Εισαγωγή
Κάθε επιστήμονας δεδομένων απαιτεί ένα αποτελεσματικό και αξιόπιστο εργαλείο για την επεξεργασία αυτών των μεγάλων ασταμάτητων δεδομένων. Σήμερα συζητάμε ένα τέτοιο εργαλείο που ονομάζεται Delta Lake, το οποίο χρησιμοποιούν οι λάτρεις των δεδομένων για να κάνουν τους αγωγούς επεξεργασίας δεδομένων τους πιο αποτελεσματικούς και αξιόπιστους.
Βασικά, το Delta Lake είναι ένα στρώμα αποθήκευσης ανοιχτού κώδικα που βρίσκεται πάνω από την υπάρχουσα υποδομή αποθήκευσης δεδομένων μας και επιτρέπει την επιβολή σχήματος, την έκδοση εκδόσεων και τις συναλλαγές ACID (ατομικότητα, συνέπεια, απομόνωση και ανθεκτικότητα) για τα δεδομένα μας. Το Delta Lake προσφέρει πολλά πλεονεκτήματα, όπως τη διαχείριση του τεράστιου όγκου δεδομένων, τη δυνατότητα εύκολης επαναφοράς των αλλαγών και την παροχή συνέπειας δεδομένων σε πολλαπλές περιόδους λειτουργίας Spark.
Εάν προετοιμάζεστε για τη συνέντευξη της Delta Lake, καταλήξατε στο σωστό blog. Εδώ συζητάμε τις πιο συχνές ερωτήσεις συνέντευξης Delta Lake.
Στόχοι μάθησης
Παρακάτω είναι τι θα μάθουμε αφού διαβάσουμε προσεκτικά αυτό το ιστολόγιο:
- Κατανόηση του τι είναι μια λίμνη Δέλτα και τι ρόλο παίζει στην τεχνική εποχή.
- Γνώση της σχέσης του με το Apache Spark.
- Κατανόηση της διαδικασίας εισαγωγής ή φόρτωσης δεδομένων στη λίμνη Δέλτα.
- Κατανόηση των συστατικών της Λίμνης Δέλτα και των ιδιοτήτων τους που είναι συμβατές με οξέα.
- Πληροφορίες για έννοιες όπως Upserts, τρόποι ανάγνωσης δεδομένων και λειτουργίες δέσμης και ροής στη λίμνη Delta.
Συνολικά, διαβάζοντας αυτόν τον οδηγό, θα αποκτήσουμε μια ολοκληρωμένη κατανόηση της λίμνης Delta για την αποθήκευση των δεδομένων. Μετά την ολοκλήρωση αυτού του ιστολογίου, έχουμε αρκετές γνώσεις και ικανότητες για να χρησιμοποιήσουμε αποτελεσματικά αυτήν την τεχνική και να απαντήσουμε σε κοινά ερωτήματα μεσαίου επιπέδου, και μπορείτε να περάσετε τη συνέντευξή σας στη λίμνη δέλτα.
.
Αυτό το άρθρο δημοσιεύθηκε ως μέρος του Data Science Blogathon.
Πίνακας περιεχομένων
Q1. Πώς διαφέρει το Delta Lake από άλλα επίπεδα αποθήκευσης συναλλαγών;
Αν και η Delta Lake επιλύει επίσης τις ίδιες προκλήσεις που επιλύονται από άλλα επίπεδα συναλλαγών, δεν είναι αυτό. έχει μια ευρύτερη κάλυψη περιπτώσεων χρήσης σε όλο το οικοσύστημα δεδομένων, γεγονός που του προσφέρει φήμη. Το Delta Lake παρέχει ασφάλεια δεδομένων, αξιοπιστία και καλύτερη απόδοση και προσφέρει ένα ενοποιημένο πλαίσιο για φόρτους εργασίας κατά παρτίδες και ροής. Βελτιώνει την αποτελεσματικότητα διαφόρων μεταγενέστερων δραστηριοτήτων όπως BI, ML, επιστήμη δεδομένων και αγωγοί μετασχηματισμού δεδομένων.
