Η οικοδόμηση μιας πλατφόρμας δεδομένων περιλαμβάνει διάφορες προσεγγίσεις, η καθεμία με το μοναδικό συνδυασμό πολυπλοκοτήτων και λύσεων. Μια σύγχρονη πλατφόρμα δεδομένων συνεπάγεται διατήρηση δεδομένων σε πολλαπλά επίπεδα, στόχευση διαφορετικών δυνατοτήτων πλατφόρμας, όπως υψηλή απόδοση, ευκολία ανάπτυξης, οικονομική απόδοση και χαρακτηριστικά DataOps όπως CI/CD, lineage και δοκιμές μονάδων. Σε αυτήν την ανάρτηση, εμβαθύνουμε σε μια μελέτη περίπτωσης για μια περίπτωση χρήσης λιανικής, διερευνώντας πώς το Εργαλείο δημιουργίας δεδομένων (dbt) χρησιμοποιήθηκε αποτελεσματικά σε περιβάλλον AWS για τη δημιουργία μιας υψηλής απόδοσης, αποτελεσματικής και σύγχρονης πλατφόρμας δεδομένων.
Το dbt είναι ένα εργαλείο γραμμής εντολών ανοιχτού κώδικα που επιτρέπει σε αναλυτές δεδομένων και μηχανικούς να μετασχηματίζουν τα δεδομένα στις αποθήκες τους πιο αποτελεσματικά. Αυτό το κάνει βοηθώντας τις ομάδες να χειριστούν τις διαδικασίες T στις διαδικασίες ETL (εξαγωγή, μετασχηματισμός και φόρτωση). Επιτρέπει στους χρήστες να γράψουν κώδικα μετασχηματισμού δεδομένων, να τον εκτελέσουν και να δοκιμάσουν την έξοδο, όλα μέσα στο πλαίσιο που παρέχει. Το dbt σάς δίνει τη δυνατότητα να γράψετε δηλώσεις επιλογής SQL και, στη συνέχεια, διαχειρίζεται τη μετατροπή αυτών των δηλώσεων επιλογής σε πίνακες ή προβολές στο Amazon RedShift.
Περίπτωση χρήσης
Ο όμιλος Enterprise Data Analytics ενός μεγάλου λιανοπωλητή κοσμημάτων ξεκίνησε το ταξίδι του στο cloud με το AWS το 2021. Στο πλαίσιο της πρωτοβουλίας εκσυγχρονισμού του cloud, προσπάθησαν να μετεγκαταστήσουν και να εκσυγχρονίσουν την παλαιού τύπου πλατφόρμα δεδομένων τους. Ο στόχος ήταν να ενισχύσουν τις αναλυτικές τους ικανότητες και να βελτιώσουν την προσβασιμότητα των δεδομένων, διασφαλίζοντας ταυτόχρονα γρήγορο χρόνο στην αγορά και υψηλή ποιότητα δεδομένων, όλα με χαμηλό συνολικό κόστος ιδιοκτησίας (TCO) και χωρίς ανάγκη για πρόσθετα εργαλεία ή άδειες.
Το dbt αναδείχθηκε ως η τέλεια επιλογή για αυτόν τον μετασχηματισμό στο υπάρχον περιβάλλον AWS. Αυτό το δημοφιλές εργαλείο ανοιχτού κώδικα για μετασχηματισμούς αποθήκης δεδομένων κέρδισε άλλα εργαλεία ETL για διάφορους λόγους. Το πλαίσιο που βασίζεται σε SQL της dbt έκανε εύκολη τη μάθηση και επέτρεψε στην υπάρχουσα ομάδα ανάπτυξης να κλιμακωθεί γρήγορα. Το εργαλείο πρόσφερε επίσης επιθυμητές λειτουργίες εκτός συσκευασίας, όπως η γενεαλογία δεδομένων, η τεκμηρίωση και η δοκιμή μονάδας. Ένα κρίσιμο πλεονέκτημα του dbt έναντι των αποθηκευμένων διαδικασιών ήταν ο διαχωρισμός του κώδικα από τα δεδομένα—σε αντίθεση με τις αποθηκευμένες διαδικασίες, το dbt δεν αποθηκεύει τον κώδικα στην ίδια τη βάση δεδομένων. Αυτός ο διαχωρισμός απλοποιεί περαιτέρω τη διαχείριση δεδομένων και βελτιώνει τη συνολική απόδοση του συστήματος.
Ας εξερευνήσουμε την αρχιτεκτονική και ας μάθουμε πώς να δημιουργήσουμε αυτήν την περίπτωση χρήσης χρησιμοποιώντας τις υπηρεσίες AWS Cloud.
Επισκόπηση λύσεων
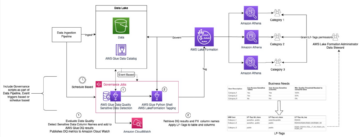
Η ακόλουθη αρχιτεκτονική δείχνει τη διοχέτευση δεδομένων που έχει δημιουργηθεί σε dbt για τη διαχείριση της διαδικασίας ETL της αποθήκης δεδομένων Redshift.
