Εικόνα από Freepik
Το Conversational AI αναφέρεται σε εικονικούς πράκτορες και chatbots που μιμούνται τις ανθρώπινες αλληλεπιδράσεις και μπορούν να εμπλακούν ανθρώπινα όντα σε συνομιλίες. Η χρήση τεχνητής νοημοσύνης συνομιλίας γίνεται γρήγορα τρόπος ζωής – από το να ζητάς από την Alexa να «βρείτε το πλησιέστερο εστιατόριο» να ζητήσει από τη Siri να "δημιουργήστε μια υπενθύμιση», Οι εικονικοί βοηθοί και τα chatbot χρησιμοποιούνται συχνά για να απαντήσουν σε ερωτήσεις των καταναλωτών, να επιλύσουν παράπονα, να κάνουν κρατήσεις και πολλά άλλα.
Η ανάπτυξη αυτών των εικονικών βοηθών απαιτεί σημαντική προσπάθεια. Ωστόσο, η κατανόηση και η αντιμετώπιση των βασικών προκλήσεων μπορεί να εξορθολογίσει τη διαδικασία ανάπτυξης. Έχω χρησιμοποιήσει την εμπειρία μου από πρώτο χέρι στη δημιουργία ενός ώριμου chatbot για μια πλατφόρμα στρατολόγησης ως σημείο αναφοράς για να εξηγήσω τις βασικές προκλήσεις και τις αντίστοιχες λύσεις τους.
Για να δημιουργήσουν ένα συνομιλητικό chatbot AI, οι προγραμματιστές μπορούν να χρησιμοποιήσουν πλαίσια όπως το RASA, το Amazon's Lex ή το Dialogflow της Google για τη δημιουργία chatbots. Οι περισσότεροι προτιμούν το RASA όταν σχεδιάζουν προσαρμοσμένες αλλαγές ή το bot βρίσκεται στο στάδιο της ώριμης ηλικίας, καθώς είναι ένα πλαίσιο ανοιχτού κώδικα. Άλλα πλαίσια είναι επίσης κατάλληλα ως αφετηρία.
Οι προκλήσεις μπορούν να ταξινομηθούν ως τρία κύρια στοιχεία ενός chatbot.
Κατανόηση φυσικής γλώσσας (NLU) είναι η ικανότητα ενός bot να κατανοεί τον ανθρώπινο διάλογο. Εκτελεί ταξινόμηση πρόθεσης, εξαγωγή οντοτήτων και ανάκτηση απαντήσεων.
Υπεύθυνος Διαλόγου είναι υπεύθυνος για ένα σύνολο ενεργειών που πρέπει να εκτελεστούν με βάση το τρέχον και το προηγούμενο σύνολο εισόδων χρήστη. Λαμβάνει πρόθεση και οντότητες ως είσοδο (ως μέρος της προηγούμενης συνομιλίας) και προσδιορίζει την επόμενη απάντηση.
Παραγωγή φυσικής γλώσσας (NLG) είναι η διαδικασία δημιουργίας γραπτών ή προφορικών προτάσεων από δεδομένα δεδομένα. Πλαισιώνει την απάντηση, η οποία στη συνέχεια παρουσιάζεται στον χρήστη.
