Δεν τα κατάφερα φέτος στην Πούντα Κάνα  αλλά είμαι χαρούμενος (από απόσταση) για τους ανθρώπους που κατάφεραν να φτάσουν εκεί παρά τους ταξιδιωτικούς περιορισμούς! Premium περιεχόμενο στο εσωτερικό.
αλλά είμαι χαρούμενος (από απόσταση) για τους ανθρώπους που κατάφεραν να φτάσουν εκεί παρά τους ταξιδιωτικούς περιορισμούς! Premium περιεχόμενο στο εσωτερικό.
Το φθινόπωρο ήταν πολύ απασχολημένο και θα ήθελα να δοκιμάσω μια πιο σύντομη μορφή: κάθε μεγάλο θέμα έχει έναν "προβολέα"  εργασία στο κύριο μπλοκ που βρίσκω ιδιαίτερα ενδιαφέρουσα, και αρκετά σχετικά έργα που έχουν λίγο πιο σύντομη περιγραφή.
εργασία στο κύριο μπλοκ που βρίσκω ιδιαίτερα ενδιαφέρουσα, και αρκετά σχετικά έργα που έχουν λίγο πιο σύντομη περιγραφή.
Το σχέδιο για σήμερα:
- KG-augmented Language Models: Κατηγοριοποίηση
- Conversational AI: Stop Hallucinating, Bro
- Entity Linking: In the Shadow of Colossal (Οντότητες)
- KG Κατασκευή
- KG Ερώτηση Απάντηση: Προσθέστε μερικά
 SPARQL
SPARQL
Εάν αυτό το σε βάθος εκπαιδευτικό περιεχόμενο είναι χρήσιμο για εσάς, εγγραφείτε στη λίστα αλληλογραφίας της AI μας να ειδοποιούμε όταν κυκλοφορούμε νέο υλικό.
KG-augmented Language Models: Κατηγοριοποίηση
Αναπαράσταση σχεσιακής παγκόσμιας γνώσης σε μοντέλα γλώσσας με βάση τα συμφραζόμενα: μια ανασκόπηση από την Tara Safavi και την Danai Koutra
Εάν είστε έμπειρος αναγνώστης τέτοιων αναλύσεων (ή προηγούμενων αναρτήσεων), τότε γνωρίζετε πολύ καλά την αφθονία των επαυξημένων LMs KG που δημοσιεύονται σε κάθε συνέδριο και ανεβαίνουν στο arxiv εβδομαδιαία. Αν νιώθεις χαμένος  — Μπορώ να διαβεβαιώσω ότι δεν είσαι ο μόνος.
— Μπορώ να διαβεβαιώσω ότι δεν είσαι ο μόνος.
Φέτος, επιτέλους έχουμε ένα υγιές πλαίσιο και ταξινόμηση διαφόρων προσεγγίσεων KG+LM! Οι συγγραφείς ορίζουν 3 μεγάλες οικογένειες: 1⃣ χωρίς επίβλεψη KG, ανίχνευση γνώσης που κωδικοποιείται σε παραμέτρους LM με προτροπές τύπου cloze. 2⃣ Εποπτεία KG με οντότητες και ταυτότητες. 3⃣ Επίβλεψη KG με πρότυπα σχέσης και φόρμες επιφάνειας.
Κάθε οικογένεια έχει μερικά υποκαταστήματα  Για παράδειγμα, ας ρίξουμε μια ματιά σε 4 μοντέλα με επίγνωση οντοτήτων που απεικονίζονται παρακάτω. Ποικίλει από “λιγότερο συμβολικό” προς την “Πιο συμβολικό”, ορισμένα LM εκτελούν κάλυψη του εύρους αναφοράς ή εκμάθηση αντίθεσης ή συγχώνευση ενσωματώσεων οντοτήτων από ένα γνωστό λεξιλόγιο. Οι συγγραφείς έκαναν εξαιρετική δουλειά ταξινομώντας δεκάδες υπάρχουσες αρχιτεκτονικές σύμφωνα με το πλαίσιο και φαίνεται πολύ καλύτερα οργανωμένο τώρα. Πολύ απαραίτητη δουλειά!
Για παράδειγμα, ας ρίξουμε μια ματιά σε 4 μοντέλα με επίγνωση οντοτήτων που απεικονίζονται παρακάτω. Ποικίλει από “λιγότερο συμβολικό” προς την “Πιο συμβολικό”, ορισμένα LM εκτελούν κάλυψη του εύρους αναφοράς ή εκμάθηση αντίθεσης ή συγχώνευση ενσωματώσεων οντοτήτων από ένα γνωστό λεξιλόγιο. Οι συγγραφείς έκαναν εξαιρετική δουλειά ταξινομώντας δεκάδες υπάρχουσες αρχιτεκτονικές σύμφωνα με το πλαίσιο και φαίνεται πολύ καλύτερα οργανωμένο τώρα. Πολύ απαραίτητη δουλειά! 

