Amazon Redshift ML ermöglicht es Datenanalysten, Entwicklern und Datenwissenschaftlern, Modelle für maschinelles Lernen (ML) mithilfe von SQL zu trainieren. In früheren Beiträgen haben wir gezeigt, wie Sie die automatische Modelltrainingsfunktion von Redshift ML zum Trainieren nutzen können Einstufung und Regression Modelle. Mit Redshift ML können Sie ein Modell mit SQL erstellen und Ihren Algorithmus angeben, z. B. XGBoost. Sie können Redshift ML verwenden, um die Datenvorbereitung, Vorverarbeitung und Auswahl Ihres Problemtyps zu automatisieren (weitere Informationen finden Sie unter Erstellen, trainieren und implementieren Sie Machine-Learning-Modelle in Amazon Redshift mithilfe von SQL mit Amazon Redshift ML). Sie können auch ein zuvor eingelerntes Modell mitbringen Amazon Sage Maker in Amazon RedShift über Redshift ML für lokale Inferenz. Für lokale Rückschlüsse auf in SageMaker erstellte Modelle muss der ML-Modelltyp von Redshift ML unterstützt werden. Jedoch, Fernschluss ist für Modelltypen verfügbar, die in Redshift ML nicht nativ verfügbar sind.
Mit der Zeit altern ML-Modelle, und selbst wenn nichts Einschneidendes passiert, häufen sich kleine Änderungen. Zu den häufigsten Gründen, warum ML-Modelle neu trainiert oder geprüft werden müssen, gehören:
- Datendrift – Da sich Ihre Daten im Laufe der Zeit geändert haben, kann es sein, dass die Vorhersagegenauigkeit Ihrer ML-Modelle im Vergleich zur beim Testen erzielten Genauigkeit abnimmt
- Konzeptdrift – Der ursprünglich verwendete ML-Algorithmus muss möglicherweise aufgrund unterschiedlicher Geschäftsumgebungen und anderer sich ändernder Anforderungen geändert werden
Möglicherweise müssen Sie das Modell regelmäßig aktualisieren, den Prozess automatisieren und die verbesserte Genauigkeit Ihres Modells neu bewerten. Zum jetzigen Zeitpunkt unterstützt Amazon Redshift keine Versionierung von ML-Modellen. In diesem Beitrag zeigen wir, wie Sie die Bring Your Own Model (BYOM)-Funktionalität von Redshift ML nutzen können, um die Versionierung von Redshift ML-Modellen zu implementieren.
Wir verwenden lokale Inferenz, um die Modellversionierung im Rahmen der Operationalisierung von ML-Modellen zu implementieren. Wir gehen davon aus, dass Sie Ihre Daten und den Problemtyp, der für Ihren Anwendungsfall am besten geeignet ist, gut verstehen und Modelle erstellt und für die Produktion bereitgestellt haben.
Lösungsüberblick
In diesem Beitrag verwenden wir Redshift ML, um ein Regressionsmodell zu erstellen, das die Anzahl der Menschen vorhersagt, die zu einer bestimmten Tageszeit den Bike-Sharing-Dienst der Stadt Toronto nutzen könnten. Das Modell berücksichtigt verschiedene Aspekte, darunter Feiertage und Wetterbedingungen, und da wir ein numerisches Ergebnis vorhersagen müssen, haben wir ein Regressionsmodell verwendet. Wir nutzen die Datendrift als Grund für die Neuschulung des Modells und nutzen die Modellversionierung als Teil der Lösung.
Nachdem ein Modell validiert wurde und regelmäßig zum Ausführen von Vorhersagen verwendet wird, können Sie Versionen der Modelle erstellen, was erfordert, dass Sie das Modell mit einem aktualisierten Trainingssatz und möglicherweise einem anderen Algorithmus neu trainieren. Die Versionierung dient zwei Hauptzwecken:
- Zur Fehlerbehebung oder zu Prüfungszwecken können Sie auf frühere Versionen eines Modells zurückgreifen. Dadurch können Sie sicherstellen, dass Ihr Modell weiterhin eine hohe Genauigkeit behält, bevor Sie auf eine neuere Modellversion umsteigen.