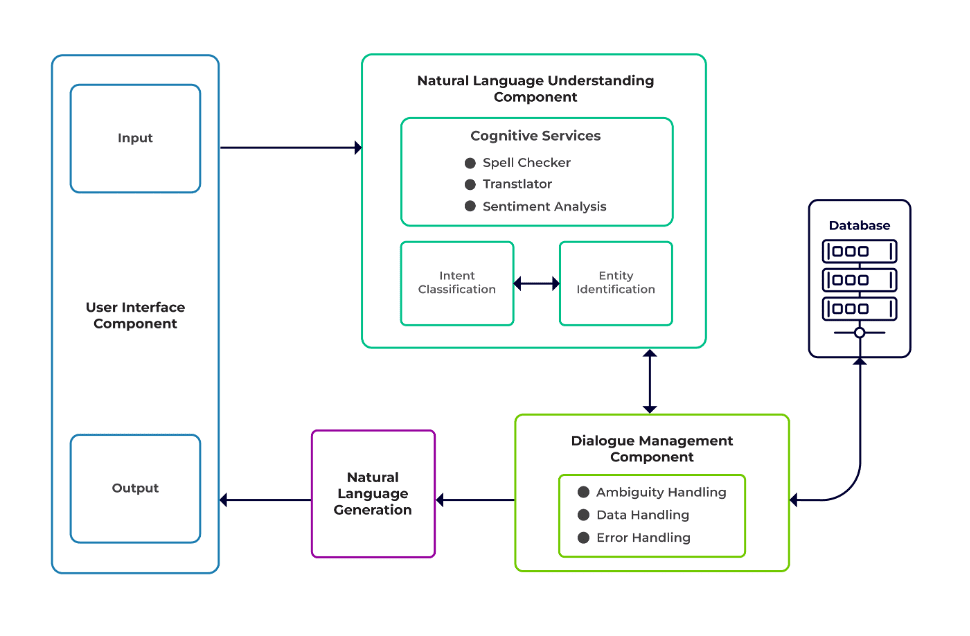
Εικόνα από το λογισμικό Talentica
Ανεπαρκή στοιχεία
Όταν οι προγραμματιστές αντικαθιστούν τις συχνές ερωτήσεις ή άλλα συστήματα υποστήριξης με ένα chatbot, λαμβάνουν μια αξιοπρεπή ποσότητα δεδομένων εκπαίδευσης. Αλλά δεν συμβαίνει το ίδιο όταν δημιουργούν το bot από την αρχή. Σε τέτοιες περιπτώσεις, οι προγραμματιστές δημιουργούν δεδομένα εκπαίδευσης συνθετικά.
Τι να κάνω;
Μια γεννήτρια δεδομένων που βασίζεται σε πρότυπα μπορεί να δημιουργήσει έναν αξιοπρεπή αριθμό ερωτημάτων χρήστη για εκπαίδευση. Μόλις το chatbot είναι έτοιμο, οι κάτοχοι έργων μπορούν να το εκθέσουν σε περιορισμένο αριθμό χρηστών για να βελτιώσουν τα δεδομένα εκπαίδευσης και να τα αναβαθμίσουν σε μια περίοδο.
Ακατάλληλη επιλογή μοντέλου
Η κατάλληλη επιλογή μοντέλου και τα δεδομένα εκπαίδευσης είναι ζωτικής σημασίας για να λάβετε τα καλύτερα αποτελέσματα εξαγωγής πρόθεσης και οντοτήτων. Οι προγραμματιστές συνήθως εκπαιδεύουν chatbots σε μια συγκεκριμένη γλώσσα και τομέα, και τα περισσότερα από τα διαθέσιμα προεκπαιδευμένα μοντέλα είναι συχνά ειδικά για τον τομέα και εκπαιδεύονται σε μία μόνο γλώσσα.
Μπορεί να υπάρχουν και περιπτώσεις μεικτών γλωσσών όπου οι άνθρωποι είναι πολύγλωσσοι. Μπορεί να εισάγουν ερωτήματα σε μικτή γλώσσα. Για παράδειγμα, σε μια περιοχή που κυριαρχείται από τη Γαλλία, οι άνθρωποι μπορούν να χρησιμοποιούν έναν τύπο αγγλικών που είναι ένας συνδυασμός γαλλικών και αγγλικών.
Τι να κάνω;
Η χρήση μοντέλων εκπαιδευμένων σε πολλές γλώσσες θα μπορούσε να μειώσει το πρόβλημα. Ένα προεκπαιδευμένο μοντέλο όπως το LaBSE (Ενσωμάτωση γλωσσικής αγνωστικιστικής πρότασης Bert) μπορεί να είναι χρήσιμο σε τέτοιες περιπτώσεις. Το LaBSE εκπαιδεύεται σε περισσότερες από 109 γλώσσες σε μια εργασία ομοιότητας προτάσεων. Το μοντέλο γνωρίζει ήδη παρόμοιες λέξεις σε διαφορετική γλώσσα. Στο έργο μας, λειτούργησε πολύ καλά.
Ακατάλληλη εξαγωγή οντοτήτων
Τα chatbot απαιτούν από τις οντότητες να προσδιορίζουν τι είδους δεδομένα αναζητά ο χρήστης. Αυτές οι οντότητες περιλαμβάνουν την ώρα, τον τόπο, το άτομο, το αντικείμενο, την ημερομηνία κ.λπ. Ωστόσο, τα ρομπότ μπορεί να μην προσδιορίσουν μια οντότητα από τη φυσική γλώσσα:
Ίδιο πλαίσιο αλλά διαφορετικές οντότητες. Για παράδειγμα, τα ρομπότ μπορούν να συγχέουν ένα μέρος ως οντότητα όταν ένας χρήστης πληκτρολογεί "Όνομα φοιτητών από το IIT Δελχί" και μετά "Όνομα φοιτητών από το Μπανγκαλόρ".
