Dies ist ein Gastbeitrag, der zusammen mit Raghu Boppanna von Vanguard geschrieben wurde.
At Vorhut, der Geschäftsbereich Enterprise Advice, verbessert die Ergebnisse der Anleger durch digitalen Zugang zu überlegener, personalisierter und erschwinglicher Finanzberatung. Sie machten dies teilweise möglich, indem sie weltweit Skaleneffekte für Investoren mit einer äußerst robusten und effizienten technischen Plattform förderten. Vanguard entschied sich für eine multiregionale Architektur für diese Workload, um zum Schutz vor Beeinträchtigungen regionaler Dienste beizutragen. Für Hochverfügbarkeitszwecke ist es erforderlich, die von der Arbeitslast verwendeten Daten nicht nur in der primären Region, sondern auch in der sekundären Region mit minimaler Replikationsverzögerung verfügbar zu machen. Im Falle einer Dienstbeeinträchtigung in der primären Region sollte die Lösung in der Lage sein, mit so wenig Datenverlust wie möglich auf die sekundäre Region umzuschalten und die Datenaufnahme wieder aufzunehmen.
Vanguard Cloud Technology Office und AWS haben sich zusammengetan, um eine Infrastrukturlösung auf AWS zu entwickeln, die ihre Resilienzanforderungen erfüllt. Die multiregionale Lösung ermöglicht einen robusten Failover-Mechanismus mit integrierter Beobachtbarkeit und Wiederherstellung. Die Lösung unterstützt auch das Streamen von Daten aus mehreren Quellen in verschiedene Kinesis-Datenströme. Die Lösung wird derzeit in den verschiedenen Geschäftsbereichsteams eingeführt, um die Ausfallsicherheit ihrer Workloads zu verbessern.
Der hier diskutierte Anwendungsfall erfordert Change Data Capture (CDC), um Daten von einer Remote-Datenquelle (Mainframe DB2) zu streamen Amazon Kinesis-Datenströme, da die Geschäftsfähigkeit von diesen Daten abhängt. Kinesis Data Streams ist ein vollständig verwalteter, hochgradig skalierbarer, langlebiger und kostengünstiger Streaming-Service, der große Datenmengen aus mehreren Quellen kontinuierlich erfassen und streamen kann und die Daten innerhalb von Millisekunden für den Verbrauch verfügbar macht. Der Dienst ist auf hohe Ausfallsicherheit ausgelegt und verwendet mehrere Availability Zones zum Verarbeiten und Speichern von Daten.
Die in diesem Beitrag besprochene Lösung erklärt, wie AWS und Vanguard innovativ waren, um eine robuste Architektur aufzubauen, um ihre Hochverfügbarkeitsziele zu erreichen.
Lösungsüberblick
Die Lösung verwendet AWS Lambda um Daten aus Kinesis-Datenströmen in der primären Region in eine sekundäre Region zu replizieren. Im Falle einer Dienstbeeinträchtigung, die sich auf die CDC-Pipeline auswirkt, stuft der Failover-Prozess die sekundäre Region für die Produzenten und Verbraucher in die primäre Region um. Wir gebrauchen Globale Amazon DynamoDB-Tabellen für Replikationsprüfpunkte, die es ermöglichen, das Datenstreaming vom Prüfpunkt fortzusetzen, und außerdem ein primäres Regionskonfigurationsflag verwaltet, das eine endlose Replikationsschleife derselben Daten hin und her verhindert.
Die Lösung bietet Kinesis Data Streams-Kunden auch die Flexibilität, die primäre oder eine beliebige sekundäre Region innerhalb desselben AWS-Kontos zu verwenden.
Das folgende Diagramm veranschaulicht die Referenzarchitektur.
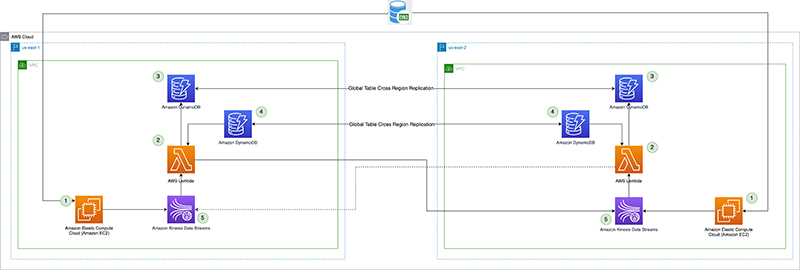
Schauen wir uns jede Komponente im Detail an:
- CDC-Prozessor (Produzent) – In dieser Referenzarchitektur wird der Producer bereitgestellt Amazon Elastic Compute-Cloud (Amazon EC2) sowohl in der primären als auch in der sekundären Region und ist in der primären Region aktiv und in der sekundären Region im Standby-Modus. Es erfasst CDC-Daten aus der externen Datenquelle (wie einer DB2-Datenbank, wie in der obigen Architektur gezeigt) und streamt an Kinesis Data Streams in der primären Region. Vanguard verwendet eine 3rd Party-Tool Qlik Replicate als CDC-Prozessor. Es erzeugt eine wohlgeformte Nutzlast, einschließlich des DB2-Commit-Zeitstempels für den Kinesis-Datenstrom, zusätzlich zu den tatsächlichen Zeilendaten aus der Remote-Datenquelle. (
