Apache Eisberg ist ein offenes Tabellenformat für sehr große analytische Datasets, das Metadateninformationen über den Zustand von Datasets erfasst, während sie sich entwickeln und im Laufe der Zeit ändern. Es fügt Tabellen zu Compute-Engines wie Spark, Trino, PrestoDB, Flink und Hive hinzu, indem es ein Hochleistungstabellenformat verwendet, das genau wie eine SQL-Tabelle funktioniert. Iceberg ist für seine Unterstützung von ACID-Transaktionen in Data Lakes und Funktionen wie Schema- und Partitionsentwicklung, Zeitreisen und Rollback sehr beliebt geworden.
Die Apache Iceberg-Integration wird von AWS-Analysediensten unterstützt, einschließlich Amazon EMR, Amazonas Athena und AWS-Kleber. Amazon EMR kann Cluster mit Spark, Hive, Trino und Flink bereitstellen, die Iceberg ausführen können. Ab Amazon EMR Version 6.5.0 ist dies möglich Verwenden Sie Iceberg mit Ihrem EMR-Cluster ohne dass eine Bootstrap-Aktion erforderlich ist. Anfang 2022 kündigte AWS die allgemeine Verfügbarkeit von Athena ACID-Transaktionen an, die von Apache Iceberg betrieben werden. Die kürzlich veröffentlichte Athena-Abfragemodul Version 3 bietet eine bessere Integration mit dem Iceberg-Tabellenformat. AWS Glue 3.0 und höher unterstützt das Apache Iceberg-Framework für Data Lakes.
In diesem Beitrag erörtern wir, was Kunden von modernen Data Lakes erwarten und wie Apache Iceberg dabei hilft, Kundenanforderungen zu erfüllen. Dann gehen wir durch eine Lösung, um einen leistungsstarken und sich entwickelnden Iceberg Data Lake aufzubauen Amazon Simple Storage-Service (Amazon S3) und verarbeiten Sie inkrementelle Daten, indem Sie SQL-Anweisungen zum Einfügen, Aktualisieren und Löschen ausführen. Abschließend zeigen wir Ihnen, wie Sie die Leistung des Prozesses optimieren, um die Lese- und Schreibleistung zu verbessern.
Wie Apache Iceberg die Wünsche der Kunden in modernen Data Lakes erfüllt
Immer mehr Kunden erstellen Data Lakes mit strukturierten und unstrukturierten Daten, um viele Benutzer, Anwendungen und Analysetools zu unterstützen. Es besteht ein erhöhter Bedarf an Data Lakes, um datenbankähnliche Funktionen wie ACID-Transaktionen, Aktualisierungen und Löschungen auf Datensatzebene, Zeitreisen und Rollback zu unterstützen. Apache Iceberg wurde entwickelt, um diese Funktionen auf kostengünstigen Data Lakes im Petabyte-Bereich auf Amazon S3 zu unterstützen.
Apache Iceberg geht auf Kundenbedürfnisse ein, indem es zum Zeitpunkt der Erstellung der einzelnen Datendateien umfangreiche Metadateninformationen über den Datensatz erfasst. Die Architektur einer Iceberg-Tabelle besteht aus drei Ebenen: dem Iceberg-Katalog, der Metadatenebene und der Datenebene, wie in der folgenden Abbildung dargestellt (Quelle).

Der Iceberg-Katalog speichert den Metadatenzeiger auf die aktuelle Tabellenmetadatendatei. Wenn eine Auswahlabfrage eine Iceberg-Tabelle liest, geht die Abfrage-Engine zuerst zum Iceberg-Katalog und ruft dann den Speicherort der aktuellen Metadatendatei ab. Bei jeder Aktualisierung der Iceberg-Tabelle wird ein neuer Snapshot der Tabelle erstellt, und der Metadatenzeiger zeigt auf die aktuelle Tabellenmetadatendatei.
Das Folgende ist ein Beispiel für einen Iceberg-Katalog mit AWS Glue-Implementierung. Sie können den Datenbanknamen, den Speicherort (S3-Pfad) der Iceberg-Tabelle und den Speicherort der Metadaten sehen.

Die Metadatenebene hat drei Arten von Dateien: die Metadatendatei, die Manifestliste und die Manifestdatei in einer Hierarchie. Ganz oben in der Hierarchie befindet sich die Metadatendatei, die Informationen über das Schema der Tabelle, Partitionsinformationen und Snapshots speichert. Der Snapshot verweist auf die Manifestliste. Die Manifestliste enthält die Informationen zu jeder Manifestdatei, aus der der Snapshot besteht, z. B. den Speicherort der Manifestdatei, die Partitionen, zu denen sie gehört, und die Unter- und Obergrenzen für Partitionsspalten für die Datendateien, die sie verfolgt. Die Manifestdatei verfolgt Datendateien sowie zusätzliche Details zu jeder Datei, z. B. das Dateiformat. Alle drei Dateien arbeiten in einer Hierarchie, um die Snapshots, das Schema, die Partitionierung, die Eigenschaften und die Datendateien in einer Iceberg-Tabelle zu verfolgen.
