Introducción
Imagina un mundo donde grandes modelos de lenguaje (LLM) pueden tejer narrativas a la perfección, traducir idiomas sobre la marcha y responder sus preguntas con un contexto que se extiende más allá del mensaje. Ésta es la promesa de los sumideros de atención, un método revolucionario que desbloquea una generación infinita de LLM.
OBJETIVOS DE APRENDIZAJE
- Reconocer los desafíos asociados con las largas conversaciones utilizando LLM tradicionales.
- Comprender el concepto de sumideros de atención y su papel a la hora de abordar la sobrecarga de memoria y la comprensión limitada.
- Explorar los beneficios de los sumideros de atención, incluida la eficiencia de la memoria, el ahorro computacional y la fluidez mejorada.
- Comprender los detalles de implementación de los sumideros de atención, particularmente en combinación con el caché KV continuo.
- Aprender cómo los captadores de atención se integran perfectamente con las arquitecturas de transformadores existentes.
- Obtener conocimientos prácticos sobre la transmisión de resultados de LLM con receptores de atención.
- Reconocer aplicaciones del mundo real de generación infinita, como chatbots de streaming, traducción en tiempo real y narraciones abiertas.
Tabla de contenidos.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
¿Qué son los sumideros de atención?
Usar modelos de lenguaje grandes (LLM) para conversaciones en curso (como chatbots) es excelente, pero presenta dos problemas:
- Sobrecarga de memoria
- Comprensión limitada
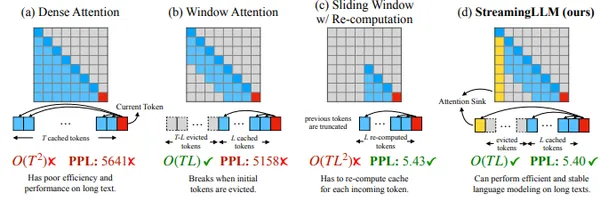
Una solución común llamada "atención de ventana" solo almacena palabras recientes, pero falla en conversaciones largas.
Información clave del resumen de la investigación: Los modelos de lenguaje grandes (LLM, por sus siglas en inglés) con frecuencia prestan excesiva atención a los tokens iniciales, comportándose como un "sumidero", incluso cuando esas palabras carecen de importancia crítica. Una solución propuesta implica retener estas primeras palabras en la memoria, lo que lleva a una mejora notable en el rendimiento de los LLM, particularmente cuando se utiliza la atención de ventana.
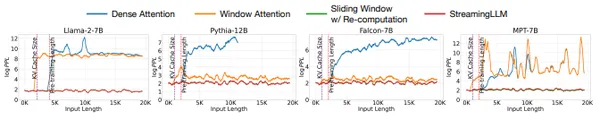
Esto abre la puerta al uso eficaz de los LLM en conversaciones largas y fluidas sin necesidad de toneladas de memoria. En resumen, los LLM tradicionales, como Transformers, tienen dificultades con secuencias largas. Prestan atención rigurosa a cada palabra, lo que genera cuellos de botella en la memoria y resultados torpes, sin contexto o alucinaciones. Los sumideros de atención ofrecen un cambio de paradigma.
Piensa en hundir una piedra en un estanque. Las ondas se extendieron hacia afuera, influyendo en el área circundante. De manera similar, los receptores de atención son palabras clave ubicadas estratégicamente que absorben el enfoque del LLM. Estas "anclas" contienen información crucial, lo que permite que el modelo procese y genere texto de manera eficiente sin perderse en la gran cantidad de palabras.
Beneficios de los sumideros de atención
- Eficiencia de la memoria: Los sumideros de atención reducen drásticamente el uso de memoria, lo que permite a los LLM manejar secuencias mucho más largas. ¡Imagínese generar capítulos de una novela sin olvidar nunca la trama!
- Ahorros computacionales: Al centrarse en puntos clave, la potencia de procesamiento del LLM se optimiza enormemente. Esto se traduce en una generación más rápida y un menor consumo de energía, ideal para aplicaciones en tiempo real.
- Fluidez mejorada: Los receptores de atención garantizan el conocimiento del contexto incluso en escenarios abiertos. El LLM conserva la esencia de interacciones anteriores, lo que conduce a diálogos y narrativas más coherentes, contextuales y que suenan naturales.