Μερικές σύντομες εργασίες επικεντρώνονται στον εμπλουτισμό των LM με βιοϊατρικά KG, μια μακροχρόνια προσπάθεια να διδαχθούν στα LM μια βιοϊατρική ειδική για τον τομέα αργκό. Οι Meng et al προτείνω Μείγμα χωρισμάτων (MoP), ένα LM που βασίζεται στο AdapterFusion τεχνική που μειώνει την ανάγκη προεκπαίδευσης των LM από την αρχή. Το MoP εκπαιδεύτηκε με κοινά βιοϊατρικά λεξιλόγια και οντολογίες UMLS και SNOMED CT. Sung et al ζητώ «Μπορούν τα γλωσσικά μοντέλα να είναι βάσεις βιοϊατρικής γνώσης;» αναφερόμενος στο διάσημη εργασία EMNLP'19 των Petroni et al. Η απάντηση είναι σε μεγάλο βαθμό ΟΧΙ. Σχεδιάζουν οι συγγραφείς BioLAMA, ένα σημείο αναφοράς για τη διερεύνηση της βιοϊατρικής γνώσης που δημιουργήθηκε από UMLS, CTD και Wikidata. Διαπιστώνουν ότι τα σύγχρονα LM έχουν ακρίβεια <10% σε αυτούς τους ανιχνευτές, επομένως η κοινότητα χρειάζεται σίγουρα κάτι πιο αξιόπιστο
Οι Meng et al προτείνω Μείγμα χωρισμάτων (MoP), ένα LM που βασίζεται στο AdapterFusion τεχνική που μειώνει την ανάγκη προεκπαίδευσης των LM από την αρχή. Το MoP εκπαιδεύτηκε με κοινά βιοϊατρικά λεξιλόγια και οντολογίες UMLS και SNOMED CT. Sung et al ζητώ «Μπορούν τα γλωσσικά μοντέλα να είναι βάσεις βιοϊατρικής γνώσης;» αναφερόμενος στο διάσημη εργασία EMNLP'19 των Petroni et al. Η απάντηση είναι σε μεγάλο βαθμό ΟΧΙ. Σχεδιάζουν οι συγγραφείς BioLAMA, ένα σημείο αναφοράς για τη διερεύνηση της βιοϊατρικής γνώσης που δημιουργήθηκε από UMLS, CTD και Wikidata. Διαπιστώνουν ότι τα σύγχρονα LM έχουν ακρίβεια <10% σε αυτούς τους ανιχνευτές, επομένως η κοινότητα χρειάζεται σίγουρα κάτι πιο αξιόπιστο  .
.
Conversational AI: Stop Hallucinating, Bro
Neural Path Hunter: Μείωση της ψευδαίσθησης στα συστήματα διαλόγου μέσω της γείωσης διαδρομής των Nouha Dziri, Andrea Madotto, Osmar Zaiane, Avishek Joey Bose
Η δημιουργία απαντήσεων με ένα σύστημα ConvAI με φόντο KG είναι δύσκολη. Σε συστήματα αγωγών με πολλά στοιχεία, χρησιμοποιείτε αυστηρά φόρμες επιφάνειας (ονόματα οντοτήτων) και καταφεύγετε κυρίως σε πρότυπα και τα πρότυπα είναι βαρετά και ελάχιστα συντηρήσιμο. Από την άλλη πλευρά, τα μοντέλα παραγωγής e2e όπως το GPT-2 και το GPT-3 παράγουν πολύ πιο μοναδικές απαντήσεις, αλλά συχνά έχουν ψευδαισθήσεις, δηλαδή εισάγετε λάθος ονόματα οντοτήτων όταν δεν το περιμένετε.
