In diesem Artikel erfahren Sie verschiedene Methoden zum Konvertieren von PDF in Google Sheets.
Sie erfahren auch, wie Nanonets das können Automatisieren Sie den gesamten Workflow der Konvertierung von PDF in Google Sheets online.
Bevor wir uns mit der Konvertierung von PDF-Dateien in Google Sheets befassen, werfen wir einen Blick darauf, warum dies wichtig ist.
Warum PDFs in Google Sheets konvertieren?
Hiernach Google-Blog Post von der offiziellen Google-Blogseite verwenden mehr als 5 Millionen Unternehmen ihre G Suite-Lösung. Gleichzeitig haben auch viele Unternehmen damit begonnen, Google Sheets-Integrationen zu verwenden, um Aufgaben zu automatisieren.
Betrachten wir einen typischen Anwendungsfall. Ihre Kreditorenbuchhaltung erhält eine Rechnung im Standard-PDF-Format. Jemand geht die Rechnung manuell durch und gibt die erforderlichen Informationen in ein Google Tabellen-Dokument ein, bevor es an den Finanzbereich weitergeleitet wird. Der Abschnitt Finanzen bezahlt Ihren Lieferanten und nimmt einen Eintrag im Hauptbuch des Unternehmens vor.
Abgesehen davon, dass dies ein langwieriger Prozess ist, ist dies fehleranfällig und es wäre viel sinnvoller, es einfach zu automatisieren.
Da nun klar ist, dass PDFs in ein Google-Blattformular konvertiert werden müssen, werfen wir einen Blick darauf, wie PDF-Dokumente strukturiert sind und welche Herausforderungen beim Parsen bestehen.
Willst du konvertieren PDF Dateien Google Blätter ? Auschecken Nanonets ' kostenlos PDF-zu-CSV-Konverter. Oder finden Sie heraus, wie es geht Automatisieren Sie Ihren gesamten PDF-zu-Google-Sheets-Workflow mit Nanonets.
Herausforderungen beim Parsen eines PDF-Dokuments
Das Portable Document Format war ein ursprünglich von Adobe entwickeltes Dateiformat, das später als offener Standard veröffentlicht wurde. Es ist seitdem weit verbreitet, da es das zugrunde liegende Betriebssystem agnostisch ist.
Warum ist es also so schwierig, ein PDF zu analysieren und seinen Inhalt in ein anderes Format zu konvertieren? Die folgenden Bilder sagen mehr als tausend Worte und werden es auf den Punkt bringen.
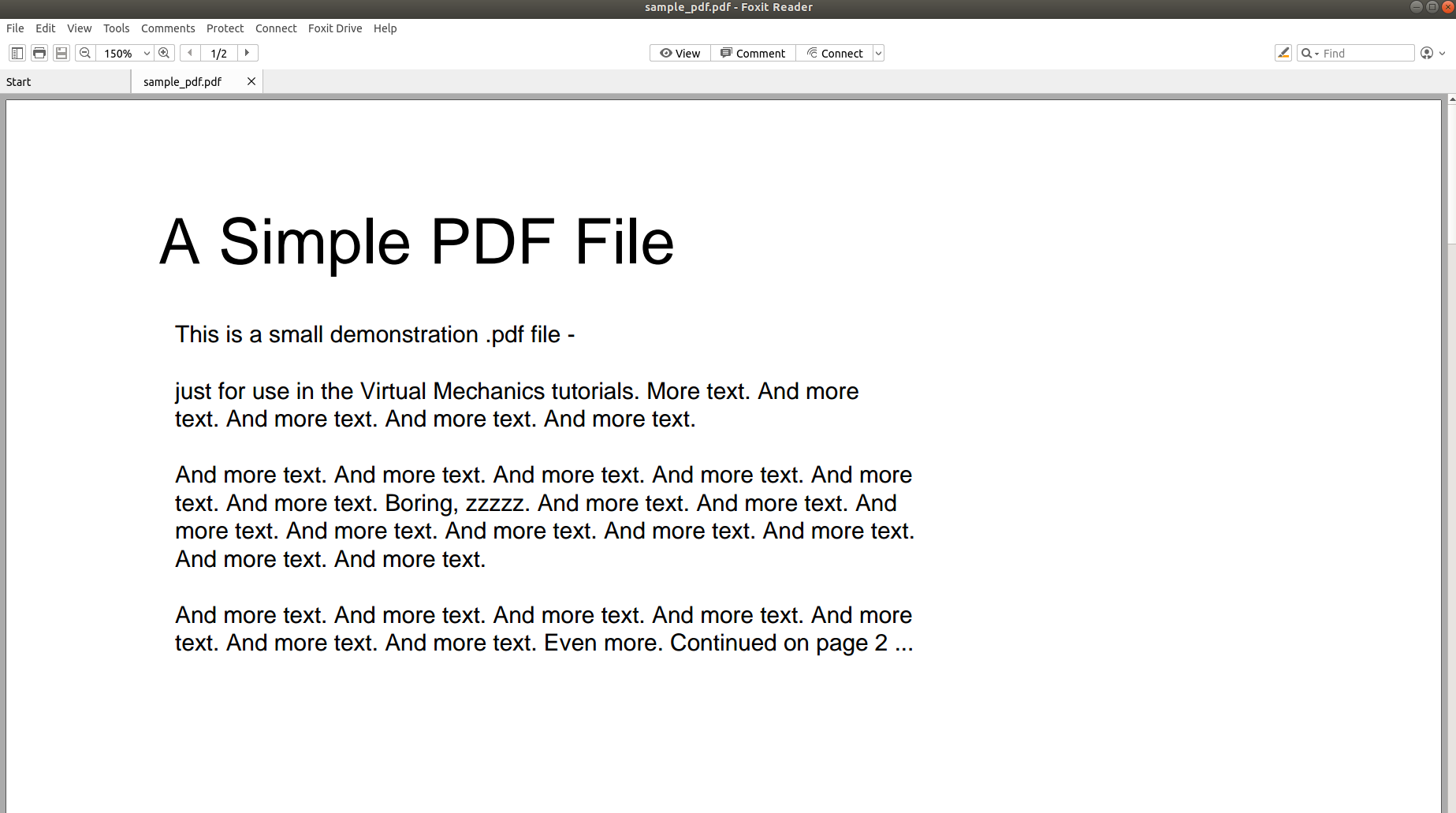
Das obige Bild zeigt den Screenshot eines PDF-Dokuments, das mit einem PDF-Reader geöffnet wird. Versuchen wir, dasselbe PDF-Dokument mit einem Texteditor zu öffnen.
