Το NLP πολλαπλών ετικετών αναφέρεται στο έργο της αντιστοίχισης πολλαπλών ετικετών σε μια δεδομένη εισαγωγή κειμένου και όχι μόνο σε μία ετικέτα. Στις παραδοσιακές εργασίες NLP, όπως η ταξινόμηση κειμένου ή η ανάλυση συναισθήματος, σε κάθε είσοδο τυπικά αποδίδεται μια ενιαία ετικέτα με βάση το περιεχόμενό της. Ωστόσο, σε πολλά σενάρια πραγματικού κόσμου, ένα κομμάτι κειμένου μπορεί να ανήκει σε πολλές κατηγορίες ή να εκφράζει πολλαπλά συναισθήματα ταυτόχρονα.
Το NLP πολλαπλών ετικετών είναι σημαντικό επειδή μας επιτρέπει να συλλαμβάνουμε πιο λεπτές και σύνθετες πληροφορίες από δεδομένα κειμένου. Για παράδειγμα, στον τομέα της ανάλυσης σχολίων πελατών, μια κριτική πελάτη μπορεί να εκφράζει θετικά και αρνητικά συναισθήματα ταυτόχρονα ή μπορεί να αγγίζει πολλές πτυχές ενός προϊόντος ή μιας υπηρεσίας. Με την αντιστοίχιση πολλαπλών ετικετών σε τέτοιες εισροές, μπορούμε να αποκτήσουμε μια πιο ολοκληρωμένη κατανόηση των σχολίων των πελατών και να λάβουμε πιο στοχευμένες ενέργειες για να αντιμετωπίσουμε τις ανησυχίες τους.
Αυτό το άρθρο εμβαθύνει σε μια αξιοσημείωτη περίπτωση χρήσης του NLP πολλαπλών ετικετών από την Provectus.
Ιστορικό:
Ένας πελάτης μας πλησίασε με αίτημα να τον βοηθήσουμε αυτοματοποίηση εγγράφων επισήμανσης συγκεκριμένου τύπου. Με την πρώτη ματιά, το έργο φαινόταν απλό και εύκολα επιλύσιμο. Ωστόσο, καθώς εργαζόμασταν στην υπόθεση, συναντήσαμε ένα σύνολο δεδομένων με ασυνεπείς σχολιασμούς. Αν και ο πελάτης μας είχε αντιμετωπίσει προκλήσεις με διαφορετικούς αριθμούς τάξεων και αλλαγές στην ομάδα αναθεώρησής του με την πάροδο του χρόνου, είχαν επενδύσει σημαντικές προσπάθειες για τη δημιουργία ενός διαφορετικού συνόλου δεδομένων με μια σειρά σχολιασμών. Ενώ υπήρχαν κάποιες ανισορροπίες και αβεβαιότητες στις ετικέτες, αυτό το σύνολο δεδομένων παρείχε μια πολύτιμη ευκαιρία για ανάλυση και περαιτέρω εξερεύνηση.
Ας ρίξουμε μια πιο προσεκτική ματιά στο σύνολο δεδομένων, ας εξερευνήσουμε τις μετρήσεις και την προσέγγισή μας και ας ανακεφαλαιώσουμε τον τρόπο με τον οποίο το Provectus έλυσε το πρόβλημα της ταξινόμησης κειμένου πολλαπλών ετικετών.
Το σύνολο δεδομένων έχει 14,354 παρατηρήσεις, με 124 μοναδικές κατηγορίες (ετικέτες). Το καθήκον μας είναι να αντιστοιχίσουμε μία ή πολλές κλάσεις σε κάθε παρατήρηση.
Ο Πίνακας 1 παρέχει περιγραφικά στατιστικά στοιχεία για το σύνολο δεδομένων.
Κατά μέσο όρο, έχουμε περίπου δύο τάξεις ανά παρατήρηση, με μέσο όρο 261 διαφορετικά κείμενα που περιγράφουν μια μόνο τάξη.

Πίνακας 1: Στατιστικά συνόλου δεδομένων
Στο σχήμα 1, βλέπουμε την κατανομή των κλάσεων στο επάνω γράφημα και έχουμε έναν ορισμένο αριθμό ετικετών HEAD με την υψηλότερη συχνότητα εμφάνισης στο σύνολο δεδομένων. Σημειώστε επίσης ότι η πλειοψηφία των τάξεων έχουν χαμηλή συχνότητα εμφάνισης.
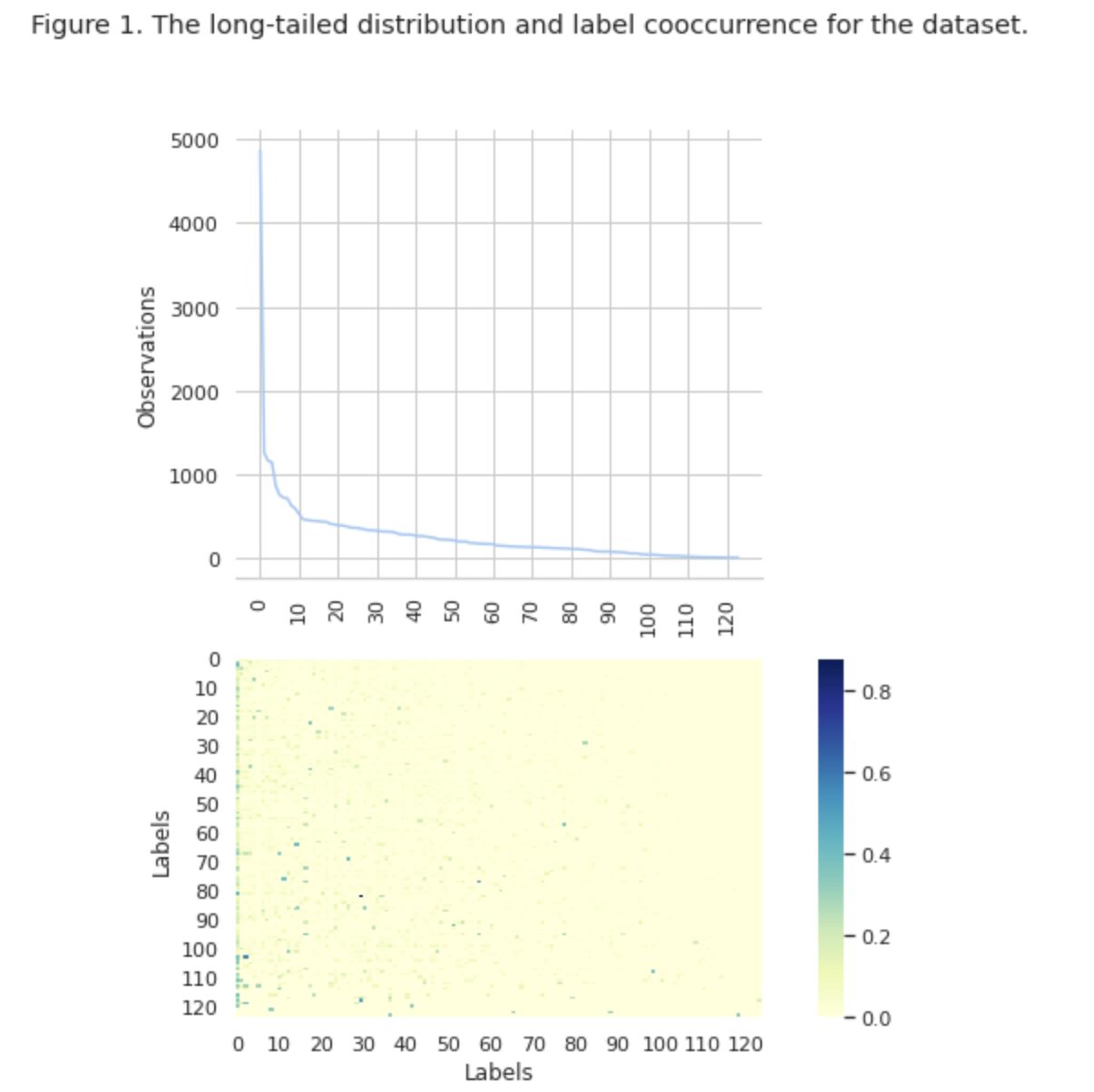
Στο κάτω γράφημα βλέπουμε ότι υπάρχει συχνή επικάλυψη μεταξύ των κλάσεων που αναπαριστώνται καλύτερα στο σύνολο δεδομένων και των κλάσεων που έχουν χαμηλή σημασία.
