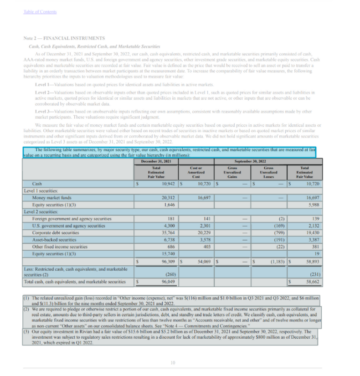
Όταν OpenAI κυκλοφόρησε την τρίτη γενιά του μοντέλου μηχανικής εκμάθησης (ML) που ειδικεύεται στη δημιουργία κειμένου τον Ιούλιο του 2020, ήξερα ότι κάτι ήταν διαφορετικό. Αυτό το μοντέλο χτύπησε ένα νεύρο όπως κανένας άλλος πριν από αυτό. Ξαφνικά άκουσα φίλους και συναδέλφους, που μπορεί να ενδιαφέρονται για την τεχνολογία, αλλά συνήθως δεν ενδιαφέρονται πολύ για τις τελευταίες εξελίξεις στον χώρο AI/ML, να μιλούν γι' αυτό. Έγραψε ακόμη και ο Guardian ένα άρθρο σχετικά με αυτό. Ή, για την ακρίβεια, το μοντέλο έγραψε το άρθρο και ο Guardian το επιμελήθηκε και το δημοσίευσε. Δεν υπήρχε αμφιβολία - GPT-3 ήταν μια αλλαγή παιχνιδιού.
Μετά την κυκλοφορία του μοντέλου, οι άνθρωποι άρχισαν αμέσως να βρίσκουν πιθανές εφαρμογές για αυτό. Μέσα σε λίγες εβδομάδες, δημιουργήθηκαν πολλά εντυπωσιακά demo, τα οποία μπορείτε να βρείτε στο Ιστότοπος GPT-3. Μια συγκεκριμένη εφαρμογή που τράβηξε το μάτι μου ήταν σύνοψη κειμένου – την ικανότητα ενός υπολογιστή να διαβάζει ένα δεδομένο κείμενο και να συνοψίζει το περιεχόμενό του. Είναι μια από τις πιο δύσκολες εργασίες για έναν υπολογιστή, επειδή συνδυάζει δύο πεδία στο πεδίο της επεξεργασίας φυσικής γλώσσας (NLP): την κατανόηση ανάγνωσης και τη δημιουργία κειμένου. Αυτός είναι ο λόγος που εντυπωσιάστηκα τόσο πολύ από τις επιδείξεις του GPT-3 για τη σύνοψη κειμένου.
Μπορείτε να τους δοκιμάσετε Ιστότοπος Hugging Face Spaces. Το αγαπημένο μου αυτή τη στιγμή είναι ένα εφαρμογή που δημιουργεί περιλήψεις ειδήσεων με μόνο τη διεύθυνση URL του άρθρου ως είσοδο.
Σε αυτήν τη σειρά δύο μερών, προτείνω έναν πρακτικό οδηγό για οργανισμούς, ώστε να μπορείτε να αξιολογήσετε την ποιότητα των μοντέλων σύνοψης κειμένου για τον τομέα σας.
Επισκόπηση φροντιστηρίου
Πολλοί οργανισμοί με τους οποίους συνεργάζομαι (φιλανθρωπικά ιδρύματα, εταιρείες, ΜΚΟ) έχουν τεράστιους όγκους κειμένων που πρέπει να διαβάσουν και να συνοψίσουν - οικονομικές εκθέσεις ή άρθρα ειδήσεων, επιστημονικές ερευνητικές εργασίες, αιτήσεις για διπλώματα ευρεσιτεχνίας, νομικές συμβάσεις και πολλά άλλα. Φυσικά, αυτοί οι οργανισμοί ενδιαφέρονται να αυτοματοποιήσουν αυτές τις εργασίες με την τεχνολογία NLP. Για να δείξω την τέχνη του δυνατού, χρησιμοποιώ συχνά τα demos σύνοψης κειμένου, τα οποία σχεδόν ποτέ δεν παραλείπουν να εντυπωσιάσουν.