- Versátil y adaptable a diferentes esquemas de codificación. Funciona con LLM existentes sin reentrenamiento, ahorrando tiempo y recursos
En general, Streaming LLM ofrece una solución práctica y eficiente para liberar el poder de los LLM en interacciones abiertas en tiempo real.
Caché KW rodante con disipadores de atención
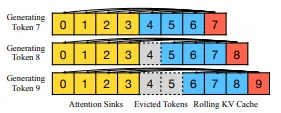
La idea clave es combinar dos cachés de memoria:
- Sumideros de atención: contienen algunos tokens iniciales (alrededor de cuatro) y sus estados clave-valor (KV). Estos actúan como anclas, estabilizando el mecanismo de atención incluso cuando el resto de la conversación sale del caché principal.
- Caché KV rodante: contiene los tokens más recientes de manera similar a la atención de ventana tradicional.
Lo crucial para Streaming LLM es cómo maneja la información posicional:
- En lugar de hacer referencia a posiciones en el texto original, utiliza posiciones relativas dentro del caché combinado.
- Esto garantiza que el modelo comprenda las relaciones entre los tokens incluso mientras fluye la conversación.
- Para esquemas de codificación específicos como RoPE y ALiBi, Streaming LLM adapta sus métodos de almacenamiento en caché y transformación de posición para una integración perfecta.
Para mayor comprensión consulte aquí.
Profundicemos en la implementación
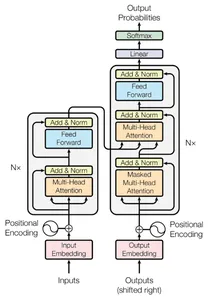
Los módulos receptores de atención se integran perfectamente con las arquitecturas de transformadores, ofreciendo una solución fácil de usar para transmitir modelos de lenguaje de gran tamaño. Su naturaleza plug-and-play le permite aprovechar sus beneficios con el mínimo esfuerzo. He aquí un vistazo de cómo encaja el módulo de captación de atención:
- Transformador existente: Imagine la configuración de su transformador estándar.
- Adición del disipador de atención: Introduzca el módulo del disipador de atención junto al transformador. Actúa como un banco de memoria dedicado, que conserva esos tokens iniciales cruciales.
- Atención mejorada: durante la decodificación, el transformador aprovecha tanto el caché continuo (tokens recientes) como el sumidero de atención (anclas tempranas). Esto estabiliza el mecanismo de atención para diálogos más largos.
Recuerde, los módulos de captación de atención requieren cambios mínimos de código, lo que los convierte en una actualización de bajo esfuerzo y alto impacto para las necesidades de transmisión de LLM.
import torch
from transformers import AutoTokenizer, TextStreamer, GenerationConfig
from attention_sinks import AutoModelForCausalLM model_id = "mistralai/Mistral-7B-v0.1" # Load the chosen model and corresponding tokenizer
model = AutoModelForCausalLM.from_pretrained( model_id, # for efficiency: device_map="auto", torch_dtype=torch.float16, # `attention_sinks`-specific arguments: attention_sink_size=4, attention_sink_window_size=252, # <- Low for the sake of faster generation
)
model.eval()
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token_id = tokenizer.eos_token_id # Our input text
text = "Data Science Blogathon - 39" # Encode the text
input_ids = tokenizer.encode(text, return_tensors="pt").to(model.device) with torch.no_grad(): # A TextStreamer prints tokens as they're being generated streamer = TextStreamer(tokenizer) generated_tokens = model.generate( input_ids, generation_config=GenerationConfig( # use_cache=True is required, the rest can be changed up. use_cache=True, min_new_tokens=100_000, max_new_tokens=1_000_000, penalty_alpha=0.6, top_k=5, pad_token_id=tokenizer.pad_token_id, eos_token_id=tokenizer.eos_token_id, ), streamer=streamer, ) # Decode the final generated text output_text = tokenizer.decode(generated_tokens[0], skip_special_tokens=True)t csvStreaming
Veamos cómo podemos transmitir la salida del LLM utilizando el receptor de atención. Usaremos el script “https://github.com/tomaarsen/attention_sinks/blob/main/demo/streaming.py".
