“En lugar de centrarse en el código, las empresas deberían centrarse en desarrollar prácticas de ingeniería sistemáticas para mejorar los datos de forma que sean fiables, eficientes y sistemáticas. En otras palabras, las empresas deben pasar de un enfoque centrado en el modelo a un enfoque centrado en los datos”. – Andrew Ng
Un enfoque de IA centrado en datos implica construir sistemas de IA con datos de calidad que involucran la preparación de datos y la ingeniería de características. Esta puede ser una tarea tediosa que implica la recopilación de datos, el descubrimiento, la creación de perfiles, la limpieza, la estructuración, la transformación, el enriquecimiento, la validación y el almacenamiento seguro de los datos.
Wrangler de datos de Amazon SageMaker es un servicio en Estudio Amazon SageMaker que proporciona una solución integral para importar, preparar, transformar, caracterizar y analizar datos con poca o ninguna codificación. Puede integrar un flujo de preparación de datos de Data Wrangler en sus flujos de trabajo de aprendizaje automático (ML) para simplificar el preprocesamiento de datos y la ingeniería de características, llevando la preparación de datos a producción más rápido sin necesidad de crear código PySpark, instalar Apache Spark o activar clústeres.
Para escenarios en los que necesita agregar sus propios scripts personalizados para transformaciones de datos, puede escribir su lógica de transformación en Pandas, PySpark, PySpark SQL. Data Wrangler ahora es compatible con las bibliotecas NLTK y SciPy para crear transformaciones personalizadas para preparar datos de texto para ML y realizar la optimización de restricciones.
Es posible que se encuentre con escenarios en los que tenga que agregar sus propios scripts personalizados para la transformación de datos. Con la capacidad de transformación personalizada de Data Wrangler, puede escribir su lógica de transformación en Pandas, PySpark, PySpark SQL.
En esta publicación, analizamos cómo puede escribir su transformación personalizada en NLTK para preparar datos de texto para ML. También compartiremos algunos ejemplos de transformación de código personalizado utilizando otros marcos comunes como NLTK, NumPy, SciPy y scikit-learn, así como los servicios de IA de AWS. Para el propósito de este ejercicio, usamos el Conjunto de datos del Titanic, un conjunto de datos popular en la comunidad de ML, que ahora se ha agregado como conjunto de datos de muestra dentro de Data Wrangler.
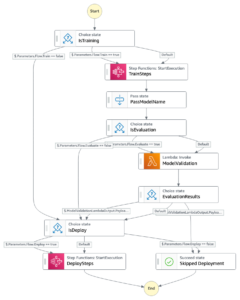
Resumen de la solución
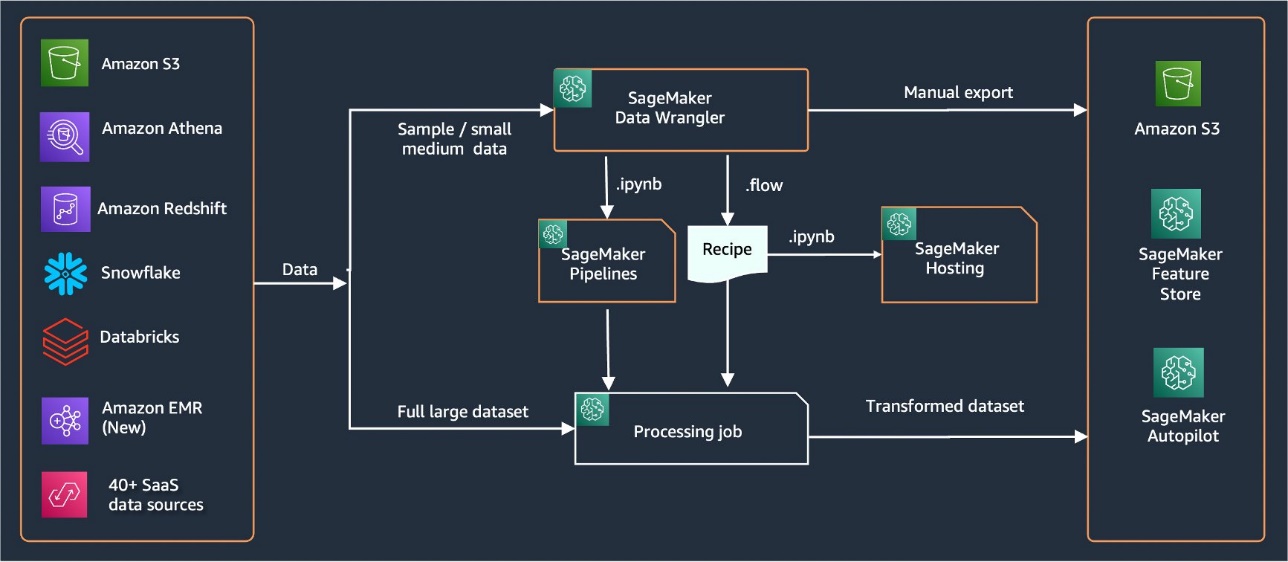
Data Wrangler proporciona más de 40 conectores integrados para importar datos. Después de importar los datos, puede crear su análisis y transformaciones de datos utilizando más de 300 transformaciones integradas. A continuación, puede generar canalizaciones industrializadas para impulsar las características a Servicio de almacenamiento simple de Amazon (Amazon S3) o Tienda de funciones de Amazon SageMaker. El siguiente diagrama muestra la arquitectura de alto nivel de un extremo a otro.