Αλλάξαμε τη διαδικασία διαχωρισμού του συνόλου δεδομένων σε σύνολα τρένων/val/δοκιμών. Αντί να χρησιμοποιούμε μια παραδοσιακή μέθοδο, χρησιμοποιήσαμε επαναληπτική διαστρωμάτωση, για να παρέχουμε μια καλά ισορροπημένη κατανομή των αποδεικτικών στοιχείων των σχέσεων ετικέτας. Για αυτό χρησιμοποιήσαμε Scikit Multi-learn
from skmultilearn.model_selection import iterative_train_test_split mlb = MultiLabelBinarizer() def balanced_split(df, mlb, test_size=0.5): ind = np.expand_dims(np.arange(len(df)), axis=1) mlb.fit_transform(df["tag"]) labels = mlb.transform(df["tag"]) ind_train, _, ind_test, _ = iterative_train_test_split( ind, labels, test_size ) return df.iloc[ind_train[:, 0]], df.iloc[ind_test[:, 0]] df_train, df_tmp = balanced_split(df, test_size=0.4)
df_val, df_test = balanced_split(df_tmp, test_size=0.5)
Πήραμε την ακόλουθη διανομή:
- Το σύνολο δεδομένων εκπαίδευσης περιέχει το 60% των δεδομένων και καλύπτει και τις 124 ετικέτες
- Το σύνολο δεδομένων επικύρωσης περιέχει το 20% των δεδομένων και καλύπτει και τις 124 ετικέτες
- Το σύνολο δεδομένων δοκιμής περιέχει το 20% των δεδομένων και καλύπτει και τις 124 ετικέτες
Η ταξινόμηση πολλαπλών ετικετών είναι ένας τύπος εποπτευόμενου αλγόριθμου μηχανικής εκμάθησης που μας επιτρέπει να αντιστοιχίσουμε πολλαπλές ετικέτες σε ένα μόνο δείγμα δεδομένων. Διαφέρει από τη δυαδική ταξινόμηση όπου το μοντέλο προβλέπει μόνο δύο κατηγορίες και από την ταξινόμηση πολλαπλών κλάσεων όπου το μοντέλο προβλέπει μόνο μία από πολλές κατηγορίες για ένα δείγμα.
Οι μετρήσεις αξιολόγησης για την απόδοση ταξινόμησης πολλαπλών ετικετών είναι εγγενώς διαφορετικές από αυτές που χρησιμοποιούνται στην ταξινόμηση πολλαπλών κλάσεων (ή δυαδικών) λόγω των εγγενών διαφορών του προβλήματος ταξινόμησης. Περισσότερες λεπτομέρειες μπορείτε να βρείτε στη Wikipedia.
Επιλέξαμε μετρήσεις που είναι πιο κατάλληλες για εμάς:
- Ακρίβεια μετρά την αναλογία των αληθινών θετικών προβλέψεων μεταξύ των συνολικών θετικών προβλέψεων που γίνονται από το μοντέλο.
- Ανάκληση μετρά το ποσοστό των αληθινών θετικών προβλέψεων μεταξύ όλων των πραγματικών θετικών δειγμάτων.
- F1-σκορ είναι το αρμονικό μέσο ακρίβειας και ανάκλησης, που βοηθά στην αποκατάσταση της ισορροπίας μεταξύ των δύο.
- Απώλεια Hamming είναι το κλάσμα των ετικετών που έχουν προβλεφθεί λανθασμένα
Επίσης παρακολουθούμε τον αριθμό των προβλεπόμενων ετικετών στο σύνολο { ορίζεται ως πλήθος για ετικέτες, για τις οποίες επιτυγχάνουμε βαθμολογία F1 > 0}.
Η ταξινόμηση πολλαπλών ετικετών είναι ένας τύπος εποπτευόμενου προβλήματος μάθησης όπου ένα μεμονωμένο παράδειγμα ή παράδειγμα μπορεί να συσχετιστεί με πολλές ετικέτες ή ταξινομήσεις, σε αντίθεση με την παραδοσιακή ταξινόμηση μιας ετικέτας, όπου κάθε παρουσία σχετίζεται μόνο με μία ετικέτα κλάσης.
Για την επίλυση προβλημάτων ταξινόμησης πολλαπλών ετικετών, υπάρχουν δύο κύριες κατηγορίες τεχνικών:
- Μέθοδοι μετασχηματισμού προβλημάτων
- Μέθοδοι προσαρμογής αλγορίθμων
Οι μέθοδοι μετασχηματισμού προβλήματος μας επιτρέπουν να μετατρέψουμε εργασίες ταξινόμησης πολλαπλών ετικετών σε πολλαπλές εργασίες ταξινόμησης μίας ετικέτας. Για παράδειγμα, η βασική προσέγγιση Binary Relevance (BR) αντιμετωπίζει κάθε ετικέτα ως ξεχωριστό πρόβλημα δυαδικής ταξινόμησης. Σε αυτήν την περίπτωση, το πρόβλημα πολλαπλών ετικετών μετατρέπεται σε προβλήματα πολλαπλών μονών ετικετών.
Οι μέθοδοι προσαρμογής αλγορίθμων τροποποιούν τους ίδιους τους αλγόριθμους για να χειρίζονται δεδομένα πολλαπλών ετικετών εγγενώς, χωρίς να μετατρέπουν την εργασία σε πολλαπλές εργασίες ταξινόμησης μιας ετικέτας. Ένα παράδειγμα αυτής της προσέγγισης είναι το μοντέλο BERT, το οποίο είναι ένα προεκπαιδευμένο μοντέλο γλώσσας που βασίζεται σε μετασχηματιστή και μπορεί να ρυθμιστεί με ακρίβεια για διάφορες εργασίες NLP, συμπεριλαμβανομένης της ταξινόμησης κειμένου πολλαπλών ετικετών. Το BERT έχει σχεδιαστεί για να χειρίζεται απευθείας δεδομένα πολλαπλών ετικετών, χωρίς την ανάγκη μετασχηματισμού προβλήματος.
