Έχω ήδη δείξει πώς να δημιουργήστε ένα γράφημα γνώσεων από μια σελίδα της Wikipedia. Ωστόσο, δεδομένου ότι η ανάρτηση τράβηξε μεγάλη προσοχή, αποφάσισα να εξερευνήσω άλλους τομείς όπου η χρήση τεχνικών NLP για την κατασκευή ενός γραφήματος γνώσης έχει νόημα. Κατά τη γνώμη μου, το βιοϊατρικό πεδίο είναι ένα χαρακτηριστικό παράδειγμα όπου η αναπαράσταση των δεδομένων ως γράφημα έχει νόημα, καθώς συχνά αναλύετε αλληλεπιδράσεις και σχέσεις μεταξύ γονιδίων, ασθενειών, φαρμάκων, πρωτεϊνών και πολλά άλλα.
Παράδειγμα υπογράφου που δείχνει σχέσεις ασκορβικού οξέος με άλλες βιοϊατρικές έννοιες. Εικόνα από τον συγγραφέα.
Στην παραπάνω απεικόνιση, έχουμε ασκορβικό οξύ, γνωστό και ως βιταμίνη C, και κάποιες από τις σχέσεις του με άλλες έννοιες. Για παράδειγμα, δείχνει ότι η βιταμίνη C θα μπορούσε να χρησιμοποιηθεί για τη θεραπεία της χρόνιας γαστρίτιδας.
Τώρα, μπορείτε να ζητήσετε από μια ομάδα ειδικών στον τομέα να χαρτογραφήσει όλες αυτές τις συνδέσεις μεταξύ φαρμάκων, ασθενειών και άλλων βιοϊατρικών εννοιών για εσάς. Αλλά, δυστυχώς, πολλοί από εμάς δεν έχουν την πολυτέλεια να προσλάβουν μια ομάδα γιατρών για να κάνουν τη δουλειά για εμάς. Σε αυτήν την περίπτωση, μπορούμε να καταφύγουμε στη χρήση τεχνικών NLP για να εξαγάγουμε αυτόματα αυτές τις σχέσεις. Το καλό είναι ότι μπορούμε να χρησιμοποιήσουμε μια διοχέτευση NLP για να διαβάσουμε όλες τις ερευνητικές εργασίες εκεί έξω, και το κακό είναι ότι δεν θα είναι τέλεια όλα τα αποτελέσματα. Ωστόσο, δεδομένου ότι δεν έχω μια ομάδα επιστημόνων έτοιμη στο πλευρό μου για να εξαγάγω σχέσεις με το χέρι, θα καταφύγω στη χρήση τεχνικών NLP για να κατασκευάσω ένα δικό μου γράφημα βιοϊατρικής γνώσης.
Θα χρησιμοποιήσω μια μόνο ερευνητική εργασία σε αυτήν την ανάρτηση ιστολογίου για να σας καθοδηγήσω σε όλα τα βήματα που απαιτούνται για τη δημιουργία ενός γραφήματος βιοϊατρικής γνώσης – Μηχανική Ιστών Αναγέννησης Δέρματος και Ανάπτυξης Τριχοφόρων.
Το χαρτί γράφτηκε από Mohammadreza Ahmadi. Η έκδοση PDF του άρθρου είναι διαθέσιμη με την άδεια CC0 1.0. Θα ακολουθήσουμε τα ακόλουθα βήματα για να δημιουργήσουμε ένα γράφημα γνώσης:
Ανάγνωση εγγράφου PDF με OCR
Προεπεξεργασία κειμένου
Βιοϊατρική αναγνώριση εννοιών και σύνδεση
Εξαγωγή σχέσης
Εμπλουτισμός εξωτερικής βάσης δεδομένων
Μέχρι το τέλος αυτής της ανάρτησης, θα κατασκευάσετε ένα γράφημα με το ακόλουθο σχήμα.
Βιοϊατρικό γραφικό σχήμα. Εικόνα από τον συγγραφέα.