Σενάρια όπου οι οντότητες είναι λανθασμένες με χαμηλή εμπιστοσύνη. Για παράδειγμα, ένα bot μπορεί να αναγνωρίσει το IIT Delhi ως πόλη με χαμηλή εμπιστοσύνη.
Μερική εξαγωγή οντοτήτων με μοντέλο μηχανικής μάθησης. Εάν ένας χρήστης πληκτρολογήσει "μαθητές από το IIT Delhi", το μοντέλο μπορεί να προσδιορίσει μόνο το "IIT" μόνο ως οντότητα αντί για "IIT Delhi".
Οι εισαγωγές μιας λέξης που δεν έχουν πλαίσιο μπορεί να μπερδέψουν τα μοντέλα μηχανικής εκμάθησης. Για παράδειγμα, μια λέξη όπως "Rishikesh" μπορεί να σημαίνει τόσο το όνομα ενός ατόμου όσο και μιας πόλης.
Τι να κάνω;
Η προσθήκη περισσότερων παραδειγμάτων εκπαίδευσης θα μπορούσε να είναι μια λύση. Αλλά υπάρχει ένα όριο μετά το οποίο η προσθήκη περισσότερων δεν θα βοηθούσε. Επιπλέον, είναι μια ατελείωτη διαδικασία. Μια άλλη λύση θα μπορούσε να είναι ο ορισμός μοτίβων regex χρησιμοποιώντας προκαθορισμένες λέξεις για να βοηθήσετε στην εξαγωγή οντοτήτων με ένα γνωστό σύνολο πιθανών τιμών, όπως πόλη, χώρα κ.λπ.
Τα μοντέλα μοιράζονται χαμηλότερη εμπιστοσύνη όποτε δεν είναι σίγουροι για την πρόβλεψη οντοτήτων. Οι προγραμματιστές μπορούν να το χρησιμοποιήσουν ως έναυσμα για να καλέσουν ένα προσαρμοσμένο στοιχείο που μπορεί να διορθώσει την οντότητα χαμηλής αυτοπεποίθησης. Ας εξετάσουμε το παραπάνω παράδειγμα. Αν IIT Δελχί προβλέπεται ως πόλη με χαμηλή εμπιστοσύνη, τότε ο χρήστης μπορεί πάντα να την αναζητήσει στη βάση δεδομένων. Αφού απέτυχε να βρει την προβλεπόμενη οντότητα στο Πόλη πίνακα, το μοντέλο θα προχωρήσει σε άλλους πίνακες και, τελικά, θα το βρει στο Ινστιτούτο πίνακα, με αποτέλεσμα τη διόρθωση οντοτήτων.
Λανθασμένη ταξινόμηση προθέσεων
Κάθε μήνυμα χρήστη έχει κάποια πρόθεση που σχετίζεται με αυτό. Δεδομένου ότι οι προθέσεις προέρχονται από την επόμενη πορεία ενεργειών ενός bot, η σωστή ταξινόμηση των ερωτημάτων χρήστη με πρόθεση είναι ζωτικής σημασίας. Ωστόσο, οι προγραμματιστές πρέπει να προσδιορίζουν τις προθέσεις με ελάχιστη σύγχυση μεταξύ των προθέσεων. Διαφορετικά, μπορεί να υπάρξουν περιπτώσεις σύγχυσης. Για παράδειγμα, "Δείξε μου ανοιχτές θέσεις» εναντίον "Δείξε μου υποψηφίους ανοιχτής θέσης».
Τι να κάνω;
Υπάρχουν δύο τρόποι για να διαφοροποιήσετε τα μπερδεμένα ερωτήματα. Πρώτον, ένας προγραμματιστής μπορεί να εισαγάγει υποπρόθεση. Δεύτερον, τα μοντέλα μπορούν να χειριστούν ερωτήματα με βάση τις οντότητες που προσδιορίζονται.
