Οι οργανισμοί έχουν επιλέξει να δημιουργήσουν λίμνες δεδομένων πάνω από Απλή υπηρεσία αποθήκευσης Amazon (Amazon S3) για πολλά χρόνια. Μια λίμνη δεδομένων είναι η πιο δημοφιλής επιλογή για τους οργανισμούς να αποθηκεύουν όλα τα οργανωτικά τους δεδομένα που δημιουργούνται από διαφορετικές ομάδες, σε τομείς επιχειρήσεων, από όλες τις διαφορετικές μορφές, ακόμη και σε όλη την ιστορία. Σύμφωνα με μια μελέτη, η μέση εταιρεία βλέπει τον όγκο των δεδομένων της να αυξάνεται με ρυθμό που υπερβαίνει το 50% ετησίως, συνήθως διαχειριζόμενος κατά μέσο όρο 33 μοναδικές πηγές δεδομένων για ανάλυση.
Οι ομάδες συχνά προσπαθούν να αναπαράγουν χιλιάδες εργασίες από σχεσιακές βάσεις δεδομένων με το ίδιο μοτίβο εξαγωγής, μετασχηματισμού και φόρτωσης (ETL). Καταβάλλεται μεγάλη προσπάθεια για τη διατήρηση των καταστάσεων εργασίας και τον προγραμματισμό αυτών των μεμονωμένων εργασιών. Αυτή η προσέγγιση βοηθά τις ομάδες να προσθέτουν πίνακες με λίγες αλλαγές και επίσης διατηρεί την κατάσταση της εργασίας με ελάχιστη προσπάθεια. Αυτό μπορεί να οδηγήσει σε τεράστια βελτίωση στο χρονοδιάγραμμα ανάπτυξης και στην παρακολούθηση των θέσεων εργασίας με ευκολία.
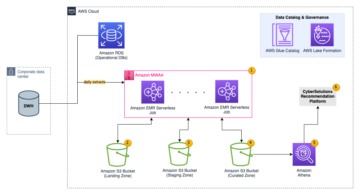
Σε αυτήν την ανάρτηση, σας δείχνουμε πώς να αναπαράγετε εύκολα όλες τις αποθήκες σχεσιακών δεδομένων σας σε μια λίμνη δεδομένων συναλλαγών με αυτοματοποιημένο τρόπο με μία μόνο εργασία ETL χρησιμοποιώντας το Apache Iceberg και Κόλλα AWS.
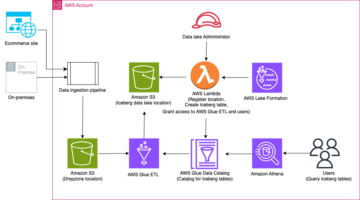
Αρχιτεκτονική λύσεων
Οι λίμνες δεδομένων είναι συνήθως οργανωμένα χρησιμοποιώντας χωριστούς κάδους S3 για τρία επίπεδα δεδομένων: το ακατέργαστο επίπεδο που περιέχει δεδομένα στην αρχική του μορφή, το επίπεδο σταδίου που περιέχει ενδιάμεσα επεξεργασμένα δεδομένα βελτιστοποιημένα για κατανάλωση και το επίπεδο ανάλυσης που περιέχει συγκεντρωτικά δεδομένα για συγκεκριμένες περιπτώσεις χρήσης. Στο ακατέργαστο επίπεδο, οι πίνακες οργανώνονται συνήθως με βάση τις πηγές δεδομένων τους, ενώ οι πίνακες στο επίπεδο στάδιο οργανώνονται με βάση τους επιχειρηματικούς τομείς στους οποίους ανήκουν.
Αυτή η ανάρτηση παρέχει ένα AWS CloudFormation πρότυπο που αναπτύσσει μια εργασία AWS Glue που διαβάζει μια διαδρομή Amazon S3 για μια πηγή δεδομένων του ακατέργαστου στρώματος λίμνης δεδομένων και απορροφά τα δεδομένα σε πίνακες Apache Iceberg στο επίπεδο σκηνής χρησιμοποιώντας Υποστήριξη AWS Glue για πλαίσια δεδομένων λίμνης. Η εργασία αναμένει ότι οι πίνακες στο ακατέργαστο επίπεδο θα είναι δομημένοι με τον τρόπο Υπηρεσία μετεγκατάστασης βάσης δεδομένων AWS (AWS DMS) τα απορροφά: σχήμα, μετά πίνακας και μετά αρχεία δεδομένων.
Αυτή η λύση χρησιμοποιεί Κατάστημα παραμέτρων AWS Systems Manager για διαμόρφωση πίνακα. Θα πρέπει να τροποποιήσετε αυτήν την παράμετρο προσδιορίζοντας τους πίνακες που θέλετε να επεξεργαστείτε και τον τρόπο, συμπεριλαμβανομένων πληροφοριών όπως το πρωτεύον κλειδί, τα διαμερίσματα και τον σχετιζόμενο επιχειρηματικό τομέα. Η εργασία χρησιμοποιεί αυτές τις πληροφορίες για να δημιουργήσει αυτόματα μια βάση δεδομένων (αν δεν υπάρχει ήδη) για κάθε επιχειρηματικό τομέα, να δημιουργήσει τους πίνακες Iceberg και να εκτελέσει τη φόρτωση δεδομένων.
Τέλος, μπορούμε να χρησιμοποιήσουμε Αμαζόν Αθηνά για να ρωτήσετε τα δεδομένα στους πίνακες Iceberg.
Το παρακάτω διάγραμμα απεικονίζει αυτή την αρχιτεκτονική.

Αυτή η υλοποίηση έχει τις ακόλουθες εκτιμήσεις:
- Όλοι οι πίνακες από την προέλευση δεδομένων πρέπει να έχουν ένα πρωτεύον κλειδί για αναπαραγωγή χρησιμοποιώντας αυτήν τη λύση. Το πρωτεύον κλειδί μπορεί να είναι μία στήλη ή ένα σύνθετο κλειδί με περισσότερες από μία στήλες.
- Εάν η λίμνη δεδομένων περιέχει πίνακες που δεν χρειάζονται προσθήκες ή δεν έχουν πρωτεύον κλειδί, μπορείτε να τους εξαιρέσετε από τη διαμόρφωση παραμέτρων και να εφαρμόσετε παραδοσιακές διαδικασίες ETL για να τους ενσωματώσετε στη λίμνη δεδομένων. Αυτό είναι έξω από το πεδίο αυτής της ανάρτησης.
- Εάν υπάρχουν πρόσθετες πηγές δεδομένων που πρέπει να απορροφηθούν, μπορείτε να αναπτύξετε πολλές στοίβες CloudFormation, μία για τη διαχείριση κάθε προέλευσης δεδομένων.
- Η εργασία AWS Glue έχει σχεδιαστεί για να επεξεργάζεται δεδομένα σε δύο φάσεις: το αρχικό φορτίο που εκτελείται αφού το AWS DMS ολοκληρώσει την εργασία πλήρους φόρτωσης και το αυξητικό φορτίο που εκτελείται σε ένα χρονοδιάγραμμα που εφαρμόζει αρχεία καταγραφής δεδομένων αλλαγών (CDC) που έχουν καταγραφεί από το AWS DMS. Η σταδιακή επεξεργασία εκτελείται χρησιμοποιώντας ένα Σελιδοδείκτης εργασίας κόλλας AWS.
Υπάρχουν εννέα βήματα για να ολοκληρώσετε αυτό το σεμινάριο:
- Ρυθμίστε ένα τελικό σημείο πηγής για AWS DMS.
- Αναπτύξτε τη λύση χρησιμοποιώντας το AWS CloudFormation.
- Ελέγξτε την εργασία αναπαραγωγής AWS DMS.
