Ich habe es dieses Jahr nicht nach Punta Cana geschafft  Aber ich freue mich (im Entferntesten) für die Leute, die es trotz aller Reisebeschränkungen geschafft haben, dorthin zu gelangen! Premium-Inhalte im Inneren.
Aber ich freue mich (im Entferntesten) für die Leute, die es trotz aller Reisebeschränkungen geschafft haben, dorthin zu gelangen! Premium-Inhalte im Inneren.
Der Herbst war sehr arbeitsreich und ich würde gerne ein kürzeres Format ausprobieren: Jedes große Thema hat einen „Spotlight“  Arbeiten im Hauptblock, die ich besonders interessant finde, und mehrere relevante Werke, deren Beschreibung etwas kürzer ist.
Arbeiten im Hauptblock, die ich besonders interessant finde, und mehrere relevante Werke, deren Beschreibung etwas kürzer ist.
Der Plan für heute:
- KG-erweiterte Sprachmodelle: Kategorisierung
- Konversations-KI: Hör auf zu halluzinieren, Bro
- Entity Linking: In the Shadow of Colossal (Entities)
- KG Bau
- Beantwortung der KG-Frage: Fügen Sie einige hinzu
 Sparql
Sparql
Wenn dieser ausführliche Bildungsinhalt für Sie nützlich ist, Abonnieren Sie unsere AI Research Mailingliste benachrichtigt werden, wenn wir neues Material veröffentlichen.
KG-erweiterte Sprachmodelle: Kategorisierung
Relationale Weltwissensdarstellung in kontextuellen Sprachmodellen: Eine Überprüfung von Tara Safavi und Danai Koutra
Wenn Sie ein erfahrener Leser solcher Zusammenfassungen (oder früherer Beiträge) sind, dann wissen Sie ziemlich gut, wie viele KG-erweiterte LMs auf jeder Konferenz veröffentlicht und wöchentlich auf arxiv hochgeladen werden. Wenn Sie sich verloren fühlen  – Ich kann Ihnen versichern, dass Sie nicht der Einzige sind.
– Ich kann Ihnen versichern, dass Sie nicht der Einzige sind.
Dieses Jahr haben wir endlich eine solider Rahmen und Taxonomie verschiedener KG+LM-Ansätze! Die Autoren definieren drei große Familien: 3⃣ keine KG-Überwachung, in LM-Parametern kodiertes Wissen mit Eingabeaufforderungen im Lückentext; 1⃣ KG-Überwachung mit Entitäten und IDs; 2⃣ KG-Überwachung mit Beziehungsvorlagen und Flächenformen.
Jede Familie hat einige Zweige  Schauen wir uns zum Beispiel die vier unten dargestellten entitätsbewussten Modelle an. Abweichend von „weniger symbolisch“ zu „symbolischer“Einige LMs führen eine Maskierung der Erwähnungsspanne oder ein kontrastives Lernen oder eine Fusion von Entitätseinbettungen aus einem bekannten Vokabular durch. Die Autoren haben großartige Arbeit geleistet und Dutzende vorhandener Architekturen nach dem Framework klassifiziert, und jetzt sieht es viel besser organisiert aus. Dringend notwendige Arbeit!
Schauen wir uns zum Beispiel die vier unten dargestellten entitätsbewussten Modelle an. Abweichend von „weniger symbolisch“ zu „symbolischer“Einige LMs führen eine Maskierung der Erwähnungsspanne oder ein kontrastives Lernen oder eine Fusion von Entitätseinbettungen aus einem bekannten Vokabular durch. Die Autoren haben großartige Arbeit geleistet und Dutzende vorhandener Architekturen nach dem Framework klassifiziert, und jetzt sieht es viel besser organisiert aus. Dringend notwendige Arbeit! 

