Haben Sie schon einmal auf dieses eine teure Paket gewartet, auf dem „versandt“ steht, aber Sie haben keine Ahnung, wo es ist? Der Tracking-Verlauf wurde vor fünf Tagen nicht mehr aktualisiert, und Sie haben fast die Hoffnung verloren. Aber warten Sie, 11 Tage später haben Sie es vor Ihrer Haustür. Sie hätten sich gewünscht, dass die Rückverfolgbarkeit besser sein könnte, um Sie von all dem ängstlichen Warten zu befreien. Hier kommt die „Beobachtbarkeit“ ins Spiel.
In einer technischen Umgebung möchten Sie vermeiden, dass dies Ihrer Software oder Ihren Datensystemen passiert. Und damit setzen Sie Überwachungstools ein, die die Protokolle und Metriken Ihrer Systeme sammeln und Sie über deren internen Zustand informieren. Die Überwachung funktioniert am besten, wenn Sie möchten, dass Ihre Systeme Sie darüber informieren, was der Fehler ist, wo und wann er aufgetreten ist, Ihnen aber nicht sagen, wie Sie den Fehler beheben können.
Vor mehr als einem Jahrzehnt fehlte Überwachungstools der Kontext und die Weitsicht auf zugrunde liegende Systemprobleme, und die Teams waren darauf beschränkt, alltägliche Betriebsfehler zu debuggen. Heute arbeiten und leben wir in einer verteilten Welt von Microservices und Datenpipelines; Selbst der Einsatz mehrerer Überwachungstools hilft Ihnen nicht dabei, Ihre geschäftlichen Fragen wie „Warum ist meine Anwendung immer langsam?“ zu beantworten. oder „In welcher Phase ist das Problem aufgetreten und wie tief ist es im Stack?“ oder „Wie kann ich die Gesamtleistung der Umgebung verbessern?“ Es ist notwendig, diese Entscheidungen proaktiv zu treffen und einen umfassenden Überblick über Ihre Systeme, Anwendungen und Daten zu haben.
Dieser Blog-Post von Etsy wurde vor einem Jahrzehnt veröffentlicht, und im zweiten Absatz heißt es:
„Anwendungsmetriken sind normalerweise die schwierigsten, aber wichtigsten der drei. Sie sind sehr spezifisch für dein Unternehmen und ändern sich, wenn sich deine Anwendungen ändern (und Etsy ändert sich stark).“
Wie messen wir also alles und jedes? Wir beginnen mit der Beobachtbarkeit.
Was ist Beobachtbarkeit?
Der Begriff „Beobachtbarkeit“ war geprägt von Rudolf Emil Kálmán im Jahr 1960 in seiner technischen Arbeit zur Beschreibung mathematischer Steuerungssysteme. Er definierte es als ein Maß dafür, wie gut aus der Kenntnis seiner externen Ausgänge auf interne Zustände eines Systems geschlossen werden kann. Aber klingt das nicht nach Überwachung? Grundsätzlich ja, es ist Überwachung.
Observability ist heutzutage ein ziemlich heißes Thema. Laut mehreren Marktstudien handelt es sich um eine milliardenschwere Plattform. Viele Unternehmen haben das Konzept übernommen und als Rahmenwerk für die End-to-End-Sichtbarkeit ihrer verteilten Systeme und Pipelines eingesetzt. Beobachtbarkeit wird jedoch mit Überwachung verwechselt. Im Moment kann ich sagen, dass Überwachung eine Teilmenge der Beobachtbarkeit ist, wobei Beobachtbarkeit ein großer Überbegriff ist.
Die Beobachtbarkeit ermöglicht eine verteilte Ablaufverfolgung durch das Sammeln und Aggregieren von Ablaufverfolgungen, Protokollen und Metriken. Mal sehen, was diese schließen:
- Spuren: Wenn ein System eine Anfrage erhält, erfahren Sie anhand von Ablaufverfolgungen, wie diese Anfrage während ihres gesamten Lebenszyklus von der Quelle zum Ziel fließt. Spuren werden durch „Spans“ dargestellt. Eine Ablaufverfolgung ist ein Baum von Spannen, und eine Spanne ist eine einzelne Operation innerhalb einer Ablaufverfolgung. Sie helfen Ihnen, Fehler, Latenzen oder Engpässe im System zu lokalisieren.
- Protokolle: Dies sind maschinengenerierte Ereignisse mit Zeitstempel, die Sie über die Vorgänge oder Änderungen im System informieren. Protokolle werden häufig verwendet, um diese Fehler oder Änderungen im System abzufragen.
- Metriken: Diese bieten quantitative Einblicke in CPU, Arbeitsspeicher, Festplattennutzung und die Leistung des Systems über einen bestimmten Zeitraum.