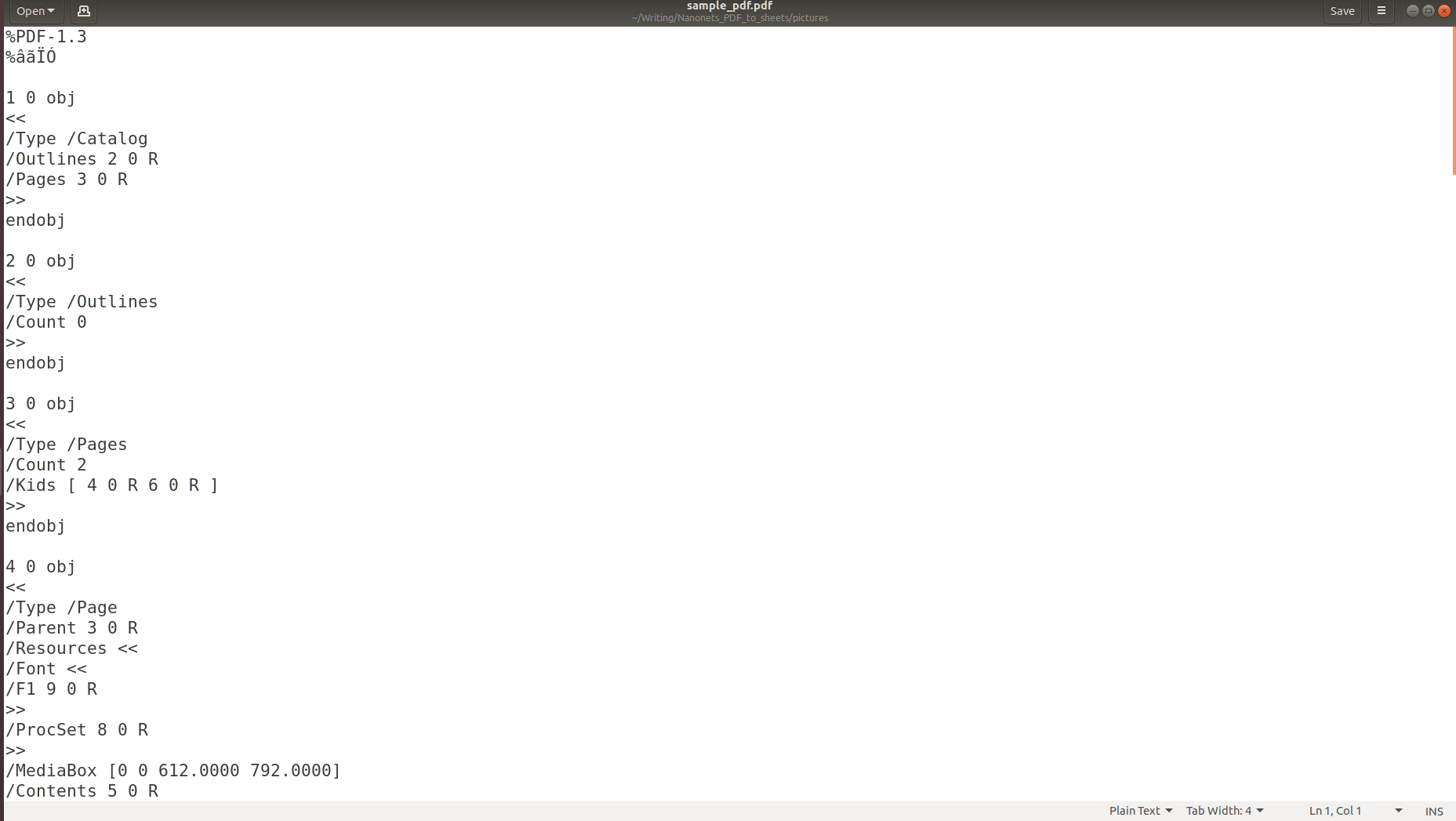
Die obigen Bilder machen deutlich, dass beim Speichern von Informationen in einem PDF die ursprüngliche Struktur vollständig verloren geht. Dies liegt daran, dass das PDF-Format einfach aus Anweisungen zum Drucken/Zeichnen einer Zeichenfolge auf einer Seite besteht.
Wenn Sie der Meinung sind, dass die Textextraktion schwierig ist, ist die Extraktion der in Tabellen enthaltenen Daten aufgrund der sehr unterschiedlichen Tabellenformate, die verwendet werden, noch schwieriger.
Hoffentlich sind Sie davon überzeugt, dass das Konvertieren eines PDF-Dokuments in ein Google Sheets-Formular kein Kinderspiel ist. Der nächste Abschnitt behandelt den Ansatz der meisten modernen PDF-Parser, um Informationen aus einem PDF-Dokument zu erkennen/zu analysieren.
