Σε αυτό το άρθρο θα μάθετε διάφορες μεθόδους μετατροπής PDF σε Φύλλα Google.
Θα μάθετε επίσης πώς μπορούν τα Nanonets αυτοματοποιήστε ολόκληρη τη ροή εργασίας της μετατροπής PDF σε Φύλλα Google σε απευθείας σύνδεση.
Πριν δούμε πώς να μετατρέψουμε το PDF σε Φύλλα Google, ας ρίξουμε μια ματιά στο γιατί είναι σημαντικό να το κάνετε αυτό.
Γιατί να μετατρέψετε αρχεία PDF σε Φύλλα Google;
Σύμφωνα με το συγκεκριμένο google-blog ανάρτηση από την επίσημη σελίδα ιστολογίου Google, περισσότερες από 5 εκατομμύρια επιχειρήσεις χρησιμοποιούν τη λύση G Suite. Ταυτόχρονα, ένας μεγάλος αριθμός εταιρειών έχουν αρχίσει επίσης να χρησιμοποιούν ενσωματώσεις Φύλλων Google για την αυτοματοποίηση εργασιών.
Ας εξετάσουμε μια τυπική περίπτωση χρήσης. Η ομάδα των πληρωτέων λογαριασμών σας λαμβάνει ένα τιμολόγιο, σε τυπική μορφή PDF. Κάποιος περνά με μη αυτόματο τρόπο το τιμολόγιο και πληκτρολογεί τις απαιτούμενες πληροφορίες σε ένα έγγραφο Φύλλων Google πριν το προωθήσει στην ενότητα Οικονομικά. Η ενότητα Οικονομικών πληρώνει τον προμηθευτή σας και κάνει μια εγγραφή στο καθολικό της εταιρείας.
Εκτός από μια πολύπλοκη διαδικασία, αυτή είναι επιρρεπής σε σφάλματα και θα ήταν πολύ πιο λογικό να την αυτοματοποιήσουμε απλώς.
Τώρα που η ανάγκη για μετατροπή αρχείων PDF σε φόρμα φύλλου Google είναι ξεκάθαρη, ας ρίξουμε μια ματιά στο πώς είναι δομημένα τα έγγραφα PDF και ποιες είναι οι προκλήσεις στην ανάλυση τους.
Θέλετε να κάνετε μετατροπή PDF αρχεία σε Google Sheets ; Ολοκλήρωση παραγγελίας Nanonets δωρεάν Μετατροπέας PDF σε CSV. Ή μάθετε πώς να αυτοματοποιήστε ολόκληρη τη ροή εργασίας PDF στα Φύλλα Google με το Nanonets.
Προκλήσεις με την ανάλυση ενός εγγράφου PDF
Η μορφή φορητού εγγράφου ήταν μια μορφή αρχείου που αναπτύχθηκε αρχικά από την Adobe και αργότερα κυκλοφόρησε ως ανοιχτό πρότυπο. Έκτοτε έχει υιοθετηθεί ευρέως καθώς είναι αγνωστικιστικό για το υποκείμενο λειτουργικό σύστημα.
Λοιπόν, γιατί είναι τόσο δύσκολη η ανάλυση ενός PDF και η μετατροπή του περιεχομένου του σε άλλη μορφή; Οι παρακάτω εικόνες λένε χίλιες λέξεις και θα οδηγήσουν το θέμα στο σπίτι.
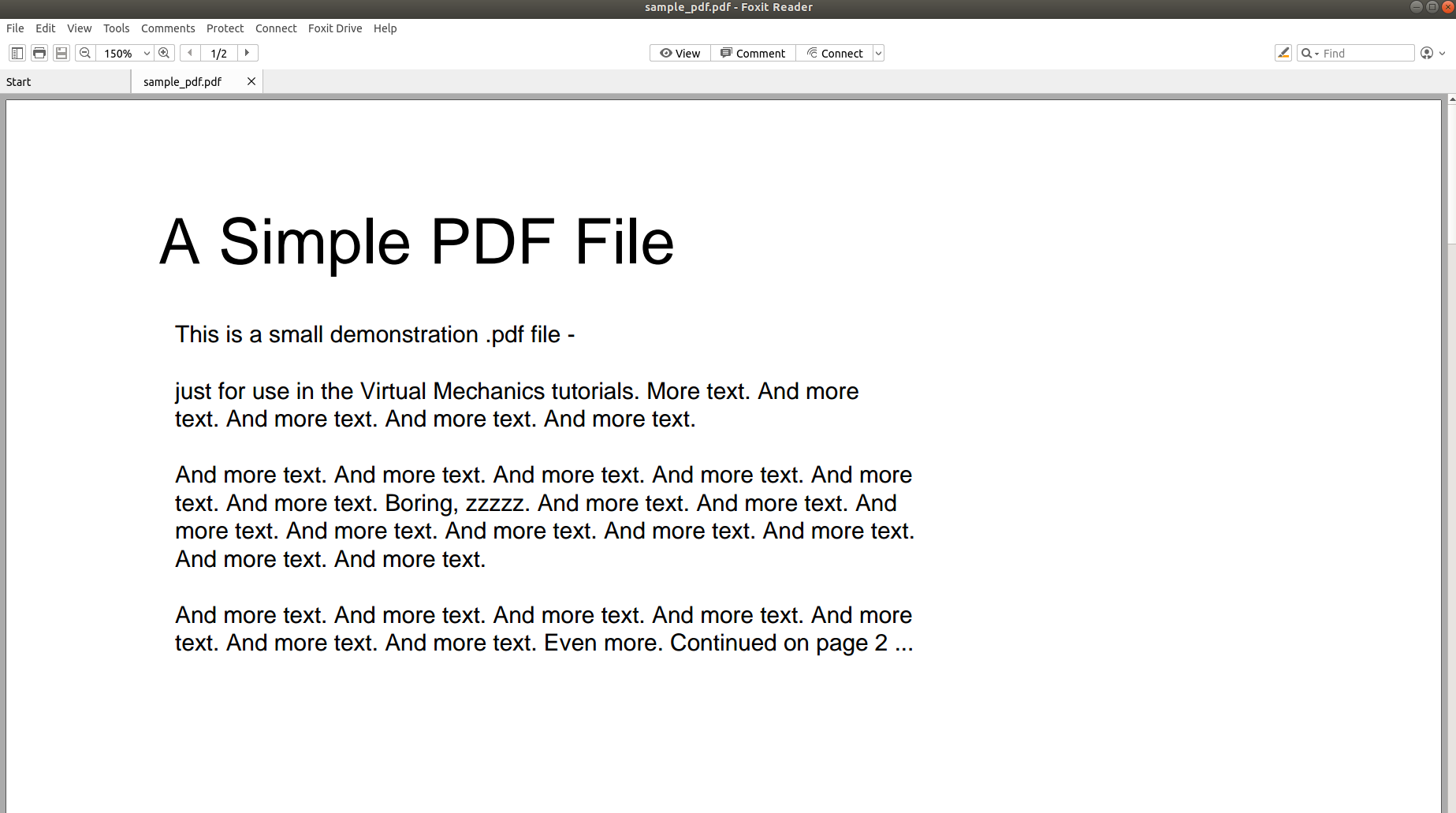
Η παραπάνω εικόνα δείχνει το στιγμιότυπο οθόνης ενός εγγράφου PDF το οποίο ανοίγει χρησιμοποιώντας ένα πρόγραμμα ανάγνωσης PDF. Ας προσπαθήσουμε να ανοίξουμε το ίδιο έγγραφο PDF χρησιμοποιώντας ένα πρόγραμμα επεξεργασίας κειμένου.
