Ανάλυση δεδομένων με χρήση Scala
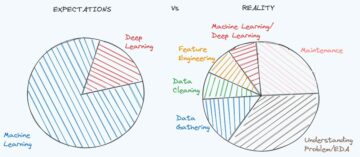
Είναι πολύ σημαντικό να επιλέξετε το σωστό εργαλείο για την ανάλυση δεδομένων. Στα φόρουμ Kaggle, όπου διεξάγονται διεθνείς διαγωνισμοί Επιστήμης Δεδομένων, οι άνθρωποι συχνά ρωτούν ποιο εργαλείο είναι καλύτερο. Οι R και Python βρίσκονται στην κορυφή της λίστας. Σε αυτό το άρθρο θα σας πούμε για μια εναλλακτική στοίβα τεχνολογιών ανάλυσης δεδομένων, που βασίζεται στο Scala.
By Ρωμαίος Ζύκοφ, Ιδρυτής/Επιστήμονας Δεδομένων @ TopDataLab

Είναι πολύ σημαντικό να επιλέξετε το σωστό εργαλείο για την ανάλυση δεδομένων. Στο Kaggle.com φόρουμ, όπου διεξάγονται διεθνείς διαγωνισμοί Επιστήμης Δεδομένων, οι άνθρωποι συχνά ρωτούν ποιο εργαλείο είναι καλύτερο. Οι R και Python βρίσκονται στην κορυφή της λίστας. Σε αυτό το άρθρο θα σας πούμε για μια εναλλακτική στοίβα τεχνολογιών ανάλυσης δεδομένων, που βασίζονται στη γλώσσα προγραμματισμού Scala και Σπινθήρας κατανεμημένη υπολογιστική πλατφόρμα.
Πώς το καταλήξαμε; Στη Retail Rocket κάνουμε πολλή μηχανική εκμάθηση σε πολύ μεγάλα σύνολα δεδομένων. Χρησιμοποιούσαμε ένα σωρό IPython + Pyhs2 (πρόγραμμα οδήγησης κυψέλης για Python) + Pandas + Sklearn για να αναπτύξουμε πρωτότυπα. Στα τέλη του καλοκαιριού του 2014 πήραμε μια θεμελιώδη απόφαση να στραφούμε στο Spark, καθώς τα πειράματα έδειξαν ότι θα έχουμε 3-4 φορές μεγαλύτερη βελτίωση απόδοσης στο ίδιο πάρκο διακομιστών.
Ένα άλλο πλεονέκτημα είναι ότι μπορούμε να χρησιμοποιήσουμε μία γλώσσα προγραμματισμού για μοντελοποίηση και κώδικα που θα τρέχει σε διακομιστές παραγωγής. Αυτό ήταν ένα τεράστιο όφελος για εμάς, αφού πριν χρησιμοποιούσαμε 4 γλώσσες ταυτόχρονα: Hive, Pig, Java, Python. Είναι ένα πρόβλημα για μια μικρή ομάδα μηχανικών.
Το Spark υποστηρίζει καλά την εργασία με Python/Scala/Java μέσω API. Αποφασίσαμε να επιλέξουμε το Scala επειδή είναι η γλώσσα στην οποία γράφεται το Spark, πράγμα που σημαίνει ότι μπορούμε να αναλύσουμε τον πηγαίο κώδικα του και να διορθώσουμε σφάλματα αν χρειαστεί. Είναι επίσης το JVM στο οποίο τρέχει το Hadoop.
Πρέπει να πω ότι η επιλογή δεν ήταν εύκολη, αφού κανείς στην ομάδα δεν γνώριζε τότε τη Σκάλα.
Είναι γνωστό ότι για να μάθετε να επικοινωνείτε καλά σε μια γλώσσα, πρέπει να βυθιστείτε στη γλώσσα και να τη χρησιμοποιήσετε όσο το δυνατόν περισσότερο. Έτσι, εγκαταλείψαμε τη στοίβα Python υπέρ της Scala για μοντελοποίηση και γρήγορη ανάλυση δεδομένων.
