Amazon Sage Maker είναι μια πλήρως διαχειριζόμενη υπηρεσία μηχανικής μάθησης (ML). Με το SageMaker, οι επιστήμονες δεδομένων και οι προγραμματιστές μπορούν γρήγορα και εύκολα να δημιουργήσουν και να εκπαιδεύσουν μοντέλα ML και στη συνέχεια να τα αναπτύξουν απευθείας σε ένα φιλοξενούμενο περιβάλλον έτοιμο για παραγωγή. Παρέχει ένα ενσωματωμένο παράδειγμα σημειωματάριου συγγραφής Jupyter για εύκολη πρόσβαση στις πηγές δεδομένων σας για εξερεύνηση και ανάλυση, ώστε να μην χρειάζεται να διαχειρίζεστε διακομιστές. Παρέχει επίσης κοινά Αλγόριθμοι ML που είναι βελτιστοποιημένα για να λειτουργούν αποτελεσματικά έναντι εξαιρετικά μεγάλων δεδομένων σε ένα κατανεμημένο περιβάλλον.
Το συμπέρασμα σε πραγματικό χρόνο του SageMaker είναι ιδανικό για φόρτους εργασίας που έχουν απαιτήσεις σε πραγματικό χρόνο, διαδραστικές και χαμηλής καθυστέρησης. Με την εξαγωγή συμπερασμάτων σε πραγματικό χρόνο του SageMaker, μπορείτε να αναπτύξετε τελικά σημεία REST που υποστηρίζονται από έναν συγκεκριμένο τύπο παρουσίας με ένα συγκεκριμένο ποσό υπολογισμού και μνήμης. Η ανάπτυξη ενός τερματικού σημείου SageMaker σε πραγματικό χρόνο είναι μόνο το πρώτο βήμα στην πορεία προς την παραγωγή για πολλούς πελάτες. Θέλουμε να είμαστε σε θέση να μεγιστοποιήσουμε την απόδοση του τελικού σημείου για να επιτύχουμε έναν στόχο συναλλαγών ανά δευτερόλεπτο (TPS), ενώ τηρούμε τις απαιτήσεις λανθάνουσας κατάστασης. Ένα μεγάλο μέρος της βελτιστοποίησης απόδοσης για εξαγωγή συμπερασμάτων είναι να βεβαιωθείτε ότι επιλέγετε τον κατάλληλο τύπο παρουσίας και μετράτε για να υποστηρίξετε ένα τελικό σημείο.
Αυτή η ανάρτηση περιγράφει τις βέλτιστες πρακτικές για τη δοκιμή φόρτωσης ενός τερματικού σημείου SageMaker για να βρείτε τη σωστή διαμόρφωση για τον αριθμό των παρουσιών και το μέγεθος. Αυτό μπορεί να μας βοηθήσει να κατανοήσουμε τις ελάχιστες προβλεπόμενες απαιτήσεις παρουσίας για την κάλυψη των απαιτήσεων λανθάνοντος χρόνου και TPS. Από εκεί, εξετάζουμε πώς μπορείτε να παρακολουθείτε και να κατανοείτε τις μετρήσεις και την απόδοση του τελικού σημείου του SageMaker που χρησιμοποιεί amazoncloudwatch μετρήσεις.
Πρώτα συγκρίνουμε την απόδοση του μοντέλου μας σε μία μόνο περίπτωση για να προσδιορίσουμε το TPS που μπορεί να χειριστεί σύμφωνα με τις αποδεκτές απαιτήσεις καθυστέρησης. Στη συνέχεια, παρεκτείνουμε τα ευρήματα για να αποφασίσουμε για τον αριθμό των περιπτώσεων που χρειαζόμαστε για να χειριστούμε την κυκλοφορία παραγωγής μας. Τέλος, προσομοιώνουμε την κυκλοφορία σε επίπεδο παραγωγής και ρυθμίζουμε δοκιμές φόρτωσης για ένα τελικό σημείο SageMaker σε πραγματικό χρόνο για να επιβεβαιώσουμε ότι το τελικό σημείο μας μπορεί να χειριστεί το φόρτο σε επίπεδο παραγωγής. Ολόκληρο το σετ κώδικα για το παράδειγμα είναι διαθέσιμο παρακάτω Αποθετήριο GitHub.
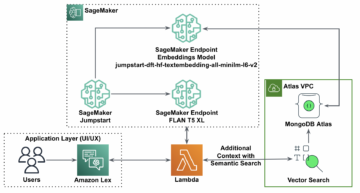
Επισκόπηση της λύσης
Για αυτήν την ανάρτηση, αναπτύσσουμε ένα προεκπαιδευμένο Hugging Face μοντέλο DistilBERT από το Humbing Face Hub. Αυτό το μοντέλο μπορεί να εκτελέσει διάφορες εργασίες, αλλά στέλνουμε ένα ωφέλιμο φορτίο ειδικά για ανάλυση συναισθήματος και ταξινόμηση κειμένου. Με αυτό το ωφέλιμο φορτίο δείγματος, προσπαθούμε να επιτύχουμε 1000 TPS.
