Einleitung
Wir haben einige ausgefallene Begriffe für KI und Deep Learning gesehen, wie z. B. vortrainierte Modelle, Transferlernen usw. Lassen Sie mich Sie mit einer weit verbreiteten Technologie und einer der wichtigsten und effektivsten aufklären: Transferlernen mit YOLOv5.
You Only Look Once oder YOLO ist eine der am weitesten verbreiteten Deep-Learning-basierten Objektidentifikationsmethoden. Anhand eines benutzerdefinierten Datensatzes zeigt Ihnen dieser Artikel, wie Sie eine der neuesten Variationen, YOLOv5, trainieren.
Lernziele
- Dieser Artikel konzentriert sich hauptsächlich auf das Training des YOLOv5-Modells für eine benutzerdefinierte Dataset-Implementierung.
- Wir werden sehen, was vortrainierte Modelle sind und was Transferlernen ist.
- Wir werden verstehen, was YOLOv5 ist und warum wir Version 5 von YOLO verwenden.
Beginnen wir also, ohne Zeit zu verlieren, mit dem Prozess
Inhaltsverzeichnis
- Vortrainierte Modelle
- Lernen übertragen
- Was und warum YOLOv5?
- Schritte beim Transferlernen
- Sytemimplementierung
- Einige Herausforderungen, denen Sie sich stellen können
- Zusammenfassung
Vortrainierte Modelle
Sie haben vielleicht gehört, dass Data Scientists häufig den Begriff „vortrainiertes Modell“ verwenden. Nachdem ich erklärt habe, was ein Deep-Learning-Modell/Netzwerk tut, werde ich den Begriff erklären. Ein Deep-Learning-Modell ist ein Modell, das verschiedene Schichten enthält, die zusammengestapelt sind, um einem einsamen Zweck zu dienen, wie z werden später verwendet, um ähnliche Aufgaben auszuführen. Vortrainierte Modelle sind bereits trainierte Deep-Learning-Modelle. Das bedeutet, dass sie bereits auf einem riesigen Datensatz mit Millionen von Bildern trainiert sind.
Hier ist wie die TensorFlow Website definiert vortrainierte Modelle: Ein vorab trainiertes Modell ist ein gespeichertes Netzwerk, das zuvor mit einem großen Datensatz trainiert wurde, typischerweise mit einer umfangreichen Bildklassifizierungsaufgabe.
Einige hochoptimiert und außerordentlich effizient vorgefertigte Modelle sind im Internet verfügbar. Unterschiedliche Modelle werden verwendet, um unterschiedliche Aufgaben zu erfüllen. Einige der vortrainierten Modelle sind VGG-16, VGG-19, YOLOv5, YOLOv3 und ResNet 50.
Welches Modell zu verwenden ist, hängt von der Aufgabe ab, die Sie ausführen möchten. Wenn ich zum Beispiel eine durchführen möchte Objekterkennung Aufgabe, werde ich das YOLOv5-Modell verwenden.
Lernen übertragen
Lernen übertragen ist die wichtigste Technik, die die Aufgabe eines Datenwissenschaftlers erleichtert. Das Trainieren eines Modells ist eine gewaltige und zeitaufwändige Aufgabe. Wenn ein Modell von Grund auf neu trainiert wird, liefert es normalerweise keine sehr guten Ergebnisse. Selbst wenn wir ein Modell ähnlich wie ein vortrainiertes Modell trainieren, wird es nicht so effektiv funktionieren, und es kann Wochen dauern, bis ein Modell trainiert ist. Stattdessen können wir die vortrainierten Modelle verwenden und die bereits erlernten Gewichtungen verwenden, indem wir sie mit einem benutzerdefinierten Dataset trainieren, um eine ähnliche Aufgabe auszuführen. Diese Modelle sind in Bezug auf Architektur und Leistung hocheffizient und raffiniert und haben sich durch bessere Leistungen in verschiedenen Wettbewerben an die Spitze gekämpft. Diese Modelle werden mit sehr großen Datenmengen trainiert, wodurch ihr Wissen vielfältiger wird.
Transfer Learning bedeutet also im Grunde die Übertragung von Wissen, das durch das Training des Modells mit früheren Daten gewonnen wurde, um dem Modell zu helfen, besser und schneller zu lernen, um eine andere, aber ähnliche Aufgabe auszuführen.
Verwenden Sie beispielsweise ein YOLOv5 für die Objekterkennung, aber das Objekt ist etwas anderes als die zuvor verwendeten Daten des Objekts.
Was und warum YOLOv5?
YOLOv5 ist ein vortrainiertes Modell, das dafür steht, dass Sie nur schauen, sobald Version 5 für die Objekterkennung in Echtzeit verwendet wird und sich in Bezug auf Genauigkeit und Inferenzzeit als äußerst effizient erwiesen hat. Es gibt andere Versionen von YOLO, aber wie man vorhersagen würde, schneidet YOLOv5 besser ab als andere Versionen. YOLOv5 ist schnell und einfach zu bedienen. Es basiert auf dem PyTorch-Framework, das eine größere Community hat als Yolo v4 Darknet.
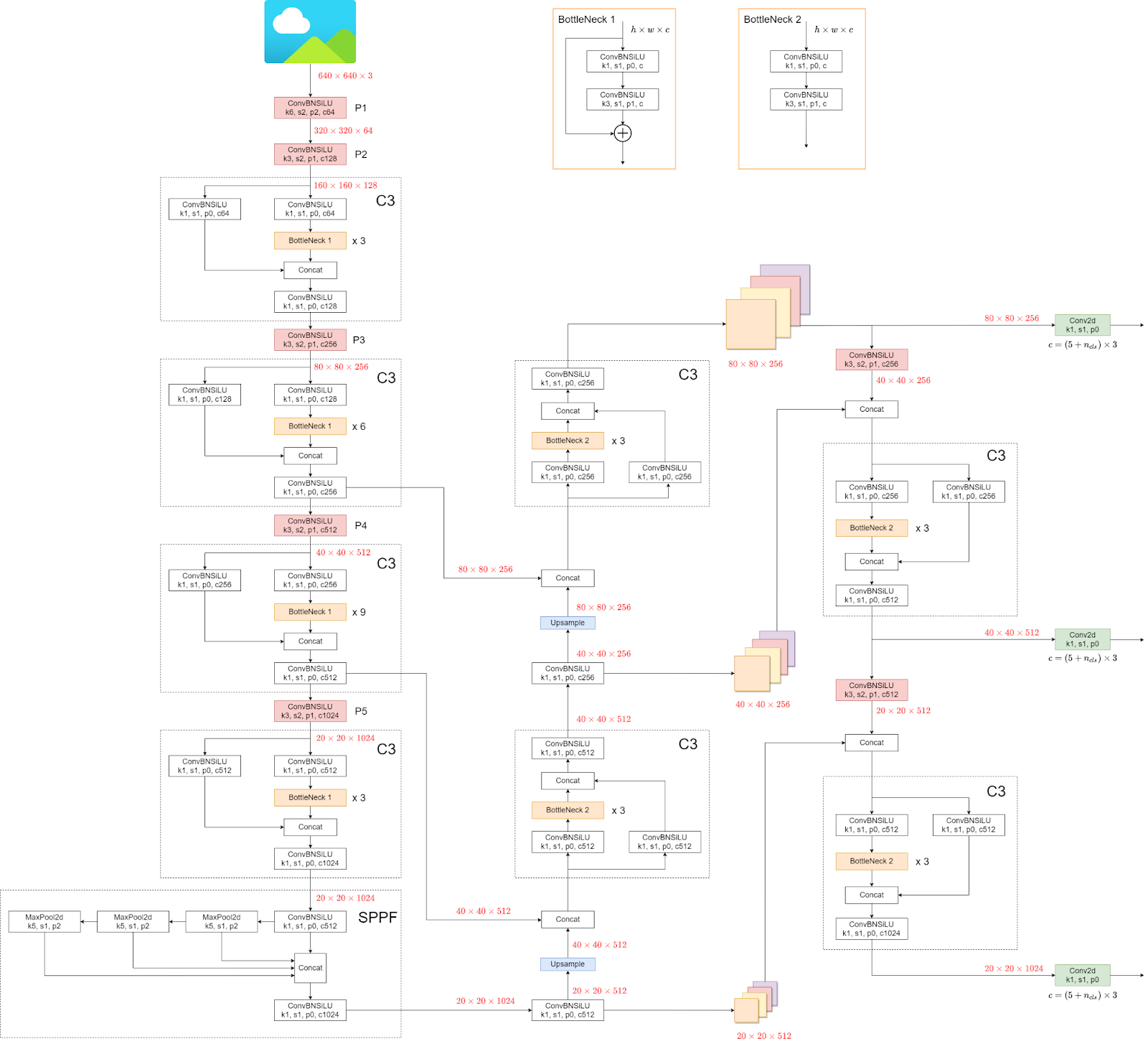
Wir werden uns nun die Architektur von YOLOv5 ansehen.
