Las organizaciones han optado por construir lagos de datos sobre Servicio de almacenamiento simple de Amazon (Amazon S3) durante muchos años. Un lago de datos es la opción más popular para que las organizaciones almacenen todos sus datos organizacionales generados por diferentes equipos, en todos los dominios comerciales, de todos los formatos diferentes e incluso a lo largo de la historia. De acuerdo a un estudio, la empresa promedio ve crecer el volumen de sus datos a una tasa que supera el 50 % por año, y generalmente administra un promedio de 33 fuentes de datos únicas para el análisis.
Los equipos a menudo intentan replicar miles de trabajos de bases de datos relacionales con el mismo patrón de extracción, transformación y carga (ETL). Se requiere mucho esfuerzo para mantener los estados de trabajo y programar estos trabajos individuales. Este enfoque ayuda a los equipos a agregar tablas con pocos cambios y también mantiene el estado del trabajo con el mínimo esfuerzo. Esto puede conducir a una gran mejora en la línea de tiempo de desarrollo y al seguimiento de los trabajos con facilidad.
En esta publicación, le mostramos cómo replicar fácilmente todos sus almacenes de datos relacionales en un lago de datos transaccionales de manera automatizada con un solo trabajo ETL usando Apache Iceberg y Pegamento AWS.
Arquitectura de soluciones
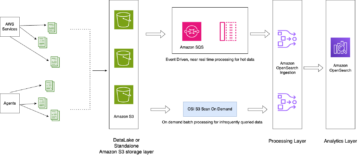
Los lagos de datos son generalmente organizado usando cubos S3 separados para tres capas de datos: la capa sin procesar que contiene datos en su forma original, la capa de etapa que contiene datos procesados intermedios optimizados para el consumo y la capa de análisis que contiene datos agregados para casos de uso específicos. En la capa sin procesar, las tablas generalmente se organizan en función de sus fuentes de datos, mientras que las tablas en la capa de etapa se organizan en función de los dominios comerciales a los que pertenecen.
Esta publicación proporciona una Formación en la nube de AWS plantilla que implementa un trabajo de AWS Glue que lee una ruta de Amazon S3 para una fuente de datos de la capa sin procesar del lago de datos e ingiere los datos en las tablas de Apache Iceberg en la capa del escenario usando Soporte de AWS Glue para marcos de lago de datos. El trabajo espera que las tablas en la capa sin procesar estén estructuradas de la manera Servicio de migración de bases de datos de AWS (AWS DMS) los ingiere: esquema, luego tabla, luego archivos de datos.
Esta solución utiliza Almacén de parámetros de AWS Systems Manager para la configuración de la mesa. Debe modificar este parámetro especificando las tablas que desea procesar y cómo, incluida información como la clave principal, las particiones y el dominio comercial asociado. El trabajo utiliza esta información para crear automáticamente una base de datos (si aún no existe) para cada dominio empresarial, crear las tablas Iceberg y realizar la carga de datos.
Finalmente, podemos usar Atenea amazónica para consultar los datos en las tablas Iceberg.
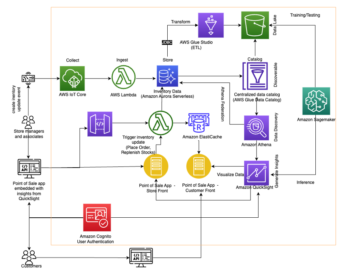
El siguiente diagrama ilustra esta arquitectura.

