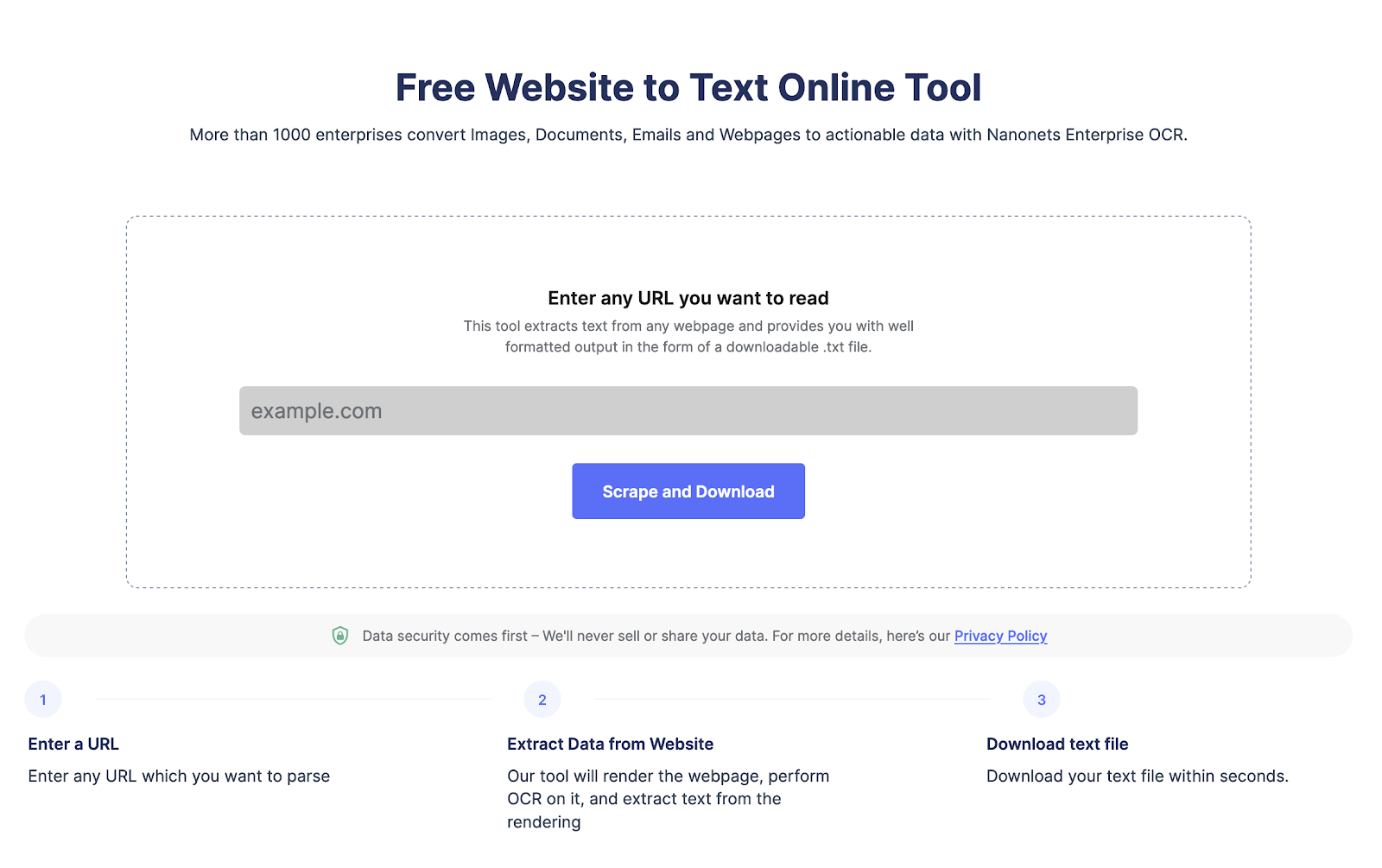
Möchten Sie Daten von einer Webseite extrahieren?