- Sie können während des Modelltrainingsprozesses der neuen Version weiterhin Inferenzabfragen für die aktuelle Version eines Modells ausführen.
Zum Zeitpunkt des Schreibens dieses Artikels verfügt Redshift ML nicht über native Versionierungsfunktionen, Sie können jedoch dennoch eine Versionierung erreichen, indem Sie einige einfache SQL-Techniken mithilfe der BYOM-Funktion implementieren. BYOM wurde eingeführt, um vorab trainierte SageMaker-Modelle zum Ausführen Ihrer Inferenzabfragen in Amazon Redshift zu unterstützen. In diesem Beitrag verwenden wir dieselbe BYOM-Technik, um eine Version eines vorhandenen Modells zu erstellen, das mit Redshift ML erstellt wurde.
Die folgende Abbildung veranschaulicht diesen Arbeitsablauf.
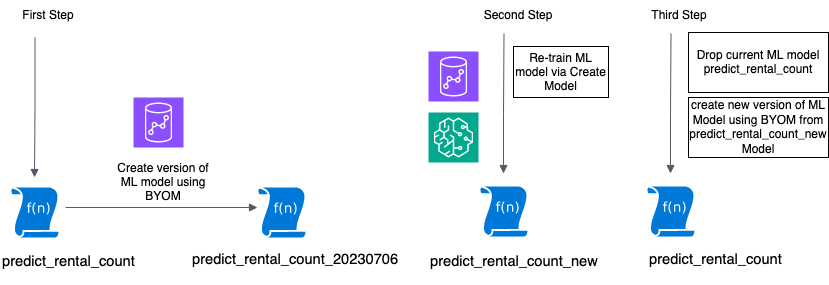
In den folgenden Abschnitten zeigen wir Ihnen, wie Sie aus einem vorhandenen Modell eine Version erstellen und anschließend ein erneutes Modelltraining durchführen können.
Voraussetzungen:
Als Voraussetzung für die Umsetzung des Beispiels in diesem Beitrag müssen Sie eine einrichten Rotverschiebungs-Cluster or Amazon Redshift ohne Server Endpunkt. Die vorbereitenden Schritte für den Einstieg und die Einrichtung Ihrer Umgebung finden Sie unter Erstellen, trainieren und implementieren Sie Machine-Learning-Modelle in Amazon Redshift mithilfe von SQL mit Amazon Redshift ML.
Wir verwenden das im Beitrag erstellte Regressionsmodell Erstellen Sie Regressionsmodelle mit Amazon Redshift ML. Wir gehen davon aus, dass es bereits bereitgestellt wurde, und verwenden dieses Modell, um neue Versionen zu erstellen und das Modell neu zu trainieren.
Erstellen Sie eine Version aus dem vorhandenen Modell
Der erste Schritt besteht darin, eine Version des vorhandenen Modells zu erstellen (was bedeutet, dass Entwicklungsänderungen des Modells gespeichert werden), damit eine Historie erhalten bleibt und das Modell später für Vergleiche zur Verfügung steht.
Der folgende Code ist das generische Format der Befehlssyntax CREATE MODEL; Im nächsten Schritt erhalten Sie die Informationen, die Sie benötigen, um mit diesem Befehl eine neue Version zu erstellen:
Als nächstes sammeln wir die Eingabeparameter und wenden sie auf den vorangehenden CREATE MODEL-Code auf das Modell an. Wir benötigen den Jobnamen und die Datentypen der Modelleingabe- und -ausgabewerte. Wir sammeln diese, indem wir das ausführen show model Befehl auf unserem bestehenden Modell. Führen Sie den folgenden Befehl im Amazon Redshift Query Editor v2 aus:

Beachten Sie die Werte für AutoML-Auftragsname, Funktionsparametertypenund der Zielspalte (trip_count) aus der Modellausgabe. Wir verwenden diese Werte im Befehl CREATE MODEL, um die Version zu erstellen.