example-stream-1in diesem Beispiel). Der folgende Code ist eine Beispielnutzlast, die nur den Primärschlüssel des geänderten Datensatzes und den Commit-Zeitstempel enthält (der Einfachheit halber werden die restlichen Tabellenzeilendaten unten nicht angezeigt):{ "eventSource": "aws:kinesis", "kinesis": { "ApproximateArrivalTimestamp": "Mon July 18 20:00:00 UTC 2022", "SequenceNumber": "49544985256907370027570885864065577703022652638596431874", "PartitionKey": "12349999", "KinesisSchemaVersion": "1.0", "Data": "eyJLZXkiOiAxMjM0OTk5OSwiQ29tbWl0VGltZXN0YW1wIjogIjIwMjItMDctMThUMjA6MDA6MDAifQ==" }, "eventId": "shardId-000000000000:49629136582982516722891309362785181370337771525377097730", "invokeIdentityArn": "arn:aws:iam::6243876582:role/kds-crr-LambdaRole-1GZWP67437SD", "eventName": "aws:kinesis:record", "eventVersion": "1.0", "eventSourceARN": "arn:aws:kinesis:us-east-1:6243876582:stream/kds-stream-1/consumer/kds-crr:6243876582", "awsRegion": "us-east-1" }Der Base64-decodierte Wert von
Dataist wie folgt. Der eigentliche Kinesis-Datensatz würde zusätzlich zum Primärschlüssel und dem Commit-Zeitstempel die gesamten Zeilendaten der geänderten Tabellenzeile enthalten.{"Key": 12349999,"CommitTimestamp": "2022-07-18T20:00:00"}Das
CommitTimestampderDataDas Feld wird im Replikationsprüfpunkt verwendet und ist entscheidend, um genau zu verfolgen, wie viele der Stream-Daten in die sekundäre Region repliziert wurden. Der Prüfpunkt kann dann verwendet werden, um ein Failover für einen CDC-Prozessor (Erzeuger) zu erleichtern und die Datenerstellung ab dem Zeitstempel des Replikationsprüfpunkts genau fortzusetzen.Die Alternative zur Verwendung einer Remote-Datenquelle
CommitTimestamp(falls nicht verfügbar) ist die zu verwendenApproximateArrivalTimestamp(das ist der Zeitstempel, wenn der Datensatz tatsächlich in den Datenstrom geschrieben wird). - Lambda-Funktion für die regionsübergreifende Replikation – Die Funktion wird sowohl in primären als auch in sekundären Regionen bereitgestellt. Es ist mit einer Ereignisquellenzuordnung zum Datenstrom eingerichtet, der CDC-Daten enthält. Dieselbe Funktion kann verwendet werden, um Daten mehrerer Streams zu replizieren. Es wird mit einem Batch von Datensätzen aus Kinesis Data Streams aufgerufen und repliziert den Batch in eine Zielreplikationsregion (die über die Lambda-Konfigurationsumgebung bereitgestellt wird). Wenn die CDC-Daten aus Kostengründen nur in der primären Region aktiv produziert werden, kann die reservierte Gleichzeitigkeit der Funktion in der sekundären Region auf null gesetzt und während des regionalen Failover geändert werden. Die Funktion hat AWS Identity and Access Management and (IAM)-Rollenberechtigungen für Folgendes:
- Lesen und schreiben Sie innerhalb desselben Kontos in die globalen DynamoDB-Tabellen, die in dieser Lösung verwendet werden.
- Lesen und schreiben Sie Kinesis Data Streams in beiden Regionen innerhalb desselben Kontos.
- Veröffentlichen Sie benutzerdefinierte Metriken in Amazon CloudWatch in beiden Regionen innerhalb desselben Kontos.
- Replikationsprüfpunkt – Der Replikationsprüfpunkt verwendet die globale DynamoDB-Tabelle sowohl in der primären als auch in der sekundären Region. Es wird von der Lambda-Funktion für die regionsübergreifende Replikation verwendet, um den Commit-Zeitstempel des letzten Replikationsdatensatzes als Replikationsprüfpunkt für jeden Stream, der für die Replikation konfiguriert ist, beizubehalten. Für diesen Beitrag erstellen und verwenden wir eine globale Tabelle namens
kdsReplicationCheckpoint. - Aktive Region-Konfig – Die aktive Region verwendet die globale DynamoDB-Tabelle sowohl in der primären als auch in der sekundären Region. Es verwendet die native regionsübergreifende Replikationsfähigkeit der globalen Tabelle, um die Konfiguration zu replizieren. Es ist vorab mit Daten darüber gefüllt, welche die primäre Region für einen Stream ist, um eine Replikation zurück in die primäre Region durch die Lambda-Funktion in der Standby-Region zu verhindern. Diese Konfiguration ist möglicherweise nicht erforderlich, wenn für die Lambda-Funktion in der Standby-Region eine reservierte Parallelität auf Null gesetzt ist, kann aber als Sicherheitsprüfung dienen, um eine Endlosreplikationsschleife der Daten zu vermeiden. Für diesen Beitrag erstellen wir eine globale Tabelle namens
kdsActiveRegionConfigund lege einen Artikel mit folgenden Daten:{ "stream-name": "example-stream-1", "active-region" : "us-east-1" } - Kinesis-Datenströme – Der Stream, für den der CDC-Prozessor die Daten produziert. Für diesen Beitrag verwenden wir einen Stream namens
example-stream-1in beiden Regionen mit derselben Shard-Konfiguration und denselben Zugriffsrichtlinien.