Die Datenschicht enthält die einzelnen Datendateien der Iceberg-Tabelle. Iceberg unterstützt eine Vielzahl von Dateiformaten, darunter Parquet, ORC und Avro. Da die Iceberg-Tabelle die einzelnen Datendateien nachverfolgt, anstatt nur auf den Partitionsspeicherort mit Datendateien zu verweisen, isoliert sie die Schreibvorgänge von den Lesevorgängen. Sie können die Datendateien jederzeit schreiben, aber nur die Änderung explizit festschreiben, wodurch eine neue Version der Snapshot- und Metadatendateien erstellt wird.
Lösungsüberblick
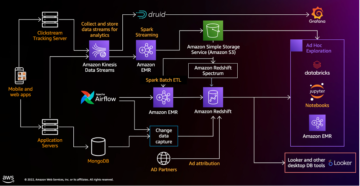
In diesem Beitrag führen wir Sie durch eine Lösung zum Erstellen eines leistungsstarken Apache Iceberg Data Lake auf Amazon S3; Verarbeitung inkrementeller Daten mit SQL-Anweisungen zum Einfügen, Aktualisieren und Löschen; und optimieren Sie die Iceberg-Tabelle, um die Lese- und Schreibleistung zu verbessern. Das folgende Diagramm veranschaulicht die Lösungsarchitektur.

Um diese Lösung zu demonstrieren, verwenden wir die Amazon Kundenrezensionen Datensatz in einem S3-Bucket (s3://amazon-reviews-pds/parquet/). Im realen Anwendungsfall wären dies Rohdaten, die in Ihrem S3-Bucket gespeichert sind. Wir können die Datengröße mit dem folgenden Code in der überprüfen AWS-Befehlszeilenschnittstelle (AWS-CLI):
Die Gesamtzahl der Objekte beträgt 430 und die Gesamtgröße 47.4 GiB.
Um diese Lösung einzurichten und zu testen, führen wir die folgenden allgemeinen Schritte aus:
- Richten Sie einen S3-Bucket in der kuratierten Zone ein, um konvertierte Daten im Iceberg-Tabellenformat zu speichern.
- Starten Sie einen EMR-Cluster mit geeigneten Konfigurationen für Apache Iceberg.
- Erstellen Sie ein Notizbuch in EMR Studio.
- Konfigurieren Sie die Spark-Sitzung für Apache Iceberg.
- Konvertieren Sie Daten in das Iceberg-Tabellenformat und verschieben Sie Daten in die kuratierte Zone.
- Führen Sie Abfragen zum Einfügen, Aktualisieren und Löschen in Athena aus, um inkrementelle Daten zu verarbeiten.
- Leistungsoptimierung durchführen.
Voraussetzungen:
Um dieser exemplarischen Vorgehensweise folgen zu können, müssen Sie über eine verfügen AWS-Konto sowie einem AWS Identity and Access Management and (IAM)-Rolle, die über ausreichenden Zugriff zum Bereitstellen der erforderlichen Ressourcen verfügt.
Richten Sie den S3-Bucket für Iceberg-Daten in der kuratierten Zone in Ihrem Data Lake ein
Wählen Sie die Region aus, in der Sie den S3-Bucket erstellen möchten, und geben Sie einen eindeutigen Namen an:
Starten Sie einen EMR-Cluster, um Iceberg-Jobs mit Spark auszuführen
Sie können einen EMR-Cluster aus der erstellen AWS-Managementkonsole, Amazon EMR-CLI oder AWS Cloud-Entwicklungskit (AWS-CDK). In diesem Beitrag führen wir Sie durch die Erstellung eines EMR-Clusters über die Konsole.
- Wählen Sie auf der Amazon EMR-Konsole Cluster erstellen.
- Auswählen Erweiterte Optionen.
- Aussichten für Software-Konfiguration, wählen Sie die neueste Amazon EMR-Version aus. Ab Januar 2023 ist die neueste Version 6.9.0. Iceberg erfordert Version 6.5.0 und höher.
- Auswählen JupyterEnterpriseGateway und Spark als zu installierende Software.
- Aussichten für Softwareeinstellungen bearbeitenWählen Konfiguration eingeben und gib ein
[{"classification":"iceberg-defaults","properties":{"iceberg.enabled":true}}]. - Belassen Sie andere Einstellungen auf ihren Standardeinstellungen und wählen Sie aus Weiter.

- Aussichten für Hardware, verwenden Sie die Standardeinstellung.
- Auswählen Weiter.
- Aussichten für Clustername, Geben Sie einen Namen ein. Wir gebrauchen
iceberg-blog-cluster. - Lassen Sie die restlichen Einstellungen unverändert und wählen Sie Weiter.
- Auswählen Cluster erstellen.
Erstellen Sie ein Notizbuch in EMR Studio
Wir führen Sie nun durch die Erstellung eines Notizbuchs in EMR Studio über die Konsole.