Diese Attribute erweitern das Monitoring-Framework um Rückverfolgbarkeit. Die Rückverfolgbarkeit bietet Ihnen die Linsen, um eine Anfrage zu verfolgen, die Ihr System anruft, wie lange es dauert, von einer Komponente zur anderen zu wechseln, welche anderen Dienste sie aufruft, ob sie Fehler auslöst, welche Protokolle sie erzeugt, welchen Zustand sie hat ist in, wann hat es begonnen und geendet, in welcher Zeitleiste ist es in Ihrem System geblieben usw. Wenn Sie diese Spuren sammeln, aggregieren und analysieren, können Sie wertvolle fundierte Entscheidungen treffen, wie z. B. die Kundenzeitleiste auf einer E-Commerce-Website , wie lange sie für die Suche nach einem Produkt gebraucht haben, wie lange sie das Produkt angesehen haben, hat die HTML-Seite alle Details wie Bilder oder eingebettete Videos geladen, wie lange hat das System für die Authentifizierung und Verarbeitung der Zahlung gebraucht usw.
Was erreichen wir mit Beobachtbarkeit in einer verteilten Umgebung?
Die Entwicklung verteilter Systeme begann, als Unternehmen begannen, sich von ihrer zentralisierten monolithischen Architektur zu einer verteilten und dezentralisierten Microservice-Architektur zu bewegen. Und dies ist noch ein Work-in-Progress, bei dem viele Organisationen die Microservice-Natur von Systemen und Anwendungen annehmen. Und all dies kann zugeschrieben werden große Datenmengen und Skalierung. Die Verwaltung einer verteilten Umgebung erfordert kontinuierliches Lernen, zusätzliches Personal, Änderungen an Frameworks und Richtlinien, IT-Management und so weiter. Es ist in der Tat eine große Veränderung.
Früher befanden sich in der begrenzten monolithischen Umgebung Hardware, Software, Daten und Datenbanken alle unter einem einzigen Dach. Mit dem Aufkommen von Big Data in den 2000er Jahren wurden Überwachungs- und Skalierungssysteme zu einem großen Problem. Häufig setzen Organisationen unterschiedliche Überwachungstools ein, um den Anforderungen ihrer verschiedenen Anwendungen gerecht zu werden. Infolgedessen wurde es bald zu einem Betriebsaufwand mit geringer Belastbarkeit, Sichtbarkeit und Zuverlässigkeit.
All diese Probleme führten zur Einführung der Beobachtbarkeit. Heutzutage gibt es mehrere Observability-Tools für Sicherheits-, Netzwerk-, Anwendungs- und Datenpipelines für die verteilte Ablaufverfolgung in einer komplexen Umgebung. Sie koexistieren mit ihrem Cousin, den Überwachungstools, und nutzen die Hebelwirkung, indem sie die Informationen von ihrem Cousin sammeln und mit zusätzlichen Informationen aus seinen eigenen Ablaufverfolgungsdaten aggregieren.
In all diesen Systemen gibt es viele bewegliche Komponenten, deren Spuren, wenn sie erfasst werden, die Geschichte der 5 Ws veranschaulichen können: wann, wo, warum, was und wie. Beispiel: Sie gehen um 1:43 Uhr auf die Website von DATAVERSITY, um einige Blogbeiträge zu lesen. Wenn Sie auf dataversity.net klicken, wird die HTTP-Anforderung im System protokolliert. Sie beginnen mit der Suche nach einem Blogbeitrag und gehen zu einem Data-Governance-Beitrag, wo Sie 17 Minuten damit verbringen, diesen Beitrag zu lesen, und dann schließen Sie Ihren Tab um 2:00 Uhr
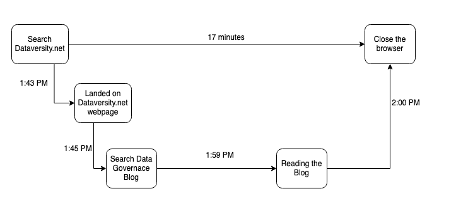
Es werden auch andere Aufrufe an das Netzwerksystem zum Erfassen von Netzwerkpaketen getätigt. Observability-Tools sammeln alle Spans und vereinheitlichen sie in einer Spur oder Spuren, sodass Sie den Pfad sehen können, den sie während ihres Lebenszyklus gebildet haben. Wenn Sie ein Problem wie Netzwerklatenz oder einen Systemdefekt haben, ist es jetzt einfacher, das Problem zu analysieren (die Zwiebel zu schälen) und zu debuggen (Fehler in welcher Schicht).