Abfolge von Schritten bei der regionsübergreifenden Replikation
Lassen Sie uns anhand des folgenden Sequenzdiagramms kurz betrachten, wie die Architektur ausgeübt wird.
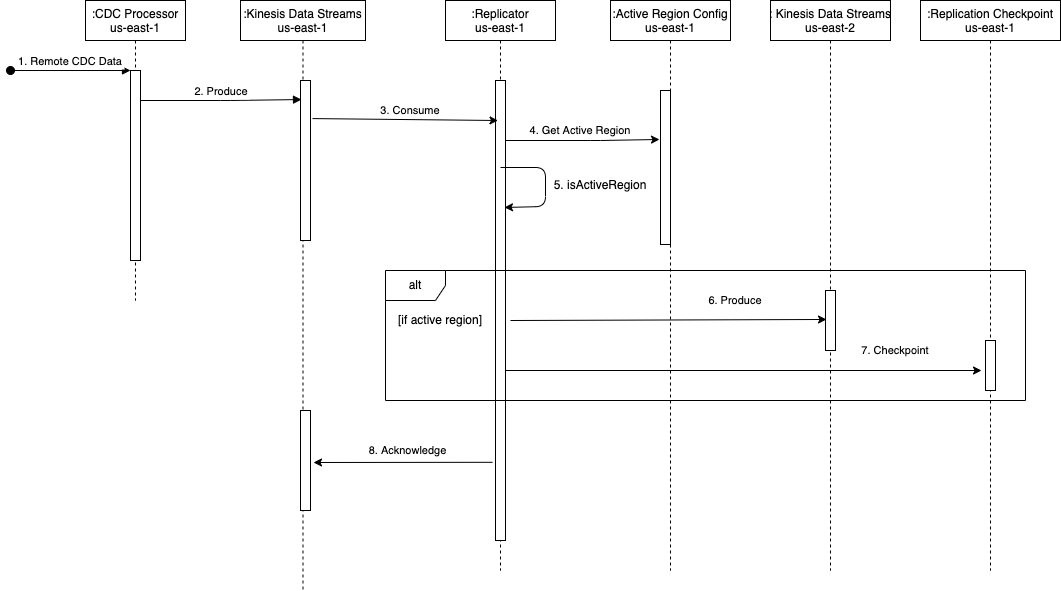
Der Ablauf besteht aus folgenden Schritten:
- Der CDC-Prozessor (in
us-east-1) liest die CDC-Daten aus der Remote-Datenquelle. - Der CDC-Prozessor (in
us-east-1) streamt die CDC-Daten an Kinesis Data Streams (inus-east-1). - Die Lambda-Funktion für die regionsübergreifende Replikation (in us-east-1) verbraucht die Daten aus dem Datenstrom (in
us-east-1). Das verbesserte Fanout-Muster wird für dedizierten und erhöhten Durchsatz für die regionsübergreifende Replikation empfohlen. - Die Replikator-Lambda-Funktion (in
us-east-1) validiert seine aktuelle Region mit der aktiven Regionskonfiguration für den verbrauchten Stream mit Hilfe vonkdsActiveRegionConfigGlobale DynamoDB-TabelleDer folgende Beispielcode (in Java) kann dabei helfen, die ausgewertete Bedingung zu veranschaulichen:// Fetch the current AWS Region from the Lambda function’s environment String currentAWSRegion = System.getenv(“AWS_REGION”); // Read the stream name from the first Kinesis Record once for the entire batch being processed. This is done because we are reusing the same Lambda function for replicating multiple streams. String currentStreamNameConsumed = kinesisRecord.getEventSourceARN().split(“:”)[5].split(“/”)[1]; // Build the DynamoDB query condition using the stream name Map<String, Condition> keyConditions = singletonMap(“streamName”, Condition.builder().comparisonOperator(EQ).attributeValueList(AttributeValue.builder().s(currentStreamNameConsumed).build()).build()); // Query the DynamoDB Global Table QueryResponse queryResponse = ddbClient.query(QueryRequest.builder().tableName("kdsActiveRegionConfig").keyConditions(keyConditions).attributesToGet(“ActiveRegion”).build()); - Die Funktion wertet die Antwort von DynamoDB mit dem folgenden Code aus:
// Evaluate the response if (queryResponse.hasItems()) { AttributeValue activeRegionForStream = queryResponse.items().get(0).get(“ActiveRegion”); return currentAWSRegion.equalsIgnoreCase(activeRegionForStream.s()); } - Abhängig von der Antwort führt die Funktion die folgenden Aktionen aus:
- Wenn die Antwort ist
true, erzeugt die Replikatorfunktion die Datensätze in Kinesis Data Streamsus-east-2in sequenzieller Weise.- Wenn ein Fehler auftritt, wird die Sequenznummer des Datensatzes nachverfolgt und die Iteration unterbrochen. Die Funktion gibt die Liste der fehlgeschlagenen Sequenznummern zurück. Durch die Rückgabe der fehlgeschlagenen Sequenznummer verwendet die Lösung die Funktion von Lambda-Checkpointing um in der Lage zu sein, die Verarbeitung eines Stapels von Datensätzen mit teilweisen Fehlern fortzusetzen. Dies ist nützlich, wenn Dienstbeeinträchtigungen behandelt werden, bei denen die Funktion versucht, die Daten über Regionen hinweg zu replizieren, um Stream-Parität und keinen Datenverlust sicherzustellen.
- Wenn keine Fehler vorliegen, wird eine leere Liste zurückgegeben, die anzeigt, dass der Batch erfolgreich war.