Der moderne Ansatz zum Parsen von PDF-Dokumenten
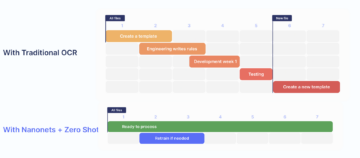
Die meisten modernen PDF-Parser verwenden den unten beschriebenen Ablauf, um unstrukturierte Daten aus PDF-Dokumenten zu parsen.
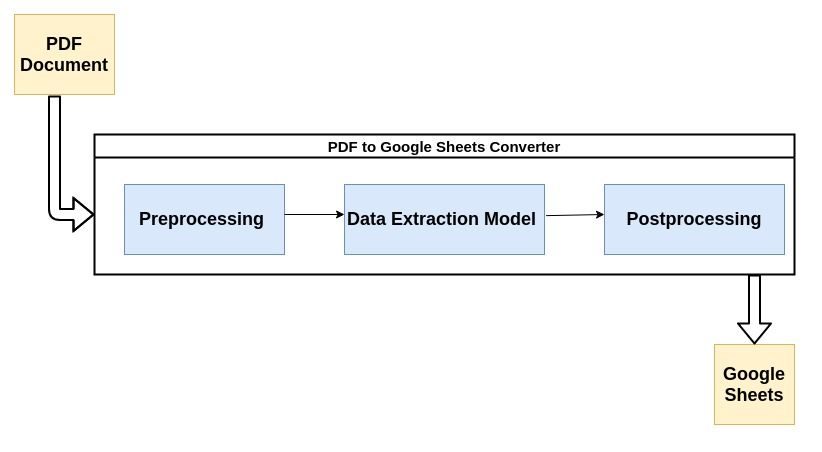
Werfen wir einen kurzen Blick auf jeden Schritt des Prozesses:
1. Vorverarbeitung oder Datenbereinigung:
Je besser Ihr PDF aussieht, desto einfacher lässt sich Ihr Machine Learning-Modell extrahieren bzw Daten erfassen davon. Wenn das PDF-Dokument beispielsweise gescannt wurde, enthält es zwangsläufig einige Scanartefakte, die die Leistung des Konverters beeinträchtigen könnten.
Rauschunterdrückung durch Verwendung geeigneter Filter, Binarisierung, Skew-Korrektur usw. sind einige der gängigsten Vorverarbeitungsschritte. Der folgende Nanonets-Beitrag Nanonets Tesseract Post enthält einige großartige Beispiele, wie Dokumente vorher vorverarbeitet werden können Optical Character Recognition(OCR) wird darauf ausgeführt.
Hier passiert die meiste Magie. Die Datenextraktion wird normalerweise durch ein Machine Learning(ML)-Modell durchgeführt. Die meisten ML-Modelle, die für die Datenextraktion aus PDFs verwendet werden, enthalten eine Kombination aus optischen Zeichenerkennungstools, Text- und Mustererkennungstools usw.
Für die Zwecke dieses Beitrags können wir das Modell als Blackbox behandeln, die Ihr PDF-Dokument als Eingabe nimmt und die geparsten Informationen ausspuckt. Da es im Kern ML verwendet, kann es mit benutzerdefinierten Daten neu trainiert werden, um dem Anwendungsfall Ihres Unternehmens zu entsprechen.
3. Nachbearbeitung:
In diesem Schritt werden die extrahierten Daten in das erforderliche Format wie CSV, XML, JSON etc. umgewandelt. Außerdem werden zusätzlich zu den Vorhersagen der KI zusätzliche benutzerdefinierte Regeln hinzugefügt. Dies kann Regeln für die Formatierung der Ausgabe, zusätzliche Einschränkungen für extrahierte Informationen usw. umfassen.
Der folgende Abschnitt befasst sich mit einigen Metriken, mit denen wir die Leistung eines PDF-Parsers messen können.
Willst du konvertieren PDF Dateien Google Blätter ? Auschecken Nanonets ' kostenlos PDF-zu-CSV-Konverter. Finden Sie heraus, wie Sie mit Nanonets Ihren gesamten PDF-zu-Google-Tabellen-Workflow automatisieren können.

Metriken zur Messung der Leistung eines PDF-Konverters
Da die meisten PDF-Konverter für die Rechnungsverarbeitung oder verwandte Aufgaben verwendet werden, ist die Genauigkeit und Geschwindigkeit der Tabellenextraktion aus einem PDF-Dokument ein entscheidender Faktor bei der Beurteilung der Leistung des PDF-Konverters.
2. Mehrsprachigkeit:
Die meisten großen Unternehmen müssen Rechnungen in verschiedenen Sprachen erhalten. Der PDF-Parser sollte entweder das mehrsprachige Parsing sofort unterstützen oder eine Option bereitstellen, mit der Benutzer das Modell mit benutzerdefinierten Daten trainieren können.
3. Integration mit Buchhaltungssoftware:
Der ideale PDF-Konverter sollte ein Plug-and-Play-Modul sein, das einfach zu Ihrem bestehenden hinzugefügt werden kann Dokumenten-Workflow. Es sollte die Integration mit gängiger Buchhaltungssoftware wie QuickBooks, Xero, Wave usw. unterstützen.
4. Einfach und intuitiv:
Das Tool wird höchstwahrscheinlich von technisch nicht versierten Benutzern bedient. Es wäre von Vorteil, wenn es mit minimalen technischen Kenntnissen bedient werden kann.