Ένα chatbot για συγκεκριμένο τομέα θα πρέπει να είναι ένα κλειστό σύστημα όπου θα πρέπει να προσδιορίζει ξεκάθαρα τι είναι ικανό και τι όχι. Οι προγραμματιστές πρέπει να κάνουν την ανάπτυξη σε φάσεις ενώ σχεδιάζουν chatbot για συγκεκριμένο τομέα. Σε κάθε φάση, μπορούν να αναγνωρίσουν τις μη υποστηριζόμενες λειτουργίες του chatbot (μέσω μη υποστηριζόμενης πρόθεσης).
Μπορούν επίσης να προσδιορίσουν τι δεν μπορεί να χειριστεί το chatbot με πρόθεση "εκτός πεδίου". Ωστόσο, μπορεί να υπάρχουν περιπτώσεις όπου το ρομπότ έχει μπερδευτεί με μη υποστηριζόμενη και εκτός πεδίου πρόθεσης. Για τέτοια σενάρια, θα πρέπει να υπάρχει ένας εναλλακτικός μηχανισμός όπου, εάν η εμπιστοσύνη πρόθεσης είναι κάτω από ένα όριο, το μοντέλο μπορεί να λειτουργήσει χαριτωμένα με μια εναλλακτική πρόθεση να χειριστεί περιπτώσεις σύγχυσης.
Μόλις το bot αναγνωρίσει την πρόθεση του μηνύματος ενός χρήστη, πρέπει να στείλει μια απάντηση. Το Bot αποφασίζει την απάντηση με βάση ένα συγκεκριμένο σύνολο καθορισμένων κανόνων και ιστοριών. Για παράδειγμα, ένας κανόνας μπορεί να είναι τόσο απλός όσο και απόλυτος "Καλημέρα" όταν ο χρήστης χαιρετά "Γεια". Ωστόσο, τις περισσότερες φορές, οι συνομιλίες με chatbots περιλαμβάνουν επακόλουθη αλληλεπίδραση και οι απαντήσεις τους εξαρτώνται από το συνολικό πλαίσιο της συνομιλίας.
Τι να κάνω;
Για να το χειριστούν αυτό, τα chatbots τροφοδοτούνται με πραγματικά παραδείγματα συνομιλιών που ονομάζονται Ιστορίες. Ωστόσο, οι χρήστες δεν αλληλεπιδρούν πάντα όπως προβλέπεται. Ένα ώριμο chatbot θα πρέπει να χειρίζεται όλες αυτές τις αποκλίσεις με χάρη. Οι σχεδιαστές και οι προγραμματιστές μπορούν να το εγγυηθούν αν δεν επικεντρωθούν μόνο σε μια ευτυχισμένη διαδρομή ενώ γράφουν ιστορίες, αλλά και εργάζονται σε δυστυχισμένα μονοπάτια.
Η αφοσίωση των χρηστών με τα chatbots βασίζεται σε μεγάλο βαθμό στις απαντήσεις του chatbot. Οι χρήστες ενδέχεται να χάσουν το ενδιαφέρον τους εάν οι απαντήσεις είναι πολύ ρομποτικές ή πολύ οικείες. Για παράδειγμα, σε έναν χρήστη μπορεί να μην αρέσει μια απάντηση όπως "Έχετε πληκτρολογήσει λάθος ερώτημα" για λάθος εισαγωγή, παρόλο που η απάντηση είναι σωστή. Η απάντηση εδώ δεν ταιριάζει με την προσωπικότητα ενός βοηθού.
Τι να κάνω;
Το chatbot χρησιμεύει ως βοηθός και θα πρέπει να διαθέτει συγκεκριμένο πρόσωπο και τόνο φωνής. Θα πρέπει να είναι φιλόξενοι και ταπεινοί και οι προγραμματιστές θα πρέπει να σχεδιάζουν τις συνομιλίες και τις δηλώσεις ανάλογα. Οι αποκρίσεις δεν πρέπει να ακούγονται ρομποτικές ή μηχανικές. Για παράδειγμα, το ρομπότ θα μπορούσε να πει, "Συγγνώμη, φαίνεται ότι δεν έχω λεπτομέρειες. Μπορείτε παρακαλώ να πληκτρολογήσετε ξανά το ερώτημά σας;» για να αντιμετωπίσετε μια λάθος εισαγωγή.