![]()
Requisitos previos
Data Wrangler es una función de SageMaker disponible en Estudio Amazon SageMaker. Puedes seguir el proceso de incorporación de Studio para activar el entorno Studio y los portátiles. Aunque puede elegir entre varios métodos de autenticación, la forma más sencilla de crear un dominio de Studio es seguir las Instrucciones de inicio rápido. El inicio rápido utiliza la misma configuración predeterminada que la configuración estándar de Studio. También puede optar por incorporarse utilizando Centro de identidad de AWS IAM (sucesor de AWS Single Sign-On) para la autenticación (consulte Incorporación al dominio de Amazon SageMaker mediante el centro de identidad de IAM).
Importar el conjunto de datos del Titanic
Inicie su entorno Studio y cree un nuevo Flujo de administrador de datos. Puede importar su propio conjunto de datos o usar un conjunto de datos de muestra (Titanic) como se muestra en la siguiente captura de pantalla. Data Wrangler le permite importar conjuntos de datos de diferentes fuentes de datos. Para nuestro caso de uso, importamos el conjunto de datos de muestra de un depósito S3.
![]()
Una vez importados, verá dos nodos (el nodo de origen y el nodo de tipo de datos) en el flujo de datos. Data Wrangler identifica automáticamente el tipo de datos para todas las columnas del conjunto de datos.
![]()
Transformaciones personalizadas con NLTK
Para la preparación de datos y la ingeniería de funciones con Data Wrangler, puede usar más de 300 transformaciones integradas o crear sus propias transformaciones personalizadas. Transformaciones personalizadas se pueden escribir como pasos separados dentro de Data Wrangler. Se convierten en parte del archivo .flow dentro de Data Wrangler. La función de transformación personalizada admite Python, PySpark y SQL como pasos diferentes en fragmentos de código. Una vez que se generan los archivos de cuaderno (.ipynb) a partir del archivo .flow o el archivo .flow se usa como recetas, los fragmentos de código de transformación personalizados persisten sin necesidad de realizar ningún cambio. Este diseño de Data Wrangler permite que las transformaciones personalizadas se conviertan en parte de un trabajo de procesamiento de SageMaker para procesar conjuntos de datos masivos con transformaciones personalizadas.
El conjunto de datos Titanic tiene un par de características (nombre y home.dest) que contienen información de texto. Usamos NLTK para dividir la columna de nombre y extraer el apellido, e imprimir la frecuencia de los apellidos. NLTK es una plataforma líder para crear programas de Python para trabajar con datos de lenguaje humano. Proporciona interfaces fáciles de usar para más de 50 corpus y recursos léxicos como WordNet, junto con un conjunto de bibliotecas de procesamiento de texto para clasificación, tokenización, derivación, etiquetado, análisis y razonamiento semántico, y envoltorios para bibliotecas de procesamiento de lenguaje natural (NLP) de potencia industrial.