Αναπτύξτε ένα τελικό σημείο σε πραγματικό χρόνο
Αυτή η ανάρτηση προϋποθέτει ότι είστε εξοικειωμένοι με τον τρόπο ανάπτυξης ενός μοντέλου. Αναφέρομαι σε Δημιουργήστε το τελικό σημείο σας και αναπτύξτε το μοντέλο σας για να κατανοήσετε τα εσωτερικά στοιχεία πίσω από τη φιλοξενία ενός τελικού σημείου. Προς το παρόν, μπορούμε να δείξουμε γρήγορα αυτό το μοντέλο στο Hugging Face Hub και να αναπτύξουμε ένα τελικό σημείο σε πραγματικό χρόνο με το ακόλουθο απόσπασμα κώδικα:
Ας δοκιμάσουμε γρήγορα το τελικό μας σημείο με το δείγμα ωφέλιμου φορτίου που θέλουμε να χρησιμοποιήσουμε για τη δοκιμή φορτίου:

Σημειώστε ότι υποστηρίζουμε το τελικό σημείο χρησιμοποιώντας ένα μόνο Amazon Elastic Compute Cloud Παρουσίαση (Amazon EC2) τύπου ml.m5.12xlarge, που περιέχει 48 vCPU και 192 GiB μνήμης. Ο αριθμός των vCPU είναι μια καλή ένδειξη της ταυτόχρονης λειτουργίας που μπορεί να χειριστεί η παρουσία. Σε γενικές γραμμές, συνιστάται να ελέγχετε διαφορετικούς τύπους παρουσιών για να βεβαιωθείτε ότι έχουμε μια παρουσία που διαθέτει πόρους που χρησιμοποιούνται σωστά. Για να δείτε μια πλήρη λίστα περιπτώσεων SageMaker και την αντίστοιχη υπολογιστική τους ισχύ για συμπέρασμα σε πραγματικό χρόνο, ανατρέξτε στο Τιμολόγηση του Amazon SageMaker.
Μετρήσεις για παρακολούθηση
Προτού μπορέσουμε να ξεκινήσουμε τη δοκιμή φόρτωσης, είναι σημαντικό να κατανοήσουμε ποιες μετρήσεις πρέπει να παρακολουθούμε για να κατανοήσουμε την ανάλυση απόδοσης του τελικού σημείου SageMaker. Το CloudWatch είναι το κύριο εργαλείο καταγραφής που χρησιμοποιεί το SageMaker για να σας βοηθήσει να κατανοήσετε τις διαφορετικές μετρήσεις που περιγράφουν την απόδοση του τελικού σας σημείου. Μπορείτε να χρησιμοποιήσετε τα αρχεία καταγραφής του CloudWatch για τον εντοπισμό σφαλμάτων στις κλήσεις σας στο τελικό σημείο. όλες οι δηλώσεις καταγραφής και εκτύπωσης που έχετε στον κώδικα συμπερασμάτων σας καταγράφονται εδώ. Για περισσότερες πληροφορίες, ανατρέξτε στο Πώς λειτουργεί το Amazon CloudWatch.
Υπάρχουν δύο διαφορετικοί τύποι μετρήσεων που καλύπτει το CloudWatch για το SageMaker: μετρήσεις σε επίπεδο παρουσίας και μετρήσεις επίκλησης.
Μετρήσεις σε επίπεδο παρουσίας
Το πρώτο σύνολο παραμέτρων που πρέπει να ληφθούν υπόψη είναι οι μετρήσεις σε επίπεδο παρουσίας: CPUUtilization και MemoryUtilization (για περιπτώσεις που βασίζονται σε GPU, GPUUtilization). Για CPUUtilization, μπορεί να δείτε ποσοστά πάνω από 100% στην αρχή στο CloudWatch. Είναι σημαντικό να συνειδητοποιήσουμε για CPUUtilization, εμφανίζεται το άθροισμα όλων των πυρήνων της CPU. Για παράδειγμα, εάν η παρουσία πίσω από το τελικό σημείο σας περιέχει 4 vCPU, αυτό σημαίνει ότι το εύρος χρήσης είναι έως και 400%. MemoryUtilization, από την άλλη πλευρά, κυμαίνεται από 0–100%.
Συγκεκριμένα, μπορείτε να χρησιμοποιήσετε CPUUtilization για να κατανοήσετε βαθύτερα εάν διαθέτετε επαρκή ή ακόμη και υπερβολική ποσότητα υλικού. Εάν έχετε μια παρουσία που χρησιμοποιείται ελάχιστα (λιγότερο από 30%), θα μπορούσατε ενδεχομένως να μειώσετε τον τύπο της παρουσίας σας. Αντίθετα, εάν χρησιμοποιείτε περίπου 80–90%, θα ωφελούσε να επιλέξετε ένα παράδειγμα με μεγαλύτερη υπολογιστική/μνήμη. Από τις δοκιμές μας, προτείνουμε περίπου 60–70% χρήση του υλικού σας.
Μετρήσεις επίκλησης
Όπως υποδηλώνει το όνομα, οι μετρήσεις επίκλησης είναι όπου μπορούμε να παρακολουθούμε τον λανθάνοντα χρόνο από άκρο σε άκρο οποιωνδήποτε κλήσεων στο τελικό σημείο σας. Μπορείτε να χρησιμοποιήσετε τις μετρήσεις επίκλησης για να καταγράψετε τον αριθμό σφαλμάτων και τον τύπο σφαλμάτων (5xx, 4xx κ.λπ.) που ενδέχεται να αντιμετωπίζει το τελικό σημείο σας. Το πιο σημαντικό, μπορείτε να κατανοήσετε την ανάλυση του λανθάνοντος χρόνου των κλήσεων τελικού σημείου σας. Πολλά από αυτά μπορούν να αποτυπωθούν με ModelLatency και OverheadLatency μετρήσεις, όπως φαίνεται στο παρακάτω διάγραμμα.