Die Struktur mag verwirrend aussehen, aber das macht nichts, da wir nicht auf die Architektur schauen müssen, sondern direkt das Modell und die Gewichte verwenden.
Beim Transferlernen verwenden wir den benutzerdefinierten Datensatz, dh die Daten, die das Modell noch nie zuvor gesehen hat, ODER die Daten, mit denen das Modell nicht trainiert wurde. Da das Modell bereits auf einem großen Datensatz trainiert wurde, haben wir bereits die Gewichtungen. Wir können das Modell jetzt für eine Reihe von Epochen mit den Daten trainieren, an denen wir arbeiten möchten. Eine Schulung ist erforderlich, da das Modell die Daten zum ersten Mal gesehen hat und einige Kenntnisse erforderlich sind, um die Aufgabe auszuführen.
Schritte beim Transfer Learning
Transfer Learning ist ein einfacher Prozess, und wir können ihn in ein paar einfachen Schritten durchführen:
- Datenaufbereitung
- Das richtige Format für die Anmerkungen
- Ändern Sie ein paar Ebenen, wenn Sie möchten
- Trainieren Sie das Modell für einige Iterationen neu
- Validieren/Testen
Datenaufbereitung
Die Datenvorbereitung kann zeitaufwändig sein, wenn Ihre ausgewählten Daten etwas groß sind. Datenvorbereitung bedeutet, die Bilder mit Anmerkungen zu versehen. Dabei handelt es sich um einen Vorgang, bei dem Sie die Bilder beschriften, indem Sie einen Rahmen um das Objekt im Bild ziehen. Dabei werden die Koordinaten des markierten Objekts in einer Datei gespeichert, die dann dem Modell zum Training zugeführt wird. Es gibt ein paar Websites, wie z machtsinn.ai und roboflow.com, die Ihnen helfen können, die Daten zu kennzeichnen.
So können Sie die Daten für das YOLOv5-Modell auf makesense.ai kommentieren.
1. Besuchen Sie https://www.makesense.ai/.
2. Klicken Sie unten rechts auf dem Bildschirm auf Loslegen.
3. Wählen Sie die Bilder aus, die Sie beschriften möchten, indem Sie auf das in der Mitte hervorgehobene Kästchen klicken.
Laden Sie die Bilder, die Sie kommentieren möchten, und klicken Sie auf Objekterkennung.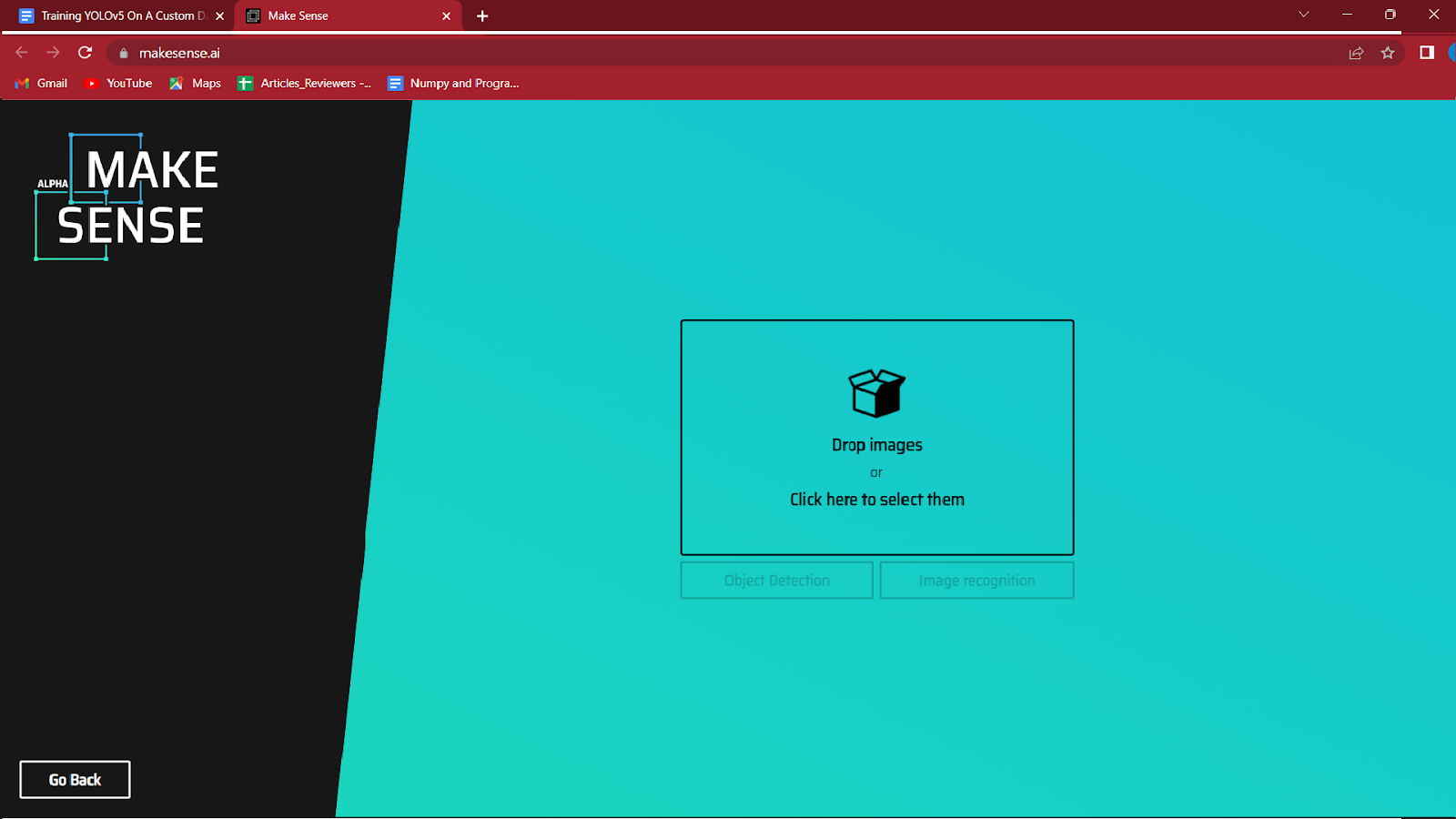
4. Nach dem Laden der Bilder werden Sie aufgefordert, Beschriftungen für die verschiedenen Klassen Ihres Datensatzes zu erstellen.
Ich erkenne Nummernschilder an einem Fahrzeug, also werde ich nur „Kennzeichen“ verwenden. Sie können weitere Etiketten erstellen, indem Sie einfach die Eingabetaste drücken, indem Sie auf die Schaltfläche „+“ auf der linken Seite des Dialogfelds klicken.
Nachdem Sie alle Etiketten erstellt haben, klicken Sie auf Projekt starten.