Einige kurze Artikel konzentrieren sich auf die Anreicherung von LMs mit biomedizinischen KGs, ein langandauernder Versuch, LMs eine domänenspezifische Biomedizin beizubringen Slang. Meng et al bietet Mischung von Partitionen (MoP), ein LM basierend auf dem AdapterFusion Technik, die die Notwendigkeit verringert, LMs von Grund auf neu zu trainieren. MoP wurde mit gängigen biomedizinischen Vokabularen und Ontologien UMLS und SNOMED CT trainiert. Sunget al fragen „Können Sprachmodelle biomedizinische Wissensbasen sein?“ in Bezug auf berühmtes EMNLP'19-Papier von Petroni et al. Die Antwort ist weitgehend NEIN. Die Autoren entwerfen BioLAMA, ein Maßstab für die Untersuchung biomedizinischen Wissens, der auf UMLS, CTD und Wikidata basiert. Sie stellen fest, dass moderne LMs bei diesen Sonden eine Genauigkeit von <10 % erreichen, sodass die Community definitiv etwas Zuverlässigeres benötigt
Meng et al bietet Mischung von Partitionen (MoP), ein LM basierend auf dem AdapterFusion Technik, die die Notwendigkeit verringert, LMs von Grund auf neu zu trainieren. MoP wurde mit gängigen biomedizinischen Vokabularen und Ontologien UMLS und SNOMED CT trainiert. Sunget al fragen „Können Sprachmodelle biomedizinische Wissensbasen sein?“ in Bezug auf berühmtes EMNLP'19-Papier von Petroni et al. Die Antwort ist weitgehend NEIN. Die Autoren entwerfen BioLAMA, ein Maßstab für die Untersuchung biomedizinischen Wissens, der auf UMLS, CTD und Wikidata basiert. Sie stellen fest, dass moderne LMs bei diesen Sonden eine Genauigkeit von <10 % erreichen, sodass die Community definitiv etwas Zuverlässigeres benötigt  .
.
Konversations-KI: Hör auf zu halluzinieren, Bro
Neural Path Hunter: Reduzierung von Halluzinationen in Dialogsystemen durch Path Grounding von Nouha Dziri, Andrea Madotto, Osmar Zaiane, Avishek Joey Bose
Das Generieren von Antworten mit einem ConvAI-System mit KG-Hintergrund ist schwierig. In Rohrleitungssystemen mit vielen Komponenten verwendet man konsequent Oberflächenformen (Entity-Namen) und greift meist auf Templates zurück Vorlagen sind langweilig und kaum wartbar. Auf der anderen Seite erzeugen generative e2e-Modelle wie GPT-2 und GPT-3 weitaus eindeutigere Antworten, aber sie halluzinieren oft, d. h. sie fügen falsche Entitätsnamen ein, wenn Sie es nicht erwarten.
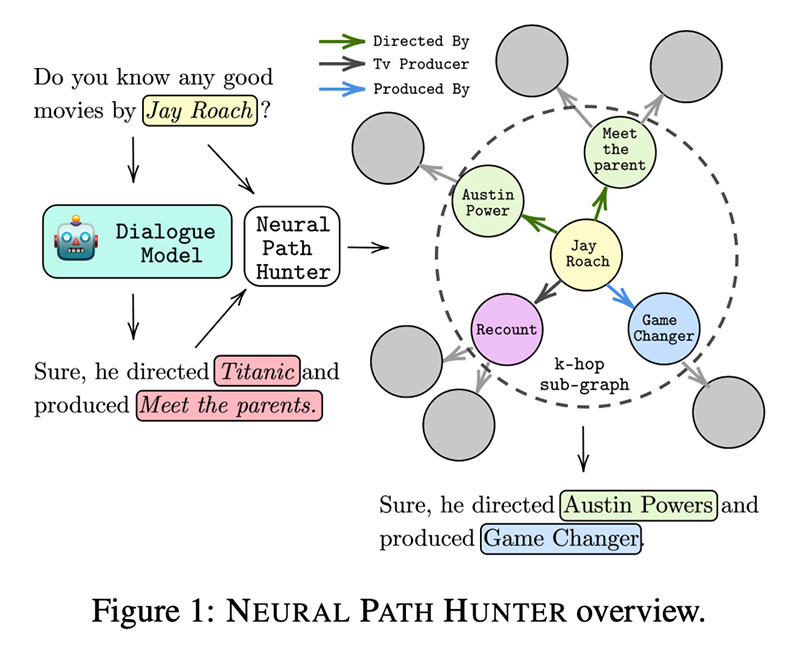
Die Autoren dieser Arbeit begaben sich auf a Jagd  Halluzinationen unter KG-Überwachung zu reduzieren Neuralpfad-Jäger. Zuerst studieren sie mehrere Arten von Halluzinationen , woher sie kommen (hauptsächlich aus Top-k-Sampling) und wie man sie quantifiziert.