Η ModelLatency Η μέτρηση καταγράφει το χρόνο που χρειάζεται το συμπέρασμα μέσα στο κοντέινερ μοντέλου πίσω από ένα τελικό σημείο του SageMaker. Λάβετε υπόψη ότι το κοντέινερ μοντέλου περιλαμβάνει επίσης οποιονδήποτε προσαρμοσμένο κώδικα συμπερασμάτων ή σενάρια που έχετε μεταβιβάσει για συμπέρασμα. Αυτή η μονάδα καταγράφεται σε μικροδευτερόλεπτα ως μέτρηση επίκλησης και γενικά μπορείτε να γράψετε ένα εκατοστημόριο στο CloudWatch (p99, p90 και ούτω καθεξής) για να δείτε εάν πληροίτε τον λανθάνοντα χρόνο στόχο σας. Λάβετε υπόψη ότι διάφοροι παράγοντες μπορούν να επηρεάσουν τον λανθάνοντα χρόνο μοντέλου και κοντέινερ, όπως οι ακόλουθοι:
- Προσαρμοσμένο σενάριο συμπερασμάτων – Είτε έχετε εφαρμόσει το δικό σας κοντέινερ είτε έχετε χρησιμοποιήσει ένα κοντέινερ που βασίζεται στο SageMaker με προσαρμοσμένους χειριστές συμπερασμάτων, είναι η καλύτερη πρακτική να δημιουργήσετε προφίλ στο σενάριό σας για να καταγράψετε τυχόν λειτουργίες που προσθέτουν πολύ χρόνο στον λανθάνοντα χρόνο σας.
- Πρωτόκολλο επικοινωνίας – Εξετάστε τις συνδέσεις REST έναντι gRPC στον διακομιστή μοντέλου εντός του κοντέινερ μοντέλου.
- Βελτιστοποιήσεις πλαισίου μοντέλων – Αυτό είναι συγκεκριμένο πλαίσιο, για παράδειγμα με TensorFlow, υπάρχει ένας αριθμός μεταβλητών περιβάλλοντος που μπορείτε να συντονίσετε και είναι συγκεκριμένες για την υπηρεσία TF. Βεβαιωθείτε ότι έχετε ελέγξει ποιο κοντέινερ χρησιμοποιείτε και εάν υπάρχουν βελτιστοποιήσεις για συγκεκριμένο πλαίσιο που μπορείτε να προσθέσετε μέσα στο σενάριο ή ως μεταβλητές περιβάλλοντος για εισαγωγή στο κοντέινερ.
OverheadLatency μετριέται από τη στιγμή που το SageMaker λαμβάνει το αίτημα μέχρι να επιστρέψει μια απάντηση στον πελάτη, μείον την καθυστέρηση του μοντέλου. Αυτό το μέρος είναι σε μεγάλο βαθμό εκτός του ελέγχου σας και εμπίπτει στον χρόνο που απαιτείται από τα γενικά έξοδα του SageMaker.
Ο λανθάνοντας χρόνος από άκρο σε άκρο στο σύνολό του εξαρτάται από διάφορους παράγοντες και δεν είναι απαραίτητα το άθροισμα των ModelLatency συν OverheadLatency. Για παράδειγμα, εάν ο πελάτης σας κάνει το InvokeEndpoint Κλήση API μέσω του Διαδικτύου, από την οπτική γωνία του πελάτη, η λανθάνουσα κατάσταση από άκρο σε άκρο θα είναι Internet + ModelLatency + OverheadLatency. Ως εκ τούτου, κατά τη φόρτωση δοκιμών στο τελικό σημείο σας προκειμένου να συγκριθεί με ακρίβεια το ίδιο το τελικό σημείο, συνιστάται να εστιάσετε στις μετρήσεις τελικού σημείου (ModelLatency, OverheadLatency, να InvocationsPerInstance) για να μετρήσετε με ακρίβεια το τελικό σημείο του SageMaker. Οποιαδήποτε ζητήματα που σχετίζονται με τον λανθάνοντα χρόνο από άκρο σε άκρο μπορούν στη συνέχεια να απομονωθούν ξεχωριστά.
Μερικές ερωτήσεις που πρέπει να λάβετε υπόψη για τον λανθάνοντα χρόνο από άκρο σε άκρο:
- Πού βρίσκεται ο πελάτης που επικαλείται το τελικό σημείο σας;
- Υπάρχουν ενδιάμεσα επίπεδα μεταξύ του πελάτη σας και του χρόνου εκτέλεσης του SageMaker;
Αυτόματη κλιμάκωση
Δεν καλύπτουμε ειδικά την αυτόματη κλιμάκωση σε αυτήν την ανάρτηση, αλλά είναι σημαντικό να λάβουμε υπόψη μας προκειμένου να παρέχουμε τον σωστό αριθμό παρουσιών με βάση τον φόρτο εργασίας. Ανάλογα με τα μοτίβα κυκλοφορίας σας, μπορείτε να επισυνάψετε ένα πολιτική αυτόματης κλιμάκωσης στο τελικό σημείο του SageMaker. Υπάρχουν διαφορετικές επιλογές κλιμάκωσης, όπως π.χ TargetTrackingScaling, SimpleScaling, να StepScaling. Αυτό επιτρέπει στο τελικό σημείο σας να κλιμακώνεται μέσα και έξω αυτόματα με βάση το μοτίβο επισκεψιμότητάς σας.