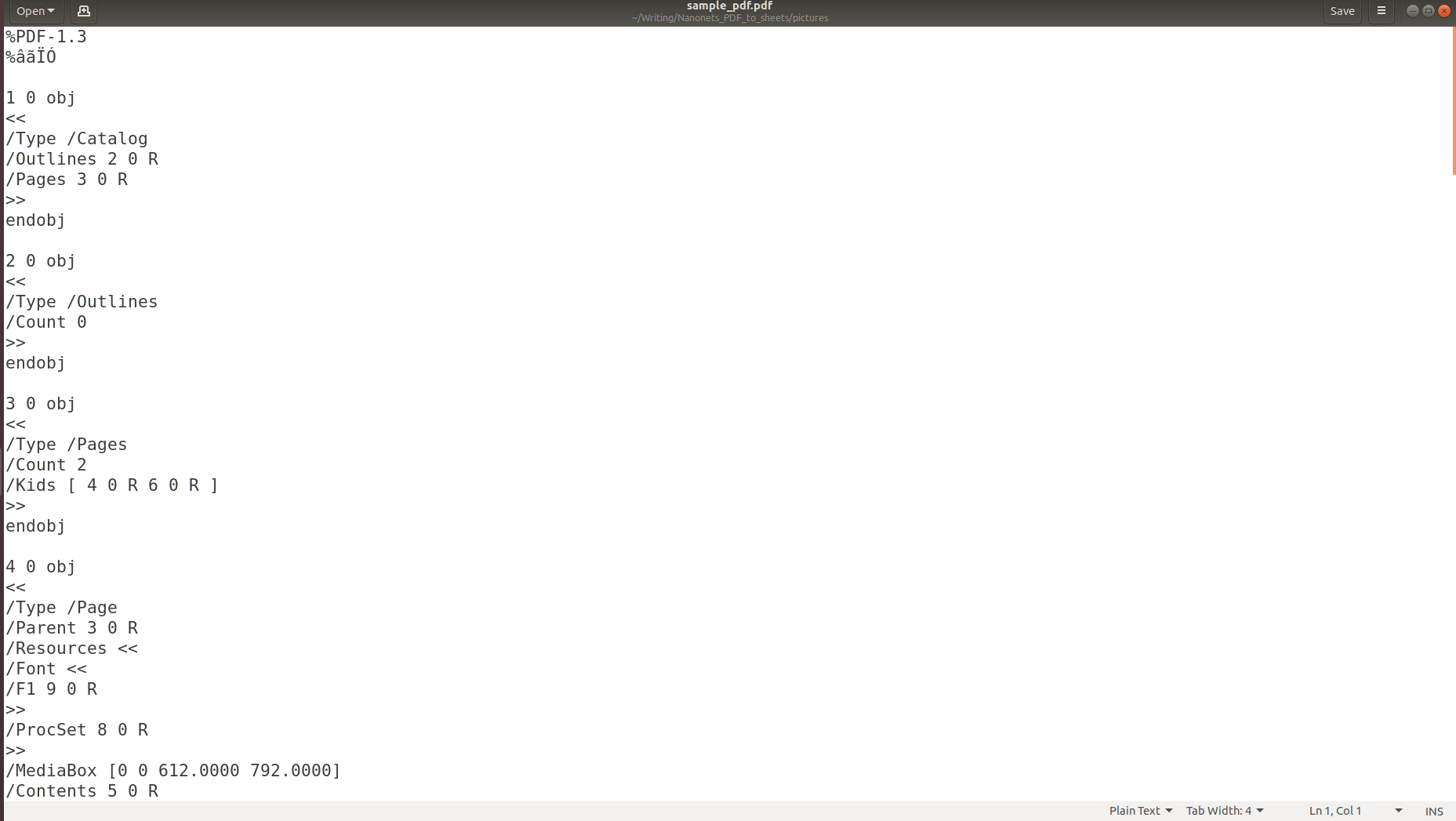
Οι παραπάνω εικόνες καθιστούν σαφές ότι όταν οι πληροφορίες αποθηκεύονται σε ένα PDF, η αρχική τους δομή χάνεται εντελώς. Αυτό συμβαίνει επειδή η μορφή PDF αποτελείται απλώς από οδηγίες σχετικά με τον τρόπο εκτύπωσης/σχεδιασμού μιας ακολουθίας χαρακτήρων σε μια σελίδα.
Εάν πιστεύετε ότι η εξαγωγή κειμένου είναι δύσκολη, η εξαγωγή των δεδομένων που υπάρχουν σε πίνακες είναι ακόμη πιο δύσκολη λόγω των πολύ διαφορετικών μορφών πινάκων που χρησιμοποιούνται.
Ας ελπίσουμε ότι είστε πεπεισμένοι ότι η μετατροπή ενός εγγράφου PDF σε μια φόρμα Φύλλων Google δεν είναι περίπατος στο πάρκο. Η επόμενη ενότητα μιλά για την προσέγγιση που ακολουθούν οι περισσότεροι σύγχρονοι αναλυτές PDF για την αναγνώριση/ανάλυση πληροφοριών από ένα έγγραφο PDF.
Η σύγχρονη προσέγγιση στην ανάλυση εγγράφων PDF
Οι περισσότεροι σύγχρονοι αναλυτές PDF χρησιμοποιούν τη ροή που περιγράφεται παρακάτω για την ανάλυση μη δομημένων δεδομένων από έγγραφα PDF.
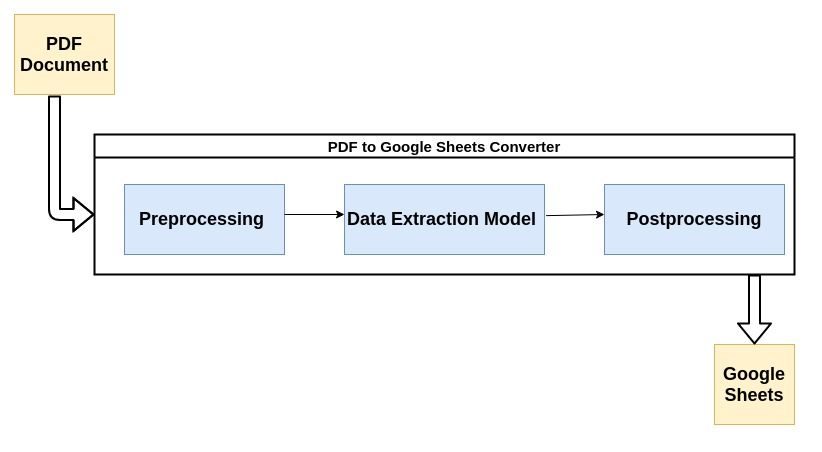
Ας ρίξουμε μια σύντομη ματιά σε κάθε βήμα της διαδικασίας:
1. Προεπεξεργασία ή καθαρισμός δεδομένων:
Όσο καλύτερη είναι η εμφάνιση του PDF σας, τόσο πιο εύκολο θα είναι για το μοντέλο Μηχανικής Εκμάθησης να εξάγει ή λήψη δεδομένων από αυτό. Για παράδειγμα, εάν το έγγραφο PDF έχει σαρωθεί, είναι βέβαιο ότι θα περιέχει ορισμένα τεχνουργήματα σάρωσης που θα μπορούσαν να επηρεάσουν την απόδοση του μετατροπέα.