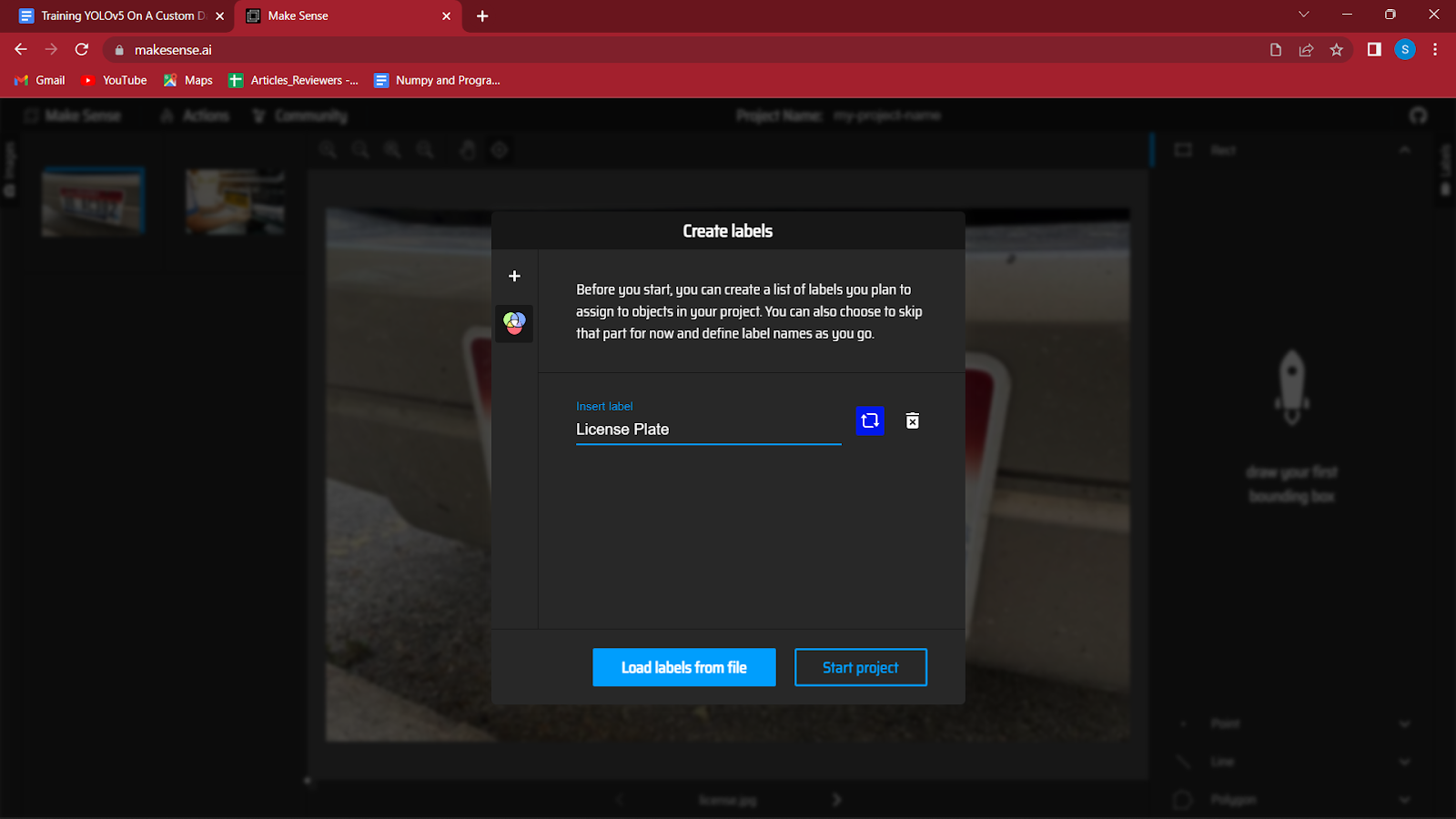
Wenn Sie Labels verpasst haben, können Sie diese später bearbeiten, indem Sie auf Aktionen klicken und dann Labels bearbeiten.
5. Erstellen Sie einen Begrenzungsrahmen um das Objekt im Bild. Diese Übung mag anfangs ein bisschen Spaß machen, aber bei sehr großen Datenmengen kann sie ermüdend sein.
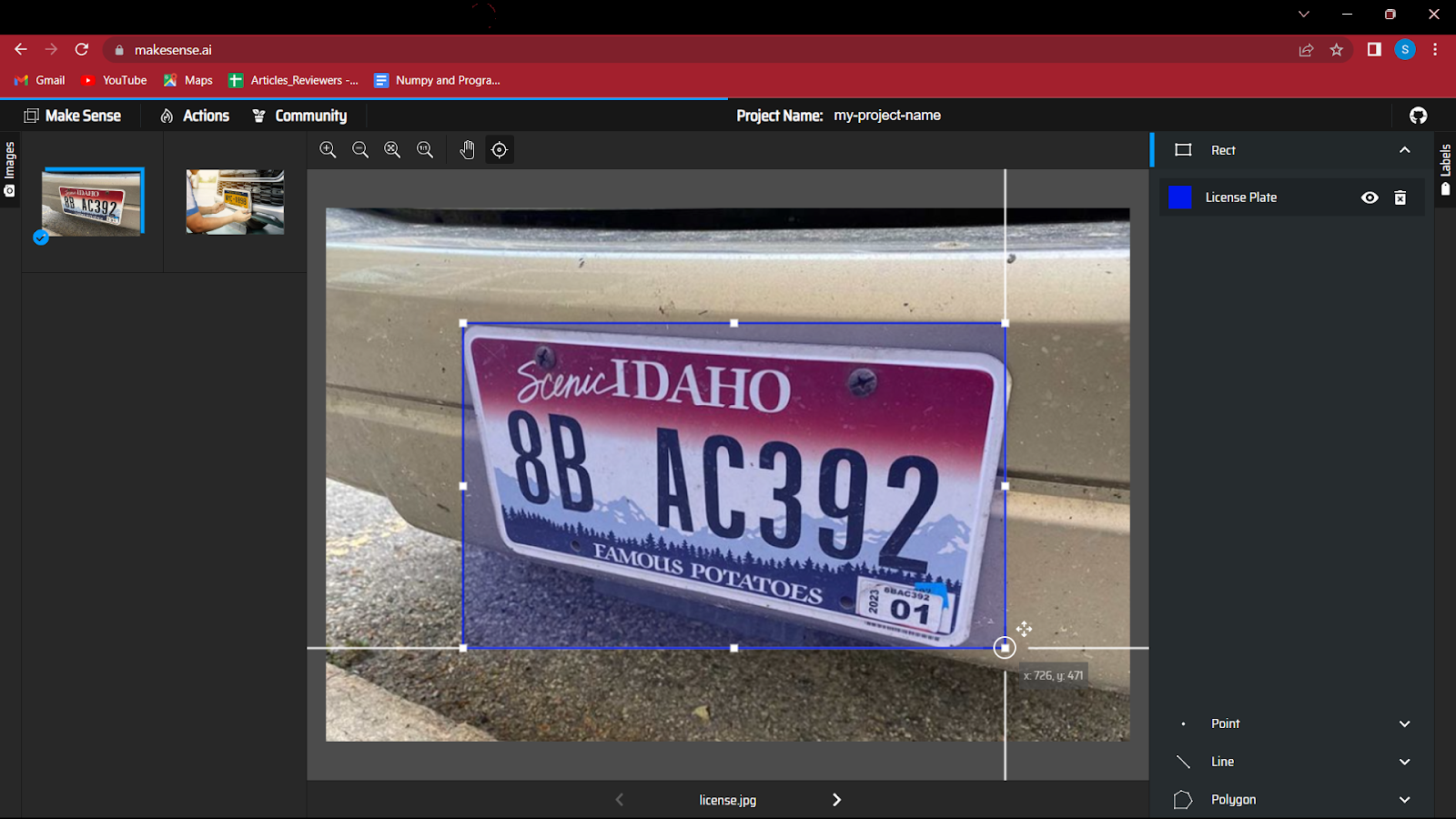
6. Nachdem Sie alle Bilder mit Anmerkungen versehen haben, müssen Sie die Datei speichern, die die Koordinaten der Begrenzungsrahmen zusammen mit der Klasse enthält.
Sie müssen also zur Schaltfläche „Aktionen“ gehen und auf „Anmerkungen exportieren“ klicken. Vergessen Sie nicht, die Option „Ein Zip-Paket mit Dateien im YOLO-Format“ zu aktivieren, da dies die Dateien im richtigen Format speichert, wie es im YOLO-Modell erforderlich ist.