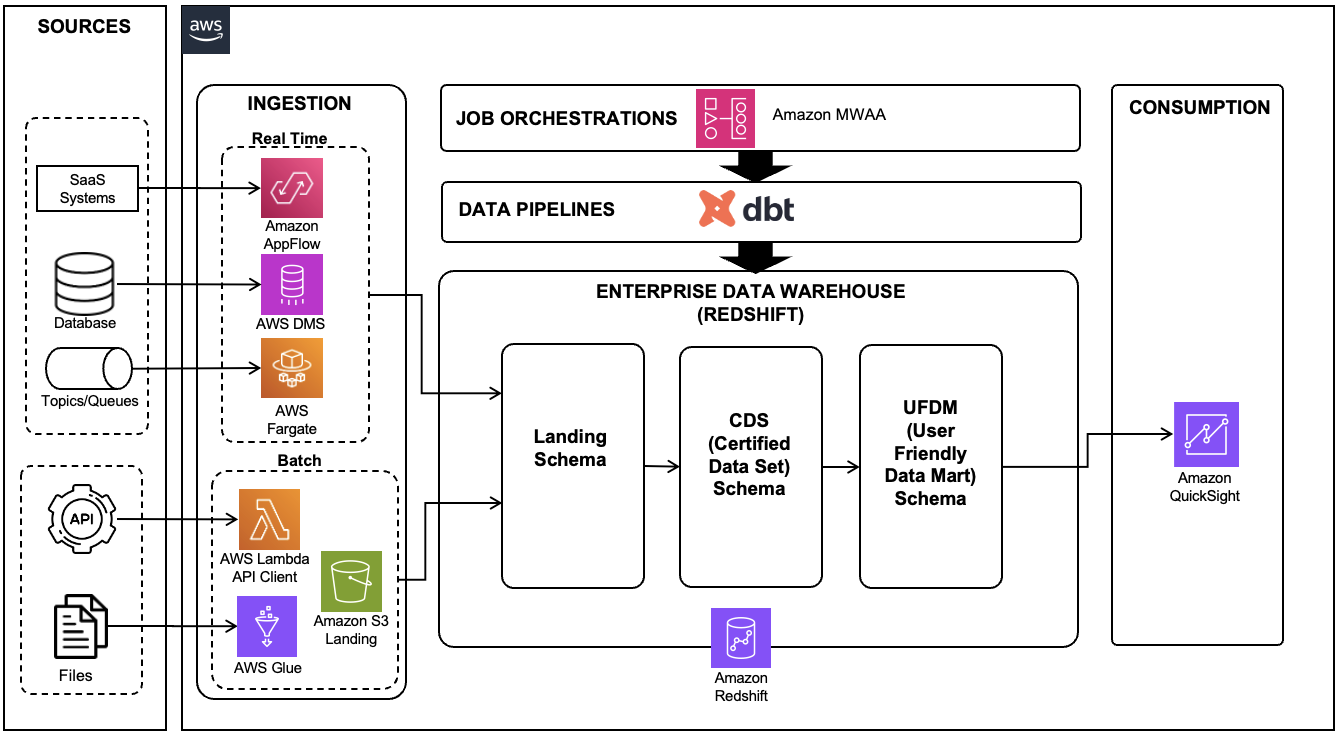
Εικόνα 1 : Σύγχρονη πλατφόρμα δεδομένων που χρησιμοποιεί AWS Data Services και dbt
Αυτή η αρχιτεκτονική αποτελείται από τις ακόλουθες βασικές υπηρεσίες και εργαλεία:
- Amazon RedShift χρησιμοποιήθηκε ως αποθήκη δεδομένων για την πλατφόρμα δεδομένων, αποθήκευση και επεξεργασία τεράστιων ποσοτήτων δομημένων και ημιδομημένων δεδομένων
- Amazon QuickSight χρησίμευσε ως εργαλείο επιχειρηματικής ευφυΐας (BI), επιτρέποντας στην επιχειρηματική ομάδα να δημιουργεί αναλυτικές αναφορές και πίνακες εργαλείων για διάφορες επιχειρηματικές πληροφορίες
- Υπηρεσία μετεγκατάστασης βάσης δεδομένων AWS (AWS DMS) χρησιμοποιήθηκε για την εκτέλεση αντιγραφής σύλληψης δεδομένων αλλαγής (CDC) από διάφορες βάσεις δεδομένων συναλλαγών προέλευσης
- Κόλλα AWS τέθηκε σε λειτουργία, φορτώνοντας αρχεία από τη θέση SFTP στο Απλή υπηρεσία αποθήκευσης Amazon (Amazon S3) κάδος προσγείωσης και στη συνέχεια στο σχήμα προσγείωσης Redshift
- AWS Lambda λειτουργούσε ως πρόγραμμα πελάτη, καλώντας API τρίτων και φορτώνοντας τα δεδομένα σε πίνακες Redshift
- AWS Fargate, μια υπηρεσία διαχείρισης κοντέινερ χωρίς διακομιστή, χρησιμοποιήθηκε για την ανάπτυξη της εφαρμογής καταναλωτή για ουρές πηγής και θέματα
- Ροές εργασίας που διαχειρίζεται η Amazon για ροή αέρα Apache (Amazon MWAA) χρησιμοποιήθηκε για την ενορχήστρωση διαφορετικών εργασιών των αγωγών dbt
- dbt, ένα εργαλείο ανοιχτού κώδικα, χρησιμοποιήθηκε για τη σύνταξη αγωγών δεδομένων που βασίζονται σε SQL για δεδομένα που είναι αποθηκευμένα στο Amazon Redshift, διευκολύνοντας πολύπλοκους μετασχηματισμούς και βελτιώνοντας τις δυνατότητες μοντελοποίησης δεδομένων
Ας ρίξουμε μια πιο προσεκτική ματιά σε κάθε στοιχείο και πώς αλληλεπιδρούν στη συνολική αρχιτεκτονική για να μετατρέψουμε τα ακατέργαστα δεδομένα σε διορατικές πληροφορίες.
