Η Gartner, Inc. εκτιμά ότι κακό κόστος δεδομένων οργανισμούς κατά μέσο όρο 12.9 εκατομμύρια USD ετησίως.
Ασχολούμαστε με Petabyte δεδομένων καθημερινά και τα προβλήματα ποιότητας δεδομένων είναι κοινά με τόσο τεράστιους όγκους δεδομένων. Τα κακά δεδομένα κοστίζουν στους οργανισμούς χρήματα, φήμη και χρόνο. Ως εκ τούτου, είναι πολύ σημαντικό να παρακολουθείτε και να επικυρώνετε συνεχώς την ποιότητα των δεδομένων.
Τα κακά δεδομένα περιλαμβάνουν ανακριβείς πληροφορίες, δεδομένα που λείπουν, εσφαλμένες πληροφορίες, μη συμμορφούμενα δεδομένα και διπλότυπα δεδομένα. Τα κακά δεδομένα θα οδηγήσουν σε εσφαλμένη ανάλυση δεδομένων, με αποτέλεσμα κακές αποφάσεις και αναποτελεσματικές στρατηγικές.
Η ποιότητα των δεδομένων Experian διαπίστωσε ότι η μέση εταιρεία χάνει το 12% των εσόδων της λόγω ανεπαρκών δεδομένων. Εκτός από χρήματα, οι εταιρείες υφίστανται και απώλεια χαμένου χρόνου.
Ο εντοπισμός των ανωμαλιών στα δεδομένα πριν από την επεξεργασία θα βοηθήσει τους οργανισμούς να αποκτήσουν πιο πολύτιμες γνώσεις για τη συμπεριφορά των πελατών τους και θα βοηθήσει στη μείωση του κόστους.
Η βιβλιοθήκη μεγάλων προσδοκιών βοηθά τους οργανισμούς να επαληθεύουν και να επιβεβαιώνουν τέτοιες ανωμαλίες στα δεδομένα με περισσότερους από 200+ out-of-the-box κανόνες που είναι άμεσα διαθέσιμοι.
Το Great Expectations είναι μια βιβλιοθήκη Python ανοιχτού κώδικα που μας βοηθά στην επικύρωση δεδομένων. Μεγάλες Προσδοκίες παρέχει ένα σύνολο μεθόδων ή λειτουργιών για να βοηθήστε τους μηχανικούς δεδομένων επικυρώστε γρήγορα ένα δεδομένο σύνολο δεδομένων.
Σε αυτό το άρθρο, θα εξετάσουμε τα βήματα που απαιτούνται για την επικύρωση των δεδομένων από τη βιβλιοθήκη Great Expectations.
Το GE είναι σαν μοναδιαίες δοκιμές για δεδομένα. Η GE παρέχει ισχυρισμούς που ονομάζονται Προσδοκίες για την εφαρμογή ορισμένων κανόνων στα υπό δοκιμή δεδομένα. Για παράδειγμα, το αναγνωριστικό/αριθμός συμβολαίου δεν πρέπει να είναι κενό για ένα έγγραφο ασφαλιστηρίου συμβολαίου. Για να ρυθμίσετε και να εκτελέσετε το GE, πρέπει να ακολουθήσετε τα παρακάτω βήματα. Αν και υπάρχουν πολλοί τρόποι για να εργαστείτε με τη GE (χρησιμοποιώντας το CLI της), θα εξηγήσω τον τρόπο ρύθμισης των πραγμάτων μέσω προγραμματισμού σε αυτό το άρθρο. Όλος ο πηγαίος κώδικας που εξηγείται σε αυτό το άρθρο είναι διαθέσιμος σε αυτό GitHub repo.
Βήμα 1: Ρυθμίστε τη διαμόρφωση δεδομένων
Η GE έχει μια ιδέα των καταστημάτων. Τα καταστήματα δεν είναι παρά η φυσική θέση στο δίσκο όπου μπορεί να αποθηκεύσει τις προσδοκίες (κανόνες/βεβαιώσεις), λεπτομέρειες εκτέλεσης, λεπτομέρειες σημείων ελέγχου, αποτελέσματα επικύρωσης και έγγραφα δεδομένων (στατικές εκδόσεις HTML των αποτελεσμάτων επικύρωσης). Περισσότερα για να μάθετε περισσότερα για τα καταστήματα.
