Einleitung
Willkommen zu unserem umfassenden Datenanalyse Blog, der tief in die Welt von Netflix eintaucht. Als eine der weltweit führenden Streaming-Plattformen hat Netflix die Art und Weise, wie wir Unterhaltung konsumieren, revolutioniert. Mit seiner umfangreichen Bibliothek an Filmen und Fernsehsendungen bietet es Zuschauern auf der ganzen Welt eine Fülle von Auswahlmöglichkeiten.
Die globale Reichweite von Netflix
Netflix hat ein bemerkenswertes Wachstum erlebt und seine Präsenz ausgebaut, um eine dominierende Kraft in der Streaming-Branche zu werden. Hier sind einige bemerkenswerte Statistiken, die seine globalen Auswirkungen veranschaulichen:
- Nutzerbasis: Bis zum Beginn des zweiten Quartals 2022 hatte Netflix ca. angehäuft 222 Millionen internationale Abonnenten, die sich über 190 Länder erstreckt (ohne China, Krim, Nordkorea, Russland und Syrien). Diese beeindruckenden Zahlen unterstreichen die große Akzeptanz und Beliebtheit der Plattform bei Zuschauern weltweit.
- Internationale Expansion: Mit seiner Verfügbarkeit in über 190 Ländern hat Netflix erfolgreich eine globale Präsenz aufgebaut. Das Unternehmen hat erhebliche Anstrengungen unternommen, um seine Inhalte zu lokalisieren, indem es Untertitel und Synchronisation in verschiedenen Sprachen anbietet und so die Zugänglichkeit für ein vielfältiges Publikum gewährleistet.
In diesem Blog begeben wir uns auf eine spannende Reise, um die faszinierenden Muster, Trends und Erkenntnisse zu erkunden, die in der Content-Landschaft von Netflix verborgen sind. Die Kraft nutzen von Python und sein Datenanalyse Bibliotheken tauchen wir in die umfangreiche Sammlung von Netflix-Angeboten ein, um wertvolle Informationen zu entdecken, die Aufschluss über Inhaltszusätze, Dauerverteilungen, Genrekorrelationen und sogar die am häufigsten verwendeten Wörter in Titeln und Beschreibungen geben.
Durch detaillierte Codeschnipsel und VisualisierungenWir werfen einen Blick auf die Ebenen des Content-Ökosystems von Netflix, um eine neue Perspektive auf die Entwicklung der Plattform zu bieten. Durch die Analyse von Veröffentlichungsmustern, saisonalen Trends und Publikumspräferenzen wollen wir die Inhaltsdynamik im riesigen Netflix-Universum besser verstehen.
Dieser Artikel wurde als Teil des veröffentlicht Data-Science-Blogathon.
Inhaltsverzeichnis
Datenaufbereitung
Die in dieser Fallstudie verwendeten Daten stammen von Kaggle, einer beliebten Plattform für Datenwissenschafts- und maschinelles Lernbegeisterte. Der Datensatz mit dem Titel „Netflix-Filme und Fernsehsendungen„“ ist auf Kaggle öffentlich verfügbar und bietet wertvolle Informationen zu den Filmen und Fernsehsendungen auf der Netflix-Streaming-Plattform.
Der Datensatz besteht aus einem tabellarischen Format mit verschiedenen Spalten, die die verschiedenen Aspekte jedes Films oder jeder Fernsehsendung beschreiben. Hier ist eine Tabelle mit einer Zusammenfassung der Spalten und ihrer Beschreibungen:
| Spaltenname | Beschreibung |
|---|---|
| show_id | Eindeutige ID für jeden Film/jede Fernsehsendung |
| tippe | Kennung – Ein Film oder eine Fernsehsendung |
| Titel | Titel des Films/der Fernsehsendung |
| Regisseur | Regisseur des Films |
| werfen | Am Film/Show beteiligte Schauspieler |
| Land | Land, in dem der Film/die Show produziert wurde |
| Datum hinzugefügt | Datum, an dem es auf Netflix hinzugefügt wurde |
| Erscheinungsjahr | Tatsächliches Erscheinungsjahr des Films/der Show |
| Wertung | TV-Bewertung des Films/der Show |
| Dauer | Gesamtdauer – in Minuten oder Anzahl der Staffeln |
In diesem Abschnitt führen wir Datenvorbereitungsaufgaben für den Netflix-Datensatz durch, um dessen Sauberkeit und Eignung für die Analyse sicherzustellen. Wir kümmern uns um fehlende Werte und Duplikate und führen bei Bedarf Datentypkonvertierungen durch. Lassen Sie uns in den Code eintauchen und jeden Schritt untersuchen.
Bibliotheken importieren
Zunächst importieren wir die notwendigen Bibliotheken für die Datenanalyse und -visualisierung. Zu diesen Bibliotheken gehören Pandas, Numpy und Matplotlib. Pyplot und Seaborn. Sie stellen wesentliche Funktionen und Werkzeuge zur effektiven Bearbeitung und Visualisierung der Daten bereit.
# Importing necessary libraries for data analysis and visualization
import pandas as pd # pandas for data manipulation and analysis
import numpy as np # numpy for numerical operations
import matplotlib.pyplot as plt # matplotlib for data visualization
import seaborn as sns # seaborn for enhanced data visualizationLaden des Datensatzes
Als nächstes laden wir den Netflix-Datensatz mit der Funktion pd.read_csv(). Der Datensatz wird in der Datei „netflix.csv“ gespeichert. Schauen wir uns die ersten fünf Datensätze des Datensatzes an, um seine Struktur zu verstehen.
# Loading the dataset from a CSV file
df = pd.read_csv('netflix.csv') # Displaying the first few rows of the dataset
df.head()Beschreibende Statistik
Es ist von entscheidender Bedeutung, die Gesamteigenschaften des Datensatzes zu verstehen beschreibende Statistik. Wir können Einblicke in die numerischen Attribute wie Anzahl, Mittelwert, Standardabweichung, Minimum, Maximum und Quartile gewinnen.
# Computing descriptive statistics for the dataset
df.describe()Prägnante Zusammenfassung
Um eine prägnante Zusammenfassung des Datensatzes zu erhalten, verwenden wir die Funktion df.info(). Es liefert Informationen über die Anzahl der Nicht-Null-Werte und die Datentypen jeder Spalte. Diese Zusammenfassung hilft dabei, fehlende Werte und potenzielle Probleme mit Datentypen zu identifizieren.
# Obtaining information about the dataset
df.info()Umgang mit fehlenden Werten
Fehlende Werte können eine genaue Analyse behindern. Dieser Datensatz untersucht die fehlenden Werte in jeder Spalte mit df. isnull().sum(). Unser Ziel ist es, die Spalten mit fehlenden Werten zu identifizieren und den Prozentsatz der fehlenden Daten in jeder Spalte zu bestimmen.