Πηγή: kpipartners
Επίσης, για να έχουμε περισσότερα οφέλη, μπορούμε να χρησιμοποιήσουμε τη λίμνη Delta Βάσεις δεδομένων; παρέχει ευρύτερη υποστήριξη οικοσυστήματος με ταχύτερες εγγενείς συνδέσεις στα πιο δημοφιλή εργαλεία Business Intelligence, επιτρέπει καλύτερη απόδοση με το Delta Engine και προσφέρει καλύτερη ασφάλεια και διακυβέρνηση με λεπτομερή στοιχεία ελέγχου πρόσβασης.
Επιτέλους, έρχονται στα στατιστικά στοιχεία, περίπου 3 petabyte δεδομένων καταπίνονται από τις λίμνες Δέλτα σε καθημερινή βάση και παράγονται για πάνω από 3 χρόνια. χιλιάδες χρήστες χρησιμοποιούν το Delta Lake στα Databricks.
Ε2. Εξηγήστε πώς οι λίμνες Delta είναι συμβατές με οξέα.
Οι λίμνες Δέλτα είναι ΟΞΥ συμμορφώνεται γιατί:
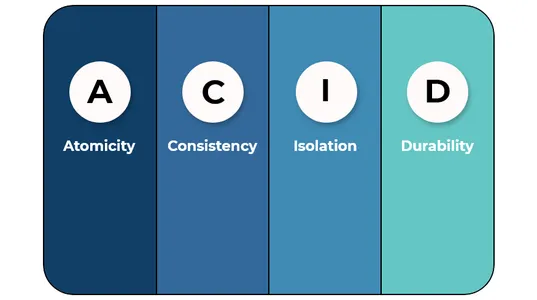
A (Atomicity)- Η Delta Lake προσφέρει ατομικές συναλλαγές, οι οποίες συνεπάγονται ότι όλες οι τροποποιήσεις στα δεδομένα σε έναν πίνακα Delta είτε δεσμεύονται είτε όλες.
Γ (Συνέπεια)- Η Delta Lake προσφέρει συνοχή δεδομένων που σημαίνει ότι οι αναγνώστες δεδομένων θα διαβάζουν πάντα τα ίδια δεδομένα τη στιγμή που ξεκίνησε η συναλλαγή.
Ι (απομόνωση)- Με τη βοήθεια μιας λειτουργίας ταξιδιού στο χρόνο, οι λίμνες δεδομένων υποστηρίζουν την απομόνωση και επιτρέπουν στους χρήστες να βλέπουν τα δεδομένα όπως υπάρχουν ανά πάσα στιγμή.
D (Ανθεκτικότητα)- Το Data Lake υποστηρίζει την ανθεκτικότητα εμφανίζοντας όλες τις αλλαγές στις συναλλαγές παρά τις αστοχίες του συστήματος.
Ε3. Εξηγήστε τη σχέση της λίμνης Δέλτα με το Apache Spark.
Η λίμνη Δέλτα είναι ένα εργαλείο χτισμένο στην κορυφή του Apache Spark και προσφέρει μια διαδρομή για τη διαχείριση του χώρου αποθήκευσης και τη βελτίωση της απόδοσης για τις εφαρμογές Spark. Το Delta Lake βελτιώνει την απόδοση όταν το Spark διαβάζει και γράφει δεδομένα αποθηκεύοντας δεδομένα σε αρχεία Parquet. Χρησιμοποιεί μορφή στήλης και για να διασφαλίσει τη συνέπεια των δεδομένων, προσφέρει έναν τρόπο διαχείρισης συναλλαγών και παρακολούθησης των τροποποιήσεων δεδομένων.