Μια κοινή επιλογή είναι η παρακολούθηση στόχων, όπου μπορείτε να καθορίσετε μια μέτρηση CloudWatch ή μια προσαρμοσμένη μέτρηση που έχετε ορίσει και να κλιμακώσετε με βάση αυτήν. Μια συχνή χρήση της αυτόματης κλιμάκωσης είναι η παρακολούθηση του InvocationsPerInstance μετρικός. Αφού εντοπίσετε ένα σημείο συμφόρησης σε ένα συγκεκριμένο TPS, μπορείτε συχνά να το χρησιμοποιήσετε ως μέτρηση για να κλιμακωθείτε σε μεγαλύτερο αριθμό περιπτώσεων ώστε να μπορείτε να χειρίζεστε τα φορτία αιχμής της κυκλοφορίας. Για να λάβετε μια βαθύτερη ανάλυση των τελικών σημείων SageMaker αυτόματης κλίμακας, ανατρέξτε στο Διαμόρφωση τελικών σημείων συμπερασμάτων αυτόματης κλιμάκωσης στο Amazon SageMaker.
Δοκιμή φόρτωσης
Αν και χρησιμοποιούμε το Locust για να εμφανίσουμε πώς μπορούμε να φορτώσουμε τη δοκιμή σε κλίμακα, εάν προσπαθείτε να βάλετε σωστά το μέγεθος της παρουσίας πίσω από το τελικό σημείο σας, SageMaker Inference Recommender είναι πιο αποτελεσματική επιλογή. Με τα εργαλεία δοκιμής φόρτωσης τρίτων, πρέπει να αναπτύξετε μη αυτόματα τερματικά σημεία σε διαφορετικές παρουσίες. Με το Inference Recommender, μπορείτε απλά να περάσετε μια σειρά από τους τύπους παρουσιών στους οποίους θέλετε να φορτώσετε τη δοκιμή και το SageMaker θα περιστραφεί θέσεις εργασίας για καθεμία από αυτές τις περιπτώσεις.
Ακρίδα
Για αυτό το παράδειγμα χρησιμοποιούμε Ακρίδα, ένα εργαλείο ελέγχου φόρτωσης ανοιχτού κώδικα που μπορείτε να εφαρμόσετε χρησιμοποιώντας Python. Το Locust είναι παρόμοιο με πολλά άλλα εργαλεία δοκιμής φόρτωσης ανοιχτού κώδικα, αλλά έχει μερικά συγκεκριμένα πλεονεκτήματα:
- Εύκολο στην εγκατάσταση – Όπως αποδεικνύουμε σε αυτήν την ανάρτηση, θα περάσουμε ένα απλό σενάριο Python που μπορεί εύκολα να αναπαρασκευαστεί για το συγκεκριμένο τελικό σημείο και το ωφέλιμο φορτίο σας.
- Κατανεμημένα και κλιμακούμενα – Το Locust βασίζεται σε γεγονότα και χρησιμοποιεί gevent κάτω από την κουκούλα. Αυτό είναι πολύ χρήσιμο για τη δοκιμή πολύ ταυτόχρονου φόρτου εργασίας και την προσομοίωση χιλιάδων ταυτόχρονων χρηστών. Μπορείτε να επιτύχετε υψηλό TPS με μία μόνο διαδικασία που εκτελεί το Locust, αλλά έχει επίσης ένα κατανεμημένη παραγωγή φορτίου χαρακτηριστικό που σας δίνει τη δυνατότητα να κλιμακωθείτε σε πολλαπλές διεργασίες και μηχανήματα-πελάτες, όπως θα εξερευνήσουμε σε αυτήν την ανάρτηση.
- Μετρήσεις Locust και διεπαφή χρήστη – Το Locust καταγράφει επίσης τον λανθάνοντα χρόνο από άκρο σε άκρο ως μέτρηση. Αυτό μπορεί να σας βοηθήσει να συμπληρώσετε τις μετρήσεις σας στο CloudWatch για να ζωγραφίσετε μια πλήρη εικόνα των δοκιμών σας. Όλα αυτά καταγράφονται στη διεπαφή χρήστη Locust, όπου μπορείτε να παρακολουθείτε ταυτόχρονα χρήστες, εργαζόμενους και πολλά άλλα.
Για να κατανοήσετε καλύτερα το Locust, ρίξτε μια ματιά στο δικό τους τεκμηρίωση.
Ρύθμιση Amazon EC2
Μπορείτε να ρυθμίσετε το Locust σε οποιοδήποτε περιβάλλον είναι συμβατό για εσάς. Για αυτήν την ανάρτηση, δημιουργήσαμε μια παρουσία EC2 και εγκαταστήσαμε εκεί το Locust για να πραγματοποιήσουμε τις δοκιμές μας. Χρησιμοποιούμε ένα στιγμιότυπο c5.18xlarge EC2. Η υπολογιστική ισχύς από την πλευρά του πελάτη είναι επίσης κάτι που πρέπει να λάβετε υπόψη. Σε περιόδους που εξαντλείται η υπολογιστική ισχύς από την πλευρά του πελάτη, αυτό συχνά δεν καταγράφεται και θεωρείται λάθος ως σφάλμα τελικού σημείου του SageMaker. Είναι σημαντικό να τοποθετήσετε τον πελάτη σας σε μια τοποθεσία με επαρκή υπολογιστική ισχύ που μπορεί να χειριστεί το φορτίο στο οποίο δοκιμάζετε. Για την περίπτωσή μας EC2, χρησιμοποιούμε ένα Ubuntu Deep Learning AMI, αλλά μπορείτε να χρησιμοποιήσετε οποιοδήποτε AMI, εφόσον μπορείτε να ρυθμίσετε σωστά το Locust στο μηχάνημα. Για να κατανοήσετε πώς να εκκινήσετε και να συνδεθείτε με την παρουσία σας EC2, ανατρέξτε στον οδηγό Ξεκινήστε με παρουσίες Amazon EC2 Linux.