Τα chatbot που βασίζονται στο LLM (Large Language Model) όπως το ChatGPT και το Bard είναι καινοτομίες που αλλάζουν το παιχνίδι και έχουν βελτιώσει τις δυνατότητες των AI συνομιλίας. Δεν είναι μόνο καλοί στο να κάνουν ανθρώπινες συνομιλίες ανοιχτού τύπου, αλλά μπορούν να εκτελούν διαφορετικές εργασίες όπως σύνοψη κειμένου, σύνταξη παραγράφων κ.λπ., οι οποίες θα μπορούσαν να επιτευχθούν νωρίτερα μόνο με συγκεκριμένα μοντέλα.
Μία από τις προκλήσεις με τα παραδοσιακά συστήματα chatbot είναι η κατηγοριοποίηση κάθε πρότασης σε προθέσεις και η απόφαση για την απάντηση ανάλογα. Αυτή η προσέγγιση δεν είναι πρακτική. Οι απαντήσεις όπως «Συγγνώμη, δεν μπορούσα να σε καταλάβω» είναι συχνά εκνευριστικές. Τα συστήματα chatbot χωρίς πρόθεση είναι ο δρόμος προς τα εμπρός και τα LLM μπορούν να το κάνουν πραγματικότητα.
Τα LLM μπορούν εύκολα να επιτύχουν αποτελέσματα τελευταίας τεχνολογίας σε γενική αναγνώριση οντοτήτων με ονομασία, αποκλείοντας την αναγνώριση οντοτήτων για συγκεκριμένο τομέα. Μια μικτή προσέγγιση για τη χρήση LLM με οποιοδήποτε πλαίσιο chatbot μπορεί να εμπνεύσει ένα πιο ώριμο και ισχυρό σύστημα chatbot.
Με τις πιο πρόσφατες εξελίξεις και τη συνεχή έρευνα στην τεχνητή νοημοσύνη συνομιλίας, τα chatbot γίνονται καλύτερα κάθε μέρα. Τομείς όπως ο χειρισμός σύνθετων εργασιών με πολλαπλές προθέσεις, όπως «Κλείστε μια πτήση για τη Βομβάη και κανονίστε ένα ταξί για το Νταντάρ», προσελκύουν μεγάλη προσοχή.
Σύντομα θα πραγματοποιηθούν εξατομικευμένες συνομιλίες με βάση τα χαρακτηριστικά του χρήστη για να κρατήσουν τον χρήστη αφοσιωμένο. Για παράδειγμα, εάν ένα bot διαπιστώσει ότι ο χρήστης είναι δυσαρεστημένος, ανακατευθύνει τη συνομιλία σε έναν πραγματικό πράκτορα. Επιπλέον, με τα συνεχώς αυξανόμενα δεδομένα chatbot, οι τεχνικές βαθιάς εκμάθησης όπως το ChatGPT μπορούν να δημιουργήσουν αυτόματα απαντήσεις για ερωτήματα χρησιμοποιώντας μια βάση γνώσεων.
Σουμάν Σαουράβ είναι Επιστήμονας Δεδομένων στην Talentica Software, μια εταιρεία ανάπτυξης προϊόντων λογισμικού. Είναι απόφοιτος του NIT Agartala με πάνω από 8 χρόνια εμπειρία στο σχεδιασμό και την υλοποίηση επαναστατικών λύσεων AI χρησιμοποιώντας NLP, Conversational AI και Generative AI.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://www.kdnuggets.com/3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them?utm_source=rss&utm_medium=rss&utm_campaign=3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them
- :έχει
- :είναι
- :δεν
- :που
- 8
- a
- ικανότητα
- Σχετικα
- πάνω από
- αναλόγως
- Κατορθώνω
- επιτευχθεί
- απέναντι
- ενεργειών
- προσθήκη
- Επιπλέον
- διεύθυνση
- διευθυνσιοδότηση
- εξελίξεις
- Μετά το
- Πράκτορας