- Wenn die Antwort ist
false, kehrt die Replikatorfunktion zurück, ohne eine Replikation durchzuführen. Um die Kosten der Lambda-Aufrufe zu reduzieren, können Sie die reservierte Gleichzeitigkeit der Funktion in der DR-Region (us-east-2) bis Null. Dadurch wird verhindert, dass die Funktion aufgerufen wird. Wenn Sie ein Failover durchführen, können Sie diesen Wert basierend auf dem CDC-Durchsatz auf eine geeignete Zahl aktualisieren und die reservierte Parallelität der Funktion in festlegenus-east-1auf Null, um zu verhindern, dass es unnötigerweise ausgeführt wird.
- Wenn die Antwort ist
- Nachdem alle Aufzeichnungen in Kinesis Data Streams produziert wurden
us-east-2, überprüft die Replikatorfunktion auf diekdsReplicationCheckpointGlobale DynamoDB-Tabelle (inus-east-1) mit folgenden Daten:{ "streamName": "example-stream-1", "lastReplicatedTimestamp": "2022-07-18T20:00:00" } - Die Funktion kehrt nach erfolgreicher Verarbeitung des Stapels von Datensätzen zurück.
Leistungsüberlegungen
Die Leistungserwartungen der Lösung sollten in Bezug auf die folgenden Faktoren verstanden werden:
- Regionsauswahl – Die Replikationslatenz ist direkt proportional zur Entfernung, die von den Daten zurückgelegt wird, also verstehen Sie Ihre Regionsauswahl
- Geschwindigkeit – Die Eingangsgeschwindigkeit der Daten oder die zu replizierende Datenmenge
- Nutzlastgröße – Die Größe der replizierten Nutzlast
Überwachen Sie die regionsübergreifende Replikation
Es wird empfohlen, die Replikation während des Vorgangs zu verfolgen und zu beobachten. Sie können die Lambda-Funktion so anpassen, dass am Ende jedes Aufrufs benutzerdefinierte Metriken in CloudWatch mit den folgenden Metriken veröffentlicht werden. Das Veröffentlichen dieser Metriken sowohl in der primären als auch in der sekundären Region trägt dazu bei, sich vor Beeinträchtigungen zu schützen, die die Beobachtbarkeit in der primären Region beeinträchtigen.
- Durchsatz – Die aktuelle Chargengröße des Lambda-Aufrufs
- ReplicationLagSeconds – Die Differenz zwischen dem aktuellen Zeitstempel (nach Verarbeitung aller Datensätze) und dem
ApproximateArrivalTimestampdes letzten replizierten Datensatzes
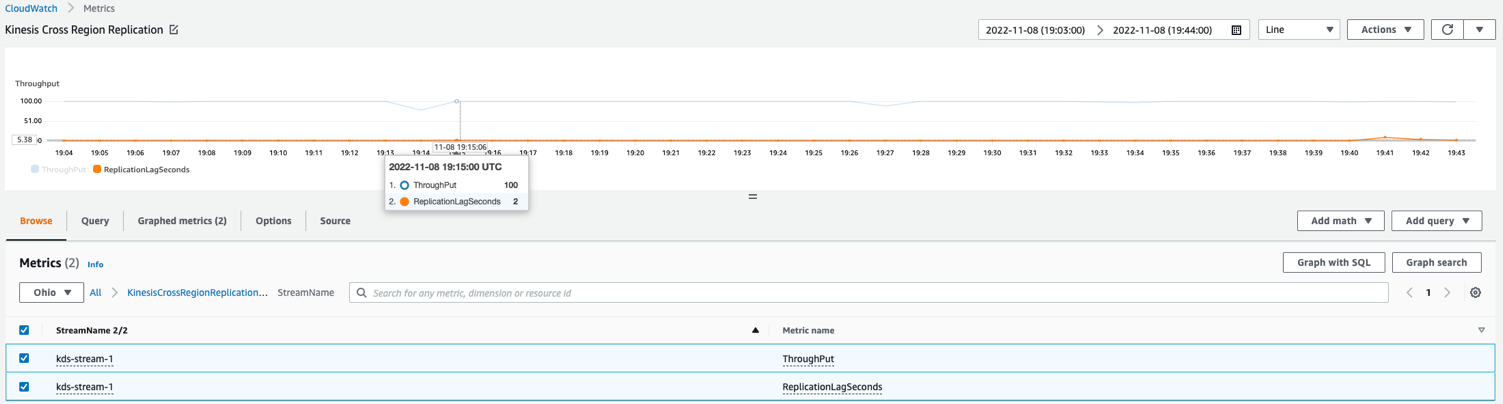
Das folgende beispielhafte CloudWatch-Metrikdiagramm zeigt, dass die durchschnittliche Replikationsverzögerung 2 Sekunden betrug, bei einem Durchsatz von 100 replizierten Datensätzen us-east-1 zu us-east-2.
Gemeinsame Failover-Strategie
Bei Beeinträchtigungen, die sich auf die CDC-Pipeline in der primären Region auswirken, können Geschäftskontinuitäts- oder Notfallwiederherstellungsanforderungen ein Pipeline-Failover auf die sekundäre (Standby-)Region vorschreiben. Dies bedeutet, dass im Rahmen dieses Failover-Prozesses einige Dinge getan werden müssen:
- Stoppen Sie nach Möglichkeit alle CDC-Tasks im CDC-Prozessortool in
us-east-1. - Der CDC-Prozessor muss auf die sekundäre Region umgeschaltet werden, damit er die CDC-Daten von der Remote-Datenquelle lesen kann, während er außerhalb der Standby-Region arbeitet.