Esta implementación tiene las siguientes consideraciones:
- Todas las tablas del origen de datos deben tener una clave principal para replicarse con esta solución. La clave principal puede ser una sola columna o una clave compuesta con más de una columna.
- Si el lago de datos contiene tablas que no necesitan upserts o no tienen una clave principal, puede excluirlas de la configuración de parámetros e implementar procesos ETL tradicionales para ingerirlas en el lago de datos. Eso está fuera del alcance de esta publicación.
- Si hay fuentes de datos adicionales que deben ingerirse, puede implementar varias pilas de CloudFormation, una para manejar cada fuente de datos.
- El trabajo de AWS Glue está diseñado para procesar datos en dos fases: la carga inicial que se ejecuta después de que AWS DMS finaliza la tarea de carga completa y la carga incremental que se ejecuta en un programa que aplica archivos de captura de datos modificados (CDC) capturados por AWS DMS. El procesamiento incremental se realiza mediante un Marcador de trabajo de AWS Glue.
Hay nueve pasos para completar este tutorial:
- Configure un punto de enlace de origen para AWS DMS.
- Implemente la solución mediante AWS CloudFormation.
- Revise la tarea de replicación de AWS DMS.
- Opcionalmente, agregue permisos para el cifrado y descifrado o Formación del lago AWS.
- Revise la configuración de la tabla en el almacén de parámetros.
- Realice la carga inicial de datos.
- Realice una carga de datos incremental.
- Supervise la ingestión de la tabla.
- Programe la carga de datos por lotes incrementales.
Requisitos previos
Antes de comenzar este tutorial, ya debería estar familiarizado con Iceberg. Si no lo está, puede comenzar replicando una sola tabla siguiendo las instrucciones en Implemente un UPSERT basado en CDC en un lago de datos utilizando Apache Iceberg y AWS Glue. Además, configure lo siguiente:
Configurar un punto de enlace de origen para AWS DMS
Antes de crear nuestra tarea de AWS DMS, debemos configurar un punto de enlace de origen para conectarnos a la base de datos de origen:
- En la consola de AWS DMS, elija Endpoints en el panel de navegación.
- Elige Crear punto final.
- Si su base de datos se ejecuta en Amazon RDS, elija Seleccione una instancia de base de datos de RDS, luego elija la instancia de la lista. De lo contrario, elija el motor de origen y proporcione la información de conexión a través de Director de secretos de AWS o manualmente
- Identificador de punto final, ingrese un nombre para el punto final; por ejemplo, fuente-postgresql.
- Elige Crear punto final.
Implemente la solución con AWS CloudFormation
Cree una pila de CloudFormation utilizando la plantilla proporcionada. Complete los siguientes pasos:
- Elige Pila de lanzamiento:

- Elige Siguiente.
- Proporcione un nombre de pila, como
transactionaldl-postgresql. - Ingrese los parámetros requeridos:
- DMSS3EndpointIAMRoleARN – El ARN del rol de IAM para que AWS DMS escriba datos en Amazon S3.
- Instancia de replicaciónArn – El ARN de la instancia de replicación de AWS DMS.
- S3BucketStage – El nombre del depósito existente utilizado para la capa de etapa del lago de datos.
- S3CuboPegamento – El nombre del depósito de S3 existente para almacenar scripts de AWS Glue.
- S3BucketRaw – El nombre del depósito existente utilizado para la capa sin procesar del lago de datos.
- FuenteEndpointArn – El ARN del punto de enlace de AWS DMS que creó anteriormente.
- Nombre de la fuente – El identificador arbitrario de la fuente de datos a replicar (por ejemplo,
postgres). Esto se usa para definir la ruta S3 del lago de datos (capa sin procesar) donde se almacenarán los datos.
- No modifique los siguientes parámetros:
- FuenteS3BucketBlog – El nombre del depósito donde se almacena el script de AWS Glue proporcionado.
- FuenteS3BucketPrefix – El nombre del prefijo del depósito donde se almacena el script de AWS Glue proporcionado.
- Elige Siguiente dos veces.
- Seleccione Reconozco que AWS CloudFormation podría crear recursos de IAM con nombres personalizados.
- Elige Crear pila.
Después de aproximadamente 5 minutos, se implementa la pila de CloudFormation.
Revise la tarea de replicación de AWS DMS
La implementación de AWS CloudFormation creó un punto de enlace de destino de AWS DMS para usted. Debido a dos configuraciones de punto final específicas, los datos se ingerirán a medida que los necesitemos en Amazon S3.
- En la consola de AWS DMS, elija Endpoints en el panel de navegación.
- Busque y elija el punto final que comienza con
dmsIcebergs3endpoint. - Revise la configuración del punto final:
DataFormatse especifica comoparquet.TimestampColumnNameañadirá la columnalast_update_timecon la fecha de creación de los registros en Amazon S3.