- Auf der IAM-Konsole Erstellen Sie eine EMR Studio-Servicerolle.
- Wählen Sie auf der Amazon EMR-Konsole EMR-Studio.
- Auswählen Los geht´s.
Das Los geht´s Seite erscheint in einem neuen Tab.
- Auswählen Studio erstellen in der neuen Registerkarte.
- Geben Sie einen Namen ein. Wir verwenden iceberg-studio.
- Wählen Sie dieselbe VPC und dasselbe Subnetz wie für den EMR-Cluster und die Standardsicherheitsgruppe.
- Auswählen AWS Identitäts- und Zugriffsverwaltung (IAM) für die Authentifizierung und wählen Sie die soeben erstellte EMR Studio-Servicerolle aus.
- Wählen Sie einen S3-Pfad für Sicherung von Arbeitsbereichen.
- Auswählen Studio erstellen.
- Nachdem das Studio erstellt wurde, wählen Sie die Studio-Zugriffs-URL aus.
- Wählen Sie im EMR Studio-Dashboard aus Arbeitsbereich erstellen.
- Geben Sie einen Namen für Ihren Arbeitsbereich ein. Wir gebrauchen
iceberg-workspace. - Erweitern Sie die Funktionalität der Erweiterte Konfiguration und wählen Sie Verbinden Sie Workspace mit einem EMR-Cluster.
- Wählen Sie den zuvor erstellten EMR-Cluster aus.
- Auswählen Erstellen Sie Arbeitsbereich.
- Wählen Sie den Arbeitsbereichsnamen aus, um eine neue Registerkarte zu öffnen.
Im Navigationsbereich befindet sich ein Notizbuch mit demselben Namen wie der Arbeitsbereich. In unserem Fall ist es ein Iceberg-Workspace.
- Öffnen Sie das Notizbuch.
- Wenn Sie aufgefordert werden, einen Kernel auszuwählen, wählen Sie Spark.
Konfigurieren Sie eine Spark-Sitzung für Apache Iceberg
Verwenden Sie den folgenden Code und geben Sie Ihren eigenen S3-Bucket-Namen an:
Dadurch werden die folgenden Spark-Sitzungskonfigurationen festgelegt:
- spark.sql.catalog.demo – Registriert einen Spark-Katalog namens demo, der das Iceberg Spark-Katalog-Plugin verwendet.
- spark.sql.catalog.demo.catalog-impl – Der Demo-Spark-Katalog verwendet AWS Glue als physischen Katalog zum Speichern von Iceberg-Datenbank- und Tabelleninformationen.
- spark.sql.catalog.demo.warehouse – Der Demo-Spark-Katalog speichert alle Iceberg-Metadaten und Datendateien unter dem durch diese Eigenschaft definierten Stammpfad:
s3://iceberg-curated-blog-data. - spark.sql.extensions – Fügt Unterstützung für Iceberg Spark-SQL-Erweiterungen hinzu, mit denen Sie Iceberg Spark-Prozeduren und einige nur für Iceberg verfügbare SQL-Befehle ausführen können (diese verwenden Sie in einem späteren Schritt).
- spark.sql.catalog.demo.io-impl – Iceberg ermöglicht es Benutzern, Daten über S3FileIO in Amazon S3 zu schreiben. Der AWS Glue-Datenkatalog verwendet standardmäßig dieses FileIO, und andere Kataloge können dieses FileIO mithilfe der io-impl-Katalogeigenschaft laden.
Konvertieren Sie Daten in das Iceberg-Tabellenformat
Sie können entweder Spark auf Amazon EMR oder Athena verwenden, um die Iceberg-Tabelle zu laden. Führen Sie in der Spark-Sitzung des EMR Studio Workspace-Notebooks die folgenden Befehle aus, um die Daten zu laden:
Nachdem Sie den Code ausgeführt haben, sollten Sie zwei Präfixe finden, die in Ihrem Data Warehouse S3-Pfad erstellt wurden (s3://iceberg-curated-blog-data/reviews.db/all_reviews): Daten und Metadaten.
Verarbeiten Sie inkrementelle Daten mit SQL-Anweisungen zum Einfügen, Aktualisieren und Löschen in Athena
Athena ist eine serverlose Abfrage-Engine, mit der Sie Lese-, Schreib-, Aktualisierungs- und Optimierungsaufgaben für Iceberg-Tabellen ausführen können. Um zu demonstrieren, wie das Data Lake-Format von Apache Iceberg die inkrementelle Datenaufnahme unterstützt, führen wir SQL-Anweisungen zum Einfügen, Aktualisieren und Löschen im Data Lake aus.
