Amazon RedShift ist ein schnelles, skalierbares, sicheres und vollständig verwaltetes Data Warehouse, mit dem Sie alle Ihre Daten einfach und kostengünstig mit Standard-SQL analysieren können. Amazon Redshift Datenübertragung ermöglicht es Kunden, transaktionskonsistente Live-Daten in einem Amazon Redshift-Cluster sicher mit einem anderen Amazon Redshift-Cluster über Konten und Regionen hinweg zu teilen, ohne Daten von einem Cluster in einen anderen kopieren oder verschieben zu müssen.
Amazon Redshift Data Sharing wurde ursprünglich in eingeführt März 2021, und zusätzliche Unterstützung für die kontoübergreifende Datenfreigabe wurde hinzugefügt August 2021. Die regionsübergreifende Unterstützung wurde allgemein verfügbar in Februar 2022. Dies bietet volle Flexibilität und Agilität, um Daten über Redshift-Cluster hinweg im selben AWS-Konto, in verschiedenen Konten oder in verschiedenen Regionen gemeinsam zu nutzen.
Amazon Redshift Data Sharing wird verwendet, um Amazon Redshift-Bereitstellungsarchitekturen grundlegend neu zu definieren in ein Hub-Spoke-Data-Mesh-Modell, um Leistungs-SLAs besser zu erfüllen, Workload-Isolierung bereitzustellen, gruppenübergreifende Analysen durchzuführen, neue Anwendungsfälle einfach zu integrieren und vor allem all das zu tun dies ohne die Komplexität von Datenbewegungen und Datenkopien. Einige der am häufigsten gestellten Fragen während der Bereitstellung von Datenfreigaben lauten: „Wie groß sollten meine Consumer-Cluster und Producer-Cluster sein?“ und „Wie erhalte ich das beste Preis-Leistungs-Verhältnis für die Workload-Isolation?“. Da Workload-Eigenschaften wie Datengröße, Aufnahmerate, Abfragemuster und Wartungsaktivitäten die Leistung der gemeinsamen Datennutzung beeinträchtigen können, sollte eine kontinuierliche Strategie zur Dimensionierung von Verbraucher- und Erzeuger-Clustern implementiert werden, um die Leistung zu maximieren und die Kosten zu minimieren. In diesem Beitrag bieten wir einen schrittweisen Ansatz, der Ihnen dabei hilft, die Größe Ihrer Erzeuger- und Verbrauchercluster für das beste Preis-Leistungs-Verhältnis basierend auf Ihrer spezifischen Arbeitslast zu bestimmen.
Allgemeine Anleitung zur Größenbestimmung für Verbraucher
Die folgenden Schritte zeigen die generische Strategie zur Dimensionierung Ihrer Producer- und Consumer-Cluster. Sie können es als Ausgangspunkt verwenden und entsprechend ändern, um es an Ihr spezifisches Anwendungsszenario anzupassen.
Dimensionieren Sie Ihren Produzentencluster
Sie sollten immer sicherstellen, dass Sie Ihren Producer-Cluster richtig dimensionieren, um die Leistung zu erhalten, die Sie zum Erfüllen Ihres SLA benötigen. Sie können den Größenrechner der Amazon Redshift-Konsole nutzen, um basierend auf der Größe Ihrer Daten und Abfragemerkmalen eine Empfehlung für den Produzenten-Cluster zu erhalten. Suchen Auswahlhilfe auf der Konsole in AWS-Regionen, die RA3-Knotentypen unterstützen, um diesen Größenrechner zu verwenden. Beachten Sie, dass dies nur eine anfängliche Empfehlung für den Einstieg ist, und Sie sollten die Ausführung Ihrer vollständigen Arbeitslast auf dem Cluster mit der ursprünglichen Größe testen und die Größe des Clusters elastisch nach oben und unten anpassen, um die beste Preisleistung zu erzielen.