Αλλά τώρα τι;
Η πρόκληση για αυτούς τους οργανισμούς είναι ότι θέλουν να αξιολογήσουν μοντέλα σύνοψης κειμένων με βάση περιλήψεις για πολλά, πολλά έγγραφα – όχι ένα κάθε φορά. Δεν θέλουν να προσλάβουν έναν ασκούμενο του οποίου η μόνη δουλειά είναι να ανοίξει την εφαρμογή, να επικολλήσει ένα έγγραφο, να χτυπήσει το Συνοψίστε κουμπί, περιμένετε για την έξοδο, αξιολογήστε εάν η περίληψη είναι καλή και κάντε το ξανά για χιλιάδες έγγραφα.
Έγραψα αυτό το σεμινάριο έχοντας στο μυαλό μου τον προηγούμενο εαυτό μου πριν από τέσσερις εβδομάδες – είναι το σεμινάριο που θα ήθελα να είχα τότε όταν ξεκίνησα αυτό το ταξίδι. Υπό αυτή την έννοια, το κοινό-στόχος αυτού του σεμιναρίου είναι κάποιος που είναι εξοικειωμένος με την AI/ML και έχει χρησιμοποιήσει μοντέλα Transformer στο παρελθόν, αλλά βρίσκεται στην αρχή του ταξιδιού σύνοψης κειμένου και θέλει να εμβαθύνει σε αυτό. Επειδή είναι γραμμένο από έναν "αρχάριο" και για αρχάριους, θέλω να τονίσω το γεγονός ότι αυτό το σεμινάριο είναι a πρακτικός οδηγός – όχι ο πρακτικός οδηγός. Παρακαλώ να το αντιμετωπίσετε σαν να George EP Box είχε πει:
![]()
Όσον αφορά το πόσες τεχνικές γνώσεις απαιτούνται σε αυτό το σεμινάριο: Περιλαμβάνει όντως κάποια κωδικοποίηση στην Python, αλλά τις περισσότερες φορές χρησιμοποιούμε απλώς τον κώδικα για να καλέσουμε API, επομένως δεν απαιτείται ούτε βαθιά γνώση κωδικοποίησης. Είναι χρήσιμο να είστε εξοικειωμένοι με ορισμένες έννοιες της ML, όπως το τι σημαίνει τρένο και παρατάσσω ένα μοντέλο, οι έννοιες του εκπαίδευση, επικύρωση, να δοκιμαστικά σύνολα δεδομένων, και ούτω καθεξής. Επίσης έχοντας ασχοληθεί με το Βιβλιοθήκη μετασχηματιστών πριν μπορεί να είναι χρήσιμο, επειδή χρησιμοποιούμε αυτή τη βιβλιοθήκη εκτενώς σε αυτό το σεμινάριο. Περιλαμβάνω επίσης χρήσιμους συνδέσμους για περαιτέρω ανάγνωση για αυτές τις έννοιες.
Επειδή αυτό το σεμινάριο είναι γραμμένο από έναν αρχάριο, δεν περιμένω από ειδικούς του NLP και προχωρημένους επαγγελματίες βαθιάς μάθησης να λάβουν μεγάλο μέρος αυτού του σεμιναρίου. Τουλάχιστον όχι από τεχνικής άποψης – ωστόσο, μπορεί να απολαμβάνετε την ανάγνωση, γι' αυτό μην φύγετε ακόμα! Αλλά θα πρέπει να είστε υπομονετικοί όσον αφορά τις απλοποιήσεις μου – προσπάθησα να ζήσω με την ιδέα να κάνω τα πάντα σε αυτό το σεμινάριο όσο το δυνατόν πιο απλά, αλλά όχι πιο απλά.