Η αφαίρεση θορύβου με τη χρήση κατάλληλων φίλτρων, η δυαδοποίηση, η διόρθωση κλίσης κ.λπ. είναι μερικά από τα πιο κοινά βήματα προεπεξεργασίας. Η ακόλουθη ανάρτηση Nanonets Nanonets Tesseract Post περιέχει μερικά εξαιρετικά παραδείγματα για το πώς τα έγγραφα μπορούν να υποβληθούν σε προεπεξεργασία πριν Οπτική αναγνώριση χαρακτήρων(OCR) εκτελείται πάνω τους.
Εδώ συμβαίνει το μεγαλύτερο μέρος της μαγείας. Η εξαγωγή δεδομένων πραγματοποιείται συνήθως με ένα μοντέλο Μηχανικής Μάθησης (ML). Τα περισσότερα μοντέλα ML που χρησιμοποιούνται για την εξαγωγή δεδομένων από αρχεία PDF περιέχουν έναν συνδυασμό εργαλείων οπτικής αναγνώρισης χαρακτήρων, εργαλείων αναγνώρισης κειμένου και μοτίβων κ.λπ.
Για τους σκοπούς αυτής της ανάρτησης, μπορούμε να αντιμετωπίσουμε το μοντέλο ως ένα μαύρο κουτί που παίρνει το έγγραφο PDF σας ως είσοδο και βγάζει τις αναλυμένες πληροφορίες. Επίσης, δεδομένου ότι χρησιμοποιεί ML στον πυρήνα του, μπορεί να επανεκπαιδευτεί με προσαρμοσμένα δεδομένα για να ταιριάζει στην περίπτωση χρήσης της εταιρείας σας.
3. Μετά την επεξεργασία:
Σε αυτό το βήμα, τα εξαγόμενα δεδομένα μετατρέπονται στην απαιτούμενη μορφή όπως CSV, XML, JSON κ.λπ. Επίσης, πρόσθετοι κανόνες που καθορίζονται από τον χρήστη προστίθενται πάνω από τις προβλέψεις που γίνονται από το AI. Αυτό θα μπορούσε να περιλαμβάνει κανόνες για τη μορφοποίηση της εξόδου, πρόσθετους περιορισμούς στις πληροφορίες που εξάγονται κ.λπ.
Η παρακάτω ενότητα εξετάζει ορισμένες μετρήσεις που θα μπορούσαμε να χρησιμοποιήσουμε για να μετρήσουμε την απόδοση ενός αναλυτή PDF.
Θέλετε να κάνετε μετατροπή PDF αρχεία σε Google Sheets ; Ολοκλήρωση παραγγελίας Nanonets δωρεάν Μετατροπέας PDF σε CSV. Μάθετε πώς μπορείτε να αυτοματοποιήσετε ολόκληρη τη ροή εργασίας PDF στα Φύλλα Google με το Nanonets.