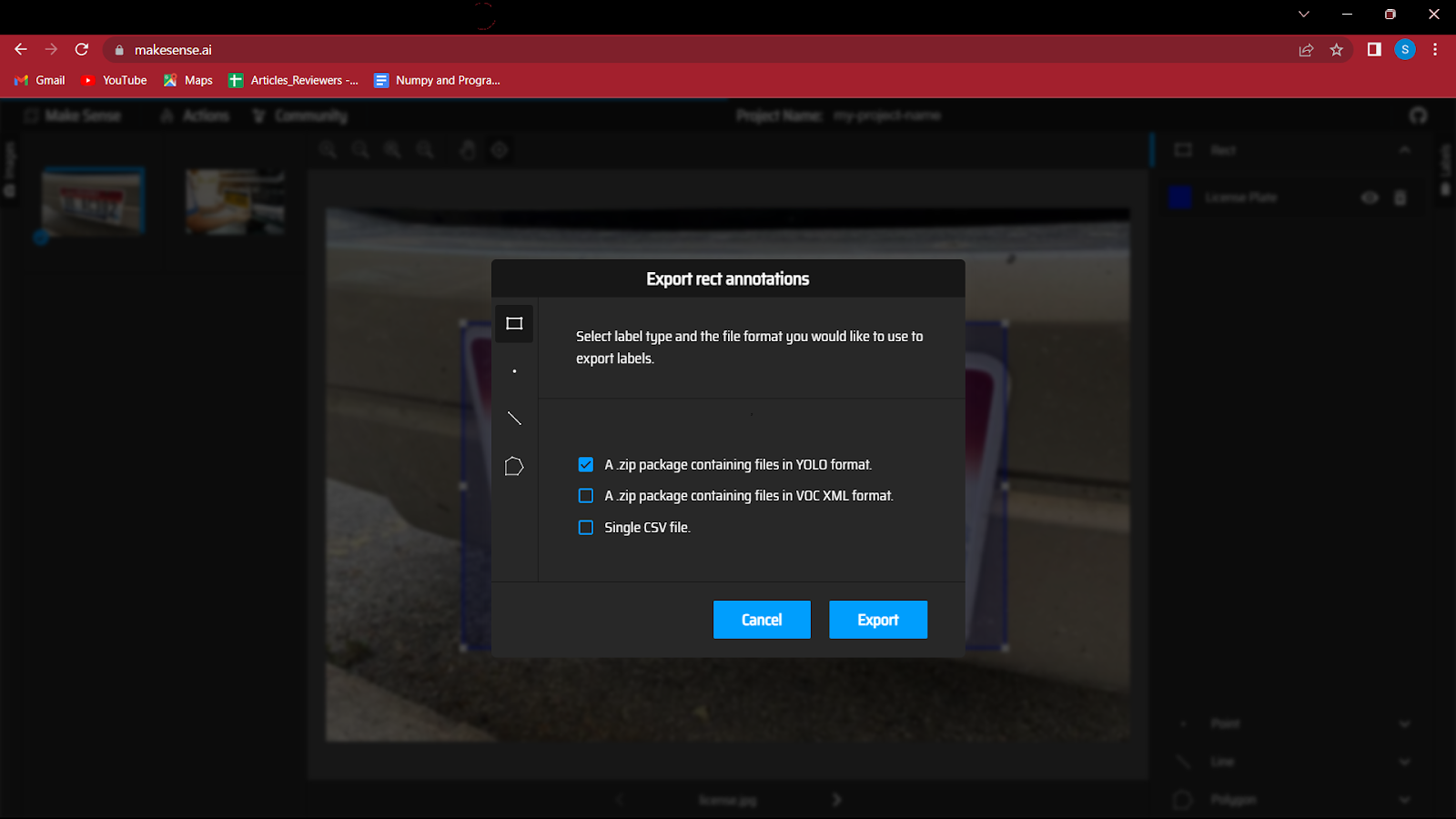
7. Dies ist ein wichtiger Schritt, also folgen Sie ihm sorgfältig.
Nachdem Sie alle Dateien und Bilder haben, erstellen Sie einen Ordner mit einem beliebigen Namen. Klicken Sie auf den Ordner und erstellen Sie zwei weitere Ordner mit den Namensbildern und Etiketten im Ordner. Vergessen Sie nicht, den Ordner wie oben zu benennen, da das Modell automatisch nach Labels sucht, nachdem Sie den Trainingspfad im Befehl eingegeben haben.
Um Ihnen eine Vorstellung von dem Ordner zu geben, habe ich einen Ordner mit dem Namen „CarsData“ erstellt und in diesem Ordner zwei Ordner angelegt – „images“ und „labels“.
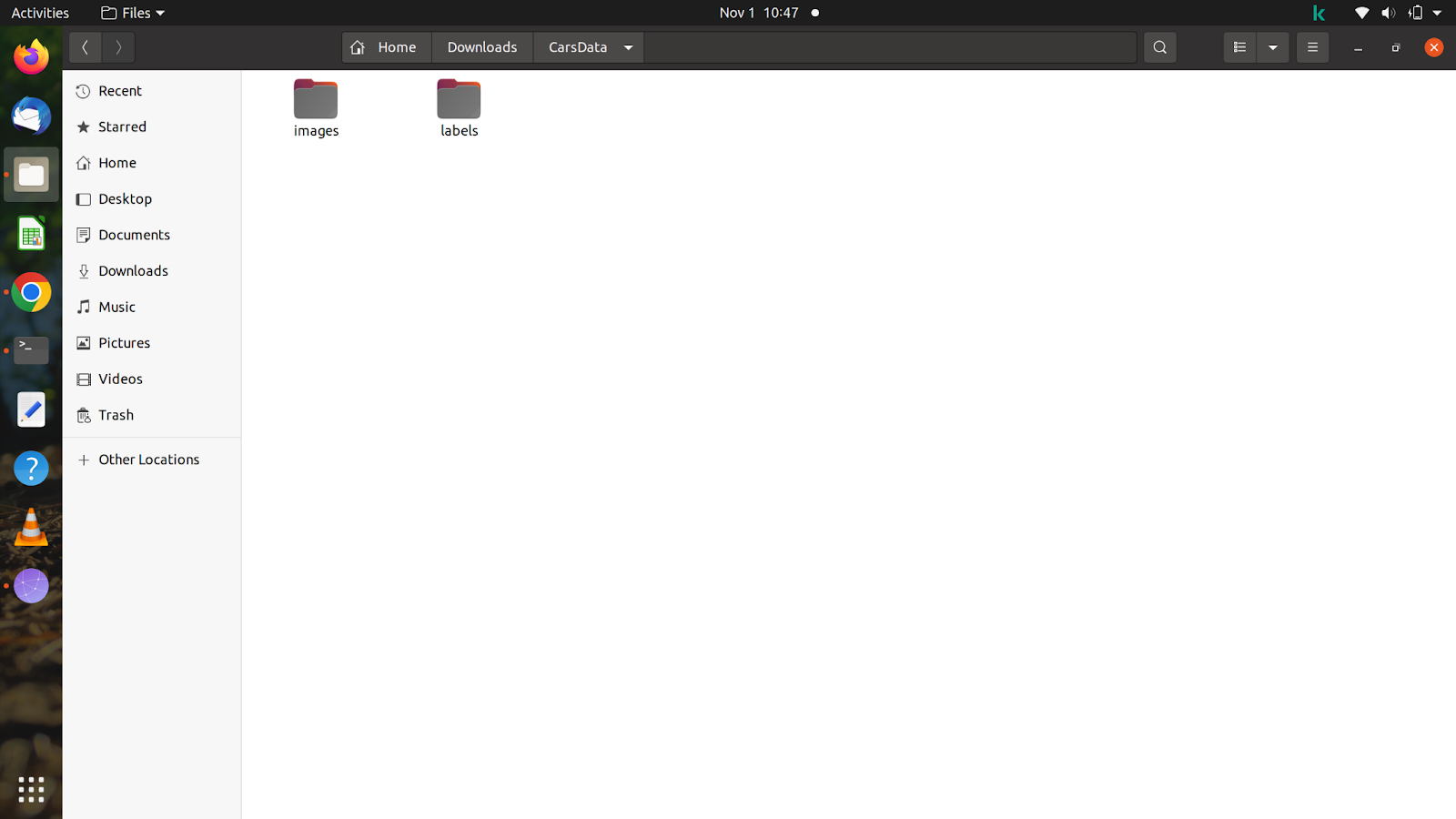
Innerhalb der beiden Ordner müssen Sie zwei weitere Ordner mit den Namen „train“ und „val“ erstellen. Im Bilderordner können Sie die Bilder nach Belieben aufteilen, aber Sie müssen beim Aufteilen der Beschriftung vorsichtig sein, da die Beschriftungen mit den von Ihnen aufgeteilten Bildern übereinstimmen sollten
8. Erstellen Sie nun eine ZIP-Datei des Ordners und laden Sie sie auf das Laufwerk hoch, damit wir sie in Colab verwenden können.