Το Locust UI είναι προσβάσιμο μέσω της θύρας 8089. Μπορούμε να το ανοίξουμε προσαρμόζοντας τους κανόνες εισερχόμενης ομάδας ασφαλείας για την παρουσία EC2. Ανοίγουμε επίσης τη θύρα 22, ώστε να μπορούμε να SSH στην παρουσία EC2. Εξετάστε το ενδεχόμενο να ρυθμίσετε την πηγή στη συγκεκριμένη διεύθυνση IP από την οποία έχετε πρόσβαση στην παρουσία EC2.

Αφού συνδεθείτε στην παρουσία σας EC2, ρυθμίζουμε ένα εικονικό περιβάλλον Python και εγκαθιστούμε το API ανοιχτού κώδικα Locust μέσω του CLI:
Είμαστε πλέον έτοιμοι να συνεργαστούμε με το Locust για τη δοκιμή φόρτωσης στο τελικό σημείο μας.
Δοκιμή ακρίδας
Όλες οι δοκιμές φορτίου Locust διεξάγονται με βάση το α Αρχείο Locust που παρέχετε. Αυτό το αρχείο Locust ορίζει μια εργασία για τη δοκιμή φόρτωσης. εδώ ορίζουμε το Boto3 μας κλήση API invoke_endpoint. Δείτε τον ακόλουθο κώδικα:
Στον προηγούμενο κώδικα, προσαρμόστε τις παραμέτρους κλήσης τελικού σημείου επίκλησης ώστε να ταιριάζουν με το συγκεκριμένο μοντέλο επίκλησής σας. Χρησιμοποιούμε το InvokeEndpoint API χρησιμοποιώντας το ακόλουθο κομμάτι κώδικα στο αρχείο Locust. αυτό είναι το σημείο εκτέλεσης δοκιμής φορτίου. Το αρχείο Locust που χρησιμοποιούμε είναι locust_script.py.
Τώρα που έχουμε έτοιμο το σενάριο Locust, θέλουμε να εκτελέσουμε κατανεμημένες δοκιμές Locust για να δοκιμάσουμε άγχος τη μοναδική παρουσία μας για να μάθουμε πόση επισκεψιμότητα μπορεί να διαχειριστεί η παρουσία μας.
Η λειτουργία κατανομής Locust είναι λίγο πιο διαφοροποιημένη από μια δοκιμή Locust μιας διαδικασίας. Σε κατανεμημένη λειτουργία, έχουμε έναν κύριο και πολλούς εργαζόμενους. Ο κύριος εργαζόμενος καθοδηγεί τους εργαζόμενους σχετικά με τον τρόπο δημιουργίας και ελέγχου των ταυτόχρονων χρηστών που στέλνουν ένα αίτημα. Στο δικό μας διανεμήθηκε.sh script, βλέπουμε από προεπιλογή ότι 240 χρήστες θα κατανεμηθούν στους 60 εργαζόμενους. Σημειώστε ότι το --headless Η σημαία στο Locust CLI καταργεί τη δυνατότητα διεπαφής χρήστη του Locust.
./distributed.sh huggingface-pytorch-inference-2022-10-04-02-46-44-677 #to execute Distributed Locust test
Εκτελούμε πρώτα το κατανεμημένο τεστ σε μία μόνο παρουσία που υποστηρίζει το τελικό σημείο. Η ιδέα εδώ είναι ότι θέλουμε να μεγιστοποιήσουμε πλήρως ένα μεμονωμένο στιγμιότυπο για να κατανοήσουμε τον αριθμό παρουσιών που χρειαζόμαστε για να επιτύχουμε το TPS-στόχο μας, διατηρώντας παράλληλα τις απαιτήσεις λανθάνουσας κατάστασης. Σημειώστε ότι εάν θέλετε να αποκτήσετε πρόσβαση στη διεπαφή χρήστη, αλλάξτε το Locust_UI μεταβλητή περιβάλλοντος σε True και πάρτε τη δημόσια IP της παρουσίας EC2 και αντιστοιχίστε τη θύρα 8089 στη διεύθυνση URL.
Το παρακάτω στιγμιότυπο οθόνης δείχνει τις μετρήσεις μας στο CloudWatch.

Τελικά, παρατηρούμε ότι, παρόλο που αρχικά επιτυγχάνουμε TPS 200, αρχίζουμε να παρατηρούμε σφάλματα 5xx στα αρχεία καταγραφής του πελάτη EC2, όπως φαίνεται στο παρακάτω στιγμιότυπο οθόνης.
Μπορούμε επίσης να το επαληθεύσουμε αυτό εξετάζοντας τις μετρήσεις σε επίπεδο παρουσίας, συγκεκριμένα CPUUtilization.