- Προαιρετικά, προσθέστε δικαιώματα για κρυπτογράφηση και αποκρυπτογράφηση ή Σχηματισμός Λίμνης AWS.
- Ελέγξτε τη διαμόρφωση του πίνακα στο Parameter Store.
- Εκτελέστε αρχική φόρτωση δεδομένων.
- Εκτελέστε σταδιακή φόρτωση δεδομένων.
- Παρακολουθήστε την κατάποση του τραπεζιού.
- Προγραμματίστε τη σταδιακή φόρτωση δεδομένων παρτίδας.
Προϋποθέσεις
Πριν ξεκινήσετε αυτό το σεμινάριο, θα πρέπει να είστε ήδη εξοικειωμένοι με το Iceberg. Εάν δεν είστε, μπορείτε να ξεκινήσετε αναπαράγοντας έναν μόνο πίνακα ακολουθώντας τις οδηγίες στο Εφαρμόστε ένα UPSERT που βασίζεται σε CDC σε μια λίμνη δεδομένων χρησιμοποιώντας Apache Iceberg και AWS Glue. Επιπλέον, ρυθμίστε τα εξής:
Ρυθμίστε ένα τελικό σημείο πηγής για AWS DMS
Πριν δημιουργήσουμε την εργασία AWS DMS, πρέπει να ρυθμίσουμε ένα τελικό σημείο προέλευσης για σύνδεση στη βάση δεδομένων προέλευσης:
- Στην κονσόλα AWS DMS, επιλέξτε Τελικά σημεία στο παράθυρο πλοήγησης.
- Επιλέξτε Δημιουργία τελικού σημείου.
- Εάν η βάση δεδομένων σας εκτελείται σε Amazon RDS, επιλέξτε Επιλέξτε την παρουσία RDS DB, μετά επιλέξτε την παρουσία από τη λίστα. Διαφορετικά, επιλέξτε τη μηχανή προέλευσης και δώστε τις πληροφορίες σύνδεσης είτε μέσω Διευθυντής μυστικών AWS ή χειροκίνητα.
- Για Αναγνωριστικό τελικού σημείου, πληκτρολογήστε ένα όνομα για το τελικό σημείο. για παράδειγμα, source-postgresql.
- Επιλέξτε Δημιουργία τελικού σημείου.
Αναπτύξτε τη λύση χρησιμοποιώντας το AWS CloudFormation
Δημιουργήστε μια στοίβα CloudFormation χρησιμοποιώντας το παρεχόμενο πρότυπο. Ολοκληρώστε τα παρακάτω βήματα:
- Επιλέξτε Εκκίνηση στοίβας:

- Επιλέξτε Επόμενο.
- Δώστε ένα όνομα στοίβας, όπως π.χ
transactionaldl-postgresql. - Εισαγάγετε τις απαιτούμενες παραμέτρους:
- DMSS3EndpointIAMRoleARN – Ο ρόλος IAM ARN για το AWS DMS για την εγγραφή δεδομένων στο Amazon S3.
- ReplicationInstanceArn – Το παράδειγμα αναπαραγωγής AWS DMS ARN.
- S3BucketStage – Το όνομα του υπάρχοντος κάδου που χρησιμοποιείται για το επίπεδο σταδίου της λίμνης δεδομένων.
- S3BucketGlue – Το όνομα του υπάρχοντος κάδου S3 για την αποθήκευση σεναρίων AWS Glue.
- S3BucketRaw – Το όνομα του υπάρχοντος κάδου που χρησιμοποιείται για το ακατέργαστο στρώμα της λίμνης δεδομένων.
- SourceEndpointArn – Το τελικό σημείο AWS DMS ARN που δημιουργήσατε νωρίτερα.
- Όνομα πηγής – Το αυθαίρετο αναγνωριστικό της πηγής δεδομένων προς αναπαραγωγή (για παράδειγμα,
postgres). Αυτό χρησιμοποιείται για τον καθορισμό της διαδρομής S3 της λίμνης δεδομένων (ακατέργαστο στρώμα) όπου θα αποθηκευτούν τα δεδομένα.
- Μην τροποποιείτε τις ακόλουθες παραμέτρους:
- SourceS3BucketBlog – Το όνομα του κάδου όπου είναι αποθηκευμένο το παρεχόμενο σενάριο AWS Glue.
- SourceS3BucketPrefix – Το όνομα του προθέματος κάδου όπου είναι αποθηκευμένο το παρεχόμενο σενάριο AWS Glue.
- Επιλέξτε Επόμενο εις διπλούν.
- Αγορά Αναγνωρίζω ότι το AWS CloudFormation ενδέχεται να δημιουργήσει πόρους IAM με προσαρμοσμένα ονόματα.
- Επιλέξτε Δημιουργία στοίβας.
Μετά από περίπου 5 λεπτά, αναπτύσσεται η στοίβα CloudFormation.
Ελέγξτε την εργασία αναπαραγωγής AWS DMS
Η ανάπτυξη του AWS CloudFormation δημιούργησε ένα τελικό σημείο στόχου AWS DMS για εσάς. Λόγω δύο συγκεκριμένων ρυθμίσεων τελικού σημείου, τα δεδομένα θα απορροφηθούν όπως τα χρειαζόμαστε στο Amazon S3.
- Στην κονσόλα AWS DMS, επιλέξτε Τελικά σημεία στο παράθυρο πλοήγησης.
- Αναζητήστε και επιλέξτε το τελικό σημείο με το οποίο αρχίζει
dmsIcebergs3endpoint. - Ελέγξτε τις ρυθμίσεις τελικού σημείου:
DataFormatορίζεται ωςparquet.TimestampColumnNameθα προσθέσει τη στήληlast_update_timeμε την ημερομηνία δημιουργίας των εγγραφών στο Amazon S3.

Η ανάπτυξη δημιουργεί επίσης μια εργασία αναπαραγωγής AWS DMS που ξεκινά με dmsicebergtask.
- Επιλέξτε Εργασίες αναπαραγωγής στο παράθυρο πλοήγησης και αναζητήστε την εργασία.
Θα δείτε ότι το Τύπος εργασίας επισημαίνεται ως Πλήρες φορτίο, συνεχής αναπαραγωγή. Το AWS DMS θα εκτελέσει μια αρχική πλήρη φόρτωση υπαρχόντων δεδομένων και, στη συνέχεια, θα δημιουργήσει αυξητικά αρχεία με αλλαγές που θα πραγματοποιηθούν στη βάση δεδομένων προέλευσης.
Στις Κανόνες χαρτογράφησης καρτέλα, υπάρχουν δύο τύποι κανόνων:
- Ένας κανόνας επιλογής με το όνομα του σχήματος πηγής και των πινάκων που θα απορροφηθούν από τη βάση δεδομένων προέλευσης. Από προεπιλογή, χρησιμοποιεί το δείγμα βάσης δεδομένων που παρέχεται στα προαπαιτούμενα,
dms_sampleκαι όλοι οι πίνακες με τη λέξη-κλειδί %. - Δύο κανόνες μετασχηματισμού που περιλαμβάνουν στα αρχεία προορισμού στο Amazon S3 το όνομα του σχήματος και το όνομα του πίνακα ως στήλες. Αυτό χρησιμοποιείται από την εργασία AWS Glue για να γνωρίζουμε σε ποιους πίνακες αντιστοιχούν τα αρχεία στη λίμνη δεδομένων.
Για να μάθετε περισσότερα σχετικά με το πώς να το προσαρμόσετε για τις δικές σας πηγές δεδομένων, ανατρέξτε στο Κανόνες και ενέργειες επιλογής.

Ας αλλάξουμε ορισμένες διαμορφώσεις για να ολοκληρώσουμε την προετοιμασία της εργασίας μας.