Η GE υποστηρίζει διάφορα backend καταστημάτων. Σε αυτό το άρθρο, χρησιμοποιούμε το backend και τις προεπιλογές αποθήκευσης αρχείων. Η GE υποστηρίζει άλλα backend καταστημάτων όπως AWS (Amazon Web Services) S3, Azure Blobs, PostgreSQL, κ.λπ. Ανατρέξτε στο μάθετε περισσότερα για τα backends. Το παρακάτω απόσπασμα κώδικα δείχνει μια πολύ απλή διαμόρφωση δεδομένων:
STORE_FOLDER = "/Users/saisyam/work/github/great-expectations-sample/ge_data"
#Setup data config
data_context_config = DataContextConfig( datasources = {}, store_backend_defaults = FilesystemStoreBackendDefaults(root_directory=STORE_FOLDER)
) context = BaseDataContext(project_config = data_context_config)
Η παραπάνω ρύθμιση παραμέτρων χρησιμοποιεί το backend του File store με προεπιλογές. Η GE θα δημιουργήσει αυτόματα τους απαραίτητους φακέλους που απαιτούνται για την εκτέλεση των προσδοκιών. Θα προσθέσουμε πηγές δεδομένων στο επόμενο βήμα μας.
Βήμα 2: Ρύθμιση παραμέτρων πηγής δεδομένων
Η GE υποστηρίζει τρεις τύπους πηγών δεδομένων:
- Πάντα
- Σπινθήρας
- SQLAlchemy
Η διαμόρφωση προέλευσης δεδομένων λέει στη GE να χρησιμοποιήσει μια συγκεκριμένη μηχανή εκτέλεσης για την επεξεργασία του παρεχόμενου συνόλου δεδομένων. Για παράδειγμα, εάν διαμορφώσετε την πηγή δεδομένων σας ώστε να χρησιμοποιεί τη μηχανή εκτέλεσης του Pandas, πρέπει να παρέχετε ένα πλαίσιο δεδομένων Pandas με δεδομένα στην GE για την εκτέλεση των προσδοκιών σας. Ακολουθεί ένα δείγμα για τη χρήση των Pandas ως πηγή δεδομένων:
datasource_config = { "name": "sales_datasource", "class_name": "Datasource", "module_name": "great_expectations.datasource", "execution_engine": { "module_name": "great_expectations.execution_engine", "class_name": "PandasExecutionEngine", }, "data_connectors": { "default_runtime_data_connector_name": { "class_name": "RuntimeDataConnector", "module_name": "great_expectations.datasource.data_connector", "batch_identifiers": ["default_identifier_name"], }, },
}
context.add_datasource(**datasource_config)
Παρακαλώ αναφερθείτε σε αυτήν την τεκμηρίωση για περισσότερες πληροφορίες σχετικά με τις πηγές δεδομένων.
Βήμα 3: Δημιουργήστε μια σουίτα προσδοκιών και προσθέστε τις προσδοκίες
Αυτό το βήμα είναι το κρίσιμο μέρος. Σε αυτό το βήμα, θα δημιουργήσουμε μια σουίτα και θα προσθέσουμε προσδοκίες στη σουίτα. Μπορείτε να θεωρήσετε μια σουίτα ως μια ομάδα προσδοκιών που θα λειτουργήσει ως παρτίδα. Οι προσδοκίες που δημιουργούμε εδώ είναι να επικυρώσουμε ένα δείγμα αναφοράς πωλήσεων. Μπορείτε να κατεβάσετε το πωλήσεις.csv αρχείο.
Το παρακάτω απόσπασμα κώδικα δείχνει πώς μπορείτε να δημιουργήσετε μια σουίτα και να προσθέσετε προσδοκίες. Θα προσθέσουμε δύο προσδοκίες στη σουίτα μας.
# Create expectations suite and add expectations
suite = context.create_expectation_suite(expectation_suite_name="sales_suite", overwrite_existing=True) expectation_config_1 = ExpectationConfiguration( expectation_type="expect_column_values_to_be_in_set", kwargs={ "column": "product_group", "value_set": ["PG1", "PG2", "PG3", "PG4", "PG5", "PG6"] }
) suite.add_expectation(expectation_configuration=expectation_config_1) expectation_config_2 = ExpectationConfiguration( expectation_type="expect_column_values_to_be_unique", kwargs={ "column": "id" }
) suite.add_expectation(expectation_configuration=expectation_config_2)
context.save_expectation_suite(suite, "sales_suite")
Η πρώτη προσδοκία, "expect_column_values_to_be_in_set" ελέγχει εάν οι τιμές της στήλης (ομάδα_προϊόντων) είναι ίσες με οποιαδήποτε από τις τιμές στο δεδομένο σύνολο_τιμών. Η δεύτερη προσδοκία ελέγχει εάν οι τιμές της στήλης "id" είναι μοναδικές.
