Wie können Sie komplexere Dinge wie Emojis oder nicht-lateinische Zeichen darstellen, wenn Sie auf ASCII beschränkt sind? Eine Antwort ist Punycode, eine Möglichkeit, Unicode-Zeichen in ASCII darzustellen. Allerdings könnten Sie die Rohbits von Unicode technisch gesehen in Zeichen kodieren, z Base64, es gibt einen Haken. Das Domain Name System (DNS) verlangt im Allgemeinen, dass bei Hostnamen die Groß-/Kleinschreibung nicht beachtet werden muss. Egal, ob Sie also HACKADAY.com, HackADay.com oder nur hackaday.com eingeben, alles landet an der gleichen Stelle.
[A. Costello] an der University of California schlug Berkley die Idee von Punycode vor RFC 3492 im März 2003. Es beschreibt einen einfachen Algorithmus, bei dem alle regulären ASCII-Zeichen herausgezogen und auf einer Seite mit einem Trennzeichen dazwischen, in diesem Fall einem Bindestrich, festgehalten werden. Anschließend werden die Unicode-Zeichen codiert und am Ende der Zeichenfolge eingefügt.
Zunächst werden der numerische Codepunkt und die Position in der Zeichenfolge miteinander multipliziert. Dann wird die Nummer als a kodiert Basis-36 (a-z und 0-9) Ganzzahl variabler Länge. Zum Beispiel eine Begrüßung und das griechische Dankeschön: „Hey, ευχαριστώ“ wird "Hey, -mxahn5algcq2″. Ebenso die schöne Stadt München wird mnchen-3ya.
Wie Sie vielleicht im griechischen Beispiel bemerken, gibt es nichts, was dem Decoder helfen könnte, zu erkennen, welche Basis-36-Zeichen zu welchem ursprünglichen Unicode-Symbol gehören. Dank der Ganzzahlen variabler Länge ist jede signifikante Ziffer erkennbar, da es Schwellenwerte dafür gibt, welche Zahlen codiert werden können. Eine endliche Zustandsmaschine kommt zur Rettung. Der RFC stellt einige beispielhafte Pseudocodes bereit, die den Algorithmus beschreiben. Es ist ziemlich clever, eine Voreingenommenheit zu nutzen, die sich im Laufe der Dekodierung verändert. Da sie immer zunimmt, handelt es sich um eine monotone Funktion mit einigen cleveren Eigenschaften.
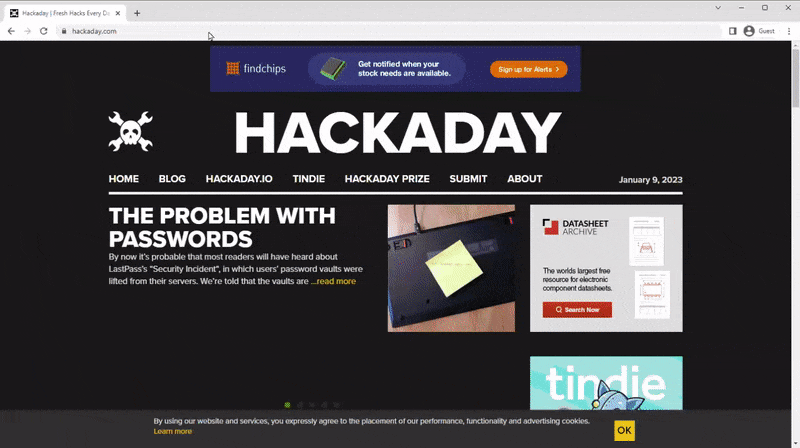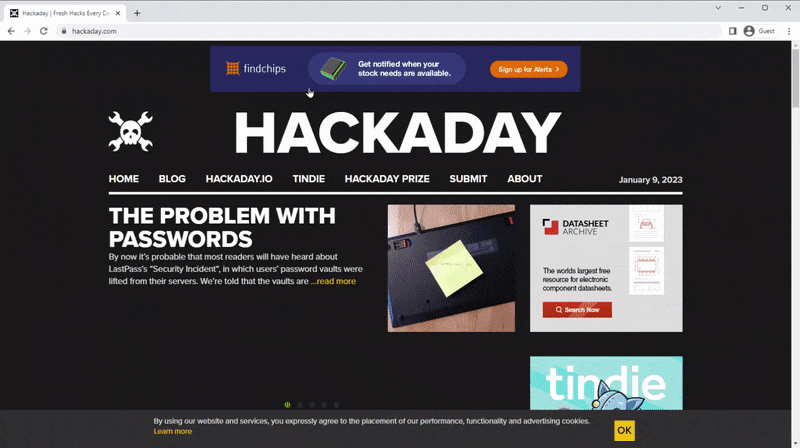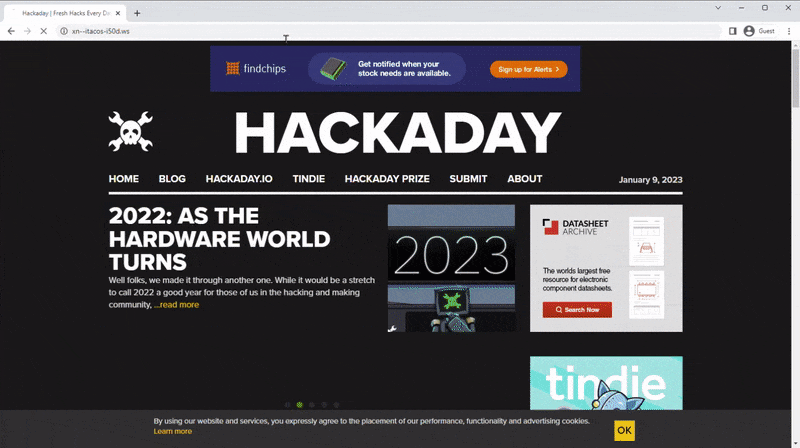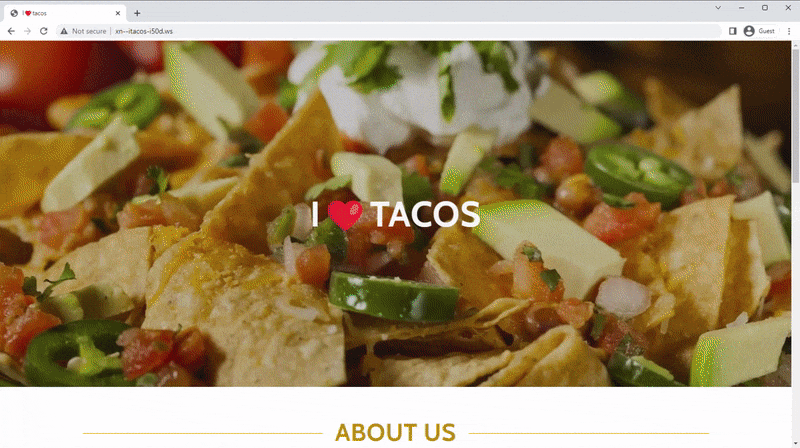