Μετρήσεις για τη μέτρηση της απόδοσης ενός μετατροπέα PDF
Δεδομένου ότι οι περισσότεροι μετατροπείς PDF θα χρησιμοποιηθούν για επεξεργασία τιμολογίων ή σχετικές εργασίες, η ακρίβεια και η ταχύτητα εξαγωγής πίνακα από ένα έγγραφο PDF είναι κρίσιμος παράγοντας για την αξιολόγηση της απόδοσης του μετατροπέα PDF.
2. Πολύγλωσση ικανότητα:
Οι περισσότερες μεγάλες εταιρείες υποχρεούνται να λαμβάνουν τιμολόγια σε πολλές διαφορετικές γλώσσες. Ο αναλυτής PDF θα πρέπει είτε να υποστηρίζει πολύγλωσση ανάλυση εκτός πλαισίου είτε θα πρέπει να παρέχει μια επιλογή με την οποία οι χρήστες μπορούν να εκπαιδεύσουν το μοντέλο χρησιμοποιώντας προσαρμοσμένα δεδομένα.
3. Ενοποίηση με Λογισμικό Λογισμικού:
Ο ιδανικός μετατροπέας PDF θα πρέπει να είναι μια μονάδα plug and play που μπορεί εύκολα να προστεθεί στο υπάρχον σας ροή εργασιών εγγράφων. Θα πρέπει να υποστηρίζει την ενοποίηση με δημοφιλές λογιστικό λογισμικό όπως QuickBooks, Xero, Wave κ.λπ.
4. Εύκολο και διαισθητικό:
Το εργαλείο πιθανότατα θα χρησιμοποιείται από μη τεχνικούς χρήστες. Θα ήταν πλεονεκτικό εάν μπορεί να λειτουργήσει με ελάχιστες τεχνικές γνώσεις.
Διάφορες μέθοδοι μετατροπής PDF σε Φύλλα Google
1.Χρήση των Εγγράφων Google για τη μετατροπή PDF σε Φύλλα Google
Το Google Drive έχει ενσωματωμένη δυνατότητα αναγνώρισης πινάκων και κειμένου σε απλά έγγραφα PDF. Χρειάζεται απλά να:
-
Ανεβάστε το αρχείο PDF στο Google Drive
-
Κάντε κλικ στο "Άνοιγμα με τα Έγγραφα Google"
-
Αντιγράψτε τα δεδομένα που θέλετε και επικολλήστε στα Φύλλα Google
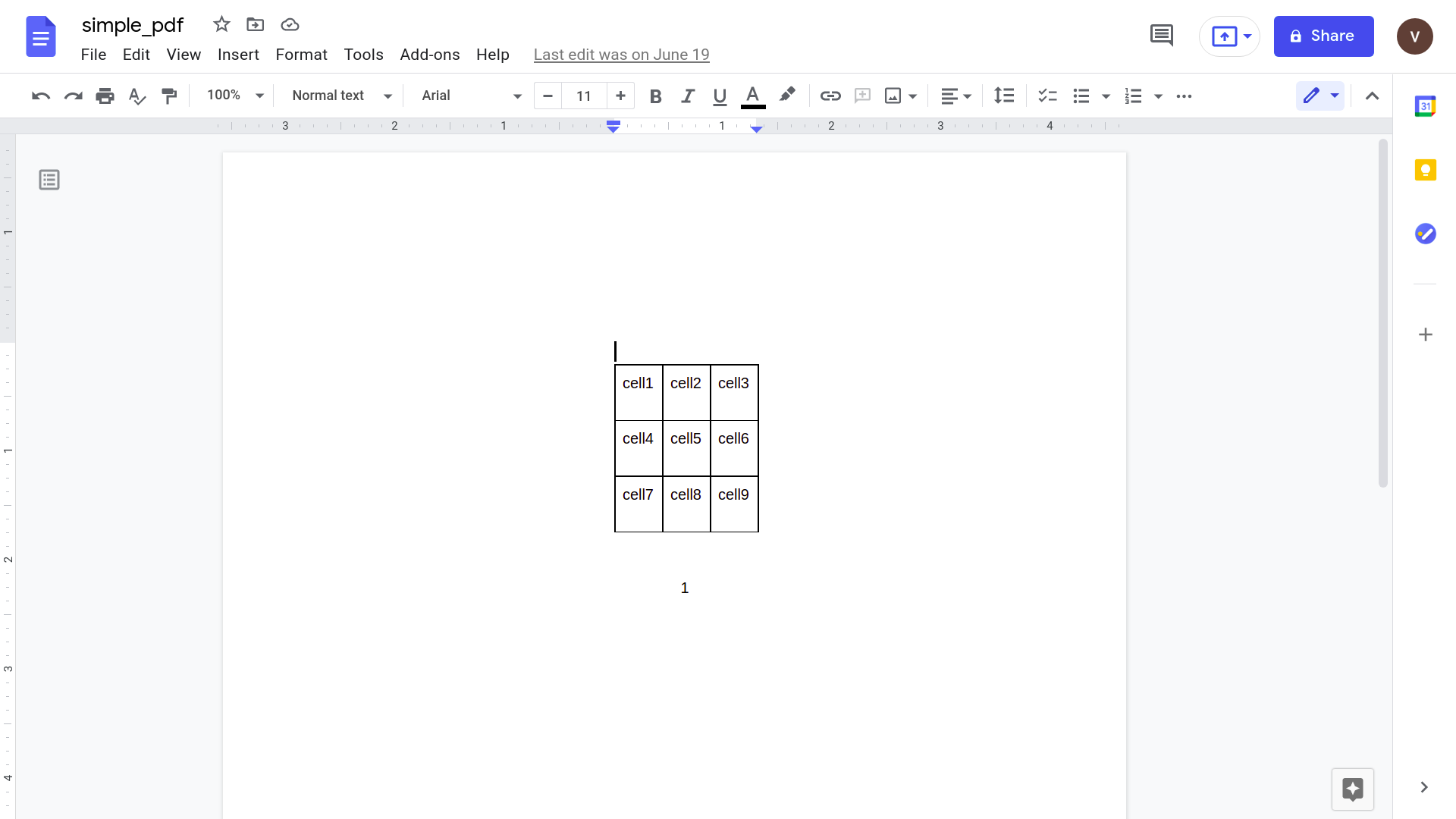
Αν και αυτό φαίνεται να λειτουργεί καλά, ας δοκιμάσουμε κάτι λίγο πιο πρακτικό. Σκεφτείτε αυτό το απλό τιμολόγιο.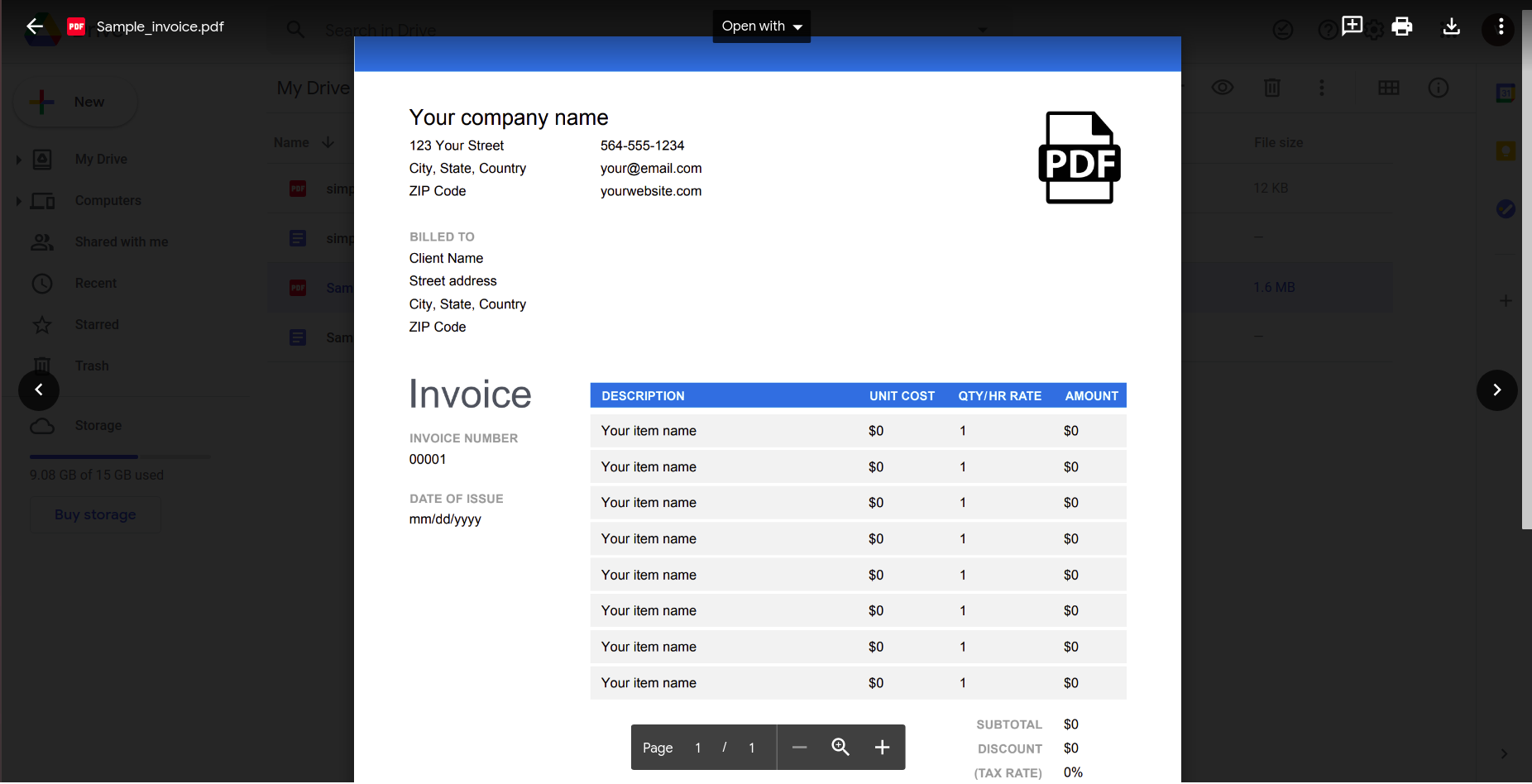
Ανοίγοντας αυτό χρησιμοποιώντας την εφαρμογή Google Docs προκύπτει το ακόλουθο αποτέλεσμα.