Πηγές δεδομένων
Ως μέρος αυτής της πλατφόρμας δεδομένων, λαμβάνουμε δεδομένα από διαφορετικές και ποικίλες πηγές δεδομένων, όπως:
- Βάσεις δεδομένων συναλλαγών – Πρόκειται για ενεργές βάσεις δεδομένων που αποθηκεύουν δεδομένα σε πραγματικό χρόνο από διάφορες εφαρμογές. Τα δεδομένα συνήθως καλύπτουν όλες τις συναλλαγές και τις λειτουργίες στις οποίες εμπλέκεται η επιχείρηση.
- Ουρές και θέματα – Οι ουρές και τα θέματα προέρχονται από διάφορες εφαρμογές ενοποίησης που δημιουργούν δεδομένα σε πραγματικό χρόνο. Αντιπροσωπεύουν μια στιγμιαία ροή πληροφοριών που μπορεί να χρησιμοποιηθεί για ανάλυση και λήψη αποφάσεων σε πραγματικό χρόνο.
- API τρίτων - Αυτά παρέχουν αναλυτικά στοιχεία και δεδομένα ερευνών που σχετίζονται με ιστότοπους ηλεκτρονικού εμπορίου. Αυτό θα μπορούσε να περιλαμβάνει λεπτομέρειες όπως μετρήσεις επισκεψιμότητας, συμπεριφορά χρήστη, ποσοστά μετατροπών, σχόλια πελατών και άλλα.
- Επίπεδα αρχεία – Άλλα συστήματα παρέχουν δεδομένα με τη μορφή επίπεδων αρχείων διαφορετικών μορφών. Αυτά τα αρχεία, που είναι αποθηκευμένα σε μια θέση SFTP, ενδέχεται να περιέχουν εγγραφές, αναφορές, αρχεία καταγραφής ή άλλα είδη πρωτογενών δεδομένων που μπορούν να υποστούν περαιτέρω επεξεργασία και ανάλυση.
Κατάποση δεδομένων
Τα δεδομένα από διάφορες πηγές ομαδοποιούνται σε δύο μεγάλες κατηγορίες: κατάποση σε πραγματικό χρόνο και κατάποση παρτίδας.
Η απορρόφηση σε πραγματικό χρόνο χρησιμοποιεί τις ακόλουθες υπηρεσίες:
- AWS DMS - Το AWS DMS χρησιμοποιείται για τη δημιουργία αγωγών αναπαραγωγής CDC από βάσεις δεδομένων OLTP (Online Transaction Processing). Τα δεδομένα φορτώνονται στο Amazon Redshift σε σχεδόν πραγματικό χρόνο για να διασφαλιστεί ότι οι πιο πρόσφατες πληροφορίες είναι διαθέσιμες για ανάλυση. Μπορείτε επίσης να χρησιμοποιήσετε Ενσωμάτωση Amazon Aurora zero-ETL με το Amazon Redshift για να απορροφήσει δεδομένα απευθείας από τις βάσεις δεδομένων OLTP στο Amazon Redshift.
- Φάργκεϊτ -Το Fargate χρησιμοποιείται για την ανάπτυξη εφαρμογών καταναλωτών Java που απορροφούν δεδομένα από θέματα πηγής και ουρές σε πραγματικό χρόνο. Αυτή η κατανάλωση δεδομένων σε πραγματικό χρόνο μπορεί να βοηθήσει την επιχείρηση να λάβει άμεσες και ενημερωμένες από δεδομένα αποφάσεις. Μπορείτε επίσης να χρησιμοποιήσετε Κατάποση ροής Amazon Redshift για την απορρόφηση δεδομένων από μηχανές ροής όπως Ροές δεδομένων Amazon Kinesis or Amazon Managed Streaming για το Apache Kafka (Amazon MSK) στο Amazon Redshift.
Η μαζική απορρόφηση χρησιμοποιεί τις ακόλουθες υπηρεσίες:
- Λάμδα – Το Lambda χρησιμοποιείται ως πελάτης για την κλήση API τρίτων και τη φόρτωση των δεδομένων που προκύπτουν σε πίνακες Redshift. Αυτή η διαδικασία έχει προγραμματιστεί να εκτελείται καθημερινά, διασφαλίζοντας μια συνεπή παρτίδα φρέσκων δεδομένων για ανάλυση.