Το πρώτο βήμα ήταν να βρεθεί ένας αντικαταστάτης για τους φορητούς υπολογιστές IPython. Οι επιλογές ήταν οι εξής:
- Zeppelin – ένα σημειωματάριο τύπου IPython για το Spark.
- ISpark;
- Σημειωματάριο Spark;
- Το Notebook Spark IPython της IBM.
- Απάτσι Τμετάλλευμα
Μέχρι στιγμής η επιλογή ήταν το ISpark γιατί είναι απλό – είναι το IPython για Scala/Spark. Ήταν σχετικά εύκολο να βιδωθεί σε γραφικά HighCharts και R. Και δεν είχαμε κανένα πρόβλημα να το συνδέσουμε με το σύμπλεγμα Yarn.
Έργο
Ας προσπαθήσουμε να απαντήσουμε στην ερώτηση: το μέσο ποσό αγοράς (AOV) στο ηλεκτρονικό σας κατάστημα εξαρτάται από στατικές παραμέτρους πελατών, οι οποίες περιλαμβάνουν τη διευθέτηση, τον τύπο προγράμματος περιήγησης (κινητό/επιτραπέζιος υπολογιστής), το λειτουργικό σύστημα και την έκδοση του προγράμματος περιήγησης; Μπορείτε να το κάνετε αυτό με Αμοιβαίες πληροφορίες.
Χρησιμοποιούμε πολύ την εντροπία για τους αλγόριθμους συστάσεων και την ανάλυσή μας: ο κλασικός τύπος Shannon, η απόκλιση Kullback-Leibler, η αμοιβαία πληροφόρηση. Υποβάλαμε ακόμη και μια εργασία για αυτό το θέμα. Υπάρχει μια ξεχωριστή, αν και μικρή, ενότητα αφιερωμένη σε αυτά τα μέτρα στο διάσημο εγχειρίδιο του Murphy για τη μηχανική μάθηση.
Ας το αναλύσουμε σε πραγματικά δεδομένα Retail Rocket. Προηγουμένως, αντέγραψα το δείγμα από το σύμπλεγμα μας στον υπολογιστή μου ως αρχείο csv.
ημερομηνία
Εδώ χρησιμοποιούμε το ISpark και το Spark που εκτελούνται σε τοπική λειτουργία, πράγμα που σημαίνει ότι όλοι οι υπολογισμοί εκτελούνται τοπικά και κατανέμονται μεταξύ των πυρήνων του επεξεργαστή. Όλα περιγράφονται στα σχόλια του κώδικα. Το πιο σημαντικό πράγμα είναι ότι στην έξοδο παίρνουμε RDD (Spark data structure), που είναι μια συλλογή από κατηγορίες case τύπου Row, που ορίζεται στον κώδικα. Αυτό θα σας επιτρέψει να ανατρέξετε σε πεδία μέσω "."", για παράδειγμα _.categoryId.


Η παραπάνω γραμμή χρησιμοποιεί τον νέο τύπο δεδομένων DataFrame που προστέθηκε στο Spark στην έκδοση 1.3.0, είναι πολύ παρόμοια με την παρόμοια δομή στη βιβλιοθήκη pandas στην Python. Το toDf συλλέγει την κλάση περιπτώσεων Row, ώστε να μπορούμε να αναφερθούμε στο πεδίο με το όνομα.
Για περαιτέρω ανάλυση, πρέπει να επιλέξουμε μία κατηγορία, κατά προτίμηση με πολλά δεδομένα. Για να γίνει αυτό, πρέπει να λάβουμε μια λίστα με τις πιο δημοφιλείς κατηγορίες.


Θεωρητικά, μπορείτε να χρησιμοποιήσετε οποιαδήποτε γραφήματα HighCharts αρκεί να υποστηρίζονται στο Wisp. Όλα τα γραφήματα είναι διαδραστικά.
Ας προσπαθήσουμε να κάνουμε το ίδιο πράγμα, αλλά με το R.