Ε4. Γιατί να χρησιμοποιήσουμε το Delta Lake εάν μπορούμε να αποθηκεύσουμε δεδομένα σε μορφή παρκέ σε S3 ή HDFS;
Το Delta Lake είναι μια καλή επιλογή έναντι του Parquet όταν πρέπει να εκτελέσουμε επεξεργασία δεδομένων μεγάλης κλίμακας, επειδή προσφέρει υψηλή επεκτασιμότητα και καλύτερη απόδοση. Επίσης, παρά τις διακοπές ρεύματος ή τις αστοχίες υλικού, τα δεδομένα θα παραμείνουν ασφαλή από διαφθορά λόγω του σχεδιασμού των Delta Lakes που είναι συμβατός με ACID.
Q5. Εξηγήστε τη διαδικασία εισαγωγής δεδομένων στη λίμνη Δέλτα.
Μπορούμε να εισάγουμε δεδομένα στη λίμνη Delta χρησιμοποιώντας απλώς το Βάσεις δεδομένων Εργαλείο Auto Loader ή την εντολή COPY INTO με SQL. λαμβάνει αυτόματα νέα αρχεία δεδομένων στο Delta Lake επειδή έρχονται στη λίμνη δεδομένων μας (δηλαδή σε S3 ή ADLS). Επιπλέον, μπορούμε να χρησιμοποιήσουμε το Apache SparkTM για ομαδική ανάγνωση των δεδομένων μας εκτελώντας τις απαραίτητες αλλαγές και αποθηκεύοντας το αποτέλεσμα στη λίμνη Delta.
Ε6. Εξηγήστε τα κύρια συστατικά μιας λίμνης Δέλτα.
Το Delta Lake περιλαμβάνει τρία σημαντικά στοιχεία, τον πίνακα Delta, το αρχείο καταγραφής Delta και την κρυφή μνήμη Delta.
Πίνακας Δέλτα: Είναι το κεντρικό τμήμα αποθήκευσης που μεταφέρει όλα τα δεδομένα για μια λίμνη Δέλτα.
Καταγραφή Δέλτα: Ένα αρχείο καταγραφής συναλλαγών χρησιμοποιείται για την παρακολούθηση ή την παρακολούθηση όλων των τροποποιήσεων που έγιναν στον πίνακα Delta.
Delta Cache: Είναι μια στήλη cache και ακριβώς όπως η κανονική κρυφή μνήμη, αποθηκεύει την τρέχουσα έκδοση των δεδομένων στον πίνακα Delta.
Ε7. Πώς εκτελούμε Upserts στη λίμνη Delta;
Το Upsert είναι ένας συνδυασμός δύο λέξεων/λειτουργιών, δηλαδή, Ενημέρωση και Εισαγωγή. Μπορούμε να εκτελέσουμε upserts στη λίμνη δέλτα χρησιμοποιώντας τις εντολές MERGE και INSERT INTO:
Συγχώνευση: Με τη βοήθεια της εντολής MERGE, μπορούμε να ενημερώσουμε ή να εισάγουμε οποιαδήποτε δεδομένα σε έναν πίνακα Delta ανάλογα με μια δεδομένη συνθήκη. Χρησιμοποιώντας τον όρο WHERE, βάζουμε μια συνθήκη σε οποιαδήποτε εντολή και εάν η συνθήκη καταλήξει σε αληθή, εκτελείται η ενέργεια UPDATE. Εάν η συνθήκη καταλήξει σε false, εκτελείται η ενέργεια INSERT.
Εισάγετε:Με τη βοήθεια της εντολής INSERT INTO, μπορούμε να εισάγουμε δεδομένα σε έναν πίνακα Delta, αλλά αυτή η εντολή θα εισάγει μόνο νέες σειρές στον πίνακα, χωρίς λειτουργία ενημέρωσης στις υπάρχουσες σειρές.
Ε8. Εξηγήστε τους διαφορετικούς τρόπους λειτουργίας που είναι διαθέσιμοι για την ανάγνωση δεδομένων από έναν πίνακα Delta Lake.