Μόλις προστεθούν και αποθηκευτούν οι προσδοκίες, τώρα μπορούμε να εκτελέσουμε αυτές τις προσδοκίες σε ένα σύνολο δεδομένων που θα δούμε στο βήμα 4.
Βήμα 4: Φόρτωση και επικύρωση των δεδομένων
Σε αυτό το βήμα, θα φορτώσουμε το αρχείο CSV στο pandas.DataFrame και θα δημιουργήσουμε ένα σημείο ελέγχου για να εκτελέσουμε τις προσδοκίες που δημιουργήσαμε παραπάνω.
# load and validate data
df = pd.read_csv("./sales.csv") batch_request = RuntimeBatchRequest( datasource_name="sales_datasource", data_connector_name="default_runtime_data_connector_name", data_asset_name="product_sales", runtime_parameters={"batch_data":df}, batch_identifiers={"default_identifier_name":"default_identifier"}
) checkpoint_config = { "name": "product_sales_checkpoint", "config_version": 1, "class_name":"SimpleCheckpoint", "expectation_suite_name": "sales_suite"
}
context.add_checkpoint(**checkpoint_config)
results = context.run_checkpoint( checkpoint_name="product_sales_checkpoint", validations=[ {"batch_request": batch_request} ]
)
Δημιουργούμε ένα αίτημα δέσμης για τα δεδομένα μας, παρέχοντας το όνομα της πηγής δεδομένων, το οποίο θα πει στην GE να χρησιμοποιήσει μια συγκεκριμένη μηχανή εκτέλεσης, στην περίπτωσή μας, Pandas. Δημιουργούμε μια ρύθμιση παραμέτρων σημείου ελέγχου και, στη συνέχεια, επικυρώνουμε το αίτημα δέσμης σε σχέση με το σημείο ελέγχου. Μπορείτε να προσθέσετε