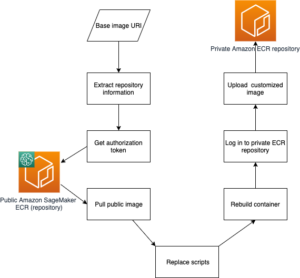
Στην όραση υπολογιστή, η σημασιολογική τμηματοποίηση είναι το καθήκον της ταξινόμησης κάθε εικονοστοιχείου σε μια εικόνα με μια κλάση από ένα γνωστό σύνολο ετικετών, έτσι ώστε τα εικονοστοιχεία με την ίδια ετικέτα να μοιράζονται ορισμένα χαρακτηριστικά. Δημιουργεί μια μάσκα τμηματοποίησης των εικόνων εισόδου. Για παράδειγμα, οι παρακάτω εικόνες δείχνουν μια μάσκα τμηματοποίησης του cat επιγραφή.
 |
 |
Τον Νοέμβριο του 2018, Amazon Sage Maker ανακοίνωσε την κυκλοφορία του αλγόριθμου σημασιολογικής τμηματοποίησης SageMaker. Με αυτόν τον αλγόριθμο, μπορείτε να εκπαιδεύσετε τα μοντέλα σας με ένα δημόσιο σύνολο δεδομένων ή το δικό σας σύνολο δεδομένων. Τα δημοφιλή σύνολα δεδομένων τμηματοποίησης εικόνων περιλαμβάνουν το σύνολο δεδομένων Common Objects in Context (COCO) και PASCAL Visual Object Classes (PASCAL VOC), αλλά οι κατηγορίες των ετικετών τους είναι περιορισμένες και μπορεί να θέλετε να εκπαιδεύσετε ένα μοντέλο σε αντικείμενα-στόχους που δεν περιλαμβάνονται στο δημόσια σύνολα δεδομένων. Σε αυτή την περίπτωση, μπορείτε να χρησιμοποιήσετε Amazon SageMaker Ground Αλήθεια για να επισημάνετε το δικό σας σύνολο δεδομένων.
Σε αυτήν την ανάρτηση, παρουσιάζω τις ακόλουθες λύσεις:
- Χρήση της βασικής αλήθειας για την επισήμανση ενός συνόλου δεδομένων σημασιολογικής τμηματοποίησης
- Μετατροπή των αποτελεσμάτων από το Ground Truth στην απαιτούμενη μορφή εισόδου για τον ενσωματωμένο αλγόριθμο σημασιολογικής τμηματοποίησης SageMaker
- Χρησιμοποιώντας τον αλγόριθμο σημασιολογικής τμηματοποίησης για την εκπαίδευση ενός μοντέλου και την εκτέλεση συμπερασμάτων
Επισήμανση δεδομένων σημασιολογικής τμηματοποίησης
Για να δημιουργήσουμε ένα μοντέλο μηχανικής εκμάθησης για σημασιολογική τμηματοποίηση, πρέπει να επισημάνουμε ένα σύνολο δεδομένων σε επίπεδο pixel. Το Ground Truth σάς δίνει την επιλογή να χρησιμοποιήσετε ανθρώπινους σχολιαστές Αμαζόν Μηχανολόγος Τούρκος, τρίτους προμηθευτές ή το δικό σας ιδιωτικό εργατικό δυναμικό. Για να μάθετε περισσότερα σχετικά με το εργατικό δυναμικό, ανατρέξτε στο Δημιουργία και διαχείριση εργατικού δυναμικού. Εάν δεν θέλετε να διαχειριστείτε μόνοι σας το εργατικό δυναμικό για τις ετικέτες, Amazon SageMaker Ground Truth Plus είναι μια άλλη εξαιρετική επιλογή ως μια νέα υπηρεσία επισήμανσης δεδομένων με το κλειδί στο χέρι που σας δίνει τη δυνατότητα να δημιουργείτε υψηλής ποιότητας σύνολα δεδομένων εκπαίδευσης γρήγορα και μειώνει το κόστος έως και 40%. Για αυτήν την ανάρτηση, σας δείχνω πώς να επισημάνετε με μη αυτόματο τρόπο το σύνολο δεδομένων με τη δυνατότητα αυτόματης τμηματοποίησης Ground Truth και την ετικέτα crowdsource με εργατικό δυναμικό της Mechanical Turk.