- Στις Δράσεις μενού, επιλέξτε Τροποποίηση.
- Στο Ρυθμίσεις εργασιών ενότητα, κάτω από Σταματήστε την εργασία μετά την ολοκλήρωση της πλήρους φόρτωσης, επιλέξτε Διακοπή μετά την εφαρμογή των αλλαγών στην προσωρινή μνήμη.
Με αυτόν τον τρόπο, μπορούμε να ελέγξουμε την αρχική φόρτωση και την αυξητική δημιουργία αρχείων ως δύο διαφορετικά βήματα. Χρησιμοποιούμε αυτήν την προσέγγιση δύο βημάτων για να εκτελέσουμε την εργασία κόλλας AWS μία φορά σε κάθε βήμα.
- Κάτω από Μητρώα εργασιών, επιλέξτε Ενεργοποιήστε τα αρχεία καταγραφής CloudWatch.
- Επιλέξτε Αποθήκευση.
- Περιμένετε περίπου 1 λεπτό για να εμφανιστεί ως η κατάσταση της εργασίας μετεγκατάστασης βάσης δεδομένων Έτοιμος.
Προσθέστε δικαιώματα για κρυπτογράφηση και αποκρυπτογράφηση ή Lake Formation
Προαιρετικά, μπορείτε να προσθέσετε δικαιώματα για κρυπτογράφηση και αποκρυπτογράφηση ή Lake Formation.
Προσθέστε δικαιώματα κρυπτογράφησης και αποκρυπτογράφησης
Εάν οι κάδοι S3 που χρησιμοποιούνται για τα επίπεδα ακατέργαστων και σταδίων είναι κρυπτογραφημένοι χρησιμοποιώντας Υπηρεσία διαχείρισης κλειδιών AWS Κλειδιά διαχείρισης πελατών (AWS KMS), πρέπει να προσθέσετε δικαιώματα για να επιτρέψετε στην εργασία AWS Glue να έχει πρόσβαση στα δεδομένα:
Προσθήκη αδειών Lake Formation
Εάν διαχειρίζεστε δικαιώματα χρησιμοποιώντας το Lake Formation, πρέπει να επιτρέψετε την εργασία σας στο AWS Glue να δημιουργήσει τις βάσεις δεδομένων και τους πίνακες του τομέα σας μέσω του ρόλου IAM GlueJobRole.
- Παραχωρήστε δικαιώματα για τη δημιουργία βάσεων δεδομένων (για οδηγίες, ανατρέξτε στο Δημιουργία Βάσης Δεδομένων).
- Παραχωρήστε SUPER άδειες στο
defaultβάση δεδομένων. - Εκχώρηση αδειών τοποθεσίας δεδομένων.
- Εάν δημιουργείτε βάσεις δεδομένων με μη αυτόματο τρόπο, παραχωρήστε δικαιώματα σε όλες τις βάσεις δεδομένων για τη δημιουργία πινάκων. Αναφέρομαι σε Εκχώρηση δικαιωμάτων πίνακα χρησιμοποιώντας την κονσόλα Lake Formation και την επώνυμη μέθοδο πόρων or Εκχώρηση δικαιωμάτων καταλόγου δεδομένων χρησιμοποιώντας τη μέθοδο LF-TBAC ανάλογα με την περίπτωση χρήσης σας.
Αφού ολοκληρώσετε το επόμενο βήμα της εκτέλεσης της αρχικής φόρτωσης δεδομένων, βεβαιωθείτε ότι έχετε προσθέσει επίσης δικαιώματα για τους καταναλωτές να υποβάλλουν ερωτήματα στους πίνακες. Ο ρόλος εργασίας θα γίνει ο κάτοχος όλων των πινάκων που δημιουργήθηκαν και ο διαχειριστής της λίμνης δεδομένων μπορεί στη συνέχεια να πραγματοποιήσει επιχορηγήσεις σε επιπλέον χρήστες.
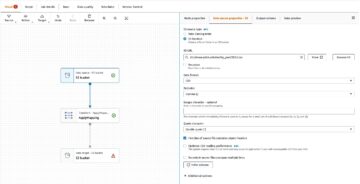
Ελέγξτε τη διαμόρφωση του πίνακα στο Parameter Store
Η εργασία AWS Glue που εκτελεί την απορρόφηση δεδομένων σε πίνακες Iceberg χρησιμοποιεί την προδιαγραφή πίνακα που παρέχεται στο Parameter Store. Ολοκληρώστε τα παρακάτω βήματα για να ελέγξετε το χώρο αποθήκευσης παραμέτρων που διαμορφώθηκε αυτόματα για εσάς. Εάν χρειάζεται, τροποποιήστε ανάλογα με τις δικές σας ανάγκες.
- Στην κονσόλα Parameter Store, επιλέξτε Οι παράμετροι μου στο παράθυρο πλοήγησης.
Η στοίβα CloudFormation δημιούργησε δύο παραμέτρους:
iceberg-configγια διαμορφώσεις εργασιώνiceberg-tablesγια διαμόρφωση πίνακα
- Επιλέξτε την παράμετρο παγόβουνο-τραπεζάκια.
Η δομή JSON περιέχει πληροφορίες που χρησιμοποιεί το AWS Glue για την ανάγνωση δεδομένων και την εγγραφή των πινάκων Iceberg στον τομέα προορισμού:
- Ένα αντικείμενο ανά τραπέζι – Το όνομα του αντικειμένου δημιουργείται χρησιμοποιώντας το όνομα του σχήματος, μια τελεία και το όνομα του πίνακα. για παράδειγμα,
schema.table. - πρωτεύων κλειδί – Αυτό θα πρέπει να προσδιορίζεται για κάθε πίνακα πηγής. Μπορείτε να παρέχετε μια μονή στήλη ή μια λίστα στηλών διαχωρισμένη με κόμματα (χωρίς κενά).
- partitionCols – Αυτό προαιρετικά χωρίζει στήλες για πίνακες προορισμού. Εάν δεν θέλετε να δημιουργήσετε πίνακες με διαμερίσματα, δώστε μια κενή συμβολοσειρά. Διαφορετικά, παρέχετε μια μονή στήλη ή μια λίστα στηλών διαχωρισμένη με κόμματα που θα χρησιμοποιηθούν (χωρίς κενά).
- Εάν θέλετε να χρησιμοποιήσετε τη δική σας πηγή δεδομένων, χρησιμοποιήστε τον ακόλουθο κώδικα JSON και αντικαταστήστε το κείμενο με ΚΕΦΑΛΑΙΑ από το πρότυπο που παρέχεται. Εάν χρησιμοποιείτε το δείγμα προέλευσης δεδομένων που παρέχεται, διατηρήστε τις προεπιλεγμένες ρυθμίσεις:
{ "SCHEMA_NAME.TABLE_NAME_1": { "primaryKey": "ONLY_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "" }, "SCHEMA_NAME.TABLE_NAME_2": { "primaryKey": "FIRST_PRIMARY_KEY,SECOND_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "PARTITION_COLUMN_ONE,PARTITION_COLUMN_TWO" }
}- Επιλέξτε Αποθηκεύστε τις αλλαγές.
Εκτελέστε αρχική φόρτωση δεδομένων
Τώρα που έχει ολοκληρωθεί η απαιτούμενη διαμόρφωση, λαμβάνουμε τα αρχικά δεδομένα. Αυτό το βήμα περιλαμβάνει τρία μέρη: εισαγωγή των δεδομένων από τη σχεσιακή βάση δεδομένων πηγής στο ακατέργαστο στρώμα της λίμνης δεδομένων, δημιουργία των πινάκων Iceberg στο επίπεδο της λίμνης δεδομένων και επαλήθευση αποτελεσμάτων χρησιμοποιώντας το Athena.
