Αυτή η ανάρτηση συντάχθηκε με τον Mahima Agarwal, Μηχανικό Μηχανικής Μάθησης, και τον Deepak Mettem, Senior Engineering Manager, στο VMware Carbon Black
VMware Carbon Black είναι μια διάσημη λύση ασφαλείας που προσφέρει προστασία από όλο το φάσμα των σύγχρονων επιθέσεων στον κυβερνοχώρο. Με terabytes δεδομένων που παράγονται από το προϊόν, η ομάδα ανάλυσης ασφαλείας εστιάζει στη δημιουργία λύσεων μηχανικής εκμάθησης (ML) για την εμφάνιση κρίσιμων επιθέσεων και την προβολή των αναδυόμενων απειλών από το θόρυβο.
Είναι ζωτικής σημασίας για την ομάδα VMware Carbon Black να σχεδιάσει και να δημιουργήσει μια προσαρμοσμένη γραμμή MLOps από άκρο σε άκρο που ενορχηστρώνει και αυτοματοποιεί τις ροές εργασίας στον κύκλο ζωής της ML και επιτρέπει την εκπαίδευση, τις αξιολογήσεις και την ανάπτυξη μοντέλων.
Υπάρχουν δύο κύριοι στόχοι για την κατασκευή αυτού του αγωγού: υποστήριξη των επιστημόνων δεδομένων για την ανάπτυξη μοντέλων στο τελευταίο στάδιο και προβλέψεις μοντέλων επιφάνειας στο προϊόν με την εξυπηρέτηση μοντέλων σε μεγάλο όγκο και σε κίνηση παραγωγής σε πραγματικό χρόνο. Επομένως, η VMware Carbon Black και η AWS επέλεξαν να δημιουργήσουν έναν προσαρμοσμένο αγωγό MLOps χρησιμοποιώντας Amazon Sage Maker για την ευκολία χρήσης, την ευελιξία και την πλήρως διαχειριζόμενη υποδομή του. Ενορχηστρώνουμε τους αγωγούς εκπαίδευσης και ανάπτυξης ML χρησιμοποιώντας Ροές εργασίας που διαχειρίζεται η Amazon για ροή αέρα Apache (Amazon MWAA), το οποίο μας δίνει τη δυνατότητα να εστιάσουμε περισσότερο στη δημιουργία ροών εργασιών και αγωγών μέσω προγραμματισμού χωρίς να χρειάζεται να ανησυχούμε για την αυτόματη κλιμάκωση ή τη συντήρηση της υποδομής.
Με αυτόν τον αγωγό, αυτό που κάποτε ήταν η έρευνα ML που βασιζόταν σε φορητούς υπολογιστές Jupyter είναι τώρα μια αυτοματοποιημένη διαδικασία που αναπτύσσει μοντέλα στην παραγωγή με μικρή χειροκίνητη παρέμβαση από επιστήμονες δεδομένων. Νωρίτερα, η διαδικασία εκπαίδευσης, αξιολόγησης και ανάπτυξης ενός μοντέλου θα μπορούσε να διαρκέσει μία ημέρα. με αυτήν την υλοποίηση, όλα είναι μόνο μια σκανδάλη μακριά και έχει μειώσει τον συνολικό χρόνο σε λίγα λεπτά.
Σε αυτήν την ανάρτηση, οι αρχιτέκτονες VMware Carbon Black και AWS συζητούν πώς δημιουργήσαμε και διαχειριστήκαμε προσαρμοσμένες ροές εργασίας ML χρησιμοποιώντας Gitlab, Amazon MWAA και SageMaker. Συζητάμε τι πετύχαμε μέχρι τώρα, περαιτέρω βελτιώσεις στον αγωγό και διδάγματα που αντλήθηκαν στην πορεία.
Επισκόπηση λύσεων
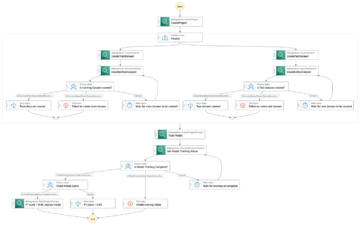
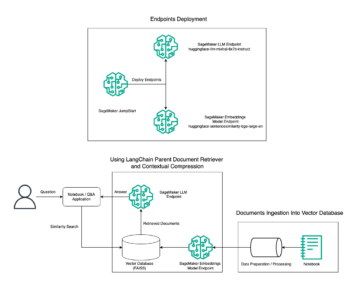
Το παρακάτω διάγραμμα απεικονίζει την αρχιτεκτονική της πλατφόρμας ML.

Σχεδιασμός λύσεων υψηλού επιπέδου
Αυτή η πλατφόρμα ML σχεδιάστηκε και σχεδιάστηκε για να καταναλώνεται από διαφορετικά μοντέλα σε διάφορα αποθετήρια κώδικα. Η ομάδα μας χρησιμοποιεί το GitLab ως εργαλείο διαχείρισης πηγαίου κώδικα για τη διατήρηση όλων των αποθετηρίων κώδικα. Οποιεσδήποτε αλλαγές στον πηγαίο κώδικα του αποθετηρίου μοντέλου ενσωματώνονται συνεχώς χρησιμοποιώντας το Gitlab CI, το οποίο επικαλείται τις επόμενες ροές εργασίας σε εξέλιξη (εκπαίδευση μοντέλου, αξιολόγηση και ανάπτυξη).
Το ακόλουθο διάγραμμα αρχιτεκτονικής απεικονίζει τη ροή εργασιών από άκρο σε άκρο και τα στοιχεία που εμπλέκονται στη διοχέτευση MLOps.