Στο πλαίσιο της χρήσης BERT για ταξινόμηση κειμένου πολλαπλών ετικετών, η τυπική προσέγγιση είναι η χρήση της απώλειας δυαδικής διασταυρούμενης εντροπίας (BCE) ως συνάρτηση απώλειας. Η απώλεια BCE είναι μια ευρέως χρησιμοποιούμενη συνάρτηση απώλειας για προβλήματα δυαδικής ταξινόμησης και μπορεί εύκολα να επεκταθεί για να χειριστεί προβλήματα ταξινόμησης πολλαπλών ετικετών υπολογίζοντας την απώλεια για κάθε ετικέτα ανεξάρτητα και στη συνέχεια αθροίζοντας τις απώλειες. Σε αυτήν την περίπτωση, η συνάρτηση απώλειας BCE μετρά το σφάλμα μεταξύ των προβλεπόμενων πιθανοτήτων και των αληθών ετικετών, όπου οι προβλεπόμενες πιθανότητες λαμβάνονται από το τελικό στρώμα ενεργοποίησης σιγμοειδούς στο μοντέλο BERT.
Τώρα, ας ρίξουμε μια πιο προσεκτική ματιά στο Σχήμα 2 παρακάτω.
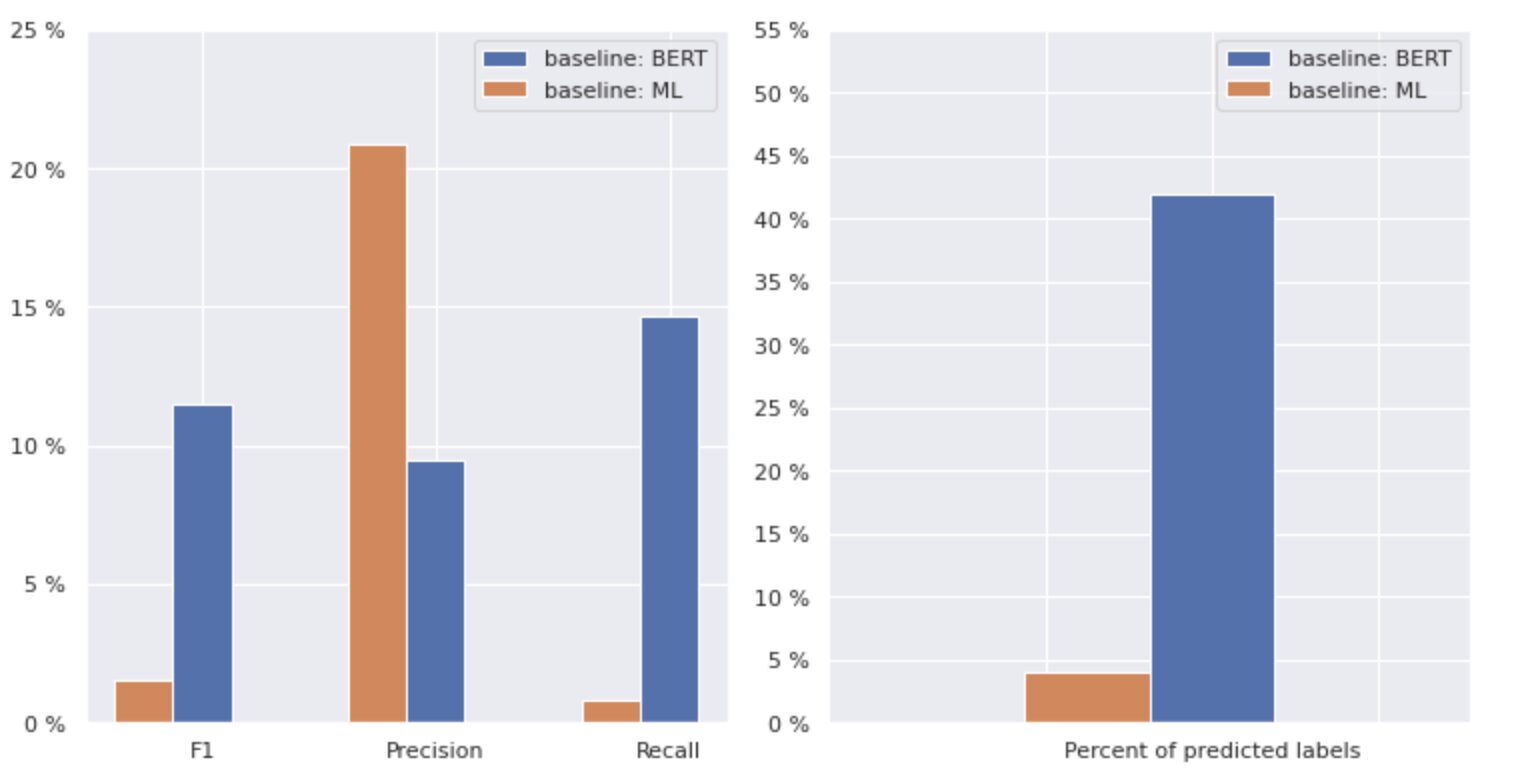
Εικόνα 2. Μετρήσεις για βασικά μοντέλα
Το γράφημα στα αριστερά δείχνει μια σύγκριση μετρήσεων για μια "γραμμή βάσης: BERT" και "γραμμή βάσης: ML". Έτσι, μπορεί να φανεί ότι για τη «βασική γραμμή: BERT», οι βαθμολογίες F1 και Ανάκληση είναι περίπου 1.5 φορές υψηλότερες, ενώ η Ακρίβεια για τη «γραμμή βάσης: ML» είναι 2 φορές υψηλότερη από αυτή του μοντέλου 1. Αναλύοντας το συνολικό ποσοστό προβλεπόμενες κλάσεις που εμφανίζονται στα δεξιά, βλέπουμε ότι η "γραμμή βάσης: BERT" προέβλεψε τις τάξεις περισσότερο από 10 φορές από αυτήν της "γραμμής βάσης: ML".
Επειδή το μέγιστο αποτέλεσμα για τη "βασική γραμμή: BERT" είναι λιγότερο από το 50% όλων των τάξεων, τα αποτελέσματα είναι αρκετά αποθαρρυντικά. Ας δούμε πώς να βελτιώσουμε αυτά τα αποτελέσματα.
Με βάση το εξαιρετικό άρθρο "Μέθοδοι εξισορρόπησης για ταξινόμηση κειμένων πολλαπλών ετικετών με κατανομή κλάσης με μακροχρόνια ουρά", μάθαμε ότι η ζημιά με ισορροπημένη διανομή μπορεί να είναι η πιο κατάλληλη προσέγγιση για εμάς.
Απώλεια ισορροπημένης διανομής
Η απώλεια ισορροπημένης διανομής είναι μια τεχνική που χρησιμοποιείται σε προβλήματα ταξινόμησης κειμένου πολλαπλών ετικετών για την αντιμετώπιση ανισορροπιών στη διανομή κλάσεων. Σε αυτά τα προβλήματα, ορισμένες κλάσεις έχουν πολύ υψηλότερη συχνότητα εμφάνισης σε σύγκριση με άλλες, με αποτέλεσμα την προκατάληψη του μοντέλου προς αυτές τις πιο συχνές κλάσεις.