- Κόλλα AWS – Το AWS Glue χρησιμοποιείται για τη φόρτωση αρχείων στο Amazon Redshift μέσω της λίμνης δεδομένων S3. Μπορείτε επίσης να χρησιμοποιήσετε λειτουργίες όπως αυτόματη αντιγραφή από το Amazon S3 (λειτουργία σε προεπισκόπηση) για την απορρόφηση δεδομένων από το Amazon S3 στο Amazon Redshift. Ωστόσο, η εστίαση αυτής της ανάρτησης είναι περισσότερο στην επεξεργασία δεδομένων στο Amazon Redshift, παρά στη διαδικασία φόρτωσης δεδομένων. Η απορρόφηση δεδομένων, είτε σε πραγματικό χρόνο είτε ομαδική, αποτελεί τη βάση οποιασδήποτε αποτελεσματικής ανάλυσης δεδομένων, επιτρέποντας στους οργανισμούς να συλλέγουν πληροφορίες από διαφορετικές πηγές και να τις χρησιμοποιούν για διορατική λήψη αποφάσεων.
Αποθήκευση δεδομένων με χρήση του Amazon Redshift
Στο Amazon Redshift, έχουμε δημιουργήσει τρία σχήματα, το καθένα από τα οποία χρησιμεύει ως διαφορετικό επίπεδο στην αρχιτεκτονική δεδομένων:
- Στρώμα προσγείωσης - Αυτό είναι όπου αρχικά προσγειώνονται όλα τα δεδομένα που λαμβάνονται από τις υπηρεσίες μας. Είναι ακατέργαστα, μη επεξεργασμένα δεδομένα απευθείας από την πηγή.
- Επίπεδο πιστοποιημένου συνόλου δεδομένων (CDS) – Αυτό είναι το επόμενο στάδιο, όπου τα δεδομένα από το επίπεδο προσγείωσης υφίστανται καθαρισμό, κανονικοποίηση και συσσώρευση. Τα καθαρισμένα και επεξεργασμένα δεδομένα αποθηκεύονται σε αυτό το πιστοποιημένο σχήμα δεδομένων. Χρησιμεύει ως αξιόπιστη, οργανωμένη πηγή για την ανάλυση δεδομένων κατάντη.
- Φιλικό προς το χρήστη επίπεδο data mart (UFDM) – Αυτό το τελικό επίπεδο χρησιμοποιεί δεδομένα από το επίπεδο CDS για τη δημιουργία πινάκων μάρκετ δεδομένων. Αυτά είναι ειδικά προσαρμοσμένα για να υποστηρίζουν αναφορές BI και πίνακες εργαλείων σύμφωνα με τις επιχειρηματικές απαιτήσεις. Ο στόχος αυτού του επιπέδου είναι να παρουσιάσει τα δεδομένα με τρόπο που είναι πιο χρήσιμος και προσβάσιμος για τους τελικούς χρήστες.
Αυτή η πολυεπίπεδη προσέγγιση στη διαχείριση δεδομένων επιτρέπει την αποτελεσματική και οργανωμένη επεξεργασία δεδομένων, οδηγώντας σε πιο ακριβείς και ουσιαστικές πληροφορίες.
Αγωγός δεδομένων
Το dbt, ένα εργαλείο ανοιχτού κώδικα, μπορεί να εγκατασταθεί στο περιβάλλον AWS και να ρυθμιστεί ώστε να λειτουργεί με το Amazon MWAA. Αποθηκεύουμε τον κωδικό μας σε έναν κάδο S3 και τον ενορχηστρώνουμε χρησιμοποιώντας τα Κατευθυνόμενα Ακυκλικά Γραφήματα (DAGs) της ροής αέρα. Αυτή η ρύθμιση διευκολύνει τις διαδικασίες μετασχηματισμού δεδομένων στο Amazon Redshift μετά την απορρόφηση των δεδομένων στο σχήμα προσγείωσης.
Για να διατηρήσουμε την αρθρωτή δομή και να χειριστούμε συγκεκριμένους τομείς, δημιουργούμε μεμονωμένα έργα dbt. Η φύση της αναφοράς δεδομένων —σε πραγματικό χρόνο ή παρτίδα— επηρεάζει τον τρόπο με τον οποίο ορίζουμε την υλοποίηση του dbt. Για αναφορές σε πραγματικό χρόνο, ορίζουμε την υλοποίηση ως προβολή, η φόρτωση δεδομένων στο σχήμα προσγείωσης χρησιμοποιώντας AWS DMS από ενημερώσεις βάσης δεδομένων ή από καταναλωτές θέματος ή ουράς. Για σωλήνες παρτίδας, ορίζουμε την υλοποίηση ως πίνακα, που επιτρέπει τη φόρτωση δεδομένων από διάφορους τύπους πηγών.
Σε ορισμένες περιπτώσεις, χρειάστηκε να δημιουργήσουμε αγωγούς δεδομένων που εκτείνονται από το σύστημα προέλευσης μέχρι το επίπεδο UFDM. Αυτό μπορεί να επιτευχθεί χρησιμοποιώντας Airflow DAG, τα οποία θα συζητήσουμε περαιτέρω στην επόμενη ενότητα.
Για να ολοκληρώσουμε, αξίζει να αναφέρουμε ότι αναπτύσσουμε μια ιστοσελίδα dbt χρησιμοποιώντας μια συνάρτηση Lambda και ενεργοποιούμε μια διεύθυνση URL για αυτήν τη λειτουργία. Αυτή η ιστοσελίδα χρησιμεύει ως κόμβος τεκμηρίωσης και γενεαλογίας δεδομένων, ενισχύοντας περαιτέρω τη διαφάνεια και την κατανόηση των διαδικασιών δεδομένων μας.