Ροή εργασιών από άκρο σε άκρο
Οι αγωγοί εκπαίδευσης, αξιολόγησης και ανάπτυξης του μοντέλου ML ενορχηστρώνονται χρησιμοποιώντας το Amazon MWAA, που αναφέρεται ως Κατευθυνόμενο ακυκλικό γράφημα (DAG). Ένα DAG είναι μια συλλογή εργασιών μαζί, οργανωμένων με εξαρτήσεις και σχέσεις για να λένε πώς πρέπει να εκτελούνται.
Σε υψηλό επίπεδο, η αρχιτεκτονική λύσης περιλαμβάνει τρία κύρια στοιχεία:
- Αποθετήριο κώδικα αγωγού ML
- Σωλήνας εκπαίδευσης και αξιολόγησης μοντέλων ML
- Σωλήνας ανάπτυξης μοντέλου ML
Ας συζητήσουμε πώς γίνεται η διαχείριση αυτών των διαφορετικών στοιχείων και πώς αλληλεπιδρούν μεταξύ τους.
Αποθετήριο κώδικα αγωγού ML
Αφού το αποθετήριο μοντέλων ενσωματώσει το αποθετήριο MLOps ως την κατάντη διοχέτευσή του και ένας επιστήμονας δεδομένων δεσμεύσει κώδικα στο αποθετήριο μοντέλων του, ένας τρέχων GitLab πραγματοποιεί τυπική επικύρωση και δοκιμή κώδικα που ορίζεται σε αυτό το αποθετήριο και ενεργοποιεί τη διοχέτευση MLOps με βάση τις αλλαγές κώδικα. Χρησιμοποιούμε τη διοχέτευση πολλαπλών έργων του Gitlab για να ενεργοποιήσουμε αυτό το έναυσμα σε διαφορετικά repos.
Ο αγωγός MLOps GitLab εκτελεί ένα συγκεκριμένο σύνολο σταδίων. Διεξάγει την επικύρωση βασικού κώδικα χρησιμοποιώντας pylint, συσκευάζει τον κώδικα εκπαίδευσης και συμπερασμάτων του μοντέλου μέσα στην εικόνα Docker και δημοσιεύει την εικόνα κοντέινερ στο Μητρώο εμπορευματοκιβωτίων Amazon Elastic (Amazon ECR). Το Amazon ECR είναι ένα πλήρως διαχειριζόμενο μητρώο κοντέινερ που προσφέρει φιλοξενία υψηλής απόδοσης, ώστε να μπορείτε να αναπτύξετε αξιόπιστα εικόνες και τεχνουργήματα εφαρμογών οπουδήποτε.
Σωλήνας εκπαίδευσης και αξιολόγησης μοντέλων ML
Μετά τη δημοσίευση της εικόνας, ενεργοποιείται η εκπαίδευση και η αξιολόγηση Ροή αέρα Apache αγωγού μέσω του AWS Lambda λειτουργία. Το Lambda είναι μια υπολογιστική υπηρεσία χωρίς διακομιστές, βασισμένη σε συμβάντα, η οποία σας επιτρέπει να εκτελείτε κώδικα για σχεδόν οποιοδήποτε τύπο εφαρμογής ή υπηρεσία υποστήριξης χωρίς παροχή ή διαχείριση διακομιστών.
Μετά την επιτυχή ενεργοποίηση του αγωγού, εκτελεί το Training and Evaluation DAG, το οποίο με τη σειρά του ξεκινά την εκπαίδευση μοντέλων στο SageMaker. Στο τέλος αυτού του αγωγού εκπαίδευσης, η αναγνωρισμένη ομάδα χρηστών λαμβάνει μια ειδοποίηση με τα αποτελέσματα της εκπαίδευσης και της αξιολόγησης του μοντέλου μέσω email μέσω Υπηρεσία απλών ειδοποιήσεων Amazon (Amazon SNS) και Slack. Το Amazon SNS είναι πλήρως διαχειριζόμενο pub/sub service για μηνύματα A2A και A2P.
Μετά από σχολαστική ανάλυση των αποτελεσμάτων αξιολόγησης, ο επιστήμονας δεδομένων ή ο μηχανικός ML μπορεί να αναπτύξει το νέο μοντέλο εάν η απόδοση του πρόσφατα εκπαιδευμένου μοντέλου είναι καλύτερη σε σύγκριση με την προηγούμενη έκδοση. Η απόδοση των μοντέλων αξιολογείται με βάση τις μετρήσεις για το συγκεκριμένο μοντέλο (όπως το σκορ F1, το MSE ή ο πίνακας σύγχυσης).
Σωλήνας ανάπτυξης μοντέλου ML
Για να ξεκινήσει η ανάπτυξη, ο χρήστης ξεκινά την εργασία GitLab που ενεργοποιεί το Deployment DAG μέσω της ίδιας συνάρτησης Lambda. Μετά την επιτυχή εκτέλεση του αγωγού, δημιουργεί ή ενημερώνει το τελικό σημείο του SageMaker με το νέο μοντέλο. Αυτό αποστέλλει επίσης μια ειδοποίηση με τις λεπτομέρειες του τελικού σημείου μέσω email χρησιμοποιώντας το Amazon SNS και το Slack.
Σε περίπτωση βλάβης σε κάποιον από τους αγωγούς, οι χρήστες ειδοποιούνται μέσω των ίδιων καναλιών επικοινωνίας.