Για να αντιμετωπιστεί αυτό το ζήτημα, η ζημιά εξισορροπημένης κατανομής στοχεύει να εξισορροπήσει τη συμβολή κάθε δείγματος στη συνάρτηση απώλειας. Αυτό επιτυγχάνεται με την εκ νέου στάθμιση της απώλειας κάθε δείγματος με βάση το αντίστροφο της συχνότητας εμφάνισής του στο σύνολο δεδομένων. Με αυτόν τον τρόπο, αυξάνεται η συνεισφορά των λιγότερο συχνών τάξεων και μειώνεται η συνεισφορά των πιο συχνών τάξεων, εξισορροπώντας έτσι τη συνολική κατανομή της τάξης.
Αυτή η τεχνική έχει αποδειχθεί ότι είναι αποτελεσματική στη βελτίωση της απόδοσης των μοντέλων σε προβλήματα διανομής κλάσης μακράς ουράς. Μειώνοντας τον αντίκτυπο των συχνών τάξεων και αυξάνοντας τον αντίκτυπο των σπάνιων κλάσεων, το μοντέλο είναι σε θέση να αποτυπώνει καλύτερα μοτίβα στα δεδομένα και να παράγει πιο ισορροπημένες προβλέψεις.

Υλοποίηση Κατηγορίας Resample
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np class ResampleLoss(nn.Module): def __init__( self, use_sigmoid=True, partial=False, loss_weight=1.0, reduction="mean", reweight_func=None, weight_norm=None, focal=dict(focal=True, alpha=0.5, gamma=2), map_param=dict(alpha=10.0, beta=0.2, gamma=0.1), CB_loss=dict(CB_beta=0.9, CB_mode="average_w"), logit_reg=dict(neg_scale=5.0, init_bias=0.1), class_freq=None, train_num=None, ): super(ResampleLoss, self).__init__() assert (use_sigmoid is True) or (partial is False) self.use_sigmoid = use_sigmoid self.partial = partial self.loss_weight = loss_weight self.reduction = reduction if self.use_sigmoid: if self.partial: self.cls_criterion = partial_cross_entropy else: self.cls_criterion = binary_cross_entropy else: self.cls_criterion = cross_entropy # reweighting function self.reweight_func = reweight_func # normalization (optional) self.weight_norm = weight_norm # focal loss params self.focal = focal["focal"] self.gamma = focal["gamma"] self.alpha = focal["alpha"] # mapping function params self.map_alpha = map_param["alpha"] self.map_beta = map_param["beta"] self.map_gamma = map_param["gamma"] # CB loss params (optional) self.CB_beta = CB_loss["CB_beta"] self.CB_mode = CB_loss["CB_mode"] self.class_freq = ( torch.from_numpy(np.asarray(class_freq)).float().cuda() ) self.num_classes = self.class_freq.shape[0] self.train_num = train_num # only used to be divided by class_freq # regularization params self.logit_reg = logit_reg self.neg_scale = ( logit_reg["neg_scale"] if "neg_scale" in logit_reg else 1.0 ) init_bias = ( logit_reg["init_bias"] if "init_bias" in logit_reg else 0.0 ) self.init_bias = ( -torch.log(self.train_num / self.class_freq - 1) * init_bias ) self.freq_inv = ( torch.ones(self.class_freq.shape).cuda() / self.class_freq ) self.propotion_inv = self.train_num / self.class_freq def forward( self, cls_score, label, weight=None, avg_factor=None, reduction_override=None, **kwargs ): assert reduction_override in (None, "none", "mean", "sum") reduction = ( reduction_override if reduction_override else self.reduction ) weight = self.reweight_functions(label) cls_score, weight = self.logit_reg_functions( label.float(), cls_score, weight ) if self.focal: logpt = self.cls_criterion( cls_score.clone(), label, weight=None, reduction="none", avg_factor=avg_factor, ) # pt is sigmoid(logit) for pos or sigmoid(-logit) for neg pt = torch.exp(-logpt) wtloss = self.cls_criterion( cls_score, label.float(), weight=weight, reduction="none" ) alpha_t = torch.where(label == 1, self.alpha, 1 - self.alpha) loss = alpha_t * ((1 - pt) ** self.gamma) * wtloss loss = reduce_loss(loss, reduction) else: loss = self.cls_criterion( cls_score, label.float(), weight, reduction=reduction ) loss = self.loss_weight * loss return loss def reweight_functions(self, label): if self.reweight_func is None: return None elif self.reweight_func in ["inv", "sqrt_inv"]: weight = self.RW_weight(label.float()) elif self.reweight_func in "rebalance": weight = self.rebalance_weight(label.float()) elif self.reweight_func in "CB": weight = self.CB_weight(label.float()) else: return None if self.weight_norm is not None: if "by_instance" in self.weight_norm: max_by_instance, _ = torch.max(weight, dim=-1, keepdim=True) weight = weight / max_by_instance elif "by_batch" in self.weight_norm: weight = weight / torch.max(weight) return weight def logit_reg_functions(self, labels, logits, weight=None): if not self.logit_reg: return logits, weight if "init_bias" in self.logit_reg: logits += self.init_bias if "neg_scale" in self.logit_reg: logits = logits * (1 - labels) * self.neg_scale + logits * labels if weight is not None: weight = ( weight / self.neg_scale * (1 - labels) + weight * labels ) return logits, weight def rebalance_weight(self, gt_labels): repeat_rate = torch.sum( gt_labels.float() * self.freq_inv, dim=1, keepdim=True ) pos_weight = ( self.freq_inv.clone().detach().unsqueeze(0) / repeat_rate ) # pos and neg are equally treated weight = ( torch.sigmoid(self.map_beta * (pos_weight - self.map_gamma)) + self.map_alpha ) return weight def CB_weight(self, gt_labels): if "by_class" in self.CB_mode: weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, self.class_freq)).cuda() ) elif "average_n" in self.CB_mode: avg_n = torch.sum( gt_labels * self.class_freq, dim=1, keepdim=True ) / torch.sum(gt_labels, dim=1, keepdim=True) weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, avg_n)).cuda() ) elif "average_w" in self.CB_mode: weight_ = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, self.class_freq)).cuda() ) weight = torch.sum( gt_labels * weight_, dim=1, keepdim=True ) / torch.sum(gt_labels, dim=1, keepdim=True) elif "min_n" in self.CB_mode: min_n, _ = torch.min( gt_labels * self.class_freq + (1 - gt_labels) * 100000, dim=1, keepdim=True, ) weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, min_n)).cuda() ) else: raise NameError return weight def RW_weight(self, gt_labels, by_class=True): if "sqrt" in self.reweight_func: weight = torch.sqrt(self.propotion_inv) else: weight = self.propotion_inv if not by_class: sum_ = torch.sum(weight * gt_labels, dim=1, keepdim=True) weight = sum_ / torch.sum(gt_labels, dim=1, keepdim=True) return weight def reduce_loss(loss, reduction): """Reduce loss as specified. Args: loss (Tensor): Elementwise loss tensor. reduction (str): Options are "none", "mean" and "sum". Return: Tensor: Reduced loss tensor. """ reduction_enum = F._Reduction.get_enum(reduction) # none: 0, elementwise_mean:1, sum: 2 if reduction_enum == 0: return loss elif reduction_enum == 1: return loss.mean() elif reduction_enum == 2: return loss.sum() def weight_reduce_loss(loss, weight=None, reduction="mean", avg_factor=None): """Apply element-wise weight and reduce loss. Args: loss (Tensor): Element-wise loss. weight (Tensor): Element-wise weights. reduction (str): Same as built-in losses of PyTorch. avg_factor (float): Avarage factor when computing the mean of losses. Returns: Tensor: Processed loss values. """ # if weight is specified, apply element-wise weight if weight is not None: loss = loss * weight # if avg_factor is not specified, just reduce the loss if avg_factor is None: loss = reduce_loss(loss, reduction) else: # if reduction is mean, then average the loss by avg_factor if reduction == "mean": loss = loss.sum() / avg_factor # if reduction is 'none', then do nothing, otherwise raise an error elif reduction != "none": raise ValueError( 'avg_factor can not be used with reduction="sum"' ) return loss def binary_cross_entropy( pred, label, weight=None, reduction="mean", avg_factor=None
): # weighted element-wise losses if weight is not None: weight = weight.float() loss = F.binary_cross_entropy_with_logits( pred, label.float(), weight, reduction="none" ) loss = weight_reduce_loss( loss, reduction=reduction, avg_factor=avg_factor ) return loss
DBLoss
loss_func = ResampleLoss( reweight_func="rebalance", loss_weight=1.0, focal=dict(focal=True, alpha=0.5, gamma=2), logit_reg=dict(init_bias=0.05, neg_scale=2.0), map_param=dict(alpha=0.1, beta=10.0, gamma=0.405), class_freq=class_freq, train_num=train_num,
) """
class_freq - list of frequencies for each class,
train_num - size of train dataset """
Διερευνώντας προσεκτικά το σύνολο δεδομένων, καταλήξαμε στο συμπέρασμα ότι η παράμετρος
= 0.405.