 Εδώ παρατηρούμε
Εδώ παρατηρούμε CPUUtilization σχεδόν στο 4,800%. Η παρουσία μας ml.m5.12x.large έχει 48 vCPU (48 * 100 = 4800~). Αυτό κορεστεί ολόκληρο το στιγμιότυπο, το οποίο βοηθά επίσης να εξηγήσουμε τα σφάλματα 5xx μας. Βλέπουμε επίσης αύξηση σε ModelLatency.
Φαίνεται ότι η μεμονωμένη παρουσία μας καταρρίπτεται και δεν έχει τον υπολογισμό να διατηρήσει ένα φορτίο πέρα από τα 200 TPS που παρατηρούμε. Το TPS-στόχος μας είναι 1000, οπότε ας προσπαθήσουμε να αυξήσουμε το πλήθος των παρουσιών μας στο 5. Αυτό μπορεί να πρέπει να είναι ακόμη περισσότερο σε μια ρύθμιση παραγωγής, επειδή παρατηρούσαμε σφάλματα στα 200 TPS μετά από ένα συγκεκριμένο σημείο.

Βλέπουμε και στα αρχεία καταγραφής Locust UI και CloudWatch ότι έχουμε TPS σχεδόν 1000 με πέντε περιπτώσεις που υποστηρίζουν το τελικό σημείο.

 Εάν αρχίσετε να αντιμετωπίζετε σφάλματα ακόμη και με αυτήν τη ρύθμιση υλικού, φροντίστε να παρακολουθείτε
Εάν αρχίσετε να αντιμετωπίζετε σφάλματα ακόμη και με αυτήν τη ρύθμιση υλικού, φροντίστε να παρακολουθείτε CPUUtilization για να κατανοήσετε την πλήρη εικόνα πίσω από τη φιλοξενία τελικού σημείου σας. Είναι σημαντικό να κατανοήσετε τη χρήση του υλικού σας για να δείτε εάν πρέπει να αυξήσετε ή ακόμα και να μειώσετε την κλίμακα. Μερικές φορές τα προβλήματα σε επίπεδο κοντέινερ οδηγούν σε σφάλματα 5xx, αλλά εάν CPUUtilization είναι χαμηλή, υποδηλώνει ότι δεν είναι το υλικό σας αλλά κάτι σε επίπεδο κοντέινερ ή μοντέλου που μπορεί να οδηγήσει σε αυτά τα ζητήματα (για παράδειγμα, η κατάλληλη μεταβλητή περιβάλλοντος για τον αριθμό των εργαζομένων που δεν έχει οριστεί). Από την άλλη πλευρά, εάν παρατηρήσετε ότι η παρουσία σας είναι πλήρως κορεσμένη, είναι ένα σημάδι ότι πρέπει είτε να αυξήσετε τον στόλο της τρέχουσας παρουσίας είτε να δοκιμάσετε μια μεγαλύτερη παρουσία με έναν μικρότερο στόλο.
Αν και αυξήσαμε το πλήθος παρουσιών σε 5 για να χειριστούμε 100 TPS, μπορούμε να δούμε ότι το ModelLatency η μέτρηση είναι ακόμα υψηλή. Αυτό οφείλεται στο ότι οι περιπτώσεις είναι κορεσμένες. Σε γενικές γραμμές, προτείνουμε να στοχεύσουμε στη χρήση των πόρων του στιγμιότυπου μεταξύ 60-70%.
εκκαθάριση
Μετά τη δοκιμή φόρτωσης, φροντίστε να καθαρίσετε τυχόν πόρους που δεν θα χρησιμοποιήσετε μέσω της κονσόλας SageMaker ή μέσω του delete_endpoint Κλήση Boto3 API. Επιπλέον, φροντίστε να διακόψετε την παρουσία σας EC2 ή οποιαδήποτε ρύθμιση πελάτη έχετε για να μην επιβαρυνθείτε και εκεί περαιτέρω χρεώσεις.
Χαρακτηριστικά
Σε αυτήν την ανάρτηση, περιγράψαμε πώς μπορείτε να φορτώσετε τη δοκιμή σας στο τελικό σημείο του SageMaker σε πραγματικό χρόνο. Συζητήσαμε επίσης ποιες μετρήσεις πρέπει να αξιολογείτε κατά τη φόρτωση δοκιμών στο τελικό σημείο σας για να κατανοήσετε την ανάλυση της απόδοσής σας. Φροντίστε να ελέγξετε έξω SageMaker Inference Recommender για την περαιτέρω κατανόηση του σωστού μεγέθους παραδείγματος και των περισσότερων τεχνικών βελτιστοποίησης απόδοσης.
Σχετικά με τους Συγγραφείς
 Μαρκ Καρπ είναι αρχιτέκτονας ML με την ομάδα του SageMaker Service. Επικεντρώνεται στο να βοηθά τους πελάτες να σχεδιάζουν, να αναπτύσσουν και να διαχειρίζονται φόρτους εργασίας ML σε κλίμακα. Στον ελεύθερο χρόνο του, του αρέσει να ταξιδεύει και να εξερευνά νέα μέρη.
Μαρκ Καρπ είναι αρχιτέκτονας ML με την ομάδα του SageMaker Service. Επικεντρώνεται στο να βοηθά τους πελάτες να σχεδιάζουν, να αναπτύσσουν και να διαχειρίζονται φόρτους εργασίας ML σε κλίμακα. Στον ελεύθερο χρόνο του, του αρέσει να ταξιδεύει και να εξερευνά νέα μέρη.