import argparse
from pathlib import Path
from typing import Any, Dict, List import torch
from datasets import Dataset, load_dataset
from transformers import ( AutoTokenizer, PreTrainedModel, PreTrainedTokenizer,
)
from utils import FileStreamerdef create_prompts(samples: Dict[str, List[Any]]) -> Dict[str, Any]: return {"prompt": [prompt for prompts in samples["prompt"] for prompt in prompts]} @torch.no_grad()
def greedy_generate( model: PreTrainedModel, tokenizer: PreTrainedTokenizer, dataset: Dataset, log_file: str, max_new_tokens: int = 1000
): streamer = FileStreamer(tokenizer, log_file) past_key_values = None new_line_tokens = tokenizer("nn", return_tensors="pt", add_special_tokens=False).input_ids for prompt_index, prompt in enumerate(dataset["prompt"]): # Use the chat template initially, as it adds the system prompt if the model has one, and then use [INST] and [/INST] if prompt_index: prompt = f"[INST] {prompt} [/INST]" else: prompt = tokenizer.apply_chat_template([{"role": "user", "content": prompt}], tokenize=False) input_ids = tokenizer(prompt, return_tensors="pt").input_ids input_ids = input_ids.to(model.device) streamer.put(input_ids) for _ in range(max_new_tokens): outputs = model(input_ids, past_key_values=past_key_values, use_cache=True) past_key_values = outputs.past_key_values pred_token_idx = outputs.logits[:, -1, :].argmax(dim=-1).unsqueeze(1) streamer.put(pred_token_idx) input_ids = pred_token_idx if pred_token_idx == tokenizer.eos_token_id: break streamer.put(new_line_tokens)La función crear_prompts creará una lista rápida a partir del conjunto de datos. en la funcion codicioso_generar inicializaremos el objeto transmisor que administra fragmentos de texto a medida que se inicializan los tokens y los valores_clave_pasados, luego iteraremos sobre el mensaje, formatea el mensaje con “[INST]” y “[/INST]” para el diálogo transmitido. Tokeniza el mensaje y lo agrega al transmisor. Genera tokens uno por uno usando el modelo, actualizando past_key_values. Se detiene si encuentra el token de fin de oración. Agrega un token de nueva línea para separar los diálogos y volcar la salida prevista al objeto streamer.
En la función principal, configuramos el experimento como lavabos_atencion y puedes cambiar el nombre del modelo en nombre_modelo_o_ruta o si tiene un modelo entrenado, puede indicarle la ruta del modelo. Si desea utilizar su propio conjunto de datos, modifique las funciones responsables de cargar datos y generar mensajes (y create_prompts). Al ejecutar el código se mostrará un flujo continuo de texto generado en su terminal, transmitiendo la salida.
def main(): parser = argparse.ArgumentParser() # Which experiment to run? parser.add_argument( "--experiment", choices=["attention_sinks", "transformers", "windowed"], default="attention_sinks" ) # Model args parser.add_argument("--model_name_or_path", type=str, default="mistralai/Mistral-7B-Instruct-v0.1") parser.add_argument("--revision", type=str, default="main") parser.add_argument("--trust_remote_code", action="store_true") # Dataset args, not recommended to change: parser.add_argument("--dataset_name", type=str, default="HuggingFaceH4/mt_bench_prompts") # Where to log parser.add_argument("--log_file", type=str, default=None) # Window size for windowed and attention_sinks parser.add_argument("--window_size", type=int, default=1024) # Attention Sinks-only settings # Attention Sink window size is calculated with args.window_size - args.attention_sink_size parser.add_argument("--attention_sink_size", type=int, default=4) args = parser.parse_args() # Initialize the model, either via transformers or via attention_sinks if args.experiment == "transformers": from transformers import AutoModelForCausalLM else: from attention_sinks import AutoModelForCausalLM kwargs = {} if args.experiment == "attention_sinks": kwargs = { "attention_sink_size": args.attention_sink_size, "attention_sink_window_size": args.window_size - args.attention_sink_size, # default: 1020 } elif args.experiment == "windowed": kwargs = { "attention_sink_size": 0, "attention_sink_window_size": args.window_size, } model = AutoModelForCausalLM.from_pretrained( args.model_name_or_path, revision=args.revision, trust_remote_code=bool(args.trust_remote_code), torch_dtype=torch.float16, device_map="auto", **kwargs, ) model.eval() tokenizer = AutoTokenizer.from_pretrained(args.model_name_or_path, trust_remote_code=bool(args.trust_remote_code)) tokenizer.pad_token_id = tokenizer.eos_token_id # Set up the dataset dataset = load_dataset(args.dataset_name, split="train") dataset = dataset.map(create_prompts, batched=True, remove_columns=dataset.column_names) log_file = args.log_file or Path("demo") / "streaming_logs" / args.experiment / f"{args.model_name_or_path}.txt" greedy_generate(model, tokenizer, dataset, log_file=log_file) if __name__ == "__main__": main()Aplicaciones de la generación infinita
- Chatbots de transmisión: Imagine un chatbot que recuerda todo su historial de conversaciones y se adapta perfectamente a sus necesidades cambiantes. Los sumideros de atención hacen esto una realidad, permitiendo interacciones enriquecedoras y personalizadas.
