Εισαγωγή
The ever-evolving landscape of artificial intelligence has presented an intersection of visual and linguistic data through large vision-language models (LVLMs). MoE-LLaVA is one of these models which stands at the forefront of revolutionizing how machines interpret and understand the world, mirroring human-like perception. However, the challenge still lies in finding the balance between model performance and the computation for their deployment.
MoE-LLaVA which is a novel Mixture of Experts (MoE) for Large Vision-Language Models (LVLMs) is a groundbreaking solution that introduces a new concept in τεχνητή νοημοσύνη. This was developed at Peking University to address the intricate balance between model performance and computation. This is a nuanced approach to large-scale visual-linguistic models.
Στόχοι μάθησης
- Understand large vision-language models in the field of artificial intelligence.
- Explore the unique features and capabilities of MoE-LLaVA, a novel Mixture of Experts for LVLMs.
- Gain insights into the MoE-tuning training strategy, which addresses challenges related to multi-modal learning and model sparsity.
- Evaluate the performance of MoE-LLaVA in comparison to existing LVLMs and its potential applications.
Αυτό το άρθρο δημοσιεύθηκε ως μέρος του Data Science Blogathon.
Πίνακας περιεχομένων
What is MoE-LLaVA: The Framework?
MoE-LLaVA, developed at Peking University, introduces a groundbreaking Mixture of Experts for Large Vision-Language Models. The special power is in being able to selectively activate only a fraction of its parameters during deployment. This strategy not only maintains computational efficiency but it enhances the model’s techniques. Let us look at this model better.
Τι είναι οι μετρήσεις απόδοσης;
MoE-LLaVA’s prowess is evident in its ability to achieve good performance with a sparse parameter count. With just 3 billion sparsely activated parameters, it not only matches the performance of larger models like LLaVA-1.5–7B but surpasses LLaVA-1.5–13B in object hallucination benchmarks. This breakthrough is a new benchmark for sparse LVLMs. This shows the potential for efficiency without compromising on performance.
What is the MoE-Tuning Training Strategy?
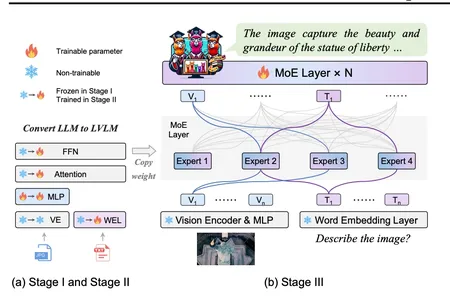
The MoE-tuning training strategy is a foundational element in the development of MoE-LLaVA which is a solution for constructing sparse models with a parameter count while maintaining computational efficiency. This strategy is implemented across three carefully designed stages allowing the model to effectively address challenges related to multi-modal learning and model sparsity.
The first stage handles the creation of a sparse structure by selecting and tuning MoE components which facilitate the capture of patterns and information. In the later stages, the model undergoes refinement to enhance specialization for specific modalities and optimize overall performance. The major success lies in its ability to strike a balance between parameter count and computational efficiency, making it a reliable and efficient solution for applications requiring stable and robust performance in the face of diverse data.
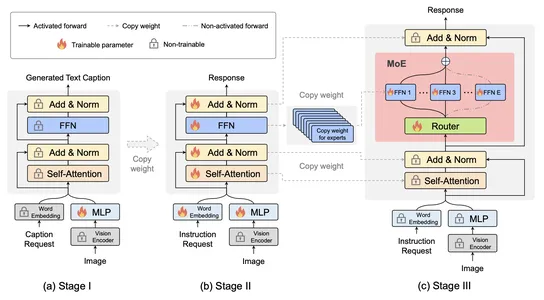
MoE-LLaVA’s unique approach to multi-modal understanding involves the activation of only the top-k experts through routers during deployment. This not only reduces computational load but shows potential reductions in hallucinations in model results which is in the model’s reliability.
What is Multi-Modal Understanding?
MoE-LLaVA introduces a strategy for multi-modal understanding which is during deployment, where only the top-k experts are activated through routers. This innovative approach not only results in a reduction in computational load but it showcases the potential to minimize hallucinations. The careful selection of experts contributes to the model’s reliability by focusing on the most relevant and accurate sources of information.
This approach places MoE-LLaVA in a league of its own compared to traditional models. The selective activation of top-k experts not only streamlines computational processes and improves efficiency, but it addresses hallucinations. This fine-tuned balance between computational efficiency and accuracy positions MoE-LLaVA as a valuable solution for real-world applications where reliability and information are paramount.