Το SageMaker προσφέρει συμπεράσματα σε πραγματικό χρόνο που είναι ιδανικά για φόρτους εργασίας εξαγωγής με χαμηλό λανθάνοντα χρόνο και απαιτήσεις υψηλής απόδοσης. Αυτά τα τελικά σημεία διαχειρίζονται πλήρως, έχουν εξισορρόπηση φορτίου και κλιμακώνονται αυτόματα και μπορούν να αναπτυχθούν σε πολλές Ζώνες Διαθεσιμότητας για υψηλή διαθεσιμότητα. Η διοχέτευση μας δημιουργεί ένα τέτοιο τελικό σημείο για ένα μοντέλο αφού εκτελεστεί με επιτυχία.
Στις επόμενες ενότητες, επεκτείνουμε τα διάφορα εξαρτήματα και εμβαθύνουμε στις λεπτομέρειες.
GitLab: Μοντέλα πακέτων και αγωγοί ενεργοποίησης
Χρησιμοποιούμε το GitLab ως χώρο αποθήκευσης κώδικα και για τη διοχέτευση για να συσκευάσει τον κωδικό μοντέλου και να ενεργοποιήσει τα DAG κατάντη ροής αέρα.
Αγωγός πολλαπλών έργων
Η δυνατότητα διοχέτευσης GitLab πολλαπλών έργων χρησιμοποιείται όπου η μητρική διοχέτευση (upstream) είναι ένα αποθετήριο μοντέλου και η θυγατρική διοχέτευση (κατάντη) είναι το αποθετήριο MLOps. Κάθε repo διατηρεί ένα .gitlab-ci.yml και το ακόλουθο μπλοκ κώδικα που είναι ενεργοποιημένο στο upstream pipeline ενεργοποιεί το downstream pipeline MLOps.
Ο ανοδικός αγωγός στέλνει μέσω του κώδικα μοντέλου στον κατάντη αγωγό όπου ενεργοποιούνται οι εργασίες CI συσκευασίας και δημοσίευσης. Ο κώδικας για την αποθήκευση του κώδικα μοντέλου σε κοντέινερ και τη δημοσίευσή του στο Amazon ECR διατηρείται και διαχειρίζεται η διοχέτευση MLOps. Στέλνει τις μεταβλητές όπως ACCESS_TOKEN (μπορεί να δημιουργηθεί κάτω από ρυθμίσεις, πρόσβαση), JOB_ID (για πρόσβαση σε upstream artifact) και $CI_PROJECT_ID (το αναγνωριστικό έργου του μοντέλου repo), έτσι ώστε η διοχέτευση MLOps να έχει πρόσβαση στα αρχεία κώδικα μοντέλου. Με την αντικείμενα εργασίας χαρακτηριστικό από το Gitlab, το downstream repo έχει πρόσβαση στα απομακρυσμένα τεχνουργήματα χρησιμοποιώντας την ακόλουθη εντολή:
Το αποθετήριο μοντέλων μπορεί να καταναλώσει κατάντη αγωγούς για πολλά μοντέλα από το ίδιο αποθετήριο επεκτείνοντας το στάδιο που το ενεργοποιεί χρησιμοποιώντας το Επεκτείνεται λέξη-κλειδί από το GitLab, το οποίο σας επιτρέπει να επαναχρησιμοποιήσετε την ίδια διαμόρφωση σε διαφορετικά στάδια.
Μετά τη δημοσίευση της εικόνας του μοντέλου στο Amazon ECR, ο αγωγός MLOps ενεργοποιεί τον εκπαιδευτικό αγωγό Amazon MWAA χρησιμοποιώντας το Lambda. Μετά την έγκριση του χρήστη, ενεργοποιεί το μοντέλο ανάπτυξης του αγωγού Amazon MWAA χρησιμοποιώντας επίσης την ίδια λειτουργία Lambda.
Σημασιολογική έκδοση και μεταβίβαση εκδόσεων κατάντη
Αναπτύξαμε προσαρμοσμένο κώδικα για την έκδοση εικόνων ECR και μοντέλων SageMaker. Η διοχέτευση MLOps διαχειρίζεται τη λογική της σημασιολογικής έκδοσης εικόνων και μοντέλων ως μέρος του σταδίου όπου ο κώδικας του μοντέλου ενσωματώνεται σε εμπορευματοκιβώτια και μεταβιβάζει τις εκδόσεις σε μεταγενέστερα στάδια ως τεχνουργήματα.
Επανεκπαίδευση
Επειδή η επανεκπαίδευση είναι μια κρίσιμη πτυχή ενός κύκλου ζωής ML, έχουμε εφαρμόσει δυνατότητες επανεκπαίδευσης ως μέρος του αγωγού μας. Χρησιμοποιούμε το API λίστας μοντέλων του SageMaker για να προσδιορίσουμε αν γίνεται επανεκπαίδευση με βάση τον αριθμό έκδοσης και τη χρονική σήμανση επανεκπαίδευσης του μοντέλου.
Διαχειριζόμαστε το ημερήσιο πρόγραμμα του αγωγού επανεκπαίδευσης χρησιμοποιώντας Οι αγωγοί χρονοδιαγράμματος του GitLab.
Terraform: Εγκατάσταση υποδομής
Εκτός από ένα σύμπλεγμα Amazon MWAA, αποθετήρια ECR, συναρτήσεις Lambda και θέμα SNS, αυτή η λύση χρησιμοποιεί επίσης Διαχείριση ταυτότητας και πρόσβασης AWS (IAM) ρόλοι, χρήστες και πολιτικές. Απλή υπηρεσία αποθήκευσης Amazon (Amazon S3) κάδοι, και ένα amazoncloudwatch ημερολόγιο προώθησης.