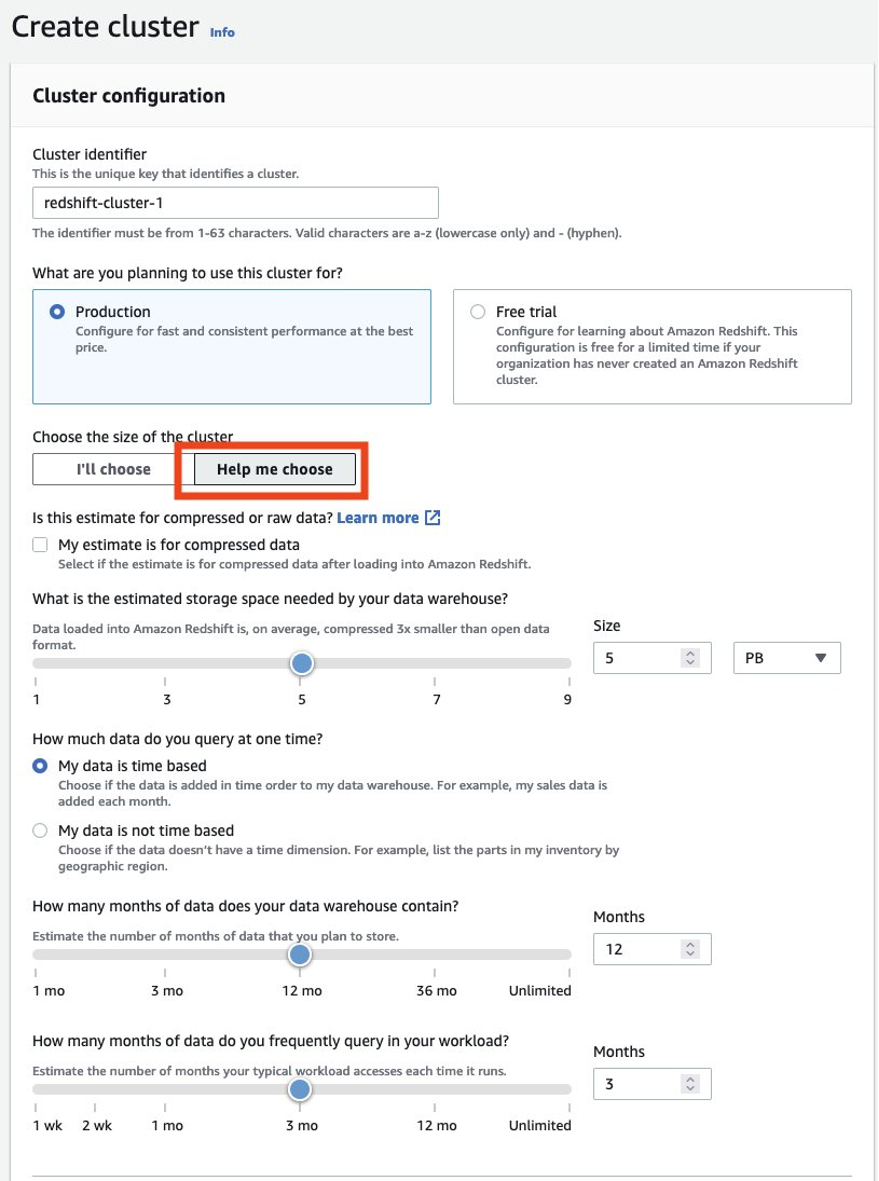
Größe und Einrichtung des anfänglichen Verbraucherclusters
Sie sollten Ihren Consumer-Cluster immer basierend auf Ihren Rechenanforderungen dimensionieren. Eine Möglichkeit für den Einstieg besteht darin, dem generischen Leitfaden zur Cluster-Größenbestimmung zu folgen, der dem obigen Producer-Cluster ähnelt.
Richten Sie die Amazon Redshift-Datenfreigabe ein
Richten Sie die Datenfreigabe vom Produzenten zum Konsumenten ein, sobald Sie sowohl den Produzenten- als auch den Konsumentencluster eingerichtet haben. Beziehen Sie sich darauf Post für Anleitungen zum Einrichten der Datenfreigabe.
Nur-Verbraucher-Workload auf anfänglichem Verbraucher-Cluster testen
Nur-Verbraucher-Workload auf dem neuen anfänglichen Verbraucher-Cluster testen. Dies kann erfolgen, indem Verbraucheranwendungen, z. B. ETL-Tools, BI-Anwendungen und SQL-Clients, auf den neuen Verbrauchercluster verweisen und die Arbeitslast erneut ausführen, um die Leistung anhand Ihrer Anforderungen zu bewerten.
Testen Sie nur Verbraucher-Workload auf verschiedenen Verbraucher-Cluster-Konfigurationen
Wenn der Consumer-Cluster der Anfangsgröße Ihre Arbeitslast-Leistungsanforderungen erfüllt oder übertrifft, können Sie diese Clusterkonfiguration entweder weiterhin verwenden oder kleinere Konfigurationen testen, um zu sehen, ob Sie die Kosten weiter senken und dennoch die benötigte Leistung erhalten können.