Χειροκίνητη επισήμανση με βασική αλήθεια
Τον Δεκέμβριο του 2019, η Ground Truth πρόσθεσε μια δυνατότητα αυτόματης τμηματοποίησης στη διεπαφή χρήστη ετικετών σημασιολογικής τμηματοποίησης για να αυξήσει την απόδοση των ετικετών και να βελτιώσει την ακρίβεια. Για περισσότερες πληροφορίες, ανατρέξτε στο Αυτόματη τμηματοποίηση αντικειμένων κατά την εκτέλεση ετικετών σημασιολογικής τμηματοποίησης με το Amazon SageMaker Ground Truth. Με αυτήν τη νέα δυνατότητα, μπορείτε να επιταχύνετε τη διαδικασία επισήμανσης σε εργασίες τμηματοποίησης. Αντί να σχεδιάζετε ένα πολύγωνο πολύγωνο ή να χρησιμοποιείτε το εργαλείο πινέλου για να τραβήξετε ένα αντικείμενο σε μια εικόνα, σχεδιάζετε μόνο τέσσερα σημεία: στο πάνω-πολύ, κάτω-πιο, στο πιο αριστερό και στο δεξιότερο σημείο του αντικειμένου. Το Ground Truth λαμβάνει αυτά τα τέσσερα σημεία ως είσοδο και χρησιμοποιεί τον αλγόριθμο Deep Extreme Cut (DEXTR) για να δημιουργήσει μια μάσκα που εφαρμόζει σφιχτά γύρω από το αντικείμενο. Για ένα σεμινάριο που χρησιμοποιεί το Ground Truth για την επισήμανση σημασιολογικής τμηματοποίησης εικόνας, ανατρέξτε στο Σημασιολογική τμηματοποίηση εικόνας. Το παρακάτω είναι ένα παράδειγμα του τρόπου με τον οποίο το εργαλείο αυτόματης τμηματοποίησης δημιουργεί αυτόματα μια μάσκα τμηματοποίησης αφού επιλέξετε τα τέσσερα ακραία σημεία ενός αντικειμένου.


Ετικέτα Crowdsourcing με εργατικό δυναμικό Μηχανικών Τούρκων
Εάν διαθέτετε ένα μεγάλο σύνολο δεδομένων και δεν θέλετε να επισημάνετε με μη αυτόματο τρόπο εκατοντάδες ή χιλιάδες εικόνες, μπορείτε να χρησιμοποιήσετε το Mechanical Turk, το οποίο παρέχει κατ' απαίτηση, επεκτάσιμο, ανθρώπινο εργατικό δυναμικό για την ολοκλήρωση εργασιών που οι άνθρωποι μπορούν να κάνουν καλύτερα από τους υπολογιστές. Το λογισμικό Mechanical Turk επισημοποιεί προσφορές εργασίας σε χιλιάδες εργαζόμενους που είναι πρόθυμοι να κάνουν αποσπασματική εργασία όποτε τους βολεύει. Το λογισμικό ανακτά επίσης την εργασία που εκτελείται και τη μεταγλωττίζει για εσάς, τον αιτούντα, ο οποίος πληρώνει τους εργαζόμενους για ικανοποιητική εργασία (μόνο). Για να ξεκινήσετε με το Mechanical Turk, ανατρέξτε στο Εισαγωγή στο Amazon Mechanical Turk.
Δημιουργήστε μια εργασία επισήμανσης
Το παρακάτω είναι ένα παράδειγμα εργασίας επισήμανσης Mechanical Turk για ένα σύνολο δεδομένων θαλάσσιας χελώνας. Το σύνολο δεδομένων θαλάσσιας χελώνας προέρχεται από τον διαγωνισμό Kaggle Ανίχνευση προσώπου θαλάσσιας χελώνας, και επέλεξα 300 εικόνες του συνόλου δεδομένων για σκοπούς επίδειξης. Η θαλάσσια χελώνα δεν είναι μια κοινή κατηγορία σε δημόσια σύνολα δεδομένων, επομένως μπορεί να αντιπροσωπεύει μια κατάσταση που απαιτεί την επισήμανση ενός τεράστιου δεδομένων.
- Στην κονσόλα SageMaker, επιλέξτε Ετικέτες εργασίας στο παράθυρο πλοήγησης.