Verschiedene Methoden zum Konvertieren von PDFs in Google Sheets
1.Verwenden Sie Google Docs zum Konvertieren von PDF-Dateien in Google Sheets
Google Drive verfügt über eine integrierte Funktion zur Erkennung von Tabellen und Text in einfachen PDF-Dokumenten. Sie müssen lediglich:
-
Laden Sie Ihre PDF-Datei auf Google Drive hoch
-
Klicken Sie auf „Mit Google Docs öffnen“
-
Kopieren Sie die gewünschten Daten und fügen Sie sie in Google Sheets ein
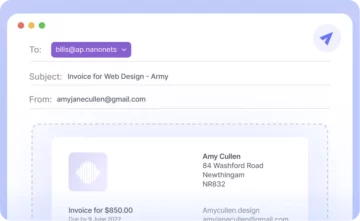
Obwohl das gut zu funktionieren scheint, probieren wir etwas Praktischeres aus. Betrachten Sie diese einfache Rechnung.
Wenn Sie dies mit der Google Docs-Anwendung öffnen, erhalten Sie das folgende Ergebnis.
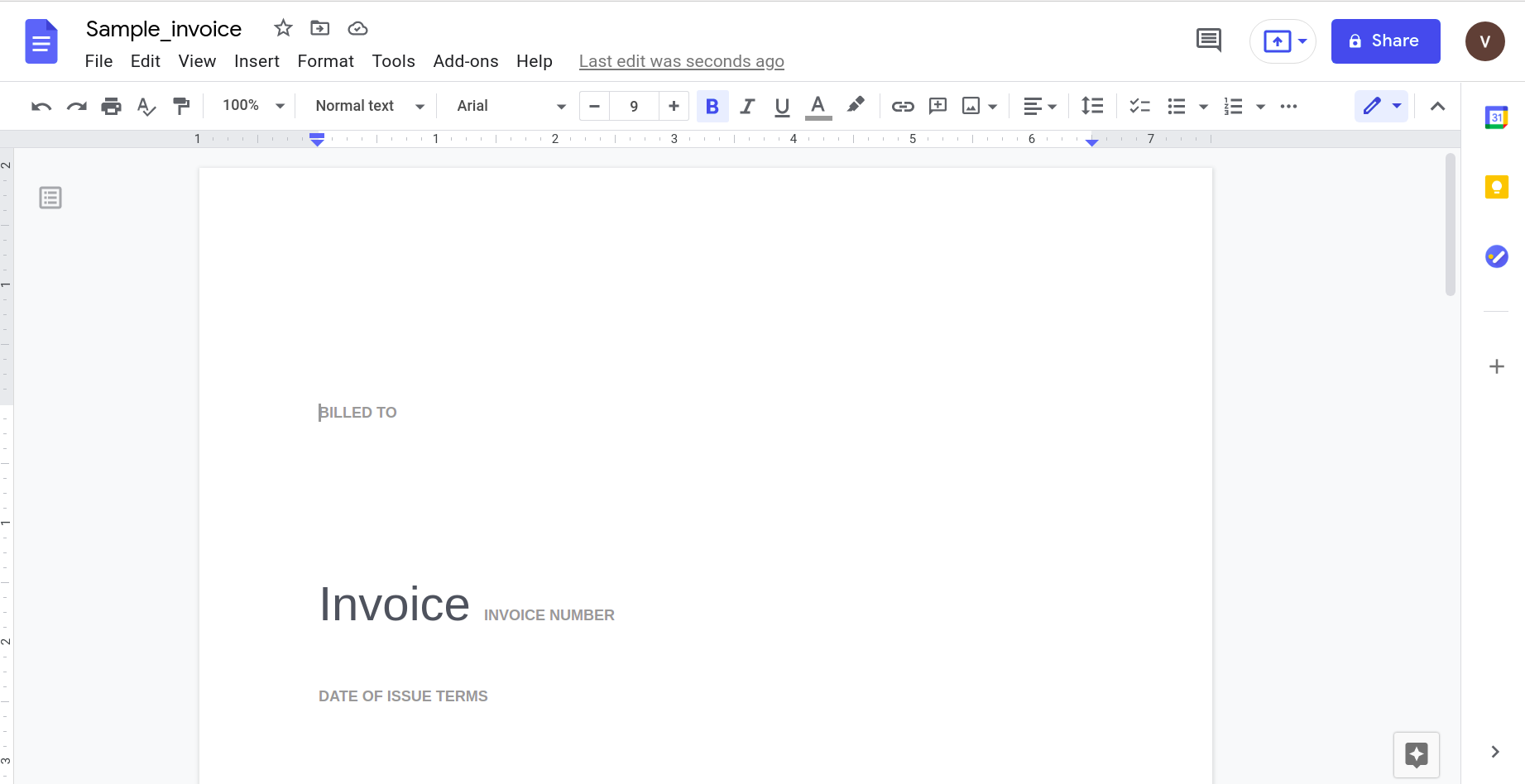
Da die Komplexität des Dokuments zunimmt, müssen wir uns natürlich auf ausgefeiltere Tools zur Datenerkennung verlassen.
2. Verwendung von Online-Tools:
Mehrere Online-Tools wie der PDF-Tabellenextraktor, Online2PDF usw. lassen sich direkt in Google Drive integrieren und bieten sofort die Möglichkeit, PDF-Dokumente in Google Sheets zu konvertieren.
Als diese Tools jedoch mit dem oben gezeigten Beispiel-Rechnungs-PDF getestet wurden, wurden die Tabellen in den meisten Fällen nicht erkannt.
Willst du konvertieren PDF Dateien Google Blätter ? Auschecken Nanonets ' kostenlos PDF-zu-CSV-Konverter. Finden Sie heraus, wie Sie Ihren gesamten PDF-zu-Google-Tabellen-Workflow mit Nanonets automatisieren können, wie unten gezeigt.
Automatisierung des PDF-zu-Google-Sheets-Konvertierungsprozesses
Mit den folgenden Tools können wir den Prozess des Parsens des PDFs und des Extrahierens der Daten in ein Google Sheets-Formular vollständig automatisieren.