 Ram Vegiraju είναι αρχιτέκτονας ML με την ομάδα του SageMaker Service. Επικεντρώνεται στο να βοηθά τους πελάτες να δημιουργήσουν και να βελτιστοποιήσουν τις λύσεις AI/ML τους στο Amazon SageMaker. Στον ελεύθερο χρόνο του λατρεύει τα ταξίδια και το γράψιμο.
Ram Vegiraju είναι αρχιτέκτονας ML με την ομάδα του SageMaker Service. Επικεντρώνεται στο να βοηθά τους πελάτες να δημιουργήσουν και να βελτιστοποιήσουν τις λύσεις AI/ML τους στο Amazon SageMaker. Στον ελεύθερο χρόνο του λατρεύει τα ταξίδια και το γράψιμο.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- Platoblockchain. Web3 Metaverse Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- πηγή: https://aws.amazon.com/blogs/machine-learning/best-practices-for-load-testing-amazon-sagemaker-real-time-inference-endpoints/
- 1
- 10
- 100
- 11
- 9
- a
- Ικανός
- πάνω από
- αποδεκτό
- πρόσβαση
- προσιτός
- πρόσβαση
- με ακρίβεια
- Κατορθώνω
- απέναντι
- Επιπλέον
- διεύθυνση
- Μετά το
- κατά
- AI / ML
- Στοχεύω
- Όλα
- επιτρέπει
- Αν και
- Amazon
- Amazon EC2
- Amazon Sage Maker
- ποσό
- ανάλυση
- και
- api
- γύρω
- Παράταξη
- αποδίδουν
- συγγραφικός
- αυτόματη
- αυτομάτως
- διαθέσιμος
- AWS
- πίσω
- υποστηρίζεται
- υποστήριξη
- βασίζονται
- επειδή
- πίσω
- είναι
- αναφοράς
- όφελος
- οφέλη
- ΚΑΛΎΤΕΡΟΣ
- βέλτιστες πρακτικές
- μεταξύ
- σώμα
- Ανάλυση
- χτίζω
- C + +
- κλήση
- κλήσεις
- Μπορεί να πάρει
- πιάνω
- συλλαμβάνει
- πάλη
- ορισμένες
- αλλαγή
- φορτία
- έλεγχος
- τάξη
- ταξινόμηση
- πελάτης
- κωδικός
- Κοινός
- σύμφωνος
- Υπολογίστε
- ανταγωνιστής
- Διεξαγωγή
- διαμόρφωση
- Επιβεβαιώνω
- Connect
- συνδεδεμένος
- Διασυνδέσεις
- Εξετάστε
- εξέταση
- πρόξενος
- Δοχείο
- Περιέχει
- συμφραζόμενα
- έλεγχος
- Αντίστοιχος
- θα μπορούσε να
- κάλυμμα
- Καλύπτει
- CPU
- δημιουργία
- κρίσιμος
- Ρεύμα
- έθιμο
- Πελάτες
- ημερομηνία
- βαθύς
- βαθιά μάθηση
- βαθύτερη
- Προεπιλογή
- Ορίζει
- αποδεικνύουν
- Σε συνάρτηση
- εξαρτάται
- παρατάσσω
- ανάπτυξη
- περιγράφουν
- περιγράφεται
- Υπηρεσίες
- προγραμματιστές
- διαφορετικές
- κατευθείαν
- συζήτηση
- Display
- διανέμονται
- Όχι
- Μην
- κάτω
- κάθε
- εύκολα
- αποτελεσματικός
- αποτελεσματικά
- είτε
- δίνει τη δυνατότητα
- από άκρη σε άκρη
- Τελικό σημείο
- Ολόκληρος
- Περιβάλλον
- σφάλμα
- λάθη
- ουσιώδης
- Αιθέρας (ΕΤΗ)
- Even
- παράδειγμα
- εξαίρεση
- εκτελέσει
- βιώνουν
- Εξηγήστε
- εξερεύνηση
- διερευνήσει
- Εξερευνώντας
- εξαγωγή
- εξαιρετικά
- Πρόσωπο
- παράγοντες
- Falls
- οικείος
- Χαρακτηριστικό
- λίγοι
- Αρχεία
- Τελικά
- Εύρεση
- Όνομα
- ΣΤΟΛΟΣ
- Συγκέντρωση
- εστιάζει
- Εξής
- μορφή
- Πλαίσιο
- συχνάζω
- από
- πλήρη
- πλήρως
- περαιτέρω
- General
- γενικά
- παίρνω
- να πάρει
- καλός
- γραφική παράσταση
- μεγαλύτερη
- Group
- Ομάδα
- λαβή
- ευτυχισμένος
- υλικού
- βοήθεια
- βοήθεια
- βοηθά
- εδώ
- Ψηλά
- υψηλά
- κουκούλα
- οικοδεσπότης
- φιλοξενείται
- φιλοξενία
- Πως
- Πώς να
- HTML
- HTTPS
- Hub
- ιδέα
- ιδανικό
- προσδιορίζονται
- προσδιορίσει
- Επίπτωση
- εφαρμογή
- εφαρμοστεί
- εισαγωγή