Navigieren Sie zur Athena-Konsole und wählen Sie aus Abfrage-Editor. Wenn Sie den Athena-Abfrageeditor zum ersten Mal verwenden, müssen Sie dies tun Konfigurieren Sie den Speicherort des Abfrageergebnisses um der S3-Bucket zu sein, den Sie zuvor erstellt haben. Sie sollten sehen können, dass die Tabelle reviews.all_reviews für Abfragen verfügbar ist. Führen Sie die folgende Abfrage aus, um zu überprüfen, ob Sie die Iceberg-Tabelle erfolgreich geladen haben:
Verarbeiten Sie inkrementelle Daten, indem Sie SQL-Anweisungen zum Einfügen, Aktualisieren und Löschen ausführen:
Leistungsoptimierung
In diesem Abschnitt gehen wir verschiedene Möglichkeiten zur Verbesserung der Lese- und Schreibleistung von Apache Iceberg durch.
Konfigurieren Sie die Apache Iceberg-Tabelleneigenschaften
Apache Iceberg ist ein Tabellenformat und unterstützt Tabelleneigenschaften, um Tabellenverhalten wie Lesen, Schreiben und Katalogisieren zu konfigurieren. Sie können die Lese- und Schreibleistung auf Iceberg-Tabellen verbessern, indem Sie die Tabelleneigenschaften anpassen.
Wenn Sie beispielsweise feststellen, dass Sie zu viele kleine Dateien für eine Iceberg-Tabelle schreiben, können Sie die Schreibdateigröße so konfigurieren, dass weniger, aber größere Dateien geschrieben werden, um die Abfrageleistung zu verbessern.
| Immobilien | Standard | Beschreibung |
| write.target-file-size-bytes | 536870912 (512 MB) | Steuert die Größe der Dateien, die generiert werden, um etwa so viele Bytes zu erreichen |
Verwenden Sie den folgenden Code, um das Tabellenformat zu ändern:
Partitionieren und Sortieren
Damit eine Abfrage schnell ausgeführt wird, gilt: Je weniger Daten gelesen werden, desto besser. Iceberg nutzt die umfangreichen Metadaten, die es zum Zeitpunkt des Schreibens erfasst, und erleichtert Techniken wie Scan-Planung, Partitionierung, Bereinigung und Statistiken auf Spaltenebene wie Min/Max-Werte, um Datendateien zu überspringen, die keine Übereinstimmungsdatensätze haben. Wir erklären Ihnen, wie die Planung und Partitionierung von Abfragescans in Iceberg funktionieren und wie wir sie verwenden, um die Abfrageleistung zu verbessern.
Scan-Planung abfragen
Für eine bestimmte Abfrage ist der erste Schritt in einer Abfrage-Engine die Scan-Planung, d. h. der Prozess, um die Dateien in einer Tabelle zu finden, die für eine Abfrage benötigt werden. Die Planung in einer Iceberg-Tabelle ist sehr effizient, da die umfangreichen Metadaten von Iceberg verwendet werden können, um Metadatendateien zu bereinigen, die nicht benötigt werden, zusätzlich zum Filtern von Datendateien, die keine übereinstimmenden Daten enthalten. In unseren Tests haben wir beobachtet, dass Athena vor der Konvertierung in das Iceberg-Format 50 % oder weniger Daten für eine bestimmte Abfrage in einer Iceberg-Tabelle im Vergleich zu den Originaldaten gescannt hat.
Es gibt zwei Arten der Filterung:
- Metadatenfilterung – Iceberg verwendet zwei Ebenen von Metadaten, um die Dateien in einem Snapshot zu verfolgen: die Manifestliste und Manifestdateien. Es verwendet zunächst die Manifestliste, die als Index der Manifestdateien dient. Während der Planung filtert Iceberg Manifeste anhand des Wertebereichs der Partition in der Manifestliste, ohne alle Manifestdateien zu lesen. Dann werden ausgewählte Manifestdateien verwendet, um Datendateien abzurufen.
- Datenfilterung – Nach Auswahl der Liste der Manifestdateien verwendet Iceberg die Partitionsdaten und Statistiken auf Spaltenebene für jede in Manifestdateien gespeicherte Datendatei, um Datendateien zu filtern. Während der Planung werden Abfrageprädikate in Prädikate für die Partitionsdaten konvertiert und zuerst zum Filtern von Datendateien angewendet. Anschließend werden die Spaltenstatistiken wie Anzahl der Werte auf Spaltenebene, Nullanzahl, Untergrenzen und Obergrenzen verwendet, um Datendateien herauszufiltern, die nicht mit dem Abfrageprädikat übereinstimmen können. Durch die Verwendung von Ober- und Untergrenzen zum Filtern von Datendateien zur Planungszeit verbessert Iceberg die Abfrageleistung erheblich.
Partitionieren und Sortieren
Die Partitionierung ist eine Möglichkeit, Datensätze mit denselben Schlüsselspaltenwerten schriftlich zusammenzufassen. Der Vorteil der Partitionierung sind schnellere Abfragen, die nur auf einen Teil der Daten zugreifen, wie weiter oben in Planung von Abfrage-Scans erläutert: Datenfilterung. Iceberg macht die Partitionierung einfach, indem es versteckte Partitionierung unterstützt, so wie Iceberg Partitionswerte erzeugt, indem es einen Spaltenwert nimmt und ihn optional umwandelt.