What are Adaptability and Applications?
Adaptability broadens MoE-LLaVA’s applicability, making it well-suited for a myriad of tasks and applications. The model’s adeptness in tasks beyond visual understanding shows its potential to address challenges across domains. Whether dealing with complex segmentation and detection tasks or generating content across diverse modalities, MoE-LLaVA proves its strength. This adaptability not only underscores the model’s efficacy but it highlights its potential to contribute to fields where diverse data types and tasks are prevalent.
How to Embrace the Power of Code Demo?
Web UI with Gradio
We will explore the capabilities of MoE-LLaVA through a user-friendly web demo powered by Gradio. The demo shows all features supported by MoE-LLaVA, allowing users to experience the model’s potential interactively. Find the notebook εδώ or paste the code below in an editor; it will provide a URL to interact with the model. Note that it may consume over 10GB of GPU and 5GB of RAM.
Open a new Google Colab Notebook:
Navigate to Google Colab and create a new notebook by clicking on “New Notebook” or “File” -> “New Notebook.” Execute the following cell to install the dependencies. Copy and paste the following code snippet into a code cell and run it.
%cd /content
!git clone -b dev https://github.com/camenduru/MoE-LLaVA-hf
%cd /content/MoE-LLaVA-hf
!pip install deepspeed==0.12.6 gradio==3.50.2 decord==0.6.0 transformers==4.37.0 einops timm tiktoken accelerate mpi4py
%cd /content/MoE-LLaVA-hf
!pip install -e .
%cd /content/MoE-LLaVA-hf
!python app.py
Hit the links to interact with the model:

To know how much this model can suit your use, let’s go further to see it in other forms using Gradio. You can use deepspeed with models like phi2. Let us see some commands useable.
CLI Inference
You could use the command line to see the power of MoE-LLaVA through command-line inference. Perform tasks with ease using the following commands.
# Run with phi2
deepspeed --include localhost:0 moellava/serve/cli.py --model-path "LanguageBind/MoE-LLaVA-Phi2-2.7B-4e" --image-file "image.jpg"
# Run with qwen
deepspeed --include localhost:0 moellava/serve/cli.py --model-path "LanguageBind/MoE-LLaVA-Qwen-1.8B-4e" --image-file "image.jpg"
# Run with stablelm
deepspeed --include localhost:0 moellava/serve/cli.py --model-path "LanguageBind/MoE-LLaVA-StableLM-1.6B-4e" --image-file "image.jpg"What are the Requirements and Installation Steps?
Similarly, you could use the repo from PKU-YuanGroup which is the official repo for MoE-LLaVA. Ensure a smooth experience with MoE-LLaVA by following the recommended requirements and installation steps outlined in the documentation. All the links are available below in the references section.
# Clone
git clone https://github.com/PKU-YuanGroup/MoE-LLaVA
# Move to the project directory
cd MoE-LLaVA
# Create and activate a virtual environment
conda create -n moellava python=3.10 -y
conda activate moellava
# Install packages
pip install --upgrade pip
pip install -e .
pip install -e ".[train]"
pip install flash-attn --no-build-isolationStep by Step Inference with MoE-LLaVA
The above steps which we cloned from GitHub are more like running the package without looking at the contents. In the below step, we will follow a more detailed step to see the model.
Step 1: Install requirement
!pip install transformers
!pip install torchStep 2: Download the MoE-LLaVA Model
Here is how to get the model link. You could consider the version for Phi which is less than 3B parameters from the Huggingface repository https://huggingface.co/LanguageBind/MoE-LLaVA-Phi2-2.7B-4e copy the transformer URL by clicking “Use in transformers” in the top right of the model interface. It looks like this:
# Load model directly
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("LanguageBind/MoE-LLaVA-Phi2-2.7B-4e", trust_remote_code=True)We will use this properly below on running inference and using gradio UI. You could download it locally or use the model calling as seen above. We will use the GPT head and transformers below. Experiment with any other model available on the LanguageBind MoE-LLaVA repo.
Βήμα 3: Εγκαταστήστε τα απαραίτητα πακέτα
- Run the following commands to install packages.