Απορρόφηση δεδομένων στο ακατέργαστο στρώμα της λίμνης δεδομένων
Για να απορροφήσετε δεδομένα από την πηγή σχεσιακών δεδομένων (PostgreSQL εάν χρησιμοποιείτε το παρεχόμενο δείγμα) στη λίμνη δεδομένων συναλλαγών μας χρησιμοποιώντας το Iceberg, ολοκληρώστε τα ακόλουθα βήματα:
- Στην κονσόλα AWS DMS, επιλέξτε Εργασίες μετεγκατάστασης βάσης δεδομένων στο παράθυρο πλοήγησης.
- Επιλέξτε την εργασία αναπαραγωγής που δημιουργήσατε και στο Δράσεις μενού, επιλέξτε Επανεκκίνηση/Συνέχιση.
- Περιμένετε περίπου 5 λεπτά για να ολοκληρωθεί η εργασία αναπαραγωγής. Μπορείτε να παρακολουθείτε τους πίνακες που λαμβάνονται στο Σε Πραγματικό Χρόνο καρτέλα της εργασίας αναπαραγωγής.

Μετά από μερικά λεπτά, η εργασία τελειώνει με το μήνυμα Ολοκληρώθηκε το πλήρες φορτίο.
- Στην κονσόλα Amazon S3, επιλέξτε τον κάδο που ορίσατε ως ακατέργαστο επίπεδο.
Κάτω από το πρόθεμα S3 που ορίζεται στο AWS DMS (για παράδειγμα, postgres), θα πρέπει να δείτε μια ιεραρχία φακέλων με την ακόλουθη δομή:
- Schema
- Όνομα πίνακα
LOAD00000001.parquetLOAD0000000N.parquet
- Όνομα πίνακα

Εάν ο κάδος S3 σας είναι άδειος, ελέγξτε Αντιμετώπιση προβλημάτων εργασιών μετεγκατάστασης στην υπηρεσία μετεγκατάστασης βάσεων δεδομένων AWS πριν εκτελέσετε την εργασία κόλλας AWS.
Δημιουργία και απορρόφηση δεδομένων σε πίνακες Iceberg
Πριν εκτελέσετε την εργασία, ας πλοηγηθούμε στο σενάριο της εργασίας AWS Glue που παρέχεται ως μέρος της στοίβας CloudFormation για να κατανοήσουμε τη συμπεριφορά της.
- Στην κονσόλα AWS Glue Studio, επιλέξτε Θέσεις εργασίας στο παράθυρο πλοήγησης.
- Αναζητήστε τη δουλειά που ξεκινάει με
IcebergJob-και ένα επίθημα του ονόματος της στοίβας CloudFormation (για παράδειγμα,IcebergJob-transactionaldl-postgresql). - Επιλέξτε τη δουλειά.

Το σενάριο εργασίας λαμβάνει τη διαμόρφωση που χρειάζεται από το Parameter Store. Η λειτουργία getConfigFromSSM() επιστρέφει διαμορφώσεις που σχετίζονται με εργασίες, όπως κουβάδες πηγής και προορισμού, από όπου πρέπει να διαβαστούν και να γραφτούν τα δεδομένα. Η μεταβλητή ssmparam_table_values περιέχουν πληροφορίες που σχετίζονται με τον πίνακα, όπως τον τομέα δεδομένων, το όνομα του πίνακα, τις στήλες διαμερίσματος και το πρωτεύον κλειδί των πινάκων που πρέπει να απορροφηθούν. Δείτε τον παρακάτω κώδικα Python:
# Main application
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'stackName'])
SSM_PARAMETER_NAME = f"{args['stackName']}-iceberg-config"
SSM_TABLE_PARAMETER_NAME = f"{args['stackName']}-iceberg-tables" # Parameters for job
rawS3BucketName, rawBucketPrefix, stageS3BucketName, warehouse_path = getConfigFromSSM(SSM_PARAMETER_NAME)
ssm_param_table_values = json.loads(ssmClient.get_parameter(Name = SSM_TABLE_PARAMETER_NAME)['Parameter']['Value'])
dropColumnList = ['db','table_name', 'schema_name','Op', 'last_update_time', 'max_op_date']Το σενάριο χρησιμοποιεί ένα αυθαίρετο όνομα καταλόγου για το Iceberg που ορίζεται ως my_catalog. Αυτό υλοποιείται στον κατάλογο δεδομένων AWS Glue χρησιμοποιώντας διαμορφώσεις Spark, επομένως μια λειτουργία SQL που οδηγεί στο my_catalog θα εφαρμοστεί στον κατάλογο δεδομένων. Δείτε τον παρακάτω κώδικα:
catalog_name = 'my_catalog'
errored_table_list = [] # Iceberg configuration
spark = SparkSession.builder .config('spark.sql.warehouse.dir', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') .config(f'spark.sql.catalog.{catalog_name}.warehouse', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}.catalog-impl', 'org.apache.iceberg.aws.glue.GlueCatalog') .config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.aws.s3.S3FileIO') .config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') .getOrCreate()
Το σενάριο επαναλαμβάνεται πάνω από τους πίνακες που ορίζονται στο Parameter Store και εκτελεί τη λογική για να ανιχνεύσει εάν ο πίνακας υπάρχει και εάν τα εισερχόμενα δεδομένα είναι ένα αρχικό φορτίο ή ένα upsert:
# Iteration over tables stored on Parameter Store
for key in ssm_param_table_values: # Get table data isTableExists = False schemaName, tableName = key.split('.') logger.info(f'Processing table : {tableName}')Η initialLoadRecordsSparkSQL() Η συνάρτηση φορτώνει τα αρχικά δεδομένα όταν δεν υπάρχει στήλη λειτουργίας στα αρχεία S3. Το AWS DMS προσθέτει αυτήν τη στήλη μόνο στα αρχεία δεδομένων Parquet που παράγονται από τη συνεχή αναπαραγωγή (CDC). Η φόρτωση δεδομένων πραγματοποιείται χρησιμοποιώντας την εντολή INSERT INTO με το SparkSQL. Δείτε τον παρακάτω κώδικα:
sqltemp = Template(""" INSERT INTO $catalog_name.$dbName.$tableName ($insertTableColumnList) SELECT $insertTableColumnList FROM insertTable $partitionStrSQL """)
SQLQUERY = sqltemp.substitute( catalog_name = catalog_name, dbName = dbName, tableName = tableName, insertTableColumnList = insertTableColumnList[ : -1], partitionStrSQL = partitionStrSQL) logger.info(f'****SQL QUERY IS : {SQLQUERY}')
spark.sql(SQLQUERY)
Τώρα εκτελούμε την εργασία AWS Glue για να απορροφήσουμε τα αρχικά δεδομένα στους πίνακες Iceberg. Η στοίβα CloudFormation προσθέτει το --datalake-formats παράμετρο, προσθέτοντας τις απαιτούμενες βιβλιοθήκες Iceberg στην εργασία.
- Επιλέξτε Εκτελέστε δουλειά.
- Επιλέξτε Εργασίες για παρακολούθηση της κατάστασης. Περιμένετε μέχρι να γίνει η κατάσταση Η εκτέλεση ολοκληρώθηκε.
Επαληθεύστε τα δεδομένα που έχουν φορτωθεί
Για να επιβεβαιώσετε ότι η εργασία επεξεργάστηκε τα δεδομένα όπως αναμενόταν, ολοκληρώστε τα ακόλουθα βήματα:
- Στην κονσόλα Athena, επιλέξτε Επεξεργαστής ερωτημάτων στο παράθυρο πλοήγησης.