πολλαπλές αιτήσεις παρτίδας εάν οι προσδοκίες ισχύουν για τα δεδομένα της παρτίδας σε ένα μόνο σημείο ελέγχου. Η μέθοδος "run_checkpoint" επιστρέφει το αποτέλεσμα σε μορφή JSON και μπορεί να χρησιμοποιηθεί για περαιτέρω επεξεργασία ή ανάλυση.
Αποτελέσματα
Αφού εκτελέσουμε τις προσδοκίες στο σύνολο δεδομένων μας, η GE δημιουργεί έναν στατικό πίνακα εργαλείων HTML με τα αποτελέσματα για το σημείο ελέγχου μας. Τα αποτελέσματα περιέχουν τον αριθμό των αξιολογημένων προσδοκιών, τις επιτυχείς προσδοκίες, τις αποτυχημένες προσδοκίες και τα ποσοστά επιτυχίας. Τυχόν εγγραφές που δεν ανταποκρίνονται στις δεδομένες προσδοκίες θα επισημαίνονται στη σελίδα. Ακολουθεί ένα δείγμα για επιτυχή εκτέλεση:
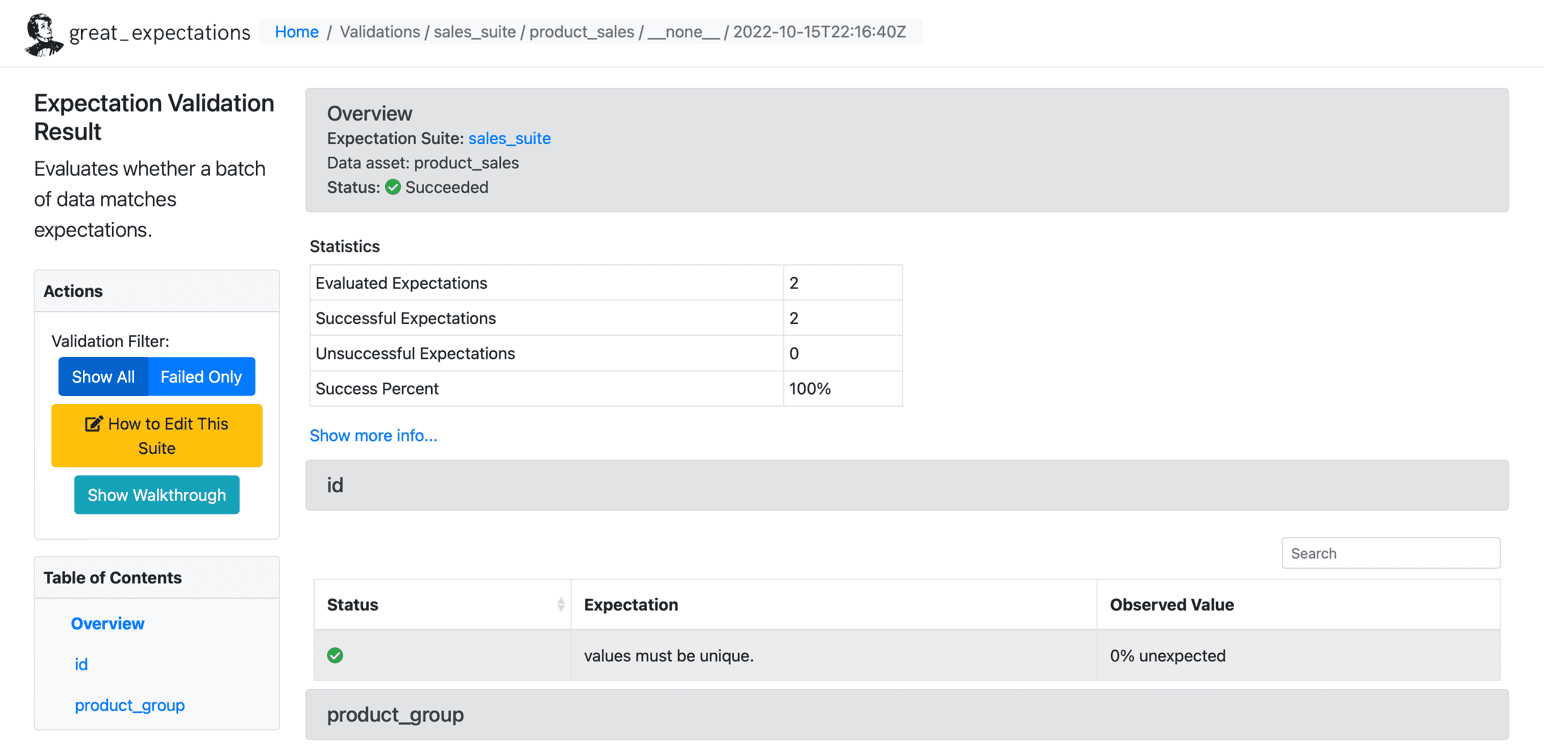
Πηγή: Μεγάλες Προσδοκίες
Παρακάτω είναι ένα δείγμα της αποτυχημένης προσδοκίας:
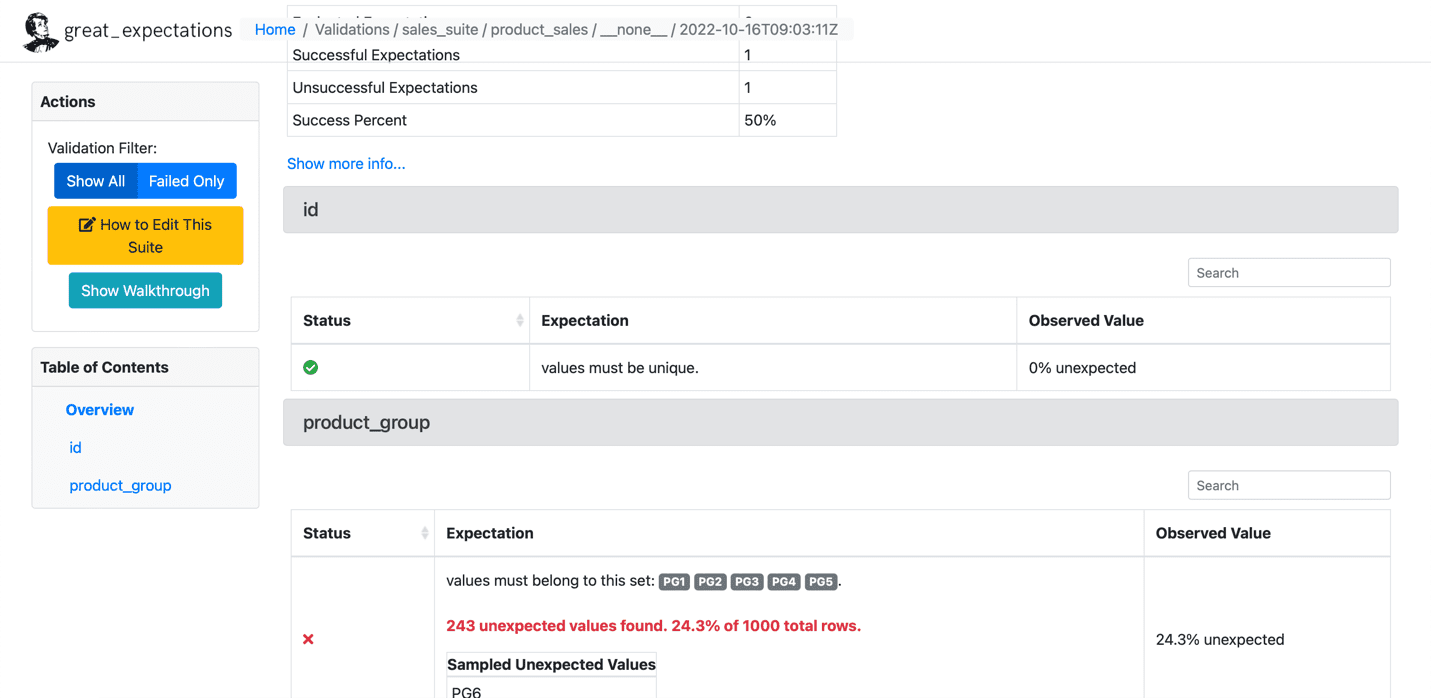
Πηγή: Μεγάλες Προσδοκίες
Ρυθμίσαμε τη GE σε τέσσερα βήματα και εκτελέσαμε με επιτυχία τις προσδοκίες σε ένα δεδομένο σύνολο δεδομένων. Η GE διαθέτει πιο προηγμένες δυνατότητες, όπως τη σύνταξη των προσαρμοσμένων προσδοκιών σας, τις οποίες θα καλύψουμε σε μελλοντικά άρθρα. Πολλοί οργανισμοί χρησιμοποιούν εκτενώς τη GE για να προσαρμόσουν τις απαιτήσεις των πελατών τους και να γράψουν προσαρμοσμένες προσδοκίες.