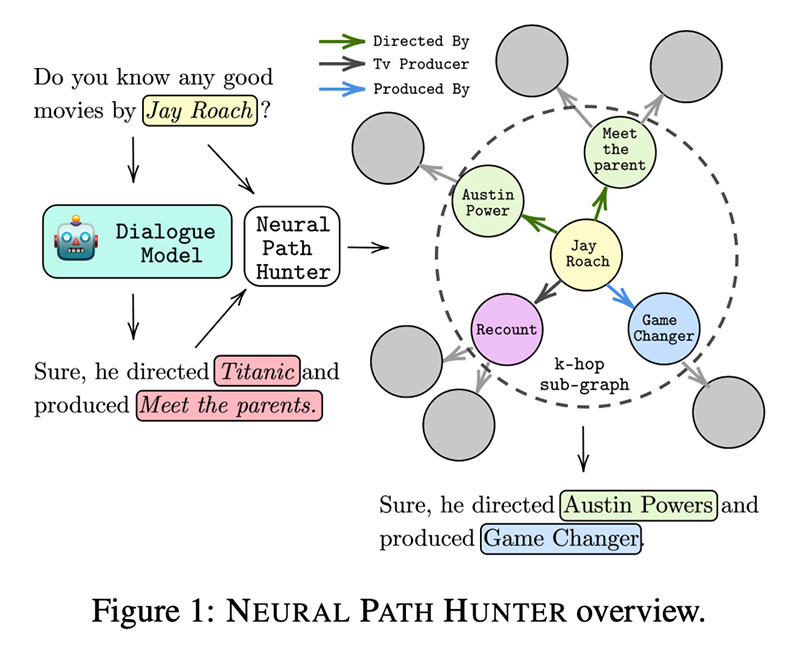
Οι συγγραφείς αυτού του έργου ξεκίνησαν α κυνήγι  για τη μείωση των παραισθήσεων με την επίβλεψη KG που προτείνει Κυνηγός νευρωνικών μονοπατιών. Πρώτον, μελετούν πολλά είδη παραισθήσεων , από πού προέρχονται (κυρίως από δειγματοληψία top-k) και πώς να ποσοτικοποιηθεί.
για τη μείωση των παραισθήσεων με την επίβλεψη KG που προτείνει Κυνηγός νευρωνικών μονοπατιών. Πρώτον, μελετούν πολλά είδη παραισθήσεων , από πού προέρχονται (κυρίως από δειγματοληψία top-k) και πώς να ποσοτικοποιηθεί.
Το ίδιο το NPH αποτελείται από δύο ενότητες: 1⃣ ένα κριτικό (μη αυτοπαλινδρομικό LM) που εκτελεί δυαδική ταξινόμηση σε διακριτικά. 2⃣ entity retriver για τη διόρθωση σφαλμάτων οντοτήτων: πρόκειται ουσιαστικά για μια μνήμη οντοτήτων όπου οι ενσωματώσεις οντοτήτων προέρχονται από το GPT και ενημερώνονται με CompGCN χρησιμοποιώντας τη δομή του γραφήματος. Οι πιο εύλογοι υποψήφιοι προέρχονται από την εφαρμογή της συνάρτησης βαθμολόγησης DistMult. Voila!
Το NPH μπορεί να συνδυαστεί με οποιοδήποτε προεκπαιδευμένο LM, πειράματα στο OpenDialKG σημείο αναφοράς με GPT2-KG, GPT2-KE, να AdapterBot παρουσιάζουν σημαντική μείωση  των παραισθήσεων και αύξηση
των παραισθήσεων και αύξηση  στην πίστη. Μια μελέτη χρηστών αναφέρει ότι η ανθρώπινη ψευδαίσθηση μειώνεται ~ 2 φορές στα μοντέλα NPH
στην πίστη. Μια μελέτη χρηστών αναφέρει ότι η ανθρώπινη ψευδαίσθηση μειώνεται ~ 2 φορές στα μοντέλα NPH
Μια άλλη σχετική εργασία στο πλαίσιο αυτό: Οι Honovich et al μελετήστε το ίδιο πρόβλημα σε συστήματα διαλόγου, αλλά χωρίς KG υπόβαθρο και προτείνετε ένα νέο σημείο αναφοράς Q² για να μετρήσετε την πραγματική συνέπεια της δημιουργίας ερωτήσεων και της απάντησης ερωτήσεων (από όπου προέρχονται και τα δύο Q, αν ρωτήσετε).
Εάν είστε στο ConvAI και τα KG της κοινής λογικής — φροντίστε να ελέγξετε το CLUE (Conversational Multi-Hop Reasoner) έως Arabshahi, Lee, et αϊπου ενσωματώνει την έννοια του αν-(κατάσταση), τότε-(δράση), επειδή-(στόχος) μοτίβα λογικούς κανόνες και συμβολικό συλλογισμό.
Entity Linking: In the Shadow of the Colossus
Αξιολόγηση ευρωστίας της αποσαφήνισης οντοτήτων με χρήση προηγούμενων ερευνών: η περίπτωση επισκίασης οντοτήτων by Vera Provatorova, Svitlana Vakulenko, Samarth Bhargav, Ευάγγελος Κανούλας
Όταν συνδέετε KG πραγματικού κόσμου για γλωσσικές εργασίες, αναπόφευκτα θα συναντήσετε διαφορετικές οντότητες που έχουν ακριβώς το ίδιο όνομα  . Δυστυχώς, η ανθρωπότητα δεν χρησιμοποιεί μοναδικούς κατακερματισμούς για όλες τις οντότητες στον κόσμο, επομένως η αποσαφήνιση οντοτήτων παραμένει ένα σημαντικό βήμα της σύνδεσης οντοτήτων.