La implementación también crea una tarea de replicación de AWS DMS que comienza con dmsicebergtask.
- Elige Tareas de replicación en el panel de navegación y busque la tarea.
Verás que el Tipo de tarea está marcado como Carga completa, replicación continua. AWS DMS realizará una carga completa inicial de los datos existentes y luego creará archivos incrementales con los cambios realizados en la base de datos de origen.
En Reglas de mapeo pestaña, hay dos tipos de reglas:
- Una regla de selección con el nombre del esquema de origen y las tablas que se incorporarán desde la base de datos de origen. De forma predeterminada, utiliza la base de datos de muestra proporcionada en los requisitos previos,
dms_sampley todas las tablas con la palabra clave %. - Dos reglas de transformación que incluyen en los archivos de destino en Amazon S3 el nombre del esquema y el nombre de la tabla como columnas. Nuestro trabajo de AWS Glue lo utiliza para saber a qué tablas corresponden los archivos en el lago de datos.
Para obtener más información sobre cómo personalizar esto para sus propias fuentes de datos, consulte Reglas de selección y acciones..

Cambiemos algunas configuraciones para terminar la preparación de nuestra tarea.
- En Acciones menú, seleccione modificar.
- En Configuración de tareas sección, bajo Detener la tarea después de completar la carga completa, escoger Detener después de aplicar los cambios almacenados en caché.
De esta forma, podemos controlar la carga inicial y la generación incremental de archivos como dos pasos diferentes. Usamos este enfoque de dos pasos para ejecutar el trabajo de AWS Glue una vez por cada paso.
- under Registros de tareas, escoger Activar registros de CloudWatch.
- Elige Guardar.
- Espere aproximadamente 1 minuto para que el estado de la tarea de migración de la base de datos se muestre como Listo!.
Agregue permisos para el cifrado y descifrado o Lake Formation
Opcionalmente, puede agregar permisos para el cifrado y descifrado o Lake Formation.
Agregar permisos de cifrado y descifrado
Si los cubos de S3 utilizados para las capas sin formato y de etapa están cifrados mediante Servicio de administración de claves de AWS (AWS KMS) administradas por el cliente, debe agregar permisos para permitir que el trabajo de AWS Glue acceda a los datos:
Agregar permisos de formación de lagos
Si está administrando permisos mediante Lake Formation, debe permitir que su trabajo de AWS Glue cree las bases de datos y las tablas de su dominio a través del rol de IAM. GlueJobRole.
- Otorgue permisos para crear bases de datos (para obtener instrucciones, consulte Crear una base de datos).
- Otorgar permisos SUPER a la
defaultbase de datos. - Otorgar permisos de ubicación de datos.
- Si crea bases de datos manualmente, conceda permisos en todas las bases de datos para crear tablas. Referirse a Concesión de permisos de tabla mediante la consola de Lake Formation y el método de recursos con nombre or Concesión de permisos de catálogo de datos mediante el método LF-TBAC según su caso de uso.
Después de completar el paso posterior de realizar la carga de datos inicial, asegúrese de agregar también permisos para que los consumidores consulten las tablas. El rol de trabajo se convertirá en el propietario de todas las tablas creadas y, a continuación, el administrador del lago de datos podrá realizar concesiones a usuarios adicionales.
Revisar la configuración de la tabla en el almacén de parámetros
El trabajo de AWS Glue que realiza la ingesta de datos en las tablas de Iceberg utiliza la especificación de tabla proporcionada en el almacén de parámetros. Complete los siguientes pasos para revisar el almacén de parámetros que se configuró automáticamente para usted. Si es necesario, modifíquelo según sus propias necesidades.
- En la consola del almacén de parámetros, seleccione Mis parámetros en el panel de navegación.
La pila de CloudFormation creó dos parámetros:
iceberg-configpara configuraciones de trabajoiceberg-tablespara configuración de mesa
- Elige el parámetro mesas-iceberg.
La estructura JSON contiene información que utiliza AWS Glue para leer datos y escribir las tablas Iceberg en el dominio de destino:
- Un objeto por mesa – El nombre del objeto se crea utilizando el nombre del esquema, un punto y el nombre de la tabla; Por ejemplo,
schema.table. - Clave primaria – Esto debe especificarse para cada tabla de origen. Puede proporcionar una sola columna o una lista de columnas separadas por comas (sin espacios).
- particiónCols – Esto, opcionalmente, divide las columnas para las tablas de destino. Si no desea crear tablas particionadas, proporcione una cadena vacía. De lo contrario, proporcione una sola columna o una lista de columnas separadas por comas que se usarán (sin espacios).
- Si desea usar su propia fuente de datos, use el siguiente código JSON y reemplace el texto en MAYÚSCULAS de la plantilla provista. Si está utilizando la fuente de datos de muestra proporcionada, mantenga la configuración predeterminada:
{ "SCHEMA_NAME.TABLE_NAME_1": { "primaryKey": "ONLY_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "" }, "SCHEMA_NAME.TABLE_NAME_2": { "primaryKey": "FIRST_PRIMARY_KEY,SECOND_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "PARTITION_COLUMN_ONE,PARTITION_COLUMN_TWO" }
}- Elige Guardar los cambios.
Realizar la carga de datos inicial
Ahora que la configuración requerida está terminada, ingerimos los datos iniciales. Este paso incluye tres partes: incorporar los datos de la base de datos relacional de origen en la capa sin procesar del lago de datos, crear las tablas Iceberg en la capa del escenario del lago de datos y verificar los resultados con Athena.
Ingerir datos en la capa sin procesar del lago de datos
Para ingerir datos de la fuente de datos relacionales (PostgreSQL si está usando la muestra proporcionada) a nuestro lago de datos transaccionales usando Iceberg, complete los siguientes pasos:
- En la consola de AWS DMS, elija Tareas de migración de base de datos en el panel de navegación.
- Seleccione la tarea de replicación que creó y en la Acciones menú, seleccione Reiniciar/Reanudar.
- Espere unos 5 minutos para que se complete la tarea de replicación. Puede monitorear las tablas ingeridas en el Estadística pestaña de la tarea de replicación.