Wenn Ihre Anwendungen heute in einer großen verteilten Umgebung Millionen von Anfragen erhalten, wächst das Volumen der Ablaufverfolgungsdaten enorm an. Das Sammeln und Analysieren dieser Ablaufverfolgungen ist teuer für den Speicherverbrauch und die Datenübertragung. Um Kosten zu sparen, werden die Ablaufverfolgungsdaten abgetastet, da Ingenieurteams in den meisten Fällen nur einige der Teile benötigen, um zu untersuchen, was schief gelaufen ist oder was das Fehlermuster ist.
Mit diesem kleinen Beispiel verstehen wir, dass wir viel tiefere Einblicke in unsere Systeme erhalten. In Anbetracht einer größeren Anzahl von Systemen können Engineering-Teams die abgetasteten Daten erfassen und bearbeiten, um die aktuelle Struktur des Systems zu verbessern, neue Komponenten anzuwenden oder zurückzuziehen, eine weitere Sicherheitsebene hinzuzufügen, Engpässe zu beseitigen und so weiter.
Sollten Unternehmen sich für Observability entscheiden?
Wir alle sollten verstehen, dass die Endziele eine bessere Benutzererfahrung und eine größere Benutzerzufriedenheit sind. Und der Weg zum Erreichen dieser Ziele kann mit einem automatisierten und proaktiven Beobachtbarkeits-Framework erleichtert werden. Die Etablierung einer Kultur der kontinuierlichen Verbesserung und Optimierung gilt als optimaler Geschäfts- und Führungsansatz.
Im Zeitalter der digitalen Transformation ist Beobachtbarkeit zu einem Muss für ein Unternehmen geworden, um auf seiner digitalen Reise erfolgreich zu sein. Die Beobachtbarkeit liefert Ihnen aufschlussreiche Spuren und manövriert Sie auch dazu, dateninformiert und nicht nur datengesteuert zu sein.
Zusammenfassung
Obwohl wir die Begriffe Überwachung und Beobachtbarkeit synonym verwendet haben, haben wir gesehen, dass Überwachung Ihnen zwar hilft, Informationen über den Zustand des Systems und darauf stattfindende Ereignisse zu erhalten, Beobachtbarkeit es Ihnen jedoch erleichtert, Schlussfolgerungen auf der Grundlage von Beweisen zu ziehen, die aus tieferen Schichten eines Endes gesammelt wurden. Umgebung zu Ende.
Observability ist und kann auch als Bestandteil des Data-Governance-Frameworks wahrgenommen werden. In dieser Generation, in der sich das ständig wachsende Datenvolumen auf einem Netzwerk aus handelsüblicher Hardware befindet, ist es von entscheidender Bedeutung, die Architekturen so einfach wie möglich zu halten. Und offensichtlich wird es zu einer unmöglichen Aufgabe, die Umwelt auf der ganzen Linie zu verwalten. Daher ist die Implementierung geeigneter und automatisierter Governance-Richtlinien und -Regeln, um Ihr großes Netz von Systemen, Pipelines und Daten übersichtlich zu halten, früher als später erforderlich.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://www.dataversity.net/observability-traceability-for-distributed-systems/
- 1
- 11
- a
- Fähig
- Über uns
- Nach
- Erreichen
- Erreichen
- Action
- Zusätzliche
- Zusätzliche Angaben
- adoptieren
- angenommen
- Adoption
- Advent
- Alle
- erlaubt
- immer
- analysieren
- Analyse
- und
- Ein anderer
- beantworten
- Anwendung
- Anwendungen
- Jetzt bewerben
- Ansatz
- angemessen
- Architektur
- Attribute
- authentifizieren
- Automatisiert
- vermeiden
- basierend
- Grundsätzlich gilt
- weil
- werden
- wird
- begann
- BESTE
- Besser
- Big
- Big Data
- Blog
- Blog-Beiträge
- Engpässe
- Geschäft
- rufen Sie uns an!