!pip install gradioStep 4: Run the Inference Code
Now, you can run the inference code. Copy and paste the following code into a code cell.
import torch
import gradio as gr
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# Load MoE-LLaVA Model
model_path = "path_to_your_model_directory_locally"
model = GPT2LMHeadModel.from_pretrained(model_path)
tokenizer = GPT2Tokenizer.from_pretrained(model_path)
# Function to generate text
def generate_text(prompt):
input_ids = tokenizer.encode(prompt, return_tensors="pt")
output_ids = model.generate(input_ids, max_length=100, num_beams=5, no_repeat_ngram_size=2, top_k=50, top_p=0.95, temperature=0.7)
generated_text = tokenizer.decode(output_ids[0], skip_special_tokens=True)
return generated_text
# Create Gradio Interface
iface = gr.Interface(fn=generate_text, inputs="text", outputs="text")
iface.launch()This will provide a text box where you can type text. After entering, the model will generate text based on your input.
That’s it! You’ve successfully set up MoE-LLaVA for inference on Google Colab. Feel free to experiment and explore the capabilities of the model.
Συμπέρασμα
MoE-LLaVA is a pioneering force in the realm of efficient, scalable, and powerful multi-modal learning systems. Its ability to deliver good performance to larger models with fewer parameters signifies a breakthrough AI models more practical. Navigating the intricate landscapes of visual and linguistic data, MoE-LLaVA is a solution that adeptly balances computational efficiency with state-of-the-art performance.
Conclusively, MoE-LLaVA not only reflects the evolution of large vision-language models but it sets new benchmarks in addressing challenges associated with model sparsity. The synergy between its innovative approach and the MoE-tuning training shows its commitment to efficiency and performance. As the exploration of AI potential in multi-modal learning grows, MoE-LLaVA is a frontrunner with accessibility and cutting-edge capabilities.
Βασικές τακτικές
- MoE-LLaVA introduces a Mixture of Expert for Large Vision-Language Models with performance with fewer parameters.
- The MoE-tuning training strategy addresses challenges associated with multi-modal learning and model sparsity, ensuring stability and robustness.
- Selective activation of top-k experts during deployment reduces computational load and minimizes hallucinations.
- With just 3 billion sparsely activated parameters, MoE-LLaVA sets a new baseline for efficient and powerful multi-modal learning systems.
- The model’s adaptability to tasks, including segmentation, detection, and generation, opens doors to diverse applications beyond visual understanding.
Συχνές Ερωτήσεις
A. MoE-LLaVA is a novel Mixture of Expert (MoE) models for Large Vision-Language Models (LVLMs), developed at Peking University. It contributes to AI by introducing a new concept, selectively activating only a fraction of its parameters during deployment, a balance between model performance and computational efficiency.
A. MoE-LLaVA distinguishes itself by activating only a fraction of its parameters during deployment, maintaining computational efficiency. It addresses the challenge by introducing a nuanced approach performing with fewer parameters compared to other models like LLaVA-1.5–7B and LLaVA-1.5–13B.
A. MoE-LLaVA broadens its applicability, making it well-suited for diverse tasks and applications beyond visual understanding. Its adeptness in tasks like segmentation, detection, and content generation gives a reliable and efficient solution across domains.
A. MoE-LLaVA’s performance prowess lies in achieving results with a sparse parameter count of 3 billion. It sets new benchmarks for sparse LVLMs by surpassing larger models in object hallucination benchmarks with the potential for efficiency without compromising on performance.
A. MoE-LLaVA introduces a unique strategy during deployment, activating only the top-k experts through routers. This strategy reduces computational load minimizes hallucinations in model results and focuses on the most relevant and accurate sources of information.