1. Verwenden von Webhooks:
Webhooks sind benutzerdefinierte HTTP-Anforderungen. Sie werden normalerweise bei einem Ereignis ausgelöst, dh wenn ein Ereignis eintritt, sendet die Anwendung Informationen an eine vordefinierte URL.
Wie können Sie dies zur Automatisierung Ihres Workflows nutzen? Betrachten wir den typischen Anwendungsfall der Rechnungsverarbeitung. Sie erhalten eine Reihe von Rechnungen von Ihren Lieferanten und geben sie in Ihren PDF-zu-Google-Tabellen-Konverter ein, der sich in der Cloud befindet. Woher wissen Sie, wann das Modell die Verarbeitung der Dokumente abgeschlossen hat?
Anstatt manuell zu überprüfen, ob die Konvertierung abgeschlossen ist, können Sie einfach einen Webhook verwenden, der Sie benachrichtigt, wenn die Daten im PDF in ein Google Sheets-Dokument extrahiert wurden.
2. APIs verwenden
API steht für Application Programming Interface. Mit den entsprechenden API-Aufrufen kann das Konvertieren von PDF-Dokumenten in Google Sheets so einfach sein wie das Schreiben der folgenden Codezeilen:
#Feed the PDF documents into the PDF to Google sheets converter
Success_code, unique_id = NanonetsAPI.uploaddata(PDF_documents)