- Traducción en tiempo real: Imagínese traducir un discurso en vivo con perfecta precisión, incluso para conversaciones prolongadas. Los disipadores de atención cierran la brecha entre oraciones consecutivas, preservando el contexto para una traducción perfecta.
- Narración abierta: Imagínese escribir el guión de una novela épica, capítulo a capítulo, en el que cada capítulo se basa perfectamente en el anterior. Los captadores de atención desbloquean el potencial de narrativas verdaderamente inmersivas e interconectadas.
Los futuros LLM
Los sumideros de atención no son sólo un salto tecnológico; representan un cambio en la forma en que pensamos sobre los LLM. En lugar de modelos estáticos, ahora podemos concebir los LLM como entidades dinámicas, que aprenden y se adaptan constantemente dentro de un flujo fluido de información.
Esto abre muchas posibilidades:
- Herramientas de escritura colaborativa que entrelazan perfectamente las aportaciones de múltiples usuarios.
- Asistentes educativos personalizados que adaptan sus explicaciones en función de tu estilo y progreso de aprendizaje.
- Socios creativos impulsados por IA que le ayudan a generar ideas.
- Las posibilidades son infinitas y la atención allana el camino para un futuro en el que los LLM no sean solo herramientas, sino colaboradores, compañeros y catalizadores de la creatividad humana.
El campo de los sumideros de atención está evolucionando rápidamente. Si está interesado en explorar este apasionante avance, aquí tiene algunos recursos:
Conclusión
En conclusión, los sumideros de atención representan una solución innovadora a los desafíos que enfrentan los grandes modelos lingüísticos al manejar conversaciones largas y dinámicas. La implementación de sumideros de atención, junto con la caché KV continua, permite a los LLM operar de manera eficiente en escenarios en tiempo real, ofreciendo beneficios como una menor huella de memoria y una mejor comprensión contextual.
Puntos clave
- Cambio de paradigma: los sumideros de atención marcan un cambio de paradigma en las capacidades de los LLM, transformándolos de modelos estáticos a entidades dinámicas adaptables a flujos de información fluidos.
- Aplicaciones prácticas: la generación infinita facilitada por receptores de atención abre la puerta a aplicaciones prácticas, incluidos chatbots personalizados, traducción en tiempo real y narraciones inmersivas.
- Posibilidades futuras: los sumideros de atención allanan el camino para herramientas de escritura colaborativa, asistentes educativos personalizados y socios creativos impulsados por inteligencia artificial, lo que señala un futuro en el que los LLM contribuirán activamente a la creatividad humana.
- Exploración de recursos: se anima a los lectores a explorar recursos adicionales, incluidas publicaciones de blogs, artículos de investigación e implementaciones de código abierto, para mantenerse informados sobre el campo en evolución de los sumideros de atención.
Preguntas frecuentes
R. Los receptores de atención son palabras clave ubicadas estratégicamente que actúan como anclas para los LLM durante las conversaciones. Abordan los desafíos de los LLM, como la sobrecarga de memoria y la comprensión limitada, absorbiendo el enfoque del modelo en tokens iniciales cruciales. Esto permite a los LLM procesar y generar texto de manera eficiente sin perderse en secuencias largas.
R. Los sumideros de atención reducen drásticamente la huella de memoria de los LLM, lo que les permite manejar secuencias mucho más largas. Al centrarse estratégicamente en puntos clave, los centros de atención optimizan la potencia de procesamiento de los LLM, lo que resulta en una generación más rápida y un menor consumo de energía. Esto los hace ideales para aplicaciones en tiempo real.