Para agregar una nueva transformación, complete los siguientes pasos:
- Elija el signo más y elija Agregar transformación.
- Elige Añadir paso y elige Transformación personalizada.
Puede crear una transformación personalizada con Pandas, PySpark, funciones definidas por el usuario de Python y SQL PySpark.
![]()
- Elige Python (pandas) y agregue el siguiente código para extraer el apellido de la columna de nombre:
- Elige Vista previa para revisar los resultados.
La siguiente captura de pantalla muestra el last_name columna extraída.
![]()
- Agregue otro paso de transformación personalizado para identificar la distribución de frecuencia de los apellidos, utilizando el siguiente código:
- Elige Vista previa para revisar los resultados de la frecuencia.

Transformaciones personalizadas con servicios de IA de AWS
Los servicios de IA preentrenados de AWS brindan inteligencia preparada para sus aplicaciones y flujos de trabajo. Los servicios de IA de AWS se integran fácilmente con sus aplicaciones para abordar muchos casos de uso comunes. Ahora puede utilizar las capacidades de los servicios de IA de AWS como un paso de transformación personalizado en Data Wrangler.
Amazon Comprehend utiliza NLP para extraer información sobre el contenido de los documentos. Desarrolla conocimientos mediante el reconocimiento de entidades, frases clave, idioma, sentimientos y otros elementos comunes en un documento.
Usamos Amazon Comprehend para extraer las entidades de la columna de nombre. Complete los siguientes pasos:
- Agregue un paso de transformación personalizado.
- Elige Python (pandas).
- Introduzca el siguiente código para extraer las entidades:
- Elige Vista previa y visualizar los resultados.
![]()
Ahora hemos agregado tres transformaciones personalizadas en Data Wrangler.
- Elige Flujo de datos para visualizar el flujo de datos de extremo a extremo.
![]()
Transformaciones personalizadas con NumPy y SciPy
NumPy es una biblioteca de código abierto para Python que ofrece funciones matemáticas integrales, generadores de números aleatorios, rutinas de álgebra lineal, transformadas de Fourier y más. Ciencia es una biblioteca Python de código abierto utilizada para computación científica y computación técnica, que contiene módulos para optimización, álgebra lineal, integración, interpolación, funciones especiales, transformada rápida de Fourier (FFT), procesamiento de señales e imágenes, solucionadores y más.
Las transformaciones personalizadas de Data Wrangler le permiten combinar Python, PySpark y SQL como pasos diferentes. En el siguiente flujo de Data Wrangler, se aplican diferentes funciones de los paquetes de Python, NumPy y SciPy en el conjunto de datos del Titanic en varios pasos.
![]()
Transformaciones numéricas
La columna de tarifas del conjunto de datos del Titanic tiene tarifas de embarque de diferentes pasajeros. El histograma de la columna de tarifa muestra una distribución uniforme, a excepción del último contenedor. Al aplicar transformaciones NumPy como logaritmo o raíz cuadrada, podemos cambiar la distribución (como se muestra en la transformación de raíz cuadrada).
Ver el siguiente código:
Transformaciones SciPy
Las funciones de SciPy como el puntaje z se aplican como parte de la transformación personalizada para estandarizar la distribución de tarifas con media y desviación estándar.
![]()
Ver el siguiente código:
Optimización de restricciones con NumPy y SciPy
Las transformaciones personalizadas de Data Wrangler pueden manejar transformaciones avanzadas como la optimización de restricciones aplicando funciones de optimización de SciPy y combinando SciPy con NumPy. En el siguiente ejemplo, la tarifa en función de la edad no muestra ninguna tendencia observable. Sin embargo, la optimización de restricciones puede transformar la tarifa en función de la edad. La condición de restricción en este caso es que la nueva tarifa total siga siendo la misma que la anterior tarifa total. Las transformaciones personalizadas de Data Wrangler le permiten ejecutar la función de optimización de SciPy para determinar el coeficiente óptimo que puede transformar la tarifa en función de la edad en condiciones de restricción.