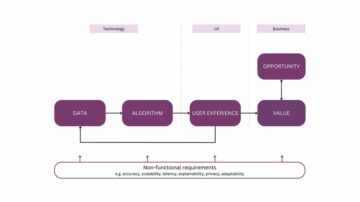
Θα χρησιμοποιήσουμε το Neo4j, μια βάση δεδομένων γραφημάτων που διαθέτει το μοντέλο γραφήματος ιδιοτήτων με ετικέτα, για να αποθηκεύσουμε το γράφημά μας. Κάθε άρθρο μπορεί να έχει έναν ή περισσότερους συγγραφείς. Θα χωρίσουμε το περιεχόμενο του άρθρου σε προτάσεις και θα χρησιμοποιήσουμε το NLP για να εξαγάγουμε τόσο ιατρικές οντότητες όσο και τις σχέσεις τους. Μπορεί να είναι λίγο αντίθετο το ότι θα αποθηκεύσουμε τις σχέσεις μεταξύ οντοτήτων ως ενδιάμεσους κόμβους αντί για σχέσεις. Ο κρίσιμος παράγοντας πίσω από αυτήν την απόφαση είναι ότι θέλουμε να έχουμε μια διαδρομή ελέγχου του αρχικού κειμένου από το οποίο εξήχθη η σχέση. Με το μοντέλο γραφήματος ιδιοτήτων με ετικέτα, δεν μπορείτε να έχετε μια σχέση που να οδηγεί σε άλλη σχέση. Για το λόγο αυτό, αναπαράγουμε τη σύνδεση μεταξύ ιατρικών εννοιών σε έναν ενδιάμεσο κόμβο. Αυτό θα επιτρέψει επίσης σε έναν ειδικό τομέα να αξιολογήσει εάν μια σχέση εξήχθη σωστά ή όχι.
Στην πορεία, θα επιδείξω επίσης εφαρμογές της χρήσης του κατασκευασμένου γραφήματος για την αναζήτηση και ανάλυση αποθηκευμένων πληροφοριών.
Όπως αναφέρθηκε, η έκδοση PDF της ερευνητικής εργασίας είναι προσβάσιμη στο κοινό με την άδεια CC0 1.0, πράγμα που σημαίνει ότι μπορούμε να το κατεβάσουμε εύκολα με Python. Θα χρησιμοποιήσουμε το pytesseract βιβλιοθήκη για εξαγωγή κειμένου από το PDF. Από όσο γνωρίζω, η βιβλιοθήκη pytesseract είναι μια από τις πιο δημοφιλείς βιβλιοθήκες για OCR. Αν θέλετε να ακολουθήσετε μαζί με παραδείγματα κώδικα, έχω ετοιμάσει ένα Σημειωματάριο Google Colab, ώστε να μην χρειάζεται να κάνετε αντιγραφή-επικόλληση μόνοι σας.
import requests
import pdf2image
import pytesseract pdf = requests.get('https://arxiv.org/pdf/2110.03526.pdf')
doc = pdf2image.convert_from_bytes(pdf.content) # Get the article text
article = []
for page_number, page_data in enumerate(doc): txt = pytesseract.image_to_string(page_data).encode("utf-8") # Sixth page are only references if page_number < 6: article.append(txt.decode("utf-8"))
article_txt = " ".join(article)
Προεπεξεργασία κειμένου
Τώρα που έχουμε διαθέσιμο το περιεχόμενο του άρθρου, θα προχωρήσουμε και θα αφαιρέσουμε τίτλους ενοτήτων και περιγραφές σχημάτων από το κείμενο. Στη συνέχεια, θα χωρίσουμε το κείμενο σε προτάσεις.
import nltk
nltk.download('punkt') def clean_text(text): """Remove section titles and figure descriptions from text""" clean = "n".join([row for row in text.split("n") if (len(row.split(" "))) > 3 and not (row.startswith("(a)")) and not row.startswith("Figure")]) return clean text = article_txt.split("INTRODUCTION")[1]
ctext = clean_text(text)
sentences = nltk.tokenize.sent_tokenize(ctext)
Σύνδεση οντότητας με όνομα βιοϊατρικής
Τώρα έρχεται το συναρπαστικό μέρος. Για εκείνους που είναι νέοι στο NLP και στην αναγνώριση και σύνδεση οντοτήτων με όνομα, ας ξεκινήσουμε με μερικά βασικά. Οι τεχνικές αναγνώρισης ονομαστικών οντοτήτων χρησιμοποιούνται για τον εντοπισμό σχετικών οντοτήτων ή εννοιών στο κείμενο. Για παράδειγμα, στον βιοϊατρικό τομέα, θέλουμε να προσδιορίσουμε διάφορα γονίδια, φάρμακα, ασθένειες και άλλες έννοιες στο κείμενο.
Εξαγωγή βιοϊατρικών εννοιών. Εικόνα από τον συγγραφέα.