Ενορχήστρωση εργασιών ETL
Στη γραμμή δεδομένων μας, ακολουθούμε αυτά τα βήματα για την ενορχήστρωση εργασιών:
- Δημιουργήστε ένα νέο περιβάλλον Amazon MWAA. Αυτό το περιβάλλον χρησιμεύει ως κεντρικός κόμβος για την ενορχήστρωση των αγωγών δεδομένων μας.
- Εγκαταστήστε το dbt στο νέο περιβάλλον Airflow προσθέτοντας την ακόλουθη εξάρτηση στο περιβάλλον σας
requirements.txt: - Αναπτύξτε DAG με συγκεκριμένες εργασίες που απαιτούν εντολές dbt για να πραγματοποιήσουν τους απαραίτητους μετασχηματισμούς. Αυτό το βήμα περιλαμβάνει τη δόμηση των ροών εργασίας μας με τρόπο που να καταγράφει τις εξαρτήσεις μεταξύ των εργασιών και να διασφαλίζει ότι οι εργασίες εκτελούνται με τη σωστή σειρά. Ο παρακάτω κώδικας δείχνει πώς να ορίσετε τις εργασίες στο DAG:
- Δημιουργήστε DAG που εστιάζουν αποκλειστικά στον μετασχηματισμό dbt. Αυτά τα DAG χειρίζονται τη διαδικασία μετασχηματισμού εντός των αγωγών δεδομένων μας, αξιοποιώντας τη δύναμη του dbt για τη μετατροπή των ακατέργαστων δεδομένων σε πολύτιμες πληροφορίες.
Η παρακάτω εικόνα δείχνει πώς θα εμφανιζόταν αυτή η ροή εργασίας στη διεπαφή χρήστη Airflow . 
- Δημιουργήστε DAG με κόλλα AWS για κατάποση. Αυτά τα DAG χρησιμοποιούν κόλλα AWS για εργασίες απορρόφησης δεδομένων. Το AWS Glue είναι μια πλήρως διαχειριζόμενη υπηρεσία ETL που διευκολύνει την προετοιμασία και τη φόρτωση δεδομένων για ανάλυση. Δημιουργούμε DAG που ενορχηστρώνουν εργασίες AWS Glue για την εξαγωγή δεδομένων από διάφορες πηγές, τη μετατροπή τους και τη φόρτωσή τους στην αποθήκη δεδομένων μας.
Η παρακάτω εικόνα δείχνει πώς θα εμφανιζόταν αυτή η ροή εργασίας στη διεπαφή χρήστη Airflow.

- Δημιουργήστε DAG με το Lambda για κατάποση. Το Lambda μας επιτρέπει να εκτελούμε κώδικα χωρίς παροχή ή διαχείριση διακομιστών. Αυτά τα DAG χρησιμοποιούν συναρτήσεις Lambda για να καλούν API τρίτων και να φορτώνουν δεδομένα στους πίνακες Redshift, οι οποίοι μπορούν να προγραμματιστούν να εκτελούνται σε συγκεκριμένα διαστήματα ή ως απόκριση σε συγκεκριμένα συμβάντα.
Η παρακάτω εικόνα δείχνει πώς θα εμφανιζόταν αυτή η ροή εργασίας στη διεπαφή χρήστη Airflow.

Τώρα έχουμε μια ολοκληρωμένη, καλά ενορχηστρωμένη διαδικασία που χρησιμοποιεί μια ποικιλία υπηρεσιών AWS για να χειριστεί διαφορετικά στάδια της διοχέτευσης δεδομένων μας, από την απορρόφηση έως τη μετατροπή.
Συμπέρασμα
Ο συνδυασμός των υπηρεσιών AWS και του έργου ανοιχτού κώδικα dbt παρέχει μια ισχυρή, ευέλικτη και επεκτάσιμη λύση για τη δημιουργία σύγχρονων πλατφορμών δεδομένων. Είναι ένας τέλειος συνδυασμός διαχειρισιμότητας και λειτουργικότητας, με το εύχρηστο πλαίσιο που βασίζεται σε SQL και λειτουργίες όπως έλεγχοι ποιότητας δεδομένων, διαμορφώσιμοι τύποι φορτίου και λεπτομερής τεκμηρίωση και γενεαλογία. Οι αρχές του "χωριστός κώδικας από τα δεδομένα" και η επαναχρησιμοποίηση του το καθιστούν ένα βολικό και αποτελεσματικό εργαλείο για ένα ευρύ φάσμα χρηστών. Αυτή η πρακτική περίπτωση χρήσης της δημιουργίας μιας πλατφόρμας δεδομένων για έναν οργανισμό λιανικής καταδεικνύει τις τεράστιες δυνατότητες του AWS και του dbt για τον μετασχηματισμό της διαχείρισης δεδομένων και των αναλυτικών στοιχείων, ανοίγοντας το δρόμο για ταχύτερες πληροφορίες και τεκμηριωμένες επιχειρηματικές αποφάσεις.