Δομή αυτού του σεμιναρίου
Αυτή η σειρά εκτείνεται σε τέσσερις ενότητες χωρισμένες σε δύο αναρτήσεις, στις οποίες περνάμε από διαφορετικά στάδια ενός έργου σύνοψης κειμένου. Στην πρώτη ανάρτηση (ενότητα 1), ξεκινάμε εισάγοντας μια μέτρηση για εργασίες σύνοψης κειμένου – ένα μέτρο απόδοσης που μας επιτρέπει να αξιολογήσουμε εάν μια σύνοψη είναι καλή ή κακή. Εισάγουμε επίσης το σύνολο δεδομένων που θέλουμε να συνοψίσουμε και δημιουργούμε μια γραμμή βάσης χρησιμοποιώντας ένα μοντέλο no-ML – χρησιμοποιούμε ένα απλό ευρετικό για να δημιουργήσουμε μια σύνοψη από ένα δεδομένο κείμενο. Η δημιουργία αυτής της γραμμής βάσης είναι ένα ζωτικής σημασίας βήμα σε κάθε έργο ML, επειδή μας δίνει τη δυνατότητα να ποσοτικοποιήσουμε πόση πρόοδο σημειώνουμε χρησιμοποιώντας την τεχνητή νοημοσύνη στο μέλλον. Μας επιτρέπει να απαντήσουμε στην ερώτηση "Αξίζει πραγματικά να επενδύσουμε στην τεχνολογία AI;"
Στη δεύτερη ανάρτηση, χρησιμοποιούμε ένα μοντέλο που έχει ήδη εκπαιδευτεί εκ των προτέρων για τη δημιουργία περιλήψεων (ενότητα 2). Αυτό είναι δυνατό με μια σύγχρονη προσέγγιση στο ML που ονομάζεται μεταφορά της μάθησης. Είναι ένα άλλο χρήσιμο βήμα γιατί βασικά παίρνουμε ένα μοντέλο εκτός ραφιού και το δοκιμάζουμε στο σύνολο δεδομένων μας. Αυτό μας επιτρέπει να δημιουργήσουμε μια άλλη γραμμή βάσης, η οποία μας βοηθά να δούμε τι συμβαίνει όταν εκπαιδεύουμε πραγματικά το μοντέλο στο σύνολο δεδομένων μας. Η προσέγγιση ονομάζεται μηδενική σύνοψη, επειδή το μοντέλο είχε μηδενική έκθεση στο σύνολο δεδομένων μας.
Μετά από αυτό, ήρθε η ώρα να χρησιμοποιήσουμε ένα προεκπαιδευμένο μοντέλο και να το εκπαιδεύσουμε στο δικό μας σύνολο δεδομένων (ενότητα 3). Αυτό λέγεται επίσης τελειοποίηση. Επιτρέπει στο μοντέλο να μάθει από τα μοτίβα και τις ιδιοσυγκρασίες των δεδομένων μας και να προσαρμοστεί σιγά σιγά σε αυτά. Αφού εκπαιδεύσουμε το μοντέλο, το χρησιμοποιούμε για να δημιουργήσουμε περιλήψεις (ενότητα 4).
Για να συνοψίσουμε:
- 1 Μέρος:
- Ενότητα 1: Χρησιμοποιήστε ένα μοντέλο χωρίς ML για να δημιουργήσετε μια γραμμή βάσης
- Μέρος 2:
- Ενότητα 2: Δημιουργήστε περιλήψεις με ένα μοντέλο μηδενικής λήψης
- Ενότητα 3: Εκπαιδεύστε ένα μοντέλο περίληψης
- Ενότητα 4: Αξιολογήστε το εκπαιδευμένο μοντέλο
Ολόκληρος ο κώδικας για αυτό το σεμινάριο είναι διαθέσιμος παρακάτω GitHub repo.
Τι θα έχουμε επιτύχει μέχρι το τέλος αυτού του σεμιναρίου;
Μέχρι το τέλος αυτού του σεμιναρίου, εμείς δεν θα έχουν ένα μοντέλο σύνοψης κειμένου που μπορεί να χρησιμοποιηθεί στην παραγωγή. Δεν θα έχουμε καν ένα καλός μοντέλο σύνοψης (εισάγετε scream emoji εδώ)!
Αυτό που θα έχουμε αντ' αυτού είναι ένα σημείο εκκίνησης για την επόμενη φάση του έργου, που είναι η φάση του πειραματισμού. Εδώ μπαίνει η «επιστήμη» στην επιστήμη δεδομένων, γιατί τώρα το μόνο που χρειάζεται είναι να πειραματιστείτε με διαφορετικά μοντέλα και διαφορετικές ρυθμίσεις για να κατανοήσετε εάν ένα αρκετά καλό μοντέλο περίληψης μπορεί να εκπαιδευτεί με τα διαθέσιμα δεδομένα εκπαίδευσης.
Και, για να είμαστε απολύτως διαφανείς, υπάρχει μεγάλη πιθανότητα το συμπέρασμα να είναι ότι η τεχνολογία απλώς δεν έχει ωριμάσει ακόμα και ότι το έργο δεν θα εφαρμοστεί. Και πρέπει να προετοιμάσετε τα ενδιαφερόμενα μέρη της επιχείρησής σας για αυτή τη δυνατότητα. Αλλά αυτό είναι ένα θέμα για άλλη ανάρτηση.