Συντονισμός κατωφλίου
Ένα άλλο βήμα για τη βελτίωση του μοντέλου μας ήταν η διαδικασία ρύθμισης του ορίου, τόσο στο στάδιο της εκπαίδευσης, όσο και στα στάδια επικύρωσης και δοκιμής. Υπολογίσαμε τις εξαρτήσεις μετρήσεων όπως η βαθμολογία f1, η ακρίβεια και η ανάκληση στο επίπεδο ορίου και επιλέξαμε το όριο με βάση την υψηλότερη βαθμολογία μέτρησης. Παρακάτω μπορείτε να δείτε την υλοποίηση της λειτουργίας αυτής της διαδικασίας.
Βελτιστοποίηση της βαθμολογίας F1 ρυθμίζοντας το όριο:
def optimise_f1_score(true_labels: np.ndarray, pred_labels: np.ndarray): best_med_th = 0.5 true_bools = [tl == 1 for tl in true_labels] micro_thresholds = (np.array(range(-45, 15)) / 100) + best_med_th f1_results, pre_results, recall_results = [], [], [] for th in micro_thresholds: pred_bools = [pl > th for pl in pred_labels] test_f1 = f1_score(true_bools, pred_bools, average="micro", zero_division=0) test_precision = precision_score( true_bools, pred_bools, average="micro", zero_division=0 ) test_recall = recall_score( true_bools, pred_bools, average="micro", zero_division=0 ) f1_results.append(test_f1) prec_results.append(test_precision) recall_results.append(test_recall) best_f1_idx = np.argmax(f1_results) return micro_thresholds[best_f1_idx]Αξιολόγηση και σύγκριση με τη βασική γραμμή
Αυτές οι προσεγγίσεις μας επέτρεψαν να εκπαιδεύσουμε ένα νέο μοντέλο και να λάβουμε το ακόλουθο αποτέλεσμα, το οποίο συγκρίνεται με τη βασική γραμμή: BERT στο Σχήμα 3 παρακάτω.

Σχήμα 3. Σύγκριση μετρήσεων κατά βάση και νεότερη προσέγγιση.
Συγκρίνοντας τις μετρήσεις που σχετίζονται με την ταξινόμηση, βλέπουμε μια σημαντική αύξηση στα μέτρα απόδοσης σχεδόν κατά 5-6 φορές:
Η βαθμολογία F1 αυξήθηκε από 12% → 55%, ενώ η ακρίβεια αυξήθηκε από 9% → 59% και η ανάκληση αυξήθηκε από 15% → 51%.
Με τις αλλαγές που φαίνονται στο δεξιό γράφημα στο Σχήμα 3, μπορούμε τώρα να προβλέψουμε το 80% των κλάσεων.
Φέτες τάξεων
Χωρίσαμε τις ετικέτες μας σε τέσσερις ομάδες: HEAD, MEDIUM, TAIL και ZERO. Κάθε ομάδα περιέχει ετικέτες με παρόμοιο αριθμό υποστηρικτικών παρατηρήσεων δεδομένων.
Όπως φαίνεται στο Σχήμα 4, οι κατανομές των ομάδων είναι διακριτές. Το τριαντάφυλλο (ΚΕΦΑΛΙ) έχει αρνητική λοξή κατανομή, το μεσαίο κουτί (MEDIUM) έχει θετική λοξή κατανομή και το πράσινο κουτί (ΟΥΡΑ) φαίνεται να έχει κανονική κατανομή.
Όλες οι ομάδες έχουν επίσης ακραία σημεία, τα οποία είναι σημεία έξω από τα μουστάκια στην πλοκή του κουτιού. Η ομάδα HEAD έχει σημαντικό αντίκτυπο σε μια τάξη MAJOR.
Επιπλέον, έχουμε εντοπίσει μια ξεχωριστή ομάδα με το όνομα "ZERO" που περιέχει ετικέτες που το μοντέλο δεν μπόρεσε να μάθει και δεν μπορεί να αναγνωρίσει λόγω του ελάχιστου αριθμού εμφανίσεων στο σύνολο δεδομένων (λιγότερο από το 3% όλων των παρατηρήσεων).