Halluzinationen unter KG-Überwachung zu reduzieren Neuralpfad-Jäger. Zuerst studieren sie mehrere Arten von Halluzinationen , woher sie kommen (hauptsächlich aus Top-k-Sampling) und wie man sie quantifiziert.
Der NPH selbst besteht aus zwei Modulen: 1⃣ einem Kritiker (nicht autoregressiver LM), der eine binäre Klassifizierung über Token durchführt; 2⃣ Entity Retriever zum Beheben von Entity-Fehlern: Dies ist im Wesentlichen ein Entity-Speicher, in dem Entity-Einbettungen von GPT stammen und mit CompGCN mithilfe der Diagrammstruktur aktualisiert werden. Die plausibelsten Kandidaten ergeben sich aus der Anwendung der DistMult-Bewertungsfunktion. Voila!
NPH kann mit jedem vortrainierten LM gekoppelt werden, Experimente auf dem OpenDialKG Benchmark mit GPT2-KG, GPT2-KE und AdapterBot zeigen eine deutliche Reduzierung  von Halluzinationen und Zunahme
von Halluzinationen und Zunahme  in Treue. Eine Benutzerstudie berichtet, dass die vom Menschen gemessene Halluzination in NPH-Modellen um das Zweifache reduziert ist
in Treue. Eine Benutzerstudie berichtet, dass die vom Menschen gemessene Halluzination in NPH-Modellen um das Zweifache reduziert ist
Eine weitere relevante Arbeit in diesem Zusammenhang: Honovich et al Untersuchen Sie das gleiche Problem in Dialogsystemen, aber ohne Hintergrund-KG, und schlagen Sie einen neuen Benchmark vor Q² um die sachliche Konsistenz der Fragegenerierung und der Fragebeantwortung zu messen (woher beide Q kommen, wenn Sie fragen).
Wenn Sie sich für ConvAI und Common-Sense-KGs interessieren, schauen Sie sich unbedingt den CLUE (Conversational Multi-Hop Reasoner) von an Arabshahi, Leeet aldas beinhaltet den Begriff von wenn-(Zustand), dann-(Aktion), weil-(Ziel) Muster logische Regeln und symbolisches Denken.
Entity Linking: Im Schatten des Kolosses
Robustheitsbewertung der Entitätsdisambiguierung unter Verwendung früherer Sonden: der Fall der Entitätsüberschattung by Vera Provatorova, Svitlana Vakulenko, Samarth Bhargav, Evangelos Kanoulas
Wenn Sie reale KGs für Sprachaufgaben anschließen, werden Sie unweigerlich darauf stoßen verschiedene Entitäten die haben genau der selbe Name  . Leider verwendet die Menschheit nicht für alle Entitäten auf der Welt eindeutige Hashes, daher bleibt die Begriffsklärung von Entitäten ein wichtiger Schritt der Entitätsverknüpfung.
. Leider verwendet die Menschheit nicht für alle Entitäten auf der Welt eindeutige Hashes, daher bleibt die Begriffsklärung von Entitäten ein wichtiger Schritt der Entitätsverknüpfung.

Zum Beispiel hat Wikidata mindestens 18 Entitäten mit dem Namen „Michael Jordan“. Oft verlassen sich EL-Systeme auf grundlegende Statistiken und Beliebtheitswerte, sodass der beliebteste „Michael Jordan, der Basketballspieler“ weniger prominente (zumindest in der Popkultur) Leute in den Schatten stellen würde.
 Die Autoren gehen dieses Problem an und stellen einen neuen Datensatz vor: ShadowLink, um den Verwechslungsgrad moderner EL-Systeme zu messen. Es stellt sich heraus, dass die höchste F1-Punktzahl kaum 0.35 erreicht (neueste generative GENRE ergibt 0.26) am härtesten Teil. Alle Systeme sättigen ihre Punktzahlen mit seltenen Long-Tail-Entitäten und kommen auch mit häufigeren Entitäten zurecht. Die Hauptherausforderung wird formuliert als „Was die Aufgabe herausfordernd macht, ist die Kombination aus Mehrdeutigkeit und Ungewöhnlichkeit“. Ich würde den Autoren empfehlen, den Datensatz auf hochzuladen HuggingFace-Datensätze um die Sichtbarkeit ihres coolen Projekts zu erhöhen
Die Autoren gehen dieses Problem an und stellen einen neuen Datensatz vor: ShadowLink, um den Verwechslungsgrad moderner EL-Systeme zu messen. Es stellt sich heraus, dass die höchste F1-Punktzahl kaum 0.35 erreicht (neueste generative GENRE ergibt 0.26) am härtesten Teil. Alle Systeme sättigen ihre Punktzahlen mit seltenen Long-Tail-Entitäten und kommen auch mit häufigeren Entitäten zurecht. Die Hauptherausforderung wird formuliert als „Was die Aufgabe herausfordernd macht, ist die Kombination aus Mehrdeutigkeit und Ungewöhnlichkeit“. Ich würde den Autoren empfehlen, den Datensatz auf hochzuladen HuggingFace-Datensätze um die Sichtbarkeit ihres coolen Projekts zu erhöhen  .