Die folgende CREATE MODEL-Anweisung erstellt eine Version des aktuellen Modells unter Verwendung der von uns gesammelten Werte show model Befehl. Wir hängen das Datum (das Beispielformat ist JJJJMMTT) an das Ende der Modell- und Funktionsnamen an, um zu verfolgen, wann diese neue Version erstellt wurde.
Die Ausführung dieses Befehls kann einige Minuten dauern. Wenn der Vorgang abgeschlossen ist, führen Sie den folgenden Befehl aus:

In der Ausgabe können wir Folgendes beobachten:
- AutoML-Auftragsname ist das gleiche wie die Originalversion des Modells
- Funktionsname zeigt wie erwartet den neuen Namen
- Inferenztyp erklärt
Local, was angibt, dass es sich um BYOM mit lokaler Schlussfolgerung handelt
Sie können Inferenzabfragen mit beiden Versionen des Modells ausführen, um die Inferenzausgaben zu validieren.
Der folgende Screenshot zeigt die Ausgabe der Modellinferenz unter Verwendung der Originalversion.

Der folgende Screenshot zeigt die Ausgabe der Modellinferenz mithilfe der Versionskopie.

Wie Sie sehen, sind die Inferenzausgaben gleich.
Sie haben nun gelernt, wie Sie eine Version eines zuvor trainierten Redshift ML-Modells erstellen.
Trainieren Sie Ihr Redshift ML-Modell neu
Nachdem Sie eine Version eines vorhandenen Modells erstellt haben, können Sie das vorhandene Modell neu trainieren, indem Sie einfach ein neues Modell erstellen.
Sie können ein neues Modell mit demselben CREATE MODEL-Befehl erstellen und trainieren, jedoch je nach Bedarf unterschiedliche Eingabeparameter, Datensätze oder Problemtypen verwenden. Für diesen Beitrag trainieren wir das Modell auf neuere Datensätze neu. Wir hängen an _new zum Modellnamen hinzufügen, sodass es zur Identifizierung dem vorhandenen Modell ähnelt.
Im folgenden Code verwenden wir den Befehl CREATE MODEL mit einem neuen Datensatz, der im verfügbar ist training_data Tabelle:
Führen Sie den folgenden Befehl aus, um den Status des neuen Modells zu überprüfen:
Ersetzen Sie das vorhandene Redshift ML-Modell durch das neu trainierte Modell
Der letzte Schritt besteht darin, das vorhandene Modell durch das neu trainierte Modell zu ersetzen. Dies erreichen wir, indem wir die Originalversion des Modells löschen und mithilfe der BYOM-Technik ein Modell neu erstellen.
Überprüfen Sie zunächst Ihr neu trainiertes Modell, um sicherzustellen, dass die MSE/RMSE-Ergebnisse zwischen den Modelltrainingsläufen stabil bleiben. Um die Modelle zu validieren, können Sie durch jede der Modellfunktionen in Ihrem Datensatz Rückschlüsse ziehen und die Ergebnisse vergleichen. Wir verwenden die in bereitgestellten Inferenzabfragen Erstellen Sie Regressionsmodelle mit Amazon Redshift ML.
Nach der Validierung können Sie Ihr Modell ersetzen.
Sammeln Sie zunächst die Details des predict_rental_count_new Modell.

Beachten Sie das AutoML-Auftragsname Wert, der Funktionsparametertypen Werte und die Zielspalte Name in der Modellausgabe.
Ersetzen Sie das ursprüngliche Modell, indem Sie das ursprüngliche Modell löschen und dann das Modell mit den ursprünglichen Modell- und Funktionsnamen erstellen, um sicherzustellen, dass die vorhandenen Verweise auf die Modell- und Funktionsnamen funktionieren:
Die Modellerstellung sollte in wenigen Minuten abgeschlossen sein. Sie können den Status des Modells überprüfen, indem Sie den folgenden Befehl ausführen:
Wenn der Modellstatus lautet ready, die neuere Version predict_rental_count Ihres vorhandenen Modells steht für die Inferenz und die Originalversion des ML-Modells zur Verfügung predict_rental_count_20230706 steht bei Bedarf als Referenz zur Verfügung.