Wenn andererseits der Consumer-Cluster der Anfangsgröße Ihre Workload-Leistungsanforderungen nicht erfüllt, können Sie größere Konfigurationen weiter testen, um die Konfiguration zu erhalten, die Ihrem SLA entspricht.
Als Faustregel sollten Sie den Consumer-Cluster schrittweise um das Doppelte der anfänglichen Cluster-Konfiguration vergrößern, bis er Ihre Workload-Anforderungen erfüllt.
Nachdem Sie geplant haben, welche Konfiguration Sie testen möchten, verwenden Sie die elastische Größenanpassung, um die Größe des anfänglichen Clusters auf die Cluster-Zielkonfiguration zu ändern. Nachdem die elastische Größenänderung abgeschlossen ist, führen Sie denselben Workload-Test durch und bewerten Sie die Leistung anhand Ihres SLA. Wählen Sie die Konfiguration, die Ihrem Preis-Leistungs-Ziel entspricht.
Testen Sie nur die Producer-Workload auf verschiedenen Producer-Cluster-Konfigurationen
Sobald Sie Ihre Consumer-Workload in den Consumer-Cluster mit dem optimalen Preis-Leistungs-Verhältnis verschieben, besteht möglicherweise die Möglichkeit, die Rechenressourcen auf dem Producer zu reduzieren, um Kosten zu sparen.
Um dies zu erreichen, können Sie die Producer-Only-Workload mit dem 1/2-fachen der ursprünglichen Producer-Größe erneut ausführen und die Workload-Leistung auswerten. Die Größenanpassung des Clusters nach oben und unten hängt vom Ergebnis ab, und dann wählen Sie die minimale Producer-Konfiguration aus, die Ihren Workload-Leistungsanforderungen entspricht.
Nach einer vollständigen Workload im Laufe der Zeit neu bewerten
Mit der Weiterentwicklung von Amazon Redshift und der kontinuierlichen Veröffentlichung von Leistungs- und Skalierbarkeitsverbesserungen wird sich die Leistung beim Datenaustausch weiter verbessern. Darüber hinaus können sich zahlreiche Variablen auf die Leistung von Datenfreigabeabfragen auswirken. Im Folgenden sind nur einige Beispiele aufgeführt:
- Aufnahmerate und Datenmenge ändern sich
- Abfragemuster und Merkmal
- Änderungen der Arbeitsbelastung
- Nebenläufigkeit
- Wartungsaktivitäten, zum Beispiel Vakuum, Analyse und ATO
Aus diesem Grund müssen Sie die Größe des Producer- und Consumer-Clusters gelegentlich mit der obigen Strategie neu bewerten, insbesondere nach einer vollständigen Workload-Bereitstellung, um die neue beste Preisleistung aus der Konfiguration Ihres Clusters zu erzielen.
Automatisierte Größenlösungen
Wenn Ihre Umgebung eine komplexere Architektur umfasst, z. B. mit mehreren Tools oder Anwendungen (BI, Erfassung oder Streaming, ETL, Data Science), ist es möglicherweise nicht möglich, die manuelle Methode aus der allgemeinen Anleitung oben zu verwenden. Stattdessen können Sie die Lösungen in diesem Abschnitt nutzen, um die Arbeitslast aus Ihrem Produktionscluster automatisch auf den Testkonsumenten- und Produzentenclustern wiederzugeben, um die Leistung zu bewerten.
Einfaches Replay-Dienstprogramm wird als automatisierte Lösung genutzt, um Sie durch den Prozess zu führen, die richtige Erzeuger- und Verbraucherclustergröße für die beste Preisleistung zu erhalten.
Simple Replay ist ein Tool zum Durchführen einer Was-wäre-wenn-Analyse und zum Bewerten der Leistung Ihrer Workload in verschiedenen Szenarien. Sie können das Tool beispielsweise verwenden, um Ihre tatsächliche Arbeitslast auf einem neuen Instance-Typ wie RA3 zu vergleichen, eine neue Funktion zu evaluieren oder verschiedene Cluster-Konfigurationen zu bewerten. Es enthält auch erweiterte Unterstützung für die Wiedergabe von Datenaufnahme- und Export-Pipelines mit COPY- und UNLOAD-Anweisungen. Um zu beginnen und Ihre Workloads zu wiederholen, laden Sie das Tool von herunter Amazon Redshift-GitHub-Repository.
Hier führen wir die Schritte durch, um Ihre Workload-Protokolle aus dem Quellproduktionscluster zu extrahieren und sie in einer isolierten Umgebung wiederzugeben. Auf diese Weise können Sie nahtlos einen direkten Vergleich zwischen diesen Amazon Redshift-Clustern durchführen und die Cluster-Konfiguration auswählen, die Ihrem Preis-Leistungs-Ziel am besten entspricht.