Wenn Ihr Unternehmen die Integration mit Webhooks bereits eingerichtet hat, erhalten Sie eine Benachrichtigung, wenn Ihre PDF-Dokumente erfolgreich konvertiert wurden. Anschließend können Sie das Google Tabellen-Formular mithilfe der unten gezeigten API herunterladen.
#Download Google Sheets forms
Google_sheets_data = NanonetsAPI.downloaddata(unqiue_id)
PDF zu Google Sheets mit Nanonets
Der Nanonets PDF-Parser macht das Parsen und Konvertieren einfach und genau. Der PDF-Parser wurde verwendet, um eine Beispielrechnung zu analysieren. Dieser Abschnitt demonstriert die Benutzerfreundlichkeit und Genauigkeit des Tools. Anstatt darüber zu sprechen, wie großartig es ist, veranschaulichen die folgenden Bilder den Punkt treffend.
Das unten gezeigte Bild ist ein Screenshot der Beispielrechnung, die dem Nanonets PDF-Parser zugeführt wurde.
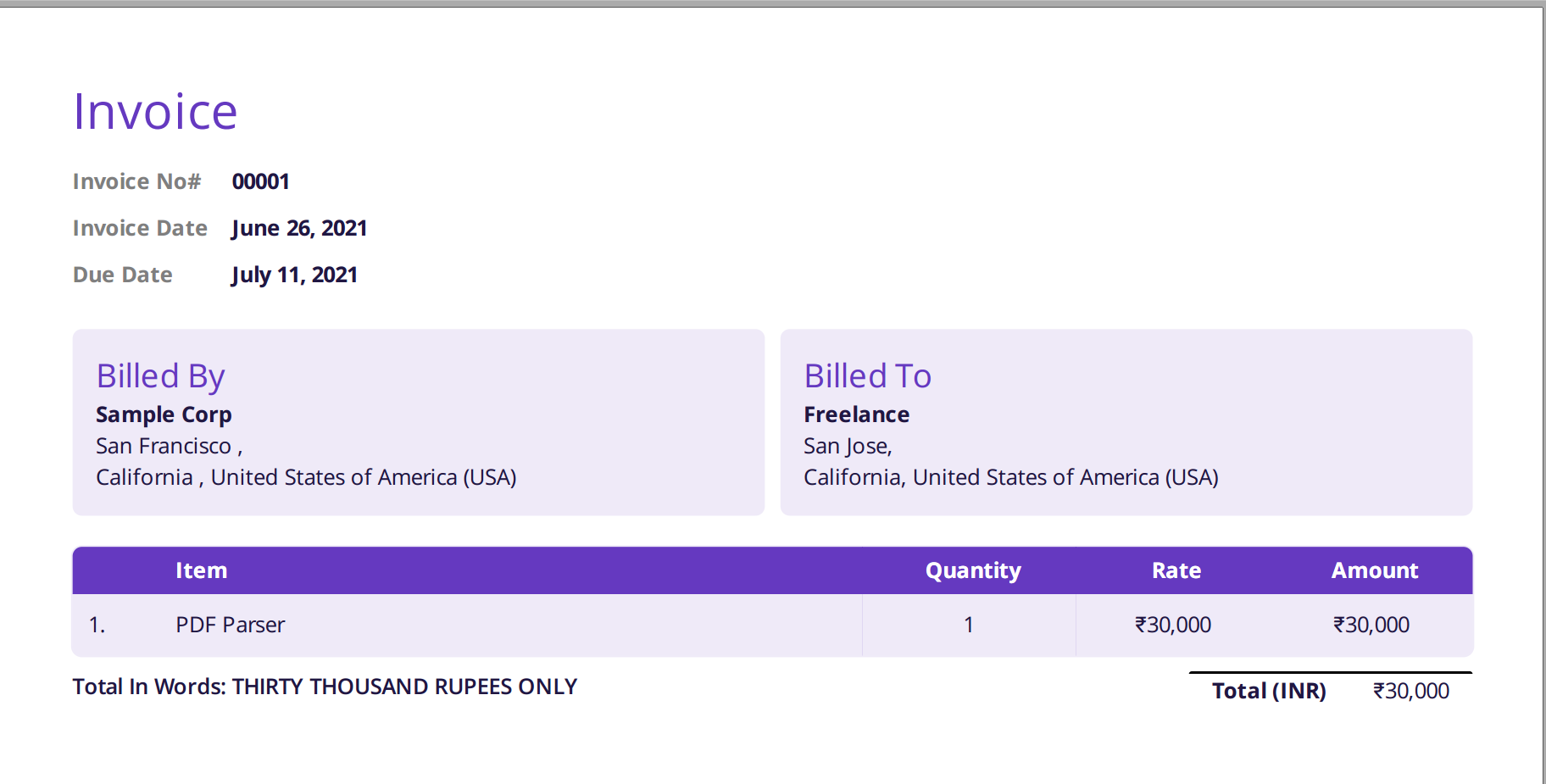
Navigieren Sie einfach auf die Website von Nanonets und laden Sie die Rechnung hoch. Die Konvertierung dauert nur wenige Sekunden, danach können die geparsten Daten in einer Vielzahl von Formaten heruntergeladen werden, z CSV, XLSX usw. (siehe Nanonets' PDF-zu-CSV-Konverter)
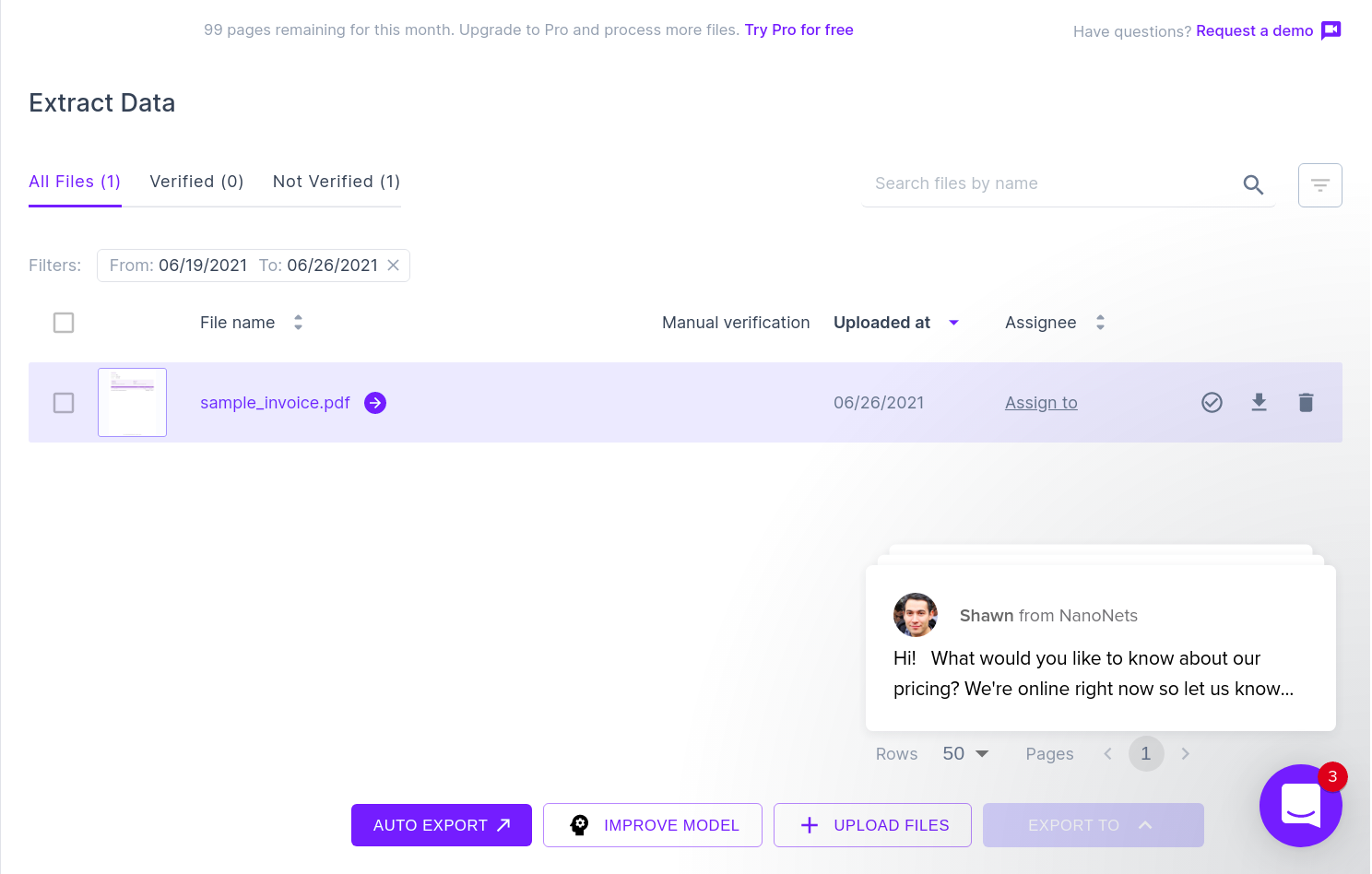
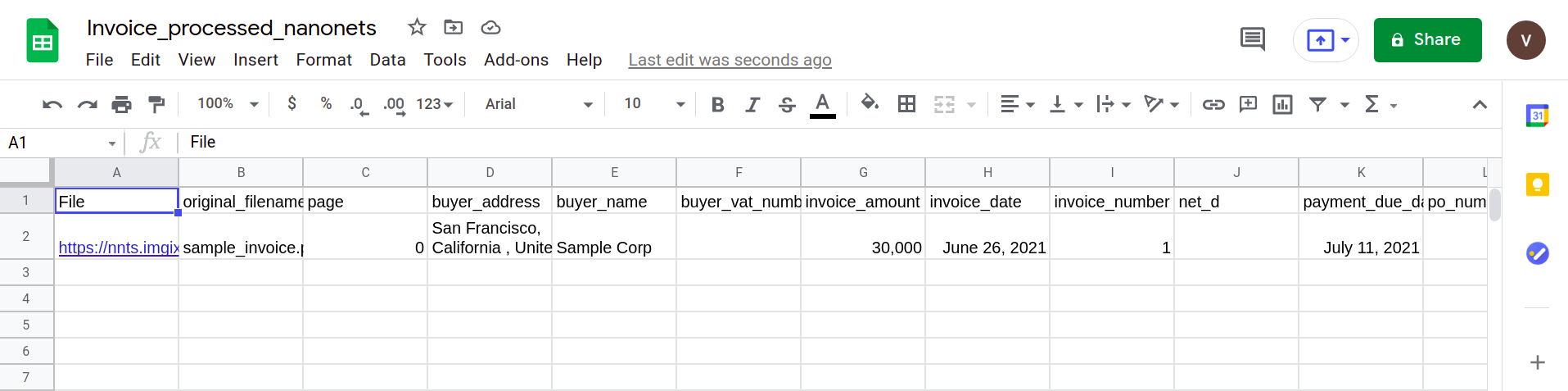
Das nächste Bild zeigt einen Screenshot der CSV-Datei, die die geparsten Daten aus dem PDF-Dokument enthält.