# Checking for missing values in the dataset
df.isnull().sum()Um mit fehlenden Werten umzugehen, wenden wir unterschiedliche Strategien für verschiedene Spalten an. Gehen wir jeden Schritt durch:
Duplikate
Duplikate können die Analyseergebnisse verfälschen, daher ist es wichtig, sie zu beheben. Wir identifizieren und entfernen doppelte Datensätze mit df.duplicated().sum().
# Checking for duplicate rows in the dataset
df.duplicated().sum()Umgang mit fehlenden Werten in bestimmten Spalten
Für die Spalten „Regisseur“ und „Besetzung“ ersetzen wir fehlende Werte durch „Keine Daten“, um die Datenintegrität aufrechtzuerhalten und Verzerrungen in der Analyse zu vermeiden.
# Replacing missing values in the 'director' column with 'No Data'
df['director'].replace(np.nan, 'No Data', inplace=True) # Replacing missing values in the 'cast' column with 'No Data'
df['cast'].replace(np.nan, 'No Data', inplace=True)In der Spalte „Land“ ergänzen wir fehlende Werte mit dem Modus (am häufigsten vorkommender Wert), um Konsistenz zu gewährleisten und Datenverluste zu minimieren.
# Filling missing values in the 'country' column with the mode value
df['country'] = df['country'].fillna(df['country'].mode()[0])Für die Spalte „Bewertung“ ergänzen wir fehlende Werte basierend auf dem „Typ“ der Sendung. Wir weisen den Modus „Bewertung“ für Filme und Fernsehsendungen separat zu.
# Finding the mode rating for movies and TV shows
movie_rating = df.loc[df['type'] == 'Movie', 'rating'].mode()[0]
tv_rating = df.loc[df['type'] == 'TV Show', 'rating'].mode()[0] # Filling missing rating values based on the type of content
df['rating'] = df.apply(lambda x: movie_rating if x['type'] == 'Movie' and pd.isna(x['rating']) else tv_rating if x['type'] == 'TV Show' and pd.isna(x['rating']) else x['rating'], axis=1)Für die Spalte „Dauer“ füllen wir fehlende Werte basierend auf der „Art“ der Show aus. Wir weisen den Modus „Dauer“ für Filme und Fernsehsendungen separat zu.
# Finding the mode duration for movies and TV shows
movie_duration_mode = df.loc[df['type'] == 'Movie', 'duration'].mode()[0]
tv_duration_mode = df.loc[df['type'] == 'TV Show', 'duration'].mode()[0] # Filling missing duration values based on the type of content
df['duration'] = df.apply(lambda x: movie_duration_mode if x['type'] == 'Movie' and pd.isna(x['duration']) else tv_duration_mode if x['type'] == 'TV Show' and pd.isna(x['duration']) else x['duration'], axis=1)Verbleibende fehlende Werte löschen
Nachdem wir fehlende Werte in bestimmten Spalten behandelt haben, löschen wir alle verbleibenden Zeilen mit fehlenden Werten, um einen sauberen Datensatz für die Analyse sicherzustellen.
# Dropping rows with missing values
df.dropna(inplace=True)Datumsverwaltung
Wir konvertieren die Spalte „date_added“ mit pd.to_datetime() in das Datetime-Format, um eine weitere Analyse basierend auf datumsbezogenen Attributen zu ermöglichen.
# Converting the 'date_added' column to datetime format
df["date_added"] = pd.to_datetime(df['date_added'])Zusätzliche Datentransformationen
Wir extrahieren zusätzliche Attribute aus der Spalte „date_added“, um unsere Analysemöglichkeiten zu verbessern. Wir entfernen die Monats- und Jahreswerte, um Trends basierend auf diesen zeitlichen Aspekten zu analysieren.
# Extracting month, month name, and year from the 'date_added' column
df['month_added'] = df['date_added'].dt.month
df['month_name_added'] = df['date_added'].dt.month_name()
df['year_added'] = df['date_added'].dt.yearDatentransformation: Besetzung, Land, aufgeführt in und Regisseur
Um kategoriale Attribute effektiver zu analysieren, wandeln wir sie in separate Datenrahmen um, was eine entspanntere Erkundung und Analyse ermöglicht.
Für die Spalten „Besetzung“, „Land“, „Listed_in“ und „Regisseur“ haben wir die Werte anhand des Kommatrennzeichens aufgeteilt und für jeden Wert separate Zeilen erstellt. Diese Transformation ermöglicht es uns, die Daten auf einer detaillierteren Ebene zu analysieren.
# Splitting and expanding the 'cast' column
df_cast = df['cast'].str.split(',', expand=True).stack()
df_cast = df_cast.reset_index(level=1, drop=True).to_frame('cast')
df_cast['show_id'] = df['show_id'] # Splitting and expanding the 'country' column
df_country = df['country'].str.split(',', expand=True).stack()
df_country = df_country.reset_index(level=1, drop=True).to_frame('country')
df_country['show_id'] = df['show_id'] # Splitting and expanding the 'listed_in' column
df_listed_in = df['listed_in'].str.split(',', expand=True).stack()
df_listed_in = df_listed_in.reset_index(level=1, drop=True).to_frame('listed_in')
df_listed_in['show_id'] = df['show_id'] # Splitting and expanding the 'director' column
df_director = df['director'].str.split(',', expand=True).stack()
df_director = df_director.reset_index(level=1, drop=True).to_frame('director')
df_director['show_id'] = df['show_id']Nach Abschluss dieser Datenvorbereitungsschritte steht uns ein sauberer und transformierter Datensatz zur weiteren Analyse zur Verfügung. Diese ersten Datenmanipulationen bilden die Grundlage für die Erkundung des Netflix-Datensatzes und die Gewinnung von Erkenntnissen über die datengesteuerten Strategien der Streaming-Plattform.