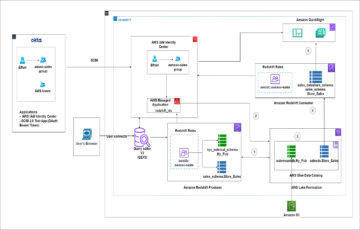
Das folgende Diagramm zeigt die Lösungsarchitektur.
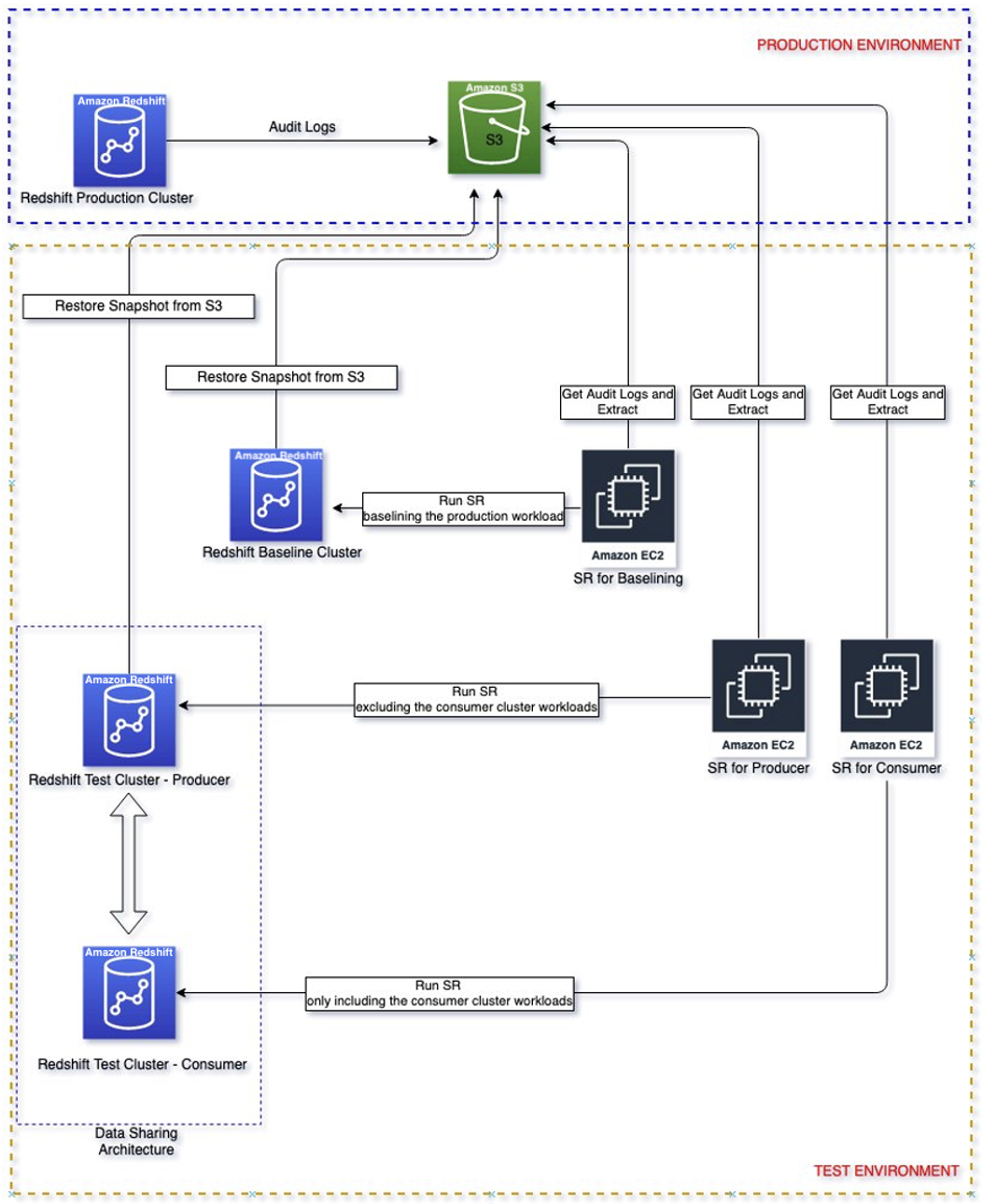
Lösungsweg
Befolgen Sie diese Schritte, um die Lösung zur Dimensionierung Ihrer Consumer- und Producer-Cluster durchzugehen.