.
Aroraet al nähern Sie sich dem Entity-Linking-Problem aus einer anderen Richtung. Die Hauptidee ist die was immer dies auch sein sollte. namens Entitäten in einem Dokument (gemeinsam verarbeitet, nicht einzeln) Spannweite ein niedriger Rang Unterraum  im Raum aller Entitäten, einschließlich Kandidaten (sehen Sie sich unten ein visuelles Beispiel an). Der Eingenthemen Der Ansatz ist unbeaufsichtigt, wenn Sie über vortrainierte Entitätseinbettungen verfügen – die Autoren verwenden DeepWalk über der englischen Teilmenge von Wikidata (alternativ versuchen sie Worteinbettungen, aber es funktioniert nicht so gut).
im Raum aller Entitäten, einschließlich Kandidaten (sehen Sie sich unten ein visuelles Beispiel an). Der Eingenthemen Der Ansatz ist unbeaufsichtigt, wenn Sie über vortrainierte Entitätseinbettungen verfügen – die Autoren verwenden DeepWalk über der englischen Teilmenge von Wikidata (alternativ versuchen sie Worteinbettungen, aber es funktioniert nicht so gut).

Ein konzeptionell ähnliches Problem von entitätsbasierten Konflikten wird studiert von Longpreet al, nämlich Wissenssubstitution – würde das Modell die Antwort ändern, wenn Sie eine wahre Entität in einem Absatz in eine zufällige (oder widersprüchliche) umwandeln? Mit anderen Worten: Würden sich Qualitätssicherungsmodelle auf das Lesen des Kontexts oder auf gespeichertes Wissen stützen? Es stellt sich heraus, dass Sie beim Training von QS-Modellen mit solchen Substitutionen die OOD-Generalisierung deutlich steigern können!
Werfen Sie abschließend noch einen Blick auf die Umfrage von Tedeschiet al on „NER für Entity Linking: Was funktioniert und was als nächstes kommt“. Die Autoren identifizieren die wichtigsten Herausforderungen von EL und versuchen, NER-relevante Herausforderungen anzugehen NER4EL Ziel ist es, die Leistungslücke zwischen großen vorab trainierten LMs und kleineren Modellen zu verringern, was besonders in Szenarien mit geringen Ressourcen relevant ist .

KG Bau
Mir ist es nicht gelungen, hier eine einprägsame Zeile zu finden :/ Wenn Sie sich für OpenIE und KG Construction interessieren, könnten die folgenden Papiere relevant sein.
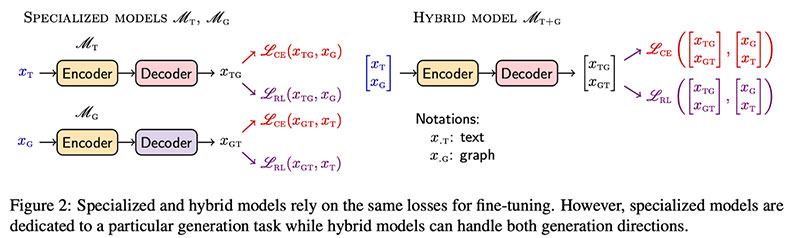
Dognin et al bietet ReGen, ein Ansatz zur Feinabstimmung von LMs, um sowohl Text2Graph- als auch Graph2Text-Aufgaben auszuführen (oder spezialisierte Modelle zu optimieren). Die wichtigste Zutat  fügt zusätzlich zur Standard-Kreuzentropie (CE) einen RL-Verlust (Self-Critical Sequence Training) hinzu. Es kann problemlos zu jedem vorab trainierten LM hinzugefügt werden – die Autoren versuchen es mit T5-Large (770 Mio. Parameter) und T5-Base (220 Mio. Parameter).
fügt zusätzlich zur Standard-Kreuzentropie (CE) einen RL-Verlust (Self-Critical Sequence Training) hinzu. Es kann problemlos zu jedem vorab trainierten LM hinzugefügt werden – die Autoren versuchen es mit T5-Large (770 Mio. Parameter) und T5-Base (220 Mio. Parameter).  Experimentell, ReGen deutlich verbessert gegenüber Text2Graph WebNLG Baselines (3–10 abs. Punkte je nach Metrik) und arbeitet an der viel größer TekGen-Datensatz (6 Millionen Trainingspaare).