- Επαλήθευση
AwsDataCatalogεπιλέγεται ως πηγή δεδομένων. - Κάτω από βάση δεδομένων, επιλέξτε τον τομέα δεδομένων που θέλετε να εξερευνήσετε, με βάση τη διαμόρφωση που ορίσατε στο χώρο αποθήκευσης παραμέτρων. Εάν χρησιμοποιείτε το δείγμα βάσης δεδομένων που παρέχεται, χρησιμοποιήστε
sports.
Κάτω από Πίνακες και όψεις, μπορούμε να δούμε τη λίστα των πινάκων που δημιουργήθηκαν από την εργασία AWS Glue.
- Επιλέξτε το μενού επιλογών (τρεις κουκκίδες) δίπλα στο όνομα του πρώτου πίνακα και, στη συνέχεια, επιλέξτε Προεπισκόπηση δεδομένων.
Μπορείτε να δείτε τα δεδομένα που έχουν φορτωθεί σε πίνακες Iceberg. 
Εκτελέστε σταδιακή φόρτωση δεδομένων
Τώρα αρχίζουμε να καταγράφουμε αλλαγές από τη σχεσιακή μας βάση δεδομένων και να τις εφαρμόζουμε στη λίμνη δεδομένων συναλλαγών. Αυτό το βήμα χωρίζεται επίσης σε τρία μέρη: καταγραφή των αλλαγών, εφαρμογή τους στους πίνακες Iceberg και επαλήθευση των αποτελεσμάτων.
Καταγράψτε αλλαγές από τη σχεσιακή βάση δεδομένων
Λόγω της διαμόρφωσης που καθορίσαμε, η εργασία αναπαραγωγής σταμάτησε μετά την εκτέλεση της φάσης πλήρους φόρτωσης. Τώρα κάνουμε επανεκκίνηση της εργασίας για να προσθέσουμε σταδιακά αρχεία με αλλαγές στο πρωτογενές στρώμα της λίμνης δεδομένων.
- Στην κονσόλα AWS DMS, επιλέξτε την εργασία που δημιουργήσαμε και εκτελέσαμε πριν.
- Στις Δράσεις μενού, επιλέξτε Συνέχιση.
- Επιλέξτε Έναρξη εργασίας για να αρχίσετε να καταγράφετε αλλαγές.
- Για να ενεργοποιήσετε τη δημιουργία νέου αρχείου στη λίμνη δεδομένων, πραγματοποιήστε εισαγωγές, ενημερώσεις ή διαγραφές στους πίνακες της βάσης δεδομένων προέλευσης χρησιμοποιώντας το προτιμώμενο εργαλείο διαχείρισης βάσης δεδομένων. Εάν χρησιμοποιείτε το δείγμα βάσης δεδομένων που παρέχεται, θα μπορούσατε να εκτελέσετε τις ακόλουθες εντολές SQL:
UPDATE dms_sample.nfl_stadium_data_upd
SET seatin_capacity=93703
WHERE team = 'Los Angeles Rams' and sport_location_id = '31'; update dms_sample.mlb_data set bats = 'R'
where mlb_id=506560 and bats='L'; update dms_sample.sporting_event set start_date = current_date where id=11 and sold_out=0;
- Στη σελίδα λεπτομερειών εργασίας AWS DMS, επιλέξτε το Στατιστικά πίνακα καρτέλα για να δείτε τις αλλαγές που καταγράφηκαν.

- Ανοίξτε το ακατέργαστο στρώμα της λίμνης δεδομένων για να βρείτε ένα νέο αρχείο που περιέχει τις σταδιακές αλλαγές μέσα στο πρόθεμα κάθε πίνακα, για παράδειγμα κάτω από το
sporting_eventπρόθεμα.
Το ρεκόρ με αλλαγές για το sporting_event ο πίνακας μοιάζει με το παρακάτω στιγμιότυπο οθόνης.

Παρατηρήστε το Op στήλη στην αρχή που προσδιορίζεται με μια ενημέρωση (U). Επίσης, η δεύτερη τιμή ημερομηνίας/ώρας είναι η στήλη ελέγχου που προστέθηκε από το AWS DMS με την ώρα που καταγράφηκε η αλλαγή.

Εφαρμόστε αλλαγές στους πίνακες Iceberg χρησιμοποιώντας κόλλα AWS
Τώρα εκτελούμε ξανά την εργασία AWS Glue και θα επεξεργαστεί αυτόματα μόνο τα νέα στοιχειώδη αρχεία αφού είναι ενεργοποιημένος ο σελιδοδείκτης εργασίας. Ας δούμε πώς λειτουργεί.
Η dedupCDCRecords() Η συνάρτηση εκτελεί αντιγραφή δεδομένων, επειδή πολλές αλλαγές σε ένα μεμονωμένο αναγνωριστικό εγγραφής θα μπορούσαν να καταγραφούν στο ίδιο αρχείο δεδομένων στο Amazon S3. Η αποδιπλασιασμός πραγματοποιείται με βάση το last_update_time στήλη που προστέθηκε από το AWS DMS που υποδεικνύει τη χρονική σήμανση κατά την οποία καταγράφηκε η αλλαγή. Δείτε τον παρακάτω κώδικα Python:
def dedupCDCRecords(inputDf, keylist): IDWindowDF = Window.partitionBy(*keylist).orderBy(inputDf.last_update_time).rangeBetween(-sys.maxsize, sys.maxsize) inputDFWithTS = inputDf.withColumn('max_op_date', max(inputDf.last_update_time).over(IDWindowDF)) NewInsertsDF = inputDFWithTS.filter('last_update_time=max_op_date').filter("op='I'") UpdateDeleteDf = inputDFWithTS.filter('last_update_time=max_op_date').filter("op IN ('U','D')") finalInputDF = NewInsertsDF.unionAll(UpdateDeleteDf) return finalInputDFΣτη γραμμή 99, η upsertRecordsSparkSQL() Η συνάρτηση εκτελεί το upsert με παρόμοιο τρόπο με το αρχικό φορτίο, αλλά αυτή τη φορά με μια εντολή SQL MERGE.
Ελέγξτε τις αλλαγές που εφαρμόστηκαν
Ανοίξτε την κονσόλα Athena και εκτελέστε ένα ερώτημα που επιλέγει τις αλλαγμένες εγγραφές στη βάση δεδομένων προέλευσης. Εάν χρησιμοποιείτε το παρεχόμενο δείγμα βάσης δεδομένων, χρησιμοποιήστε ένα από τα ακόλουθα ερωτήματα SQL:
SELECT * FROM "sports"."nfl_stadiu_data_upd"
WHERE team = 'Los Angeles Rams' and sport_location_id = 31
LIMIT 1;

Παρακολουθήστε την κατάποση του τραπεζιού
Το σενάριο εργασίας AWS Glue είναι κωδικοποιημένο με απλό Χειρισμός εξαιρέσεων Python για να εντοπίσετε σφάλματα κατά την επεξεργασία ενός συγκεκριμένου πίνακα. Ο σελιδοδείκτης εργασίας αποθηκεύεται μετά την επιτυχή ολοκλήρωση της επεξεργασίας κάθε πίνακα, για να αποφευχθεί η επανεπεξεργασία των πινάκων εάν επαναληφθεί η εκτέλεση της εργασίας για τους πίνακες με σφάλματα.
Η Διεπαφή γραμμής εντολών AWS (AWS CLI) παρέχει α get-job-bookmark εντολή για AWS Glue που παρέχει πληροφορίες για την κατάσταση του σελιδοδείκτη για κάθε πίνακα που υποβάλλεται σε επεξεργασία.
- Στην κονσόλα AWS Glue Studio, επιλέξτε την εργασία ETL.
- Επιλέξτε Εργασίες καρτέλα και αντιγράψτε το αναγνωριστικό εκτέλεσης εργασίας.