Για να εξορθολογίσουμε τη ρύθμιση και τη συντήρηση της υποδομής για τις υπηρεσίες που εμπλέκονται σε όλο τον αγωγό μας, χρησιμοποιούμε Terraform για την υλοποίηση της υποδομής ως κώδικα. Όποτε απαιτούνται ενημερώσεις υπερύθρων, οι αλλαγές κώδικα ενεργοποιούν μια διοχέτευση GitLab CI που ρυθμίσαμε, η οποία επικυρώνει και αναπτύσσει τις αλλαγές σε διάφορα περιβάλλοντα (για παράδειγμα, προσθέτοντας μια άδεια σε μια πολιτική IAM σε λογαριασμούς προγραμματιστών, σταδίων και παραγωγών).
Amazon ECR, Amazon S3 και Lambda: Διευκόλυνση αγωγών
Χρησιμοποιούμε τις ακόλουθες βασικές υπηρεσίες για τη διευκόλυνση του αγωγού μας:
- ECR Amazon – Για να διατηρήσουμε και να επιτρέψουμε εύκολες ανακτήσεις των εικόνων κοντέινερ μοντέλου, τους προσθέτουμε ετικέτες με σημασιολογικές εκδόσεις και τις ανεβάζουμε σε αποθετήρια ECR που έχουν ρυθμιστεί ανά
${project_name}/${model_name}μέσω Terraform. Αυτό επιτρέπει ένα καλό επίπεδο απομόνωσης μεταξύ διαφορετικών μοντέλων και μας επιτρέπει να χρησιμοποιούμε προσαρμοσμένους αλγόριθμους και να μορφοποιούμε αιτήματα συμπερασμάτων και απαντήσεις ώστε να συμπεριλαμβάνονται οι επιθυμητές πληροφορίες δήλωσης μοντέλου (όνομα μοντέλου, έκδοση, διαδρομή δεδομένων εκπαίδευσης κ.λπ.). - Amazon S3 – Χρησιμοποιούμε κάδους S3 για να διατηρήσουμε δεδομένα εκπαίδευσης μοντέλων, εκπαιδευμένα τεχνουργήματα μοντέλων ανά μοντέλο, DAG ροής αέρα και άλλες πρόσθετες πληροφορίες που απαιτούνται από τους αγωγούς.
- Λάμδα – Επειδή το σύμπλεγμα Airflow μας έχει αναπτυχθεί σε ξεχωριστό VPC για λόγους ασφαλείας, δεν είναι δυνατή η απευθείας πρόσβαση στα DAG. Επομένως, χρησιμοποιούμε μια συνάρτηση Lambda, η οποία διατηρείται επίσης με το Terraform, για να ενεργοποιήσουμε τυχόν DAG που καθορίζονται από το όνομα DAG. Με την κατάλληλη ρύθμιση IAM, η εργασία GitLab CI ενεργοποιεί τη συνάρτηση Lambda, η οποία περνά μέσα από τις διαμορφώσεις μέχρι τα απαιτούμενα DAG εκπαίδευσης ή ανάπτυξης.
Amazon MWAA: Αγωγοί εκπαίδευσης και ανάπτυξης
Όπως αναφέρθηκε προηγουμένως, χρησιμοποιούμε το Amazon MWAA για την ενορχήστρωση των αγωγών εκπαίδευσης και ανάπτυξης. Χρησιμοποιούμε τελεστές SageMaker που είναι διαθέσιμοι στο Πακέτο παρόχου Amazon για Airflow για ενσωμάτωση με το SageMaker (για αποφυγή προτύπων jinja).
Χρησιμοποιούμε τους ακόλουθους τελεστές σε αυτόν τον αγωγό εκπαίδευσης (που φαίνεται στο ακόλουθο διάγραμμα ροής εργασίας):

Εκπαιδευτικός αγωγός MWAA
Χρησιμοποιούμε τους ακόλουθους τελεστές στον αγωγό ανάπτυξης (που φαίνεται στο ακόλουθο διάγραμμα ροής εργασίας):

Μοντέλο αγωγού ανάπτυξης
Χρησιμοποιούμε το Slack και το Amazon SNS για τη δημοσίευση των μηνυμάτων σφάλματος/επιτυχίας και των αποτελεσμάτων αξιολόγησης και στους δύο αγωγούς. Το Slack παρέχει ένα ευρύ φάσμα επιλογών για την προσαρμογή των μηνυμάτων, συμπεριλαμβανομένων των εξής:
- SnsPublishOperator - Χρησιμοποιούμε SnsPublishOperator για αποστολή ειδοποιήσεων επιτυχίας/αποτυχίας στα email των χρηστών
- Slack API – Δημιουργήσαμε το εισερχόμενη διεύθυνση URL webhook για να λαμβάνετε τις ειδοποιήσεις του αγωγού στο επιθυμητό κανάλι
CloudWatch και VMware Wavefront: Παρακολούθηση και καταγραφή
Χρησιμοποιούμε έναν πίνακα εργαλείων CloudWatch για να διαμορφώσουμε την παρακολούθηση και την καταγραφή τελικού σημείου. Βοηθά στην οπτικοποίηση και παρακολούθηση διαφόρων λειτουργικών μετρήσεων και μετρήσεων απόδοσης μοντέλων ειδικά για κάθε έργο. Εκτός από τις πολιτικές αυτόματης κλιμάκωσης που έχουν ρυθμιστεί για την παρακολούθηση ορισμένων από αυτές, παρακολουθούμε συνεχώς τις αλλαγές στη χρήση της CPU και της μνήμης, των αιτημάτων ανά δευτερόλεπτο, των καθυστερήσεων απόκρισης και των μετρήσεων του μοντέλου.