Experimentell, ReGen deutlich verbessert gegenüber Text2Graph WebNLG Baselines (3–10 abs. Punkte je nach Metrik) und arbeitet an der viel größer TekGen-Datensatz (6 Millionen Trainingspaare).
Dashet al studiere die Kanonisierung Problem in OpenIE — wenn Entitäten mit unterschiedlichen Oberflächenformen wie (NYC, New York City) beziehen sich auf den gleichen Prototyp. Wir möchten, dass IE-Systeme diese Erwähnungen auf unbeaufsichtigte Weise automatisch gruppieren. Die Methode, TROMMEL, greift auf Variational Autoencoders (VAEs) zurück, um die Cluster zu identifizieren (Entitäten und Beziehungen werden durch Gaußsche Parameter parametrisiert). Zusätzlich zum Standard für VAEs Wiederaufbau Verlust, CUVA beschäftigt zusätzlich Link-Vorhersage Verlust basierend auf der HolE-Bewertungsfunktion.  Darüber hinaus stellen die Autoren einen Roman vor CanonicNELL Datensatz!
Darüber hinaus stellen die Autoren einen Roman vor CanonicNELL Datensatz!

Beantwortung der KG-Frage: Fügen Sie einige hinzu Sparql
SPARQLing-Datenbankabfragen aus Zwischenfragezerlegungen by Irina Saparina und Anton Osokin
Leider gibt es in der *CL-Domäne nicht so viele Anwendungen von SPARQL. Ich denke, es verdient eine viel breitere Akzeptanz im NLP. Wenn es von einer coolen Anwendung unterstützt wird, bin ich dabei  .
.
Die meisten strukturierten QA-Datensätze oder solche, die semantisches Parsing verwenden, zielen auf SQL als Hauptausgabeformat ab. Gibt es ein Leben jenseits von SQL-Pipelines?
Saparina und Osokin Schlagen Sie einen neuen Blick auf dieses Problem vor, indem Sie 1⃣ zunächst a verwenden Fragezerlegung Bedeutungsdarstellung (QDMR) Framework, das eine Frage in eine syntaxunabhängige logische Form übersetzt; 2⃣ Dieses Formular kann in jedes strukturierte Format übersetzt werden, und hier greifen die Autoren auf SPARQL zurück, um zu zeigen, dass es viel einfacher ist, Datenbanken im Diagrammformat abzufragen. Es erfordert zwar die Umwandlung einer Eingabetabelle in RDF, aber für Datensätze der Spiders skalieren ist sehr einfach möglich.
Zu den trainierbaren Modulen gehören RAT-Transformator Encoder mit LSTM-Decoder, der QDMR-Token erzeugt. QDMR -> SPARQL ist eine reine Transpilation, die auf wenigen Regeln basiert. Auf Augenhöhe mit SOTA-Ergebnissen; Code ist verfügbar ; SPARQL funktioniert besser als SQL;
Auf Augenhöhe mit SOTA-Ergebnissen; Code ist verfügbar ; SPARQL funktioniert besser als SQL;
Was braucht man sonst noch für eine gute Arbeit?

Ein weiteres spannendes Werk „Fallbasierte Argumentation für Abfragen in natürlicher Sprache über Wissensdatenbanken“ von Das et al kombiniert SPARQL mit fallbezogene Argumentation (CBR). CBR hat tiefe Wurzeln in Expertensystemen in den 80er Jahren, wurde aber kürzlich mit der Kraft des Repräsentationslernens wiederbelebt. TLDR-Erklärung von CBR im Jahr 2021: Es ist konzeptionell nahe an der kompositorischen Verallgemeinerung, dh nachdem Sie einige grundlegende Beispiele gesehen haben, können Sie eine komplexere Abfrage über zuvor unsichtbare Entitäten erstellen.