Explorative Datenanalyse
Verteilung von Inhaltstypen
Um die Verteilung von Inhalten in der Netflix-Bibliothek zu bestimmen, können wir die prozentuale Verteilung von Inhaltstypen (Filme und Fernsehsendungen) mithilfe des folgenden Codes berechnen:
# Calculate the percentage distribution of content types
x = df.groupby(['type'])['type'].count()
y = len(df)
r = ((x/y) * 100).round(2) # Create a DataFrame to store the percentage distribution
mf_ratio = pd.DataFrame(r)
mf_ratio.rename({'type': '%'}, axis=1, inplace=True) # Plot the 3D-effect pie chart
plt.figure(figsize=(12, 8))
colors = ['#b20710', '#221f1f']
explode = (0.1, 0)
plt.pie(mf_ratio['%'], labels=mf_ratio.index, autopct='%1.1f%%', colors=colors, explode=explode, shadow=True, startangle=90, textprops={'color': 'white'}) plt.legend(loc='upper right')
plt.title('Distribution of Content Types')
plt.show()
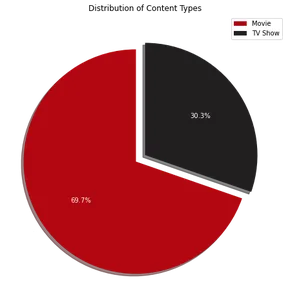
Die Tortendiagramm-Visualisierung zeigt, dass etwa 70 % der Inhalte auf Netflix aus Filmen bestehen, während die restlichen 30 % Fernsehsendungen sind. Als Nächstes können wir den folgenden Code verwenden, um die 10 Länder zu identifizieren, in denen Netflix am beliebtesten ist:
Top 10 Länder, in denen Netflix beliebt ist
Als Nächstes können wir den folgenden Code verwenden, um die 10 Länder zu identifizieren, in denen Netflix am beliebtesten ist:
# Remove white spaces from 'country' column
df_country['country'] = df_country['country'].str.rstrip() # Find value counts
country_counts = df_country['country'].value_counts() # Select the top 10 countries
top_10_countries = country_counts.head(10) # Plot the top 10 countries
plt.figure(figsize=(16, 10))
colors = ['#b20710'] + ['#221f1f'] * (len(top_10_countries) - 1)
bar_plot = sns.barplot(x=top_10_countries.index, y=top_10_countries.values, palette=colors) plt.xlabel('Country')
plt.ylabel('Number of Titles')
plt.title('Top 10 Countries Where Netflix is Popular') # Add count values on top of each bar
for index, value in enumerate(top_10_countries.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') plt.show()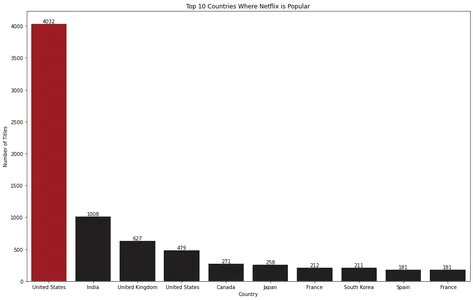
Die Balkendiagramm-Visualisierung zeigt, dass die Vereinigten Staaten das Land sind, in dem Netflix am beliebtesten ist.
Top 10 Schauspieler nach Anzahl der Filme/Fernsehsendungen
Um die Top-10-Schauspieler mit den meisten Auftritten in Filmen und Fernsehsendungen zu identifizieren, können Sie den folgenden Code verwenden:
# Count the occurrences of each actor
cast_counts = df_cast['cast'].value_counts()[1:] # Select the top 10 actors
top_10_cast = cast_counts.head(10) plt.figure(figsize=(16, 8))
colors = ['#b20710'] + ['#221f1f'] * (len(top_10_cast) - 1)
bar_plot = sns.barplot(x=top_10_cast.index, y=top_10_cast.values, palette=colors) plt.xlabel('Actor')
plt.ylabel('Number of Appearances')
plt.title('Top 10 Actors by Movie/TV Show Count') # Add count values on top of each bar
for index, value in enumerate(top_10_cast.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') plt.show()
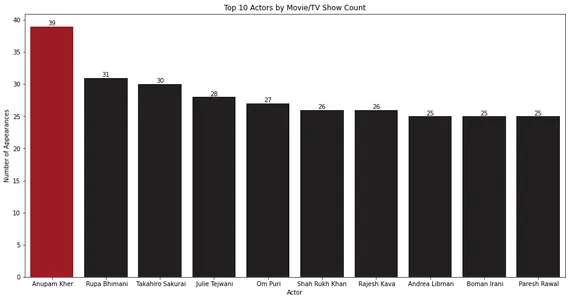
Das Balkendiagramm zeigt, dass Anupam Kher die häufigsten Auftritte in Filmen und Fernsehsendungen hat.
Top 10 Regisseure nach Anzahl der Filme/Fernsehsendungen
Um die Top-10-Regisseure zu identifizieren, die die meisten Filme oder Fernsehsendungen gedreht haben, können Sie den folgenden Code verwenden:
# Count the occurrences of each actor
director_counts = df_director['director'].value_counts()[1:] # Select the top 10 actors
top_10_directors = director_counts.head(10) plt.figure(figsize=(16, 8))
colors = ['#b20710'] + ['#221f1f'] * (len(top_10_directors) - 1)
bar_plot = sns.barplot(x=top_10_directors.index, y=top_10_directors.values, palette=colors) plt.xlabel('Director')
plt.ylabel('Number of Movies/TV Shows')
plt.title('Top 10 Directors by Movie/TV Show Count') # Add count values on top of each bar
for index, value in enumerate(top_10_directors.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') plt.show()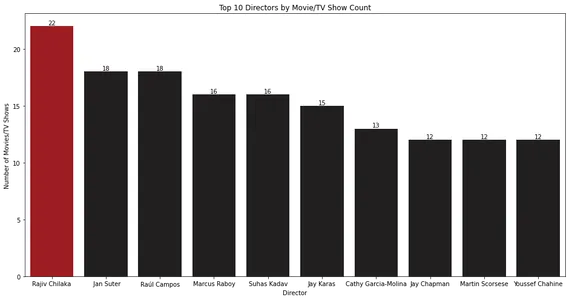
Das Balkendiagramm zeigt die Top-10-Regisseure mit den meisten Filmen oder Fernsehsendungen. Rajiv Chilaka scheint bei den meisten Inhalten in der Netflix-Bibliothek Regie geführt zu haben.
Top 10 Kategorien nach Anzahl der Filme/Fernsehsendungen
Um die Verteilung von Inhalten in verschiedenen Kategorien zu analysieren, können Sie den folgenden Code verwenden:
df_listed_in['listed_in'] = df_listed_in['listed_in'].str.strip() # Count the occurrences of each actor
listed_in_counts = df_listed_in['listed_in'].value_counts() # Select the top 10 actors
top_10_listed_in = listed_in_counts.head(10) plt.figure(figsize=(12, 8))
bar_plot = sns.barplot(x=top_10_listed_in.index, y=top_10_listed_in.values, palette=colors) # Customize the plot
plt.xlabel('Category')
plt.ylabel('Number of Movies/TV Shows')
plt.title('Top 10 Categories by Movie/TV Show Count')
plt.xticks(rotation=45) # Add count values on top of each bar
for index, value in enumerate(top_10_listed_in.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') # Show the plot
plt.show()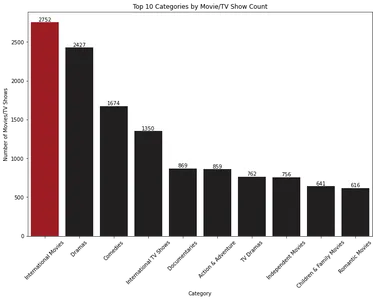
Das Balkendiagramm zeigt die Top-10-Kategorien von Filmen und Fernsehsendungen basierend auf ihrer Anzahl. „Internationale Filme“ ist die dominierende Kategorie, gefolgt von „Dramen“.