- Εκτελέστε την ακόλουθη εντολή σε ένα τερματικό με έλεγχο ταυτότητας για το AWS CLI, αντικαθιστώντας
<GLUE_JOB_RUN_ID>στη γραμμή 1 με την τιμή που αντιγράψατε. Εάν η στοίβα σας CloudFormation δεν έχει όνομαtransactionaldl-postgresql, δώστε το όνομα της εργασίας σας στη γραμμή 2 του σεναρίου:
jobrun=<GLUE_JOB_RUN_ID>
jobname=IcebergJob-transactionaldl-postgresql
aws glue get-job-bookmark --job-name jobname --run-id $jobrunΣε αυτήν τη λύση, όταν μια επεξεργασία πίνακα προκαλεί εξαίρεση, η εργασία AWS Glue δεν θα αποτύχει σύμφωνα με αυτήν τη λογική. Αντίθετα, ο πίνακας θα προστεθεί σε έναν πίνακα που θα εκτυπωθεί μετά την ολοκλήρωση της εργασίας. Σε ένα τέτοιο σενάριο, η εργασία θα επισημανθεί ως αποτυχημένη αφού προσπαθήσει να επεξεργαστεί τους υπόλοιπους πίνακες που εντοπίστηκαν στην πηγή μη επεξεργασμένων δεδομένων. Με αυτόν τον τρόπο, οι πίνακες χωρίς σφάλματα δεν χρειάζεται να περιμένουν μέχρι ο χρήστης να εντοπίσει και να λύσει το πρόβλημα στους πίνακες που βρίσκονται σε διένεξη. Ο χρήστης μπορεί να εντοπίσει γρήγορα εκτελέσεις εργασιών που είχαν προβλήματα με τη χρήση της κατάστασης εκτέλεσης εργασίας AWS Glue και να προσδιορίσει ποιοι συγκεκριμένοι πίνακες προκαλούν το πρόβλημα χρησιμοποιώντας τα αρχεία καταγραφής CloudWatch για την εκτέλεση εργασίας.
- Το σενάριο εργασίας υλοποιεί αυτήν τη δυνατότητα με τον ακόλουθο κώδικα Python:
# Performed for every table try: # Table processing logic except Exception as e: logger.info(f'There is an issue with table: {tableName}') logger.info(f'The exception is : {e}') errored_table_list.append(tableName) continue job.commit()
if (len(errored_table_list)): logger.info('Total number of errored tables are ',len(errored_table_list)) logger.info('Tables that failed during processing are ', *errored_table_list, sep=', ') raise Exception(f'***** Some tables failed to process.')Το ακόλουθο στιγμιότυπο οθόνης δείχνει πώς τα αρχεία καταγραφής του CloudWatch αναζητούν πίνακες που προκαλούν σφάλματα κατά την επεξεργασία.

Ευθυγραμμισμένο με το Καλά αρχιτεκτονημένος φακός ανάλυσης δεδομένων πλαισίου AWS πρακτικές, μπορείτε να προσαρμόσετε πιο εξελιγμένους μηχανισμούς ελέγχου για τον εντοπισμό και την ειδοποίηση των ενδιαφερομένων όταν εμφανίζονται σφάλματα στους αγωγούς δεδομένων. Για παράδειγμα, μπορείτε να χρησιμοποιήσετε ένα Amazon DynamoDB πίνακα ελέγχου για αποθήκευση όλων των πινάκων και των εργασιών με σφάλματα ή με χρήση Υπηρεσία απλών ειδοποιήσεων Amazon (Amazon SNS) προς αποστολή ειδοποιήσεων στους χειριστές όταν πληρούνται ορισμένα κριτήρια.
Προγραμματισμός σταδιακής φόρτωσης δεδομένων παρτίδας
Η στοίβα CloudFormation αναπτύσσει ένα Amazon EventBridge κανόνας (απενεργοποιημένος από προεπιλογή) που μπορεί να ενεργοποιήσει την εργασία κόλλας AWS για να εκτελεστεί σε ένα χρονοδιάγραμμα. Για να παρέχετε το δικό σας πρόγραμμα και να ενεργοποιήσετε τον κανόνα, ολοκληρώστε τα παρακάτω βήματα:
- Στην κονσόλα EventBridge, επιλέξτε Κανόνες που στο παράθυρο πλοήγησης.
- Αναζητήστε τον κανόνα με πρόθεμα το όνομα της στοίβας CloudFormation σας, ακολουθούμενο από
JobTrigger(για παράδειγμα,transactionaldl-postgresql-JobTrigger-randomvalue). - Επιλέξτε τον κανόνα.
- Κάτω από Πρόγραμμα εκδηλώσεων, επιλέξτε Αλλαγή.
Το προεπιλεγμένο χρονοδιάγραμμα έχει ρυθμιστεί ώστε να ενεργοποιείται κάθε ώρα.
- Δώστε το χρονοδιάγραμμα που θέλετε να εκτελέσετε την εργασία.
- Επιπλέον, μπορείτε να χρησιμοποιήσετε ένα Έκφραση cron EventBridge επιλέγοντας Ένα λεπτό χρονοδιάγραμμα.

- Όταν ολοκληρώσετε τη ρύθμιση της έκφρασης cron, επιλέξτε Επόμενο τρεις φορές, και τελικά επιλέξτε Ενημέρωση κανόνα για να αποθηκεύσετε αλλαγές.
Ο κανόνας δημιουργείται απενεργοποιημένος από προεπιλογή για να σας επιτρέψει να εκτελέσετε πρώτα την αρχική φόρτωση δεδομένων.
- Ενεργοποιήστε τον κανόνα επιλέγοντας Ενεργοποίηση.
Μπορείτε να χρησιμοποιήσετε το παρακολούθηση καρτέλα για να δείτε τις επικλήσεις κανόνων ή απευθείας στην κόλλα AWS Job Run Λεπτομέριες.
Συμπέρασμα
Μετά την ανάπτυξη αυτής της λύσης, έχετε αυτοματοποιήσει την απορρόφηση των πινάκων σας σε μία μόνο σχεσιακή πηγή δεδομένων. Οι οργανισμοί που χρησιμοποιούν μια λίμνη δεδομένων ως κεντρική πλατφόρμα δεδομένων συνήθως πρέπει να χειρίζονται πολλαπλές, μερικές φορές ακόμη και δεκάδες πηγές δεδομένων. Επίσης, όλο και περισσότερες περιπτώσεις χρήσης απαιτούν από τους οργανισμούς να εφαρμόσουν συναλλακτικές δυνατότητες στη λίμνη δεδομένων. Μπορείτε να χρησιμοποιήσετε αυτήν τη λύση για να επιταχύνετε την υιοθέτηση τέτοιων δυνατοτήτων σε όλες τις πηγές σχεσιακών δεδομένων σας για να ενεργοποιήσετε νέες περιπτώσεις επιχειρηματικής χρήσης, αυτοματοποιώντας τη διαδικασία υλοποίησης για να αντλήσετε περισσότερη αξία από τα δεδομένα σας.
Σχετικά με τους Συγγραφείς
 Λουίς Χεράρντο Μπαέζα είναι Αρχιτέκτονας Μεγάλων Δεδομένων στο Εργαστήριο Δεδομένων των Υπηρεσιών Ιστού της Amazon (AWS). Έχει 12 χρόνια εμπειρίας βοηθώντας οργανισμούς στους τομείς της υγειονομικής περίθαλψης, του χρηματοοικονομικού τομέα και της εκπαίδευσης να υιοθετήσουν προγράμματα αρχιτεκτονικής επιχειρήσεων, cloud computing και δυνατότητες ανάλυσης δεδομένων. Ο Luis βοηθά σήμερα οργανισμούς σε ολόκληρη τη Λατινική Αμερική να επιταχύνουν τις στρατηγικές πρωτοβουλίες δεδομένων.