- Das
kdsActiveRegionConfigDie globale DynamoDB-Tabelle muss aktualisiert werden. Zum Beispiel für den Streamexample-stream-1In unserem Beispiel wird die aktive Region geändertus-east-2:
{ "stream-name": "example-stream-1", "active-Region" : "us-east-2"
}- Alle Stream-Checkpoints müssen aus dem gelesen werden
kdsReplicationCheckpointGlobale DynamoDB-Tabelle (inus-east-2), und die Zeitstempel von jedem der Prüfpunkte werden verwendet, um die CDC-Aufgaben im Produzententool zu startenus-east-2Region. Dies minimiert die Wahrscheinlichkeit eines Datenverlusts und setzt das Streaming der CDC-Daten von der Remote-Datenquelle ab dem Checkpoint-Zeitstempel genau fort. - Wenn Sie reservierte Parallelität verwenden, um Lambda-Aufrufe zu steuern, setzen Sie den Wert in der primären Region(
us-east-1) und auf einen geeigneten Wert ungleich Null in der sekundären Region (us-east-2).
Vanguards mehrstufige Failover-Strategie
Einige der von Vanguard verwendeten Tools von Drittanbietern verfügen über einen zweistufigen CDC-Prozess zum Streamen von Daten von einer entfernten Datenquelle zu einem Ziel. Vanguards bevorzugtes Tool für seinen CDC-Prozessor folgt diesem zweistufigen Ansatz:
- Der erste Schritt umfasst das Einrichten einer Protokolldatenstromaufgabe, die die Daten aus der Remotedatenquelle liest und an einem Staging-Speicherort verbleibt.
- Der zweite Schritt umfasst das Einrichten einzelner Consumer-Tasks, die Daten vom Staging-Speicherort lesen – der eingeschaltet sein könnte Amazon Elastic File System (Amazon EFS) oder Amazon FSx, zum Beispiel – und zum Ziel streamen. Die Flexibilität besteht hier darin, dass jede dieser Verbraucheraufgaben zum Streamen von unterschiedlichen Commit-Zeitstempeln ausgelöst werden kann. Die Log-Stream-Aufgabe beginnt normalerweise mit dem Lesen von Daten ab dem Minimum aller Commit-Zeitstempel, die von den Consumer-Aufgaben verwendet werden.
Sehen wir uns ein Beispiel an, um das Szenario zu erläutern:
- Consumer-Task A streamt Daten ab einem Commit-Zeitstempel 2022-07-19T20:00:00 aufwärts
example-stream-1. - Consumer-Task B streamt Daten ab einem Commit-Zeitstempel 2022-07-19T21:00:00 aufwärts
example-stream-2. - In dieser Situation sollte der Protokollstream Daten aus der Remote-Datenquelle aus dem Minimum der Zeitstempel lesen, die von den Consumer-Tasks verwendet werden, also 2022-07-19T20:00:00.
Das folgende Sequenzdiagramm zeigt die genauen Schritte, die während eines Failovers ausgeführt werden us-east-2 (die Standby-Region).
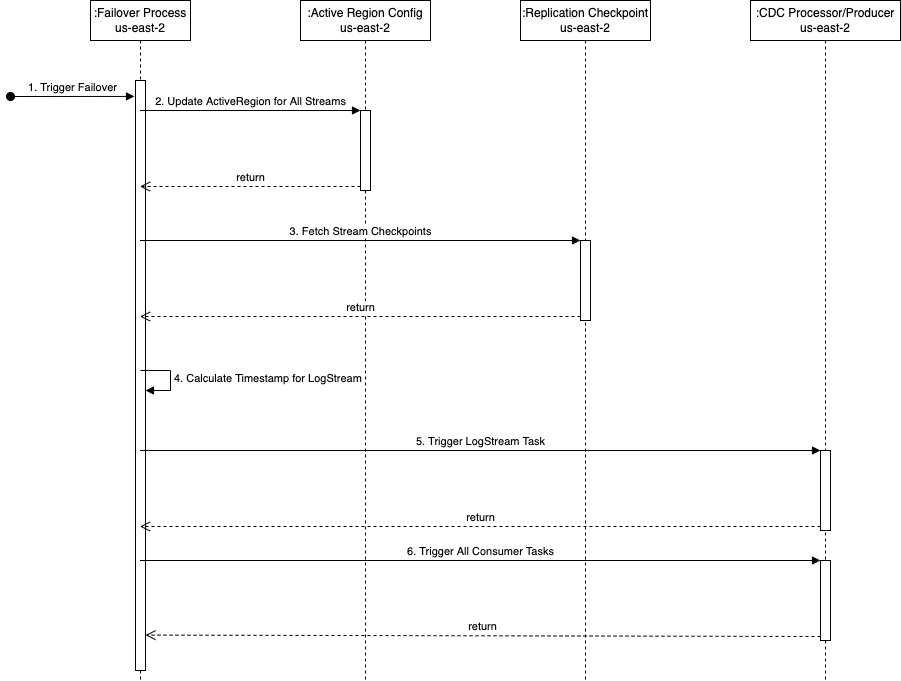
Die Schritte sind wie folgt:
- Der Failover-Prozess wird in der Standby-Region (
us-east-2in diesem Beispiel) bei Bedarf. Beachten Sie, dass der Trigger mithilfe umfassender Zustandsprüfungen der Pipeline in der primären Region automatisiert werden kann. - Der Failover-Prozess aktualisiert die globale DynamoDB-Tabelle kdsActiveRegionConfig mit dem neuen Wert für die Region als
us-east-2für alle Stream-Namen. - Der nächste Schritt besteht darin, alle Stream-Checkpoints aus dem abzurufen
kdsReplicationCheckpointGlobale DynamoDB-Tabelle (inus-east-2). - Nachdem die Checkpoint-Informationen gelesen wurden, findet der Failover-Prozess das Minimum aller
lastReplicatedTimestamp. - Die Log-Stream-Aufgabe im CDC-Prozessortool wird gestartet
us-east-2mit dem in Schritt 4 gefundenen Zeitstempel. Es beginnt ab diesem Zeitstempel mit dem Lesen von CDC-Daten aus der Remote-Datenquelle und speichert sie am Staging-Speicherort auf AWS. - Der nächste Schritt besteht darin, alle Consumer-Tasks zu starten, um Daten vom Staging-Speicherort zu lesen und zum Zieldatenstrom zu streamen. Hier wird jeder Consumer-Task mit dem passenden Zeitstempel aus dem versorgt
kdsReplicationCheckpointTabelle gemstreamNamean die die Aufgabe die Daten streamt.