Sytemimplementierung
Wir kommen nun zum Implementierungsteil, der sehr einfach, aber knifflig ist. Wenn Sie nicht genau wissen, welche Dateien geändert werden sollen, können Sie das Modell nicht mit dem benutzerdefinierten Dataset trainieren.
Hier sind also die Codes, die Sie befolgen sollten, um das YOLOv5-Modell mit einem benutzerdefinierten Dataset zu trainieren
Ich empfehle Ihnen, Google Colab für dieses Tutorial zu verwenden, da es auch eine GPU bietet, die schnellere Berechnungen ermöglicht.
1. !git-Klon https://github.com/ultralytics/yolov5
Dadurch wird eine Kopie des YOLOv5-Repositorys erstellt, bei dem es sich um ein von Ultralytics erstelltes GitHub-Repository handelt.
2. CD yolov5
Dies ist ein Befehlszeilen-Shell-Befehl, der verwendet wird, um das aktuelle Arbeitsverzeichnis in das YOLOv5-Verzeichnis zu ändern.
3. !pip install -r Anforderungen.txt
Dieser Befehl installiert alle Pakete und Bibliotheken, die beim Trainieren des Modells verwendet werden.
4. Entpacken Sie '/content/drive/MyDrive/CarsData.zip'
Entpacken des Ordners, der Bilder und Labels in Google Colab enthält
Hier kommt der wichtigste Schritt…
Sie haben jetzt fast alle Schritte ausgeführt und müssen eine weitere Codezeile schreiben, die das Modell trainiert, aber zuvor müssen Sie einige weitere Schritte ausführen und einige Verzeichnisse ändern, um den Pfad Ihres benutzerdefinierten Datensatzes anzugeben und trainieren Sie Ihr Modell mit diesen Daten.
Hier ist was du tun musst.
Nachdem Sie die 4 obigen Schritte ausgeführt haben, haben Sie den Ordner yolov5 in Ihrem Google Colab. Gehen Sie zum Ordner yolov5 und klicken Sie auf den Ordner „data“. Jetzt sehen Sie einen Ordner mit dem Namen ‚coco128.yaml‘.
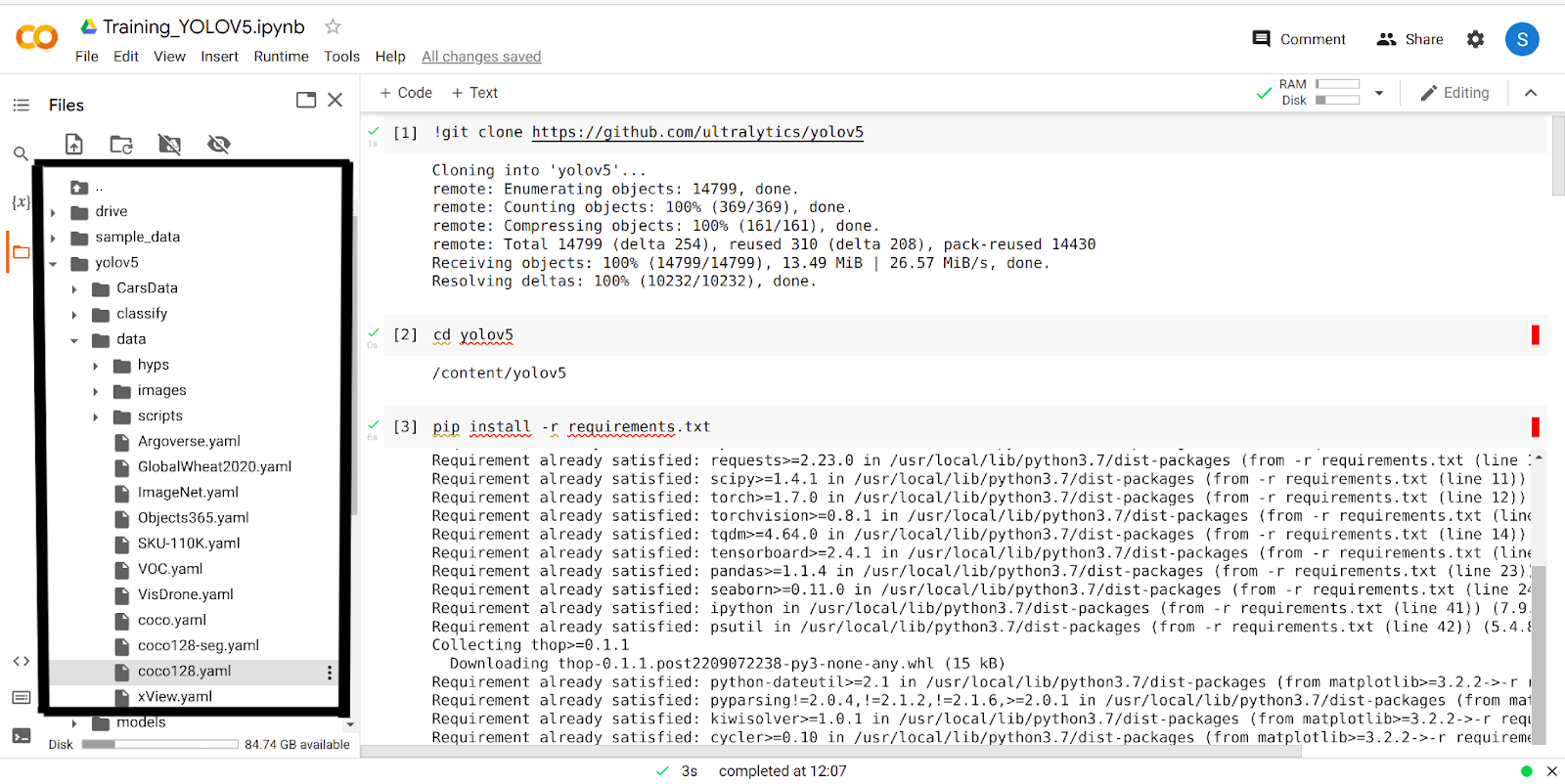
Fahren Sie fort und laden Sie diesen Ordner herunter.
Nachdem der Ordner heruntergeladen wurde, müssen Sie einige Änderungen daran vornehmen und ihn wieder in denselben Ordner hochladen, aus dem Sie ihn heruntergeladen haben.
Schauen wir uns nun den Inhalt der Datei an, die wir heruntergeladen haben, und er wird ungefähr so aussehen.