Im Laufe der Zeit hinzugefügte Filme und Fernsehsendungen
Um die Hinzufügung von Filmen und Fernsehsendungen im Laufe der Zeit zu analysieren, können Sie den folgenden Code verwenden:
# Filter the DataFrame to include only Movies and TV Shows
df_movies = df[df['type'] == 'Movie']
df_tv_shows = df[df['type'] == 'TV Show'] # Group the data by year and count the number of Movies and TV Shows # added in each year
movies_count = df_movies['year_added'].value_counts().sort_index()
tv_shows_count = df_tv_shows['year_added'].value_counts().sort_index() # Create a line chart to visualize the trends over time
plt.figure(figsize=(16, 8))
plt.plot(movies_count.index, movies_count.values, color='#b20710', label='Movies', linewidth=2)
plt.plot(tv_shows_count.index, tv_shows_count.values, color='#221f1f', label='TV Shows', linewidth=2) # Fill the area under the line charts
plt.fill_between(movies_count.index, movies_count.values, color='#b20710')
plt.fill_between(tv_shows_count.index, tv_shows_count.values, color='#221f1f') # Customize the plot
plt.xlabel('Year')
plt.ylabel('Count')
plt.title('Movies & TV Shows Added Over Time')
plt.legend() # Show the plot
plt.show()
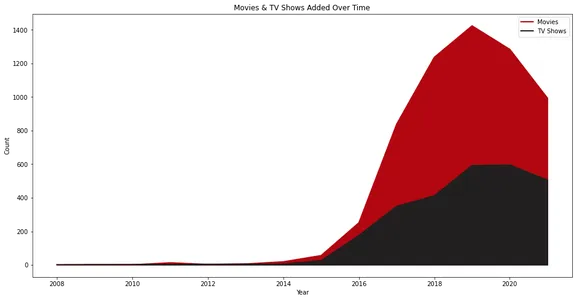
Das Liniendiagramm veranschaulicht die Anzahl der Filme und Fernsehsendungen, die im Laufe der Zeit zu Netflix hinzugefügt wurden. Es stellt das Wachstum und die Trends bei der Ergänzung von Inhalten visuell dar, mit separaten Zeilen für Filme und Fernsehsendungen.
Netflix erlebte sein wahres Wachstum ab dem Jahr 2015 und wir können sehen, dass im Laufe der Jahre mehr Filme als Fernsehsendungen hinzugefügt wurden.
Interessant ist auch, dass das Hinzufügen von Inhalten im Jahr 2020 zurückgegangen ist. Dies könnte auf die Pandemie-Situation zurückzuführen sein.
Als nächstes untersuchen wir die Verteilung der Inhaltsergänzungen über verschiedene Monate. Diese Analyse hilft uns, Muster zu erkennen und zu verstehen, wann Netflix neue Inhalte einführt.
Monatlich hinzugefügter Inhalt
Um dies zu untersuchen, extrahieren wir den Monat aus der Spalte „date_added“ und zählen die Vorkommen jedes Monats. Durch die Visualisierung dieser Daten als Balkendiagramm können wir schnell die Monate mit den höchsten Inhaltszugängen identifizieren.
# Extract the month from the 'date_added' column
df['month_added'] = pd.to_datetime(df['date_added']).dt.month_name() # Define the order of the months
month_order = ['January', 'February', 'March', 'April', 'May', 'June', 'July', 'August', 'September', 'October', 'November', 'December'] # Count the number of shows added in each month
monthly_counts = df['month_added'].value_counts().loc[month_order] # Determine the maximum count
max_count = monthly_counts.max() # Set the color for the highest bar and the rest of the bars
colors = ['#b20710' if count == max_count else '#221f1f' for count in monthly_counts] # Create the bar chart
plt.figure(figsize=(16, 8))
bar_plot = sns.barplot(x=monthly_counts.index, y=monthly_counts.values, palette=colors) # Customize the plot
plt.xlabel('Month')
plt.ylabel('Count')
plt.title('Content Added by Month') # Add count values on top of each bar
for index, value in enumerate(monthly_counts.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') # Rotate x-axis labels for better readability
plt.xticks(rotation=45) # Show the plot
plt.show()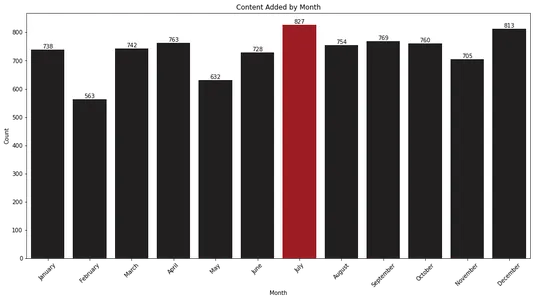
Das Balkendiagramm zeigt, dass Juli und Dezember die Monate sind, in denen Netflix die meisten Inhalte zu seiner Bibliothek hinzufügt. Diese Informationen können für Zuschauer wertvoll sein, die in diesen Monaten neue Veröffentlichungen erwarten möchten.
Ein weiterer entscheidender Aspekt der Inhaltsanalyse von Netflix ist das Verständnis der Verteilung der Bewertungen. Indem wir die Anzahl der einzelnen Bewertungskategorien untersuchen, können wir die am häufigsten vorkommenden Inhaltstypen auf der Plattform ermitteln.
Verteilung der Bewertungen
Wir berechnen zunächst die Vorkommen jeder Bewertungskategorie und visualisieren diese anhand eines Balkendiagramms. Diese Visualisierung bietet einen klaren Überblick über die Verteilung der Bewertungen.