Σε αυτό το παράδειγμα, το μοντέλο NLP εντόπισε γονίδια, ασθένειες, φάρμακα, είδη, μεταλλάξεις και μονοπάτια στο κείμενο. Όπως αναφέρθηκε, αυτή η διαδικασία ονομάζεται αναγνώριση ονομαζόμενης οντότητας. Μια αναβάθμιση στην αναγνώριση ονομαζόμενης οντότητας είναι η λεγόμενη σύνδεση ονομαζόμενης οντότητας. Η ονομαζόμενη τεχνική σύνδεσης οντοτήτων ανιχνεύει σχετικές έννοιες στο κείμενο και προσπαθεί να τις αντιστοιχίσει στη βάση γνώσεων στόχου. Στον βιοϊατρικό τομέα, ορισμένες από τις βάσεις γνώσεων-στόχων είναι:
Γιατί θα θέλαμε να συνδέσουμε τις ιατρικές οντότητες με μια στοχευμένη βάση γνώσεων; Ο κύριος λόγος είναι ότι μας βοηθά να αντιμετωπίσουμε την αποσαφήνιση οντοτήτων. Για παράδειγμα, δεν θέλουμε ξεχωριστές οντότητες στο γράφημα που αντιπροσωπεύουν το ασκορβικό οξύ και τη βιταμίνη C, καθώς οι ειδικοί του τομέα μπορούν να σας πουν ότι είναι το ίδιο πράγμα. Ο δευτερεύων λόγος είναι ότι με την αντιστοίχιση των εννοιών σε μια βάση γνώσεων στόχου, μπορούμε να εμπλουτίσουμε το μοντέλο γραφήματος λαμβάνοντας πληροφορίες σχετικά με τις αντιστοιχισμένες έννοιες από τη βάση γνώσεων στόχου. Εάν χρησιμοποιήσουμε ξανά το παράδειγμα ασκορβικού οξέος, θα μπορούσαμε εύκολα να ανακτήσουμε πρόσθετες πληροφορίες από τη βάση δεδομένων CHEBI εάν γνωρίζουμε ήδη CHEBI id.
Διαθέσιμα δεδομένα εμπλουτισμού σχετικά με το ασκορβικό οξύ στον ιστότοπο του CHEBI. Όλο το περιεχόμενο στον ιστότοπο είναι διαθέσιμο κάτω από Άδεια CC BY 4.0. Εικόνα από τον συγγραφέα.
Αναζητώ μια αξιοπρεπή προεκπαιδευμένη βιοϊατρική οντότητα ανοιχτού κώδικα που να συνδέεται εδώ και αρκετό καιρό. Πολλά μοντέλα NLP επικεντρώνονται στην εξαγωγή μόνο ενός συγκεκριμένου υποσυνόλου ιατρικών εννοιών όπως γονίδια ή ασθένειες. Είναι ακόμη πιο σπάνιο να βρεθεί ένα μοντέλο που να ανιχνεύει τις περισσότερες ιατρικές έννοιες και να τις συνδέει με μια στοχευόμενη βάση γνώσεων. Ευτυχώς έπεσα πάνω BERN[1], ένα εργαλείο αναγνώρισης νευρωνικών βιοϊατρικών οντοτήτων και κανονικοποίησης πολλαπλών τύπων. Αν καταλαβαίνω καλά, είναι ένα βελτιστοποιημένο μοντέλο BioBert με διάφορα επώνυμα μοντέλα που συνδέουν οντότητες ενσωματωμένα για χαρτογράφηση εννοιών σε βάσεις γνώσεων βιοϊατρικών στόχων. Όχι μόνο αυτό, αλλά παρέχουν επίσης ένα δωρεάν τελικό σημείο REST, οπότε δεν χρειάζεται να αντιμετωπίσουμε τον πονοκέφαλο της εφαρμογής των εξαρτήσεων και του μοντέλου. Η βιοϊατρική οπτικοποίηση αναγνώρισης οντοτήτων με το όνομα που χρησιμοποίησα παραπάνω δημιουργήθηκε χρησιμοποιώντας το μοντέλο BERN, επομένως γνωρίζουμε ότι ανιχνεύει γονίδια, ασθένειες, φάρμακα, είδη, μεταλλάξεις και μονοπάτια στο κείμενο.