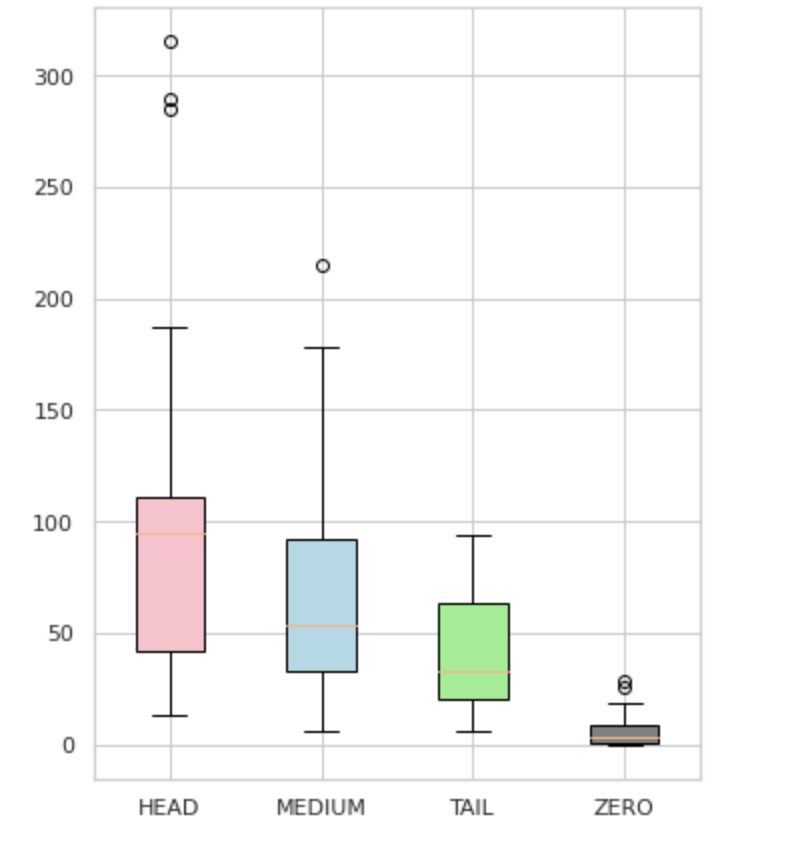
Εικόνα 4. Αριθμοί ετικετών έναντι ομάδων
Ο Πίνακας 2 παρέχει πληροφορίες σχετικά με τις μετρήσεις ανά ομάδα ετικετών για το δοκιμαστικό υποσύνολο δεδομένων.
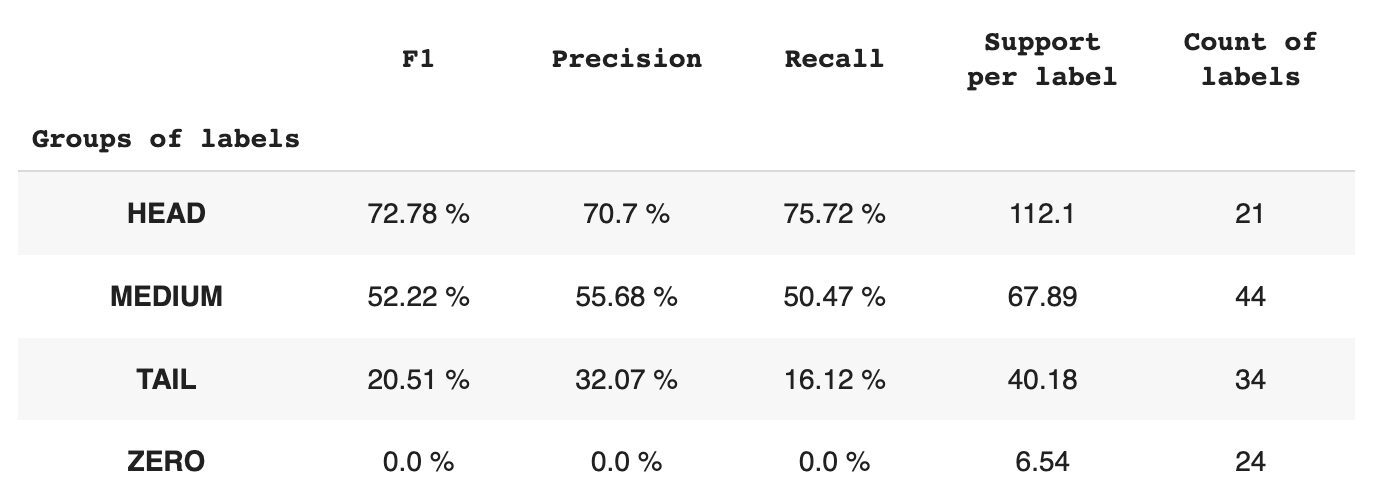
Πίνακας 2. Μετρήσεις ανά ομάδα.
- Η ομάδα HEAD περιέχει 21 ετικέτες με μέσο όρο 112 υποστηρικτικές παρατηρήσεις ανά ετικέτα. Αυτή η ομάδα επηρεάζεται από ακραίες τιμές και, λόγω της υψηλής εκπροσώπησής της στο σύνολο δεδομένων, οι μετρήσεις της είναι υψηλές: F1 – 73%, Ακρίβεια – 71%, Ανάκληση – 75%.
- Η ομάδα MEDIUM αποτελείται από 44 ετικέτες με μέση υποστήριξη 67 παρατηρήσεων, που είναι περίπου δύο φορές χαμηλότερη από την ομάδα HEAD. Οι μετρήσεις για αυτήν την ομάδα αναμένεται να μειωθούν κατά 50%: F1 – 52%, Ακρίβεια – 56%, Ανάκληση – 51%.
- Η ομάδα TAIL έχει τον μεγαλύτερο αριθμό κλάσεων, αλλά όλες εκπροσωπούνται ελάχιστα στο σύνολο δεδομένων, με μέσο όρο 40 υποστηρικτικές παρατηρήσεις ανά ετικέτα. Ως αποτέλεσμα, οι μετρήσεις μειώνονται σημαντικά: F1 – 21%, Precision – 32%, Recall – 16%.
- Η ομάδα ZERO περιλαμβάνει κλάσεις που το μοντέλο δεν μπορεί να αναγνωρίσει καθόλου, πιθανώς λόγω της χαμηλής εμφάνισής τους στο σύνολο δεδομένων. Κάθε μία από τις 24 ετικέτες αυτής της ομάδας έχει κατά μέσο όρο 7 υποστηρικτικές παρατηρήσεις.
Το Σχήμα 5 απεικονίζει τις πληροφορίες που παρουσιάζονται στον Πίνακα 2, παρέχοντας μια οπτική αναπαράσταση των μετρήσεων ανά ομάδα ετικετών.
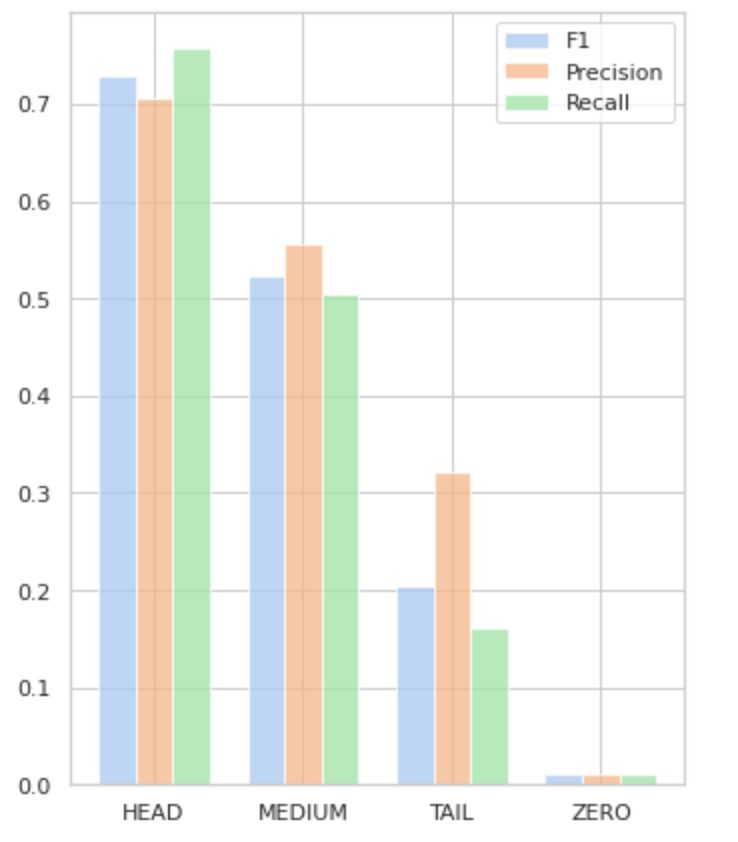
Εικόνα 5. Μετρήσεις έναντι ομάδων ετικετών. Όλες οι τιμές ZERO = 0.