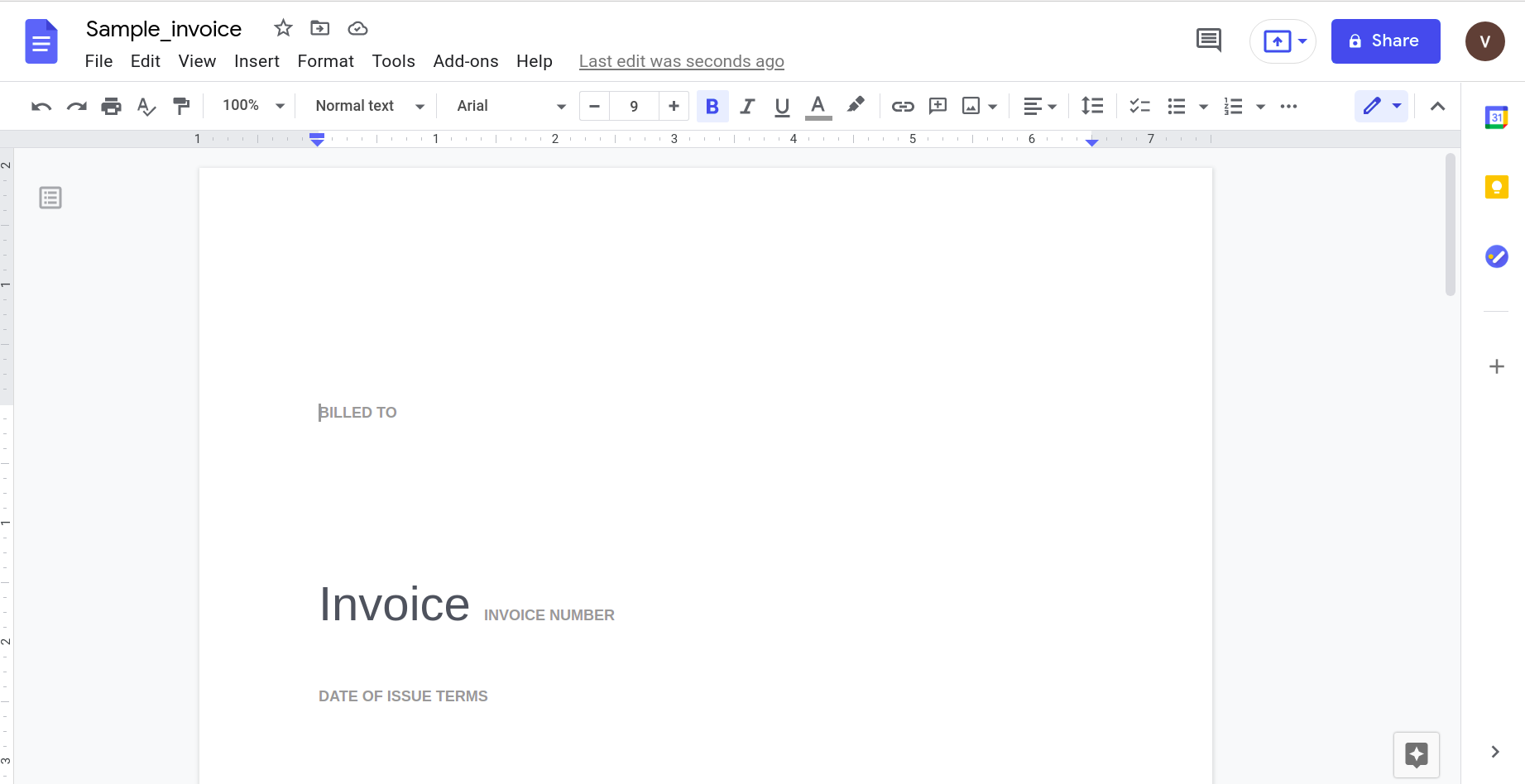
Σαφώς, καθώς αυξάνεται η πολυπλοκότητα του εγγράφου, πρέπει να βασιζόμαστε σε πιο εξελιγμένα εργαλεία για την αναγνώριση δεδομένων.
2. Χρήση διαδικτυακών εργαλείων:
Διάφορα διαδικτυακά εργαλεία, όπως η εξαγωγή πινάκων PDF, το Online2PDF κ.λπ., ενσωματώνονται απευθείας στο Google Drive και παρέχουν τη δυνατότητα μετατροπής εγγράφων PDF σε Φύλλα Google.
Ωστόσο, όταν αυτά τα εργαλεία δοκιμάστηκαν χρησιμοποιώντας το δείγμα PDF τιμολογίου που εμφανίζεται παραπάνω, οι πίνακες δεν εντοπίστηκαν στην πλειονότητα των περιπτώσεων.
Θέλετε να κάνετε μετατροπή PDF αρχεία σε Google Sheets ; Ολοκλήρωση παραγγελίας Nanonets δωρεάν Μετατροπέας PDF σε CSV. Μάθετε πώς μπορείτε να αυτοματοποιήσετε ολόκληρη τη ροή εργασίας PDF στα Φύλλα Google με τα Nanonets όπως φαίνεται παρακάτω.
Αυτοματοποίηση της διαδικασίας μετατροπής PDF σε Φύλλα Google
Μπορούμε να αυτοματοποιήσουμε πλήρως τη διαδικασία ανάλυσης του PDF και εξαγωγής των δεδομένων σε μια φόρμα Φύλλων Google χρησιμοποιώντας τα παρακάτω εργαλεία.
1. Χρήση Webhooks:
Τα Webhook είναι προσαρμοσμένα καθορισμένα αιτήματα HTTP. Συνήθως ενεργοποιούνται σε ένα συμβάν, δηλαδή όταν συμβαίνει ένα συμβάν, η εφαρμογή στέλνει πληροφορίες σε μια προκαθορισμένη διεύθυνση URL.
Πώς μπορείτε να το χρησιμοποιήσετε για την αυτοματοποίηση της ροής εργασίας σας; Ας εξετάσουμε την τυπική περίπτωση χρήσης της επεξεργασίας τιμολογίων. Λαμβάνετε έναν αριθμό τιμολογίων από τους προμηθευτές σας και τα τροφοδοτείτε στον μετατροπέα PDF σε Φύλλα Google που βρίσκεται στο cloud. Πώς ξέρετε πότε το μοντέλο έχει ολοκληρώσει την επεξεργασία των εγγράφων;
Αντί να ελέγχετε μη αυτόματα εάν η μετατροπή έχει ολοκληρωθεί, θα μπορούσατε απλώς να χρησιμοποιήσετε ένα webhook που σας ειδοποιεί όταν τα δεδομένα στο PDF έχουν εξαχθεί σε ένα έγγραφο Φύλλων Google.
2. Χρήση API
Το API σημαίνει Διασύνδεση προγραμματισμού εφαρμογών. Χρησιμοποιώντας τις κατάλληλες κλήσεις API, η μετατροπή εγγράφων PDF σε Φύλλα Google μπορεί να αποδειχθεί τόσο εύκολη όσο η σύνταξη των ακόλουθων γραμμών κώδικα:
#Feed the PDF documents into the PDF to Google sheets converter
Success_code, unique_id = NanonetsAPI.uploaddata(PDF_documents)
Εάν η εταιρεία σας έχει ήδη ρυθμίσει την ενοποίηση με το Webhooks, θα λάβετε μια ειδοποίηση όταν τα έγγραφα PDF σας έχουν μετατραπεί με επιτυχία. Στη συνέχεια, μπορείτε να κάνετε λήψη της φόρμας Φύλλων Google χρησιμοποιώντας το API που φαίνεται παρακάτω.
#Download Google Sheets forms
Google_sheets_data = NanonetsAPI.downloaddata(unqiue_id)
PDF σε Φύλλα Google με Nanonets
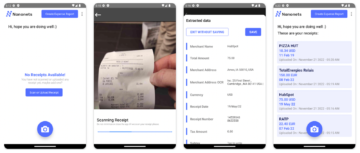
Ο αναλυτής PDF Nanonets κάνει την ανάλυση και τη μετατροπή εύκολη και ακριβή. Ο αναλυτής PDF χρησιμοποιήθηκε για την ανάλυση ενός δείγματος τιμολογίου. Αυτή η ενότητα καταδεικνύει την ευκολία χρήσης και την ακρίβεια του εργαλείου. Αντί να μιλάμε για το πόσο υπέροχο είναι, οι παρακάτω εικόνες απεικονίζουν εύστοχα το θέμα.
Η εικόνα που εμφανίζεται παρακάτω είναι ένα στιγμιότυπο οθόνης του δείγματος τιμολογίου που τροφοδοτήθηκε στον αναλυτή PDF Nanonets.