Dimensionieren Sie Ihren Produktionscluster
Sie sollten immer sicherstellen, dass Sie Ihren vorhandenen Produktionscluster richtig dimensionieren, um die Leistung zu erhalten, die Sie benötigen, um Ihre Workload-Anforderungen zu erfüllen. Sie können den Größenrechner der Amazon Redshift-Konsole nutzen, um basierend auf der Größe Ihrer Daten und Abfragemerkmalen eine Empfehlung für den Produktionscluster zu erhalten. Suchen Auswahlhilfe auf der Konsole in AWS-Regionen, die RA3-Knotentypen unterstützen, um diesen Größenrechner zu verwenden. Beachten Sie, dass dies nur eine erste Empfehlung für den Einstieg ist. Sie sollten die Ausführung Ihrer vollständigen Arbeitslast auf dem Cluster der ursprünglichen Größe testen und die Größe des Clusters elastisch nach oben und unten anpassen, um das beste Preis-Leistungs-Verhältnis zu erzielen.
Identifizieren Sie die zu isolierende Workload
Auf Ihrem ursprünglichen Cluster werden möglicherweise unterschiedliche Workloads ausgeführt, aber der erste Schritt besteht darin, den kritischsten Workload für das Unternehmen zu identifizieren, den wir isolieren möchten. Dies liegt daran, dass wir sicherstellen möchten, dass die neue Architektur Ihre Workload-Anforderungen erfüllen kann. Diese Post ist eine gute Referenz zu einem Anwendungsfall zur Workload-Isolation mit gemeinsamer Datennutzung, der Ihnen bei der Entscheidung helfen kann, welche Workload isoliert werden kann.
Einfache Wiedergabe einrichten
Sobald Sie Ihre kritische Workload kennen, müssen Sie Aktivieren Sie die Audit-Protokollierung in Ihrem Produktionscluster, in dem die oben identifizierte kritische Workload ausgeführt wird, um Abfrageaktivitäten zu erfassen und zu speichern Einfacher Amazon-Speicherdienst (Amazon S3). Beachten Sie, dass es bis zu drei Stunden dauern kann, bis die Prüfprotokolle an Amazon S3 übermittelt werden. Sobald das Prüfprotokoll verfügbar ist, fahren Sie mit fort Einfache Wiedergabe einrichten und dann Extrakt die kritische Workload aus dem Audit-Log. Beachten Sie, dass start_time und end_time als Parameter verwendet werden könnten, um die kritische Workload herauszufiltern, wenn diese Workloads in bestimmten Zeiträumen ausgeführt werden, z. B. von 9:11 bis XNUMX:XNUMX Uhr. Andernfalls werden alle protokollierten Aktivitäten extrahiert.
Grundlegende Arbeitsbelastung
Erstellen Sie einen Baseline-Cluster mit derselben Konfiguration wie der Producer-Cluster, indem Sie ihn aus dem Produktions-Snapshot wiederherstellen. Der Zweck, mit derselben Konfiguration zu beginnen, besteht darin, die Leistung mit einer isolierten Umgebung abzugleichen.
Sobald der Baseline-Cluster verfügbar ist, Wiederholung die extrahierte Workload im Baseline-Cluster. Die Ausgabe dieser Wiedergabe ist die Basislinie, die zum Vergleich mit nachfolgenden Wiedergaben auf verschiedenen Verbraucherkonfigurationen verwendet wird.
Richten Sie anfängliche Producer- und Consumer-Testcluster ein
Erstellen Sie einen Producer-Cluster mit derselben Konfiguration des Produktionsclusters, indem Sie den Produktions-Snapshot wiederherstellen. Erstellen Sie einen Verbrauchercluster mit der empfohlenen anfänglichen Verbrauchergröße aus der vorherigen Anleitung. Richten Sie außerdem den Datenaustausch zwischen Erzeuger und Verbraucher ein.
Wiederholen Sie die Arbeitslast auf dem ursprünglichen Producer und Consumer
Replay die Producer-Only-Workload auf dem Producer-Cluster der Anfangsgröße. Dies kann mit dem Filterparameter „Exclude“ erreicht werden, um Verbraucherabfragen auszuschließen, z. B. den Benutzer, der Verbraucherabfragen ausführt.
Replay die reine Verbraucherarbeitslast auf dem Verbrauchercluster der anfänglichen Größe. Dies kann mit dem Filterparameter „Include“ erreicht werden, um Verbraucherabfragen auszuschließen, beispielsweise den Benutzer, der Verbraucherabfragen ausführt.