Εκτελέστε τον πελάτη R και σχεδιάστε έναν χαρακτήρα:


Αμοιβαίες πληροφορίες
Τα γραφήματα δείχνουν ότι υπάρχει σχέση, αλλά θα μας επιβεβαιώσουν οι μετρήσεις αυτό το συμπέρασμα; Υπάρχουν πολλοί τρόποι για να γίνει αυτό. Στην περίπτωσή μας, χρησιμοποιούμε Αμοιβαία Πληροφορίες μεταξύ των τιμών του πίνακα. Μετρά την αμοιβαία εξάρτηση μεταξύ των κατανομών δύο τυχαίων (διακριτών) μεταβλητών.
Για διακριτές κατανομές, υπολογίζεται χρησιμοποιώντας τον τύπο:

Αλλά μας ενδιαφέρει μια πιο πρακτική μέτρηση - το Μέγιστος Συντελεστής Πληροφοριών (MIC) που απαιτεί μερικούς δύσκολους υπολογισμούς για συνεχείς μεταβλητές. Δείτε πώς ακούγεται ο ορισμός αυτής της παραμέτρου.
Έστω D = (x, y) ένα σύνολο από n διατεταγμένα ζεύγη στοιχείων των τυχαίων μεταβλητών X και Y. Αυτός ο δισδιάστατος χώρος διαιρείται από πλέγματα X και Y, ομαδοποιώντας τις τιμές x και y σε διαμερίσματα X και Y, αντίστοιχα ( θυμηθείτε τα ιστογράμματα!).

όπου B(n) είναι το μέγεθος του πλέγματος, I∗(D, X, Y ) είναι η αμοιβαία πληροφορία των διαμερισμάτων X και Y. Ο παρονομαστής καθορίζει τον λογάριθμο, ο οποίος χρησιμεύει για την κανονικοποίηση του MIC στις τιμές του τμήματος [0, 1]. Το MIC λαμβάνει συνεχείς τιμές στο διάστημα [0,1]: για ακραίες τιμές είναι 1 εάν υπάρχει εξάρτηση, 0 εάν δεν υπάρχει. Τι άλλο μπορεί να διαβαστεί για αυτό το θέμα παρατίθεται στο τέλος του άρθρου, στη λίστα των αναφορών.
Η βιβλίο (Machine Learning: a Probabilistic Perspective) αποκαλεί το MIC (αμοιβαία πληροφορία) συσχέτιση του 21ου αιώνα. Και να γιατί! Το παρακάτω γράφημα δείχνει 6 εξαρτήσεις (γραφήματα C έως H). Η συσχέτιση του Pearson και το MIC έχουν υπολογιστεί για αυτά και σημειώνονται με τα αντίστοιχα γράμματα στο γράφημα στα αριστερά. Όπως μπορούμε να δούμε, η συσχέτιση Pearson είναι σχεδόν μηδενική, ενώ η MIC δείχνει συσχέτιση (γραφήματα F, G, E).
 Πηγή: Reshef, DN, YA Reshef, HK Finucane, SR Grossman, G. McVean, PJ Turnbaugh, ES Lander, M. Mitzenmacher και PC Sabeti. «Ανίχνευση νέων συσχετισμών σε μεγάλα σύνολα δεδομένων».
Πηγή: Reshef, DN, YA Reshef, HK Finucane, SR Grossman, G. McVean, PJ Turnbaugh, ES Lander, M. Mitzenmacher και PC Sabeti. «Ανίχνευση νέων συσχετισμών σε μεγάλα σύνολα δεδομένων».Ο παρακάτω πίνακας δείχνει έναν αριθμό μετρήσεων που έχουν υπολογιστεί σε διαφορετικές εξαρτήσεις: τυχαίες, γραμμικές, κυβικές κ.λπ. Ο πίνακας δείχνει ότι το MIC συμπεριφέρεται πολύ καλά, ανιχνεύοντας μη γραμμικές εξαρτήσεις.