Bitte beziehen Sie sich darauf GitHub-Repository für Beispielskripte zur Automatisierung der Modellversionierung.
Zusammenfassung
In diesem Beitrag haben wir gezeigt, wie Sie die BYOM-Funktion von Redshift ML für die Modellversionierung nutzen können. Auf diese Weise können Sie über einen Verlauf Ihrer Modelle verfügen, sodass Sie die Modellbewertungen im Laufe der Zeit vergleichen, auf Prüfanfragen reagieren und Schlussfolgerungen ziehen können, während Sie ein neues Modell trainieren.
Weitere Informationen zum Erstellen verschiedener Modelle mit Redshift ML finden Sie unter Amazon Redshift ML.
Über die Autoren
 Rohit Bansal ist Analytics Specialist Solutions Architect bei AWS. Er ist auf Amazon Redshift spezialisiert und arbeitet mit Kunden zusammen, um Analyselösungen der nächsten Generation unter Verwendung anderer AWS Analytics-Services zu entwickeln.
Rohit Bansal ist Analytics Specialist Solutions Architect bei AWS. Er ist auf Amazon Redshift spezialisiert und arbeitet mit Kunden zusammen, um Analyselösungen der nächsten Generation unter Verwendung anderer AWS Analytics-Services zu entwickeln.
 Phil Bates ist Senior Analytics Specialist Solutions Architect bei AWS. Er verfügt über mehr als 25 Jahre Erfahrung in der Implementierung umfangreicher Data-Warehouse-Lösungen. Er ist leidenschaftlich daran interessiert, Kunden bei ihrer Cloud-Reise zu unterstützen und die Leistungsfähigkeit von ML in ihrem Data Warehouse zu nutzen.
Phil Bates ist Senior Analytics Specialist Solutions Architect bei AWS. Er verfügt über mehr als 25 Jahre Erfahrung in der Implementierung umfangreicher Data-Warehouse-Lösungen. Er ist leidenschaftlich daran interessiert, Kunden bei ihrer Cloud-Reise zu unterstützen und die Leistungsfähigkeit von ML in ihrem Data Warehouse zu nutzen.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/implement-model-versioning-with-amazon-redshift-ml/
- :hast
- :Ist
- :nicht
- $UP
- 100
- 11
- 25
- 5000
- 7
- a
- Über Uns
- Trading Konten
- Akkumulieren
- Genauigkeit
- Erreichen
- Algorithmus
- erlaubt
- bereits
- ebenfalls
- Amazon
- Amazon Web Services
- an
- Business Analysten
- Analytik
- und
- jedem
- anwendbar
- Bewerben
- SIND
- AS
- Aspekte
- annehmen
- At
- Prüfung
- geprüft
- automatisieren
- automatische
- verfügbar
- AWS
- Grundlage
- BE
- weil
- war
- Bevor
- beginnen
- Sein
- zwischen
- beide
- bringen
- bauen
- Building
- erbaut
- Geschäft
- aber
- by
- CAN
- Fähigkeiten
- capability
- Häuser
- geändert
- Änderungen
- Ändern
- aus der Ferne überprüfen
- Stadt
- Cloud
- Code
- sammeln
- Das Sammeln
- Kolonne
- gemeinsam
- vergleichen
- verglichen
- Vergleich
- abschließen
- Bedingungen
- fortsetzen
- erstellen
- erstellt
- schafft
- Erstellen
- Schaffung
- Strom
- Kunden
- technische Daten
- Datenaufbereitung
- Data Warehouse
- Datensätze
- Datum
- Tag
- verringern
- Standard
- Synergie
- einsetzen
- Einsatz
- Details
- Entwickler
- Entwicklungsstörungen
- anders
- do
- Tut nicht
- Abwurf
- zwei
- im
- jeder
- Herausgeber
- ermöglicht
- Ende
- Endpunkt
- gewährleisten
- Arbeitsumfeld
- Umgebungen
- Äther (ETH)
- Sogar
- Beispiel
- ausgestellt
- vorhandenen
- ERFAHRUNGEN
- Merkmal
- wenige
- Abbildung
- Vorname
- Folgende
- Aussichten für
- Format
- für
- Funktion
- Funktionalität
- Funktionen
- bekommen
- gegeben
- gut
- Wachsen Sie über sich hinaus
- das passiert
- Haben
- he
- Unternehmen
- GUTE
- Geschichte
- Ferien
- Stunde
- Ultraschall
- Hilfe
- aber
- HTML
- http
- HTTPS
- IAM
- Login
- if
- zeigt
- implementieren
- Umsetzung
- verbessert
- in
- das
- Einschließlich
- Information
- anfänglich
- Varianten des Eingangssignals:
- in
- eingeführt
- IT
- Job
- Reise
- jpg
- großflächig
- Nachname
- später
- gelernt
- lernen
- aus einer regionalen
- Maschine
- Maschinelles Lernen
- Main
- um
- Kann..