Σε αυτό το περιεκτικό άρθρο, δείξαμε ότι μια φαινομενικά απλή διαδικασία ταξινόμησης κειμένου πολλαπλών ετικετών μπορεί να είναι δύσκολη όταν εφαρμόζονται παραδοσιακές μέθοδοι. Έχουμε προτείνει τη χρήση συναρτήσεων απώλειας εξισορρόπησης διανομής για την αντιμετώπιση του ζητήματος της ανισορροπίας τάξης.
Συγκρίναμε την απόδοση της προτεινόμενης προσέγγισής μας με την κλασική μέθοδο και την αξιολογήσαμε χρησιμοποιώντας πραγματικές επιχειρηματικές μετρήσεις. Τα αποτελέσματα καταδεικνύουν ότι η χρήση συναρτήσεων απώλειας για την αντιμετώπιση ανισορροπιών κλάσεων και συνεμφανίσεων ετικετών προσφέρει μια βιώσιμη λύση για ταξινόμηση κειμένου πολλαπλών ετικετών.
Η προτεινόμενη περίπτωση χρήσης υπογραμμίζει τη σημασία της εξέτασης διαφορετικών προσεγγίσεων και τεχνικών όταν ασχολείται με την ταξινόμηση κειμένου πολλαπλών ετικετών και τα πιθανά οφέλη των συναρτήσεων απώλειας εξισορρόπησης διανομής για την αντιμετώπιση ανισορροπιών κλάσεων.
Εάν αντιμετωπίζετε παρόμοιο πρόβλημα και το επιδιώκετε εξορθολογισμός των εργασιών επεξεργασίας εγγράφων εντός του οργανισμού σας, επικοινωνήστε μαζί μου ή με την ομάδα της Provectus. Θα χαρούμε να σας βοηθήσουμε να βρείτε πιο αποτελεσματικές μεθόδους για την αυτοματοποίηση των διαδικασιών σας.
Oleksii Babych είναι Μηχανικός Μηχανικής Μάθησης στο Provectus. Με υπόβαθρο στη φυσική, κατέχει εξαιρετικές αναλυτικές και μαθηματικές δεξιότητες και έχει αποκτήσει πολύτιμη εμπειρία μέσω επιστημονικής έρευνας και παρουσιάσεων διεθνών συνεδρίων, συμπεριλαμβανομένου του SPIE Photonics West. Η Oleksii ειδικεύεται στη δημιουργία ολοκληρωμένων, μεγάλης κλίμακας λύσεων AI/ML για βιομηχανίες υγειονομικής περίθαλψης και fintech. Συμμετέχει σε κάθε στάδιο του κύκλου ζωής ανάπτυξης ML, από τον εντοπισμό επιχειρηματικών προβλημάτων έως την ανάπτυξη και τη λειτουργία μοντέλων ML παραγωγής.
Ρινάτ Αχμέτοφ είναι ο ML Solution Architect στο Provectus. Με ένα σταθερό πρακτικό υπόβαθρο στη Μηχανική Μάθηση (ειδικά στο Computer Vision), ο Rinat είναι ένας σπασίκλας, λάτρης των δεδομένων, μηχανικός λογισμικού και εργασιομανής του οποίου το δεύτερο μεγαλύτερο πάθος είναι ο προγραμματισμός. Στο Provectus, ο Rinat είναι υπεύθυνος για την ανακάλυψη και την απόδειξη των φάσεων της ιδέας και ηγείται της εκτέλεσης πολύπλοκων έργων τεχνητής νοημοσύνης.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- Platoblockchain. Web3 Metaverse Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- πηγή: https://www.kdnuggets.com/2023/03/multilabel-nlp-analysis-class-imbalance-loss-function-approaches.html?utm_source=rss&utm_medium=rss&utm_campaign=multi-label-nlp-an-analysis-of-class-imbalance-and-loss-function-approaches
- :είναι
- 1
- 10
- 100
- 15%
- 67
- 7
- 9
- a
- Ικανός
- Σχετικά
- Κατορθώνω
- επιτευχθεί
- ενεργειών
- Δραστηριοποίηση
- προσαρμογή
- διεύθυνση
- διευθυνσιοδότηση
- AI
- AI / ML
- στόχοι
- αλγόριθμος
- αλγόριθμοι
- Όλα
- επιτρέπει
- Άλφα
- μεταξύ των
- ποσό
- ανάλυση
- Αναλυτικός
- αναλύοντας
- και
- Εμφανίστηκε
- εφαρμοσμένος
- Εφαρμογή
- πλησιάζω
- προσεγγίσεις
- περίπου
- ΕΙΝΑΙ
- άρθρο
- AS
- πτυχές
- ανατεθεί
- βοηθήσει
- συσχετισμένη
- At
- αυτοματοποίηση
- μέσος
- φόντο
- Υπόλοιπο
- βασίζονται
- Baseline
- BE
- επειδή
- παρακάτω
- οφέλη
- ΚΑΛΎΤΕΡΟΣ
- βήτα
- Καλύτερα
- μεταξύ
- προκατάληψη
- Μεγαλύτερη
- Κάτω μέρος
- Κουτί
- ενσωματωμένο
- επιχείρηση
- by
- υπολογίζεται
- CAN
- δεν μπορώ
- πιάνω
- περίπτωση
- κατηγορίες
- CB
- ορισμένες
- προκλήσεις
- πρόκληση
- Αλλαγές
- χρέωση
- τάξη
- τάξεις
- κλασικό
- ταξινόμηση
- πελάτης
- στενά
- πιο κοντά
- συνήθως
- σύγκριση
- συγκρίνοντας
- σύγκριση
- συγκρότημα
- περιεκτικός
- υπολογιστή
- Computer Vision
- χρήση υπολογιστή
- έννοια
- Πιθανά ερωτήματα
- Κατέληξε στο συμπέρασμα
- Διάσκεψη
- θεωρώντας
- επικοινωνήστε μαζί μας
- Περιέχει
- περιεχόμενο
- συμφραζόμενα
- συμβολή
- Καλύπτει
- δημιουργία
- πελάτης
- κύκλος
- ημερομηνία
- μοιρασιά
- μείωση
- ορίζεται
- αποδεικνύουν
- κατέδειξε
- ανάπτυξη
- σχεδιασμένα
- λεπτομερής
- Ανάπτυξη
- διαφορές
- διαφορετικές
- κατευθείαν