Ενότητα 1: Χρησιμοποιήστε ένα μοντέλο χωρίς ML για να δημιουργήσετε μια γραμμή βάσης
Αυτή είναι η πρώτη ενότητα του σεμιναρίου μας σχετικά με τη δημιουργία ενός έργου σύνοψης κειμένου. Σε αυτήν την ενότητα, καθιερώνουμε μια γραμμή βάσης χρησιμοποιώντας ένα πολύ απλό μοντέλο, χωρίς να χρησιμοποιούμε στην πραγματικότητα ML. Αυτό είναι ένα πολύ σημαντικό βήμα σε κάθε έργο ML, γιατί μας επιτρέπει να κατανοήσουμε πόση αξία προσθέτει η ML κατά τη διάρκεια του έργου και αν αξίζει να επενδύσουμε σε αυτό.
Μπορείτε να βρείτε τον κωδικό για το σεμινάριο παρακάτω GitHub repo.
Δεδομένα, δεδομένα, δεδομένα
Κάθε έργο ML ξεκινά με δεδομένα! Εάν είναι δυνατόν, θα πρέπει πάντα να χρησιμοποιούμε δεδομένα που σχετίζονται με αυτό που θέλουμε να επιτύχουμε με ένα έργο σύνοψης κειμένου. Για παράδειγμα, εάν ο στόχος μας είναι να συνοψίσουμε τις αιτήσεις για διπλώματα ευρεσιτεχνίας, θα πρέπει επίσης να χρησιμοποιήσουμε αιτήσεις διπλωμάτων ευρεσιτεχνίας για να εκπαιδεύσουμε το μοντέλο. Μια μεγάλη προειδοποίηση για ένα έργο ML είναι ότι τα δεδομένα εκπαίδευσης συνήθως πρέπει να επισημαίνονται. Στο πλαίσιο της σύνοψης κειμένου, αυτό σημαίνει ότι πρέπει να παρέχουμε το κείμενο που πρόκειται να συνοψιστεί καθώς και την περίληψη (την ετικέτα). Μόνο παρέχοντας και τα δύο μπορεί το μοντέλο να μάθει πώς φαίνεται μια καλή περίληψη.
Σε αυτό το σεμινάριο, χρησιμοποιούμε ένα δημοσίως διαθέσιμο σύνολο δεδομένων, αλλά τα βήματα και ο κώδικας παραμένουν ακριβώς τα ίδια εάν χρησιμοποιούμε προσαρμοσμένο ή ιδιωτικό σύνολο δεδομένων. Και πάλι, εάν έχετε στο μυαλό σας έναν στόχο για το μοντέλο σύνοψης κειμένου και έχετε αντίστοιχα δεδομένα, χρησιμοποιήστε τα δεδομένα σας για να αξιοποιήσετε στο έπακρο αυτό.
Τα δεδομένα που χρησιμοποιούμε είναι τα σύνολο δεδομένων arXiv, το οποίο περιέχει περιλήψεις εργασιών arXiv καθώς και τους τίτλους τους. Για το σκοπό μας, χρησιμοποιούμε την περίληψη ως κείμενο που θέλουμε να συνοψίσουμε και τον τίτλο ως περίληψη αναφοράς. Όλα τα βήματα λήψης και προεπεξεργασίας των δεδομένων είναι διαθέσιμα παρακάτω σημειωματάριο. Απαιτούμε ένα Διαχείριση ταυτότητας και πρόσβασης AWS (IAM) ρόλος που επιτρέπει τη φόρτωση δεδομένων από και προς Απλή υπηρεσία αποθήκευσης Amazon (Amazon S3) για να εκτελέσετε αυτό το σημειωματάριο με επιτυχία. Το σύνολο δεδομένων αναπτύχθηκε ως μέρος της εργασίας Σχετικά με τη χρήση του ArXiv ως συνόλου δεδομένων και έχει άδεια σύμφωνα με το Αφιέρωση καθολικού δημόσιου τομέα Creative Commons CC0 1.0.
Τα δεδομένα χωρίζονται σε τρία σύνολα δεδομένων: εκπαίδευση, επικύρωση και δεδομένα δοκιμής. Εάν θέλετε να χρησιμοποιήσετε τα δικά σας δεδομένα, βεβαιωθείτε ότι ισχύει και αυτό. Το παρακάτω διάγραμμα δείχνει πώς χρησιμοποιούμε τα διαφορετικά σύνολα δεδομένων.