. Δυστυχώς, η ανθρωπότητα δεν χρησιμοποιεί μοναδικούς κατακερματισμούς για όλες τις οντότητες στον κόσμο, επομένως η αποσαφήνιση οντοτήτων παραμένει ένα σημαντικό βήμα της σύνδεσης οντοτήτων.

Για παράδειγμα, τα Wikidata έχουν τουλάχιστον 18 οντότητες με το όνομα «Michael Jordan». Συχνά, τα συστήματα EL βασίζονται σε βασικά στατιστικά στοιχεία και βαθμολογίες δημοτικότητας, έτσι ώστε ο πιο δημοφιλής «Μάικλ Τζόρνταν ο μπασκετμπολίστας» θα επισκίαζε λιγότερο εξέχοντες (τουλάχιστον στην ποπ κουλτούρα) ανθρώπους.
 Οι συγγραφείς αντιμετωπίζουν αυτό το πρόβλημα και εισάγουν ένα νέο σύνολο δεδομένων, ShadowLink, για τη μέτρηση του βαθμού σύγχυσης των σύγχρονων συστημάτων EL. Αποδεικνύεται ότι η υψηλότερη βαθμολογία F1 μόλις φτάνει το 0.35 (πρόσφατη γενετική ΕΙΔΟΣ αποδόσεις 0.26) στο πιο δύσκολο κομμάτι. Όλα τα συστήματα κορεστούν τις βαθμολογίες τους σε σπάνιες οντότητες με μακριά ουρά και αντιμετωπίζουν επίσης πιο κοινές οντότητες. Η κύρια πρόκληση διατυπώνεται ως «Αυτό που κάνει το έργο δύσκολο είναι ο συνδυασμός ασάφειας και ασυνήθιστου". Θα συνιστούσα στους συγγραφείς να ανεβάσουν το σύνολο δεδομένων στο Σύνολο δεδομένων HuggingFace για να αυξήσουν την προβολή του κουλ έργου τους
Οι συγγραφείς αντιμετωπίζουν αυτό το πρόβλημα και εισάγουν ένα νέο σύνολο δεδομένων, ShadowLink, για τη μέτρηση του βαθμού σύγχυσης των σύγχρονων συστημάτων EL. Αποδεικνύεται ότι η υψηλότερη βαθμολογία F1 μόλις φτάνει το 0.35 (πρόσφατη γενετική ΕΙΔΟΣ αποδόσεις 0.26) στο πιο δύσκολο κομμάτι. Όλα τα συστήματα κορεστούν τις βαθμολογίες τους σε σπάνιες οντότητες με μακριά ουρά και αντιμετωπίζουν επίσης πιο κοινές οντότητες. Η κύρια πρόκληση διατυπώνεται ως «Αυτό που κάνει το έργο δύσκολο είναι ο συνδυασμός ασάφειας και ασυνήθιστου". Θα συνιστούσα στους συγγραφείς να ανεβάσουν το σύνολο δεδομένων στο Σύνολο δεδομένων HuggingFace για να αυξήσουν την προβολή του κουλ έργου τους  .
.
Οι Arora et al προσεγγίσουν την οντότητα που συνδέει το πρόβλημα από άλλη κατεύθυνση. Η βασική ιδέα είναι αυτή αληθής το όνομά του οντότητες σε ένα έγγραφο (υπό επεξεργασία από κοινού, όχι ένα προς ένα) σπιθαμή ένας χαμηλόβαθμος υποπεριοχή  στο χώρο όλων των οντοτήτων συμπεριλαμβανομένων των υποψηφίων (δείτε ένα οπτικό παράδειγμα παρακάτω). ο Eingenthemes Η προσέγγιση είναι χωρίς επίβλεψη εάν έχετε προεκπαιδευμένες ενσωματώσεις οντοτήτων — οι συγγραφείς χρησιμοποιούν το DeepWalk πάνω από το αγγλικό υποσύνολο των Wikidata (εναλλακτικά, δοκιμάζουν ενσωματώσεις λέξεων, αλλά δεν λειτουργεί τόσο καλά).
στο χώρο όλων των οντοτήτων συμπεριλαμβανομένων των υποψηφίων (δείτε ένα οπτικό παράδειγμα παρακάτω). ο Eingenthemes Η προσέγγιση είναι χωρίς επίβλεψη εάν έχετε προεκπαιδευμένες ενσωματώσεις οντοτήτων — οι συγγραφείς χρησιμοποιούν το DeepWalk πάνω από το αγγλικό υποσύνολο των Wikidata (εναλλακτικά, δοκιμάζουν ενσωματώσεις λέξεων, αλλά δεν λειτουργεί τόσο καλά).