Για να διαβάσετε τα δεδομένα από έναν πίνακα Delta Lake, έχουμε δύο διαθέσιμους τρόπους:
1. Λειτουργία πλήρους σάρωσης: Αυτή η λειτουργία χρησιμοποιείται για την ανάγνωση ολόκληρου του περιεχομένου του πίνακα Delta Lake.
2. Λειτουργία σταδιακής σάρωσης: Αυτή η λειτουργία χρησιμοποιείται για την ανάγνωση μόνο δεδομένων που έχουν εισαχθεί ή τροποποιηθεί από την τελευταία φορά που διαβάστηκε ο πίνακας Delta.
Ε9. Εξηγήστε τη σημασία των λειτουργιών παρτίδας και ροής στη λίμνη Δέλτα.
Μπορούμε να εκτελέσουμε λειτουργίες δέσμης και ροής με το Delta Lake σε μια ενιαία απλοποιημένη αρχιτεκτονική, αποφεύγοντας πολύπλοκα, περιττά συστήματα και λειτουργικές προκλήσεις. Στη λίμνη Delta, ένα τραπέζι είναι ταυτόχρονα πίνακας παρτίδας και πηγή ροής.
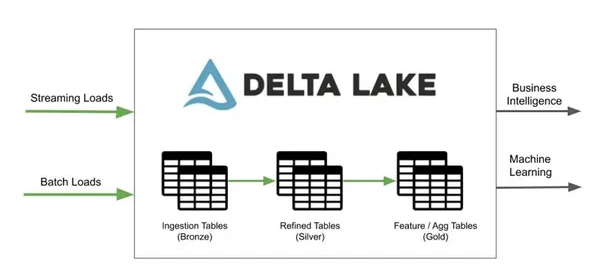
Πηγή: hevodata.com
Όσον αφορά τη σημασία, τα διαδραστικά ερωτήματα, η απορρόφηση δεδομένων ροής και η δέσμη ιστορικών συμπληρωμάτων λειτουργούν ασυνήθιστα και ενσωματώνονται άμεσα με τη Δομημένη ροή Spark.
Q10. Πώς μπορούμε να φορτώσουμε δεδομένα σε έναν πίνακα από άλλο σύστημα αρχείων στο Delta Lake;
Για να εκτελέσετε τη λειτουργία φόρτωσης, το Delta Lake υποστηρίζει μια διαδικασία που ονομάζεται "upserts". Φορτώνει δεδομένα σε έναν πίνακα Delta από άλλο υπάρχον σύστημα αρχείων. Σε αυτή τη διαδικασία, πρώτα ελέγχουμε εάν μια σειρά με το ίδιο πρωτεύον κλειδί υπάρχει ήδη στον πίνακα ή όχι. Εάν η σειρά υπάρχει, ενημερώνεται με τα νέα δεδομένα. Διαφορετικά, εισάγεται στον πίνακα.
Συμπέρασμα
Αυτό το ιστολόγιο καλύπτει μερικές από τις συχνές ερωτήσεις συνέντευξης Delta Lake που θα μπορούσαν να τεθούν στις συνεντεύξεις της επιστήμης δεδομένων και στις συνεντεύξεις προγραμματιστών μεγάλων δεδομένων. Χρησιμοποιώντας αυτές τις ερωτήσεις συνέντευξης στη λίμνη δέλτα ως αναφορά, μπορείτε να κατανοήσετε καλύτερα τις έννοιες και να διαμορφώσετε αποτελεσματικές απαντήσεις για τις επερχόμενες συνεντεύξεις. Τα βασικά συμπεράσματα από αυτό το ιστολόγιο Delta Lake είναι:
- Το Delta Lake είναι ένα επίπεδο αποθήκευσης ανοιχτού κώδικα συμβατό με ACID που βρίσκεται πάνω από την υπάρχουσα υποδομή αποθήκευσης δεδομένων μας.
- Η Delta Lake μας διευκολύνει με τη διαχείριση τεράστιων δεδομένων και τη διατήρηση της συνέπειας δεδομένων σε πολλαπλές περιόδους λειτουργίας Spark.