Bewerten Sie die Leistung dieser Wiedergaben anhand der Basislinien- und Workload-Leistungsanforderungen.
Wiederholen Sie die Verbraucherarbeitslast auf verschiedenen Konfigurationen
Wenn der Consumer-Cluster der Anfangsgröße Ihre Workload-Leistungsanforderungen erfüllt oder übertrifft, können Sie entweder diese Clusterkonfiguration verwenden oder diese Schritte ausführen, um kleinere Konfigurationen zu testen, um zu sehen, ob Sie die Kosten weiter senken und dennoch die benötigte Leistung erzielen können.
Vergleichen Sie die anfänglichen Ergebnisse der Verbraucherleistung mit Ihren Workload-Anforderungen:
- Wenn das Ergebnis Ihre Workload-Leistungsanforderungen übersteigt, können Sie die Größe des Consumer-Clusters schrittweise reduzieren, beginnend mit 1/2x, die Wiedergabe wiederholen und die Leistung bewerten, dann die Größe entsprechend dem Ergebnis vergrößern oder verkleinern, bis es Ihrer Workload entspricht Bedarf. Der Zweck besteht darin, einen optimalen Punkt zu finden, an dem Sie mit den Leistungsanforderungen zufrieden sind, und den niedrigstmöglichen Preis zu erzielen.
- Wenn das Ergebnis Ihre Workload-Leistungsanforderungen nicht erfüllt, können Sie die Größe des Clusters schrittweise erhöhen, beginnend mit dem Zweifachen der ursprünglichen Größe, die Wiedergabe wiederholen und die Leistung auswerten, bis sie Ihren Workload-Leistungsanforderungen entspricht.
Producer-Workload auf verschiedenen Konfigurationen wiedergeben
Nachdem Sie Ihre Workloads auf Consumer-Cluster aufgeteilt haben, sollte die Last auf dem Producer-Cluster reduziert werden, und Sie sollten die Workload-Leistung Ihres Producer-Clusters bewerten, um nach einer Möglichkeit zu suchen, die Größe zu verringern, um Kosten zu sparen.
Die Schritte ähneln der Verbraucherwiedergabe. Elastic ändert die Größe des Producer-Clusters inkrementell, beginnend mit dem 1/2-fachen der ursprünglichen Größe, gibt den Nur-Producer-Workload wieder und bewertet die Leistung und passt dann die Größe weiter nach oben oder unten an, bis er Ihren Workload-Leistungsanforderungen entspricht. Der Zweck besteht darin, einen idealen Punkt zu finden, an dem Sie mit den Anforderungen an die Workload-Leistung zufrieden sind, und den niedrigstmöglichen Preis zu erzielen. Sobald Sie die gewünschte Producer-Cluster-Konfiguration haben, versuchen Sie erneut, Consumer-Workloads auf dem Consumer-Cluster wiederzugeben, um sicherzustellen, dass die Leistung nicht durch Änderungen der Producer-Cluster-Konfiguration beeinträchtigt wurde. Schließlich sollten Sie sowohl Producer- als auch Consumer-Workloads gleichzeitig wiedergeben, um sicherzustellen, dass die Leistung in einem Szenario mit vollständiger Workload erreicht wird.
Nach einer vollständigen Workload im Laufe der Zeit neu bewerten
Ähnlich wie bei der allgemeinen Anleitung sollten Sie die Größe der Producer- und Consumer-Cluster gelegentlich mit der vorherigen Strategie neu bewerten, insbesondere nach der vollständigen Workload-Bereitstellung, um die neue beste Preisleistung aus der Konfiguration Ihres Clusters zu erzielen.
Aufräumen
Das Ausführen dieser Größentests in Ihrem AWS-Konto kann einige Kostenauswirkungen haben, da es neue Amazon Redshift-Cluster bereitstellt, die als On-Demand-Instances berechnet werden können, wenn Sie keine Reserved Instances haben. Wenn Sie Ihre Auswertungen abschließen, empfehlen wir, die Amazon Redshift-Cluster zu löschen, um Kosten zu sparen. Wir empfehlen außerdem, Ihre Cluster zu pausieren, wenn sie nicht verwendet werden.
Anwendung von Amazon Redshift und Best Practices für den Datenaustausch
Die richtige Dimensionierung Ihrer Erzeuger- und Verbraucher-Cluster gibt Ihnen einen guten Start, um das beste Preis-Leistungs-Verhältnis aus Ihrer Amazon Redshift-Bereitstellung zu erzielen. Die Größe ist jedoch nicht der einzige Faktor, der Ihre Leistung maximieren kann. In diesem Fall ist es ebenso wichtig, Best Practices zu verstehen und zu befolgen.