Ένα εννοιολογικά παρόμοιο πρόβλημα συγκρούσεων που βασίζονται σε οντότητες μελετάται από Longpre et al, δηλαδή, αντικατάσταση γνώσης — εάν αντιστρέψετε μια αληθινή οντότητα σε μια παράγραφο σε τυχαία (ή αντιφατική), θα άλλαζε το μοντέλο την απάντηση; Με άλλα λόγια, θα βασίζονταν τα μοντέλα ΔΠ στην ανάγνωση του πλαισίου ή στην απομνημόνευση της γνώσης; Αποδεικνύεται ότι όταν εκπαιδεύετε μοντέλα QA με τέτοιες αντικαταστάσεις, μπορείτε να αυξήσετε τη γενίκευση OOD με ένα καλό περιθώριο!
Τέλος, ρίξτε μια ματιά στην έρευνα του Οι Tedeschi et al on “NER for Entity Linking: What Works and What's Next”. Οι συγγραφείς εντοπίζουν βασικές προκλήσεις του EL και προσπαθούν να αντιμετωπίσουν αυτές που σχετίζονται με το NER ΝΕΡ4ΕΛ με στόχο τη μείωση του χάσματος απόδοσης μεταξύ μεγάλων προεκπαιδευμένων LM και μικρότερων μοντέλων που είναι ιδιαίτερα σημαντικό σε σενάρια χαμηλών πόρων .

KG Κατασκευή
Δεν κατάφερα να καταλήξω σε μια συναρπαστική γραμμή εδώ :/ Αν ασχολείστε με το OpenIE και το KG Construction, τα παρακάτω άρθρα μπορεί να είναι σχετικά.
Dognin et al προτείνω ReGen, μια προσέγγιση για τη λεπτομέρεια των LM για την εκτέλεση εργασιών Text2Graph και Graph2Text (ή βελτιστοποίησης εξειδικευμένων μοντέλων). Το βασικό συστατικό  προσθέτει μια απώλεια RL (Self-Critical Sequence Training) επιπλέον της τυπικής διασταυρούμενης εντροπίας (CE). Μπορεί εύκολα να προστεθεί σε οποιοδήποτε προεκπαιδευμένο LM — οι συγγραφείς το δοκιμάζουν με T5-Large (770M params) και T5-base (220M params).
προσθέτει μια απώλεια RL (Self-Critical Sequence Training) επιπλέον της τυπικής διασταυρούμενης εντροπίας (CE). Μπορεί εύκολα να προστεθεί σε οποιοδήποτε προεκπαιδευμένο LM — οι συγγραφείς το δοκιμάζουν με T5-Large (770M params) και T5-base (220M params).  Πειραματικά, ReGen βελτιώνεται σημαντικά σε σχέση με τις βασικές γραμμές Text2Graph WebNLG (3–10 βαθμοί κοιλίας ανάλογα με τη μέτρηση) και λειτουργεί σε πολύ μεγαλύτερος Δεδομένα TekGen (6M προπονητικά ζευγάρια).
Πειραματικά, ReGen βελτιώνεται σημαντικά σε σχέση με τις βασικές γραμμές Text2Graph WebNLG (3–10 βαθμοί κοιλίας ανάλογα με τη μέτρηση) και λειτουργεί σε πολύ μεγαλύτερος Δεδομένα TekGen (6M προπονητικά ζευγάρια).
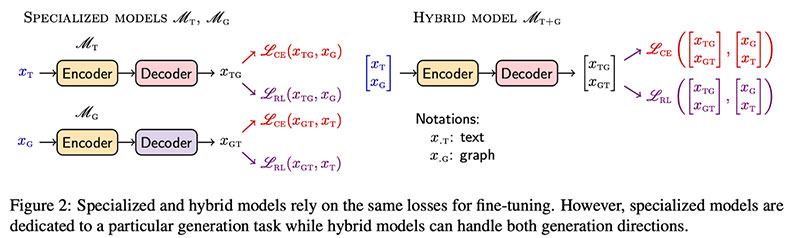
Dash et al μελετήστε το κανονικοποίηση πρόβλημα στο OpenIE — όταν οντότητες με διαφορετικές μορφές επιφάνειας όπως (NYC, Νέα Υόρκη) αναφέρονται στο ίδιο πρωτότυπο. Με τρόπο χωρίς επίβλεψη, θέλουμε τα συστήματα IE να συγκεντρώνουν αυτόματα αυτές τις αναφορές μαζί. Η μέθοδος, ΤΥΜΠΑΝΟ, καταφεύγει σε Variational Autoencoders (VAEs) για να αναγνωρίσει τα clusters (οι οντότητες και οι σχέσεις παραμετροποιούνται από Gaussians). Εκτός από το πρότυπο για VAE απώλεια ανασυγκρότησης, CUVA απασχολεί επιπλέον πρόβλεψη συνδέσμου off με βάση τη συνάρτηση βαθμολόγησης Hole.  Επιπλέον, οι συγγραφείς εισάγουν ένα μυθιστόρημα CanonicNELL σύνολο δεδομένων!