# Count the occurrences of each rating
rating_counts = df['rating'].value_counts() # Create a bar chart to visualize the ratings
plt.figure(figsize=(16, 8))
colors = ['#b20710'] + ['#221f1f'] * (len(rating_counts) - 1)
sns.barplot(x=rating_counts.index, y=rating_counts.values, palette=colors) # Customize the plot
plt.xlabel('Rating')
plt.ylabel('Count')
plt.title('Distribution of Ratings') # Rotate x-axis labels for better readability
plt.xticks(rotation=45) # Show the plot
plt.show()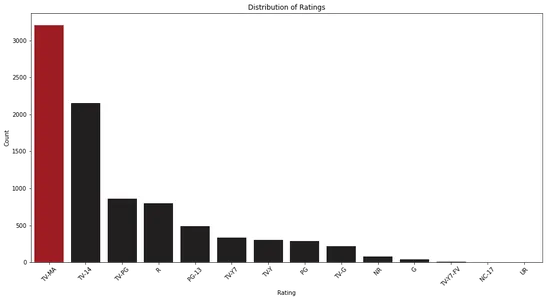
Bei der Analyse des Balkendiagramms können wir die Verteilung der Bewertungen auf Netflix beobachten. Es hilft uns, die häufigsten Bewertungskategorien und ihre relative Häufigkeit zu identifizieren.
Genre-Korrelations-Heatmap
Genres spielen eine wichtige Rolle bei der Kategorisierung und Organisation von Inhalten auf Netflix. Die Analyse der Korrelation zwischen Genres kann interessante Beziehungen zwischen verschiedenen Arten von Inhalten aufdecken.
Wir erstellen einen Genre-Daten-DataFrame, um die Genre-Korrelation zu untersuchen und ihn mit Nullen zu füllen. Indem wir jede Zeile im ursprünglichen DataFrame durchlaufen, aktualisieren wir den Genre-Daten-DataFrame basierend auf den aufgelisteten Genres. Anschließend erstellen wir anhand dieser Genredaten eine Korrelationsmatrix und visualisieren diese als Heatmap.
# Extracting unique genres from the 'listed_in' column
genres = df['listed_in'].str.split(', ', expand=True).stack().unique() # Create a new DataFrame to store the genre data
genre_data = pd.DataFrame(index=genres, columns=genres, dtype=float) # Fill the genre data DataFrame with zeros
genre_data.fillna(0, inplace=True) # Iterate over each row in the original DataFrame and update the genre data DataFrame
for _, row in df.iterrows(): listed_in = row['listed_in'].split(', ') for genre1 in listed_in: for genre2 in listed_in: genre_data.at[genre1, genre2] += 1 # Create a correlation matrix using the genre data
correlation_matrix = genre_data.corr() # Create the heatmap
plt.figure(figsize=(20, 16))
sns.heatmap(correlation_matrix, annot=False, cmap='coolwarm') # Customize the plot
plt.title('Genre Correlation Heatmap')
plt.xticks(rotation=90)
plt.yticks(rotation=0) # Show the plot
plt.show()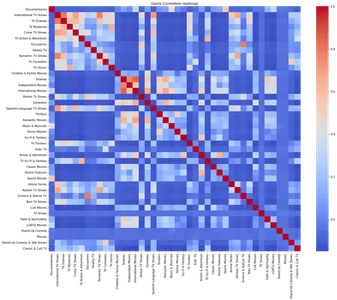
Die Heatmap zeigt die Korrelation zwischen verschiedenen Genres. Durch die Analyse der Heatmap können wir starke positive Korrelationen zwischen bestimmten Genres identifizieren, z. B. TV-Dramen und internationalen TV-Shows, romantischen TV-Shows und internationalen TV-Shows.
Verteilung der Filmlängen und der Anzahl der TV-Sendungen
Wenn Sie die Dauer von Filmen und Fernsehsendungen verstehen, erhalten Sie Einblicke in die Länge des Inhalts und können den Zuschauern helfen, ihre Sehzeit zu planen. Indem wir die Verteilung der Filmlängen und der Dauer von Fernsehsendungen untersuchen, können wir die auf Netflix verfügbaren Inhalte besser verstehen.
Um dies zu erreichen, extrahieren wir die Filmlängen und die Anzahl der TV-Sendungen aus der Spalte „Dauer“. Anschließend erstellen wir Histogramme und Boxplots, um die Verteilung der Filmlängen und der Dauer von Fernsehsendungen zu visualisieren.
# Extract the movie lengths and TV show episode counts
movie_lengths = df_movies['duration'].str.extract('(d+)', expand=False).astype(int)
tv_show_episodes = df_tv_shows['duration'].str.extract('(d+)', expand=False).astype(int) # Plot the histogram
plt.figure(figsize=(10, 6))
plt.hist(movie_lengths, bins=10, color='#b20710', label='Movies')
plt.hist(tv_show_episodes, bins=10, color='#221f1f', label='TV Shows') # Customize the plot
plt.xlabel('Duration/Episode Count')
plt.ylabel('Frequency')
plt.title('Distribution of Movie Lengths and TV Show Episode Counts')
plt.legend() # Show the plot
plt.show()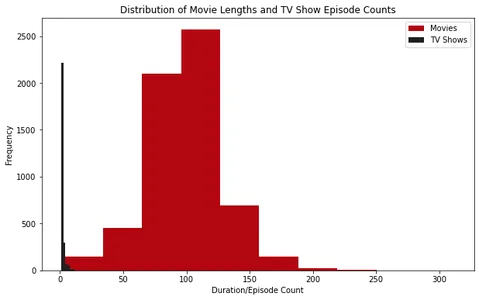
Bei der Analyse der Histogramme können wir feststellen, dass die meisten Filme auf Netflix eine Dauer von etwa 100 Minuten haben. Andererseits haben die meisten Fernsehsendungen auf Netflix nur eine Staffel.
Darüber hinaus können wir bei der Untersuchung der Boxplots erkennen, dass Filme, die länger als etwa 2.5 Stunden dauern, als Ausreißer gelten. Bei Fernsehsendungen ist es ungewöhnlich, Sendungen mit mehr als vier Staffeln zu finden.
Der Trend der Längen von Filmen/Fernsehsendungen im Laufe der Jahre
Wir können Liniendiagramme zeichnen, um zu verstehen, wie sich Filmlängen und Episodenzahlen von Fernsehsendungen im Laufe der Jahre entwickelt haben. Identifizieren von Mustern oder Verschiebungen in der Inhaltsdauer durch Analyse dieser Trends.