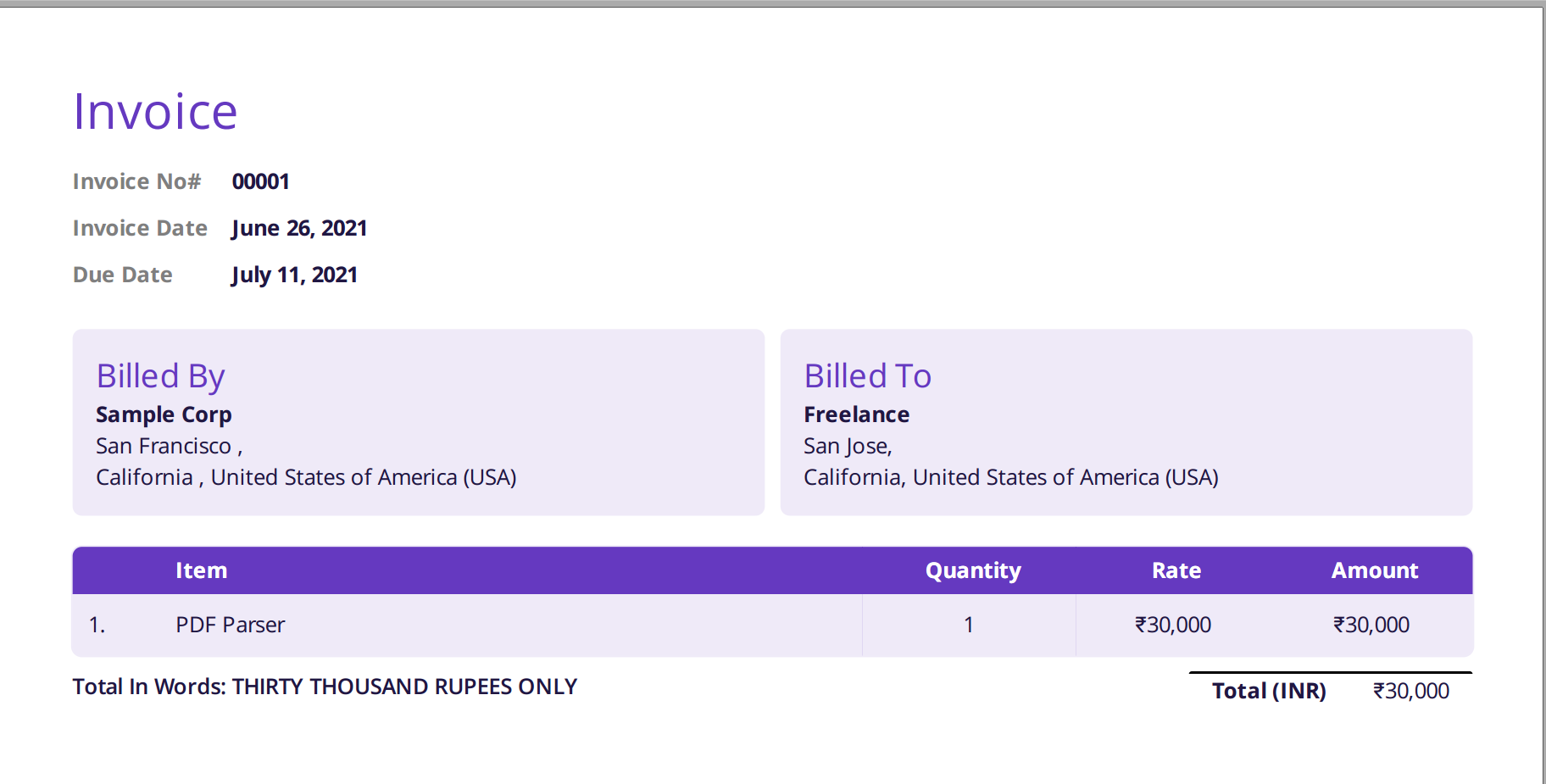
Απλώς μεταβείτε στον ιστότοπο Nanonets και ανεβάστε το τιμολόγιο. Η μετατροπή διαρκεί μόνο λίγα δευτερόλεπτα μετά τα οποία τα αναλυμένα δεδομένα μπορούν να ληφθούν σε διάφορες μορφές, όπως π.χ CSV, XLSX κ.λπ. (δείτε Nanonets' Μετατροπέας PDF σε CSV)
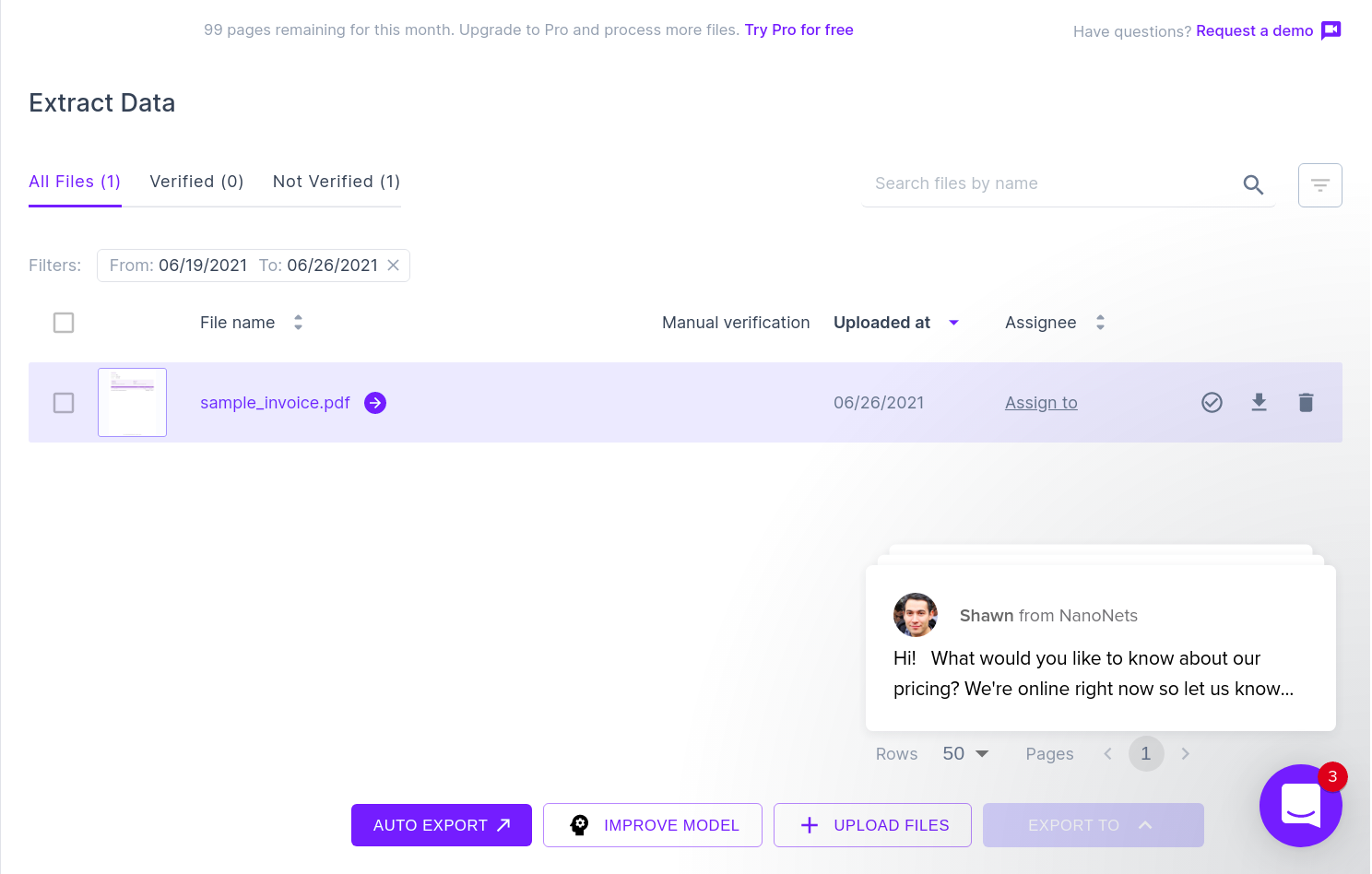
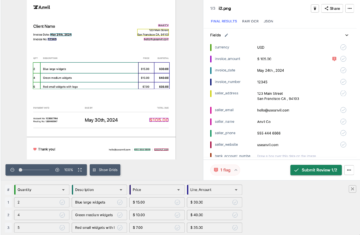
Η επόμενη εικόνα δείχνει ένα στιγμιότυπο οθόνης του αρχείου CSV που περιέχει τα αναλυμένα δεδομένα από το έγγραφο PDF.