In unserem Anwendungsfall führen wir zunächst die folgende Abfrage für die nicht partitionierte Iceberg-Tabelle aus. Dann partitionieren wir die Iceberg-Tabelle nach der Kategorie der Bewertungen, die in der Abfrage-WHERE-Bedingung verwendet werden, um Datensätze herauszufiltern. Mit der Partitionierung könnte die Abfrage viel weniger Daten scannen. Siehe folgenden Code:
Führen Sie die folgende select-Anweisung für die nicht partitionierte all_reviews-Tabelle im Vergleich zur partitionierten Tabelle aus, um den Leistungsunterschied zu sehen:
Die folgende Tabelle zeigt die Leistungsverbesserung der Datenpartitionierung mit etwa 50 % Leistungsverbesserung und 70 % weniger gescannten Daten.
| Datensatzname | Nicht partitionierter Datensatz | Partitionierter Datensatz |
| Laufzeit (Sekunden) | 8.20 | 4.25 |
| Gescannte Daten (MB) | 131.55 | 33.79 |
Beachten Sie, dass die Laufzeit die durchschnittliche Laufzeit mit mehreren Durchläufen in unserem Test ist.
Wir haben nach der Partitionierung eine gute Leistungsverbesserung festgestellt. Dies kann jedoch weiter verbessert werden, indem Statistiken auf Spaltenebene aus Iceberg-Manifestdateien verwendet werden. Um die Statistiken auf Spaltenebene effektiv zu nutzen, möchten Sie Ihre Datensätze basierend auf den Abfragemustern weiter sortieren. Durch das Sortieren des gesamten Datensatzes mithilfe der Spalten, die häufig in Abfragen verwendet werden, werden die Daten so neu angeordnet, dass jede Datendatei einen eindeutigen Wertebereich für die spezifischen Spalten enthält. Wenn diese Spalten in der Abfragebedingung verwendet werden, können Abfragemodule Datendateien weiter überspringen, wodurch noch schnellere Abfragen ermöglicht werden.
Copy-on-Write vs. Read-on-Merge
Beim Implementieren von Update und Delete für Iceberg-Tabellen im Data Lake gibt es zwei Ansätze, die durch die Iceberg-Tabelleneigenschaften definiert werden:
- Copy-on-Write – Bei diesem Ansatz werden bei Änderungen an der Iceberg-Tabelle, entweder Aktualisierungen oder Löschungen, die mit den betroffenen Datensätzen verknüpften Datendateien dupliziert und aktualisiert. Die Datensätze werden entweder aktualisiert oder aus den duplizierten Datendateien gelöscht. Es wird ein neuer Snapshot der Iceberg-Tabelle erstellt, der auf die neuere Version der Datendateien verweist. Dadurch werden die Schreibvorgänge insgesamt langsamer. Es kann Situationen geben, in denen gleichzeitige Schreibvorgänge mit Konflikten erforderlich sind, sodass ein erneuter Versuch erfolgen muss, was die Schreibzeit noch weiter verlängert. Andererseits ist beim Lesen der Daten kein zusätzlicher Prozess erforderlich. Die Abfrage ruft Daten aus der neuesten Version der Datendateien ab.
- Beim Lesen zusammenführen – Bei diesem Ansatz werden bei Aktualisierungen oder Löschungen in der Iceberg-Tabelle die vorhandenen Datendateien nicht neu geschrieben; stattdessen werden neue Löschdateien erstellt, um die Änderungen nachzuverfolgen. Für Löschungen wird eine neue Löschdatei mit den gelöschten Datensätzen erstellt. Beim Lesen der Iceberg-Tabelle wird die Löschdatei auf die abgerufenen Daten angewendet, um die Löschdatensätze herauszufiltern. Bei Aktualisierungen wird eine neue Löschdatei erstellt, um die aktualisierten Datensätze als gelöscht zu markieren. Dann wird eine neue Datei für diese Datensätze erstellt, jedoch mit aktualisierten Werten. Beim Lesen der Iceberg-Tabelle werden sowohl die gelöschten als auch die neuen Dateien auf die abgerufenen Daten angewendet, um die letzten Änderungen widerzuspiegeln und die richtigen Ergebnisse zu liefern. Daher wird für alle nachfolgenden Abfragen ein zusätzlicher Schritt zum Zusammenführen der Datendateien mit den gelöschten und neuen Dateien ausgeführt, was normalerweise die Abfragezeit verlängert. Andererseits können die Schreibvorgänge schneller sein, da die vorhandenen Datendateien nicht neu geschrieben werden müssen.