La definición de optimización, la definición de objetivos y las restricciones múltiples se pueden mencionar como funciones diferentes al formular la optimización de restricciones en una transformación personalizada de Data Wrangler usando SciPy y NumPy. Las transformaciones personalizadas también pueden traer diferentes métodos de resolución que están disponibles como parte del paquete de optimización de SciPy. Se puede generar una nueva variable transformada multiplicando el coeficiente óptimo con la columna original y añadiéndola a las columnas existentes de Data Wrangler. Ver el siguiente código:
La función de transformación personalizada de Data Wrangler tiene la capacidad de interfaz de usuario para mostrar los resultados de las funciones de optimización de SciPy, como el valor del coeficiente óptimo (o coeficientes múltiples).
![]()
Transformaciones personalizadas con scikit-learn
scikit-aprender es un módulo de Python para el aprendizaje automático construido sobre SciPy. Es una biblioteca ML de código abierto que admite el aprendizaje supervisado y no supervisado. También proporciona varias herramientas para el ajuste de modelos, preprocesamiento de datos, selección de modelos, evaluación de modelos y muchas otras utilidades.
discretización
discretización (de otra manera conocido como cuantización or agrupamiento) proporciona una forma de dividir características continuas en valores discretos. Ciertos conjuntos de datos con características continuas pueden beneficiarse de la discretización, porque la discretización puede transformar el conjunto de datos de atributos continuos en uno con solo atributos nominales. Las características discretizadas codificadas en caliente pueden hacer que un modelo sea más expresivo, manteniendo la interpretabilidad. Por ejemplo, el preprocesamiento con un discretizador puede introducir no linealidad en los modelos lineales.
En el siguiente código, usamos KBinsDiscretizer para discretizar la columna de edad en 10 contenedores:
Puede ver los bordes del contenedor impresos en la siguiente captura de pantalla.
![]()
Codificación one-hot
Los valores de las columnas Embarcados son valores categóricos. Por lo tanto, tenemos que representar estas cadenas como valores numéricos para realizar nuestra clasificación con nuestro modelo. También podríamos hacer esto usando una transformación de codificación one-hot.
Hay tres valores para Embarcado: S, C y Q. Los representamos con números. Ver el siguiente código:
![]()
Limpiar
Cuando no esté utilizando Data Wrangler, es importante cerrar la instancia en la que se ejecuta para evitar incurrir en cargos adicionales.
Data Wrangler guarda automáticamente su flujo de datos cada 60 segundos. Para evitar perder trabajo, guarde su flujo de datos antes de apagar Data Wrangler.
- Para guardar su flujo de datos en Studio, elija Archive, A continuación, elija Guardar flujo de datos Wrangler.
- Para cerrar la instancia de Data Wrangler, en Studio, elija Ejecución de instancias y kernels.
- under APLICACIONES EN EJECUCIÓN, elija el icono de apagado junto a la aplicación sagemaker-data-wrangler-1.0.
- Elige Apagar todo para confirmar.
Data Wrangler se ejecuta en una instancia ml.m5.4xlarge. Esta instancia desaparece de INSTANCIAS EN EJECUCIÓN cuando cierra la aplicación Data Wrangler.
Después de cerrar la aplicación Data Wrangler, debe reiniciarse la próxima vez que abra un archivo de flujo de Data Wrangler. Esto puede tardar unos minutos.
Conclusión
En esta publicación, demostramos cómo puede usar transformaciones personalizadas en Data Wrangler. Utilizamos las bibliotecas y el marco dentro del contenedor de Data Wrangler para ampliar las capacidades de transformación de datos integradas. Los ejemplos en esta publicación representan un subconjunto de los marcos utilizados. Las transformaciones en el flujo de Data Wrangler ahora se pueden escalar en una canalización para DataOps.
Para obtener más información sobre el uso de flujos de datos con Data Wrangler, consulte Crear y usar un flujo de Wrangler de datos y Precios de Amazon SageMaker. Para comenzar con Data Wrangler, consulte Prepare datos de AA con Amazon SageMaker Data Wrangler. Para obtener más información sobre Autopilot y AutoML en SageMaker, visite Automatice el desarrollo de modelos con Amazon SageMaker Autopilot.
Sobre los autores
![]() Meenakshisundaram Thandavarayan es un especialista sénior en IA/ML de AWS. Ayuda a las cuentas estratégicas de alta tecnología en su viaje de IA y ML. Es un apasionado de la IA basada en datos.
