erster Linie
- primär
- Probleme
- Prozessdefinierung
- Verarbeitung
- Prozessor
- Producers
- produktiv
- PRODUKTIVITÄT
- Projekt
- die
- bietet
- Kauf
- Schieben
- Qualität
- Fragen
- schnell
- Bewerten
- Roh
- Rohdaten
- erreichen
- realen Welt
- Echtzeit
- Gründe
- Rezepte
- Reduzierung
- bezieht sich
- bemerkenswert
- Entfernt
- falls angefordert
- Anforderung
- Voraussetzungen:
- Ressourcen
- Antwort
- Verantwortlichkeiten
- Verantwortung
- ansprechbar
- REST
- Folge
- Rollen
- Rollen
- Führen Sie
- Laufen
- Vertrieb
- gleich
- Einsparung
- Skalierbarkeit
- skalierbaren
- Skalieren
- Skalierung
- Scan
- vorgesehen
- Wissenschaftler
- nahtlos
- Suche
- Abschnitte
- Senior
- Serverlos
- Leistungen
- Teilen
- von Locals geführtes
- Versand
- Konzerte
- signifikant
- ähnlich
- Einfacher
- da
- Single
- Schnappschuss
- So
- Software
- Software IngenieurIn
- Lösung
- Lösungen
- LÖSEN
- Auflösung
- etwas
- Quelle
- Quellen
- überspannt
- Spektrum
- verbrachte
- SQL
- Stabilität
- Stakeholder
- Stakeholder
- Standard
- Anfang
- begonnen
- Beginnen Sie
- beginnt
- Status
- Schritt
- Shritte
- Lagerung
- speichern
- gelagert
- Läden
- Strategien
- Strategie
- erfolgreich
- so
- liefern
- Supply Chain
- Unterstützung
- Unterstützt
- System
- Tabelle
- Nehmen
- nimmt
- Teams
- Technologie
- Vorlage
- Testen
- Das
- Die Quelle
- ihr
- deswegen
- Tausende
- Durch
- während
- Zeit
- mal
- Zeitstempel
- Tipps
- zu
- Top
- Transaktionen
- Transformieren
- Reise
- auslösen
- Typen
- einheitlich
- Updates
- us
- -
- Nutzer
- Bestätigung
- Wert
- Werte
- Vielfalt
- verschiedene
- Geschwindigkeit
- Version
- Anzeigen
- Verstöße
- flüchtig
- Volumen
- wollte
- Warehouse
- Wege
- Was
- welche
- während
- breit
- werden wir
- Arbeitsablauf.
- Workflows
- Werk
- würde
- Jahr
- Ihr
- Zephyrnet