Σύνδεσμοι αναφοράς
Τα μέσα που εμφανίζονται σε αυτό το άρθρο δεν ανήκουν στο Analytics Vidhya και χρησιμοποιούνται κατά την κρίση του συγγραφέα.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://www.analyticsvidhya.com/blog/2024/02/moe-llava-advancing-sparse-lvlms-for-improved-efficiency/
- :έχει
- :είναι
- :δεν
- :που
- $UP
- 1
- 10
- 12
- 13
- 19
- 2%
- 4
- 48
- 5
- 50
- 6
- 7
- 9
- a
- ικανότητα
- Ικανός
- πάνω από
- επιταχύνουν
- προσιτότητα
- ακρίβεια
- ακριβής
- Κατορθώνω
- την επίτευξη
- απέναντι
- ενεργοποιημένη
- ενεργοποιείται
- ενεργοποίησης
- Δραστηριοποίηση
- ικανότητα προσαρμογής
- διεύθυνση
- διευθύνσεις
- διευθυνσιοδότηση
- προχωρώντας
- Μετά το
- AI
- Μοντέλα AI
- Όλα
- Επιτρέποντας
- an
- analytics
- Ανάλυση Vidhya
- και
- κάθε
- χώρια
- app
- εφαρμογές
- πλησιάζω
- ΕΙΝΑΙ
- άρθρο
- τεχνητός
- τεχνητή νοημοσύνη
- AS
- ρώτησε
- συσχετισμένη
- At
- διαθέσιμος
- Υπόλοιπο
- ισορροπίες
- εξισορρόπησης
- βασίζονται
- Baseline
- είναι
- παρακάτω
- αναφοράς
- αναφοράς
- Καλύτερα
- μεταξύ
- Πέρα
- Δισεκατομμύριο
- blogathon
- Κουτί
- επανάσταση
- αλλά
- by
- κλήση
- CAN
- δυνατότητες
- πιάνω
- προσεκτικός
- προσεκτικά
- CD
- κύτταρο
- πρόκληση
- προκλήσεις
- κλικ
- κωδικός
- δέσμευση
- σύγκριση
- σύγκριση
- συγκρότημα
- εξαρτήματα
- συμβιβασμός
- υπολογισμός
- υπολογιστική
- έννοια
- Εξετάστε
- κατασκευή
- καταναλώνουν
- περιεχόμενο
- περιεχόμενα
- συμβάλλει
- συμβάλλει
- αντίγραφο
- θα μπορούσε να
- μετράνε
- δημιουργία
- δημιουργία
- αιχμής
- ημερομηνία
- μοιρασιά
- def
- παραδώσει
- Διαδήλωση
- εξαρτήσεις
- ανάπτυξη
- σχεδιασμένα
- λεπτομερής
- Ανίχνευση
- Dev
- αναπτύχθηκε
- Ανάπτυξη
- κατευθείαν
- κατάλογο
- διακριτικότητα
- διακρίνει
- διάφορα
- τεκμηρίωση
- κάνει
- domains
- πόρτες
- κατεβάσετε
- κατά την διάρκεια
- ευκολία
- συντάκτης
- αποτελεσματικά
- αποτελεσματικότητα
- αποδοτικότητα
- αποτελεσματικός
- στοιχείο
- αγκαλιάζω
- ενίσχυση
- Ενισχύει
- εξασφαλίζω
- εξασφαλίζοντας
- εισερχόμενοι
- Περιβάλλον
- Αιθέρας (ΕΤΗ)
- εμφανές
- εξέλιξη
- εκτελέσει
- υφιστάμενα
- εμπειρία
- πείραμα
- εμπειρογνώμονας
- εμπειρογνώμονες
- εξερεύνηση
- διερευνήσει
- Πρόσωπο
- διευκολύνω
- Χαρακτηριστικά
- αισθάνομαι
- λιγότερα
- πεδίο
- Πεδία
- Εύρεση
- εύρεση
- Όνομα
- εστιάζει
- εστιάζοντας
- ακολουθήστε
- Εξής
- Για
- Δύναμη
- Πρώτη γραμμή
- μορφές
- θεμελιακών
- κλάσμα
- Πλαίσιο
- Δωρεάν
- από
- λειτουργία
- περαιτέρω
- παράγουν
- παραγωγής
- γενεά
- παίρνω
- Git
- GitHub
- δίνει
- Go
- καλός
- GPU
- πρωτοποριακή
- μεγαλώνει
- Handles
- κεφάλι
- ανταύγειες
- Πως
- Πώς να
- Ωστόσο
- HTTPS
- Πρόσωπο αγκαλιάς
- εικόνα
- Επίπτωση
- εφαρμοστεί
- εισαγωγή
- βελτιωθεί
- βελτιώνει
- in
- Σε άλλες
- Συμπεριλαμβανομένου
- πληροφορίες
- καινοτόμες
- εισαγωγή
- ιδέες
- εγκαθιστώ
- εγκατάσταση
- Νοημοσύνη
- αλληλεπιδρούν
- περιβάλλον λειτουργίας
- διασταύρωση
- σε
- πολύπλοκος
- εισήγαγε
- Εισάγει
- εισάγοντας
- Inuwa
- περιλαμβάνει
- IT
- ΤΟΥ
- εαυτό
- jpg
- μόλις
- Ξέρω
- τοπίο
- τοπία
- large
- μεγάλης κλίμακας
- μεγαλύτερος
- αργότερα
- Λιγκ
- μάθηση
- μείον
- ας
- βρίσκεται
- Μου αρέσει
- γραμμή
- LINK
- ΣΥΝΔΕΣΜΟΙ
- φορτίο
- τοπικά
- ματιά
- κοιτάζοντας
- ΦΑΊΝΕΤΑΙ
- μηχανήματα
- Η διατήρηση
- διατηρεί
- μεγάλες
- Κατασκευή
- σπίρτα
- Ενδέχεται..