Για περισσότερες πληροφορίες σχετικά με τη χρήση του dbt με το Amazon Redshift, βλ Διαχειριστείτε μετασχηματισμούς δεδομένων με dbt στο Amazon Redshift.
Σχετικά με τους Συγγραφείς
 Prantik Gachhayat είναι Enterprise Architect στην Infosys με εμπειρία σε διάφορους τομείς τεχνολογίας και επιχειρηματικούς τομείς. Έχει αποδεδειγμένο ιστορικό βοηθώντας μεγάλες επιχειρήσεις να εκσυγχρονίσουν τις ψηφιακές πλατφόρμες και να προσφέρουν σύνθετα προγράμματα μετασχηματισμού. Η Prantik ειδικεύεται στην αρχιτεκτονική των σύγχρονων πλατφορμών δεδομένων και αναλυτικών στοιχείων στο AWS. Η Prantik λατρεύει να εξερευνά τις νέες τάσεις της τεχνολογίας και της αρέσει να μαγειρεύει.
Prantik Gachhayat είναι Enterprise Architect στην Infosys με εμπειρία σε διάφορους τομείς τεχνολογίας και επιχειρηματικούς τομείς. Έχει αποδεδειγμένο ιστορικό βοηθώντας μεγάλες επιχειρήσεις να εκσυγχρονίσουν τις ψηφιακές πλατφόρμες και να προσφέρουν σύνθετα προγράμματα μετασχηματισμού. Η Prantik ειδικεύεται στην αρχιτεκτονική των σύγχρονων πλατφορμών δεδομένων και αναλυτικών στοιχείων στο AWS. Η Prantik λατρεύει να εξερευνά τις νέες τάσεις της τεχνολογίας και της αρέσει να μαγειρεύει.
 Ashutosh Dubey είναι Senior Partner Solutions Architect και Global Tech ηγέτης στην Amazon Web Services με έδρα το New Jersey των ΗΠΑ. Έχει εκτεταμένη εμπειρία με εξειδίκευση στον τομέα Δεδομένων και Αναλύσεων και AIML, συμπεριλαμβανομένης της γενετικής AI, συνέβαλε στην κοινότητα γράφοντας διάφορα τεχνολογικά περιεχόμενα και έχει βοηθήσει εταιρείες του Fortune 500 στο ταξίδι τους στο cloud στο AWS.
Ashutosh Dubey είναι Senior Partner Solutions Architect και Global Tech ηγέτης στην Amazon Web Services με έδρα το New Jersey των ΗΠΑ. Έχει εκτεταμένη εμπειρία με εξειδίκευση στον τομέα Δεδομένων και Αναλύσεων και AIML, συμπεριλαμβανομένης της γενετικής AI, συνέβαλε στην κοινότητα γράφοντας διάφορα τεχνολογικά περιεχόμενα και έχει βοηθήσει εταιρείες του Fortune 500 στο ταξίδι τους στο cloud στο AWS.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://aws.amazon.com/blogs/big-data/create-a-modern-data-platform-using-the-data-build-tool-dbt-in-the-aws-cloud/
- :έχει
- :είναι
- :που
- $UP
- 1
- 100
- 11
- 12
- 17
- 20
- 2021
- 500
- 54
- 7
- 8
- a
- Σχετικα
- προσιτότητα
- προσιτός
- επιτυγχάνεται
- ακριβής
- απέναντι
- ενεργός
- απεριοδικός
- προσθήκη
- Πρόσθετος
- Πλεονέκτημα
- Μετά το
- συσσωμάτωση
- AI
- στοχεύουν
- AIML
- Όλα
- Όλες οι συναλλαγές
- επιτρέπεται
- Επιτρέποντας
- επιτρέπει
- ήδη
- Επίσης
- Amazon
- Amazon υπηρεσίες Web
- μεταξύ των
- Ποσά
- an
- ανάλυση
- Αναλυτές
- Αναλυτικός
- analytics
- αναλύθηκε
- και
- κάθε
- Apache
- APIs
- Εφαρμογή
- εφαρμογές
- πλησιάζω
- προσεγγίσεις
- αρχιτεκτονική
- ΕΙΝΑΙ
- AS
- At
- αυγή
- διαθέσιμος
- AWS
- Κόλλα AWS
- βασίζονται
- βάση
- BE
- ήταν
- συμπεριφορά
- Μείγμα
- μαξιλάρα
- ενίσχυση
- χτίζω
- Κτίριο
- χτισμένο
- επιχείρηση
- επιχειρηματικής ευφυΐας
- by
- κλήση
- κλήση
- CAN
- δυνατότητες
- πιάνω
- συλλαμβάνει
- κουβαλάω
- περίπτωση
- μελέτη περίπτωσης
- κατηγορίες
- CDC
- CDS
- κεντρικός
- ορισμένες
- Πιστοποίηση
- αλλαγή
- έλεγχος
- έλεγχος
- έλεγχοι
- επιλογή