Wir beginnen damit, die Filmlängen und die Anzahl der TV-Sendungen aus der Spalte „Dauer“ zu extrahieren. Anschließend erstellen wir Liniendiagramme, um die Veränderungen der Filmlängen und Episoden von Fernsehsendungen im Laufe der Jahre zu visualisieren.
import seaborn as sns
import matplotlib.pyplot as plt # Extract the movie lengths and TV show episodes from the 'duration' column
movie_lengths = df_movies['duration'].str.extract('(d+)', expand=False).astype(int)
tv_show_episodes = df_tv_shows['duration'].str.extract('(d+)', expand=False).astype(int) # Create line plots for movie lengths and TV show episodes
plt.figure(figsize=(16, 8)) plt.subplot(2, 1, 1)
sns.lineplot(data=df_movies, x='release_year', y=movie_lengths, color=colors[0])
plt.xlabel('Release Year')
plt.ylabel('Movie Length')
plt.title('Trend of Movie Lengths Over the Years') plt.subplot(2, 1, 2)
sns.lineplot(data=df_tv_shows, x='release_year', y=tv_show_episodes,color=colors[1])
plt.xlabel('Release Year')
plt.ylabel('TV Show Episodes')
plt.title('Trend of TV Show Episodes Over the Years') # Adjust the layout and spacing
plt.tight_layout() # Show the plots
plt.show()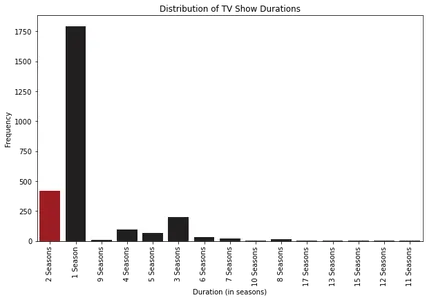
Bei der Analyse der Liniendiagramme beobachten wir spannende Muster. Wir können sehen, dass die Filmlänge zunächst bis etwa 1963–1964 zunahm und dann allmählich abnahm und sich bei einem Durchschnitt von 100 Minuten stabilisierte. Dies deutet auf eine Verschiebung der Publikumspräferenzen im Laufe der Zeit hin.
Bei den Episoden von Fernsehsendungen beobachten wir seit Anfang der 2000er Jahre einen anhaltenden Trend, bei dem die meisten Fernsehsendungen auf Netflix eine bis drei Staffeln haben. Dies deutet darauf hin, dass die Zuschauer kürzere Serien oder limitierte Serienformate bevorzugen.
Die häufigsten Wörter in Titeln und Beschreibungen
Die Analyse der am häufigsten in Titeln und Beschreibungen verwendeten Wörter kann Einblicke in die Themen und Inhaltsschwerpunkte von Netflix geben. Wir können Wortwolken generieren, um diese Muster basierend auf den Titeln und Beschreibungen der Netflix-Inhalte aufzudecken.
from wordcloud import WordCloud # Concatenate all the titles into a single string
text = ' '.join(df['title']) wordcloud = WordCloud(width = 800, height = 800, background_color ='white', min_font_size = 10).generate(text) # plot the WordCloud image
plt.figure(figsize = (8, 8), facecolor = None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad = 0) plt.show() # Concatenate all the titles into a single string
text = ' '.join(df['description']) wordcloud = WordCloud(width = 800, height = 800, background_color ='white', min_font_size = 10).generate(text) # plot the WordCloud image
plt.figure(figsize = (8, 8), facecolor = None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad = 0) plt.show()
Wenn wir die Wortwolke nach Titeln untersuchen, stellen wir fest, dass Begriffe wie „Liebe“, „Mädchen“, „Mann“, „Leben“ und „Welt“ häufig verwendet werden, was auf die Präsenz von Romantik, Erwachsenwerden und Drama hinweist Genres in der Inhaltsbibliothek von Netflix.
Bei der Analyse der Wortwolke nach Beschreibungen fallen uns dominante Wörter wie „Leben“, „finden“ und „Familie“ auf, die auf Themen wie persönliche Reisen, Beziehungen und Familiendynamik hinweisen, die in den Inhalten von Netflix vorherrschen.
Dauerverteilung für Filme und Fernsehsendungen
Durch die Analyse der Dauerverteilung von Filmen und Fernsehsendungen können wir die typische Länge der auf Netflix verfügbaren Inhalte verstehen. Wir können Boxplots erstellen, um diese Verteilungen zu visualisieren und Ausreißer oder Standarddauern zu identifizieren.
# Extracting and converting the duration for movies
df_movies['duration'] = df_movies['duration'].str.extract('(d+)', expand=False).astype(int) # Creating a boxplot for movie duration
plt.figure(figsize=(10, 6))
sns.boxplot(data=df_movies, x='type', y='duration')
plt.xlabel('Content Type')
plt.ylabel('Duration')
plt.title('Distribution of Duration for Movies')
plt.show() # Extracting and converting the duration for TV shows
df_tv_shows['duration'] = df_tv_shows['duration'].str.extract('(d+)', expand=False).astype(int) # Creating a boxplot for TV show duration
plt.figure(figsize=(10, 6))
sns.boxplot(data=df_tv_shows, x='type', y='duration')
plt.xlabel('Content Type')
plt.ylabel('Duration')
plt.title('Distribution of Duration for TV Shows')
plt.show()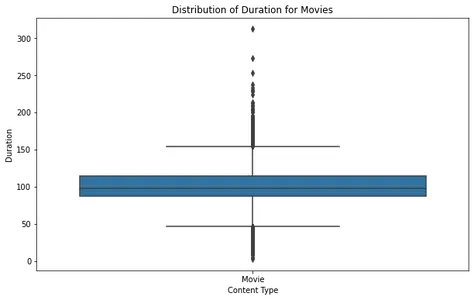
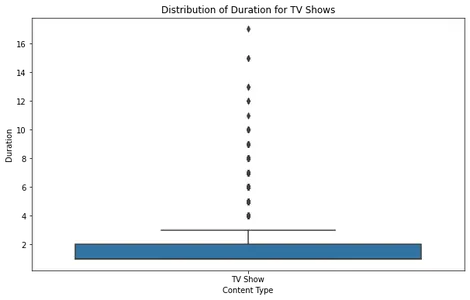
Bei der Analyse des Boxplots des Films können wir erkennen, dass die meisten Filme in einem angemessenen Dauerbereich liegen, wobei nur wenige Ausreißer etwa 2.5 Stunden überschreiten. Dies deutet darauf hin, dass die meisten Filme auf Netflix so konzipiert sind, dass sie in eine Standard-Sehdauer passen.
Bei Fernsehsendungen zeigt der Boxplot, dass die meisten Sendungen eine bis vier Staffeln haben, wobei nur sehr wenige Ausreißer eine längere Dauer haben. Dies deckt sich mit den früheren Trends und deutet darauf hin, dass Netflix sich auf kürzere Serienformate konzentriert.
Zusammenfassung
Mithilfe dieses Artikels konnten wir Folgendes erfahren:
- Menge: Unsere Analyse ergab, dass Netflix mehr Filme als Fernsehsendungen hinzugefügt hat, was mit der Erwartung übereinstimmt, dass Filme seine Inhaltsbibliothek dominieren.