Δυστυχώς, το μοντέλο BERN δεν εκχωρεί αναγνωριστικά βάσης γνώσεων στόχου σε όλες τις έννοιες. Ετοίμασα λοιπόν ένα σενάριο που αρχικά εξετάζει εάν δίνεται ένα διακριτό αναγνωριστικό για μια έννοια, και αν δεν είναι, θα χρησιμοποιεί το όνομα της οντότητας ως αναγνωριστικό. Θα υπολογίσουμε επίσης το sha256 του κειμένου των προτάσεων για να προσδιορίσουμε πιο εύκολα συγκεκριμένες προτάσεις αργότερα όταν θα κάνουμε εξαγωγή σχέσεων.
import hashlib def query_raw(text, url="https://bern.korea.ac.kr/plain"): """Biomedical entity linking API""" return requests.post(url, data={'sample_text': text}).json() entity_list = []
# The last sentence is invalid
for s in sentences[:-1]: entity_list.append(query_raw(s)) parsed_entities = []
for entities in entity_list: e = [] # If there are not entities in the text if not entities.get('denotations'): parsed_entities.append({'text':entities['text'], 'text_sha256': hashlib.sha256(entities['text'].encode('utf-8')).hexdigest()}) continue for entity in entities['denotations']: other_ids = [id for id in entity['id'] if not id.startswith("BERN")] entity_type = entity['obj'] entity_name = entities['text'][entity['span']['begin']:entity['span']['end']] try: entity_id = [id for id in entity['id'] if id.startswith("BERN")][0] except IndexError: entity_id = entity_name e.append({'entity_id': entity_id, 'other_ids': other_ids, 'entity_type': entity_type, 'entity': entity_name}) parsed_entities.append({'entities':e, 'text':entities['text'], 'text_sha256': hashlib.sha256(entities['text'].encode('utf-8')).hexdigest()})
Έχω επιθεωρήσει τα αποτελέσματα της σύνδεσης της ονομαζόμενης οντότητας και, όπως ήταν αναμενόμενο, δεν είναι τέλεια. Για παράδειγμα, δεν προσδιορίζει τα βλαστοκύτταρα ως ιατρική έννοια. Από την άλλη πλευρά, ανίχνευσε μια μοναδική οντότητα που ονομάζεται «καρδιά, εγκέφαλος, νεύρα και νεφρός». Ωστόσο, το BERN εξακολουθεί να είναι το καλύτερο βιοϊατρικό μοντέλο ανοιχτού κώδικα που θα μπορούσα να βρω κατά τη διάρκεια της έρευνάς μου.
Κατασκευάστε ένα γράφημα γνώσης
Πριν εξετάσουμε τις τεχνικές εξαγωγής σχέσεων, θα κατασκευάσουμε ένα γράφημα βιοϊατρικής γνώσης χρησιμοποιώντας μόνο οντότητες και θα εξετάσουμε τις πιθανές εφαρμογές. Όπως αναφέρθηκε, έχω ετοιμάσει ένα Σημειωματάριο Google Colab που μπορείτε να χρησιμοποιήσετε για να ακολουθήσετε τα παραδείγματα κώδικα σε αυτήν την ανάρτηση. Για να αποθηκεύσουμε το γράφημά μας, θα χρησιμοποιήσουμε το Neo4j. Δεν χρειάζεται να ασχοληθείτε με την προετοιμασία ενός τοπικού περιβάλλοντος Neo4j. Αντίθετα, μπορείτε να χρησιμοποιήσετε μια δωρεάν παρουσία του Neo4j Sandbox.
Ξεκινήστε το Κενό έργο στο sandbox και αντιγράψτε τα στοιχεία σύνδεσης στο σημειωματάριο Colab.
Λεπτομέρειες σύνδεσης Neo4j Sandbox. Εικόνα από τον συγγραφέα.
Τώρα μπορείτε να προχωρήσετε και να προετοιμάσετε τη σύνδεση Neo4j στο σημειωματάριο.
from neo4j import GraphDatabase
import pandas as pd host = 'bolt://3.236.182.55:7687'
user = 'neo4j'
password = 'hydrometer-ditches-windings'
driver = GraphDatabase.driver(host,auth=(user, password)) def neo4j_query(query, params=None): with driver.session() as session: result = session.run(query, params) return pd.DataFrame([r.values() for r in result], columns=result.keys())
Θα ξεκινήσουμε εισάγοντας τον συγγραφέα και το άρθρο στο γράφημα. Ο κόμβος του άρθρου θα περιέχει μόνο τον τίτλο.
Εάν ανοίξετε το πρόγραμμα περιήγησης Neo4j, θα πρέπει να δείτε το παρακάτω γράφημα.
Εικόνα από τον συγγραφέα.