Después de unos minutos, la tarea termina con el mensaje Carga completa completa.
- En la consola de Amazon S3, elija el depósito que definió como la capa sin formato.
Bajo el prefijo S3 definido en AWS DMS (por ejemplo, postgres), debería ver una jerarquía de carpetas con la siguiente estructura:
- Esquema
- Nombre de la tabla
LOAD00000001.parquetLOAD0000000N.parquet
- Nombre de la tabla

Si su depósito S3 está vacío, revise Solución de problemas de tareas de migración en AWS Database Migration Service antes de ejecutar el trabajo de AWS Glue.
Crear e ingerir datos en tablas Iceberg
Antes de ejecutar el trabajo, naveguemos por el script del trabajo de AWS Glue proporcionado como parte de la pila de CloudFormation para comprender su comportamiento.
- En la consola de AWS Glue Studio, elija Empleo en el panel de navegación.
- Busca el trabajo que comienza con
IcebergJob-y un sufijo de su nombre de pila de CloudFormation (por ejemplo,IcebergJob-transactionaldl-postgresql). - Elige el trabajo.

El script de trabajo obtiene la configuración que necesita del almacén de parámetros. La función getConfigFromSSM() devuelve configuraciones relacionadas con el trabajo, como cubos de origen y destino desde donde se deben leer y escribir los datos. La variable ssmparam_table_values contienen información relacionada con la tabla, como el dominio de datos, el nombre de la tabla, las columnas de partición y la clave principal de las tablas que deben ingerirse. Vea el siguiente código de Python:
# Main application
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'stackName'])
SSM_PARAMETER_NAME = f"{args['stackName']}-iceberg-config"
SSM_TABLE_PARAMETER_NAME = f"{args['stackName']}-iceberg-tables" # Parameters for job
rawS3BucketName, rawBucketPrefix, stageS3BucketName, warehouse_path = getConfigFromSSM(SSM_PARAMETER_NAME)
ssm_param_table_values = json.loads(ssmClient.get_parameter(Name = SSM_TABLE_PARAMETER_NAME)['Parameter']['Value'])
dropColumnList = ['db','table_name', 'schema_name','Op', 'last_update_time', 'max_op_date']El script usa un nombre de catálogo arbitrario para Iceberg que se define como my_catalog. Esto se implementa en el catálogo de datos de AWS Glue mediante configuraciones de Spark, por lo que se aplicará una operación de SQL que apunte a my_catalog en el catálogo de datos. Ver el siguiente código:
catalog_name = 'my_catalog'
errored_table_list = [] # Iceberg configuration
spark = SparkSession.builder .config('spark.sql.warehouse.dir', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') .config(f'spark.sql.catalog.{catalog_name}.warehouse', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}.catalog-impl', 'org.apache.iceberg.aws.glue.GlueCatalog') .config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.aws.s3.S3FileIO') .config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') .getOrCreate()
El script itera sobre las tablas definidas en el almacén de parámetros y realiza la lógica para detectar si la tabla existe y si los datos entrantes son una carga inicial o una inserción:
# Iteration over tables stored on Parameter Store
for key in ssm_param_table_values: # Get table data isTableExists = False schemaName, tableName = key.split('.') logger.info(f'Processing table : {tableName}')El initialLoadRecordsSparkSQL() La función carga los datos iniciales cuando no hay una columna de operación presente en los archivos de S3. AWS DMS agrega esta columna solo a los archivos de datos de Parquet producidos por la replicación continua (CDC). La carga de datos se realiza mediante el comando INSERT INTO con SparkSQL. Ver el siguiente código:
sqltemp = Template(""" INSERT INTO $catalog_name.$dbName.$tableName ($insertTableColumnList) SELECT $insertTableColumnList FROM insertTable $partitionStrSQL """)
SQLQUERY = sqltemp.substitute( catalog_name = catalog_name, dbName = dbName, tableName = tableName, insertTableColumnList = insertTableColumnList[ : -1], partitionStrSQL = partitionStrSQL) logger.info(f'****SQL QUERY IS : {SQLQUERY}')
spark.sql(SQLQUERY)
Ahora ejecutamos el trabajo de AWS Glue para ingerir los datos iniciales en las tablas de Iceberg. La pila de CloudFormation agrega la --datalake-formats parámetro, agregando las bibliotecas Iceberg requeridas al trabajo.
- Elige Ejecutar trabajo.
- Elige Ejecuciones de trabajo para monitorear el estado. Espere hasta que el estado sea Ejecutar con éxito.
Verificar los datos cargados
Para confirmar que el trabajo procesó los datos como se esperaba, complete los siguientes pasos:
- En la consola de Athena, elija Editor de consultas en el panel de navegación.
- Verificar
AwsDataCatalogse selecciona como fuente de datos. - under Base de datos, elija el dominio de datos que desea explorar, según la configuración que definió en el almacén de parámetros. Si usa la base de datos de muestra provista, use
sports.
under Tablas y vistas, podemos ver la lista de tablas creadas por el trabajo de AWS Glue.
- Elija el menú de opciones (tres puntos) junto al nombre de la primera tabla, luego elija Vista previa de datos.
Puede ver los datos cargados en tablas Iceberg. 
Realizar carga de datos incremental
Ahora comenzamos a capturar cambios de nuestra base de datos relacional y aplicarlos al lago de datos transaccionales. Este paso también se divide en tres partes: capturar los cambios, aplicarlos a las tablas Iceberg y verificar los resultados.
Capture cambios de la base de datos relacional
Debido a la configuración que especificamos, la tarea de replicación se detuvo después de ejecutar la fase de carga completa. Ahora reiniciamos la tarea para agregar archivos incrementales con cambios en la capa sin formato del lago de datos.
- En la consola de AWS DMS, seleccione la tarea que creamos y ejecutamos antes.
- En Acciones menú, seleccione Currículum.
- Elige Iniciar tarea para comenzar a capturar los cambios.
- Para desencadenar la creación de nuevos archivos en el lago de datos, realice inserciones, actualizaciones o eliminaciones en las tablas de su base de datos de origen utilizando su herramienta de administración de base de datos preferida. Si usa la base de datos de muestra provista, puede ejecutar los siguientes comandos SQL:
UPDATE dms_sample.nfl_stadium_data_upd
SET seatin_capacity=93703
WHERE team = 'Los Angeles Rams' and sport_location_id = '31'; update dms_sample.mlb_data set bats = 'R'
where mlb_id=506560 and bats='L'; update dms_sample.sporting_event set start_date = current_date where id=11 and sold_out=0;
- En la página de detalles de la tarea de AWS DMS, elija el Estadísticas de la tabla pestaña para ver los cambios capturados.