Schauen Sie sich das Beispiel unten an. Wir haben eine Eingangsabfrage „Wer ist das Geschwisterchen von Gimlis Vater im Hobbit?“. In den Trainingsdaten haben wir vielleicht nichts über Gimli oder Hobbit, aber wir haben vielleicht „relativ ähnlich“ Fälle über die Beziehungen, die wir für unsere Abfrage nützlich finden könnten, z. „Wer ist Charlie Sheens Vater?“ mit Freebase-Beziehung people.person_parents machen „Wer sind Rihannas Geschwister?“ mit Beziehung people.person.sibling_s . Indem wir sie für unsere Frage zusammenstellen, erstellen wir eine SPARQL-Abfrage an die Datenbank.
Die vorgeschlagene CBR-KBQA Der Ansatz kombiniert 1⃣ einen trainierbaren neuronalen Retriever im DPR-Stil (Überwachung basiert auf überlappenden Beziehungen), 2⃣ einen linearen Transformator (sie verwenden BigBird), da verkettete relevante Fragen und Abfragen ziemlich lang sind, 3⃣ mehrere Neuordnungsmechanismen zum Bereinigen der Vorhersagen. Sie verwenden handelsübliche NER- und Entity-Linking-Module und verwenden außerdem vorab trainierte TransE-Beziehungseinbettungen für die Neubewertung. CBR-KBQA zeigt eine beeindruckende Leistung bei mehreren KBQA-Datensätzen, darunter CFQ. Eine kleine Anmerkung: Ich bin etwas misstrauisch, dass das beste verfügbare SOTA-Modell (67.3 MCD-Mean) um einen solchen Vorsprung auf 78.1 übertroffen und nicht dem Benchmark unterzogen wird, der Code ist auch noch nicht verfügbar.

Shiet al Multi-Hop-QA studieren und vorschlagen, sowohl Entitäts-/Beziehungs-IDs (Etikettenform) als auch ihre Beschreibungen in natürlicher Sprache (Textform) in ihr Nachrichtenverbreitungs-Framework zu integrieren TransferNet. Die Auswertung erfolgt anhand von standardmäßigen MetaQA-, WebQuestionsSP- und Complex Web Questions-Datensätzen.
In derselben Aufgabe (dieselben Datensätze wie in der vorherigen Arbeit) Oliyaet al bemerkte, dass die meisten SOTA-QA-Modelle Textspannen erfordern, die bereits mit KG-Entitäten verknüpft sind, und versuchen, diese Anforderung durch dynamisches Re-Ranking von Entitäten unter Verwendung von Merkmalen der Knotennachbarschaft von KG-Entitäten und Merkmalen von Textspannen zu umgehen.
Das war's Leute
Lassen Sie mich wissen, ob Ihnen dieses kürzere „Premum“ gefällt.  Formatieren Sie besser als lange Textwände wie in früheren Rezensionen! Vielen Dank, dass Sie hier Ihre Zeit investiert haben. Ich hoffe, Sie haben etwas Nützliches mit nach Hause genommen
Formatieren Sie besser als lange Textwände wie in früheren Rezensionen! Vielen Dank, dass Sie hier Ihre Zeit investiert haben. Ich hoffe, Sie haben etwas Nützliches mit nach Hause genommen

Dieser Artikel wurde ursprünglich veröffentlicht am Medium und mit Genehmigung des Autors erneut auf TOPBOTS veröffentlicht.
Genießen Sie diesen Artikel? Melden Sie sich für weitere AI-Updates an.
Wir werden Sie informieren, wenn wir mehr technische Ausbildung veröffentlichen.
Die Post Wissensgraphen auf der EMNLP 2021 erschien zuerst auf TOPBOTS.
- '
- "
- 10
- 11
- 2021
- 67
- 7
- 9
- a
- Über uns
- Fülle
- Nach
- Action
- hinzugefügt
- Zusatz
- Adresse
- Verwaltung
- Adoption
- AI
- ai Forschung
- Anvisieren
- Alle
- bereits
- Mehrdeutigkeit
- Analytik
- Ein anderer
- beantworten
- Anwendung
- Anwendungen
- angewandt
- Anwendung
- Ansatz
- Artikel
- Autoren
- Im Prinzip so, wie Sie es von Google Maps kennen.