Um die CSV-Datei schließlich in ein Google Sheets-Formular zu konvertieren, müssen Sie einfach die XLSX/CSV-Datei in Ihr Google-Laufwerk hochladen. Dieser Schritt kann mithilfe von Google Drive-APIs automatisiert werden.
Der folgende Abschnitt zeigt, wie mit dem Nanonets PDF-Parser eine einfache Pipeline erstellt werden kann.
Möchten Sie Informationen aus PDF-Dokumenten extrahieren und sie in ein Google Sheets-Dokument konvertieren/hinzufügen? Schauen Sie sich Nanonets an™ um den Export von Informationen aus jedem PDF-Dokument in Google Sheets zu automatisieren!
Erstellen einer einfachen Pipeline
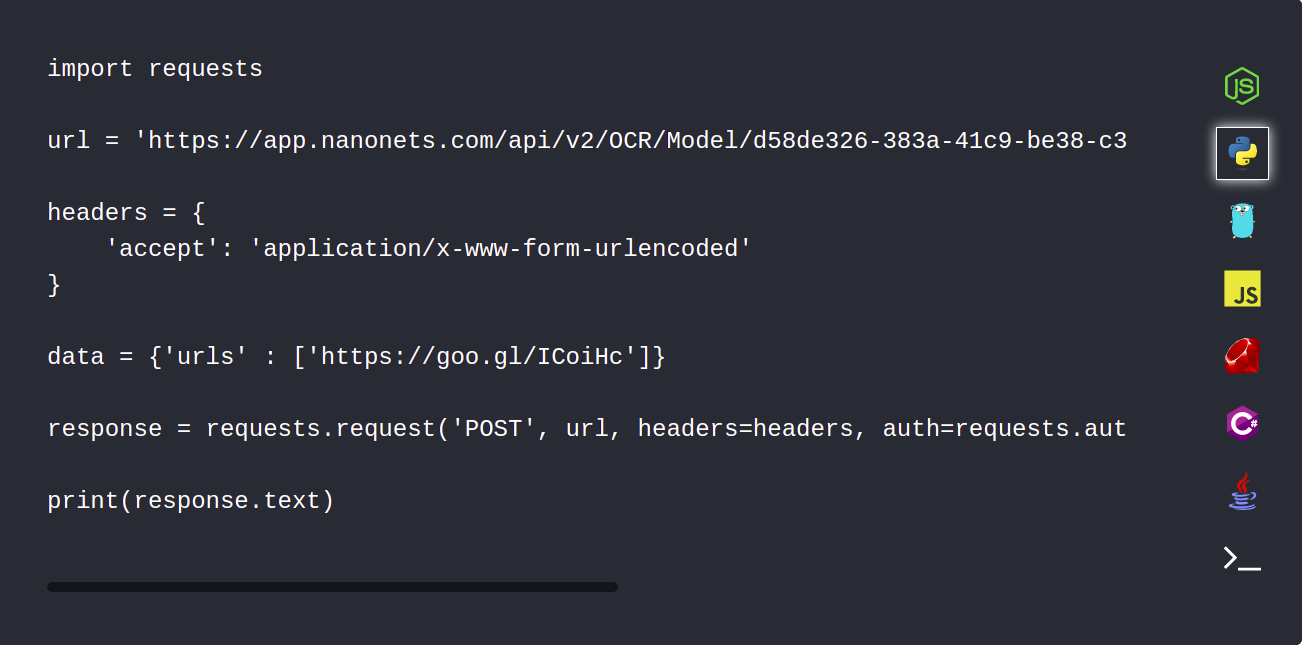
1. Laden Sie Ihre PDF-Dokumente automatisch mit der Nanonets-API hoch
Mit der Nanonets API können Sie Ihre zu parsenden Dokumente automatisch hochladen. Der folgende Codeausschnitt zeigt, wie dies mit Python möglich ist.
2. Verwenden Sie die Webhooks-Integration, um eine Benachrichtigung nach Abschluss des Parsens zu erhalten
Webhooks können so konfiguriert werden, dass Sie automatisch benachrichtigt werden, sobald die Dokumente analysiert wurden.
3. Überprüfen und in Google Tabellen hochladen
Laden Sie die CSV-Dateien herunter und überprüfen Sie sie, um sicherzustellen, dass alles in Ordnung ist, und laden Sie die Daten mithilfe der Google Drive-API in Google Tabellen hoch.
Die Nanonets Edge
Hier sind einige Funktionen des Nanonets PDF Parsers, die ihn zum idealen Werkzeug für Ihr Unternehmen machen.
1. Externe Integrationen:
Das nanonets-Modell lässt sich problemlos in MySql, Quickbooks, Salesforce etc. integrieren. So bleibt Ihr aktueller Workflow ungestört und der nanonets-Konverter kann einfach als Zusatzmodul eingesteckt werden.