Gehen Sie zu Nanonets Website-Scraper, fügen Sie die URL hinzu und klicken Sie auf „Scrape“ und laden Sie den Webseitentext sofort als Datei herunter. Probieren Sie es jetzt kostenlos aus.
Was ist Web Scraping und seine Vorteile?
Web Scraping wird verwendet, um Daten in großem Umfang automatisch von Webseiten zu schaben. Web Scraping wird durchgeführt, um Daten in komplexen HTML-Strukturen in ein strukturiertes Format wie eine Tabellenkalkulation oder Datenbank umzuwandeln und für verschiedene Zwecke wie Recherche, Analyse und Automatisierung verwendet.
Hier sind einige der Gründe, warum Menschen Web Scraping verwenden:
- Extrahieren Sie Webseitendaten effizient für erweiterte Analysen.
- Behalten Sie die Entwicklungen auf den Websites der Mitbewerber im Auge und achten Sie auf Änderungen in ihren Produktangeboten, Taktiken oder Preisen.
- Kratzen Sie Leads oder E-Mail-Daten aus LinkedIn oder einem anderen Verzeichnis.
- Automatisieren Sie Aufgaben wie Dateneingabe, Formularausfüllen und andere sich wiederholende Aufgaben, sparen Sie Zeit und steigern Sie die Effizienz.
Warum sollten Sie Node.js für Web Scraping verwenden?
Node.js wird häufig verwendet, da es sich um eine leichtgewichtige, leistungsstarke und effiziente Plattform handelt. Hier sind einige Gründe, warum node.js eine gute Wahl für Web Scraping ist:
- Node.js kann mehrere Web-Scraping-Anfragen parallel verarbeiten.
- Es hat eine große Community, die sinnvolle Web-Scraping-Bibliotheken unterstützt und erstellt.
- Node.js ist plattformübergreifend und damit eine vielseitige Wahl für Web-Scraping-Projekte
- Node.js ist leicht zu erlernen, besonders wenn Sie bereits JavaScript kennen
- Node.js verfügt über eine integrierte Unterstützung für HTTP-Anforderungen, wodurch das Abrufen und Analysieren von HTML-Seiten von Websites vereinfacht wird
- Node.js ist hochgradig skalierbar, was beim Web Scraping bei der Verarbeitung großer Datenmengen wichtig ist
Möchten Sie Daten von einer Webseite extrahieren?
Gehen Sie zu Nanonets Website-Scraper, fügen Sie die URL hinzu und klicken Sie auf „Scrape“ und laden Sie den Webseitentext sofort als Datei herunter. Probieren Sie es jetzt kostenlos aus.
Wie kratzt man Webseiten mit Node JS?
Schritt 1 Einrichten Ihrer Umgebung:
Sie müssen node.js installieren, falls Sie dies noch nicht getan haben. Sie können es über die offizielle Website herunterladen.
Schritt 2 Notwendige Pakete für Web Scraping mit Node.js installieren:
Node.js bietet mehrere Optionen für Web Scraping wie Cheerio, Puppeteer und Request. Sie können sie einfach mit dem folgenden Befehl installieren.
npm install cheerio
npm install puppeteer
npm install requestSchritt 3 Einrichten Ihres Projektverzeichnisses:
Sie müssen ein neues Verzeichnis für das neue Projekt erstellen. Navigieren Sie dann zur Eingabeaufforderung, um eine neue Datei zum Speichern Ihres NodeJS-Web-Scraping-Codes zu erstellen.
Mit dem folgenden Befehl können Sie ein neues Verzeichnis und eine neue Datei erstellen:
mkdir my-web-scraper
cd my-web-scraper
touch scraper.jsSchritt 4 HTTP-Anforderungen mit Node.js stellen:
Um Webseiten zu scrapen, müssen Sie HTTP-Anfragen stellen. Jetzt hat Node.js ein eingebautes http-Modul. Das macht es einfach, Anfragen zu stellen. Sie können auch Axios oder Anfragen verwenden, um eine Anfrage zu stellen.