- παράγοντες
- AI
- AI chatbot
- Alexa
- Όλα
- ήδη
- Επίσης
- απόφοιτος
- πάντοτε
- ποσό
- an
- και
- Άλλος
- απάντηση
- κάθε
- πλησιάζω
- ΕΙΝΑΙ
- περιοχές
- AS
- ζητώντας
- Βοηθός
- βοηθούς
- συσχετισμένη
- At
- προσοχή
- αυτομάτως
- διαθέσιμος
- αποφύγετε
- πίσω
- βάση
- βασίζονται
- BE
- να γίνει
- όντα
- παρακάτω
- ΚΑΛΎΤΕΡΟΣ
- Καλύτερα
- Bot
- και οι δύο
- bots
- χτίζω
- αλλά
- by
- κλήση
- που ονομάζεται
- CAN
- δεν μπορώ
- δυνατότητες
- ικανός
- περιπτώσεις
- κατηγοριοποιώντας
- ορισμένες
- προκλήσεις
- Αλλαγές
- χαρακτηριστικά
- chatbot
- chatbots
- ChatGPT
- Πόλη
- ταξινόμηση
- ταξινομούνται
- σαφώς
- κλειστό
- εταίρα
- παραπόνων
- συγκρότημα
- συστατικό
- εξαρτήματα
- κατανοώ
- εμπιστοσύνη
- συγχέεται
- σύγχυση
- σύγχυση
- Εξετάστε
- συμφραζόμενα
- συνεχής
- Συνομιλία
- ομιλητικός
- συνομιλία AI
- συνομιλίες
- διορθώσει
- σωστά
- Αντίστοιχος
- θα μπορούσε να
- χώρα
- πορεία
- δημιουργία
- δημιουργία
- κρίσιμος
- Ρεύμα
- έθιμο
- ημερομηνία
- επιστήμονας δεδομένων
- βάση δεδομένων
- Ημερομηνία
- ημέρα
- Αποφασίζοντας
- βαθύς
- βαθιά μάθηση
- ορίζεται
- ορίζεται
- Δελχί
- εξαρτηθεί
- τάση
- Υπηρεσίες
- σχεδιαστές
- σχέδιο
- καθέκαστα
- Εργολάβος
- προγραμματιστές
- Ανάπτυξη
- διαλόγου
- Διάλογος
- διαφορετικές
- διαφοροποιούν
- do
- Όχι
- τομέα
- Μην
- κάθε
- Νωρίτερα
- εύκολα
- προσπάθεια
- ενσωμάτωση
- Ατελείωτη
- ασκούν
- ασχολούνται
- δέσμευση
- Αγγλικά
- ενίσχυση
- εισάγετε
- οντότητες
- οντότητα
- κ.λπ.
- Even
- τελικά
- συνεχώς αυξανόμενη
- Κάθε
- κάθε μέρα
- παράδειγμα
- παραδείγματα
- εμπειρία
- Εξηγήστε
- εκχύλισμα
- εξαγωγή
- ΑΠΟΤΥΓΧΑΝΩ
- παραλείποντας
- οικείος
- FAST
- Χαρακτηριστικά
- Fed
- Εύρεση
- ευρήματα
- πρώτα
- πτήση
- Συγκέντρωση
- Για
- Προς τα εμπρός
- Πλαίσιο
- πλαισίων
- Γαλλικά
- από
- General
- παράγουν
- παραγωγής
- γενεά
- γενετική
- Παραγωγική τεχνητή νοημοσύνη
- γεννήτρια
- παίρνω
- να πάρει
- δεδομένου
- καλός
- Της Google
- εγγύηση
- λαβή
- Χειρισμός
- συμβαίνω
- ευτυχισμένος
- Έχω
- που έχει
- he
- βαριά
- βοήθεια
- χρήσιμο
- εδώ
- Πως
- Πώς να
- Ωστόσο
- HTTPS
- ανθρώπινος
- ταπεινός
- i
- προσδιορίζονται
- αναγνωρίζει
- προσδιορίσει
- if
- εκτελεστικών
- βελτιωθεί
- in
- περιλαμβάνουν
- καινοτομίες
- εισαγωγή
- είσοδοι
- εμπνεύσει
- παράδειγμα
- αντί
- προορίζονται
- πρόθεση
- αλληλεπιδρούν
- αλληλεπίδραση
- αλληλεπιδράσεις
- τόκος
- σε
- εισαγάγει
- IT
- jpg
- μόλις
- KDnuggets
- Διατήρηση
- Κλειδί
- Είδος
- γνώση
- γνωστός
- ξέρει
- Γλώσσα
- Γλώσσες
- large
- αργότερο
- μάθηση
- ζωή
- Μου αρέσει
- LIMIT
- Περιωρισμένος
- χάνουν
- Χαμηλός
- χαμηλότερα
- μηχανή
- μάθηση μηχανής
- μεγάλες
- κάνω
- Κατασκευή
- Ταίριασμα
- ώριμος
- Ενδέχεται..