Επιπλέον, οι συγγραφείς εισάγουν ένα μυθιστόρημα CanonicNELL σύνολο δεδομένων!

KG Ερώτηση Απάντηση: Προσθέστε μερικά SPARQL
Ερωτήματα βάσης δεδομένων SPARQLing από αποσυνθέσεις ενδιάμεσων ερωτήσεων by Irina Saparina και Anton Osokin
Δεν υπάρχουν τόσες πολλές εφαρμογές του SPARQL στον τομέα *CL, δυστυχώς. Νομίζω ότι αξίζει πολύ ευρύτερη υιοθέτηση στο NLP. Όταν υποστηρίζεται από μια δροσερή εφαρμογή — είμαι μέσα  .
.
Η πλειοψηφία των δομημένων συνόλων δεδομένων QA ή εκείνων που χρησιμοποιούν σημασιολογική ανάλυση στοχεύουν την SQL ως την κύρια μορφή εξόδου. Υπάρχει ζωή πέρα από τους αγωγούς SQL;
Σαπαρίνα και Οσοκίν προτείνετε μια νέα ματιά σε αυτό το πρόβλημα χρησιμοποιώντας 1⃣ πρώτα a Αναπαράσταση νοήματος αποσύνθεσης ερώτησης (QDMR) πλαίσιο που μεταφράζει μια ερώτηση σε μια ανεξάρτητη από σύνταξη λογική μορφή. 2⃣ αυτή η φόρμα μπορεί να μεταφραστεί σε οποιαδήποτε δομημένη μορφή και εδώ οι συγγραφείς καταφεύγουν στο SPARQL δείχνοντας ότι είναι πολύ πιο εύκολο να ρωτήσετε βάσεις δεδομένων σε μορφή γραφήματος. Απαιτεί μετατροπή ενός πίνακα εισόδου σε RDF, αλλά για σύνολα δεδομένων του Αράχνη κλίμακα μπορεί να γίνει πολύ εύκολα.
Οι εκπαιδεύσιμες ενότητες περιλαμβάνουν Μετασχηματιστής RAT κωδικοποιητής με αποκωδικοποιητή LSTM που παράγει διακριτικά QDMR. QDMR -> SPARQL είναι μια ευθεία μεταγραφή που βασίζεται σε λίγους κανόνες. Αποτελέσματα ίσα προς το SOTA. ο κωδικός είναι διαθέσιμος ; Το SPARQL λειτουργεί καλύτερα από το SQL.
Αποτελέσματα ίσα προς το SOTA. ο κωδικός είναι διαθέσιμος ; Το SPARQL λειτουργεί καλύτερα από το SQL.
τι άλλο χρειάζεσαι για ένα καλό χαρτί;

Άλλο ένα συναρπαστικό έργο «Συλλογισμός βάσει περιπτώσεων για ερωτήματα φυσικής γλώσσας πάνω από βάσεις γνώσεων» από Das et al συνδυάζει το SPARQL με περιπτωσιολογικός συλλογισμός (CBR). Το CBR έχει βαθιές ρίζες σε έμπειρα συστήματα στη δεκαετία του '80, αλλά πρόσφατα αναβίωσε με τη δύναμη της εκμάθησης αναπαράστασης. Εξήγηση TLDR του CBR το 2021: είναι εννοιολογικά κοντά στη συνθετική γενίκευση, δηλαδή, έχοντας δει μερικά βασικά παραδείγματα, μπορείτε να δημιουργήσετε ένα πιο περίπλοκο ερώτημα σχετικά με οντότητες που δεν είχαν εμφανιστεί στο παρελθόν.
Ρίξτε μια ματιά στο παρακάτω παράδειγμα. Έχουμε ένα ερώτημα εισαγωγής «Ποιος είναι ο αδερφός του πατέρα του Γκίμλι στο Χόμπιτ;». Στα δεδομένα εκπαίδευσης μπορεί να μην έχουμε τίποτα για το Gimli ή το Hobbit, αλλά μπορεί να έχουμε "σχετικά παρόμοια" περιπτώσεις σχετικά με τις σχέσεις που θα μπορούσαμε να βρούμε χρήσιμες για το ερώτημά μας, π.χ. «Ποιος είναι ο μπαμπάς του Τσάρλι Σιν;» με σχέση Freebase people.person_parents και «Ποιος είναι ο αδερφός της Rihanna;» με σχέση people.person.sibling_s . Συνθέτοντας τα για την ερώτησή μας, κατασκευάζουμε ένα ερώτημα SPARQL στη βάση δεδομένων.