- Το Delta Lake είναι καλύτερο από διάφορα επίπεδα αποθήκευσης συναλλαγών όσον αφορά
- Συζητήσαμε τα upserts, έναν τρόπο φόρτωσης δεδομένων στους πίνακες Data Lake.
- Σε αυτό το ιστολόγιο, συζητήσαμε επίσης τα στοιχεία της Delta Lake, συμπεριλαμβανομένων του πίνακα, του αρχείου καταγραφής και της κρυφής μνήμης Delta.
Τα μέσα που εμφανίζονται σε αυτό το άρθρο δεν ανήκουν στο Analytics Vidhya και χρησιμοποιούνται κατά την κρίση του συγγραφέα.
Σχετικά:
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- Platoblockchain. Web3 Metaverse Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- πηγή: https://www.analyticsvidhya.com/blog/2023/02/ace-your-interview-with-top-10-interview-questions-on-delta-lake/
- 10
- 11
- a
- ικανότητα
- Ικανός
- πρόσβαση
- απέναντι
- Ενέργειες
- δραστηριοτήτων
- Μετά το
- Όλα
- ήδη
- πάντοτε
- analytics
- Ανάλυση Vidhya
- και
- Άλλος
- απαντήσεις
- Apache
- Apache Spark
- εφαρμογές
- αρχιτεκτονική
- γύρω
- άρθρο
- αυτόματη
- αυτομάτως
- διαθέσιμος
- αποφεύγοντας
- πίσω
- βάση
- επειδή
- είναι
- οφέλη
- Καλύτερα
- Μεγάλος
- Big Data
- Blog
- blogathon
- Κουτί
- ευρύτερη
- χτισμένο
- επιχείρηση
- επιχειρηματικής ευφυΐας
- κρύπτη
- που ονομάζεται
- προσεκτικά
- περίπτωση
- κεντρικός
- προκλήσεις
- Αλλαγές
- έλεγχος
- επιλογή
- συνδυασμός
- Ελάτε
- ερχομός
- δεσμεύεται
- Κοινός
- ολοκληρώνοντας
- συγκρότημα
- υποχωρητικός
- εξαρτήματα
- περιεκτικός
- έννοιες
- συμπέρασμα
- κατάσταση
- περιεχόμενα
- ελέγχους
- Διαφθορά
- θα μπορούσε να
- κάλυψη
- Καλύπτει
- Ρεύμα
- καθημερινά
- ημερομηνία
- Λίμνη δεδομένων
- επεξεργασία δεδομένων
- επιστημονικά δεδομένα
- επιστήμονας δεδομένων
- την ασφάλεια των δεδομένων
- αποθήκευση δεδομένων
- Βάσεις δεδομένων
- Δέλτα
- απαιτήσεις
- Σε συνάρτηση
- Υπηρεσίες
- Παρά
- Εργολάβος
- διαφέρω
- διαφορετικές
- κατευθείαν
- διακριτικότητα
- συζητήσουν
- συζήτηση
- αντοχή
- εύκολα
- οικοσύστημα
- Αποτελεσματικός
- αποτελεσματικά
- αποδοτικότητα
- αποτελεσματικός
- είτε
- δίνει τη δυνατότητα
- επιβολή
- Κινητήρας
- Ενισχύει
- αρκετά
- εξασφαλίζω
- ενθουσιώδες
- Ολόκληρος
- Εποχή
- υφιστάμενα
- υπάρχει
- Εξηγήστε
- διευκολύνει
- ΦΗΜΗ
- γρηγορότερα
- Χαρακτηριστικό
- Αρχεία
- Αρχεία
- Όνομα
- μορφή
- Πλαίσιο
- συχνά