Το CloudWatch είναι ακόμη ενσωματωμένο με έναν πίνακα εργαλείων VMware Tanzu Wavefront, ώστε να μπορεί να απεικονίσει τις μετρήσεις για τα τελικά σημεία του μοντέλου καθώς και άλλες υπηρεσίες σε επίπεδο έργου.
Επιχειρηματικά οφέλη και τι ακολουθεί
Οι αγωγοί ML είναι πολύ σημαντικοί για τις υπηρεσίες και τις δυνατότητες ML. Σε αυτήν την ανάρτηση, συζητήσαμε μια περίπτωση χρήσης ML από άκρο σε άκρο που χρησιμοποιεί δυνατότητες από το AWS. Κατασκευάσαμε έναν προσαρμοσμένο αγωγό χρησιμοποιώντας το SageMaker και το Amazon MWAA, το οποίο μπορούμε να επαναχρησιμοποιήσουμε σε έργα και μοντέλα, και αυτοματοποιήσαμε τον κύκλο ζωής του ML, ο οποίος μείωσε τον χρόνο από την εκπαίδευση του μοντέλου μέχρι την ανάπτυξη παραγωγής σε μόλις 10 λεπτά.
Με τη μετατόπιση του βάρους του κύκλου ζωής ML στο SageMaker, παρείχε βελτιστοποιημένη και επεκτάσιμη υποδομή για την εκπαίδευση και την ανάπτυξη του μοντέλου. Η προβολή μοντέλων με το SageMaker μας βοήθησε να κάνουμε προβλέψεις σε πραγματικό χρόνο με λανθάνοντες χρόνους χιλιοστών του δευτερολέπτου και δυνατότητες παρακολούθησης. Χρησιμοποιήσαμε το Terraform για την ευκολία εγκατάστασης και τη διαχείριση της υποδομής.
Τα επόμενα βήματα για αυτόν τον αγωγό θα είναι η ενίσχυση του αγωγού εκπαίδευσης μοντέλων με δυνατότητες επανεκπαίδευσης είτε είναι προγραμματισμένο είτε βασίζεται σε ανίχνευση μετατόπισης μοντέλων, υποστήριξη ανάπτυξης σκιάς ή δοκιμή A/B για ταχύτερη και κατάλληλη ανάπτυξη μοντέλου και παρακολούθηση γενεαλογίας ML. Σχεδιάζουμε επίσης να αξιολογήσουμε Αγωγοί Amazon SageMaker επειδή τώρα υποστηρίζεται η ενοποίηση του GitLab.
Διδάγματα
Ως μέρος της οικοδόμησης αυτής της λύσης, μάθαμε ότι πρέπει να γενικεύετε νωρίς, αλλά να μην το γενικεύετε υπερβολικά. Όταν ολοκληρώσαμε για πρώτη φορά τον σχεδιασμό της αρχιτεκτονικής, προσπαθήσαμε να δημιουργήσουμε και να επιβάλουμε πρότυπα κώδικα για τον κώδικα μοντέλου ως βέλτιστη πρακτική. Ωστόσο, ήταν τόσο νωρίς στη διαδικασία ανάπτυξης που τα πρότυπα ήταν είτε πολύ γενικευμένα είτε πολύ λεπτομερή για να μπορούν να επαναχρησιμοποιηθούν για μελλοντικά μοντέλα.
Μετά την παράδοση του πρώτου μοντέλου μέσω του αγωγού, τα πρότυπα βγήκαν φυσικά με βάση τις πληροφορίες από την προηγούμενη δουλειά μας. Ένας αγωγός δεν μπορεί να κάνει τα πάντα από την πρώτη μέρα.
Ο πειραματισμός και η παραγωγή μοντέλων έχουν συχνά πολύ διαφορετικές (ή μερικές φορές ακόμη και αντικρουόμενες) απαιτήσεις. Είναι ζωτικής σημασίας να εξισορροπήσουμε αυτές τις απαιτήσεις από την αρχή ως ομάδα και να ιεραρχήσουμε ανάλογα.
Επιπλέον, μπορεί να μην χρειάζεστε όλες τις δυνατότητες μιας υπηρεσίας. Η χρήση βασικών χαρακτηριστικών από μια υπηρεσία και η διαμορφωμένη σχεδίαση είναι κλειδιά για αποτελεσματικότερη ανάπτυξη και ευέλικτο αγωγό.
Συμπέρασμα
Σε αυτήν την ανάρτηση, δείξαμε πώς κατασκευάσαμε μια λύση MLOps χρησιμοποιώντας το SageMaker και το Amazon MWAA που αυτοματοποίησε τη διαδικασία ανάπτυξης μοντέλων στην παραγωγή, με ελάχιστη χειροκίνητη παρέμβαση από επιστήμονες δεδομένων. Σας ενθαρρύνουμε να αξιολογήσετε διάφορες υπηρεσίες AWS όπως το SageMaker, το Amazon MWAA, το Amazon S3 και το Amazon ECR για να δημιουργήσετε μια ολοκληρωμένη λύση MLOps.