Hier ist der Code, um HTTP-Anfragen mit node.js zu stellen
const http = require('http');
const url = 'http://example.com';
http.get(url, (res) => {
let data = '';
res.on('data', (chunk) => {
data += chunk;
});
res.on('end', () => {
console.log(data);
});
});Ersetzen Sie http.//example.com durch die URL Ihrer Wahl, um die Webseiten zu scrapen,
Schritt 5 HTML mit Node.js scrapen:
Sobald Sie den HTML-Inhalt einer Webseite haben, müssen Sie ihn parsen, um die benötigten Daten zu extrahieren. Zum Analysieren von HTML in Node.js stehen mehrere Bibliotheken von Drittanbietern zur Verfügung, z. B. Cheerio und JSDOM.
Hier ist ein Beispielcode-Snippet, das Cheerio verwendet, um HTML zu parsen und Daten zu extrahieren:
const cheerio = require('cheerio');
const request = require('request');
const url = 'https://example.com';
request(url, (error, response, html) => {
if (!error && response.statusCode == 200) {
const $ = cheerio.load(html);
const title = $('title').text();
const firstParagraph = $('p').first().text();
console.log(title);
console.log(firstParagraph);
}
});Dieser Code verwendet die Anforderungsbibliothek, um den HTML-Inhalt der Webseite unter url abzurufen, und verwendet dann Cheerio, um den HTML-Code zu analysieren und den Titel und den ersten Absatz zu extrahieren.
Wie gehe ich mit Javascript und dynamischen Inhalten mit Node.js um?
Viele moderne Webseiten verwenden JavaScript, um dynamische Inhalte zu rendern, was es schwierig macht, sie zu kratzen. Für das JavaScript-Rendering können Sie Headless-Browser wie Puppeteer und Playwright verwenden, mit denen Sie eine Browserumgebung simulieren und dynamische Inhalte kratzen können.
Hier ist ein Beispielcode-Snippet, das Puppeteer verwendet, um eine Webseite zu schaben, die Inhalte mit JavaScript rendert:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
const title = await page.$eval('title', el => el.textContent);
const firstParagraph = await page.$eval('p', el => el.textContent);
console.log(title);
console.log(firstParagraph);
await browser.close();
})();Dieser Code verwendet Puppeteer, um einen Headless-Browser zu starten, zur Webseite unter URL zu navigieren und den Titel und den ersten Absatz zu extrahieren. Die Methode page.$eval() selektiert und extrahiert Daten aus HTML-Elementen.
Hier sind einige Bibliotheken, die Sie zum einfachen Scrapen von Webseiten mit NodeJS verwenden können:
Tschüss: ist eine schnelle, flexible und leichtgewichtige Implementierung von Kern-jQuery, die für die Serverseite entwickelt wurde.
JSDOM: ist eine reine JavaScript-Implementierung des DOM für Node.js. Es bietet eine Möglichkeit, eine DOM-Umgebung in Node.js zu erstellen und sie mit einer Standard-API zu manipulieren.
Puppenspieler: ist eine Node.js-Bibliothek, die eine High-Level-API zur Steuerung von Headless Chrome oder Chromium bereitstellt. Es kann für Web Scraping, automatisiertes Testen, Crawlen und Rendern verwendet werden.
Best Practices für Web Scraping mit Node.js
Hier sind einige Best Practices, die Sie befolgen sollten, wenn Sie Node.js für Web Scraping verwenden:
- Lesen Sie vor dem Scrapen einer Website deren Nutzungsbedingungen. Stellen Sie sicher, dass die Webseite keine Beschränkungen für das Web-Scraping oder die Häufigkeit des Scrapings von Webseiten hat.
- Begrenzen Sie die Anzahl der HTTP-Anfragen, um eine Überlastung der Website zu verhindern, indem Sie die Häufigkeit der Anfragen steuern.
- Legen Sie geeignete Header in Ihren HTTP-Anforderungen fest, um das Verhalten eines normalen Benutzers nachzuahmen.
- Zwischenspeichern von Webseiten und extrahierten Daten, um die Belastung der Website zu reduzieren.
- Web Scraping kann aufgrund der Komplexität und Variabilität von Websites fehleranfällig sein.