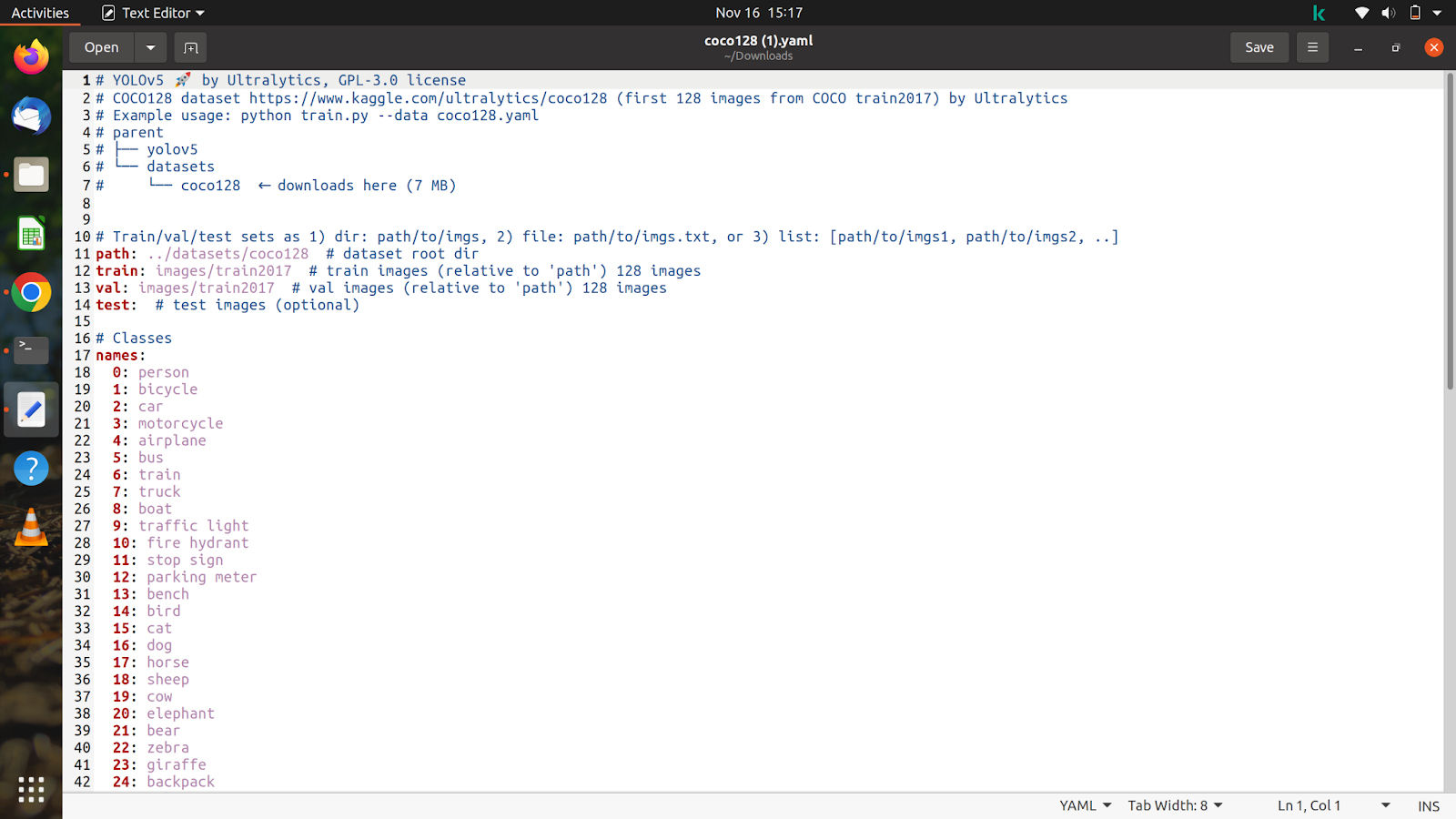
Wir werden diese Datei gemäß unserem Datensatz und unseren Anmerkungen anpassen.
Wir haben den Datensatz bereits auf Colab entpackt, also kopieren wir den Pfad unserer Zug- und Validierungsbilder. Nachdem Sie den Pfad der Zugbilder kopiert haben, der sich im Datensatzordner befindet und in etwa so aussieht: „/content/yolov5/CarsData/images/train“, fügen Sie ihn in die coco128.yaml-Datei ein, die wir gerade heruntergeladen haben.
Machen Sie dasselbe mit den Test- und Validierungsbildern.
Nachdem wir damit fertig sind, erwähnen wir die Anzahl der Klassen wie 'nc: 1'. Die Anzahl der Klassen beträgt in diesem Fall nur 1. Wir nennen dann den Namen wie im Bild unten gezeigt. Entfernen Sie alle anderen Klassen und den kommentierten Teil, der nicht benötigt wird, danach sollte unsere Datei ungefähr so aussehen.
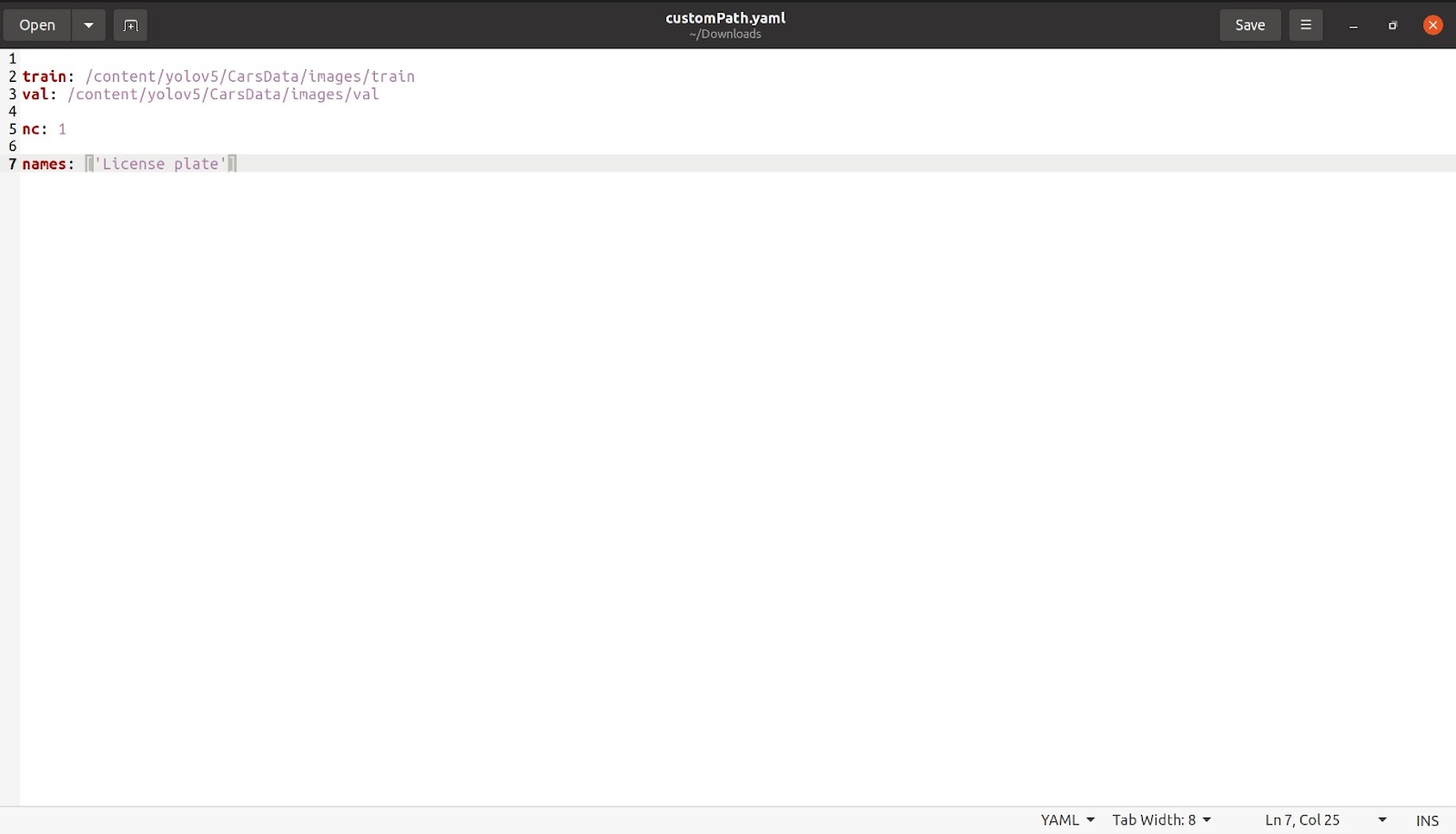
Speichern Sie diese Datei unter einem beliebigen Namen. Ich habe die Datei mit dem Namen customPath.yaml gespeichert und lade diese Datei nun wieder in das Colab an der gleichen Stelle hoch, wo coco128.yaml war.
Jetzt sind wir mit dem Bearbeitungsteil fertig und bereit, das Modell zu trainieren.
Führen Sie den folgenden Befehl aus, um Ihr Modell für einige Interaktionen mit Ihrem benutzerdefinierten Dataset zu trainieren.
Vergessen Sie nicht, den Namen der hochgeladenen Datei ('customPath.yaml) zu ändern. Sie können auch die Anzahl der Epochen ändern, in denen Sie das Modell trainieren möchten. In diesem Fall werde ich das Modell nur für 3 Epochen trainieren.
5. !python train.py –img 640 –batch 16 –epochs 10 –data /content/yolov5/customPath.yaml –weights yolov5s.pt
Merken Sie sich den Pfad, in den Sie den Ordner hochladen. Wenn der Pfad geändert wird, funktionieren die Befehle überhaupt nicht.