- Επιλέξτε Δημιουργήστε εργασία επισήμανσης.
- Εισαγάγετε ένα όνομα για τη δουλειά σας.
- Για Ρύθμιση δεδομένων εισαγωγής, Επιλέξτε Αυτοματοποιημένη ρύθμιση δεδομένων.
Αυτό δημιουργεί ένα μανιφέστο δεδομένων εισόδου. - Για Θέση S3 για σύνολα δεδομένων εισόδου, εισαγάγετε τη διαδρομή για το σύνολο δεδομένων.

- Για Κατηγορία εργασιών, επιλέξτε Εικόνα.
- Για Επιλογή εργασιών, Επιλέξτε Σημασιολογική κατάτμηση.

- Για Τύποι εργαζομένων, Επιλέξτε Αμαζόν Μηχανολόγος Τούρκος.
- Διαμορφώστε τις ρυθμίσεις σας για το χρονικό όριο λήξης της εργασίας, το χρόνο λήξης της εργασίας και την τιμή ανά εργασία.

- Προσθέστε μια ετικέτα (για αυτήν την ανάρτηση,
sea turtle), και παρέχετε οδηγίες επισήμανσης. - Επιλέξτε Δημιουργία.

Αφού ρυθμίσετε την εργασία τοποθέτησης ετικετών, μπορείτε να ελέγξετε την πρόοδο της τοποθέτησης ετικετών στην κονσόλα SageMaker. Όταν επισημανθεί ως ολοκληρωμένη, μπορείτε να επιλέξετε την εργασία για να ελέγξετε τα αποτελέσματα και να τα χρησιμοποιήσετε για τα επόμενα βήματα.

Μετασχηματισμός συνόλου δεδομένων
Αφού λάβετε την έξοδο από το Ground Truth, μπορείτε να χρησιμοποιήσετε τους ενσωματωμένους αλγόριθμους του SageMaker για να εκπαιδεύσετε ένα μοντέλο σε αυτό το σύνολο δεδομένων. Αρχικά, πρέπει να προετοιμάσετε το επισημασμένο σύνολο δεδομένων ως τη διεπαφή εισόδου που ζητήθηκε για τον αλγόριθμο σημασιολογικής τμηματοποίησης SageMaker.
Ζητήθηκαν κανάλια δεδομένων εισόδου
Η σημασιολογική τμηματοποίηση του SageMaker αναμένει ότι θα αποθηκευτεί το εκπαιδευτικό σας σύνολο Απλή υπηρεσία αποθήκευσης Amazon (Amazon S3). Το σύνολο δεδομένων στο Amazon S3 αναμένεται να παρουσιαστεί σε δύο κανάλια, το ένα για train και ένα για validation, χρησιμοποιώντας τέσσερις καταλόγους, δύο για εικόνες και δύο για σχολιασμούς. Οι σχολιασμοί αναμένεται να είναι μη συμπιεσμένες εικόνες PNG. Το σύνολο δεδομένων μπορεί επίσης να έχει έναν χάρτη ετικετών που περιγράφει τον τρόπο δημιουργίας των αντιστοιχίσεων σχολιασμού. Εάν όχι, ο αλγόριθμος χρησιμοποιεί μια προεπιλογή. Για συμπέρασμα, ένα τελικό σημείο δέχεται εικόνες με ένα image/jpeg Τύπος περιεχομένου. Ακολουθεί η απαιτούμενη δομή των καναλιών δεδομένων:
Κάθε εικόνα JPG στους καταλόγους αμαξοστοιχίας και επικύρωσης έχει μια αντίστοιχη εικόνα ετικέτας PNG με το ίδιο όνομα στο train_annotation και validation_annotation καταλόγους. Αυτή η σύμβαση ονομασίας βοηθά τον αλγόριθμο να συσχετίσει μια ετικέτα με την αντίστοιχη εικόνα της κατά τη διάρκεια της εκπαίδευσης. Το τρένο, train_annotation, επικύρωση και validation_annotation τα κανάλια είναι υποχρεωτικά. Οι σχολιασμοί είναι εικόνες PNG μονού καναλιού. Η μορφή λειτουργεί εφόσον τα μεταδεδομένα (λειτουργίες) στην εικόνα βοηθούν τον αλγόριθμο να διαβάσει τις εικόνες σχολιασμού σε έναν ακέραιο χωρίς υπογραφή ενός καναλιού 8-bit.