- Hinzufügung von Inhalten: Der Juli erwies sich als der Monat, in dem Netflix die meisten Inhalte hinzufügte, dicht gefolgt vom Dezember, was auf einen strategischen Ansatz bei der Veröffentlichung von Inhalten hinweist.
- Genrekorrelation: Es wurden starke positive Assoziationen zwischen verschiedenen Genres beobachtet, beispielsweise zwischen Fernsehdramen und internationalen Fernsehsendungen, romantischen und internationalen Fernsehsendungen sowie unabhängigen Filmen und Dramen. Diese Korrelationen geben Einblicke in Zuschauerpräferenzen und inhaltliche Zusammenhänge.
- Filmlängen: Die Analyse der Filmlängen ergab einen Höhepunkt um die 1960er Jahre, gefolgt von einer Stabilisierung bei etwa 100 Minuten, was einen Trend bei der Filmlänge im Laufe der Zeit verdeutlicht.
- Episoden von Fernsehsendungen: Die meisten Fernsehsendungen auf Netflix haben eine Staffel, was darauf hindeutet, dass die Zuschauer kürzere Serien bevorzugen.
- Häufige Themen: Wörter wie Liebe, Leben, Familie und Abenteuer wurden häufig in Titeln und Beschreibungen gefunden und spiegeln wiederkehrende Themen in Netflix-Inhalten wider.
- Bewertungsverteilung: Die Verteilung der Bewertungen über die Jahre bietet Einblicke in die sich entwickelnde Inhaltslandschaft und die Publikumsrezeption.
- Datengesteuerte Erkenntnisse: Unsere Reise zur Datenanalyse zeigte die Macht von Daten bei der Entschlüsselung der Geheimnisse der Netflix-Inhaltslandschaft und lieferte wertvolle Erkenntnisse für Zuschauer und Inhaltsersteller.
- Anhaltende Relevanz: Da sich die Streaming-Branche weiterentwickelt, wird das Verständnis dieser Muster und Trends immer wichtiger, um sich in der dynamischen Landschaft von Netflix und seiner umfangreichen Bibliothek zurechtzufinden.
- Viel Spaß beim Streamen: Wir hoffen, dass dieser Blog eine aufschlussreiche und unterhaltsame Reise in die Welt von Netflix war und ermutigen Sie, die fesselnden Geschichten in den sich ständig ändernden Inhaltsangeboten zu erkunden. Lassen Sie sich bei Ihren Streaming-Abenteuern von den Daten leiten!
Offizielle Dokumentation und Ressourcen
Nachfolgend finden Sie die offiziellen Links zu den in unserer Analyse verwendeten Bibliotheken. Weitere Informationen zu den von diesen Bibliotheken bereitgestellten Methoden und Funktionen finden Sie unter diesen Links:
- Pandas: https://pandas.pydata.org/
- numPy: https://numpy.org/
- matplotlib: https://matplotlib.org/
- SciPy: https://scipy.org/
- Seegeboren: https://seaborn.pydata.org/
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.
Verbunden
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoAiStream. Web3-Datenintelligenz. Wissen verstärkt. Hier zugreifen.
- Die Zukunft prägen mit Adryenn Ashley. Hier zugreifen.
- Kaufen und verkaufen Sie Anteile an PRE-IPO-Unternehmen mit PREIPO®. Hier zugreifen.
- Quelle: https://www.analyticsvidhya.com/blog/2023/06/netflix-case-study-eda-unveiling-data-driven-strategies-for-streaming/
- :hast
- :Ist
- :nicht
- :Wo
- 1
- 10
- 100
- 12
- 20
- 2015
- 2020
- 2022
- 8
- 9
- a
- Fähig
- Über Uns
- Fülle
- Akzeptanz
- Zugänglichkeit
- genau
- Erreichen
- über
- Akteure
- hinzufügen
- hinzugefügt
- Zusatz
- Zusätzliche
- Zugänge
- Adresse
- Fügt
- Abenteuer
- Ziel
- Richtet sich aus
- Alle
- Zulassen
- erlaubt
- angehäuft
- unter
- an
- Analyse
- Analytik
- Analytics-Vidhya
- analysieren
- Analyse
- und
- erwarten
- jedem
- Auftritte
- Ansatz
- ca.
- April
- SIND
- Bereich
- um
- Artikel
- AS
- Aussehen
- Aspekte
- Verbände
- At
- Attribute
- Publikum
- AUGUST
- Verfügbarkeit
- verfügbar
- durchschnittlich
- vermeiden
- Zurück
- Bar
- Riegel
- Base
- basierend
- BE
- werden
- wird
- war
- beginnen
- Anfang
- unten
- Besser
- zwischen
- vorspannen
- Blog
- Boden
- Box
- by
- Berechnen
- Berechnung
- CAN
- Fähigkeiten
- bestechend
- Capturing
- Häuser
- Fallstudie
- Kategorien
- Kategorisieren
- Kategorie
- Center
- Änderungen
- Charakteristik
- Chart
- Charts
- Überprüfung
- China
- Entscheidungen
- klar
- eng
- Cloud
- Code
- Sammlung
- Farbe
- Kolonne
- Spalten
- gemeinsam
- häufig
- Unternehmen
- Abschluss
- umfassend
- Computing
- betrachtet
- konsistent
- besteht
- verbrauchen
- Inhalt
- Inhaltsentwickler
- Inhaltstypen
- Konvertierungen
- verkaufen
- Umwandlung
- Korrelation
- Korrelationen
- könnte
- Ländern
- Land
- erstellen
- erstellt
- Erstellen
- Schöpfer
- wichtig
- anpassen
- technische Daten
- Datenanalyse
- Data Loss
- Datenaufbereitung
- Datenwissenschaft
- Datenvisualisierung
- datengesteuerte
- Datengesteuerte Strategie
- datetime
- Dezember
- tief
- zeigt
- beschreiben
- Beschreibung
- entworfen
- detailliert
- Bestimmen
- Abweichung
- anders
- gerichtet
- Direktor
- Geschäftsführung
- Diskretion
- Anzeige
- Displays
- Verteilung
- Ausschüttungen
- verschieden
- Vielfältiges Publikum
- Dokumentation
- dominant
- dominieren
- Drama
- Drop
- fallen gelassen
- Abwurf
- zwei
- Duplikate
- Dauer
- im
- dynamisch
- Dynamik
- jeder
- Früher
- Früh
- Ökosystem
- effektiv
- Bemühungen