- Καθάρισμα
- πελάτης
- πιο κοντά
- Backup
- υπηρεσίες cloud
- κωδικός
- συνδυασμός
- Ελάτε
- κοινότητα
- Εταιρείες
- συγκρότημα
- πολυπλοκότητα
- συστατικό
- περιεκτικός
- συνεπής
- αποτελείται
- καταναλωτής
- Καταναλωτές
- κατανάλωση
- περιέχουν
- Δοχείο
- περιεχόμενα
- συνέβαλε
- Βολικός
- Μετατροπή
- μετατρέψετε
- μαγείρεμα
- διορθώσει
- Κόστος
- θα μπορούσε να
- δημιουργία
- κρίσιμος
- πελάτης
- DAG
- καθημερινά
- dashboards
- ημερομηνία
- ανάλυση δεδομένων
- Δεδομένα Analytics
- Λίμνη δεδομένων
- διαχείριση δεδομένων
- Πλατφόρμα δεδομένων
- επεξεργασία δεδομένων
- την ποιότητα των δεδομένων
- αποθήκη δεδομένων
- βάση δεδομένων
- βάσεις δεδομένων
- Λήψη Αποφάσεων
- αποφάσεις
- ορίζεται
- παράδοση
- σκάβω
- καταδεικνύει
- εξαρτήσεις
- Εξάρτηση
- παρατάσσω
- λεπτομερής
- καθέκαστα
- Ανάπτυξη
- ομάδα ανάπτυξης
- διαφορετικές
- ψηφιακό
- ψηφιακές πλατφόρμες
- κατευθύνθηκε
- κατευθείαν
- συζητήσουν
- διάφορα
- τεκμηρίωση
- κάνει
- Όχι
- domains
- κάθε
- ευκολία
- εύκολος
- εύκολο στη χρήση
- ηχώ
- ηλεκτρονικού εμπορίου
- Αποτελεσματικός
- αποτελεσματικά
- αποτελεσματικός
- αλλιώς
- ξεκίνησε
- προέκυψαν
- μισθωτών
- ενεργοποιήσετε
- δίνει τη δυνατότητα
- ενεργοποίηση
- περιλαμβάνει
- δεσμεύεται
- Μηχανικοί
- Κινητήρες
- Ενισχύει
- ενίσχυση
- εξασφαλίζω
- εξασφαλίζει
- εξασφαλίζοντας
- Εταιρεία
- επιχειρήσεις
- Περιβάλλον
- εγκατεστημένος
- Αιθέρας (ΕΤΗ)
- εκδηλώσεις
- υφιστάμενα
- εμπειρία
- διερευνήσει
- Εξερευνώντας
- επεκτείνουν
- εκτενής
- Εκτεταμένη εμπειρία
- εκχύλισμα
- διευκολύνει
- διευκολύνοντας
- γρηγορότερα
- Χαρακτηριστικό
- Χαρακτηριστικά
- ανατροφοδότηση
- πεδίο
- Πεδία
- Αρχεία
- τελικός
- ίσια
- εύκαμπτος
- ροή
- Συγκέντρωση
- ακολουθήστε
- Εξής
- Για
- μορφή
- μορφές
- μορφές
- Τύχη
- Πλαίσιο
- φρέσκο
- από
- πλήρως
- λειτουργία
- λειτουργικότητα
- λειτουργίες
- περαιτέρω
- συγκεντρώνουν
- παράγουν
- γενετική
- Παραγωγική τεχνητή νοημοσύνη
- Παγκόσμιο
- γκολ
- γραφικές παραστάσεις
- Group
- είχε
- λαβή
- Αξιοποίηση
- Έχω
- που έχει
- he
- βοήθεια
- βοήθησε
- βοήθεια
- Ψηλά
- υψηλή απόδοση
- Πως
- Πώς να
- Ωστόσο
- http
- HTTPS
- Hub
- if
- εικόνα
- άμεσος
- τεράστια
- βελτίωση
- in
- περιλαμβάνουν
- Συμπεριλαμβανομένου
- ατομικές
- πληροφορίες
- ενημερώνεται
- Infosys
- αρχικά
- Πρωτοβουλία
- διορατικός
- ιδέες
- εγκαθιστώ
- εγκατασταθεί
- περιπτώσεις
- ολοκλήρωση
- Νοημοσύνη
- αλληλεπιδρούν
- σε
- περιλαμβάνει
- IT
- ΤΟΥ
- εαυτό
- Java
- Φανέλα
- κοσμήματα
- Δουλειά
- Θέσεις εργασίας
- ταξίδι
- jpg
- Κλειδί
- λίμνη
- προσγείωση
- Χώρες
- large
- Μεγάλες επιχειρήσεις
- στρώμα
- στρώσεις
- στρώματα
- ηγέτης
- που οδηγεί
- ΜΑΘΑΊΝΩ
- Κληροδότημα
- Αφήνει
- άδειες
- Μου αρέσει
- γραμμή
- γενεαλογία
- λίστα
- φορτίο
- φόρτωση
- τοποθεσία
- ματιά
- αγαπά
- Χαμηλός
- που
- διατηρήσουν
- Η διατήρηση
- μεγάλες
- κάνω
- ΚΑΝΕΙ
- διαχείριση
- διαχειρίζεται
- διαχείριση
- διαχειρίζεται
- διαχείριση
- αγορά
- νόημα
- Metrics
- ενδέχεται να
- μεταναστεύσουν
- μετανάστευση
- μοντελοποίηση
- ΜΟΝΤΕΡΝΑ
- εκσυγχρονισμός
- εκμοντερνίζω
- περισσότερο
- πλέον
- πολλαπλούς
- Φύση
- απαραίτητος
- Ανάγκη
- Νέα
- New Jersey
- Νέα τεχνολογία
- επόμενη
- Όχι.