- ανακάλυψη
- διακριτή
- διανομή
- Διανομές
- διάφορα
- διαιρούμενο
- έγγραφο
- έγγραφα
- πράξη
- τομέα
- Πτώση
- κάθε
- εύκολα
- Αποτελεσματικός
- αποτελεσματικός
- προσπάθειες
- ενεργοποιήσετε
- από άκρη σε άκρη
- μηχανικός
- θιασώτης
- εξίσου
- σφάλμα
- ειδικά
- Αιθέρας (ΕΤΗ)
- αξιολόγηση
- Κάθε
- απόδειξη
- παράδειγμα
- έξοχος
- εκτέλεση
- αναμένεται
- εμπειρία
- εξερεύνηση
- διερευνήσει
- ρητή
- f1
- αντιμετωπίζουν
- αντιμέτωπος
- ανατροφοδότηση
- Εικόνα
- τελικός
- εύρεση
- fintech
- Όνομα
- φλοτέρ
- Εξής
- Για
- Βρέθηκαν
- κλάσμα
- Συχνότητα
- συχνάζω
- από
- λειτουργία
- λειτουργικός
- λειτουργίες
- περαιτέρω
- Κέρδος
- δεδομένου
- Ματιά
- γραφική παράσταση
- Πράσινο
- Group
- Ομάδα
- λαβή
- ευτυχισμένος
- Έχω
- κεφάλι
- υγειονομική περίθαλψη
- βοήθεια
- βοηθά
- Ψηλά
- υψηλότερο
- υψηλότερο
- ανταύγειες
- Πως
- Πώς να
- Ωστόσο
- HTML
- http
- HTTPS
- προσδιορίζονται
- προσδιορισμό
- ανισορροπία
- Επίπτωση
- επηρεάζονται
- εκτέλεση
- εισαγωγή
- σπουδαιότητα
- σημαντικό
- βελτίωση
- βελτίωση
- in
- περιλαμβάνει
- Συμπεριλαμβανομένου
- εσφαλμένα
- Αυξάνουν
- αυξημένη
- αύξηση
- ανεξάρτητα
- βιομηχανίες
- πληροφορίες
- συμφυής
- εισαγωγή
- παράδειγμα
- αντί
- International
- επενδύσει
- συμμετέχουν
- ζήτημα
- IT
- ΤΟΥ
- jpg
- μόνο ένα
- KDnuggets
- επιγραφή
- τιτλοφόρηση
- Ετικέτες
- Γλώσσα
- μεγάλης κλίμακας
- μεγαλύτερη
- στρώμα
- Οδηγεί
- ΜΑΘΑΊΝΩ
- μάθει
- μάθηση
- Επίπεδο
- ζωή
- Λίστα
- ματιά
- off
- απώλειες
- Χαμηλός
- μηχανή
- μάθηση μηχανής
- που
- Κυρίως
- μεγάλες
- Η πλειοψηφία
- πολοί
- χαρτης
- μαθηματικά
- ανώτατο όριο
- μέτρα
- medium
- μέθοδος
- μέθοδοι
- μετρικός
- Metrics
- ελάχιστος
- ML
- MLB
- μοντέλο
- μοντέλα
- τροποποιήσει
- ενότητα
- περισσότερο
- πιο αποτελεσματικό
- πλέον
- πολλαπλούς
- Ονομάστηκε
- Ανάγκη
- αρνητικός
- αρνητικά
- Νέα
- nlp
- κανονικός
- αξιοσημείωτος
- αριθμός
- αριθμοί
- πολλοί
- αποκτήσει
- λαμβάνεται
- of
- προσφορά
- on
- ONE
- Ευκαιρία
- αντίθετος
- Επιλογές
- επιχειρήσεις
- Άλλα
- αλλιώς
- εκτός
- εκκρεμή
- φόρμες
- παράμετρος
- πάθος
- πρότυπα
- ποσοστό
- επίδοση
- Φυσική
- κομμάτι
- Πλάτων
- Πληροφορία δεδομένων Plato
- Πλάτωνα δεδομένα
- σας παρακαλούμε
- σημεία
- PoS
- θετικός
- δυναμικού
- ενδεχομένως
- Πρακτικός
- Ακρίβεια
- προβλέψει
- προβλεπόμενη
- Προβλέψεις
- Προβλέπει
- Παρουσιάσεις
- παρουσιάζονται
- Πρόβλημα
- προβλήματα
- διαδικασια μας
- Διεργασίες
- μεταποίηση
- παράγει
- Προϊόν
- παραγωγή
- Προγραμματισμός
- έργα
- απόδειξη
- απόδειξη της έννοιας
- προτείνεται
- παρέχουν
- παρέχεται
- παρέχει
- χορήγηση
- pytorch
- αύξηση
- σειρά
- μάλλον
- πραγματικό κόσμο
- εξισορρόπηση
- ανακεφαλαιώσουμε
- αναγνωρίζω
- μείωση
- Μειωμένος
- μείωση
- αναφέρεται
- συγγένειες
- συνάφεια
- αντιπροσώπευση
- εκπροσωπούνται
- ζητήσει
- έρευνα
- αποτέλεσμα
- με αποτέλεσμα
- Αποτελέσματα
- απόδοση
- Επιστροφές
- ανασκόπηση
- ROSE
- τρέξιμο
- s
- ίδιο
- σενάρια
- Επιστημονική έρευνα
- Δεύτερος
- αναζήτηση
- επιλέγονται
- ΕΑΥΤΟΣ
- συναίσθημα
- ξεχωριστό
- υπηρεσία
- σειρά
- Σέτς
- Shape
- παρουσιάζεται
- Δείχνει
- σημασία
- σημαντικός
- σημαντικά
- παρόμοιες
- Απλούς
- ταυτοχρόνως
- ενιαίας
- Μέγεθος
- δεξιότητες
- So
- λογισμικό
- Μηχανικός Λογισμικού
- στέρεο
- λύση
- Λύσεις
- SOLVE
- μερικοί
- ειδικεύεται
- καθορίζεται
- Στάδιο
- στάδια
- πρότυπο
- στατιστική
- Βήμα
- ειλικρινής
- τέτοιος
- κατάλληλος
- εποπτευόμενη μάθηση
- υποστήριξη
- Στήριξη
- τραπέζι
- TAG
- Πάρτε
- στοχευμένες
- Έργο
- εργασίες
- τεχνικές
- δοκιμή
- Δοκιμές
- Ταξινόμηση κειμένου
- ότι
- Η
- οι πληροφορίες
- τους
- Τους
- τους
- Αυτοί
- κατώφλι
- Μέσω
- ώρα
- φορές
- προς την
- κορυφή
- δάδα
- Σύνολο
- αφή
- προς
- τροχιά
- παραδοσιακός
- Τρένο
- Εκπαίδευση
- Μεταμορφώστε
- Μεταμόρφωση
- μετασχηματίζεται
- μετασχηματίζοντας
- μεταχειρίζεται
- αληθής
- συνήθως
- αβεβαιότητες
- κατανόηση
- μοναδικός
- us
- χρήση
- περίπτωση χρήσης
- αξιοποιώντας
- επικύρωση
- Πολύτιμος
- Αξίες
- διάφορα
- βιώσιμος
- όραμα
- vs
- βάρος
- δυτικά
- Ποιό
- ενώ
- Wikipedia
- θα
- με
- εντός
- χωρίς
- εργάστηκαν
- Σας
- zephyrnet
- μηδέν