Meenakshisundaram Thandavarayan es un especialista sénior en IA/ML de AWS. Ayuda a las cuentas estratégicas de alta tecnología en su viaje de IA y ML. Es un apasionado de la IA basada en datos.
![]() Sovik Kumar Nath es un arquitecto de soluciones de IA/ML con AWS. Tiene una amplia experiencia en diseños y soluciones de extremo a extremo para el aprendizaje automático; análisis de negocios dentro del análisis financiero, operativo y de marketing; cuidado de la salud; cadena de suministro; e IoT. Fuera del trabajo, a Sovik le gusta viajar y ver películas.
Sovik Kumar Nath es un arquitecto de soluciones de IA/ML con AWS. Tiene una amplia experiencia en diseños y soluciones de extremo a extremo para el aprendizaje automático; análisis de negocios dentro del análisis financiero, operativo y de marketing; cuidado de la salud; cadena de suministro; e IoT. Fuera del trabajo, a Sovik le gusta viajar y ver películas.
![]() Abigail es ingeniero de desarrollo de software en Amazon SageMaker. Le apasiona ayudar a los clientes a preparar sus datos en DataWrangler y crear sistemas de aprendizaje automático distribuidos. En su tiempo libre, a Abigail le gusta viajar, hacer caminatas, esquiar y hornear.
Abigail es ingeniero de desarrollo de software en Amazon SageMaker. Le apasiona ayudar a los clientes a preparar sus datos en DataWrangler y crear sistemas de aprendizaje automático distribuidos. En su tiempo libre, a Abigail le gusta viajar, hacer caminatas, esquiar y hornear.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/authoring-custom-transformations-in-amazon-sagemaker-data-wrangler-using-nltk-and-scipy/
- :es
- $ UP
- 1
- 10
- 100
- 7
- 8
- 9
- a
- Nuestra Empresa
- Cuentas
- adicional
- Adicionales
- dirección
- avanzado
- Después
- EDAD
- AI
- Servicios de IA
- Sistemas de IA
- AI / ML
- Todos
- permite
- Aunque
- Amazon
- Amazon Comprehend
- Amazon SageMaker
- Wrangler de datos de Amazon SageMaker
- análisis
- Analytics
- analizar
- y
- Andrés
- Otra
- APACHE
- Apache Spark
- applicación
- aplicaciones
- aplicada
- La aplicación de
- enfoque
- arquitectura
- somos
- AS
- At
- atributos
- Autenticación
- autor
- autoría
- automáticamente
- AutoML
- piloto automático
- Hoy Disponibles
- evitar
- AWS
- cocinando
- BE
- porque
- a las que has recomendado
- antes
- es el beneficio
- BIN
- Tablas de remo
- llevar
- build
- Construir la
- construido
- incorporado
- by
- PUEDEN
- capacidades
- case
- cases
- a ciertos
- cadena
- el cambio
- Cambios
- Elige
- clasificación
- código
- Codificación
- --
- Columna
- Columnas
- combinar
- combinar
- Algunos
- vibrante e inclusiva
- Empresas
- completar
- comprender
- exhaustivo
- informática
- condición
- condiciones
- Confirmar
- Desventajas
- restricciones
- Envase
- contenido
- continuo
- podría
- Parejas
- Para crear
- personalizado
- Clientes
- datos
- análisis de los datos
- Preparación de datos
- basada en datos
- conjuntos de datos
- Predeterminado
- demostrado
- Diseño
- diseños
- Determinar
- el desarrollo
- Desarrollo
- desarrolla el
- desviación
- una experiencia diferente
- descubrimiento
- discutir
- distribuidos
- documento
- documentos
- No
- dominio
- DE INSCRIPCIÓN
- pasan fácilmente
- fácil de usar
- eficiente
- ya sea
- elementos
- de extremo a extremo
- ingeniero
- Ingeniería
- enriquecedor
- entidades
- entidad
- Entorno
- Éter (ETH)
- evaluación
- Cada
- ejemplo
- ejemplos
- Excepto
- Haz ejercicio
- existente
- experience
- expresivo
- ampliar
- en los detalles
- Amplia experiencia
- extraerlos
- RÁPIDO
- más rápida
- Feature
- Caracteristicas
- Costes
- pocos
- Archive
- archivos
- financiero
- adecuado
- de tus señales
- Flujos
- Focus
- enfoque
- seguir
- siguiendo
- formulando
- Marco conceptual
- marcos
- Gratis
- Frecuencia
- Desde
- diversión
- función
- funciones
- generar
- generado
- generadores
- obtener
- encargarse de
- Tienen
- la salud
- ayudando
- ayuda
- de alta tecnología
- de alto nivel
- excursionismo
- Inicio
- Cómo
- Sin embargo
- HTML
- http
- HTTPS
- humana
- AMI
- ICON
- identifica
- Identifique
- Identidad
- imagen
- importar
- importante
- importador
- la mejora de
- in
- En otra
- información
- Insights
- instalar
- ejemplo
- integrar
- integración
- Intelligence
- las interfaces
- introducir
- implica
- IOT
- IT
- Trabajos
- jpg
- Clave
- conocido
- idioma
- Apellidos
- líder
- APRENDE:
- aprendizaje
- bibliotecas
- Biblioteca
- como
- pequeño
- no logras
- máquina
- máquina de aprendizaje
- para lograr
- muchos
- Marketing
- masivo
- matemático
- Puede..