*Το Apache, το Apache Airflow και το Airflow είναι σήματα κατατεθέντα ή εμπορικά σήματα της Apache Software Foundation στις Ηνωμένες Πολιτείες ή / και σε άλλες χώρες.
Σχετικά με τους Συγγραφείς
 Deepak Mettem είναι Senior Engineering Manager στο VMware, Carbon Black Unit. Αυτός και η ομάδα του εργάζονται για τη δημιουργία εφαρμογών και υπηρεσιών που βασίζονται σε ροή που είναι εξαιρετικά διαθέσιμες, επεκτάσιμες και ανθεκτικές για να προσφέρουν στους πελάτες λύσεις που βασίζονται στη μηχανική εκμάθηση σε πραγματικό χρόνο. Αυτός και η ομάδα του είναι επίσης υπεύθυνοι για τη δημιουργία εργαλείων που είναι απαραίτητα για τους επιστήμονες δεδομένων για την κατασκευή, την εκπαίδευση, την ανάπτυξη και την επικύρωση των μοντέλων ML τους στην παραγωγή.
Deepak Mettem είναι Senior Engineering Manager στο VMware, Carbon Black Unit. Αυτός και η ομάδα του εργάζονται για τη δημιουργία εφαρμογών και υπηρεσιών που βασίζονται σε ροή που είναι εξαιρετικά διαθέσιμες, επεκτάσιμες και ανθεκτικές για να προσφέρουν στους πελάτες λύσεις που βασίζονται στη μηχανική εκμάθηση σε πραγματικό χρόνο. Αυτός και η ομάδα του είναι επίσης υπεύθυνοι για τη δημιουργία εργαλείων που είναι απαραίτητα για τους επιστήμονες δεδομένων για την κατασκευή, την εκπαίδευση, την ανάπτυξη και την επικύρωση των μοντέλων ML τους στην παραγωγή.
 Mahima Agarwal είναι Μηχανικός Μηχανικής Μάθησης στο VMware, Carbon Black Unit.
Mahima Agarwal είναι Μηχανικός Μηχανικής Μάθησης στο VMware, Carbon Black Unit.
Εργάζεται στο σχεδιασμό, την κατασκευή και την ανάπτυξη των βασικών στοιχείων και της αρχιτεκτονικής της πλατφόρμας μηχανικής εκμάθησης για το VMware CB SBU.
 Βάμσι Κρίσνα Εναμποθάλα είναι Sr. Applied AI Specialist Architect στο AWS. Συνεργάζεται με πελάτες από διαφορετικούς τομείς για να επιταχύνει πρωτοβουλίες δεδομένων, αναλύσεων και μηχανικής μάθησης υψηλού αντίκτυπου. Είναι παθιασμένος με τα συστήματα συστάσεων, το NLP και τους τομείς όρασης υπολογιστών στο AI και ML. Εκτός δουλειάς, ο Vamshi είναι λάτρης του RC, κατασκευάζει εξοπλισμό RC (αεροπλάνα, αυτοκίνητα και drones) και του αρέσει επίσης η κηπουρική.
Βάμσι Κρίσνα Εναμποθάλα είναι Sr. Applied AI Specialist Architect στο AWS. Συνεργάζεται με πελάτες από διαφορετικούς τομείς για να επιταχύνει πρωτοβουλίες δεδομένων, αναλύσεων και μηχανικής μάθησης υψηλού αντίκτυπου. Είναι παθιασμένος με τα συστήματα συστάσεων, το NLP και τους τομείς όρασης υπολογιστών στο AI και ML. Εκτός δουλειάς, ο Vamshi είναι λάτρης του RC, κατασκευάζει εξοπλισμό RC (αεροπλάνα, αυτοκίνητα και drones) και του αρέσει επίσης η κηπουρική.
 Σαχίλ Θαπάρ είναι αρχιτέκτονας Enterprise Solutions. Συνεργάζεται με πελάτες για να τους βοηθήσει να δημιουργήσουν εξαιρετικά διαθέσιμες, επεκτάσιμες και ανθεκτικές εφαρμογές στο AWS Cloud. Αυτήν τη στιγμή επικεντρώνεται σε κοντέινερ και λύσεις μηχανικής εκμάθησης.