- me
- εννοώ
- μηχανικός
- μηχανισμός
- μήνυμα
- ενδέχεται να
- ελάχιστος
- μείγμα
- μικτός
- μοντέλο
- μοντέλα
- περισσότερο
- Εξάλλου
- πλέον
- πολύ
- πολλαπλούς
- Βομβάη
- πρέπει
- my
- όνομα
- Ονομάστηκε
- Φυσικό
- Φυσική γλώσσα
- επόμενη
- NLG
- nlp
- ουδ
- Όχι.
- αριθμός
- of
- συχνά
- on
- μια φορά
- αποκλειστικά
- ανοίξτε
- ανοικτού κώδικα
- or
- ΑΛΛΑ
- αλλιώς
- δικός μας
- επί
- φόρμες
- ιδιοκτήτες
- μέρος
- μονοπάτι
- μονοπάτια
- πρότυπα
- People
- εκτελέσει
- εκτελούνται
- εκτελεί
- περίοδος
- person
- Εξατομικευμένη
- φάση
- φάσεις
- Μέρος
- σχέδιο
- σχεδιασμό
- πλατφόρμες
- Πλάτων
- Πληροφορία δεδομένων Plato
- Πλάτωνα δεδομένα
- σας παρακαλούμε
- Σημείο
- θέση
- έχουν
- δυνατός
- Πρακτικός
- προβλεπόμενη
- πρόβλεψη
- προτιμώ
- παρουσιάζονται
- προηγούμενος
- Πρόβλημα
- προχωρήσει
- διαδικασια μας
- Προϊόν
- ανάπτυξη προϊόντων
- σχέδιο
- ερωτήματα
- Ερωτήσεις
- R
- rasa
- έτοιμος
- πραγματικός
- Πραγματικότητα
- πραγματικά
- αναγνώριση
- στρατολόγηση
- μείωση
- αναφορά
- αναφέρεται
- περιοχή
- βασίζονται
- υπενθύμιση
- αντικαθιστώ
- απαιτούν
- Απαιτεί
- έρευνα
- επίλυση
- απάντησης
- απαντήσεις
- υπεύθυνος
- με αποτέλεσμα
- Αποτελέσματα
- επαναστατικός
- Ρομποτική
- εύρωστος
- Άρθρο
- κανόνες
- ίδιο
- λένε
- σενάρια
- Επιστήμονας
- μηδέν
- Αναζήτηση
- αναζήτηση
- φαίνεται
- επιλογή
- στείλετε
- ποινή
- εξυπηρετεί
- σειρά
- Κοινοποίηση
- θα πρέπει να
- παρόμοιες
- Απλούς
- αφού
- ενιαίας
- Siri
- λογισμικό
- λύση
- Λύσεις
- μερικοί
- Ήχος
- συγκεκριμένες
- ομιλείται
- Στάδιο
- Ξεκινήστε
- state-of-the-art
- ιστορίες
- εξορθολογισμό
- Φοιτητές
- ουσιώδης
- τέτοιος
- κατάλληλος
- υποστήριξη
- Συστήματα Υποστήριξης
- βέβαιος
- συνθετικώς
- σύστημα
- συστήματα
- T
- τραπέζι
- Πάρτε
- παίρνει
- Έργο
- εργασίες
- τεχνικές
- κείμενο
- από
- ότι
- Η
- τους
- Τους
- τότε
- Εκεί.
- Αυτοί
- αυτοί
- αυτό
- αν και?
- τρία
- κατώφλι
- ώρα
- προς την
- TONE
- Ο τόνος της φωνής
- πολύ
- παραδοσιακός
- Τρένο
- εκπαιδευμένο
- Εκπαίδευση
- ενεργοποιούν
- δύο
- τύπος
- τύποι
- κατανόηση
- αναβάθμισης
- χρήση
- μεταχειρισμένος
- Χρήστες
- Χρήστες
- χρησιμοποιώντας
- συνήθως
- Αξίες
- μέσω
- Πραγματικός
- Φωνή
- vs
- W
- Τρόπος..
- τρόπους
- υποδοχή
- ΛΟΙΠΌΝ
- Τι
- πότε
- οποτεδήποτε
- Ποιό
- ενώ
- θα
- με
- λέξη
- λόγια
- Εργασία
- εργάστηκαν
- θα
- γραφή
- γραπτή
- Λανθασμένος
- χρόνια
- εσείς
- Σας
- zephyrnet