![]()
Φυσικά, μια κοινή ερώτηση σε αυτό το σημείο είναι: Πόσα δεδομένα χρειαζόμαστε; Όπως πιθανότατα μπορείτε ήδη να μαντέψετε, η απάντηση είναι: εξαρτάται. Εξαρτάται από το πόσο εξειδικευμένος είναι ο τομέας (η περίληψη των αιτήσεων για διπλώματα ευρεσιτεχνίας διαφέρει αρκετά από τη σύνοψη ειδησεογραφικών άρθρων), πόσο ακριβές πρέπει να είναι το μοντέλο για να είναι χρήσιμο, πόσο θα κοστίσει η εκπαίδευση του μοντέλου κ.λπ. Επιστρέφουμε σε αυτό το ερώτημα αργότερα, όταν εκπαιδεύσουμε πραγματικά το μοντέλο, αλλά το μικρότερο από αυτό είναι ότι πρέπει να δοκιμάσουμε διαφορετικά μεγέθη δεδομένων όταν βρισκόμαστε στη φάση πειραματισμού του έργου.
Τι κάνει ένα καλό μοντέλο;
Σε πολλά έργα ML, η μέτρηση της απόδοσης ενός μοντέλου είναι μάλλον απλή. Αυτό συμβαίνει επειδή συνήθως υπάρχει μικρή ασάφεια σχετικά με το αν το αποτέλεσμα του μοντέλου είναι σωστό. Οι ετικέτες στο σύνολο δεδομένων είναι συχνά δυαδικές (Σωστό/Λάθος, Ναι/Όχι) ή κατηγορικές. Σε κάθε περίπτωση, είναι εύκολο σε αυτό το σενάριο να συγκρίνετε την έξοδο του μοντέλου με την ετικέτα και να την επισημάνετε ως σωστή ή λανθασμένη.
Κατά τη δημιουργία κειμένου, αυτό γίνεται πιο δύσκολο. Οι περιλήψεις (οι ετικέτες) που παρέχουμε στο σύνολο δεδομένων μας είναι μόνο ένας τρόπος για να συνοψίσουμε το κείμενο. Υπάρχουν όμως πολλές δυνατότητες για να συνοψίσουμε ένα δεδομένο κείμενο. Έτσι, ακόμα κι αν το μοντέλο δεν ταιριάζει με την ετικέτα μας 1:1, η έξοδος μπορεί να εξακολουθεί να είναι μια έγκυρη και χρήσιμη περίληψη. Πώς συγκρίνουμε λοιπόν τη σύνοψη του μοντέλου με αυτή που παρέχουμε; Η μέτρηση που χρησιμοποιείται συχνότερα στη σύνοψη κειμένου για τη μέτρηση της ποιότητας ενός μοντέλου είναι η ROUGE σκορ. Για να κατανοήσετε τη μηχανική αυτής της μέτρησης, ανατρέξτε στο Η απόλυτη μέτρηση απόδοσης στο NLP. Συνοπτικά, η βαθμολογία ROUGE μετρά την επικάλυψη n-γραμμάρια (συνεχής ακολουθία του n στοιχεία) μεταξύ της περίληψης του μοντέλου (σύνοψη υποψηφίου) και της περίληψης αναφοράς (η ετικέτα που παρέχουμε στο σύνολο δεδομένων μας). Αλλά, φυσικά, αυτό δεν είναι τέλειο μέτρο. Για να κατανοήσετε τους περιορισμούς του, ρίξτε μια ματιά Σε ROUGE ή όχι σε ROUGE;
Λοιπόν, πώς υπολογίζουμε τη βαθμολογία ROUGE; Υπάρχουν αρκετά πακέτα Python εκεί έξω για τον υπολογισμό αυτής της μέτρησης. Για να διασφαλίσουμε τη συνέπεια, θα πρέπει να χρησιμοποιούμε την ίδια μέθοδο σε όλο το έργο μας. Επειδή, σε μεταγενέστερο σημείο αυτού του σεμιναρίου, θα χρησιμοποιήσουμε ένα σενάριο εκπαίδευσης από τη βιβλιοθήκη Transformers αντί να γράφουμε το δικό μας, μπορούμε απλώς να κοιτάξουμε πρωτογενής κώδικας του σεναρίου και αντιγράψτε τον κώδικα που υπολογίζει τη βαθμολογία ROUGE:
Χρησιμοποιώντας αυτή τη μέθοδο για τον υπολογισμό της βαθμολογίας, διασφαλίζουμε ότι συγκρίνουμε πάντα μήλα με μήλα σε όλο το έργο.