Έξοδος από την εργασία επισήμανσης Ground Truth
Οι έξοδοι που δημιουργούνται από την εργασία επισήμανσης Ground Truth έχουν την ακόλουθη δομή φακέλου:
Οι μάσκες τμηματοποίησης αποθηκεύονται s3://turtle2022/labelturtles/annotations/consolidated-annotation/output. Κάθε εικόνα σχολιασμού είναι ένα αρχείο .png που ονομάζεται από το ευρετήριο της εικόνας προέλευσης και την ώρα που ολοκληρώθηκε αυτή η επισήμανση εικόνας. Για παράδειγμα, τα ακόλουθα είναι η εικόνα πηγής (Image_1.jpg) και η μάσκα τμηματοποίησής της που δημιουργήθηκε από το εργατικό δυναμικό της Mechanical Turk (0_2022-02-10T17:41:04.724225.png). Παρατηρήστε ότι το ευρετήριο της μάσκας είναι διαφορετικό από τον αριθμό στο όνομα της εικόνας προέλευσης.
 |
 |
Το μανιφέστο εξόδου από την εργασία επισήμανσης βρίσκεται στο /manifests/output/output.manifest αρχείο. Είναι ένα αρχείο JSON και κάθε γραμμή καταγράφει μια αντιστοίχιση μεταξύ της εικόνας προέλευσης και της ετικέτας της και άλλων μεταδεδομένων. Η ακόλουθη γραμμή JSON καταγράφει μια αντιστοίχιση μεταξύ της εμφανιζόμενης εικόνας πηγής και του σχολιασμού της:
Η εικόνα πηγής ονομάζεται Image_1.jpg και το όνομα του σχολιασμού είναι 0_2022-02-10T17:41: 04.724225.png. Για να προετοιμάσουμε τα δεδομένα ως τις απαιτούμενες μορφές καναλιών δεδομένων του αλγόριθμου σημασιολογικής τμηματοποίησης SageMaker, πρέπει να αλλάξουμε το όνομα του σχολιασμού έτσι ώστε να έχει το ίδιο όνομα με τις εικόνες πηγής JPG. Και πρέπει επίσης να χωρίσουμε το σύνολο δεδομένων σε train και validation καταλόγους για εικόνες πηγής και σχολιασμούς.
Μετατρέψτε την έξοδο από μια εργασία επισήμανσης Ground Truth στην απαιτούμενη μορφή εισαγωγής
Για να μετατρέψετε την έξοδο, ολοκληρώστε τα παρακάτω βήματα:
- Λήψη όλων των αρχείων από την εργασία επισήμανσης από το Amazon S3 σε έναν τοπικό κατάλογο:
- Διαβάστε το αρχείο δήλωσης και αλλάξτε τα ονόματα του σχολιασμού με τα ίδια ονόματα με τις εικόνες πηγής:
- Διαχωρίστε τα σύνολα δεδομένων αμαξοστοιχίας και επικύρωσης:
- Δημιουργήστε έναν κατάλογο στην απαιτούμενη μορφή για τα κανάλια δεδομένων αλγορίθμου σημασιολογικής τμηματοποίησης:
- Μετακινήστε τις εικόνες τρένου και επικύρωσης και τους σχολιασμούς τους στους καταλόγους που δημιουργήθηκαν.
- Για εικόνες, χρησιμοποιήστε τον ακόλουθο κώδικα:
- Για σχολιασμούς, χρησιμοποιήστε τον ακόλουθο κώδικα:
- Μεταφορτώστε τα σύνολα δεδομένων αμαξοστοιχίας και επικύρωσης και τα σύνολα δεδομένων σχολιασμού τους στο Amazon S3:
Εκπαίδευση μοντέλου σημασιολογικής τμηματοποίησης SageMaker
Σε αυτήν την ενότητα, ακολουθούμε τα βήματα για την εκπαίδευση του μοντέλου σημασιολογικής τμηματοποίησης.