- Überwachen und passen Sie Ihre Scraping-Aktivität an und passen Sie Ihre Ratenbegrenzung, Header und andere Einstellungen nach Bedarf an.
Möchten Sie Daten von einer Webseite extrahieren?
Gehen Sie zu Nanonets Website-Scraper, fügen Sie die URL hinzu und klicken Sie auf „Scrape“ und laden Sie den Webseitentext sofort als Datei herunter. Probieren Sie es jetzt kostenlos aus.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://nanonets.com/blog/web-scraping-with-node-js/
- :Ist
- ][P
- $UP
- 1
- 2023
- a
- Aktivität
- advanced
- bereits
- Analyse
- und
- Bienen
- angemessen
- SIND
- AS
- At
- Automatisiert
- Im Prinzip so, wie Sie es von Google Maps kennen.
- Automation
- verfügbar
- – warten auf Sie!
- Axios
- BE
- Vorteile
- BESTE
- Best Practices
- Browser
- Browsern
- eingebaut
- by
- CAN
- CD
- Übernehmen
- aus der Ferne überprüfen
- Wahl
- Chrome
- Chrom
- klicken Sie auf
- Code
- COM
- community
- Wettbewerber
- Komplex
- Komplexität
- Konsul (Console)
- Inhalt
- Smartgeräte App
- Regelung
- verkaufen
- Kernbereich
- erstellen
- schafft
- Cross-Plattform-
- technische Daten
- Dateneingabe
- Datenbase
- entworfen
- Entwicklungen
- schwer
- Tut nicht
- DOM
- herunterladen
- dynamisch
- leicht
- Einfache
- Effizienz
- effizient
- effizient
- Elemente
- gewährleisten
- Eintrag
- Arbeitsumfeld
- Fehler
- insbesondere
- Äther (ETH)
- Beispiel
- Extrakt
- Extrahieren Sie die Daten
- KONZENTRAT
- Auge
- FAST
- Reichen Sie das
- Vorname
- flexibel
- folgen
- Folgende
- Aussichten für
- unten stehende Formular
- Format
- Frei
- Frequenz
- für
- groß
- Griff
- Haben
- Überschriften
- hier
- High-Level
- Hohe Leistungsfähigkeit
- hoch
- HTML
- http
- HTTPS
- Implementierung
- wichtig
- Verbesserung
- in
- installieren
- IT
- SEINE
- JavaScript
- jQuery
- Behalten
- Wissen
- grosse
- große Gemeinschaft
- starten
- umwandeln
- LERNEN
- Bibliotheken
- Bibliothek
- leicht
- Gefällt mir
- Belastung
- um
- MACHT
- Making
- sinnvoll
- Methode
- modern
- Modulen
- mehrere
- Navigieren
- notwendig,
- Need
- erforderlich
- Neu
- Knoten
- Node.js
- Anzahl
- of
- Angebote
- offiziell
- Offizielle Website
- on
- Optionen
- Auftrag
- Andere
- Pakete
- Seite
- Personen
- Plattform
- Plato
- Datenintelligenz von Plato
- PlatoData
- Praktiken
- verhindern
- gebühr
- Verarbeitung
- Produkt
- Projekt
- bietet
- Zwecke
- Bewerten
- Lesen Sie mehr
- Gründe
- Veteran
- regulär
- Rendering
- macht
- repetitiv
- Anforderung
- Zugriffe
- Forschungsprojekte
- Antwort
- Einschränkungen
- Einsparung
- skalierbaren
- Skalieren
- kratzen
- Einstellung
- Einstellungen
- mehrere
- sollte
- einige
- Kalkulationstabelle
- Standard
- speichern
- strukturierte
- so
- Support
- Taktik
- und Aufgaben
- AGB
- Testen
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- ihr
- Sie
- basierte Online-to-Offline-Werbezuordnungen von anderen gab.
- Zeit
- Titel
- zu
- aufnehmen
- URL
- -
- Mitglied
- verschiedene
- vielseitig
- Volumen
- Weg..
- Netz
- Bahnkratzen
- Webseite
- Webseiten
- welche
- mit
- Ihr
- Zephyrnet