Μπορείτε να εισαγάγετε τις προτάσεις και τις αναφερόμενες οντότητες εκτελώντας το ακόλουθο ερώτημα Cypher:
neo4j_query("""
MATCH (a:Article)
UNWIND $data as row
MERGE (s:Sentence{id:row.text_sha256})
SET s.text = row.text
MERGE (a)-[:HAS_SENTENCE]->(s)
WITH s, row.entities as entities
UNWIND entities as entity
MERGE (e:Entity{id:entity.entity_id})
ON CREATE SET e.other_ids = entity.other_ids, e.name = entity.entity, e.type = entity.entity_type
MERGE (s)-[m:MENTIONS]->(e)
ON CREATE SET m.count = 1
ON MATCH SET m.count = m.count + 1
""", {'data': parsed_entities})
Μπορείτε να εκτελέσετε το ακόλουθο ερώτημα Cypher για να επιθεωρήσετε το κατασκευασμένο γράφημα:
MATCH p=(a:Article)-[:HAS_SENTENCE]->()-[:MENTIONS]->(e:Entity)
RETURN p LIMIT 25
Εάν έχετε εισαγάγει σωστά τα δεδομένα, θα πρέπει να δείτε μια παρόμοια απεικόνιση.
Η εξαγωγή οντοτήτων αποθηκεύεται ως γράφημα. Εικόνα από τον συγγραφέα.
Εφαρμογές γραφημάτων γνώσης
Ακόμη και χωρίς τη ροή εξαγωγής σχέσης, υπάρχουν ήδη μερικές περιπτώσεις χρήσης για το γράφημά μας.
Μηχανή αναζήτησης
Θα μπορούσαμε να χρησιμοποιήσουμε το γράφημά μας ως μηχανή αναζήτησης. Για παράδειγμα, μπορείτε να χρησιμοποιήσετε το ακόλουθο ερώτημα Cypher για να βρείτε προτάσεις ή άρθρα που αναφέρουν μια συγκεκριμένη ιατρική οντότητα.
MATCH (e:Entity)<-[:MENTIONS]-(s:Sentence)
WHERE e.name = "autoimmune diseases"
RETURN s.text as result
Αποτελέσματα
Εικόνα από τον συγγραφέα.
Ανάλυση συνεμφάνισης
Η δεύτερη επιλογή είναι η ανάλυση συν-συμβάντος. Θα μπορούσατε να ορίσετε τη συνύπαρξη μεταξύ ιατρικών οντοτήτων εάν εμφανίζονται στην ίδια πρόταση ή άρθρο. Βρήκα ένα άρθρο[2] που χρησιμοποιεί το δίκτυο ιατρικής συν-εμφάνισης για να προβλέψει νέες πιθανές συνδέσεις μεταξύ ιατρικών οντοτήτων.
Θα μπορούσατε να χρησιμοποιήσετε το ακόλουθο ερώτημα Cypher για να βρείτε οντότητες που συχνά συνυπάρχουν στην ίδια πρόταση.
MATCH (e1:Entity)<-[:MENTIONS]-()-[:MENTIONS]->(e2:Entity)
MATCH (e1:Entity)<-[:MENTIONS]-()-[:MENTIONS]->(e2:Entity)
WHERE id(e1) < id(e2)
RETURN e1.name as entity1, e2.name as entity2, count(*) as cooccurrence
ORDER BY cooccurrence
DESC LIMIT 3
Αποτελέσματα
οντότητα 1
οντότητα 2
συνυπάρχουν
δερματικές παθήσεις
διαβητικά έλκη
2
χρόνιες πληγές
διαβητικά έλκη
2
δερματικές παθήσεις
χρόνιες πληγές
2
Προφανώς, τα αποτελέσματα θα ήταν καλύτερα αν αναλύαμε χιλιάδες ή περισσότερα άρθρα.
Ελέγξτε την εμπειρία του συγγραφέα
Θα μπορούσατε επίσης να χρησιμοποιήσετε αυτό το γράφημα για να βρείτε την τεχνογνωσία του συγγραφέα εξετάζοντας τις ιατρικές οντότητες για τις οποίες γράφουν πιο συχνά. Με αυτές τις πληροφορίες, θα μπορούσατε να προτείνετε και μελλοντικές συνεργασίες.
Εκτελέστε το ακόλουθο ερώτημα Cypher για να ελέγξετε ποιες ιατρικές οντότητες ανέφερε ο μοναδικός μας συγγραφέας στην ερευνητική εργασία.