Saisyam Dampuri έρχεται με 18+ χρόνια εμπειρίας στην ανάπτυξη λογισμικού και είναι παθιασμένος με την εξερεύνηση νέων τεχνολογιών και εργαλείων. Αυτήν τη στιγμή εργάζεται ως Sr. Cloud Architect στο Anblicks, TX, ΗΠΑ. Αν και δεν κωδικοποιεί, θα είναι απασχολημένος με τη φωτογραφία, το μαγείρεμα και τα ταξίδια.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- Platoblockchain. Web3 Metaverse Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- πηγή: https://www.kdnuggets.com/2023/01/overcome-data-quality-issues-great-expectations.html?utm_source=rss&utm_medium=rss&utm_campaign=overcome-your-data-quality-issues-with-great-expectations
- 1
- 11
- 18 +
- 9
- a
- Σχετικά
- πάνω από
- προστιθέμενη
- προηγμένες
- κατά
- Όλα
- Amazon
- Amazon υπηρεσίες Web
- ανάλυση
- analytics
- και
- χώρια
- Εφαρμογή
- άρθρο
- εμπορεύματα
- αυτομάτως
- διαθέσιμος
- μέσος
- AWS
- Γαλανός
- Backend
- Κακός
- κακά δεδομένα
- πριν
- παρακάτω
- που ονομάζεται
- περίπτωση
- έλεγχοι
- πελάτες
- Backup
- κωδικός
- Κωδικοποίηση
- Στήλη
- Κοινός
- Εταιρείες
- εταίρα
- έννοια
- διαμόρφωση
- Εξετάστε
- συμφραζόμενα
- μαγείρεμα
- Δικαστικά έξοδα
- κάλυμμα
- δημιουργία
- δημιουργήθηκε
- δημιουργεί
- κρίσιμος
- Τη στιγμή
- έθιμο
- πελάτης
- συμπεριφορά πελατών
- προσαρμόσετε
- καθημερινά
- ταμπλό
- ημερομηνία
- ανάλυση δεδομένων
- την ποιότητα των δεδομένων
- σύνολο δεδομένων
- συμφωνία
- αποφάσεις
- προεπιλογές
- καθέκαστα
- Ανάπτυξη
- έγγραφο
- κατεβάσετε
- Κινητήρας
- εκτιμήσεις
- κ.λπ.