2. Hohe Genauigkeit und niedrige Bearbeitungszeiten:
Das PDF-Parser-Tool von Nanonets hat eine Genauigkeit von über 95% und mehr, was im Vergleich zu seinen Konkurrenten viel höher ist.
3. Coole Nachbearbeitungsfunktionen:
Angenommen, Ihre Datenbank wurde in das Nanonets-Modell integriert. Das Modell füllt automatisch einige Felder (mit Daten aus Ihrer Datenbank) basierend auf den aus dem Dokument extrahierten Daten aus. Zum Beispiel:
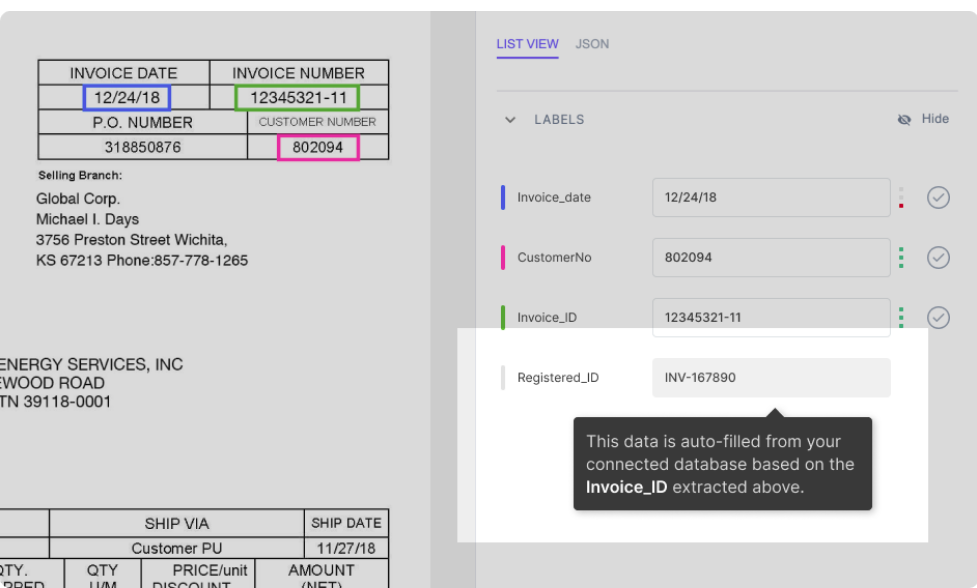
Wie in der Abbildung gezeigt, wird das Feld Registered_ID automatisch (durch eine Datenbanksuche) basierend auf der aus dem PDF extrahierten Invoice_ID gefüllt.
4. Einfache und intuitive Benutzeroberfläche
Obwohl diese Funktion unterschätzt wird, fand ich die Benutzeroberfläche und UX genau richtig. Der gesamte Vorgang der Anmeldung, des Hochladens des Dokuments und des Parsens der Daten dauerte weniger als 5 Minuten. Das entspricht fast der Zeit, die mein Laptop zum Hochfahren benötigt!
5. Riesiger Kundenstamm
Falls Sie noch Bedenken haben, Nanonets zur Automatisierung Ihres Workflows zu verwenden, schauen Sie sich einfach einige der Unternehmen an, die ihre Dienste nutzen.
- Deloitte
- Sherwin Williams
- DoorDash
- P & G
Möchten Sie Informationen aus PDF-Dokumenten extrahieren und sie in ein Google Sheets-Dokument konvertieren/hinzufügen? Schauen Sie sich Nanonets an™ um den Export von Informationen aus jedem PDF-Dokument in Google Sheets zu automatisieren!
Zusammenfassung
In diesem Beitrag haben wir uns angeschaut, wie Sie Ihren Workflow automatisieren können, indem Sie einen PDF-zu-Google-Tabellen-Konverter verwenden. Zunächst erfuhren wir von der Notwendigkeit der Konvertierung von PDF-Dokumenten in Google Sheets, gefolgt von den Herausforderungen, mit denen dieser Prozess konfrontiert war. Anschließend haben wir uns mit den Ansätzen moderner Parser zum Parsen von PDF-Dokumenten beschäftigt und einige der gängigen Ansätze implementiert. Wir haben auch gelernt, wie wir die Konvertierung mithilfe externer Integrationen wie Webhooks und APIs vollständig automatisieren können. Schließlich haben wir das Nanonets-Tool verwendet, um eine Beispielrechnung zu analysieren, die Daten in ein Google Sheets-Formular zu extrahieren und auch einige seiner coolen Nachbearbeitungsfunktionen zu erkunden.
Haben Sie dem Nanonets-Modell eine Chance gegeben? Wenn ja, hinterlassen Sie bitte unten einen Kommentar zu Ihren Erfahrungen mit dem Tool. Wenn nicht, probieren Sie es aus. Es könnte Ihren Tag einfach machen!
- AI
- KI & Maschinelles Lernen
- Kunst
- KI-Kunstgenerator
- KI-Roboter
- künstliche Intelligenz
- Zertifizierung für künstliche Intelligenz
- Künstliche Intelligenz im Bankwesen
- Roboter mit künstlicher Intelligenz
- Roboter mit künstlicher Intelligenz
- Software für künstliche Intelligenz
- Blockchain
- Blockchain-Konferenz ai
- Einfallsreichtum
- dialogorientierte künstliche Intelligenz
- Krypto-Konferenz ai
- Dalls
- tiefe Lernen
- Google Ai
- Maschinelles Lernen
- pdf zu google tabellen
- Plato
- platon ai
- Datenintelligenz von Plato
- Plato-Spiel
- PlatoData
- Platogaming
- Skala ai
- Syntax
- Zephyrnet