Nachdem alle Consumer-Tasks gestartet wurden, werden Daten für die Kinesis-Datenströme in us-east-2 produziert. Von da an ist der Prozess der regionsübergreifenden Replikation derselbe wie zuvor beschrieben – die Lambda-Replikationsfunktion in us-east-2 startet die Replikation von Daten in den Datenstrom in us-east-1.
Von den Verbraucheranwendungen, die Daten aus den Streams lesen, wird erwartet, dass sie idempotent sind, um mit Duplikaten umgehen zu können. Duplikate können aus vielen Gründen in den Stream eingeführt werden, von denen einige unten genannt werden.
- Der Produzent oder der CDC-Prozessor fügt Duplikate in den Stream ein, während er die CDC-Daten während eines Failovers wiedergibt
- DynamoDB Global Table verwendet die asynchrone Replikation von Daten über Regionen hinweg und wenn die
kdsReplicationCheckpointTabellendaten eine Replikationsverzögerung aufweisen, kann der Failover-Prozess möglicherweise einen älteren Checkpoint-Zeitstempel verwenden, um die CDC-Daten wiederzugeben.
Verbraucheranwendungen sollten außerdem den CommitTimestamp des letzten verbrauchten Datensatzes überprüfen. Dies soll eine bessere Überwachung und Wiederherstellung ermöglichen.
Weg zur Reife: Automatisierte Wiederherstellung
Der ideale Zustand besteht darin, den Failover-Prozess vollständig zu automatisieren, die Wiederherstellungszeit zu verkürzen und das Service Level Objective (SLO) für Ausfallsicherheit zu erreichen. In den meisten Organisationen erfordert die Entscheidung für ein Failover, ein Failback und das Auslösen des Failover jedoch einen manuellen Eingriff bei der Bewertung der Situation und der Entscheidung über das Ergebnis. Das Erstellen einer Skriptautomatisierung zum Durchführen des Failovers, die von einem Menschen ausgeführt werden kann, ist ein guter Ausgangspunkt.
Vanguard hat alle Failover-Schritte automatisiert, lässt aber immer noch Menschen entscheiden, wann es aufgerufen wird. Sie können die Lösung an Ihre Anforderungen und je nach CDC-Prozessortool anpassen, das Sie in Ihrer Umgebung verwenden.
Zusammenfassung
In diesem Beitrag haben wir beschrieben, wie Vanguard eine Lösung zur Replikation von Daten über Regionen hinweg in Kinesis Data Streams entwickelt und entwickelt hat, um die Daten hochverfügbar zu machen. Wir haben auch eine robuste Checkpoint-Strategie demonstriert, um bei Bedarf ein regionales Failover des Replikationsprozesses zu erleichtern. Die Lösung veranschaulichte auch, wie globale DynamoDB-Tabellen zum Verfolgen der Replikationsprüfpunkte und -konfiguration verwendet werden. Mit dieser Architektur war Vanguard in der Lage, Workloads in Abhängigkeit von den CDC-Daten in mehreren Regionen bereitzustellen, um die geschäftlichen Anforderungen an Hochverfügbarkeit angesichts von Servicebeeinträchtigungen zu erfüllen, die sich auf CDC-Pipelines in der primären Region auswirken.
Wenn Sie Feedback haben, hinterlassen Sie bitte einen Kommentar im Kommentarbereich unten.
Über die Autoren
 Raghu Boppana arbeitet als Enterprise Architect im Chief Technology Office von Vanguard. Raghu ist auf Datenanalyse, Datenmigration/-replikation einschließlich CDC-Pipelines, Notfallwiederherstellung und Datenbanken spezialisiert. Er hat mehrere AWS-Zertifizierungen erworben, darunter AWS Certified Security – Specialty und AWS Certified Data Analytics – Specialty.
Raghu Boppana arbeitet als Enterprise Architect im Chief Technology Office von Vanguard. Raghu ist auf Datenanalyse, Datenmigration/-replikation einschließlich CDC-Pipelines, Notfallwiederherstellung und Datenbanken spezialisiert. Er hat mehrere AWS-Zertifizierungen erworben, darunter AWS Certified Security – Specialty und AWS Certified Data Analytics – Specialty.