Um zu verhindern, dass normale URLs als Punycodes interpretiert werden, haben URLs natürlich ein spezielles kleines Präfix xn-- um dem Browser mitzuteilen, dass es sich um einen Code handelt. Dazu gehören alle Unicode-Zeichen, sodass auch Emojis gültig sind. Warum kannst du also nicht hingehen? xn--mnchen-3ya.de? Wenn Sie es in Ihren Browser eingeben oder auf den Link klicken, sehen Sie möglicherweise, wie Ihr Browser diese verwirrende Buchstabensuppe in eine schöne URL umwandelt (das tun nicht alle Browser). Das größte Problem ist Unicode selbst.
Während Unicode eine unglaubliche Unterstützung bietet, um die Hunderten von Sprachen, die täglich im Internet verwendet werden, möglich zu machen, und wir wagen zu sagen, sogar einigermaßen unkompliziert, gibt es einige Schwachstellen. Kyrillisch, Buchstaben mit der Breite Null und andere Unicode-Skurrilitäten ermöglichen denjenigen mit schändlicheren Absichten die Einrichtung einer Domain, die, wenn sie gerendert wird, wird als bekannte Website angezeigt. Die SSL-Zertifikate sind gültig und alles andere wird geprüft. Kyrillisch umfasst Zeichen, die optisch mit ihren lateinischen Gegenstücken identisch sind, aber anders dargestellt werden. Die Chancen für Hacker und Phishing-Versuche sind zu groß und Punycodes sind auf den meisten Domains bisher nicht erlaubt.
Können Sie beispielsweise den Unterschied zwischen diesen beiden Domänen erkennen?
Einige Browser rendern den Hover-Text als Punycode, andere behalten ihn als UTF-8-Äquivalent bei. Das „a“ (U+0061) wurde durch das kyrillische „a“ (U+0430) ersetzt, das die meisten Computer mit genau demselben Zeichen wiedergeben.
Hier ist eine IDN-Homograph-Angriff, wo sie sich darauf verlassen, dass ein Benutzer auf einen Link klickt, zwischen dem er keinen Unterschied erkennen kann. Im Jahr 2001 veröffentlichten zwei Sicherheitsforscher einen Artikel zu diesem Thema, in dem sie „microsoft.com“ mit kyrillischen Zeichen als Proof of Concept registrierten. Als Reaktion darauf wurde Top-Level-Domains empfohlen, nur Unicode-Zeichen zu akzeptieren, die lateinische Zeichen und Zeichen aus den in diesem Land verwendeten Sprachen enthalten. Aus diesem Grund akzeptieren viele der gängigen Top-Level-Domains mit Sitz in den USA überhaupt keine Unicode-Domainnamen. Zumindest die nicht anzeigbaren Zeichen werden von der ICANN speziell mit einem Band versehen, was eine große Menge an Würmern vermeidet, aber optisch identische, aber bitweise unterschiedliche Zeichen da draußen zu haben, führt jedoch zu Verwirrung.