Το προτεινόμενο CBR-KBQA Η προσέγγιση συνδυάζει 1⃣ έναν εκπαιδεύσιμο νευρωνικό ανάκτηση σε στυλ DPR (η επίβλεψη βασίζεται σε αλληλεπικαλυπτόμενες σχέσεις), 2⃣ έναν γραμμικό μετασχηματιστή (χρησιμοποιούν BigBird) ως συναφείς σχετικές ερωτήσεις και τα ερωτήματα είναι αρκετά μεγάλα, 3⃣ αρκετούς μηχανισμούς ανακατάταξης για τον καθαρισμό του προβλέψεις. Χρησιμοποιούν εκτός ραφιού λειτουργικές μονάδες NER και Entity Linking, και χρησιμοποιούν επίσης προεκπαιδευμένες ενσωματώσεις σχέσεων TransE για ανακατάταξη. Το CBR-KBQA επιδεικνύει εντυπωσιακή απόδοση σε πολλά σύνολα δεδομένων KBQA, συμπεριλαμβανομένων CFQ. Μια μικρή σημείωση: Είμαι λίγο καχύποπτος ότι το καλύτερο διαθέσιμο μοντέλο SOTA (67.3 MCD-Mean) έχει καλύτερη απόδοση με τέτοιο περιθώριο στο 78.1 και δεν έχει υποβληθεί στο σημείο αναφοράς, ο κωδικός δεν είναι επίσης διαθέσιμος ακόμη.

Shi et al μελετήστε QA πολλαπλών βημάτων και προτείνετε να ενσωματωθούν τόσο τα αναγνωριστικά οντοτήτων/σχέσεων (φόρμα ετικέτας) όσο και οι περιγραφές φυσικής γλώσσας τους (φόρμα κειμένου) στο πλαίσιο διάδοσης μηνυμάτων TransferNet. Η αξιολόγηση πραγματοποιείται σε τυπικά σύνολα δεδομένων MetaQA, WebQuestionsSP και Complex Web Questions.
Στην ίδια εργασία (τα ίδια σύνολα δεδομένων όπως στην προηγούμενη εργασία), Oliya et al παρατήρησε ότι τα περισσότερα μοντέλα SOTA QA απαιτούν διαστήματα κειμένου που είναι ήδη συνδεδεμένα με οντότητες KG και προσπαθούν να παρακάμψουν αυτήν την απαίτηση με δυναμική ανακατάταξη οντοτήτων χρησιμοποιώντας χαρακτηριστικά γειτονιάς κόμβων οντοτήτων KG και χαρακτηριστικά εκτάσεων κειμένου.
Αυτό ήταν παιδιά
Πείτε μου αν σας αρέσει αυτό το μικρότερο "premum"  μορφοποιήστε καλύτερα από τους τοίχους κειμένου όπως σε προηγούμενες κριτικές! Ευχαριστούμε που αφιερώσατε τον χρόνο σας εδώ, ελπίζω να πήρατε κάτι χρήσιμο
μορφοποιήστε καλύτερα από τους τοίχους κειμένου όπως σε προηγούμενες κριτικές! Ευχαριστούμε που αφιερώσατε τον χρόνο σας εδώ, ελπίζω να πήρατε κάτι χρήσιμο

Αυτό το άρθρο δημοσιεύθηκε αρχικά στις Μέτριας Δυσκολίας και εκδόθηκε εκ νέου στο TOPBOTS με την άδεια του συντάκτη.
Σας αρέσει αυτό το άρθρο; Εγγραφείτε για περισσότερες ενημερώσεις AI.
Θα σας ενημερώσουμε όταν κυκλοφορούμε περισσότερη τεχνική εκπαίδευση.
Ο ορθοστάτης Γραφήματα Γνώσης στο EMNLP 2021 εμφανίστηκε για πρώτη φορά σε ΚΟΡΥΦΑΙΑ.