- verfügbar
- Hintergrund
- Basketball
- unten
- Benchmark
- BESTE
- zwischen
- Beyond
- Größte
- Bit
- Blockieren
- Geschäft
- rufen Sie uns an!
- Kandidaten
- Häuser
- Fälle
- challenges
- Herausforderungen
- herausfordernd
- Übernehmen
- Stadt
- Einstufung
- Code
- Kombination
- wie die
- gemeinsam
- community
- Komplex
- Komponenten
- Konferenz
- Verwirrung
- Baugewerbe
- Inhalt
- könnte
- KULTUR
- Kunde
- Kundensupport
- technische Daten
- Datenbase
- Datenbanken
- tief
- zeigen
- Abhängig
- beschreiben
- DID
- anders
- Tut nicht
- Domain
- dynamisch
- jeder
- leicht
- Bildungswesen
- Bildungs-
- Anstrengung
- beschäftigt
- Englisch
- Entitäten
- Einheit
- insbesondere
- im Wesentlichen
- Auswertung
- Event
- Beispiel
- Beispiele
- unterhaltsame Programmpunkte
- vorhandenen
- erwarten
- Experte
- Familien
- Familie
- Eigenschaften
- Endlich
- Finanzen
- Vorname
- Setzen Sie mit Achtsamkeit
- Folgende
- unten stehende Formular
- Format
- Formen
- Unser Ansatz
- für
- Funktion
- Lücke
- Generation
- generativ
- GitHub
- Kundenziele
- gut
- groß
- glücklich
- mit
- Höhe
- hier
- Startseite
- ein Geschenk
- Ultraschall
- Hilfe
- hr
- HTTPS
- Menschlichkeit
- Idee
- identifizieren
- wichtig
- beeindruckend
- In anderen
- Einschließlich
- Erhöhung
- Varianten des Eingangssignals:
- Instanz
- integrieren
- Investitionen
- IT
- selbst
- Job
- Wesentliche
- Wissen
- Wissen
- bekannt
- Label
- Sprache
- grosse
- lernen
- Rechtlich
- Line
- Linking
- London
- Lang
- aussehen
- Mehrheit
- um
- MACHT
- verwalten
- verwaltet
- Weise
- Marketing
- Ihres Materials
- Bedeutung
- messen
- mittlere
- Memory
- Erwähnungen
- könnte
- Modell
- für
- mehr
- vor allem warme
- Am beliebtesten
- nämlich
- Namen
- Natürliche
- Bedürfnisse
- New York
- New York City
- Notion
- NYC
- Ontario
- Einkauf & Prozesse
- Organisiert
- Andere
- Papier
- Teil
- besonders
- Leistung
- person
- Bitte
- Punkte
- Beliebt
- Popularität
- BLOG-POSTS
- Werkzeuge
- Prognosen
- Prämie
- ziemlich
- früher
- Aufgabenstellung:
- produziert
- Produkt
- Projekt
- prominent
- bietet
- Frage
- Leser
- Lesebrillen
- kürzlich
- kürzlich
- empfehlen
- Veteran
- Reduziert
- Reduzierung
- Verhältnis
- Release
- relevant
- zuverlässig
- bleibt bestehen
- Meldungen
- Darstellung
- erfordern
- Forschungsprojekte
- Resort
- Die Ergebnisse
- Ohne eine erfahrene Medienplanung zur Festlegung von Regeln und Strategien beschleunigt der programmatische Medieneinkauf einfach die Rate der verschwenderischen Ausgaben.
- Vertrieb
- gleich
- Skalieren
- Wertung
- mehrere
- Shadow
- Short
- Schild
- signifikant
- klein
- So
- einige
- etwas
- Raumfahrt
- spezialisiert
- Standard
- Bundesstaat
- Statistik
- strukturierte
- Studie
- eingereicht
- Aufsicht
- Support
- Unterstützte
- Oberfläche
- Umfrage
- System
- Systeme und Techniken
- Target
- und Aufgaben
- Technische
- Vorlagen
- Das
- die Welt
- Zeit
- heute
- gemeinsam
- Tokens
- Thema
- Ausbildung
- Transformieren
- Reise
- Uk
- einzigartiges
- Updates
- -
- verschiedene
- Sichtbarkeit
- W
- Netz
- wöchentlich
- Was
- WHO
- breiter
- Worte
- Arbeiten
- Werk
- weltweit wie ausgehandelt und gekauft ausgeführt wird.
- würde
- Jahr
- Ihr