- Aufrufe
- Erfassung
- Fälle
- zentralisierte
- Übernehmen
- Änderungen
- Auswählen
- Menu
- sammeln
- Das Sammeln
- Ware
- abschließen
- Komplex
- Komponente
- Komponenten
- konzept
- Hautpflegeprobleme
- verwirrt
- betrachtet
- Berücksichtigung
- Verbrauch
- Kontext
- kontinuierlich
- Smartgeräte App
- Kosten
- könnte
- CPU
- KULTUR
- Strom
- Kunde
- technische Daten
- datengesteuerte
- Datenbanken
- DATENVERSITÄT
- Täglich, von Tag zu Tag
- Tage
- Jahrzehnte
- dezentralisiert
- Entscheidungen
- tief
- tiefer
- definiert
- beschreiben
- Reiseziel
- Details
- DID
- anders
- digital
- Digitale Transformation
- verteilt
- verteilte Systeme
- Tut nicht
- nach unten
- im
- e-commerce
- einfacher
- eingebettet
- umarmen
- ermöglichen
- End-to-End
- Entwicklung
- Arbeitsumfeld
- Fehler
- Fehler
- Festlegung
- etc
- Sogar
- Veranstaltungen
- ÜBERHAUPT
- immer größer
- alles
- Beweis
- Evolution
- Beispiel
- teuer
- ERFAHRUNGEN
- extern
- erleichtert
- Fließt
- gebildet
- Unser Ansatz
- Gerüste
- für
- Generation
- bekommen
- Go
- Ziele
- Governance
- mehr
- Wächst
- passiert
- Los
- Hardware
- Gesundheit
- Hilfe
- hilft
- Geschichte
- Hit
- ein Geschenk
- HEISS
- Ultraschall
- Hilfe
- aber
- HTML
- HTTPS
- riesig
- Bilder
- Umsetzung
- wichtig
- unmöglich
- zu unterstützen,
- Verbesserung
- in
- Information
- informiert
- Einblicke
- intern
- untersuchen
- ruft auf
- Problem
- Probleme
- IT
- IT-Management
- Reise
- Behalten
- Wissen
- Landschaft
- grosse
- größer
- Latency
- Schicht
- Lagen
- Leadership
- lernen
- Objektive
- Hebelwirkung
- Lebenszyklus
- Limitiert
- Line
- leben
- Belastung
- Lang
- Los
- gemacht
- um
- MACHT
- Making
- verwalten
- Management
- flächendeckende Gesundheitsprogramme
- viele
- Markt
- mathematisch
- max-width
- messen
- Memory
- Metrik
- Microservices
- Millionen
- Minuten
- Überwachung
- Monolithisch
- vor allem warme
- schlauer bewegen
- ziehen um
- mehrere
- Haben müssen
- Natur
- notwendig,
- Need
- Bedürfnisse
- Netto-
- Netzwerk
- Netzwerk System
- Neu
- EINEM
- Betrieb
- Betriebs-
- Einkauf & Prozesse
- optimal
- Optimierung
- Organisationen
- Andere
- Gesamt-
- besitzen
- Papier
- Weg
- Schnittmuster
- Zahlung
- wahrgenommen
- Leistung
- Durchführung
- Zeit
- Stücke
- Plattform
- Plato
- Datenintelligenz von Plato
- PlatoData
- Play
- Politik durchzulesen
- Arm
- möglich
- Post
- BLOG-POSTS
- Proaktives Handeln
- Aufgabenstellung:
- Prozessdefinierung
- Produkt
- Fortschritt
- die
- bietet
- Bereitstellung
- veröffentlicht
- quantitativ
- Fragen
- lieber
- Lesen Sie mehr
- Lesebrillen
- erhalten
- erhält
- Zuverlässigkeit
- entfernen
- vertreten
- Anforderung
- Zugriffe
- erfordert
- Elastizität
- eingeschränkt
- Folge
- Rise
- roof
- Ohne eine erfahrene Medienplanung zur Festlegung von Regeln und Strategien beschleunigt der programmatische Medieneinkauf einfach die Rate der verschwenderischen Ausgaben.
- Zufriedenheit
- Speichern
- Skalieren
- Skalierung
- Suche
- Suche
- Zweite
- Sicherheitdienst
- Leistungen
- mehrere
- sollte
- Konzerte
- Einfacher
- Single
- langsam
- klein
- So
- Software
- LÖSEN
- einige
- Bald
- Klingen
- Quelle
- überspannt
- spezifisch
- verbringen
- Stapel
- Stufe
- Anfang
- begonnen
- Bundesstaat
- Staaten
- blieb
- Immer noch
- gestoppt
- storage
- Geschichte
- Struktur
- erfolgreich
- System
- Systeme und Techniken
- Nehmen
- nimmt
- Aufgabe
- Teams
- Technische
- AGB
- Das
- die Informationen
- Die Quelle
- ihr
- damit
- nach drei
- Durch
- während
- Zeit
- Timeline
- zu
- heute
- Werkzeuge
- Thema
- Spur
- Rückverfolgbarkeit
- Tracing
- Tracking
- privaten Transfer
- Transformation
- Regenschirm
- für
- zugrunde liegen,
- verstehen
- Aktualisierung
- Anwendungsbereich
- Mitglied
- Benutzererfahrung
- gewöhnlich
- wertvoll
- verschiedene
- Videos
- Sichtbarkeit
- lebenswichtig
- Volumen
- warten
- Warten
- Webseite
- Was
- Was ist
- welche
- während
- werden wir
- .
- Arbeiten
- Belegschaft
- Werk
- weltweit wie ausgehandelt und gekauft ausgeführt wird.
- würde
- Falsch
- Ihr
- Zephyrnet