- Αιθέρας (ΕΤΗ)
- αξιολόγηση
- παράδειγμα
- εκτελέσει
- εκτέλεση
- προσδοκία
- προσδοκίες
- εμπειρία
- Εξηγήστε
- εξήγησε
- Εξερευνώντας
- Απέτυχε
- Χαρακτηριστικά
- Αρχεία
- Όνομα
- ακολουθήστε
- Forbes
- μορφή
- Βρέθηκαν
- ΠΛΑΙΣΙΟ
- από
- λειτουργίες
- περαιτέρω
- μελλοντικός
- Κέρδος
- ge
- δεδομένου
- εξαιρετική
- Group
- βοήθεια
- βοηθά
- εδώ
- Τόνισε
- Πως
- Πώς να
- HTML
- HTTPS
- τεράστιος
- σημαντικό
- in
- ανακριβής
- Α.Ε.
- περιλαμβάνει
- πληροφορίες
- ιδέες
- ασφάλιση
- συμμετέχουν
- θέματα
- IT
- json
- KDnuggets
- ΜΑΘΑΊΝΩ
- Βιβλιοθήκη
- φορτίο
- τοποθεσία
- ματιά
- Χάνει
- off
- πολοί
- Ταίριασμα
- μέθοδος
- μέθοδοι
- εκατομμύριο
- Λείπει
- χρήματα
- Παρακολούθηση
- περισσότερο
- πολλαπλούς
- όνομα
- απαραίτητος
- Ανάγκη
- που απαιτούνται
- Νέα
- Νέες τεχνολογίες
- επόμενη
- αριθμός
- ανοικτού κώδικα
- οργανώσεις
- ΑΛΛΑ
- Ξεπεράστε
- Πάντα
- μέρος
- παθιασμένος
- φωτογραφία
- φυσικός
- Πλάτων
- Πληροφορία δεδομένων Plato
- Πλάτωνα δεδομένα
- πολιτική
- postgresql
- διαδικασια μας
- μεταποίηση
- προγραμματικός
- παρέχουν
- παρέχεται
- παρέχει
- χορήγηση
- Python
- ποιότητα
- γρήγορα
- αρχεία
- Μειωμένος
- αναφέρουν
- φήμη
- ζητήσει
- αιτήματα
- απαιτήσεις
- αποτέλεσμα
- με αποτέλεσμα
- Αποτελέσματα
- Επιστροφές
- έσοδα
- κανόνες
- τρέξιμο
- εμπορικός
- Δεύτερος
- Υπηρεσίες
- σειρά
- τον καθορισμό
- θα πρέπει να
- Δείχνει
- Απλούς
- ενιαίας
- λογισμικό
- ανάπτυξη λογισμικού
- μερικοί
- Πηγή
- πρωτογενής κώδικας
- Πηγές
- συγκεκριμένες
- Βήμα
- Βήματα
- κατάστημα
- καταστήματα
- στρατηγικές
- επιτυχία
- επιτυχής
- Επιτυχώς
- τέτοιος
- σουίτα
- Υποστηρίζει
- Τεχνολογίες
- λέει
- δοκιμή
- δοκιμές
- Η
- Η Πηγη
- τους
- πράγματα
- τρία
- ώρα
- προς την
- εργαλεία
- Ταξίδια
- TX
- τύποι
- υπό
- μοναδικός
- μονάδα
- us
- USD
- χρήση
- ΕΠΙΚΥΡΩΝΩ
- επικύρωση
- Πολύτιμος
- Αξίες
- διάφορα
- επαληθεύει
- όγκους
- τρόπους
- ιστός
- διαδικτυακές υπηρεσίες
- αν
- Ποιό
- ενώ
- θα
- Εργασία
- εργαζόμενος
- γράφω
- γραφή
- χρόνια
- Σας
- zephyrnet