Nachdem Sie diesen Befehl ausgeführt haben, sollte Ihr Modell mit dem Training beginnen und Sie werden so etwas wie dieses auf Ihrem Bildschirm sehen.
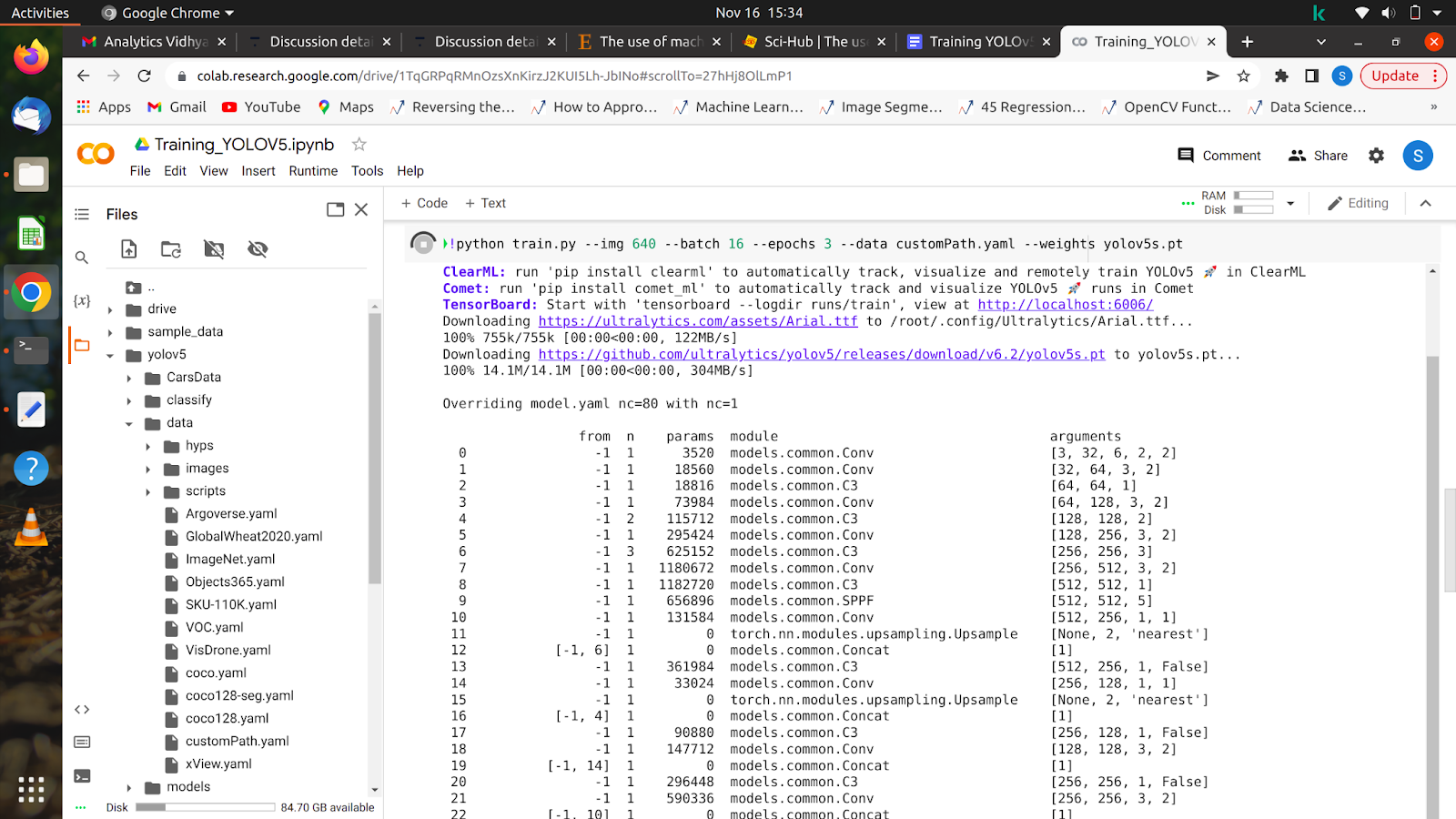
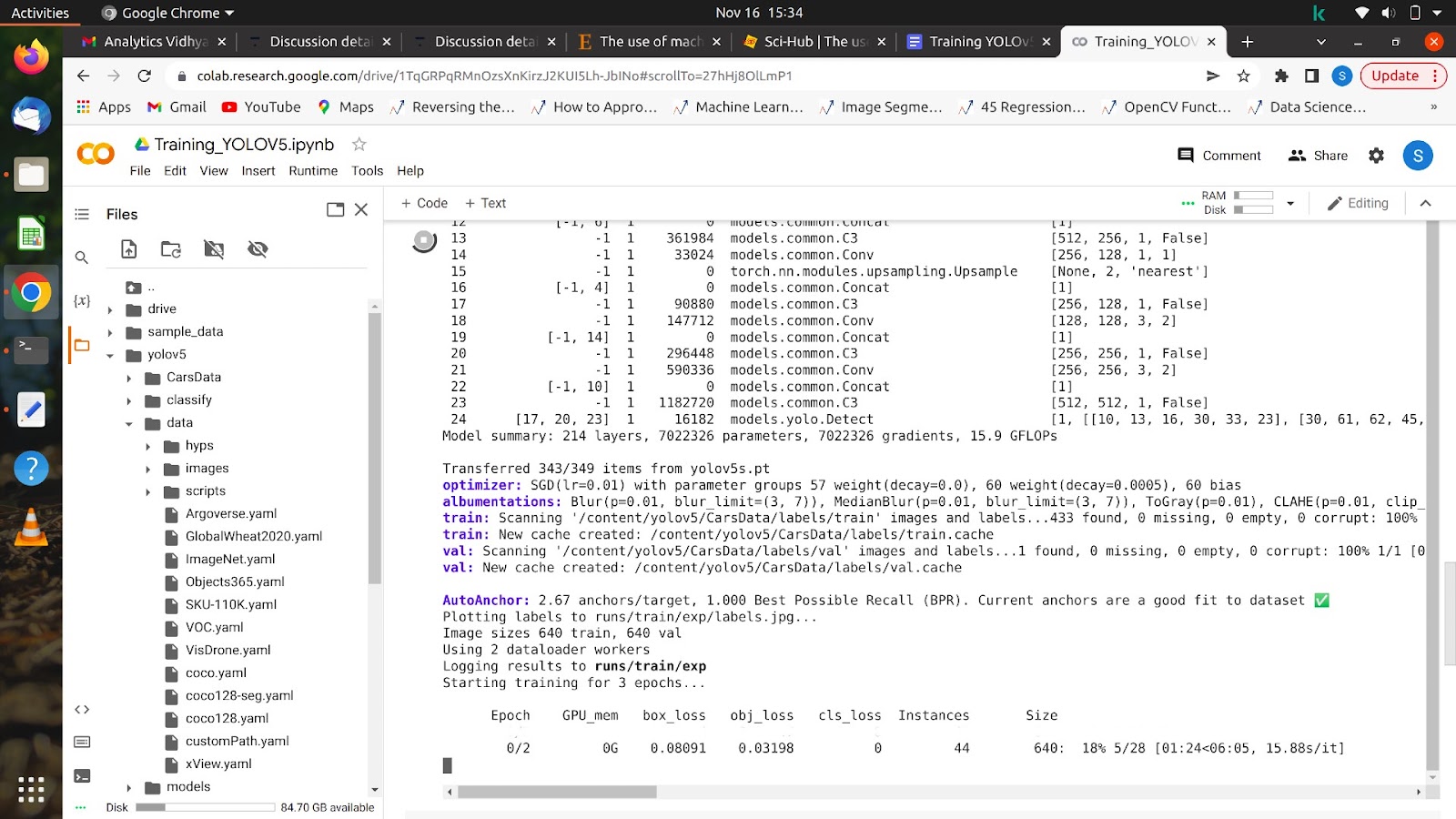
Nachdem alle Epochen abgeschlossen sind, kann Ihr Modell auf jedem Bild getestet werden.