 Πηγή: Reshef, DN, YA Reshef, HK Finucane, SR Grossman, G. McVean, PJ Turnbaugh, ES Lander, M. Mitzenmacher και PC Sabeti. «Ανίχνευση νέων συσχετισμών σε μεγάλα σύνολα δεδομένων».
Πηγή: Reshef, DN, YA Reshef, HK Finucane, SR Grossman, G. McVean, PJ Turnbaugh, ES Lander, M. Mitzenmacher και PC Sabeti. «Ανίχνευση νέων συσχετισμών σε μεγάλα σύνολα δεδομένων».Στην περίπτωσή μας, έχουμε να κάνουμε με έναν υπολογισμό MIC όπου έχουμε μια συνεχή μεταβλητή Aov και όλες οι άλλες είναι διακριτές με μη διατεταγμένες τιμές, όπως ο τύπος προγράμματος περιήγησης. Για να υπολογίσουμε σωστά το MIC πρέπει να διακριτοποιήσουμε τη μεταβλητή Aov. Θα χρησιμοποιήσουμε έτοιμη λύση από exploredata.net. Υπάρχει ένα πρόβλημα με αυτή τη λύση: υποθέτει ότι και οι δύο μεταβλητές είναι συνεχείς και εκφράζονται σε τιμές Float. Επομένως, θα πρέπει να ξεγελάσουμε τον κώδικα κωδικοποιώντας τις τιμές των διακριτών μεταβλητών στο Float και αλλάζοντας τυχαία τη σειρά αυτών των μεταβλητών. Για να γίνει αυτό, θα πρέπει να κάνουμε πολλές επαναλήψεις με τυχαία σειρά (100) και θα πάρουμε ως αποτέλεσμα τη μέγιστη τιμή MIC.



Για το πείραμα, πρόσθεσα μια τυχαία μεταβλητή με ομοιόμορφη κατανομή και την ίδια την AOV (Μέση Αξία Αγοράς). Όπως μπορούμε να δούμε, σχεδόν όλο το MIC ήταν κάτω από το τυχαίο MIC, το οποίο μπορεί να θεωρηθεί ως όριο απόφασης «υπό όρους». Το Aov MIC είναι σχεδόν ενότητα, κάτι που είναι φυσικό, επειδή η συσχέτιση με τον εαυτό του ισούται με 1.
Ένα ενδιαφέρον ερώτημα προκύπτει: γιατί βλέπουμε μια συσχέτιση στα γραφήματα, αλλά το MIC είναι μηδέν; Μπορούμε να καταλήξουμε σε πολλές υποθέσεις, αλλά πιθανότατα για την περίπτωση του os Family είναι αρκετά απλό – ο αριθμός των μηχανών Windows είναι πολύ μεγαλύτερος από τον αριθμό των άλλων:

Συμπέρασμα
Ελπίζω ότι το Scala θα αποκτήσει τη δημοτικότητά του μεταξύ των αναλυτών δεδομένων (Data Scientists). Είναι πολύ βολικό επειδή είναι δυνατό να εργαστείτε με ένα τυπικό notebook IPython + να αποκτήσετε όλες τις δυνατότητες του Spark. Αυτός ο κώδικας μπορεί να λειτουργήσει με ασφάλεια με terabyte δεδομένων, απλά πρέπει να αλλάξετε τη γραμμή διαμόρφωσης στο ISpark, προσδιορίζοντας το URI του συμπλέγματός σας.
αναφορές
[1] Reshef, DN, YA Reshef, HK Finucane, SR Grossman, G. McVean, PJ Turnbaugh, ES Lander, M. Mitzenmacher και PC Sabeti. «Ανίχνευση νέων συσχετισμών σε μεγάλα σύνολα δεδομένων».
[2] MINE: Λογισμικό μη παραμετρικής εξερεύνησης Maximal Information με χρήση MIC
[3] Minepy – Μέγιστη Πληροφορία που βασίζεται σε Μη Παράμ (Python, C++, MATLAB, Octave)) μετρική εξερεύνηση.