- σημαντικό
- in
- περιλαμβάνει
- Αυξάνουν
- αυξημένη
- υποδηλώνει
- ένδειξη
- πληροφορίες
- αρχικά
- εγκαθιστώ
- παράδειγμα
- ενσωματωθεί
- διαδραστικό
- Internet
- επικαλείται
- IP
- Διεύθυνση IP
- απομονωμένος
- θέματα
- IT
- εαυτό
- json
- large
- σε μεγάλο βαθμό
- μεγαλύτερος
- Αφάνεια
- ξεκινήσει
- στρώματα
- οδηγήσει
- που οδηγεί
- μάθηση
- Επίπεδο
- linux
- Λίστα
- λίγο
- φορτίο
- φορτία
- τοποθεσία
- Μακριά
- κοιτάζοντας
- Παρτίδα
- Χαμηλός
- μηχανή
- μάθηση μηχανής
- μηχανήματα
- κάνω
- Κατασκευή
- διαχείριση
- διαχειρίζεται
- χειροκίνητα
- πολοί
- χάρτη
- Αυξάνω στον ανώτατο βαθμό
- μέσα
- Γνωρίστε
- συνάντηση
- Μνήμη
- μετρικός
- Metrics
- ενδέχεται να
- ελάχιστο
- ML
- Τρόπος
- μοντέλο
- μοντέλα
- Παρακολούθηση
- περισσότερο
- πιο αποτελεσματικό
- πολλαπλούς
- όνομα
- σχεδόν
- αναγκαίως
- Ανάγκη
- Νέα
- σημειωματάριο
- αριθμός
- ONE
- ανοίξτε
- ανοικτού κώδικα
- λειτουργίες
- βελτιστοποίηση
- Βελτιστοποίηση
- βελτιστοποιημένη
- Επιλογή
- Επιλογές
- τάξη
- ΑΛΛΑ
- εκτός
- δική
- χρώμα
- παράμετροι
- μέρος
- πέρασε
- Το παρελθόν
- μονοπάτι
- πρότυπο
- πρότυπα
- Κορυφή
- εκτελέσει
- επίδοση
- προοπτική
- επιλέξτε
- εικόνα
- κομμάτι
- Μέρος
- Μέρη
- Πλάτων
- Πληροφορία δεδομένων Plato
- Πλάτωνα δεδομένα
- συν
- Σημείο
- Θέση
- ενδεχομένως
- δύναμη
- πρακτική
- πρακτικές
- Predictor
- πρωταρχικός
- προβλήματα
- διαδικασια μας
- Διεργασίες
- παραγωγή
- Προφίλ ⬇️
- κατάλληλος
- δεόντως
- παρέχουν
- παρέχει
- πρόβλεψη
- δημόσιο
- Python
- Ερωτήσεις
- γρήγορα
- σειρά
- έτοιμος
- σε πραγματικό χρόνο
- συνειδητοποιήσουν
- λαμβάνει
- συνιστάται
- περιοχή
- σχετίζεται με
- ζητήσει
- απαιτήσεις
- Υποστηρικτικό υλικό
- απάντησης
- ΠΕΡΙΦΕΡΕΙΑ
- αποτέλεσμα
- Αποτελέσματα
- Επιστροφές
- κανόνες
- τρέξιμο
- τρέξιμο
- σοφός
- Συμπεράσματα SageMaker
- Κλίμακα
- απολέπιση
- επιστήμονες
- Πεδίο
- Εφαρμογές
- Δεύτερος
- ασφάλεια
- φαίνεται
- ΕΑΥΤΟΣ
- αποστολή
- συναίσθημα
- υπηρεσία
- εξυπηρετούν
- σειρά
- τον καθορισμό
- ρυθμίσεις
- setup
- διάφοροι
- θα πρέπει να
- παρουσιάζεται
- Δείχνει
- υπογράψουν
- παρόμοιες
- Απλούς
- απλά
- ενιαίας
- Μέγεθος
- μικρότερος
- So
- Λύσεις
- κάτι
- Πηγή
- Πηγές
- Ο Spawn
- συγκεκριμένες
- ειδικά
- Γνέθω
- πρότυπο
- Εκκίνηση
- ξεκίνησε
- δηλώσεις
- Βήμα
- Ακόμη
- στάση
- στρες
- προσπαθώ
- τέτοιος
- επαρκής
- κοστούμι
- Σούπερ
- συμπλήρωμα
- Πάρτε
- παίρνει
- στόχος
- Έργο
- εργασίες
- τεχνικές
- δοκιμή
- Δοκιμαστικό τρέξιμο
- Δοκιμές
- δοκιμές
- Ταξινόμηση κειμένου
- Η
- Η Πηγη
- τους
- τρίτους
- χιλιάδες
- Μέσω
- ώρα
- φορές
- προς την
- εργαλείο
- εργαλεία
- Tps
- τροχιά
- Παρακολούθηση
- ΚΙΝΗΣΗ στους ΔΡΟΜΟΥΣ
- Τρένο
- Συναλλαγές
- Ταξίδια
- αληθής
- φροντιστήριο
- τύποι
- Ubuntu
- ui
- υπό
- καταλαβαίνω
- κατανόηση
- μονάδα
- URL
- us
- χρήση
- Χρήστες
- χρησιμοποιώ
- χρησιμοποιούνται
- χρησιμοποιεί
- αξιοποιώντας
- ποικιλία
- επαληθεύει
- μέσω
- Πραγματικός
- Τι
- αν
- Ποιό
- ενώ
- θα
- εντός
- Εργασία
- εργάτης
- εργαζομένων
- θα
- γραφή
- Σας
- zephyrnet