Um die Auswirkungen der beiden Ansätze zu testen, können Sie den folgenden Code ausführen, um die Iceberg-Tabelleneigenschaften festzulegen:
Führen Sie die SQL-Anweisungen update, delete und select in Athena aus, um den Laufzeitunterschied für Copy-on-Write vs. Merge-on-Read anzuzeigen:
Die folgende Tabelle fasst die Abfragelaufzeiten zusammen.
| Abfrage | Copy-on-Write | Beim Lesen zusammenführen | ||||
| AKTUALISIEREN | LÖSCHEN | SELECT | AKTUALISIEREN | LÖSCHEN | SELECT | |
| Laufzeit (Sekunden) | 66.251 | 116.174 | 97.75 | 10.788 | 54.941 | 113.44 |
| Gescannte Daten (MB) | 494.06 | 3.07 | 137.16 | 494.06 | 3.07 | 137.16 |
Beachten Sie, dass die Laufzeit die durchschnittliche Laufzeit mit mehreren Durchläufen in unserem Test ist.
Wie unsere Testergebnisse zeigen, gibt es bei beiden Ansätzen immer Kompromisse. Welcher Ansatz zu verwenden ist, hängt von Ihren Anwendungsfällen ab. Zusammenfassend reduzieren sich die Überlegungen auf die Latenz beim Lesen gegenüber dem Schreiben. Sie können sich auf die folgende Tabelle beziehen und die richtige Wahl treffen.
| . | Copy-on-Write | Beim Lesen zusammenführen |
| Vorteile | Schnelleres Lesen | Schreibt schneller |
| Nachteile | Teure schreibt | Höhere Latenz beim Lesen |
| Wann zu verwenden | Gut für häufiges Lesen, seltene Aktualisierungen und Löschungen oder große Stapelaktualisierungen | Gut für Tabellen mit häufigen Aktualisierungen und Löschungen |
Datenkomprimierung
Wenn Ihre Datendatei klein ist, können Sie am Ende Tausende oder Millionen von Dateien in einer Iceberg-Tabelle haben. Dadurch wird der E/A-Vorgang drastisch erhöht und die Abfragen verlangsamt. Darüber hinaus verfolgt Iceberg jede Datendatei in einem Datensatz. Mehr Datendateien führen zu mehr Metadaten. Dies erhöht wiederum den Overhead und die E/A-Operation beim Lesen von Metadatendateien. Um die Abfrageleistung zu verbessern, wird empfohlen, kleine Datendateien in größere Datendateien zu komprimieren.
Wenn Sie beim Aktualisieren und Löschen von Datensätzen in der Iceberg-Tabelle den Read-on-Merge-Ansatz verwenden, erhalten Sie möglicherweise viele kleine Löschungen oder neue Datendateien. Beim Ausführen der Komprimierung werden alle diese Dateien kombiniert und eine neuere Version der Datendatei erstellt. Dadurch entfällt die Notwendigkeit, sie während des Lesens abzugleichen. Es wird empfohlen, regelmäßige Komprimierungsjobs durchzuführen, um Lesevorgänge so wenig wie möglich zu beeinträchtigen und gleichzeitig eine höhere Schreibgeschwindigkeit beizubehalten.
Führen Sie den folgenden Datenkomprimierungsbefehl aus, und führen Sie dann die Auswahlabfrage von Athena aus:
Die folgende Tabelle vergleicht die Laufzeit vor und nach der Datenkomprimierung. Sie können eine Leistungssteigerung von etwa 40 % feststellen.
| Abfrage | Vor der Datenkomprimierung | Nach der Datenkomprimierung |
| Laufzeit (Sekunden) | 97.75 | 32.676 Sekunden |
| Gescannte Daten (MB) | 137.16 M | 189.19 M |
Beachten Sie, dass die ausgewählten Abfragen auf dem ausgeführt wurden all_reviews Tabelle nach Aktualisierungs- und Löschvorgängen, vor und nach der Datenkomprimierung. Die Laufzeit ist die durchschnittliche Laufzeit bei mehreren Durchläufen in unserem Test.
Aufräumen
Nachdem Sie die exemplarische Vorgehensweise für die Lösung befolgt haben, um die Anwendungsfälle durchzuführen, führen Sie die folgenden Schritte aus, um Ihre Ressourcen zu bereinigen und weitere Kosten zu vermeiden:
- Löschen Sie die AWS Glue-Tabellen und -Datenbank aus Athena oder führen Sie den folgenden Code in Ihrem Notebook aus:
- Wählen Sie auf der EMR Studio-Konsole aus Workspaces im Navigationsbereich.
- Wählen Sie den von Ihnen erstellten Arbeitsbereich aus und wählen Sie Löschen.
- Navigieren Sie auf der EMR-Konsole zu Studios
- Wählen Sie das von Ihnen erstellte Studio aus und wählen Sie Löschen.
- Wählen Sie auf der EMR-Konsole aus Cluster im Navigationsbereich.
- Wählen Sie den Cluster aus und wählen Sie Beenden.
- Löschen Sie den S3-Bucket und alle anderen Ressourcen, die Sie als Teil der Voraussetzungen für diesen Beitrag erstellt haben.