Αυτή η συνάρτηση υπολογίζει αρκετές βαθμολογίες ROUGE: rouge1, rouge2, rougeL, να rougeLsum. Το «άθροισμα» σε rougeLsum αναφέρεται στο γεγονός ότι αυτή η μέτρηση υπολογίζεται σε μια ολόκληρη περίληψη, ενώ rougeL υπολογίζεται ως ο μέσος όρος για μεμονωμένες προτάσεις. Λοιπόν, ποια βαθμολογία ROUGE πρέπει να χρησιμοποιήσουμε για το έργο μας; Και πάλι, πρέπει να δοκιμάσουμε διαφορετικές προσεγγίσεις στη φάση του πειραματισμού. Για ό,τι αξίζει, το πρωτότυπο χαρτί ROUGE δηλώνει ότι «Το ROUGE-2 και το ROUGE-L λειτούργησαν καλά σε εργασίες σύνοψης μεμονωμένων εγγράφων», ενώ «Το ROUGE-1 και το ROUGE-L έχουν εξαιρετική απόδοση στην αξιολόγηση σύντομων περιλήψεων».
Δημιουργήστε τη γραμμή βάσης
Στη συνέχεια θέλουμε να δημιουργήσουμε τη γραμμή βάσης χρησιμοποιώντας ένα απλό μοντέλο χωρίς ML. Τι σημαίνει αυτό? Στον τομέα της σύνοψης κειμένων, πολλές μελέτες χρησιμοποιούν μια πολύ απλή προσέγγιση: λαμβάνουν την πρώτη n προτάσεις του κειμένου και να το χαρακτηρίσετε ως υποψήφιο περίληψη. Στη συνέχεια συγκρίνουν την περίληψη του υποψηφίου με την περίληψη αναφοράς και υπολογίζουν τη βαθμολογία ROUGE. Αυτή είναι μια απλή αλλά ισχυρή προσέγγιση που μπορούμε να εφαρμόσουμε σε λίγες γραμμές κώδικα (όλος ο κώδικας για αυτό το μέρος βρίσκεται παρακάτω σημειωματάριο):
Χρησιμοποιούμε το σύνολο δεδομένων δοκιμής για αυτήν την αξιολόγηση. Αυτό είναι λογικό γιατί αφού εκπαιδεύσουμε το μοντέλο, χρησιμοποιούμε επίσης το ίδιο σύνολο δεδομένων δοκιμής για την τελική αξιολόγηση. Δοκιμάζουμε επίσης διαφορετικούς αριθμούς για n: ξεκινάμε μόνο με την πρώτη πρόταση ως υποψήφια περίληψη, μετά τις δύο πρώτες προτάσεις και τέλος τις τρεις πρώτες προτάσεις.
Το παρακάτω στιγμιότυπο οθόνης δείχνει τα αποτελέσματα για το πρώτο μας μοντέλο.
![]()
Οι βαθμολογίες ROUGE είναι οι υψηλότερες, με μόνο την πρώτη πρόταση ως περίληψη του υποψηφίου. Αυτό σημαίνει ότι η λήψη περισσότερων από μία προτάσεων καθιστά την περίληψη υπερβολικά περιεκτική και οδηγεί σε χαμηλότερη βαθμολογία. Αυτό σημαίνει ότι θα χρησιμοποιήσουμε τις βαθμολογίες για τις περιλήψεις μιας πρότασης ως βάση μας.
Είναι σημαντικό να σημειωθεί ότι, για μια τόσο απλή προσέγγιση, αυτοί οι αριθμοί είναι στην πραγματικότητα αρκετά καλοί, ειδικά για τους rouge1 σκορ. Για να βάλουμε αυτούς τους αριθμούς στο πλαίσιο, μπορούμε να αναφερθούμε Μοντέλα Pegasus, το οποίο δείχνει τις βαθμολογίες ενός μοντέλου τελευταίας τεχνολογίας για διαφορετικά σύνολα δεδομένων.
Συμπέρασμα και τι ακολουθεί
Στο Μέρος 1 της σειράς μας, παρουσιάσαμε το σύνολο δεδομένων που χρησιμοποιούμε σε όλο το έργο περίληψης, καθώς και μια μέτρηση για την αξιολόγηση των περιλήψεων. Στη συνέχεια δημιουργήσαμε την ακόλουθη γραμμή βάσης με ένα απλό μοντέλο χωρίς ML.