- Mittel
- Minuten
- ML
- Modell
- für
- mehr
- vor allem warme
- sollen
- Name
- Namen
- nativen
- Need
- erforderlich
- Bedürfnisse
- Neu
- neuer
- weiter
- nächste Generation
- nichts
- jetzt an
- Anzahl
- numerisch
- Ziel
- beobachten
- of
- WOW!
- Alt
- on
- or
- Original
- Andere
- UNSERE
- Ergebnis
- Möglichkeiten für das Ausgangssignal:
- Ausgänge
- übrig
- besitzen
- Parameter
- Parameter
- Teil
- leidenschaftlich
- Personen
- ausführen
- Plato
- Datenintelligenz von Plato
- PlatoData
- gegebenenfalls
- Post
- BLOG-POSTS
- Werkzeuge
- vorhersagen
- Prognose
- Prognosen
- sagt voraus,
- vorläufig
- Vorbereitung
- früher
- vorher
- Vor
- Aufgabenstellung:
- Prozessdefinierung
- Produktion
- vorausgesetzt
- Zwecke
- Abfragen
- Grund
- Gründe
- siehe
- Referenz
- Referenzen
- Regression
- regulär
- ersetzen
- Zugriffe
- erfordert
- Reagieren
- Die Ergebnisse
- behält
- Umschulung
- Rückgabe
- Führen Sie
- Laufen
- läuft
- sagemaker
- gleich
- Einsparung
- Wissenschaftler
- Partituren
- Skripte
- Abschnitte
- sehen
- Auswahl
- Senior
- dient
- Lösungen
- kompensieren
- Einstellungen
- ,,teilen"
- sollte
- erklären
- zeigte
- Konzerte
- ähnlich
- Einfacher
- einfach
- klein
- So
- Lösung
- Lösungen
- Spezialist
- spezialisiert
- SQL
- stabil
- begonnen
- Erklärung
- Status
- bleiben
- Schritt
- Shritte
- Immer noch
- so
- Support
- Unterstützte
- sicher
- Syntax
- Tabelle
- Nehmen
- Target
- Technik
- Techniken
- als
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- die Informationen
- ihr
- dann
- Diese
- fehlen uns die Worte.
- Durch
- Zeit
- zu
- verfolgen sind
- Training
- trainiert
- Ausbildung
- XNUMX
- tippe
- Typen
- Verständnis
- aktualisiert
- -
- Anwendungsfall
- benutzt
- Verwendung von
- BESTÄTIGEN
- validiert
- Bestätigung
- Wert
- Werte
- verschiedene
- Version
- Versionen
- Warehouse
- wurde
- we
- Wetter
- Netz
- Web-Services
- wann
- welche
- während
- warum
- mit
- .
- Arbeiten
- Arbeitsablauf.
- Werk
- Schreiben
- XGBoost
- Jahr
- U
- Ihr
- Zephyrnet