Zusammenfassung
In diesem Beitrag haben wir das Apache Iceberg-Framework vorgestellt und wie es dabei hilft, einige der Herausforderungen zu lösen, die wir in einem modernen Data Lake haben. Dann haben wir Sie durch eine Lösung zur Verarbeitung inkrementeller Daten in einem Data Lake mit Apache Iceberg geführt. Schließlich haben wir uns intensiv mit der Leistungsoptimierung befasst, um die Lese- und Schreibleistung für unsere Anwendungsfälle zu verbessern.
Wir hoffen, dass dieser Beitrag einige nützliche Informationen für Sie bereitstellt, damit Sie entscheiden können, ob Sie Apache Iceberg in Ihrer Data Lake-Lösung verwenden möchten.
Über die Autoren
 Flora Wu ist Senior Resident Architect bei AWS Data Lab. Sie unterstützt Unternehmenskunden bei der Erstellung von Datenanalysestrategien und der Entwicklung von Lösungen zur Beschleunigung ihrer Geschäftsergebnisse. In ihrer Freizeit spielt sie gerne Tennis, tanzt Salsa und reist.
Flora Wu ist Senior Resident Architect bei AWS Data Lab. Sie unterstützt Unternehmenskunden bei der Erstellung von Datenanalysestrategien und der Entwicklung von Lösungen zur Beschleunigung ihrer Geschäftsergebnisse. In ihrer Freizeit spielt sie gerne Tennis, tanzt Salsa und reist.
 Daniel Li ist Senior Solutions Architect bei Amazon Web Services. Er konzentriert sich darauf, Kunden bei der Entwicklung, Einführung und Implementierung von Cloud-Services und -Strategien zu unterstützen. Wenn er nicht arbeitet, verbringt er gerne Zeit mit seiner Familie im Freien.
Daniel Li ist Senior Solutions Architect bei Amazon Web Services. Er konzentriert sich darauf, Kunden bei der Entwicklung, Einführung und Implementierung von Cloud-Services und -Strategien zu unterstützen. Wenn er nicht arbeitet, verbringt er gerne Zeit mit seiner Familie im Freien.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/use-apache-iceberg-in-a-data-lake-to-support-incremental-data-processing/
- 10
- 100
- 11
- 2022
- 2023
- 7
- 9
- a
- Fähig
- Über uns
- oben
- beschleunigen
- Zugang
- Action
- Handlungen
- Zusatz
- Zusätzliche
- Adresse
- Adressen
- Fügt
- adoptieren
- Vorteil
- Nach der
- gegen
- Alle
- erlaubt
- immer
- Amazon
- Amazon EMR
- Amazon Web Services
- Analytisch
- Analytik
- und
- angekündigt
- Apache
- Anwendungen
- angewandt
- Ansatz
- Ansätze
- angemessen
- Architektur
- damit verbundenen
- Authentifizierung
- Verfügbarkeit
- verfügbar
- durchschnittlich
- vermeiden
- AWS
- AWS-Kleber
- basierend
- weil
- werden
- Bevor
- Nutzen
- Besser
- zwischen
- größer
- Bootstrap
- bauen
- Building
- Unternehmen
- Captures
- Capturing
- Häuser
- Fälle
- Katalog
- Kataloge
- Kategorie
- Herausforderungen
- Übernehmen
- Änderungen
- aus der Ferne überprüfen
- Wahl
- Auswählen
- Einstufung
- Cloud
- Cloud-Services
- Cluster
- Code
- Kolonne
- Spalten
- kombinieren
- wie die
- verpflichten
- verglichen
- abschließen
- Berechnen
- Wettbewerber
- Zustand
- Konfigurationen
- Überlegungen
- Konsul (Console)
- Umwandlung (Conversion)
- umgewandelt
- kostengünstiger
- Kosten
- könnte
- erstellen
- erstellt
- schafft
- kuratiert
- Strom
- Kunde
- Kunden
- Tanzen
- Armaturenbrett
- technische Daten
- Datenanalyse
- Datensee
- Datenverarbeitung
- Data Warehouse
- Datenbase
- Datensätze
- tief
- Tieftauchgang
- Standard
- definiert
- Demo
- zeigen
- hängt
- entworfen
- Details
- entwickeln
- Entwicklung
- Unterschied
- anders
- diskutieren
- Nicht
- nach unten
- Dramatisch
- Drop
- im
- jeder
- Früher
- Früh
- Herausgeber
- effektiv
- effizient
- entweder
- eliminiert
- freigegeben
- ermöglichen
- endet
- Motor
- Motor (en)
- Enter
- Unternehmen
- Unternehmenskunden
- Äther (ETH)
- Sogar
- Evolution
- entwickelt sich
- sich entwickelnden
- Beispiel
- vorhandenen
- existiert