Λουίς Χεράρντο Μπαέζα είναι Αρχιτέκτονας Μεγάλων Δεδομένων στο Εργαστήριο Δεδομένων των Υπηρεσιών Ιστού της Amazon (AWS). Έχει 12 χρόνια εμπειρίας βοηθώντας οργανισμούς στους τομείς της υγειονομικής περίθαλψης, του χρηματοοικονομικού τομέα και της εκπαίδευσης να υιοθετήσουν προγράμματα αρχιτεκτονικής επιχειρήσεων, cloud computing και δυνατότητες ανάλυσης δεδομένων. Ο Luis βοηθά σήμερα οργανισμούς σε ολόκληρη τη Λατινική Αμερική να επιταχύνουν τις στρατηγικές πρωτοβουλίες δεδομένων.
 SaiKiran Reddy Aenugu είναι αρχιτέκτονας δεδομένων στο εργαστήριο δεδομένων Amazon Web Services (AWS). Διαθέτει 10ετή εμπειρία στην εφαρμογή διαδικασιών φόρτωσης, μετασχηματισμού και οπτικοποίησης δεδομένων. Το SaiKiran βοηθά σήμερα οργανισμούς στη Βόρεια Αμερική να υιοθετήσουν σύγχρονες αρχιτεκτονικές δεδομένων, όπως λίμνες δεδομένων και πλέγμα δεδομένων. Έχει εμπειρία στους τομείς του λιανικού εμπορίου, των αεροπορικών εταιρειών και των χρηματοοικονομικών.
SaiKiran Reddy Aenugu είναι αρχιτέκτονας δεδομένων στο εργαστήριο δεδομένων Amazon Web Services (AWS). Διαθέτει 10ετή εμπειρία στην εφαρμογή διαδικασιών φόρτωσης, μετασχηματισμού και οπτικοποίησης δεδομένων. Το SaiKiran βοηθά σήμερα οργανισμούς στη Βόρεια Αμερική να υιοθετήσουν σύγχρονες αρχιτεκτονικές δεδομένων, όπως λίμνες δεδομένων και πλέγμα δεδομένων. Έχει εμπειρία στους τομείς του λιανικού εμπορίου, των αεροπορικών εταιρειών και των χρηματοοικονομικών.
 Ναρέντρα Μέρλα είναι αρχιτέκτονας δεδομένων στο εργαστήριο δεδομένων Amazon Web Services (AWS). Έχει 12 χρόνια εμπειρία στο σχεδιασμό και την παραγωγή αγωγών δεδομένων σε πραγματικό χρόνο και σε παρτίδες και στην κατασκευή λιμνών δεδομένων τόσο σε περιβάλλον cloud όσο και σε περιβάλλοντα εσωτερικού χώρου. Ο Narendra βοηθά σήμερα οργανισμούς στη Βόρεια Αμερική να δημιουργήσουν και να σχεδιάσουν ισχυρές αρχιτεκτονικές δεδομένων και έχει εμπειρία στους τομείς των τηλεπικοινωνιών και των χρηματοοικονομικών.
Ναρέντρα Μέρλα είναι αρχιτέκτονας δεδομένων στο εργαστήριο δεδομένων Amazon Web Services (AWS). Έχει 12 χρόνια εμπειρία στο σχεδιασμό και την παραγωγή αγωγών δεδομένων σε πραγματικό χρόνο και σε παρτίδες και στην κατασκευή λιμνών δεδομένων τόσο σε περιβάλλον cloud όσο και σε περιβάλλοντα εσωτερικού χώρου. Ο Narendra βοηθά σήμερα οργανισμούς στη Βόρεια Αμερική να δημιουργήσουν και να σχεδιάσουν ισχυρές αρχιτεκτονικές δεδομένων και έχει εμπειρία στους τομείς των τηλεπικοινωνιών και των χρηματοοικονομικών.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- Platoblockchain. Web3 Metaverse Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- πηγή: https://aws.amazon.com/blogs/big-data/automate-replication-of-relational-sources-into-a-transactional-data-lake-with-apache-iceberg-and-aws-glue/
- 1
- 10
- 100
- 102
- 107
- 7
- a
- Σχετικά
- επιταχύνουν
- πρόσβαση
- Σύμφωνα με
- αναγνωρίζω
- απέναντι
- προσαρμόσει
- προστιθέμενη
- Πρόσθετος
- Επιπλέον
- Προσθέτει
- διαχειριστής
- διαχείριση
- ενστερνίζομαι
- Υιοθεσία
- Μετά το
- αερογραμμή
- Όλα
- ήδη
- Amazon
- Αμαζόν Αθηνά
- Amazon RDS
- Amazon υπηρεσίες Web
- Amazon Web Services (AWS)
- Αμερική
- ανάλυση
- analytics
- και
- Angeles
- Apache
- εμφανίζομαι
- Εφαρμογή
- εφαρμοσμένος
- εφαρμόζοντας
- πλησιάζω
- περίπου
- αρχιτεκτονική
- Παράταξη
- συσχετισμένη
- επικυρωμένο
- αυτοματοποίηση
- Αυτοματοποιημένη
- αυτομάτως
- αυτοματοποίηση
- μέσος
- αποφύγετε
- AWS
- AWS CloudFormation
- Κόλλα AWS
- βασίζονται
- νυχτερίδες
- επειδή
- γίνονται
- πριν
- Αρχή
- Μεγάλος
- Big Data
- χτίζω
- Builder
- Κτίριο
- επιχείρηση
- Μπορεί να πάρει
- δυνατότητες
- καλύμματα
- πιάνω
- Καταγραφή
- περίπτωση
- περιπτώσεις
- κατάλογος
- πάλη
- Αιτία
- αίτια
- προκαλώντας
- CDC
- κεντρικός
- ορισμένες
- αλλαγή
- Αλλαγές
- επιλογή
- Επιλέξτε
- επιλέγοντας
- επιλέγονται
- Backup
- cloud computing
- κωδικός
- Στήλη
- Στήλες
- εταίρα
- πλήρης
- χρήση υπολογιστή
- διαμόρφωση
- διαμορφώσεις
- Επιβεβαιώνω
- Αντιφατικός
- Connect
- σύνδεση
- θεωρήσεις
- πρόξενος
- Καταναλωτές
- κατανάλωση
- Περιέχει
- ΣΥΝΕΧΕΙΑ
- συνεχής
- έλεγχος
- θα μπορούσε να
- δημιουργία
- δημιουργήθηκε
- δημιουργεί
- δημιουργία
- δημιουργία
- κριτήρια
- Τη στιγμή
- έθιμο
- πελάτης
- προσαρμόσετε
- ημερομηνία
- Δεδομένα Analytics
- Λίμνη δεδομένων
- Πλατφόρμα δεδομένων
- βάση δεδομένων
- βάσεις δεδομένων
- Ημερομηνία
- Προεπιλογή
- ορίζεται
- παρατάσσω
- αναπτυχθεί
- ανάπτυξη
- ανάπτυξη
- αναπτύσσεται
- Υπηρεσίες
- σχεδιασμένα
- σχέδιο
- καθέκαστα
- εντοπιστεί