Allgemeine Best Practices zur Leistungsoptimierung von Amazon Redshift gelten für die Bereitstellung von Datenfreigaben. Stellen Sie sicher, dass Ihre Bereitstellung diesen folgt Best Practices.
Es gibt zahlreiche Best Practices für die gemeinsame Nutzung von Daten, die Sie befolgen sollten, um sicherzustellen, dass Sie die Leistung maximieren. Beziehen Sie sich darauf Post für weitere Informationen an.
Zusammenfassung
Es gibt keine allgemeingültige Empfehlung für die Größe von Produzenten- und Verbraucherclustern. Sie variiert je nach Workloads und Ihrem Leistungs-SLA. Der Zweck dieses Beitrags besteht darin, Ihnen eine Anleitung zu geben, wie Sie die Leistung Ihrer spezifischen Datenfreigabe-Workload bewerten können, um sowohl Verbraucher- als auch Erzeugerclustergrößen zu bestimmen, um die beste Preisleistung zu erzielen. Erwägen Sie, Ihre Workloads auf Producer und Consumer mit einfacher Wiedergabe zu testen, bevor Sie sie in der Produktion einsetzen, um das beste Preis-Leistungs-Verhältnis zu erzielen.
Über die Autoren
 BP Yau ist Senior Product Manager bei AWS. Er ist begeistert davon, Kunden bei der Entwicklung von Big-Data-Lösungen zu unterstützen, um Daten in großem Maßstab zu verarbeiten. Vor AWS half er Amazon.com Supply Chain Optimization Technologies bei der Migration seines Oracle Data Warehouse zu Amazon Redshift und beim Aufbau seiner Big-Data-Analyseplattform der nächsten Generation mit AWS-Technologien.
BP Yau ist Senior Product Manager bei AWS. Er ist begeistert davon, Kunden bei der Entwicklung von Big-Data-Lösungen zu unterstützen, um Daten in großem Maßstab zu verarbeiten. Vor AWS half er Amazon.com Supply Chain Optimization Technologies bei der Migration seines Oracle Data Warehouse zu Amazon Redshift und beim Aufbau seiner Big-Data-Analyseplattform der nächsten Generation mit AWS-Technologien.
 Sidhanth Muralidhar ist Principal Technical Account Manager bei AWS. Er arbeitet mit großen Unternehmenskunden zusammen, die ihre Workloads auf AWS ausführen. Er arbeitet leidenschaftlich gerne mit Kunden zusammen und hilft ihnen, Workloads auf ihrer Cloud-Reise im Hinblick auf Kosten, Zuverlässigkeit, Leistung und operative Exzellenz in großem Umfang zu entwerfen. Er interessiert sich auch sehr für Data Analytics.
Sidhanth Muralidhar ist Principal Technical Account Manager bei AWS. Er arbeitet mit großen Unternehmenskunden zusammen, die ihre Workloads auf AWS ausführen. Er arbeitet leidenschaftlich gerne mit Kunden zusammen und hilft ihnen, Workloads auf ihrer Cloud-Reise im Hinblick auf Kosten, Zuverlässigkeit, Leistung und operative Exzellenz in großem Umfang zu entwerfen. Er interessiert sich auch sehr für Data Analytics.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/how-to-get-best-price-performance-from-your-amazon-redshift-data-sharing-deployment/
- 100
- a
- Über uns
- oben
- entsprechend
- Konto
- Trading Konten
- Erreichen
- erreicht
- über
- Aktivitäten
- hinzugefügt
- Die Annahme
- Nach der
- gegen
- Alle
- erlaubt
- immer
- Amazon
- Amazon.com
- Betrag
- Analyse
- Analytik
- analysieren
- und
- Ein anderer
- anwendbar
- Anwendungen
- Ansatz
- Architektur
- Prüfung
- Automatisiert
- Im Prinzip so, wie Sie es von Google Maps kennen.