Es werden jedoch langsam Maßnahmen zur Eindämmung dieser Art von Angriffen eingeführt. Als erste Schutzebene zeigen Firefox- und Chromium-basierte Browser die Nicht-Punycode-Version nur dann an, wenn alle Zeichen aus derselben Sprache stammen. Einige Browser konvertieren alle Unicode-URLs in Punycode. Andere Techniken nutzen die optische Zeichenerkennung (OCR), um festzustellen, ob eine URL anders interpretiert werden kann. Außerhalb des Browsers verfügen Links, die per SMS oder E-Mail gesendet werden, möglicherweise nicht über die gleiche Intelligenz, und Sie werden es erst erfahren, wenn Sie sie in Ihrem Browser geöffnet haben. Und dann ist es zu spät.
Abgesehen von den Herausforderungen: Werden Punycodes ihre Zeit in der Sonne haben? Wird Hackaday jemals ☠️📅.com bekommen? Wer weiß. Aber in der Zwischenzeit können wir uns über eine clevere Lösung freuen, die 2003 für das heikle Problem der Internationalisierung von Domainnamen vorgeschlagen wurde, das wir immer noch nicht ganz gelöst haben.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://hackaday.com/2023/01/18/punycodes-explained/
- 2001
- a
- Akzeptieren
- Algorithmus
- Alle
- immer
- und
- beantworten
- um
- Anschläge
- Versuche
- schön
- wird
- Sein
- zwischen
- vorspannen
- Größte
- Browser
- Browsern
- Kalifornien
- Häuser
- Zertifikate
- Charakter
- Zeichenerkennung
- Zeichen
- Schecks
- Stadt
- Code
- COM
- gemeinsam
- Komplex
- Computer
- konzept
- verwirrend
- Verwirrung
- verkaufen
- könnte
- Land
- Kurs
- Tag
- Decoding
- Bestimmen
- Unterschied
- anders
- Stelle
- dns
- Domain
- Domain Name
- DOMAIN NAMEN
- Domains
- Nicht
- jeder
- E-Mails
- genießen
- Äquivalent
- Sogar
- ÜBERHAUPT
- jeden Tag
- alles
- Beispiel
- erklärt
- Firefox
- Vorname
- für
- Funktion
- allgemein
- bekommen
- gif
- gibt
- Go
- Goes
- groß
- Gruß
- Hacker
- mit
- Hilfe
- schweben
- Ultraschall
- aber
- HTTPS
- hunderte
- Idee
- identisch
- in
- Dazu gehören
- zunehmend
- unglaublich
- Absichten
- IT
- selbst
- Behalten
- Wissen
- Sprache
- Sprachen
- grosse
- Spät
- Lateinisch
- Schicht
- umwandeln
- Brief
- LINK
- Links
- wenig
- aussehen
- Maschine
- Making
- viele
- März
- inzwischen
- Nachricht
- könnte
- mehr
- vor allem warme
- multipliziert
- Name
- Namen
- Anzahl
- Zahlen
- OCR
- Merkwürdigkeiten
- Angebote
- EINEM
- geöffnet
- Entwicklungsmöglichkeiten
- optische Zeichenerkennung
- Original
- Andere
- Umrissen
- aussen
- Papier
- Phishing
- Ort
- Plato
- Datenintelligenz von Plato
- PlatoData
- Position
- möglich
- ziemlich
- verhindern
- Aufgabenstellung:
- Beweis
- Proof of Concept
- immobilien
- vorgeschlage
- Sicherheit
- veröffentlicht
- Roh
- Anerkennung
- empfohlen
- Registrieren
- regulär
- ersetzt
- vertreten
- vertreten
- erfordert
- retten
- Forscher
- Antwort
- eingeschränkt
- Folge
- Gerollt
- Rollen
- gleich
- Sicherheitdienst
- Sicherheitsforscher
- kompensieren
- erklären
- signifikant
- Ähnlich
- Einfacher
- Langsam
- So
- bis jetzt
- Lösung
- einige
- etwas
- besondere
- speziell
- SSL
- Immer noch
- einfach
- Fach
- Sun
- Support
- Symbol
- System
- Techniken
- Das
- ihr
- Zeit
- zu
- gemeinsam
- auch
- Top-Level
- Transformieren
- Typen
- Unicode
- Universität
- University of California
- URL
- -
- Mitglied
- Verwendung
- Version
- Netz
- bekannt
- Was
- ob
- welche
- während
- WHO
- Wikipedia
- werden wir
- Würmern
- Ihr
- Zephyrnet