MATCH (a:Author)-[:WROTE]->()-[:HAS_SENTENCE]->()-[:MENTIONS]->(e:Entity)
RETURN a.name as author, e.name as entity,
MATCH (a:Author)-[:WROTE]->()-[:HAS_SENTENCE]->()-[:MENTIONS]->(e:Entity)
RETURN a.name as author, e.name as entity, count(*) as count
ORDER BY count DESC
LIMIT 5
Αποτελέσματα
συγγραφέας
οντότητα
μετράνε
Mohammadreza Ahmadi
κολλαγόνο
9
Mohammadreza Ahmadi
εγκαύματα
4
Mohammadreza Ahmadi
δερματικές παθήσεις
4
Mohammadreza Ahmadi
ένζυμα κολλαγενάσης
2
Mohammadreza Ahmadi
Βουλώδης επιδερμόλυση
2
Εξαγωγή σχέσης
Τώρα θα προσπαθήσουμε να εξαγάγουμε σχέσεις μεταξύ ιατρικών εννοιών. Από την εμπειρία μου, η εξαγωγή των σχέσεων είναι τουλάχιστον μια τάξη μεγέθους δυσκολότερη από την εξαγωγή της ονομαστικής οντότητας. Εάν δεν πρέπει να περιμένετε τέλεια αποτελέσματα με τη σύνδεση επώνυμης οντότητας, τότε σίγουρα μπορείτε να περιμένετε κάποια λάθη με την τεχνική εξαγωγής σχέσεων.
Έψαχνα για διαθέσιμα μοντέλα εξαγωγής βιοϊατρικών σχέσεων, αλλά δεν βρήκα τίποτα που να λειτουργεί εκτός συσκευασίας ή να μην απαιτεί λεπτομέρεια. Φαίνεται ότι το πεδίο της εξαγωγής σχέσεων βρίσκεται στην αιχμή και ελπίζουμε ότι θα δούμε περισσότερη προσοχή γι 'αυτό στο μέλλον. Δυστυχώς, δεν είμαι ειδικός στο NLP, οπότε απέφυγα να τελειοποιήσω το δικό μου μοντέλο. Αντίθετα, θα χρησιμοποιήσουμε τον εξαγωγέα μηδενικής σχέσης με βάση το χαρτί Εξερευνώντας το όριο μηδενικών βολών του FewRel[3]. Αν και δεν θα συνιστούσα να βάλετε αυτό το μοντέλο στην παραγωγή, είναι αρκετά καλό για μια απλή επίδειξη. Το μοντέλο είναι διαθέσιμο στο Πρόσωπο αγκαλιάς, οπότε δεν χρειάζεται να ασχοληθούμε με την εκπαίδευση ή τη ρύθμιση του μοντέλου.
from transformers import AutoTokenizer
from zero_shot_re import RelTaggerModel, RelationExtractor model = RelTaggerModel.from_pretrained("fractalego/fewrel-zero-shot")
tokenizer = AutoTokenizer.from_pretrained("bert-large-uncased-whole-word-masking-finetuned-squad")
relations = ['associated', 'interacts']
extractor = RelationExtractor(model, tokenizer, relations)
Με τον εξαγωγέα σχέσεων μηδενικής βολής, μπορείτε να ορίσετε ποιες σχέσεις θα θέλατε να ανιχνεύσετε. Σε αυτό το παράδειγμα, χρησιμοποίησα το συσχετισμένη και διαδραστικός σχέσεις. Έχω δοκιμάσει επίσης πιο συγκεκριμένους τύπους σχέσεων, όπως θεραπείες, αιτίες και άλλους, αλλά τα αποτελέσματα δεν ήταν εξαιρετικά.
Με αυτό το μοντέλο, πρέπει να ορίσετε ανάμεσα σε ποια ζεύγη οντοτήτων θα θέλατε να ανιχνεύσετε σχέσεις. Θα χρησιμοποιήσουμε τα αποτελέσματα της ονομαζόμενης οντότητας που συνδέεται ως είσοδο στη διαδικασία εξαγωγής σχέσης. Αρχικά, βρίσκουμε όλες τις προτάσεις όπου αναφέρονται δύο ή περισσότερες οντότητες και στη συνέχεια τις εκτελούμε μέσω του μοντέλου εξαγωγής σχέσεων για να εξαγάγουμε τυχόν συνδέσεις. Έχω ορίσει επίσης μια τιμή κατωφλίου 0.85, που σημαίνει ότι εάν ένα μοντέλο προβλέπει μια σύνδεση μεταξύ οντοτήτων με πιθανότητα μικρότερη από 0.85, θα αγνοήσουμε την πρόβλεψη.