- τώρα
- of
- προσφέρονται
- on
- διαδικτυακά (online)
- ανοικτού κώδικα
- λειτουργίες
- or
- ενορχήστρωση
- τάξη
- επιχειρήσεις
- οργανώσεις
- Οργανωμένος
- ΑΛΛΑ
- δικός μας
- έξω
- παραγωγή
- επί
- φόρμες
- ιδιοκτησία
- πακέτο
- μέρος
- εταίρος
- Λιθόστρωση
- για
- τέλειος
- εκτελέσει
- επίδοση
- αγωγού
- πλατφόρμες
- Πλατφόρμες
- Πλάτων
- Πληροφορία δεδομένων Plato
- Πλάτωνα δεδομένα
- Δημοφιλής
- Θέση
- δυναμικού
- δύναμη
- ισχυρός
- Πρακτικός
- Προετοιμάστε
- παρόν
- Προβολή
- αρχές
- διαδικασίες
- διαδικασια μας
- επεξεργασία
- Διεργασίες
- μεταποίηση
- Πρόγραμμα
- Προγράμματα
- σχέδιο
- έργα
- δεόντως
- αποδεδειγμένη
- παρέχουν
- παρέχει
- βάζω
- Python
- ποιότητα
- Γρήγορα
- γρήγορα
- σειρά
- Τιμές
- μάλλον
- Ακατέργαστος
- ακατέργαστα δεδομένα
- πραγματικός
- σε πραγματικό χρόνο
- δεδομένα σε πραγματικό χρόνο
- λόγους
- πρόσφατος
- ρεκόρ
- αρχεία
- σχετίζεται με
- αξιόπιστος
- αναπαραγωγή
- Αναφορά
- Εκθέσεις
- εκπροσωπώ
- απαιτείται
- απαιτήσεις
- απάντησης
- επακόλουθο
- λιανική πώληση
- έμπορος λιανικής
- τρέξιμο
- επεκτάσιμη
- Κλίμακα
- προγραμματιστεί
- Τμήμα
- δείτε
- δει
- αρχαιότερος
- ξεχωριστό
- σερβίρεται
- Χωρίς διακομιστή
- Διακομιστές
- εξυπηρετεί
- υπηρεσία
- Υπηρεσίες
- εξυπηρετούν
- σειρά
- setup
- διάφοροι
- Δείχνει
- Απλούς
- μόνο
- λύση
- Λύσεις
- μερικοί
- επιδιώξει
- Πηγή
- Πηγές
- ειδικεύεται
- ειδικευμένη
- συγκεκριμένες
- ειδικά
- SQL
- Στάδιο
- στάδια
- Εκκίνηση
- δηλώσεις
- Βήμα
- Βήματα
- χώρος στο δίσκο
- κατάστημα
- αποθηκεύονται
- ευθεία
- ειλικρινής
- μετάδοση
- ροής
- δομημένος
- δομή
- Μελέτη
- Ακολούθως
- τέτοιος
- προμήθεια
- υποστήριξη
- Έρευνες
- σύστημα
- συστήματα
- T
- τραπέζι
- επειξειργασμένος από ραπτήν
- Πάρτε
- στόχευση
- Έργο
- εργασίες
- ομάδες
- tech
- Τεχνολογία
- δοκιμή
- Δοκιμές
- από
- ότι
- Η
- Η Πηγη
- τους
- τότε
- Αυτοί
- αυτοί
- τρίτους
- αυτό
- τρία
- Μέσω
- ώρα
- προς την
- εργαλείο
- εργαλεία
- τοπικός
- Θέματα
- Σύνολο
- τροχιά
- ιστορικό
- ΚΙΝΗΣΗ στους ΔΡΟΜΟΥΣ
- συναλλαγή
- συναλλακτική
- Συναλλαγές
- Μεταμορφώστε
- Μεταμόρφωση
- μετασχηματισμούς
- μετασχηματίζοντας
- Διαφάνεια
- Τάσεις
- Στροφή
- δύο
- τύποι
- συνήθως
- ui
- υπό
- υφίσταται
- κατανόηση
- μοναδικός
- μονάδα
- ενημερώσεις
- επάνω σε
- URL
- us
- ΗΠΑ
- χρήση
- περίπτωση χρήσης
- μεταχειρισμένος
- χρήσιμος
- Χρήστες
- Χρήστες
- χρησιμοποιεί
- χρησιμοποιώντας
- χρησιμοποιούνται
- Πολύτιμος
- ποικιλία
- διάφορα
- Σταθερή
- επαληθεύει
- εκδοχή
- Δες
- εμφανίσεις
- Αποθήκη
- Αποθήκευση
- ήταν
- Τρόπος..
- we
- ιστός
- διαδικτυακές υπηρεσίες
- ιστοσελίδες
- αν
- Ποιό
- ενώ
- ευρύς
- Ευρύ φάσμα
- με
- εντός
- χωρίς
- Κέρδισε
- Εργασία
- ροής εργασίας
- ροές εργασίας
- αξία
- θα
- τυλίξτε
- γράφω
- γραφή
- εσείς
- zephyrnet