Ακολουθήστε το δείγμα σημειωματάριου και ρυθμίστε τα κανάλια δεδομένων
Μπορείτε να ακολουθήσετε τις οδηγίες στο Ο αλγόριθμος Semantic Segmentation είναι πλέον διαθέσιμος στο Amazon SageMaker για να εφαρμόσετε τον αλγόριθμο σημασιολογικής τμηματοποίησης στο επισημασμένο σύνολο δεδομένων σας. Αυτό το δείγμα σημειωματάριο δείχνει ένα από άκρο σε άκρο παράδειγμα που εισάγει τον αλγόριθμο. Στο σημειωματάριο, μαθαίνετε πώς να εκπαιδεύετε και να φιλοξενείτε ένα μοντέλο σημασιολογικής τμηματοποίησης χρησιμοποιώντας το πλήρως συνελικτικό δίκτυο (FCN) αλγόριθμος που χρησιμοποιεί το Σύνολο δεδομένων Pascal VOC για εκπαίδευση. Επειδή δεν σκοπεύω να εκπαιδεύσω ένα μοντέλο από το σύνολο δεδομένων Pascal VOC, παρέλειψα το Βήμα 3 (προετοιμασία δεδομένων) σε αυτό το σημειωματάριο. Αντίθετα, δημιούργησα άμεσα train_channel, train_annotation_channe, validation_channel, να validation_annotation_channel χρησιμοποιώντας τις τοποθεσίες S3 όπου αποθηκεύσα τις εικόνες και τους σχολιασμούς μου:
Προσαρμόστε τις υπερπαραμέτρους για το δικό σας σύνολο δεδομένων στον εκτιμητή SageMaker
Ακολούθησα το σημειωματάριο και δημιούργησα ένα αντικείμενο εκτιμητή SageMaker (ss_estimator) για να εκπαιδεύσω τον αλγόριθμο τμηματοποίησης μου. Ένα πράγμα που πρέπει να προσαρμόσουμε για το νέο σύνολο δεδομένων είναι μέσα ss_estimator.set_hyperparameters: Πρέπει να αλλάξουμε num_classes=21 προς την num_classes=2 (turtle και background), και άλλαξα κι εγώ epochs=10 προς την epochs=30 επειδή το 10 είναι μόνο για σκοπούς επίδειξης. Στη συνέχεια χρησιμοποίησα το παράδειγμα p3.2xlarge για εκπαίδευση μοντέλων με ρύθμιση instance_type="ml.p3.2xlarge". Η προπόνηση ολοκληρώθηκε σε 8 λεπτά. Το καλύτερο MIoU (Μέση διασταύρωση πάνω από την ένωση) 0.846 επιτυγχάνεται στην εποχή 11 με pix_acc (το ποσοστό των εικονοστοιχείων στην εικόνα σας που έχουν ταξινομηθεί σωστά) 0.925, που είναι ένα πολύ καλό αποτέλεσμα για αυτό το μικρό σύνολο δεδομένων.
Αποτελέσματα συμπερασμάτων μοντέλου
Φιλοξενούσα το μοντέλο σε μια χαμηλού κόστους παράδειγμα ml.c5.xlarge:
Τέλος, ετοίμασα ένα δοκιμαστικό σετ 10 εικόνων χελώνας για να δω το συμπέρασμα του εκπαιδευμένου μοντέλου τμηματοποίησης:
Οι παρακάτω εικόνες δείχνουν τα αποτελέσματα.

Οι μάσκες τμηματοποίησης των θαλάσσιων χελωνών φαίνονται ακριβείς και είμαι ευχαριστημένος με αυτό το αποτέλεσμα που εκπαιδεύτηκε σε ένα σύνολο δεδομένων 300 εικόνων με ετικέτα από εργάτες της Mechanical Turk. Μπορείτε επίσης να εξερευνήσετε άλλα διαθέσιμα δίκτυα όπως π.χ δίκτυο ανάλυσης πυραμίδας σκηνής (PSP) or DeepLab-V3 στο δείγμα σημειωματάριου με το σύνολο δεδομένων σας.