Σαχίλ Θαπάρ είναι αρχιτέκτονας Enterprise Solutions. Συνεργάζεται με πελάτες για να τους βοηθήσει να δημιουργήσουν εξαιρετικά διαθέσιμες, επεκτάσιμες και ανθεκτικές εφαρμογές στο AWS Cloud. Αυτήν τη στιγμή επικεντρώνεται σε κοντέινερ και λύσεις μηχανικής εκμάθησης.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- Platoblockchain. Web3 Metaverse Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- πηγή: https://aws.amazon.com/blogs/machine-learning/how-vmware-built-an-mlops-pipeline-from-scratch-using-gitlab-amazon-mwaa-and-amazon-sagemaker/
- :είναι
- $UP
- 1
- 10
- 100
- 7
- 8
- a
- Σχετικά
- επιταχύνουν
- πρόσβαση
- πρόσβαση
- αναλόγως
- Λογαριασμοί
- επιτευχθεί
- απέναντι
- απεριοδικός
- Επιπλέον
- Πρόσθετος
- Επιπλέον πληροφορίες
- Μετά το
- κατά
- AI
- αλγόριθμοι
- Όλα
- επιτρέπει
- Amazon
- Amazon Sage Maker
- ανάλυση
- analytics
- και
- οπουδήποτε
- Apache
- api
- Εφαρμογή
- εφαρμογές
- εφαρμοσμένος
- Εφαρμοσμένη AI
- έγκριση
- αρχιτεκτονική
- ΕΙΝΑΙ
- περιοχές
- AS
- άποψη
- At
- Επιθέσεις
- συγγραφικός
- αυτόματη
- Αυτοματοποιημένη
- αυτοκίνητα
- διαθεσιμότητα
- διαθέσιμος
- αποφύγετε
- AWS
- Backend
- Υπόλοιπο
- βασίζονται
- βασικός
- BE
- επειδή
- Αρχή
- οφέλη
- ΚΑΛΎΤΕΡΟΣ
- Καλύτερα
- μεταξύ
- Μαύρη
- Αποκλεισμός
- Υποκατάστημα
- φέρω
- χτίζω
- Κτίριο
- χτισμένο
- βάρος
- by
- CAN
- δεν μπορώ
- δυνατότητες
- άνθρακας
- αυτοκίνητα
- περίπτωση
- CB
- ορισμένες
- Αλλαγές
- κανάλια
- παιδί
- επέλεξε
- Backup
- συστάδα
- κωδικός
- συλλογή
- Επικοινωνία
- σύγκριση
- πλήρης
- εξαρτήματα
- Υπολογίστε
- υπολογιστή
- Computer Vision
- συμπεριφέρεται
- διαμόρφωση
- διαμορφώσεις
- Αντιφατικός
- σύγχυση
- θεωρήσεις
- καταναλώνουν
- καταναλώνεται
- Δοχείο
- Εμπορευματοκιβώτια
- συνεχώς
- Βολικός
- πυρήνας
- θα μπορούσε να
- χώρες
- CPU
- δημιουργία
- δημιουργήθηκε
- δημιουργεί
- δημιουργία
- κρίσιμης
- κρίσιμος
- Τη στιγμή
- έθιμο
- Πελάτες
- προσαρμόσετε
- cyberattacks
- DAG
- καθημερινά
- ταμπλό
- ημερομηνία
- επιστήμονας δεδομένων
- ημέρα
- ορίζεται
- παράδοση
- παρατάσσω
- αναπτυχθεί
- ανάπτυξη
- ανάπτυξη
- αναπτύξεις
- αναπτύσσεται
- Υπηρεσίες
- σχεδιασμένα
- σχέδιο
- λεπτομερής
- καθέκαστα
- Ανίχνευση
- Dev
- αναπτύχθηκε
- ανάπτυξη
- Ανάπτυξη
- διαφορετικές
- κατευθείαν
- συζητήσουν
- συζήτηση
- Λιμενεργάτης
- Μην
- κάτω
- Drones
- κάθε
- Νωρίτερα
- Νωρίς
- ευκολία στη χρήση
- αποτελεσματικός
- είτε
- ΗΛΕΚΤΡΟΝΙΚΗ ΔΙΕΥΘΥΝΣΗ
- σμυριδόπετρα
- ενεργοποιήσετε
- ενεργοποιημένη
- δίνει τη δυνατότητα
- ενθαρρύνει
- από άκρη σε άκρη
- Τελικό σημείο
- μηχανικός
- Μηχανική
- Εταιρεία
- Επιχειρηματικές Λύσεις
- θιασώτης
- περιβάλλοντα
- εξοπλισμός
- ουσιώδης
- Αιθέρας (ΕΤΗ)
- αξιολογήσει
- αξιολόγηση
- αξιολογώντας
- εκτίμηση
- αξιολογήσεις
- Even
- Συμβάν
- Κάθε
- πάντα
- παράδειγμα
- Ανάπτυξη
- επέκταση
- f1
- διευκολύνω
- Αποτυχία
- μακριά
- γρηγορότερα
- Χαρακτηριστικό
- Χαρακτηριστικά
- λίγοι
- Αρχεία
- Όνομα
- εύκαμπτος
- Συγκέντρωση
- επικεντρώθηκε
- εστιάζει
- Εξής
- Για
- μορφή
- από
- πλήρη
- όλο το φάσμα
- πλήρως
- λειτουργία
- λειτουργίες
- περαιτέρω
- μελλοντικός
- παράγεται
- παίρνω
- καλός
- Group
- Έχω
- που έχει
- βοήθεια
- βοήθησε
- βοηθά
- Ψηλά
- υψηλή απόδοση
- υψηλά
- φιλοξενία
- Πως
- Ωστόσο
- HTML
- http
- HTTPS
- IAM
- ID
- ιδανικό
- προσδιορίζονται
- προσδιορίσει
- Ταυτότητα
- εικόνα
- εικόνες
- εφαρμογή
- εκτέλεση
- εφαρμοστεί
- in
- περιλαμβάνουν