import itertools
# Candidate sentence where there is more than a single entity present
candidates = [s for s in parsed_entities if (s.get('entities')) and (len(s['entities']) > 1)]
predicted_rels = []
for c in candidates: combinations = itertools.combinations([{'name':x['entity'], 'id':x['entity_id']} for x in c['entities']], 2) for combination in list(combinations): try: ranked_rels = extractor.rank(text=c['text'].replace(",", " "), head=combination[0]['name'], tail=combination[1]['name']) # Define threshold for the most probable relation if ranked_rels[0][1] > 0.85: predicted_rels.append({'head': combination[0]['id'], 'tail': combination[1]['id'], 'type':ranked_rels[0][0], 'source': c['text_sha256']}) except: pass # Store relations to Neo4j
neo4j_query("""
UNWIND $data as row
MATCH (source:Entity {id: row.head})
MATCH (target:Entity {id: row.tail})
MATCH (text:Sentence {id: row.source})
MERGE (source)-[:REL]->(r:Relation {type: row.type})-[:REL]->(target)
MERGE (text)-[:MENTIONS]->(r)
""", {'data': predicted_rels})
Αποθηκεύουμε τις σχέσεις καθώς και το κείμενο προέλευσης που χρησιμοποιείται για την εξαγωγή αυτής της σχέσης στο γράφημα.
Εξήχθησαν σχέσεις αποθηκευμένες σε ένα γράφημα. Εικόνα από τον συγγραφέα.
Μπορείτε να εξετάσετε τις εξαγόμενες σχέσεις μεταξύ οντοτήτων και του κειμένου προέλευσης με το ακόλουθο ερώτημα Cypher:
MATCH (s:Entity)-[:REL]->(r:Relation)-[:REL]->(t:Entity), (r)<-[:MENTIONS]-(st:Sentence)
RETURN s.name as source_entity, t.name as target_entity, r.type as type, st.text as source_text
Αποτελέσματα
Εικόνα από τον συγγραφέα.
Όπως αναφέρθηκε, το μοντέλο NLP που έχω χρησιμοποιήσει για την εξαγωγή σχέσεων δεν είναι τέλειο, και επειδή δεν είμαι γιατρός, δεν ξέρω πόσες συνδέσεις έχασε. Ωστόσο, αυτά που εντόπισε φαίνονται λογικά.
Εμπλουτισμός εξωτερικής βάσης δεδομένων
Όπως ανέφερα προηγουμένως, μπορούμε ακόμα να χρησιμοποιήσουμε τις εξωτερικές βάσεις δεδομένων όπως το CHEBI ή το MESH για να εμπλουτίσουμε το γράφημά μας. Για παράδειγμα, το γράφημά μας περιέχει μια ιατρική οντότητα Βουλώδης επιδερμόλυση και γνωρίζουμε επίσης το MeSH id του.
Μπορείτε να ανακτήσετε το MeSH id του Epidermolysis bullosa με το ακόλουθο ερώτημα:
MATCH (e:Entity)
WHERE e.name = "Epidermolysis bullosa"
RETURN e.name as entity, e.other_ids as other_ids
Θα μπορούσατε να προχωρήσετε και να επιθεωρήσετε το MeSH για να βρείτε διαθέσιμες πληροφορίες:
Στιγμιότυπο οθόνης από τον συγγραφέα. Τα δεδομένα προέρχονται από την Εθνική Βιβλιοθήκη Ιατρικής των ΗΠΑ.
Ακολουθεί ένα στιγμιότυπο οθόνης των διαθέσιμων πληροφοριών στον ιστότοπο του MeSH για το Epidermolysis bullosa. Όπως αναφέρθηκε, δεν είμαι γιατρός, επομένως δεν ξέρω ακριβώς ποιος θα ήταν ο καλύτερος τρόπος για να μοντελοποιήσω αυτές τις πληροφορίες σε ένα γράφημα. Ωστόσο, θα σας δείξω πώς να ανακτήσετε αυτές τις πληροφορίες στο Neo4j χρησιμοποιώντας τη διαδικασία apoc.load.json για να ανακτήσετε τις πληροφορίες από το τελικό σημείο MeSH REST. Στη συνέχεια, μπορείτε να ζητήσετε από έναν ειδικό τομέα να σας βοηθήσει να μοντελοποιήσετε αυτές τις πληροφορίες.