 Parameswaran V Vaidyanathan ist Senior Cloud Resilience Architect bei Amazon Web Services. Er hilft großen Unternehmen, die Geschäftsziele zu erreichen, indem er skalierbare und ausfallsichere Lösungen in der AWS Cloud entwickelt und erstellt.
Parameswaran V Vaidyanathan ist Senior Cloud Resilience Architect bei Amazon Web Services. Er hilft großen Unternehmen, die Geschäftsziele zu erreichen, indem er skalierbare und ausfallsichere Lösungen in der AWS Cloud entwickelt und erstellt.
 Richa Kaul ist ein Senior Leader im Bereich Kundenlösungen, der Finanzdienstleistungskunden betreut. Sie lebt in New York. Sie verfügt über umfangreiche Erfahrung in den Bereichen groß angelegte Cloud-Transformation, Mitarbeiterexzellenz und digitale Lösungen der nächsten Generation. Sie und ihr Team konzentrieren sich darauf, den Wert der Cloud zu optimieren, indem sie leistungsstarke, belastbare und agile Lösungen entwickeln. Richa mag Multisportarten wie Triathlons, Musik und lernt etwas über neue Technologien.
Richa Kaul ist ein Senior Leader im Bereich Kundenlösungen, der Finanzdienstleistungskunden betreut. Sie lebt in New York. Sie verfügt über umfangreiche Erfahrung in den Bereichen groß angelegte Cloud-Transformation, Mitarbeiterexzellenz und digitale Lösungen der nächsten Generation. Sie und ihr Team konzentrieren sich darauf, den Wert der Cloud zu optimieren, indem sie leistungsstarke, belastbare und agile Lösungen entwickeln. Richa mag Multisportarten wie Triathlons, Musik und lernt etwas über neue Technologien.
 Mithil Prasad ist Principal Customer Solutions Manager bei Amazon Web Services. In seiner Rolle arbeitet Mithil mit Kunden zusammen, um die Realisierung von Cloud-Werten voranzutreiben und eine Vordenkerrolle zu übernehmen, um Unternehmen dabei zu helfen, Geschwindigkeit, Agilität und Innovation zu erreichen.
Mithil Prasad ist Principal Customer Solutions Manager bei Amazon Web Services. In seiner Rolle arbeitet Mithil mit Kunden zusammen, um die Realisierung von Cloud-Werten voranzutreiben und eine Vordenkerrolle zu übernehmen, um Unternehmen dabei zu helfen, Geschwindigkeit, Agilität und Innovation zu erreichen.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/how-vanguard-made-their-technology-platform-resilient-and-efficient-by-building-cross-region-replication-for-amazon-kinesis-data-streams/
- 1
- 100
- 2022
- 28
- a
- Fähigkeit
- Fähig
- Über uns
- oben
- Zugang
- Nach
- Konto
- genau
- Erreichen
- über
- Aktionen
- aktiv
- aktiv
- berührt das Schneidwerkzeug
- Zusatz
- Beratung
- beeinflussen
- Ranking
- Nach der
- gegen
- agil
- Alle
- erlaubt
- Alternative
- Amazon
- Amazon EC2
- Amazon Kinesis
- Amazon Web Services
- Beträge
- Analytik
- und
- Anwendungen
- Ansatz
- angemessen
- Architektur
- automatisieren
- Automatisiert
- Automation
- Verfügbarkeit
- verfügbar
- durchschnittlich
- vermeiden
- AWS
- AWS-zertifiziert
- Zurück
- basierend
- weil
- Sein
- unten
- Besser
- zwischen
- kurz
- Gebrochen
- bauen
- Building
- erbaut
- eingebaut
- Geschäft
- Geschäftskontinuität
- Unternehmen
- namens
- Erfassung
- Captures
- Häuser
- CDC
- Zertifizierungen
- Zertifzierte
- Chancen
- Übernehmen
- aus der Ferne überprüfen
- Schecks
- Chef
- Wahl
- Cloud
- CLOUD-TECHNOLOGIE
- Code
- Kommentar
- Bemerkungen
- verpflichten
- Komponente
- umfassend
- Berechnen
- Zustand
- Konfiguration
- Überlegungen
- verbraucht
- Verbraucher
- KUNDEN
- Verbrauch
- ständig
- Smartgeräte App
- Kosten
- könnte
- Paar
- erstellen
- Erstellen
- kritischem
- Strom
- Zur Zeit
- Original
- Kunde
- Kundenlösungen
- Kunden
- anpassen
- technische Daten
- Datenanalyse
- Data Loss
- Datenbase
- Datenbanken
- Entscheiden
- Entscheidung
- gewidmet
- weisen nach, dass
- zeigt
- Abhängig
- hängt
- einsetzen
- Einsatz
- beschrieben
- Reiseziel
- Detail
- Unterschied
- anders
- digital
- Direkt
- Katastrophe
- diskutiert
- Abstand
- Antrieb
- Fahren
- Duplikate
- im
- jeder
- Früher
- verdient
- Wirtschaft
- Economies of Scale
- effizient
- Mitarbeiter