- περιλαμβάνει
- Συμπεριλαμβανομένου
- πληροφορίες
- Υποδομή
- πρωτοβουλίες
- ιδέες
- ενσωματώσει
- ενσωματωθεί
- Ενσωματώνει
- ολοκλήρωση
- αλληλεπιδρούν
- παρέμβαση
- επικαλείται
- συμμετέχουν
- απομόνωση
- IT
- ΤΟΥ
- Δουλειά
- Θέσεις εργασίας
- jpg
- Διατήρηση
- Κλειδί
- πλήκτρα
- Αφάνεια
- στρώμα
- μάθει
- μάθηση
- Μαθήματα
- Διδάγματα
- Αφήνει
- Επίπεδο
- κύκλος ζωής
- Μου αρέσει
- λίγο
- φορτίο
- Χαμηλός
- μηχανή
- μάθηση μηχανής
- Κυρίως
- διατηρήσουν
- διατηρεί
- συντήρηση
- κάνω
- διαχείριση
- διαχειρίζεται
- διαχείριση
- διευθυντής
- διαχειρίζεται
- διαχείριση
- Ταχύτητες
- Μήτρα
- Μνήμη
- που αναφέρθηκαν
- μηνύματα
- μηνυμάτων
- Metrics
- ενδέχεται να
- χιλιοστά του δευτερολέπτου
- πρακτικά
- ML
- MLOps
- μοντέλο
- μοντέλα
- ΜΟΝΤΕΡΝΑ
- Παρακολούθηση
- παρακολούθηση
- περισσότερο
- πιο αποτελεσματικό
- πολλαπλούς
- όνομα
- φυσικά
- απαραίτητος
- Ανάγκη
- Νέα
- επόμενη
- nlp
- Θόρυβος
- κοινοποίηση
- κοινοποιήσεις
- αριθμός
- of
- προσφορά
- προσφορές
- on
- ONE
- επιχειρήσεων
- φορείς
- βελτιστοποιημένη
- Επιλογές
- ενορχηστρωμένη
- Οργανωμένος
- ΑΛΛΑ
- εκτός
- φόρμες
- πακέτο
- Packages
- συσκευασία
- μέρος
- περάσματα
- Πέρασμα
- παθιασμένος
- μονοπάτι
- επίδοση
- άδεια
- αγωγού
- σχέδιο
- Αεροπλάνα
- πλατφόρμες
- Πλάτων
- Πληροφορία δεδομένων Plato
- Πλάτωνα δεδομένα
- Πολιτικές
- πολιτική
- Θέση
- πρακτική
- Προβλέψεις
- προηγούμενος
- Δώστε προτεραιότητα
- διαδικασια μας
- Προϊόν
- παραγωγή
- σχέδιο
- έργα
- κατάλληλος
- προστασία
- παρέχεται
- προμηθευτής
- παρέχει
- δημοσιεύει
- δημοσιεύθηκε
- Δημοσιεύει
- Δημοσιεύσεις
- σκοποί
- αρμόδιος
- σειρά
- σε πραγματικό χρόνο
- Σύσταση
- Μειωμένος
- αναφέρεται
- καταχωρηθεί
- μητρώου
- Σχέσεις
- μακρινός
- Περίφημος
- Αποθήκη
- ζητείται
- αιτήματα
- απαιτείται
- απαιτήσεις
- έρευνα
- ελαστικός
- απάντησης
- υπεύθυνος
- Αποτελέσματα
- επανεκπαίδευση
- επαναχρησιμοποιήσιμη
- ρόλους
- τρέξιμο
- δρομέας
- σοφός
- ίδιο
- επεκτάσιμη
- απολέπιση
- πρόγραμμα
- προγραμματιστεί
- Επιστήμονας
- επιστήμονες
- Δεύτερος
- τμήματα
- Τομείς
- ασφάλεια
- αρχαιότερος
- ξεχωριστό
- Χωρίς διακομιστή
- Διακομιστές
- υπηρεσία
- Υπηρεσίες
- εξυπηρετούν
- σειρά
- setup
- σκιά
- ΜΕΤΑΤΟΠΙΣΗ
- θα πρέπει να
- παρουσιάζεται
- Απλούς
- χαλαρότητα
- So
- μέχρι τώρα
- λογισμικό
- λύση
- Λύσεις
- μερικοί
- Πηγή
- πρωτογενής κώδικας
- ειδικός
- συγκεκριμένες
- καθορίζεται
- Φάσμα
- Προβολέας θέατρου
- Στάδιο
- στάδια
- πρότυπο
- Εκκίνηση
- ξεκινά
- Μελών
- Βήματα
- χώρος στο δίσκο
- Στρατηγική
- ροής
- εξορθολογισμό
- μεταγενέστερος
- Επιτυχώς
- τέτοιος
- υποστήριξη
- υποστηριζόνται!
- Επιφάνεια
- συστήματα
- TAG
- Πάρτε
- εργασίες
- πρότυπα
- Terraform
- Δοκιμές
- ότι
- Η
- τους
- Τους
- επομένως
- Αυτοί
- απειλές
- τρία
- Μέσω
- παντού
- διακίνηση
- ώρα
- timestamp
- προς την
- μαζι
- πολύ
- εργαλείο
- εργαλεία
- κορυφή
- τοπικός
- τροχιά
- Παρακολούθηση
- εμπορικά σήματα
- ΚΙΝΗΣΗ στους ΔΡΟΜΟΥΣ
- Τρένο
- εκπαιδευμένο
- Εκπαίδευση
- ενεργοποιούν
- ενεργοποιήθηκε
- ΣΤΡΟΦΗ
- υπό
- μονάδα
- Ενωμένος
- United States
- ενημερώσεις
- us
- Χρήση
- χρήση
- περίπτωση χρήσης
- Χρήστες
- Χρήστες
- ΕΠΙΚΥΡΩΝΩ
- επικύρωση
- μεταβλητές
- διάφορα
- εκδοχή
- πρακτικώς
- όραμα
- φαντάζομαι
- vmware
- τόμος
- Τρόπος..
- ΛΟΙΠΌΝ
- Τι
- αν
- Ποιό
- ευρύς
- Ευρύ φάσμα
- με
- εντός
- χωρίς
- Εργασία
- ροής εργασίας
- ροές εργασίας
- λειτουργεί
- θα
- zephyrnet
- Zip
- ζώνες