Τέλος, για να μετατρέψετε το αρχείο CSV σε μια φόρμα φύλλων Google, είναι απλώς θέμα να ανεβάσετε το αρχείο XLSX/CSV στη μονάδα google. Αυτό το βήμα μπορεί να αυτοματοποιηθεί χρησιμοποιώντας τα API του Google Drive.
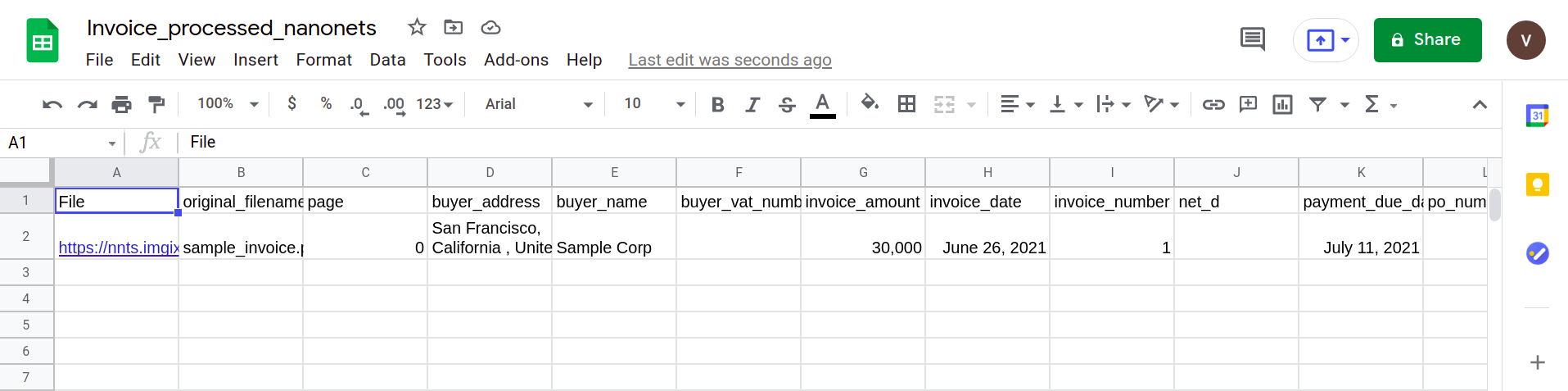
Η παρακάτω ενότητα δείχνει πώς μπορεί να δημιουργηθεί μια απλή διοχέτευση χρησιμοποιώντας τον αναλυτή PDF Nanonets.
Θέλετε να εξαγάγετε πληροφορίες από έγγραφα PDF και να τα μετατρέψετε/προσθέσετε σε ένα έγγραφο Φύλλων Google; Ρίξτε μια ματιά στα Nanonets™ για να αυτοματοποιήσετε την εξαγωγή οποιασδήποτε πληροφορίας από οποιοδήποτε έγγραφο PDF στα Φύλλα Google!
Δημιουργία απλού αγωγού
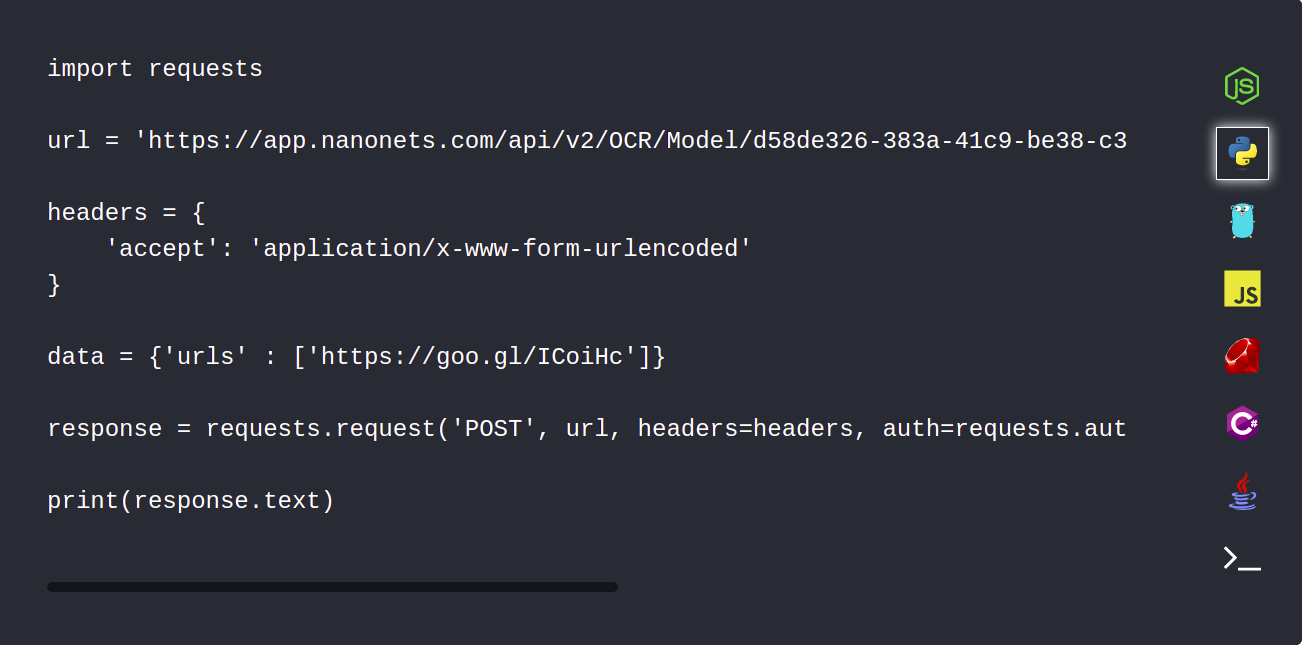
1. Ανεβάστε αυτόματα τα έγγραφα PDF χρησιμοποιώντας το Nanonets API
Το Nanonets API σάς επιτρέπει να ανεβάζετε αυτόματα τα έγγραφά σας που πρέπει να αναλυθούν. Το παρακάτω απόσπασμα κώδικα δείχνει πώς μπορεί να γίνει αυτό χρησιμοποιώντας python.
2. Χρησιμοποιήστε την ενοποίηση webhooks για να λάβετε μια ειδοποίηση μετά την ολοκλήρωση της ανάλυσης
Τα Webhook μπορούν να διαμορφωθούν ώστε να σας ειδοποιούν αυτόματα μετά την ανάλυση των εγγράφων.
3. Ελέγξτε και μεταφορτώστε στα Φύλλα Google
Κατεβάστε και ελέγξτε τα αρχεία CSV για να βεβαιωθείτε ότι όλα είναι εντάξει και μεταφορτώστε τα δεδομένα στα Φύλλα Google χρησιμοποιώντας το API του Google Drive.
Το Nanonets Edge
Ακολουθούν ορισμένα χαρακτηριστικά του Nanonets PDF Parser που τον καθιστούν το ιδανικό εργαλείο για την επιχείρησή σας.