[4] Βιβλιοθήκη Java με σύνολα δεδομένων για MIC
[5] «Μηχανική μάθηση: μια πιθανολογική προοπτική» Kevin Patrick Murphy
[6] Η ουσία του παραπάνω κώδικα
Bio: Ρωμαίος Ζύκοφ είναι Ιδρυτής και Επιστήμονας Δεδομένων στο TopDataLab, και έχει 20ετή εμπειρία στην ανάλυση δεδομένων, κάτοχος μεταπτυχιακού τίτλου στα εφαρμοσμένα μαθηματικά και τη φυσική. Ο Roman έγραψε επίσης το βιβλίο «Roman's Data Science: How to monetize your data», που είναι διαθέσιμο στο Amazon.
Πρωτότυπο. Αναδημοσιεύτηκε με άδεια.
Συγγενεύων:
Πηγή: https://www.kdnuggets.com/2021/09/data-analysis-scala.html
- "
- &
- 100
- Πλεονέκτημα
- αλγόριθμοι
- Όλα
- Amazon
- μεταξύ των
- ανάλυση
- Apache
- APIs
- εφαρμογές
- άρθρο
- Bolt
- πρόγραμμα περιήγησης
- σφάλματα
- χτίζω
- τσαμπί
- αλλαγή
- Διαγράμματα
- κωδικός
- σχόλια
- Διαγωνισμοί
- χρήση υπολογιστή
- ημερομηνία
- ανάλυση δεδομένων
- επιστημονικά δεδομένα
- επιστήμονας δεδομένων
- μοιρασιά
- βαθιά μάθηση
- ανάπτυξη
- DID
- κατανεμημένων υπολογιστών
- οδηγός
- Μηχανική
- Μηχανικοί
- κ.λπ.
- Excel
- εμπειρία
- πείραμα
- εξερεύνηση
- Πρόσωπο
- οικογένεια
- FAST
- Χαρακτηριστικά
- Πεδία
- Όνομα
- σταθερός
- ιδρυτής
- Πλαίσιο
- GitHub
- Hadoop
- εδώ
- Κυψέλη
- Πως
- Πώς να
- HTTPS
- τεράστιος
- πληροφορίες
- διαδραστικό
- International
- IT
- Java
- Γλώσσα
- Γλώσσες
- large
- ΜΑΘΑΊΝΩ
- μάθηση
- Βιβλιοθήκη
- γραμμή
- Λίστα
- τοπικός
- τοπικά
- Μακριά
- μάθηση μηχανής
- μηχανήματα
- μαθηματικά
- Metrics
- Microsoft
- μοντελοποίηση
- Δημοφιλέστερα
- φορητούς υπολογιστές
- διαδικτυακά (online)
- ηλεκτρονικό κατάστημα
- ανοίξτε
- ανοικτού κώδικα
- λειτουργίας
- το λειτουργικό σύστημα
- Επιλογές
- τάξη
- Άλλα
- Χαρτί
- People
- επίδοση
- προοπτική
- Φυσική
- πλατφόρμες
- Δημοφιλής
- χαρτοφυλάκιο
- παραγωγή
- Προγραμματισμός
- σχέδιο
- αγορά
- Python
- λιανική πώληση
- τρέξιμο
- τρέξιμο
- Scala
- Επιστήμη
- επιστήμονες
- σειρά
- επίλυση
- Απλούς
- Μέγεθος
- δεξιότητες
- small
- So
- λογισμικό
- Χώρος
- κατάστημα
- ιστορίες
- υποβάλλονται
- καλοκαίρι
- υποστηριζόνται!
- Υποστηρίζει
- διακόπτης
- σύστημα
- Τεχνολογίες
- Δοκιμές
- Το γράφημα
- ώρα
- κορυφή
- Ενότητα
- URI
- us
- αξία
- ιστός
- Wikipedia
- παράθυρα
- Εργασία
- X
- χρόνια
- μηδέν