- verfügbar
- AWS
- basierend
- Baseline
- weil
- Bevor
- Benchmark
- BESTE
- Best Practices
- Besser
- zwischen
- Big
- Big Data
- bauen
- Geschäft
- Erfassung
- Häuser
- Fälle
- sicher
- Kette
- Änderungen
- Merkmal
- Charakteristik
- berechnet
- Kunden
- Cloud
- Cluster
- COM
- komfortabel
- gemeinsam
- vergleichen
- Vergleich
- abschließen
- Abgeschlossene Verkäufe
- Komplex
- Komplexität
- Berechnen
- Leitung
- Konfiguration
- Geht davon
- konsistent
- Konsul (Console)
- Verbraucher
- fortsetzen
- weiter
- kontinuierlich
- Kosten
- Kosten
- könnte
- erstellen
- kritischem
- Kunden
- technische Daten
- Datenanalyse
- Datenwissenschaft
- Datenübertragung
- geliefert
- hängt
- Einsatz
- Details
- Bestimmen
- anders
- Direkt
- Nicht
- nach unten
- herunterladen
- im
- leicht
- entweder
- ermöglicht
- verbesserte
- Unternehmen
- Arbeitsumfeld
- gleichermaßen
- insbesondere
- Äther (ETH)
- bewerten
- Auswertungen
- sich entwickelnden
- Beispiel
- Beispiele
- übersteigt
- Exzellenz
- vorhandenen
- exportieren
- Extrakt
- scheitert
- FAST
- möglich
- Merkmal
- Filter
- Endlich
- Vorname
- Flexibilität
- folgen
- Folgende
- folgt
- für
- voller
- grundlegend
- weiter
- Außerdem
- Gewinnen
- allgemein
- Generation
- bekommen
- bekommen
- GitHub
- ABSICHT
- Go
- gut
- Guide
- Hilfe
- dazu beigetragen,
- Unternehmen
- STUNDEN
- Ultraschall
- Hilfe
- aber
- HTTPS
- identifiziert
- identifizieren
- Impact der HXNUMXO Observatorien
- wirkt
- umgesetzt
- Auswirkungen
- wichtig
- Verbesserung
- Verbesserung
- in
- Dazu gehören
- Erhöhung
- Anfangs-
- anfänglich
- Instanz
- beantragen müssen
- Interesse
- beteiligt
- isoliert
- Isolierung
- IT
- Reise
- Scharf
- Wissen
- grosse
- größer
- ins Leben gerufen
- Lasst uns
- Hebelwirkung
- leben
- Belastung
- aussehen
- Wartung
- um
- Manager
- manuell
- Maximieren
- Triff
- Trifft
- Methode
- könnte
- migriert
- Minimum
- Modell
- mehr
- vor allem warme
- schlauer bewegen
- Bewegung
- mehrere
- Need
- benötigen
- Bedürfnisse
- Neu
- weiter
- Knoten
- und viele
- Anlass
- Onboard
- EINEM
- Betriebs-
- Gelegenheit
- Optimierung
- Optimum
- Orakel
- Original
- Andere
- Andernfalls
- Parameter
- Parameter
- leidenschaftlich
- Schnittmuster
- ausführen
- Leistung
- führt
- Zeiträume
- Plan
- Plattform
- Plato
- Datenintelligenz von Plato
- PlatoData
- Points
- möglich
- Post
- Praktiken
- früher
- Preis
- Principal
- Prozessdefinierung
- Hersteller
- Produkt
- Produkt-Manager
- Produktion
- richtig
- die
- bietet
- Zweck
- Fragen
- Bewerten
- empfehlen
- Software Empfehlungen
- empfohlen
- Veteran
- Reduziert
- Regionen
- Mitteilungen
- Zuverlässigkeit
- Voraussetzungen:
- reserviert
- Ressourcen
- Wiederherstellen
- Folge
- Die Ergebnisse
- Regel
- Führen Sie
- Laufen
- gleich
- Speichern
- Skalierbarkeit
- skalierbaren
- Skalieren
- Szenarien
- Wissenschaft
- nahtlos
- Abschnitt
- Verbindung
- sicher
- Suchen
- Setup
- Teilen
- ,,teilen"
- sollte
- erklären
- Konzerte
- ähnlich
- Einfacher
- Größe
- Größen
- kleinere
- Schnappschuss
- Lösung
- Lösungen
- einige
- Quelle
- spezifisch
- gespalten
- Spot
- Standard
- Anfang
- begonnen
- Beginnen Sie
- Aussagen
- Schritt
- Shritte
- Immer noch
- Lagerung
- speichern
- Strategie
- Streaming
- Folge
- liefern
- Supply Chain
- Optimierung der Lieferkette
- Support
- süß
- Nehmen
- Target
- Technische
- Technologies
- Test
- Testen
- Tests
- Das
- Die Quelle
- ihr
- nach drei
- Durch
- Zeit
- zu
- Werkzeug
- Werkzeuge
- Typen
- Verständnis
- -
- Anwendungsfall
- Mitglied
- Vakuum
- Was
- welche
- WHO
- werden wir
- ohne
- arbeiten,
- Werk
- Ihr
- Zephyrnet