- Εικόνες / Βίντεο
- Metrics
- ελαχιστοποίηση
- ελαχιστοποιεί
- αντανακλώντας
- μίγμα
- λεπτομέρειες
- μοντέλο
- μοντέλα
- περισσότερο
- πλέον
- μετακινήσετε
- πολύ
- μυριάδα
- πλοήγηση
- απαραίτητος
- Νέα
- σημείωση
- σημειωματάριο
- μυθιστόρημα
- αποχρώσεις
- αντικείμενο
- of
- επίσημος ανώτερος υπάλληλος
- on
- ONE
- αποκλειστικά
- ανοίγει
- Βελτιστοποίηση
- or
- ΑΛΛΑ
- σκιαγραφείται
- επί
- φόρμες
- δική
- ανήκει
- πακέτο
- Packages
- παράμετρος
- παράμετροι
- κυρίαρχος
- μέρος
- πρότυπα
- Πεκίνο
- αντίληψη
- εκτελέσει
- επίδοση
- εκτέλεση
- Πρωτοποριακή
- Μέρη
- Πλάτων
- Πληροφορία δεδομένων Plato
- Πλάτωνα δεδομένα
- θέσεις
- δυναμικού
- δύναμη
- τροφοδοτείται
- ισχυρός
- Πρακτικός
- παρουσιάζονται
- επικρατών
- Διεργασίες
- σχέδιο
- δεόντως
- αποδεικνύει
- παρέχουν
- ανδρεία
- δημοσιεύθηκε
- RAM
- πραγματικό κόσμο
- βασίλειο
- συνιστάται
- μειώνει
- μείωση
- μειώσεις
- αναφορές
- αντικατοπτρίζει
- σχετίζεται με
- αξιοπιστία
- αξιόπιστος
- απαιτήσεις
- Υποστηρικτικό υλικό
- Αποτελέσματα
- απόδοση
- Επανάσταση
- δεξιά
- εύρωστος
- ευρωστία
- τρέξιμο
- τρέξιμο
- επεκτάσιμη
- Επιστήμη
- Τμήμα
- δείτε
- δει
- κατάτμηση
- επιλογή
- επιλογή
- εκλεκτικός
- σειρά
- Σέτς
- προθήκες
- παρουσιάζεται
- Δείχνει
- σημαίνει
- εξομαλύνουν
- Απόσπασμα
- λύση
- μερικοί
- Πηγές
- αραιός
- ειδική
- συγκεκριμένες
- σταθερότητα
- σταθερός
- Στάδιο
- στάδια
- στέκεται
- state-of-the-art
- Βήμα
- Βήματα
- Ακόμη
- Στρατηγική
- απλουστεύει
- δύναμη
- απεργία
- δομή
- επιτυχία
- Επιτυχώς
- κοστούμι
- κατάλληλος
- υποστηριζόνται!
- ξεπερνάει
- υπέροχος
- συνεργία
- συστήματα
- εργασίες
- τεχνικές
- όροι
- κείμενο
- από
- ότι
- Η
- ο κόσμος
- τους
- Αυτοί
- αυτό
- τρία
- Μέσω
- προς την
- κορυφή
- δάδα
- παραδοσιακός
- Τρένο
- Εκπαίδευση
- μετασχηματιστής
- μετασχηματιστές
- βραχυχρόνιων διακυμάνσεων της ρευστότητας
- τύπος
- τύποι
- ui
- υφίσταται
- υπογράμμισης
- καταλαβαίνω
- κατανόηση
- μοναδικός
- πανεπιστήμιο
- URL
- us
- χρήση
- μεταχειρισμένος
- φιλική προς το χρήστη
- Χρήστες
- χρησιμοποιώντας
- Πολύτιμος
- εκδοχή
- Πραγματικός
- οπτικές
- ήταν
- we
- ιστός
- webp
- Τι
- Τι είναι
- αν
- Ποιό
- ενώ
- θα
- με
- χωρίς
- κόσμος
- εσείς
- Σας
- zephyrnet