- mencionado
- métodos
- podría
- minutos
- ML
- modelo
- modelos
- módulo
- Módulos
- más,
- movimiento
- Películas
- múltiples
- multiplicando
- nombre
- nombres
- Natural
- Lenguaje natural
- Procesamiento natural del lenguaje
- ¿ Necesita ayuda
- Nuevo
- Next
- nlp
- nodo
- nodos
- cuaderno
- ordenadores portátiles
- número
- números
- numpy
- objetivo
- of
- que ofrece
- Viejo
- on
- A bordo
- Inmersión
- ONE
- habiertos
- de código abierto
- operativos.
- óptimo
- optimización
- Optimización
- solicite
- reconocida por
- Otro
- de otra manera
- afuera
- EL DESARROLLADOR
- paquete
- paquetes
- Los pandas
- parte
- apasionado
- realizar
- frases
- industrial
- plataforma
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- más
- Popular
- Publicación
- prácticas
- Preparar
- Imprimir
- tratamiento
- Producción
- perfiles
- Programas
- proporcionar
- proporciona un
- propósito
- Push
- Python
- calidad
- datos de calidad
- Búsqueda
- azar
- Crudo
- datos en bruto
- confeccionado
- Recetas
- confianza
- permanece
- representar
- respuesta
- Resultados
- volvemos
- una estrategia SEO para aparecer en las búsquedas de Google.
- raíz
- rutinas
- Ejecutar
- s
- sabio
- mismo
- Conjunto de datos de muestra
- Guardar
- escenarios
- scikit-aprender
- guiones
- segundos
- segura
- selección
- mayor
- separado
- de coches
- Servicios
- ajustes
- Configure
- Compartir
- tienes
- Mostrar
- mostrado
- Shows
- cerrar
- cierre
- firmar
- Signal
- sencillos
- simplificar
- soltero
- Software
- Desarrollo de software ad-hoc
- a medida
- Soluciones
- algo
- Fuente
- Fuentes
- Spark
- especial
- especialista
- Girar
- dividido
- SQL
- cuadrado
- estándar
- comienzo
- fundó
- estadísticas
- paso
- pasos
- STORAGE
- Estratégico
- estructurando
- estudio
- tal
- suite
- suministro
- cadena de suministro
- soportes
- Todas las funciones a su disposición
- mesa
- ¡Prepárate!
- toma
- Tarea
- Técnico
- esa
- La
- La Fuente
- su
- por lo tanto
- Estas
- Tres
- equipo
- a
- ficha
- Tokenization
- Tokens
- parte superior
- Total
- Transformar
- transformaciones
- transformado
- transformadora
- Viajar
- Tendencia
- ui
- bajo
- aprendizaje sin supervisión
- utilizan el
- caso de uso
- utilidades
- propuesta de
- Valores
- diversos
- Visite
- visualizar
- ver
- Camino..
- formas
- WELL
- que
- mientras
- seguirá
- dentro de
- sin
- palabras
- Actividades:
- flujos de trabajo
- escribir
- escrito
- tú
- zephyrnet