εκκαθάριση
Διαγράψτε το τελικό σημείο όταν τελειώσετε με αυτό για να αποφύγετε το συνεχές κόστος:
Συμπέρασμα
Σε αυτήν την ανάρτηση, έδειξα πώς να προσαρμόζω την επισήμανση δεδομένων σημασιολογικής τμηματοποίησης και την εκπαίδευση μοντέλων χρησιμοποιώντας το SageMaker. Αρχικά, μπορείτε να ρυθμίσετε μια εργασία επισήμανσης με το εργαλείο αυτόματης τμηματοποίησης ή να χρησιμοποιήσετε ένα εργατικό δυναμικό της Mechanical Turk (καθώς και άλλες επιλογές). Εάν έχετε περισσότερα από 5,000 αντικείμενα, μπορείτε επίσης να χρησιμοποιήσετε αυτοματοποιημένη επισήμανση δεδομένων. Στη συνέχεια, μετατρέπετε τα αποτελέσματα από την εργασία επισήμανσης Ground Truth στις απαιτούμενες μορφές εισόδου για την ενσωματωμένη εκπαίδευση σημασιολογικής τμηματοποίησης του SageMaker. Μετά από αυτό, μπορείτε να χρησιμοποιήσετε μια παρουσία επιτάχυνσης υπολογιστών (όπως p2 ή p3) για να εκπαιδεύσετε ένα μοντέλο σημασιολογικής τμηματοποίησης με τα ακόλουθα σημειωματάριο και αναπτύξτε το μοντέλο σε μια πιο οικονομική παρουσία (όπως ml.c5.xlarge). Τέλος, μπορείτε να ελέγξετε τα αποτελέσματα συμπερασμάτων στο σύνολο δεδομένων δοκιμής σας με μερικές γραμμές κώδικα.
Ξεκινήστε με τη σημασιολογική τμηματοποίηση του SageMaker επισήμανση δεδομένων και εκπαίδευση μοντέλου με το αγαπημένο σας σύνολο δεδομένων!
Σχετικά με το Συγγραφέας
 Κάρα Γιανγκ είναι Επιστήμονας Δεδομένων στο AWS Professional Services. Είναι παθιασμένη να βοηθά τους πελάτες να επιτύχουν τους επιχειρηματικούς τους στόχους με τις υπηρεσίες cloud AWS. Έχει βοηθήσει οργανισμούς να δημιουργήσουν λύσεις ML σε πολλούς κλάδους όπως η μεταποίηση, η αυτοκινητοβιομηχανία, η περιβαλλοντική βιωσιμότητα και η αεροδιαστημική.
Κάρα Γιανγκ είναι Επιστήμονας Δεδομένων στο AWS Professional Services. Είναι παθιασμένη να βοηθά τους πελάτες να επιτύχουν τους επιχειρηματικούς τους στόχους με τις υπηρεσίες cloud AWS. Έχει βοηθήσει οργανισμούς να δημιουργήσουν λύσεις ML σε πολλούς κλάδους όπως η μεταποίηση, η αυτοκινητοβιομηχανία, η περιβαλλοντική βιωσιμότητα και η αεροδιαστημική.
- Coinsmart. Το καλύτερο ανταλλακτήριο Bitcoin και Crypto στην Ευρώπη.
- Platoblockchain. Web3 Metaverse Intelligence. Ενισχύθηκε η γνώση. ΕΛΕΥΘΕΡΗ ΠΡΟΣΒΑΣΗ.
- CryptoHawk. Ραντάρ Altcoin. Δωρεάν δοκιμή.
- Πηγή: https://aws.amazon.com/blogs/machine-learning/semantic-segmentation-data-labeling-and-model-training-using-amazon-sagemaker/
- '
- "
- 000
- 10
- 100
- 11
- 2019
- a
- Σχετικά
- επιταχύνουν
- επιτάχυνση
- ακριβής
- Κατορθώνω
- επιτευχθεί
- απέναντι
- προστιθέμενη
- Αεροδιαστημική
- αλγόριθμος
- αλγόριθμοι
- Όλα
- Amazon
- ανακοίνωσε
- Άλλος
- γύρω
- Συνεργάτης
- Αυτοματοποιημένη
- αυτομάτως