R. Sí, los receptores de atención están diseñados para funcionar perfectamente con los LLM existentes, como Transformers, sin necesidad de volver a capacitarse. Ofrecen una solución plug-and-play que requiere cambios mínimos de código. Esto hace que los fregaderos de atención sean una actualización práctica y eficiente para los LLM, ahorrando tiempo y recursos.
R. Los sumideros de atención representan un cambio en la forma en que percibimos los LLM. Abren posibilidades para entidades dinámicas que aprenden y se adaptan constantemente dentro de un flujo fluido de información. Esta evolución allana el camino para herramientas de escritura colaborativa, asistentes educativos personalizados y socios creativos impulsados por inteligencia artificial, lo que convierte a los LLM en más que simples herramientas, sino en colaboradores y catalizadores de la creatividad humana.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/12/attention-sinks-for-llm/
- :posee
- :es
- :no
- :dónde
- $ UP
- 1
- 12
- 13
- 15%
- 39
- a
- Nuestra Empresa
- RESUMEN
- la exactitud
- Actúe
- activamente
- hechos
- adaptar
- adaptación
- se adapta
- adición
- Adicionales
- dirección
- direccionamiento
- Añade
- Alimentado por IA
- asignar
- Permitir
- permite
- junto al
- an
- Analytics
- Analítica Vidhya
- y
- https://www.youtube.com/watch?v=xB-eutXNUMXJtA&feature=youtu.be
- cualquier
- aplicaciones
- somos
- Reservada
- argumentos
- en torno a
- artículo
- AS
- preguntaron
- asistentes
- asociado
- At
- asistir
- auto
- conciencia
- Banca
- basado
- BE
- "Ser"
- beneficios
- entre
- Más allá de
- Blog
- Entradas De Blog
- blogatón
- ambas
- cuellos de botella
- una lluvia de ideas
- Descanso
- ruptura
- PUENTE
- Construir la
- pero
- by
- cache
- calculado
- , que son
- PUEDEN
- capacidades
- catalizadores
- retos
- el cambio
- cambiado
- Cambios
- cambio
- Capítulo
- capítulos
- chatterbot
- Chatbots
- elegido
- código
- COHERENTE
- colaboración
- colaboradores
- combinación
- combinar
- combinado
- Algunos
- compañeros
- computational
- concepto
- conclusión
- consecutivo
- constantemente
- consumo
- contenido
- contexto
- contextual
- continuo
- contribuir
- Conversación
- conversaciones
- Correspondiente
- acoplado
- Para crear
- Estudio
- creatividad
- crítico
- crucial
- datos
- Ciencia de los datos
- conjuntos de datos
- Descodificación
- a dedicados
- Predeterminado
- De demostración
- diseñado
- detalles
- dispositivo
- Diálogo
- DICT
- una experiencia diferente
- discreción
- Pantalla
- inmersión
- do
- Puerta
- dramáticamente
- arrojar
- durante
- lugar de trabajo dinámico
- cada una
- Temprano en la
- fácil de usar
- educativo
- de manera eficaz
- eficiencia
- eficiente
- eficiente.