Το ερώτημα Cypher για τη λήψη των πληροφοριών από το τελικό σημείο MeSH REST είναι:
MATCH (e:Entity)
WHERE e.name = "Epidermolysis bullosa"
WITH e, [id in e.other_ids WHERE id contains "MESH" | split(id,":")[1]][0] as meshId
CALL apoc.load.json("https://id.nlm.nih.gov/mesh/lookup/details?descriptor=" + meshId) YIELD value
RETURN value
Γράφημα γνώσης ως εισαγωγή δεδομένων μηχανικής εκμάθησης
Ως τελική σκέψη, θα σας καθοδηγήσω γρήγορα στο πώς θα μπορούσατε να χρησιμοποιήσετε το γράφημα της βιοϊατρικής γνώσης ως είσοδο σε μια ροή εργασιών μηχανικής μάθησης. Τα τελευταία χρόνια, έχει γίνει πολλή έρευνα και πρόοδος στον τομέα της ενσωμάτωσης κόμβων. Τα μοντέλα ενσωμάτωσης κόμβων μεταφράζουν την τοπολογία του δικτύου σε χώρο ενσωμάτωσης.
Ας υποθέσουμε ότι κατασκευάσατε ένα γράφημα βιοϊατρικής γνώσης που περιέχει ιατρικές οντότητες και έννοιες, τις σχέσεις τους και τον εμπλουτισμό τους από διάφορες ιατρικές βάσεις δεδομένων. Θα μπορούσατε να χρησιμοποιήσετε τεχνικές ενσωμάτωσης κόμβων για να μάθετε τις αναπαραστάσεις κόμβων, οι οποίες είναι διανύσματα σταθερού μήκους, και να τις εισαγάγετε στη ροή εργασιών μηχανικής εκμάθησης. Διάφορες εφαρμογές χρησιμοποιούν αυτήν την προσέγγιση, που κυμαίνονται από τον επαναπροσδιορισμό του φαρμάκου έως τις προβλέψεις παρενεργειών ή ανεπιθύμητων ενεργειών. Βρήκα μια ερευνητική εργασία που χρησιμοποιεί σύνδεση πρόβλεψης για πιθανές θεραπείες νέων ασθενειών[4].
Συμπέρασμα
Ο βιοϊατρικός τομέας είναι ένα χαρακτηριστικό παράδειγμα όπου εφαρμόζονται γραφήματα γνώσης. Υπάρχουν πολλές εφαρμογές που κυμαίνονται από απλές μηχανές αναζήτησης έως πιο περίπλοκες ροές εργασιών μηχανικής εκμάθησης. Ας ελπίσουμε ότι διαβάζοντας αυτήν την ανάρτηση ιστολογίου, βρήκατε μερικές ιδέες για το πώς θα μπορούσατε να χρησιμοποιήσετε γραφήματα βιοϊατρικής γνώσης για να υποστηρίξετε τις εφαρμογές σας. Μπορείτε να ξεκινήσετε ένα δωρεάν Neo4j Sandbox και ξεκινήστε την εξερεύνηση σήμερα.
Όπως πάντα, ο κωδικός είναι διαθέσιμος στο GitHub.
αναφορές
[1] D. Kim et αϊ., «A Neural Named Entity Recognition and Multi-Type Normalization Tool for Biomedical Text Mining», στο Πρόσβαση IEEE, τόμ. 7, σελ. 73729–73740, 2019, doi: 10.1109/ACCESS.2019.2920708.
[2] Kastrin A, Rindflesch TC, Hristovski D. Πρόβλεψη σύνδεσης σε δίκτυο συν-συμβάντος MeSH: προκαταρκτικά αποτελέσματα. Stud Health Technol Inform. 2014; 205:579–83. PMID: 25160252.
[3] Cetoli, A. (2020). Εξερευνώντας το όριο μηδενικών βολών του FewRel. Σε Πρακτικά 28ου Διεθνούς Συνεδρίου Υπολογιστικής Γλωσσολογίας (σελ. 1447–1451). Διεθνής Επιτροπή Υπολογιστικής Γλωσσολογίας.
[4] Zhang, R., Hristovski, D., Schutte, D., Kastrin, A., Fiszman, M., & Kilicoglu, H. (2021). Επαναχρησιμοποίηση φαρμάκων για τον COVID-19 μέσω συμπλήρωσης γραφήματος γνώσης. Journal of Biomedical Informatics, 115, 103696.
Αυτό το άρθρο δημοσιεύθηκε αρχικά στις Προς την επιστήμη των δεδομένων και εκδόθηκε εκ νέου στο TOPBOTS με την άδεια του συντάκτη.
Σας αρέσει αυτό το άρθρο; Εγγραφείτε για περισσότερες ενημερώσεις AI.
Θα σας ενημερώσουμε όταν κυκλοφορούμε περισσότερη τεχνική εκπαίδευση.