![]()
Στο επόμενη θέση, χρησιμοποιούμε ένα μοντέλο μηδενικής λήψης – συγκεκριμένα, ένα μοντέλο που έχει εκπαιδευτεί ειδικά για σύνοψη κειμένων σε δημόσια άρθρα ειδήσεων. Ωστόσο, αυτό το μοντέλο δεν θα εκπαιδευτεί καθόλου στο σύνολο δεδομένων μας (εξ ου και το όνομα "zero-shot").
Το αφήνω σε εσάς ως εργασία να μαντέψετε πώς θα αποδώσει αυτό το μοντέλο μηδενικής λήψης σε σύγκριση με την πολύ απλή γραμμή βάσης μας. Από τη μία πλευρά, θα είναι ένα πολύ πιο εξελιγμένο μοντέλο (στην πραγματικότητα είναι ένα νευρωνικό δίκτυο). Από την άλλη πλευρά, χρησιμοποιείται μόνο για τη σύνοψη άρθρων ειδήσεων, επομένως μπορεί να δυσκολεύεται με τα μοτίβα που είναι εγγενή στο σύνολο δεδομένων arXiv.
Σχετικά με το Συγγραφέας
![]() Heiko Hotz είναι Senior Solutions Architect για AI & Machine Learning και ηγείται της κοινότητας Επεξεργασίας Φυσικής Γλώσσας (NLP) εντός του AWS. Πριν από αυτόν τον ρόλο, ήταν επικεφαλής της Επιστήμης Δεδομένων για την Εξυπηρέτηση Πελατών στην ΕΕ της Amazon. Η Heiko βοηθά τους πελάτες μας να είναι επιτυχημένοι στο ταξίδι τους AI/ML στο AWS και έχει συνεργαστεί με οργανισμούς σε πολλούς κλάδους, όπως Ασφάλειες, Χρηματοοικονομικές Υπηρεσίες, Μέσα και Ψυχαγωγία, Υγεία, Υπηρεσίες κοινής ωφελείας και Βιομηχανία. Στον ελεύθερο χρόνο του ο Heiko ταξιδεύει όσο περισσότερο μπορεί.
Heiko Hotz είναι Senior Solutions Architect για AI & Machine Learning και ηγείται της κοινότητας Επεξεργασίας Φυσικής Γλώσσας (NLP) εντός του AWS. Πριν από αυτόν τον ρόλο, ήταν επικεφαλής της Επιστήμης Δεδομένων για την Εξυπηρέτηση Πελατών στην ΕΕ της Amazon. Η Heiko βοηθά τους πελάτες μας να είναι επιτυχημένοι στο ταξίδι τους AI/ML στο AWS και έχει συνεργαστεί με οργανισμούς σε πολλούς κλάδους, όπως Ασφάλειες, Χρηματοοικονομικές Υπηρεσίες, Μέσα και Ψυχαγωγία, Υγεία, Υπηρεσίες κοινής ωφελείας και Βιομηχανία. Στον ελεύθερο χρόνο του ο Heiko ταξιδεύει όσο περισσότερο μπορεί.
- Coinsmart. Το καλύτερο ανταλλακτήριο Bitcoin και Crypto στην Ευρώπη.
- Platoblockchain. Web3 Metaverse Intelligence. Ενισχύθηκε η γνώση. ΕΛΕΥΘΕΡΗ ΠΡΟΣΒΑΣΗ.
- CryptoHawk. Ραντάρ Altcoin. Δωρεάν δοκιμή.