1.Εξωτερικές ενσωματώσεις:
Το μοντέλο νανοδικτύων μπορεί εύκολα να ενσωματωθεί με τα MySql, Quickbooks, Salesforce κ.λπ. Αυτό σημαίνει ότι η τρέχουσα ροή εργασίας σας παραμένει αδιατάρακτη και ο μετατροπέας νανοδικτύων μπορεί απλώς να συνδεθεί ως πρόσθετη μονάδα.
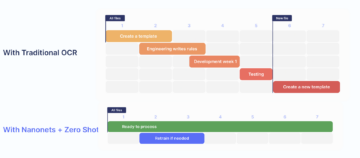
2. Υψηλή ακρίβεια και χαμηλοί χρόνοι επεξεργασίας:
Το εργαλείο ανάλυσης PDF Nanonets έχει ακρίβεια πάνω από 95%+, η οποία είναι πολύ μεγαλύτερη σε σύγκριση με τους ανταγωνιστές του.
3. Δροσερά χαρακτηριστικά μετά την επεξεργασία:
Ας υποθέσουμε ότι η βάση δεδομένων σας έχει ενσωματωθεί με το μοντέλο νανοδικτύων. Το μοντέλο συμπληρώνει αυτόματα ορισμένα πεδία (με δεδομένα από τη βάση δεδομένων σας) με βάση τα δεδομένα που εξάγονται από το έγγραφο. Για παράδειγμα:
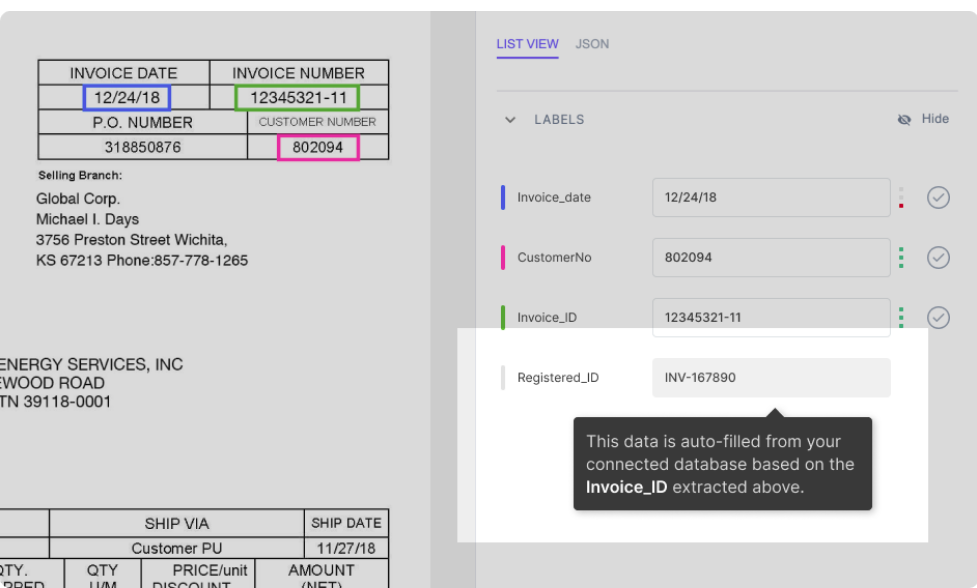
Όπως φαίνεται στο σχήμα, το πεδίο Registered_ID συμπληρώνεται αυτόματα (με αναζήτηση βάσης δεδομένων) με βάση το Invoice_ID που εξάγεται από το PDF.
4. Απλή και διαισθητική διεπαφή
Αν και αυτό το χαρακτηριστικό είναι υποτιμημένο, βρήκα ότι το UI και το UX είναι επίκαιρα. Η όλη διαδικασία εγγραφής, φόρτωσης του εγγράφου και ανάλυσης των δεδομένων κράτησε λιγότερο από 5 λεπτά. Αυτός είναι σχεδόν ίσος με τον χρόνο που χρειάζεται ο φορητός μου υπολογιστής για να εκκινήσει!
5. Τεράστια βάση πελατών
Σε περίπτωση που εξακολουθείτε να έχετε επιφυλάξεις σχετικά με τη χρήση των Nanonets για την αυτοματοποίηση της ροής εργασιών σας, απλώς ρίξτε μια ματιά σε μερικές από τις εταιρείες που χρησιμοποιούν τις υπηρεσίες τους.
- Deloitte
- Sherwin Williams
- DoorDash
- P&G
Θέλετε να εξαγάγετε πληροφορίες από έγγραφα PDF και να τα μετατρέψετε/προσθέσετε σε ένα έγγραφο Φύλλων Google; Ρίξτε μια ματιά στα Nanonets™ για να αυτοματοποιήσετε την εξαγωγή οποιασδήποτε πληροφορίας από οποιοδήποτε έγγραφο PDF στα Φύλλα Google!
Συμπέρασμα
Σε αυτήν την ανάρτηση ρίξαμε μια ματιά στο πώς μπορείτε να αυτοματοποιήσετε τη ροή εργασίας σας χρησιμοποιώντας έναν μετατροπέα PDF σε Φύλλα Google. Αρχικά, μάθαμε για την ανάγκη μετατροπής εγγράφων PDF σε Φύλλα Google ακολουθούμενη από τις προκλήσεις που αντιμετωπίστηκαν κατά τη διάρκεια αυτής της διαδικασίας. Στη συνέχεια, ασχοληθήκαμε με τις προσεγγίσεις που ακολουθούν οι σύγχρονοι αναλυτές για την ανάλυση εγγράφων PDF και επίσης εφαρμόσαμε μερικές από τις κοινές προσεγγίσεις. Μάθαμε επίσης πώς μπορούμε να αυτοματοποιήσουμε πλήρως τη μετατροπή χρησιμοποιώντας εξωτερικές ενσωματώσεις όπως webhook και API. Τέλος, χρησιμοποιήσαμε το εργαλείο Nanonets για την ανάλυση ενός δείγματος τιμολογίου, εξάγοντας τα δεδομένα σε μια φόρμα των Φύλλων Google και επίσης εξερευνήσαμε μερικές από τις συναρπαστικές του δυνατότητες μετά την επεξεργασία.
Έχετε δώσει μια ευκαιρία στο μοντέλο Nanonets; Εάν ναι, αφήστε ένα σχόλιο παρακάτω σχετικά με την εμπειρία σας με το εργαλείο. Αν όχι, προχωρήστε και δοκιμάστε το. Μπορεί απλά να σου φτιάξει τη μέρα!
- AI
- AI και μηχανική μάθηση
- αι τέχνη
- ι γεννήτρια τέχνης
- ρομπότ ai
- τεχνητή νοημοσύνη
- πιστοποίηση τεχνητής νοημοσύνης
- τεχνητή νοημοσύνη στον τραπεζικό τομέα
- ρομπότ τεχνητής νοημοσύνης
- ρομπότ τεχνητής νοημοσύνης
- λογισμικό τεχνητής νοημοσύνης
- blockchain
- συνέδριο blockchain ai
- Coingenius
- συνομιλητική τεχνητή νοημοσύνη
- κρυπτοσυνεδριο αι
- του νταλ
- βαθιά μάθηση
- έχεις google
- μάθηση μηχανής
- pdf σε φύλλα google
- Πλάτων
- πλάτων αι
- Πληροφορία δεδομένων Plato
- Παιχνίδι Πλάτωνας
- Πλάτωνα δεδομένα
- platogaming
- κλίμακα αι
- σύνταξη
- zephyrnet