- ermöglicht
- verbesserte
- gewährleisten
- Unternehmen
- Unternehmen
- Ganz
- Arbeitsumfeld
- Äther (ETH)
- bewerten
- Bewerten
- Event
- Jedes
- Beispiel
- Exzellenz
- Ausführung
- Erwartungen
- erwartet
- ERFAHRUNGEN
- Erklären
- Erklärt
- umfangreiche
- extern
- Gesicht
- erleichtern
- Faktoren
- FAIL
- Gescheitert
- Scheitern
- Merkmal
- Feedback
- Feld
- Reichen Sie das
- Revolution
- Finanzdienstleistungen
- findet
- Vorname
- Flexibilität
- Setzen Sie mit Achtsamkeit
- Folgende
- folgt
- Für Investoren
- gefunden
- für
- voll
- Funktion
- Generation
- Global
- Globus
- Ziele
- gut
- Graph
- GUEST
- Guest Post
- Griff
- Handling
- das passiert
- Gesundheit
- Hilfe
- hilft
- hier
- High
- hoch
- Ultraschall
- Hilfe
- aber
- HTTPS
- human
- Humans
- IAM
- ideal
- Identitätsschutz
- Beeinträchtigung
- zu unterstützen,
- verbessert
- in
- Einschließlich
- Eingehende
- hat
- zeigt
- Krankengymnastik
- Information
- Infrastruktur
- Innovation
- Instanz
- Intervention
- eingeführt
- Stellt vor
- Investor
- Investoren
- beinhaltet
- IT
- Iteration
- Javac
- Juli
- Wesentliche
- Kinesis-Datenströme
- grosse
- Nachname
- Latency
- Führer
- Leadership
- lernen
- Verlassen
- Niveau
- Line
- Linien
- Liste
- wenig
- Standorte
- aussehen
- Verlust
- gemacht
- unterhält
- um
- MACHT
- verwaltet
- Manager
- Weise
- manuell
- viele
- Mapping
- massiv
- Reife
- Mittel
- Mechanismus
- Triff
- Treffen
- Metrisch
- Metrik
- minimal
- Minimum
- Model
- geändert
- Überwachung
- vor allem warme
- Multi
- mehrere
- Musik
- Name
- Namen
- nativen
- Need
- erforderlich
- Bedürfnisse
- Neu
- Neue Technologien
- New York
- weiter
- Anzahl
- Zahlen
- Ziel
- beobachten
- Office
- die
- Optimierung
- Organisationen
- Ergebnis
- Parität
- Teil
- Partnerschaft
- Party
- Schnittmuster
- ausführen
- Leistung
- Durchführung
- Berechtigungen
- besteht fort
- Personalisiert
- Pipeline
- Ort
- Plattform
- Plato
- Datenintelligenz von Plato
- PlatoData
- Bitte
- Politik durchzulesen
- möglich
- Post
- möglicherweise
- verhindern
- primär
- Principal
- Prozessdefinierung
- Verarbeitung
- Prozessor
- Produziert
- Hersteller
- Producers
- fördert
- Risiken zu minimieren
- die
- vorausgesetzt
- bietet
- veröffentlichen
- Publishing
- Zwecke
- setzen
- Lesen Sie mehr
- Lesebrillen
- Realisierung
- Gründe
- empfohlen
- Rekord
- Aufzeichnungen
- Entspannung
- Erholung
- Veteran
- Reduzierung
- Region
- regional
- Regionen
- entfernt
- repliziert
- repliziert
- Replikation
- falls angefordert
- Voraussetzungen:
- erfordert
- reserviert
- Elastizität
- federnde
- Antwort
- REST
- fortsetzen
- Rückkehr
- Rückkehr
- Rückgabe
- robust
- Rollen
- Gerollt
- REIHE
- Führen Sie
- Sicherheit
- gleich
- skalierbaren
- Skalieren
- Szenario
- Zweite
- Sekundär-
- Sekunden
- Abschnitt
- Sicherheitdienst
- Senior
- Reihenfolge
- brauchen
- Leistungen
- Dienst
- kompensieren
- Einstellung
- mehrere
- sollte
- gezeigt
- Konzerte
- Einfachheit
- Situation
- Größe
- So
- Lösung
- Lösungen
- einige
- Quelle
- Quellen
- spezialisiert
- Spezialprodukte
- Geschwindigkeit
- Sports
- Aufführung
- Anfang
- begonnen
- beginnt
- Bundesstaat
- Schritt
- Shritte
- Immer noch
- Stoppen
- speichern
- Strategie
- Strom
- Streaming
- Streaming-Service
- Ströme
- erfolgreich
- Erfolgreich
- geeignet
- Oberteil
- geliefert
- Unterstützt
- System
- Tabelle
- nimmt
- Target
- Aufgabe
- und Aufgaben
- Team
- Teams
- Technische
- Technologies
- Technologie
- Das
- ihr
- basierte Online-to-Offline-Werbezuordnungen von anderen gab.
- dachte
- Gedankenführung
- Durch
- Durchsatz
- Zeit
- Zeitstempel
- zu
- Werkzeug
- Werkzeuge
- verfolgen sind
- Tracking
- Transformation
- reiste
- auslösen
- ausgelöst
- verstehen
- verstanden
- unnötigerweise
- Aktualisierung
- aktualisiert
- Updates
- -
- Anwendungsfall
- gewöhnlich
- UTC
- Wert
- Vorhut
- Geschwindigkeit
- Volumen
- Netz
- Web-Services
- welche
- während
- werden wir
- .
- ohne
- Werk
- würde
- schreiben
- geschrieben
- Ihr
- sich selbst
- Zephyrnet
- Null
- Zonen