Sie können in der Datei detect.py weitere Anpassungen vornehmen, was Sie speichern möchten und was Ihnen nicht gefällt, die Erkennungen, bei denen die Nummernschilder erkannt werden, usw.
6. !python discover.py –weight /content/yolov5/runs/train/exp/weights/best.pt –source path_of_the_image
Sie können diesen Befehl verwenden, um die Vorhersage des Modells für einige der Bilder zu testen.
Einige Herausforderungen, denen Sie sich stellen können
Obwohl die oben erläuterten Schritte korrekt sind, können einige Probleme auftreten, wenn Sie sie nicht genau befolgen.
- Falscher Pfad: Dies kann Kopfschmerzen oder ein Problem sein. Wenn Sie beim Trainieren des Bildes irgendwo den falschen Pfad eingegeben haben, kann dieser nicht leicht identifiziert werden, und Sie können das Modell nicht trainieren.
- Falsches Etikettenformat: Dies ist ein weit verbreitetes Problem, mit dem Menschen beim Training eines YOLOv5 konfrontiert sind. Das Modell akzeptiert nur ein Format, in dem jedes Bild eine eigene Textdatei mit dem gewünschten Format enthält. Häufig wird eine Datei im XLS-Format oder eine einzelne CSV-Datei in das Netzwerk eingespeist, was zu einem Fehler führt. Wenn Sie die Daten von irgendwoher herunterladen, kann es ein anderes Dateiformat geben, in dem die Etiketten gespeichert werden, anstatt jedes einzelne Bild mit Anmerkungen zu versehen. Hier ist ein Artikel zum Konvertieren des XLS-Formats in das YOLO-Format. (Link nach Abschluss des Artikels).
- Benennen Sie die Dateien nicht richtig: Wenn Sie die Datei nicht richtig benennen, führt dies erneut zu einem Fehler. Beachten Sie die Schritte beim Benennen der Ordner und vermeiden Sie diesen Fehler.
Zusammenfassung
In diesem Artikel haben wir gelernt, was Transfer Learning ist und welches vortrainierte Modell es gibt. Wir haben gelernt, wann und warum das YOLOv5-Modell verwendet wird und wie das Modell mit einem benutzerdefinierten Datensatz trainiert wird. Wir haben jeden einzelnen Schritt durchlaufen, von der Vorbereitung des Datensatzes über die Änderung der Pfade bis hin zur endgültigen Einspeisung in das Netzwerk bei der Implementierung der Technik, und die Schritte gründlich verstanden. Wir haben uns auch häufige Probleme beim Training eines YOLOv5 und deren Lösung angesehen. Ich hoffe, dieser Artikel hat Ihnen geholfen, Ihr erstes YOLOv5 mit einem benutzerdefinierten Datensatz zu trainieren, und dass Ihnen der Artikel gefällt.
Verbunden
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://www.analyticsvidhya.com/blog/2023/02/how-to-train-a-custom-dataset-with-yolov5/
- 1
- 10
- a
- Fähig
- oben
- Akzeptiert
- Nach
- Genauigkeit
- Aktionen
- Nach der
- voraus
- AI
- Alle
- bereits
- Beträge
- und
- Architektur
- um
- Artikel
- Aufmerksamkeit
- Im Prinzip so, wie Sie es von Google Maps kennen.
- verfügbar
- vermeiden
- Zurück
- basierend
- Grundsätzlich gilt
- Bevor
- unten
- Besser
- Bit
- Boden
- Box
- Boxen
- Taste im nun erscheinenden Bestätigungsfenster nun wieder los.
- vorsichtig
- vorsichtig
- Häuser
- CD
- Center
- Herausforderungen
- Übernehmen
- Änderungen
- Ändern
- aus der Ferne überprüfen
- gewählt
- Klasse
- Unterricht
- Einstufung
- Code
- wie die
- kommentierte
- gemeinsam
- community
- Abgeschlossene Verkäufe
- Abschluss
- kompliziert
- Berechnungen
- verwirrend
- enthält
- Inhalt
- verkaufen
- Kopieren
- korrekt
- erstellen
- erstellt
- Erstellen
- Strom
- Original
- Anpassung
- anpassen
- darknet
- technische Daten
- Datenaufbereitung
- Datenwissenschaftler
- tief
- tiefe Lernen
- Definiert
- hängt
- erkannt
- Entdeckung
- Dialog
- anders
- Direkt
- Verzeichnisse
- entdecken
- verschieden
- Dabei
- Nicht
- herunterladen
- Antrieb
- jeder
- Erleichtert
- erziehen
- Effektiv
- effektiv
- effizient
- Enter
- eingegeben
- Epochen
- Fehler
- etc
- Sogar
- Jedes
- genau
- Beispiel
- Training
- Erklären
- erklärt
- Erläuterung
- exportieren
- außerordentlich
- Gesicht
- konfrontiert
- FAST
- beschleunigt
- Fed
- Fütterung
- wenige
- Reichen Sie das
- Mappen
- Endlich
- Vorname
- erstes Mal
- Setzen Sie mit Achtsamkeit
- folgen
- Folgende
- Format
- Unser Ansatz
- für
- Spaß
- bekommen
- GitHub
- ABSICHT
- Go
- gehen
- gut
- GPU
- ganzer
- gehört
- Hilfe
- dazu beigetragen,
- hier
- Besondere
- hoch
- schlagen
- ein Geschenk
- Ultraschall
- Hilfe
- HTTPS
- riesig
- Idee
- Login
- identifizieren
- Image
- Bilder
- Implementierung
- wichtig
- in
- anfänglich
- installieren
- beantragen müssen
- Interaktionen
- Internet
- beteiligt
- IT
- Wissen
- Wissen
- Label
- Etiketten
- grosse
- großflächig
- größer
- Lagen
- führen
- LERNEN
- gelernt
- lernen
- Bibliotheken
- Lizenz
- Line
- LINK
- Laden
- aussehen
- sah
- SIEHT AUS
- gemacht
- um
- Making
- markiert
- Spiel
- Materie
- max-width
- Mittel
- Methoden
- könnte
- Millionen
- Geist / Bewusstsein
- Modell
- für
- mehr
- vor allem warme
- Name
- Namens
- Benennung
- Need
- erforderlich
- Netzwerk
- Netzwerke
- Anzahl
- Objekt
- Objekterkennung
- EINEM
- optimiert
- Option
- Auftrag
- Andere
- besitzen
- Paket
- Pakete
- Teil
- Weg
- AUFMERKSAMKEIT
- Personen
- ausführen
- Leistung
- Durchführung
- führt
- Ort
- Plato
- Datenintelligenz von Plato
- PlatoData
- vorhersagen
- Prognose
- Vorbereitung
- früher
- vorher
- Aufgabenstellung:
- Probleme
- Prozessdefinierung
- Projekt
- zuverlässig
- bietet
- Zweck
- Pytorch
- bereit
- Echtzeit
- kürzlich
- empfehlen
- raffiniert
- entfernen
- Quelle
- erfordern
- falls angefordert
- Voraussetzungen:
- was zu
- Die Ergebnisse
- Führen Sie
- gleich
- Speichern
- Einsparung
- Wissenschaftler
- Wissenschaftler
- Bildschirm
- brauchen
- Schale
- sollte
- erklären
- gezeigt
- signifikant
- ähnlich
- Einfacher
- einfach
- da
- Single
- So
- Lösung
- einige
- etwas
- irgendwo
- gespalten
- gestapelt
- steht
- Anfang
- begonnen
- Schritt
- Shritte
- Struktur
- so
- Nehmen
- Aufgabe
- und Aufgaben
- Technologie
- AGB
- Test
- Das
- ihr
- gründlich
- Durch
- Zeit
- Zeitaufwendig
- zu
- gemeinsam
- Top
- Training
- trainiert
- Ausbildung
- privaten Transfer
- Übertragen
- Lernprogramm
- typisch
- verstehen
- verstanden
- -
- gewöhnlich
- Bestätigung
- verschiedene
- Fahrzeug
- Version
- Webseite
- Webseiten
- Wochen
- Was
- welche
- während
- weit
- weit verbreitet
- werden wir
- ohne
- Arbeiten
- arbeiten,
- würde
- schreiben
- Falsch
- YAML
- Yolo
- Ihr
- Zephyrnet
- PLZ