- Ανάπτυξη
- διαφορετικές
- κατευθείαν
- ανάπηρος
- διαιρούμενο
- Όχι
- τομέα
- domains
- Μην
- κατά την διάρκεια
- κάθε
- Νωρίτερα
- εύκολα
- Εκπαίδευση
- προσπάθεια
- είτε
- ενεργοποιήσετε
- ενεργοποιημένη
- κρυπτογραφημένα
- κρυπτογράφηση
- Τελικό σημείο
- Κινητήρας
- εισάγετε
- Εταιρεία
- περιβάλλοντα
- λάθη
- Αιθέρας (ΕΤΗ)
- Even
- Κάθε
- παράδειγμα
- υπερβαίνει
- Εκτός
- εξαίρεση
- υφιστάμενα
- υπάρχει
- αναμένεται
- αναμένει
- εμπειρία
- διερευνήσει
- επεκτάσεις
- εκχύλισμα
- Απέτυχε
- οικείος
- Μόδα
- Χαρακτηριστικό
- λίγοι
- Αρχεία
- Αρχεία
- Τελικά
- χρηματοδότηση
- οικονομικός
- Εύρεση
- φινίρισμα
- Όνομα
- ακολουθείται
- Εξής
- Για τους καταναλωτές
- μορφή
- σχηματισμός
- Πλαίσιο
- από
- πλήρη
- λειτουργία
- παράγεται
- γενεά
- παίρνω
- χορηγεί
- επιχορηγήσεις
- Μεγαλώνοντας
- λαβή
- υγειονομική περίθαλψη
- βοήθεια
- βοηθά
- ιεραρχία
- ιστορία
- κράτημα
- Πως
- Πώς να
- HTML
- HTTPS
- τεράστιος
- IAM
- προσδιορίζονται
- αναγνωριστικό
- αναγνωρίζει
- προσδιορίσει
- εφαρμογή
- εκτέλεση
- εφαρμοστεί
- εκτελεστικών
- υλοποιεί
- βελτίωση
- in
- περιλαμβάνουν
- περιλαμβάνει
- Συμπεριλαμβανομένου
- Εισερχόμενος
- υποδηλώνει
- ατομικές
- πληροφορίες
- αρχικός
- πρωτοβουλίες
- Ένθετα
- διορατικότητα
- παράδειγμα
- αντί
- οδηγίες
- Ενδιάμεσος
- ζήτημα
- θέματα
- IT
- επανάληψη
- Δουλειά
- Θέσεις εργασίας
- json
- Διατήρηση
- Κλειδί
- πλήκτρα
- Ξέρω
- εργαστήριο
- λίμνη
- Latin
- Λατινική Αμερική
- στρώμα
- στρώματα
- οδηγήσει
- ΜΑΘΑΊΝΩ
- βιβλιοθήκες
- LIMIT
- γραμμή
- Λίστα
- φορτίο
- φόρτωση
- φορτία
- τοποθεσία
- ματιά
- ΦΑΊΝΕΤΑΙ
- ο
- Λος Άντζελες
- Παρτίδα
- Κυρίως
- διατηρεί
- κάνω
- διαχειρίζεται
- διαχείριση
- διευθυντής
- διαχείριση
- χειροκίνητα
- πολοί
- χαρτης
- μαρκαρισμένος
- Μενού
- πηγαίνω
- μήνυμα
- ενδέχεται να
- μετανάστευση
- ελάχιστο
- λεπτό
- πρακτικά
- ΜΟΝΤΕΡΝΑ
- τροποποιήσει
- Παρακολούθηση
- παρακολούθηση
- περισσότερο
- πλέον
- Δημοφιλέστερα
- πολλαπλούς
- όνομα
- Ονομάστηκε
- ονόματα
- Πλοηγηθείτε
- Πλοήγηση
- Ανάγκη
- που απαιτούνται
- ανάγκες
- Νέα
- επόμενη
- Βόρειος
- Βόρεια Αμερική
- κοινοποίηση
- αριθμός
- αντικείμενο
- αντικειμένων
- ONE
- συνεχή
- OP
- λειτουργία
- βελτιστοποιημένη
- Επιλογές
- οργανωτικός
- οργανώσεις
- Οργανωμένος
- πρωτότυπο
- αλλιώς
- εκτός
- δική
- ιδιοκτήτης
- παράθυρο
- παράμετρος
- παράμετροι
- μέρος
- εξαρτήματα
- μονοπάτι
- πρότυπο
- εκτελέσει
- εκτέλεση
- εκτελεί
- περίοδος
- δικαιώματα
- φάση
- πλατφόρμες
- Πλάτων
- Πληροφορία δεδομένων Plato
- Πλάτωνα δεδομένα
- Δημοφιλής
- Θέση
- postgresql
- πρακτικές
- προτιμάται
- προαπαιτούμενα
- παρόν
- πρωταρχικός
- Πρόβλημα
- διαδικασια μας
- Διεργασίες
- μεταποίηση
- Παράγεται
- Προγράμματα
- παρέχουν
- παρέχεται
- παρέχει
- Python
- γρήγορα
- αύξηση
- Τιμή
- Ακατέργαστος
- ακατέργαστα δεδομένα
- Διάβασε
- σε πραγματικό χρόνο
- ρεκόρ
- αρχεία
- αντικαθιστώ
- επαναλαμβάνεται
- αναπαραγωγή
- απαιτούν
- απαιτείται
- πόρος
- Υποστηρικτικό υλικό
- ΠΕΡΙΦΕΡΕΙΑ
- Αποτελέσματα
- λιανική πώληση
- απόδοση
- Επιστροφές
- ανασκόπηση
- εύρωστος
- Ρόλος
- Άρθρο
- κανόνες
- τρέξιμο
- τρέξιμο
- ίδιο
- Αποθήκευση
- σενάριο
- πρόγραμμα
- έκταση
- Εφαρμογές
- Αναζήτηση
- Δεύτερος
- Τομείς
- βλέποντας
- επιλέγονται
- επιλογή
- επιλογή
- ξεχωριστό
- Υπηρεσίες
- σειρά
- τον καθορισμό
- ρυθμίσεις
- θα πρέπει να
- δείχνουν
- Δείχνει
- παρόμοιες
- Απλούς
- αφού
- ενιαίας
- So
- λύση
- Λύει
- μερικοί
- εξελιγμένα
- Πηγή
- Πηγές
- χώρων
- Σπινθήρας
- συγκεκριμένες
- προσδιορισμός
- καθορίζεται
- Αθλητισμός
- SQL
- σωρός
- Στοίβες
- Στάδιο
- ενδιαφερόμενα μέρη
- Εκκίνηση
- ξεκίνησε
- Ξεκινήστε
- ξεκινά
- Μελών
- στατιστική
- Κατάσταση
- Βήμα
- Βήματα
- σταμάτησε
- χώρος στο δίσκο
- κατάστημα
- αποθηκεύονται
- καταστήματα
- Στρατηγική
- δομή
- δομημένος
- στούντιο
- Επιτυχώς
- τέτοιος
- Σούπερ
- υποστήριξη
- συστήματα
- τραπέζι
- στόχος
- Έργο
- εργασίες
- ομάδες
- τηλεπικοινωνιών
- πρότυπο
- τερματικό
- Η
- Η Πηγη
- τους
- χιλιάδες
- τρία
- Μέσω
- ώρα
- χρονοδιάγραμμα
- φορές
- timestamp
- προς την
- εργαλείο
- κορυφή
- Σύνολο
- Παρακολούθηση
- παραδοσιακός
- συναλλακτική
- Μεταμορφώστε
- Μεταμόρφωση
- ενεργοποιούν
- φροντιστήριο
- τύποι
- υπό
- καταλαβαίνω
- μοναδικός
- Ενημέρωση
- ενημερώσεις
- χρήση
- περίπτωση χρήσης
- Χρήστες
- Χρήστες
- συνήθως
- αξία
- επαληθεύοντας
- Δες
- οραματισμός
- τόμος
- περιμένετε
- Αποθήκη
- ιστός
- διαδικτυακές υπηρεσίες
- Ποιό
- θα
- εντός
- χωρίς
- λειτουργεί
- γράφω
- γραπτή
- γιαμ
- έτος
- χρόνια
- Σας
- zephyrnet