- '
- "
- 10
- 11
- 2021
- 67
- 7
- 9
- a
- Σχετικά
- αφθονία
- Σύμφωνα με
- Ενέργειες
- προστιθέμενη
- Επιπλέον
- διεύθυνση
- διαχείριση
- Υιοθεσία
- AI
- ai έρευνα
- Στοχεύω
- Όλα
- ήδη
- Ασάφεια
- analytics
- Άλλος
- απάντηση
- Εφαρμογή
- εφαρμογές
- εφαρμοσμένος
- εφαρμόζοντας
- πλησιάζω
- άρθρο
- συγγραφείς
- αυτομάτως
- διαθέσιμος
- φόντο
- Μπάσκετ
- παρακάτω
- αναφοράς
- ΚΑΛΎΤΕΡΟΣ
- μεταξύ
- Πέρα
- Μεγαλύτερη
- Κομμάτι
- Αποκλεισμός
- επιχείρηση
- κλήση
- υποψηφίους
- περίπτωση
- περιπτώσεις
- πρόκληση
- προκλήσεις
- πρόκληση
- αλλαγή
- Πόλη
- ταξινόμηση
- κωδικός
- συνδυασμός
- Ελάτε
- Κοινός
- κοινότητα
- συγκρότημα
- εξαρτήματα
- Διάσκεψη
- σύγχυση
- δόμηση
- περιεχόμενο
- θα μπορούσε να
- κουλτούρα
- πελάτης
- Εξυπηρέτηση πελατών
- ημερομηνία
- βάση δεδομένων
- βάσεις δεδομένων
- βαθύς
- αποδεικνύουν
- Σε συνάρτηση
- περιγράφουν
- DID
- διαφορετικές
- Όχι
- τομέα
- δυναμικός
- κάθε
- εύκολα
- Εκπαίδευση
- εκπαιδευτικών
- προσπάθεια
- απασχολεί
- Αγγλικά
- οντότητες
- οντότητα
- ειδικά
- κατ 'ουσίαν,
- εκτίμηση
- Συμβάν
- παράδειγμα
- παραδείγματα
- συναρπαστικός
- υφιστάμενα
- αναμένω
- εμπειρογνώμονας
- οικογένειες
- οικογένεια
- Χαρακτηριστικά
- Τελικά
- χρηματοδότηση
- Όνομα
- Συγκέντρωση
- Εξής
- μορφή
- μορφή
- μορφές
- Πλαίσιο
- από
- λειτουργία
- χάσμα
- γενεά
- γενετική
- GitHub
- γκολ
- καλός
- εξαιρετική
- ευτυχισμένος
- που έχει
- ύψος
- εδώ
- Αρχική
- ελπίζω
- Πως
- Πώς να
- hr
- HTTPS
- Ανθρωπότητα
- ιδέα
- προσδιορίσει
- σημαντικό
- εντυπωσιακός
- Σε άλλες
- Συμπεριλαμβανομένου
- Αυξάνουν
- εισαγωγή
- παράδειγμα
- ενσωματώσει
- επενδύοντας
- IT
- εαυτό
- Δουλειά
- Κλειδί
- Ξέρω
- γνώση
- γνωστός
- επιγραφή
- Γλώσσα
- large
- μάθηση
- Νομικά
- γραμμή
- σύνδεση
- Λονδίνο
- Μακριά
- ματιά
- Η πλειοψηφία
- κάνω
- ΚΑΝΕΙ
- διαχείριση
- διαχειρίζεται
- τρόπος
- Μάρκετινγκ
- υλικό
- νόημα
- μέτρο
- medium
- Μνήμη
- αναφέρει
- ενδέχεται να
- μοντέλο
- μοντέλα
- περισσότερο
- πλέον
- Δημοφιλέστερα
- και συγκεκριμένα
- ονόματα
- Φυσικό
- ανάγκες
- Νέα Υόρκη
- Νέα Υόρκη
- Εννοια
- NYC
- Οντάριο
- λειτουργίες
- Οργανωμένος
- ΑΛΛΑ
- Χαρτί
- μέρος
- ιδιαίτερα
- επίδοση
- person
- σας παρακαλούμε
- σημεία
- Δημοφιλής
- δημοτικότητα
- Δημοσιεύσεις
- δύναμη
- Προβλέψεις
- Ανώτερο
- αρκετά
- προηγούμενος
- Πρόβλημα
- παράγει
- Προϊόν
- σχέδιο
- διακεκριμένος
- προτείνω
- ερώτηση
- Αναγνώστης
- Ανάγνωση
- πρόσφατος
- πρόσφατα
- συνιστώ
- μείωση
- Μειωμένος
- μείωση
- συγγένειες
- απελευθερώνουν
- αξιόπιστος
- λείψανα
- Εκθέσεις
- αντιπροσώπευση
- απαιτούν
- έρευνα
- Resort
- Αποτελέσματα
- κανόνες
- εμπορικός
- ίδιο
- Κλίμακα
- βαθμολόγησης
- διάφοροι
- σκιά
- Κοντά
- υπογράψουν
- σημαντικός
- small
- So
- μερικοί
- κάτι
- Χώρος
- ειδικευμένος
- πρότυπο
- Κατάσταση
- stats
- δομημένος
- Μελέτη
- υποβάλλονται
- εποπτεία
- υποστήριξη
- υποστηριζόνται!
- Επιφάνεια
- Έρευνες
- σύστημα
- συστήματα
- στόχος
- εργασίες
- Τεχνικός
- πρότυπα
- Η
- ο κόσμος
- ώρα
- σήμερα
- μαζι
- κουπόνια
- τοπικός
- Εκπαίδευση
- μετασχηματίζοντας
- Ταξίδια
- Uk
- μοναδικός
- ενημερώσεις
- χρήση
- διάφορα
- ορατότητα
- W
- ιστός
- εβδομαδιαίος
- Τι
- Ο ΟΠΟΊΟΣ
- ευρύτερο
- λόγια
- Εργασία
- λειτουργεί
- κόσμος
- θα
- έτος
- Σας