- erklärt
- Erweiterungen
- extra
- erleichtert
- Familie
- FAST
- beschleunigt
- Eigenschaften
- Abbildung
- Reichen Sie das
- Mappen
- Filter
- Filterung
- Filter
- Endlich
- Finden Sie
- Vorname
- erstes Mal
- konzentriert
- folgen
- Folgende
- Format
- Unser Ansatz
- häufig
- für
- weiter
- Außerdem
- Allgemeines
- erzeugt
- bekommen
- gegeben
- Goes
- gut
- sehr
- Gruppe an
- Pflege
- passieren
- Hilfe
- Unternehmen
- hilft
- versteckt
- Hierarchie
- High-Level
- Hohe Leistungsfähigkeit
- leistungsstark
- Bienenstock
- ein Geschenk
- Ultraschall
- Hilfe
- aber
- HTML
- HTTPS
- IAM
- Identitätsschutz
- Identitäts- und Zugriffsverwaltung
- Impact der HXNUMXO Observatorien
- wirkt
- implementieren
- Implementierung
- Umsetzung
- zu unterstützen,
- verbessert
- Verbesserung
- verbessert
- in
- Einschließlich
- Erhöhung
- hat
- Steigert
- Index
- Krankengymnastik
- Information
- installieren
- beantragen müssen
- Integration
- eingeführt
- Isolate
- IT
- Januar
- Jobs
- Wesentliche
- Labor
- See
- grosse
- größer
- Latency
- neueste
- neueste Erscheinung
- Schicht
- Lagen
- führen
- Cholesterinspiegel
- LIMIT
- Line
- Liste
- wenig
- Belastung
- Standorte
- um
- MACHT
- Management
- viele
- Kennzeichen
- Marktplatz
- Spiel
- Abstimmung
- Merge
- Metadaten
- könnte
- Millionen
- modern
- mehr
- schlauer bewegen
- mehrere
- Name
- Namens
- Navigieren
- Navigation
- Need
- erforderlich
- Bedürfnisse
- Neu
- Notizbuch
- Objekt
- XNUMXh geöffnet
- Betrieb
- Einkauf & Prozesse
- Optimierung
- Optimieren
- Auftrag
- Original
- Andere
- im Freien
- Gesamt-
- besitzen
- Brot
- Teil
- Weg
- Muster
- ausführen
- Leistung
- physikalisch
- Planung
- Plato
- Datenintelligenz von Plato
- PlatoData
- spielend
- Plugin
- Punkte
- Beliebt
- möglich
- Post
- angetriebene
- Voraussetzungen
- Verfahren
- Prozessdefinierung
- Verarbeitung
- produziert
- immobilien
- Resorts
- die
- bietet
- Bereitstellung
- Bereitstellung
- Angebot
- Roh
- Rohdaten
- Lesen Sie mehr
- Lesebrillen
- echt
- kürzlich
- empfohlen
- Aufzeichnungen
- reflektieren
- Region
- registriert
- regulär
- Release
- freigegeben
- verbleibenden
- falls angefordert
- erfordert
- Downloads
- Folge
- Die Ergebnisse
- Bewertungen
- Reiches
- Rollen
- Wurzel
- Führen Sie
- Laufen
- gleich
- Scan
- Sekunden
- Abschnitt
- Sicherheitdienst
- ausgewählt
- Auswahl
- Serverlos
- Leistungen
- Sitzung
- kompensieren
- Sets
- Einstellung
- Einstellungen
- sollte
- erklären
- Konzerte
- Einfacher
- Umstände
- Größe
- verlangsamt
- klein
- Schnappschuss
- So
- Software
- Lösung
- Lösungen
- einige
- Spark
- spezifisch
- Geschwindigkeit
- Ausgabe
- SQL
- Beginnen Sie
- Bundesstaat
- Erklärung
- Aussagen
- Statistik
- Schritt
- Shritte
- Immer noch
- storage
- speichern
- gelagert
- Läden
- Strategien
- Strategie
- strukturierte
- strukturierte und unstrukturierte Daten
- Studio Adressen
- Subnetz
- Folge
- Erfolgreich
- so
- ausreichend
- ZUSAMMENFASSUNG
- Support
- Unterstützte
- Unterstützung
- Unterstützt
- Tabelle
- nimmt
- Einnahme
- Target
- und Aufgaben
- Techniken
- Tennis
- Test
- Testen
- Tests
- Das
- die Informationen
- Der Staat
- ihr
- damit
- Tausende
- nach drei
- Durch
- Zeit
- Zeitreise
- zu
- gemeinsam
- auch
- Werkzeuge
- Top
- Gesamt
- verfolgen sind
- Transaktionen
- Transformieren
- reisen
- Reise
- WENDE
- Typen
- für
- einzigartiges
- Aktualisierung
- aktualisiert
- Updates
- Aktualisierung
- URL
- -
- Anwendungsfall
- Nutzer
- gewöhnlich
- VAL
- Wert
- Werte
- überprüfen
- Version
- ging
- Walkthrough
- Warehouse
- Uhren
- Wege
- Netz
- Web-Services
- Was
- ob
- welche
- während
- breit
- Große Auswahl
- werden wir
- ohne
- Arbeiten
- arbeiten,
- Werk
- würde
- schreiben
- Schreiben
- Ihr
- Zephyrnet