- esfuerzo
- ya sea
- más
- permite
- permitiendo
- codificación
- encuentro
- ser dado
- Sin fin
- energía
- Consumo de energía
- mejorado
- Estrategias orientadas
- garantizar
- asegura
- Todo
- entidades
- EPIC
- esencia
- Incluso
- NUNCA
- Cada
- evolución
- evolución
- excesivo
- emocionante
- existente
- experimento
- exploración
- explorar
- Explorar
- extensión
- enfrentado
- facilitado
- falla
- más rápida
- pocos
- campo
- final
- Fluido
- Flujos
- Focus
- enfoque
- Footprint
- formatos
- Digital XNUMXk
- frecuentemente
- Desde
- función
- funciones
- futuras
- brecha
- generar
- generado
- genera
- la generación de
- generación de AHSS
- conseguir
- Donar
- Vislumbrar
- maravillosa
- muy
- innovador
- encargarse de
- Manijas
- Manejo
- Tienen
- ayuda
- esta página
- historia
- mantener
- tenencia
- mantiene
- Cómo
- http
- HTTPS
- humana
- idea
- ideal
- ideas
- if
- imagen
- inmersiva
- Cuentacuentos inmersiva
- implementación
- implementaciones
- importar
- importancia
- mejorar
- in
- Incluye
- influenciando
- información
- informó
- inicial
- posiblemente
- Las opciones de entrada
- entradas
- penetración
- Insights
- integrar
- COMPLETAMENTE
- interacciones
- interconectado
- interesado
- dentro
- introducir
- implica
- IT
- SUS
- solo
- Clave
- las palabras claves
- Falta
- idioma
- Idiomas
- large
- Apellidos
- líder
- Saltar
- APRENDE:
- aprendizaje
- Permíteme
- Apalancamiento
- como
- Limitada
- Lista
- para vivir
- carga
- carga
- log
- Largo
- por más tiempo
- perdido
- Lote
- Baja
- inferior
- Inicio
- para lograr
- HACE
- Realizar
- gestiona
- marca
- mecanismo
- Medios
- Salud Cerebral
- Método
- métodos
- mínimo
- modelo
- modelos
- modificar
- módulo
- Módulos
- más,
- MEJOR DE TU
- mucho más
- múltiples
- nombre
- narrativas
- Naturaleza
- ¿ Necesita ayuda
- necesidad
- Ninguna
- notable
- novela
- ahora
- objeto
- of
- LANZAMIENTO
- que ofrece
- Ofertas
- on
- ONE
- en marcha
- , solamente
- sobre
- habiertos
- de código abierto
- abre
- funcionar
- Optimización
- optimizado
- or
- reconocida por
- nuestros
- salir
- salida
- salidas
- Más de
- EL DESARROLLADOR
- propiedad
- papeles
- paradigma
- parte
- particularmente
- socios
- camino
- pavimentar
- naufragios
- (PDF)
- perfecto
- actuación
- Personalizado
- metido
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- solución plug-and-play
- puntos
- ESTANQUE
- posición
- abiertas
- POSIBILIDADES
- Artículos
- posible
- industria
- Metodología
- Aplicaciones Prácticas
- previsto
- regalos
- conservación
- anterior
- huellas dactilares
- problemas
- tratamiento
- Poder de procesamiento
- Progreso
- PROMETEMOS
- ideas
- propuesto
- publicado
- Preguntas
- rápidamente
- RE
- lectores
- mundo real
- en tiempo real
- Realidad
- reciente
- recomendado
- reducir
- Reducción
- referenciando
- Relaciones
- relativo
- representar
- exigir
- Requisitos
- la investigación
- Recursos
- responsable
- RESTO
- resultante
- retención
- conserva
- reentrenamiento
- volvemos
- revolucionario
- Rico
- ondas
- Función
- Rolling
- Ejecutar
- correr
- sake
- ahorro
- Ahorros
- escenarios
- esquemas
- Ciencia:
- guión
- sin problemas
- ver
- separado
- set
- ajustes
- Configure
- Turno
- En Corto
- mostrado
- similares
- Del mismo modo
- Tamaño
- a medida
- algo
- Fuente
- soluciones y
- habla
- propagación
- estándar
- Zonas
- estático
- quedarse
- STONE
- Paradas
- tiendas
- la narración
- Estratégicamente
- stream
- streaming
- en streaming
- corrientes
- Luchar
- papa
- tal
- Rodeando
- te
- Grifos
- tecnológico
- plantilla
- terminal
- texto
- que
- esa
- La
- El futuro de las
- su
- Les
- luego
- Estas
- ellos
- Pensar
- así
- aquellos
- equipo
- a
- juntos
- ficha
- tokeniza
- Tokens
- TONS
- antorcha
- tradicional
- Entrenar
- entrenado
- transformador
- transformers
- transformadora
- la traducción
- Traducción
- verdaderamente
- dos
- comprensión
- entiende
- desencadenando
- desbloquear
- desbloquea
- actualización
- actualizar
- a
- utilizan el
- usado
- Usuario
- usuarios
- usos
- usando
- Utilizando
- Vasto
- vía
- quieres
- fue
- Camino..
- we
- Acabado
- webp
- ¿
- cuando
- que
- seguirá
- ventana
- dentro de
- sin
- Palabra
- palabras
- Actividades:
- funciona
- mundo
- la escritura
- si
- Usted
- tú
- zephyrnet