- sonst
- einsteigen
- entstanden
- ermöglichen
- ermöglicht
- ermutigen
- zu steigern,
- verbesserte
- gewährleisten
- Gewährleistung
- unterhaltsam
- Unterhaltung
- Enthusiasten
- Folge anschauen
- Folgen
- essential
- etablierten
- Äther (ETH)
- Sogar
- ständig wechselnd
- Jedes
- entwickelt
- entwickelt sich
- sich entwickelnden
- Untersuchen
- unterhaltsame Programmpunkte
- ohne
- ergänzt
- Ausbau
- Expansion
- Erwartung
- erfahrensten
- Exploration
- ERKUNDEN
- erforscht
- Möglichkeiten sondieren
- Extrakt
- Fallen
- Familie
- Februar
- wenige
- Zahlen
- Reichen Sie das
- füllen
- Filme
- Filme
- Filter
- Finden Sie
- Suche nach
- Vorname
- passen
- Setzen Sie mit Achtsamkeit
- konzentriert
- gefolgt
- Folgende
- Aussichten für
- Zwingen
- Format
- gefunden
- Foundation
- vier
- Frequenz
- häufig
- frisch
- für
- Funktion
- Funktionsumfang
- Funktionen
- weiter
- Gewinnen
- erzeugen
- bekommen
- Global
- globale Präsenz
- Global
- Go
- allmählich
- Gruppe an
- Wachstum
- Guide
- hätten
- Pflege
- Griff
- Handling
- Haben
- mit
- Höhe
- Hilfe
- hilft
- hier
- versteckt
- höchste
- Hervorheben
- behindern
- ein Geschenk
- STUNDEN
- Ultraschall
- HTTPS
- ID
- identifizieren
- Identifizierung
- if
- zeigt
- Image
- Impact der HXNUMXO Observatorien
- importieren
- Einfuhr
- beeindruckend
- in
- das
- hat
- zunehmend
- unabhängig
- Index
- angegeben
- zeigt
- Energiegewinnung
- Information
- Anfangs-
- anfänglich
- Einblicke
- Integrität
- interessant
- International
- in
- faszinierend
- Stellt vor
- untersuchen
- beteiligt
- Probleme
- IT
- SEINE
- Januar
- Reise
- Reisen
- Juli
- Juni
- Korea
- Etiketten
- Landschaft
- Sprachen
- Lagen
- Layout
- führenden
- LERNEN
- lernen
- Länge
- Niveau
- Nutzung
- Bibliotheken
- Bibliothek
- Lebensdauer
- !
- Gefällt mir
- Limitiert
- Line
- Linien
- Links
- Gelistet
- Belastung
- Laden
- länger
- aussehen
- Verlust
- ich liebe
- Maschine
- Maschinelles Lernen
- gemacht
- halten
- Manipulation
- März
- Matplotlib
- Matrix
- maximal
- Kann..
- bedeuten
- Medien
- Methoden
- Million
- minimieren
- Minimum
- Minuten
- Kommt demnächst...
- Model
- Monat
- Monat
- mehr
- vor allem warme
- Film
- Filme
- Name
- navigieren
- notwendig,
- erforderlich
- Netflix
- Neu
- weiter
- nicht
- Norden
- Nordkorea
- bemerkenswert
- Notiz..
- November
- Anzahl
- numpig
- beobachten
- beschaffen
- vorkommend
- Oktober
- of
- WOW!
- bieten
- Angebote
- Angebote
- offiziell
- on
- EINEM
- einzige
- Einkauf & Prozesse
- or
- Auftrag
- Organisieren
- Original
- Andere
- UNSERE
- übrig
- Gesamt-
- Überblick
- Besitz
- Unterlage
- Pandas
- Pandemie
- Teil
- Muster
- Haupt
- Prozentsatz
- ausführen
- persönliche
- Perspektive
- Plan
- Plattform
- Plattformen
- Plato
- Datenintelligenz von Plato
- PlatoData
- Play
- Beliebt
- Popularität
- positiv
- Potenzial
- Werkzeuge
- Vorlieben
- Vorbereitung
- Präsenz
- vorherrschend
- die
- vorausgesetzt
- bietet
- Bereitstellung
- öffentlich
- veröffentlicht
- Quartal
- schnell
- Angebot
- Wertung
- Bewertungen
- bereit
- echt
- vernünftig
- Rezeption
- Aufzeichnungen
- wiederkehrend
- Beziehungen
- relativ
- Release
- Mitteilungen
- Relevanz
- verbleibenden
- bemerkenswert
- entfernen
- ersetzen
- representiert
- REST
- Die Ergebnisse
- zeigen
- Revealed
- Enthüllt
- revolutioniert
- Recht
- Rollen
- REIHE
- Russland
- Wissenschaft
- Seeschneur
- Jahreszeit
- saisonal
- Jahreszeiten
- Zweite
- zweites Viertel
- Abschnitt
- sehen
- scheint
- getrennte
- getrennt
- September
- Modellreihe
- kompensieren
- verschieben
- Schichten
- erklären
- Vitrine
- präsentiert
- gezeigt
- Konzerte
- signifikant
- da
- Single
- Situation
- So
- einige
- bezogen
- Räume
- spezifisch
- gespalten
- Standard
- Anfang
- Beginnen Sie
- Staaten
- Statistiken
- Schritt
- Shritte
- speichern
- gelagert
- Geschichten
- Strategisch
- strategischer Ansatz
- Strategien
- Strategie
- Streaming
- Schnur
- stark
- Struktur
- Studie
- Untertitel
- Erfolgreich
- so
- Schlägt vor
- Eignung
- ZUSAMMENFASSUNG
- Syrien
- Tabelle
- und Aufgaben
- AGB
- als
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- Die Gegend
- die Welt
- ihr
- Sie
- dann
- Diese
- vom Nutzer definierten
- fehlen uns die Worte.
- diejenigen
- nach drei
- Durch
- Zeit
- Titel
- betitelt
- Titel
- zu
- Werkzeuge
- Top
- Top 10
- Transformieren
- Transformation
- verwandelt
- Trend
- Trends
- tv
- tv show
- tippe
- Typen
- typisch
- Ungewöhnlich
- aufdecken
- für
- unterstreichen
- verstehen
- Verständnis
- einzigartiges
- Vereinigt
- USA
- Universum
- bis
- Enthüllung
- Aktualisierung
- us
- -
- benutzt
- Verwendung von
- wertvoll
- Wertvolle Information
- Wert
- Werte
- verschiedene
- riesig
- sehr
- weltweit
- Besichtigung
- Visualisierung
- visualisieren
- wollen
- wurde
- beobachten
- we
- webp
- waren
- wann
- während
- Weiß
- WHO
- weit verbreitet
- werden wir
- mit
- .
- Word
- Worte
- weltweit wie ausgehandelt und gekauft ausgeführt wird.
- Das weltweit
- X
- Jahr
- Jahr
- U
- Ihr
- Zephyrnet