- Πηγή: https://aws.amazon.com/blogs/machine-learning/part-1-set-up-a-text-summarization-project-with-hugging-face-transformers/
- '
- "
- &
- 100
- 2020
- Σχετικά
- ΠΕΡΙΛΗΨΗ
- πρόσβαση
- ακριβής
- επιτευχθεί
- προηγμένες
- εξελίξεις
- AI
- Όλα
- ήδη
- Amazon
- Ασάφεια
- Ποσά
- Άλλος
- APIs
- Εφαρμογή
- εφαρμογές
- πλησιάζω
- γύρω
- Τέχνη
- άρθρο
- εμπορεύματα
- ακροατήριο
- διαθέσιμος
- μέσος
- AWS
- Baseline
- Βασικα
- Αρχή
- είναι
- επιχείρηση
- κλήση
- ο οποίος
- αλιεύονται
- πρόκληση
- κωδικός
- Κωδικοποίηση
- Κοινός
- κοινότητα
- Εταιρείες
- σύγκριση
- εντελώς
- Υπολογίστε
- έννοια
- Περιέχει
- περιεχόμενο
- συμβάσεις
- δημιουργία
- έθιμο
- Εξυπηρέτηση πελατών
- Πελάτες
- ημερομηνία
- επιστημονικά δεδομένα
- βαθύτερη
- αναπτύχθηκε
- διαφορετικές
- έγγραφα
- Όχι
- τομέα
- Ψυχαγωγία
- ειδικά
- εγκαθιδρύω
- EU
- πάντα
- παράδειγμα
- αναμένω
- εμπειρογνώμονες
- μάτι
- Πρόσωπο
- Πεδία
- Τελικά
- οικονομικός
- των χρηματοπιστωτικών υπηρεσιών
- Όνομα
- Εξής
- Προς τα εμπρός
- Βρέθηκαν
- λειτουργία
- περαιτέρω
- παιχνίδι
- παράγουν
- γενεά
- γκολ
- μετάβαση
- καλός
- εξαιρετική
- κηδεμόνας
- καθοδηγήσει
- που έχει
- κεφάλι
- υγειονομική περίθαλψη
- χρήσιμο
- βοηθά
- εδώ
- ενοικίαση
- Πως
- HTTPS
- τεράστιος
- Ταυτότητα
- εφαρμογή
- εφαρμοστεί
- σημαντικό
- περιλαμβάνουν
- Συμπεριλαμβανομένου
- ατομικές
- βιομηχανίες
- ασφάλιση
- εισάγοντας
- επενδύοντας
- IT
- Δουλειά
- Ιούλιος
- Κλειδί
- γνώση
- Ετικέτες
- Γλώσσα
- αργότερο
- Οδηγεί
- ΜΑΘΑΊΝΩ
- μάθηση
- Άδεια
- Νομικά
- Βιβλιοθήκη
- Άδεια
- ΣΥΝΔΕΣΜΟΙ
- λίγο
- μηχανή
- μάθηση μηχανής
- ΚΑΝΕΙ
- Κατασκευή
- κατασκευής
- σημάδι
- Ταίριασμα
- μέτρο
- Εικόνες / Βίντεο
- νου
- ML
- μοντέλο
- μοντέλα
- περισσότερο
- πλέον
- Φυσικό
- δίκτυο
- νέα
- σημειωματάριο
- αριθμοί
- ανοίξτε
- τάξη
- οργανώσεις
- ΑΛΛΑ
- Χαρτί
- ευρεσιτεχνία
- People
- επίδοση
- προοπτική
- φάση
- Σημείο
- δυνατότητες
- δυνατότητα
- δυνατός
- Δημοσιεύσεις
- δυναμικού
- ισχυρός
- ιδιωτικός
- παραγωγή
- σχέδιο
- έργα
- προτείνω
- παρέχουν
- χορήγηση
- δημόσιο
- σκοπός
- ποιότητα
- ερώτηση
- σειρά
- RE
- Ανάγνωση
- Εκθέσεις
- απαιτούν
- απαιτείται
- έρευνα
- Αποτελέσματα
- τρέξιμο
- Είπε
- Επιστήμη
- αίσθηση
- Σειρές
- υπηρεσία
- Υπηρεσίες
- σειρά
- τον καθορισμό
- Κοντά
- Απλούς
- So
- Λύσεις
- Κάποιος
- κάτι
- εξελιγμένα
- Χώρος
- χώρων
- ειδικευμένος
- ειδικεύεται
- ειδικά
- διαίρεση
- Εκκίνηση
- ξεκίνησε
- ξεκινά
- state-of-the-art
- Μελών
- χώρος στο δίσκο
- στρες
- μελέτες
- επιτυχής
- Επιτυχώς
- Συζήτηση
- στόχος
- εργασίες
- Τεχνικός
- Τεχνολογία
- δοκιμή
- χιλιάδες
- Μέσω
- παντού
- ώρα
- Τίτλος
- Εκπαίδευση
- διαφανής
- θεραπεία
- τελικός
- καταλαβαίνω
- Παγκόσμιος
- us
- χρήση
- συνήθως
- αξία
- περιμένετε
- Τι
- αν
- Ο ΟΠΟΊΟΣ
- Wikipedia
- εντός
- χωρίς
- Εργασία
- εργάστηκαν
- αξία
- γραφή
- X
- μηδέν