- αυτοκινήτων
- διαθέσιμος
- AWS
- φόντο
- επειδή
- ΚΑΛΎΤΕΡΟΣ
- Καλύτερα
- μεταξύ
- χτίζω
- ενσωματωμένο
- επιχείρηση
- πιάνω
- περίπτωση
- ορισμένες
- αλλαγή
- κανάλια
- Επιλέξτε
- τάξη
- τάξεις
- ταξινομούνται
- Backup
- υπηρεσίες cloud
- κωδικός
- Κοινός
- ανταγωνισμός
- πλήρης
- υπολογιστή
- υπολογιστές
- χρήση υπολογιστή
- εμπιστοσύνη
- πρόξενος
- περιεχόμενο
- ευκολία
- Αντίστοιχος
- αποδοτική
- Δικαστικά έξοδα
- δημιουργία
- δημιουργήθηκε
- Πελάτες
- προσαρμόσετε
- ημερομηνία
- επιστήμονας δεδομένων
- βαθύς
- αποδεικνύουν
- παρατάσσω
- διαφορετικές
- κατευθείαν
- σχέδιο
- κατά την διάρκεια
- κάθε
- δίνει τη δυνατότητα
- από άκρη σε άκρη
- Τελικό σημείο
- εισάγετε
- περιβάλλοντος
- εγκατεστημένος
- παράδειγμα
- Εκτός
- αναμένεται
- αναμένει
- διερευνήσει
- άκρο
- Πρόσωπο
- Χαρακτηριστικό
- Όνομα
- ακολουθήστε
- Εξής
- μορφή
- από
- παράγεται
- Στόχοι
- καλός
- γκρί
- εξαιρετική
- ευτυχισμένος
- βοήθησε
- βοήθεια
- βοηθά
- υψηλής ποιότητας
- φιλοξενείται
- Πως
- Πώς να
- HTTPS
- ανθρώπινος
- Οι άνθρωποι
- Εκατοντάδες
- εικόνα
- εικόνες
- εφαρμογή
- βελτίωση
- περιλαμβάνουν
- περιλαμβάνονται
- Αυξάνουν
- ευρετήριο
- βιομηχανίες
- πληροφορίες
- εισαγωγή
- παράδειγμα
- περιβάλλον λειτουργίας
- διασταύρωση
- εισάγοντας
- IT
- Δουλειά
- Θέσεις εργασίας
- γνωστός
- επιγραφή
- τιτλοφόρηση
- Ετικέτες
- large
- ξεκινήσει
- ΜΑΘΑΊΝΩ
- μάθηση
- Επίπεδο
- Περιωρισμένος
- γραμμή
- γραμμές
- Λίστα
- τοπικός
- τοποθεσία
- θέσεις
- Μακριά
- ματιά
- μηχανή
- μάθηση μηχανής
- διαχείριση
- υποχρεωτικό
- χειροκίνητα
- κατασκευής
- χάρτη
- χαρτης
- μάσκα
- Masks
- μαζική
- μηχανικός
- ενδέχεται να
- ML
- μοντέλο
- μοντέλα
- περισσότερο
- πολλαπλούς
- ονόματα
- ονοματοδοσία
- Πλοήγηση
- δίκτυο
- δίκτυα
- επόμενη
- σημειωματάριο
- αριθμός
- προσφορές
- Επιλογή
- Επιλογές
- οργανώσεις
- ΑΛΛΑ
- δική
- παθιασμένος
- τοις εκατό
- εκτέλεση
- σημεία
- Πολύγωνο
- Δημοφιλής
- Προετοιμάστε
- αρκετά
- τιμή
- ιδιωτικός
- διαδικασια μας
- παράγει
- επαγγελματίας
- παρέχουν
- παρέχει
- δημόσιο
- σκοποί
- γρήγορα
- RE
- αρχεία
- εκπροσωπώ
- απαιτείται
- Απαιτεί
- Αποτελέσματα
- ανασκόπηση
- ίδιο
- επεκτάσιμη
- Επιστήμονας
- ΘΆΛΑΣΣΑ
- κατάτμηση
- επιλέγονται
- υπηρεσία
- Υπηρεσίες
- σειρά
- τον καθορισμό
- Κοινοποίηση
- δείχνουν
- παρουσιάζεται
- Απλούς
- κατάσταση
- small
- So
- λογισμικό
- Λύσεις
- διαίρεση
- ξεκίνησε
- χώρος στο δίσκο
- Βιωσιμότητα
- στόχος
- εργασίες
- δοκιμή
- Η
- Η Πηγη
- πράγμα
- τρίτους
- χιλιάδες
- Μέσω
- διακίνηση
- ώρα
- εργαλείο
- Τρένο
- Εκπαίδευση
- Μεταμορφώστε
- ένωση
- χρήση
- επικύρωση
- πωλητές
- όραμα
- Ο ΟΠΟΊΟΣ
- Εργασία
- εργαζομένων
- Εργατικό δυναμικό
- λειτουργεί
- Σας