- από
- πλήρη
- Κέρδος
- παίρνω
- δεδομένου
- καλός
- διακυβέρνησης
- καθοδηγήσει
- υλικού
- βοήθεια
- εδώ
- Ψηλά
- ιστορικό
- Πως
- HTTPS
- τεράστιος
- εισαγωγή
- σημαντικό
- εισαγωγή
- βελτιώνει
- in
- Συμπεριλαμβανομένου
- Υποδομή
- ενσωματώσει
- Νοημοσύνη
- διαδραστικό
- συνέντευξη
- ερωτήσεις συνέντευξης
- συνεντεύξεις
- Εισαγωγή
- απομόνωση
- IT
- Διατήρηση
- Κλειδί
- γνώση
- λίμνη
- μεγάλης κλίμακας
- Επίθετο
- στρώμα
- στρώματα
- ΜΑΘΑΊΝΩ
- φορτίο
- φορτωτής
- φόρτωση
- φορτία
- που
- Κυρίως
- κάνω
- διαχείριση
- διαχείριση
- διαχείριση
- Εικόνες / Βίντεο
- πηγαίνω
- ML
- Τρόπος
- τρόπων
- τροποποιήσεις
- τροποποιημένο
- Παρακολούθηση
- περισσότερο
- πιο αποτελεσματικό
- πλέον
- Δημοφιλέστερα
- πολλαπλούς
- ντόπιος
- nav
- απαραίτητος
- Νέα
- κανονικός
- προσφορές
- ONE
- ανοικτού κώδικα
- λειτουργία
- επιχειρήσεων
- λειτουργίες
- ΑΛΛΑ
- αλλιώς
- Διακοπές
- Αποτέλεσμα
- ανήκει
- μέρος
- μονοπάτι
- εκτελέσει
- επίδοση
- εκτέλεση
- Πλάτων
- Πληροφορία δεδομένων Plato
- Πλάτωνα δεδομένα
- Δημοφιλής
- δύναμη
- προετοιμασία
- πρωταρχικός
- διαδικασια μας
- μεταποίηση
- παραγωγή
- ιδιότητες
- παρέχει
- χορήγηση
- δημοσιεύθηκε
- βάζω
- Q1
- Q2
- Q3
- Ερωτήσεις
- Διάβασε
- αναγνώστες
- Ανάγνωση
- σχέση
- αξιοπιστία
- αξιόπιστος
- παραμένουν
- Απάντηση
- Αποτελέσματα
- Ρόλος
- Ρολό
- Έλασης
- ΣΕΙΡΑ
- τρέξιμο
- ένα ασφαλές
- ίδιο
- Απεριόριστες δυνατότητες
- σάρωση
- Επιστήμη
- Επιστήμονας
- ασφάλεια
- συνεδρίες
- διάφοροι
- παρουσιάζεται
- σημασία
- απλοποιημένη
- αφού
- ενιαίας
- Λύει
- μερικοί
- Πηγή
- Σπινθήρας
- SQL
- ξεκίνησε
- stats
- χώρος στο δίσκο
- κατάστημα
- Αποθηκεύστε τα δεδομένα
- καταστήματα
- ροής
- δομημένος
- τέτοιος
- υποστήριξη
- Υποστηρίζει
- σύστημα
- συστήματα
- τραπέζι
- Takeaways
- Τεχνικός
- όροι
- Η
- Η συγχώνευση
- τους
- χιλιάδες
- τρία
- ώρα
- ταξίδι στο χρόνο
- προς την
- σήμερα
- εργαλείο
- εργαλεία
- κορυφή
- Top 10
- τροχιά
- συναλλαγή
- συναλλακτική
- Συναλλαγές
- Μεταμόρφωση
- ταξίδι
- αληθής
- καταλαβαίνω
- κατανόηση
- ενιαία
- ασταμάτητη.
- ανερχόμενος
- Ενημέρωση
- ενημερώθηκε
- us
- χρήση
- περίπτωση χρήσης
- Χρήστες
- διάφορα
- εκδοχή
- Δες
- τόμος
- Τι
- αν
- Ποιό
- θα
- Εργασία
- επεξεργάζομαι
- χρόνια
- Σας
- zephyrnet