- Abra la capa sin formato del lago de datos para encontrar un nuevo archivo que contenga los cambios incrementales dentro del prefijo de cada tabla, por ejemplo, bajo el
sporting_eventprefijo.
El registro con cambios para el sporting_event La tabla se parece a la siguiente captura de pantalla.

Note la Op columna al principio identificada con una actualización (U). Además, el segundo valor de fecha/hora es la columna de control agregada por AWS DMS con la hora en que se capturó el cambio.

Aplicar cambios en las tablas de Iceberg usando AWS Glue
Ahora ejecutamos el trabajo de AWS Glue nuevamente y procesará automáticamente solo los nuevos archivos incrementales ya que el marcador de trabajo está habilitado. Repasemos cómo funciona.
El dedupCDCRecords() La función realiza la deduplicación de datos porque se pueden capturar varios cambios en un solo ID de registro dentro del mismo archivo de datos en Amazon S3. La deduplicación se realiza en función de la last_update_time columna agregada por AWS DMS que indica la marca de tiempo de cuando se capturó el cambio. Vea el siguiente código de Python:
def dedupCDCRecords(inputDf, keylist): IDWindowDF = Window.partitionBy(*keylist).orderBy(inputDf.last_update_time).rangeBetween(-sys.maxsize, sys.maxsize) inputDFWithTS = inputDf.withColumn('max_op_date', max(inputDf.last_update_time).over(IDWindowDF)) NewInsertsDF = inputDFWithTS.filter('last_update_time=max_op_date').filter("op='I'") UpdateDeleteDf = inputDFWithTS.filter('last_update_time=max_op_date').filter("op IN ('U','D')") finalInputDF = NewInsertsDF.unionAll(UpdateDeleteDf) return finalInputDFEn la línea 99, el upsertRecordsSparkSQL() La función realiza el upsert de manera similar a la carga inicial, pero esta vez con un comando SQL MERGE.
Revisar los cambios aplicados
Abra la consola de Athena y ejecute una consulta que seleccione los registros modificados en la base de datos de origen. Si usa la base de datos de muestra provista, use una de las siguientes consultas SQL:
SELECT * FROM "sports"."nfl_stadiu_data_upd"
WHERE team = 'Los Angeles Rams' and sport_location_id = 31
LIMIT 1;

Supervisar la ingestión de tablas
El script de trabajo de AWS Glue está codificado con simple Manejo de excepciones de Python para detectar errores durante el procesamiento de una tabla específica. El marcador del trabajo se guarda después de que cada tabla termine de procesarse correctamente, para evitar volver a procesar las tablas si se vuelve a intentar ejecutar el trabajo para las tablas con errores.
El Interfaz de línea de comandos de AWS (AWS CLI) proporciona una get-job-bookmark Comando para AWS Glue que proporciona información sobre el estado del marcador para cada tabla procesada.
- En la consola de AWS Glue Studio, elija el trabajo de ETL.
- Elija el Ejecuciones de trabajo y copie el ID de ejecución del trabajo.
- Ejecute el siguiente comando en un terminal autenticado para AWS CLI, reemplazando
<GLUE_JOB_RUN_ID>en la línea 1 con el valor que copiaste. Si su pila de CloudFormation no tiene nombretransactionaldl-postgresql, proporcione el nombre de su trabajo en la línea 2 del script:
jobrun=<GLUE_JOB_RUN_ID>
jobname=IcebergJob-transactionaldl-postgresql
aws glue get-job-bookmark --job-name jobname --run-id $jobrunEn esta solución, cuando el procesamiento de una tabla provoca una excepción, el trabajo de AWS Glue no fallará según esta lógica. En su lugar, la tabla se agregará a una matriz que se imprimirá una vez que se complete el trabajo. En tal escenario, el trabajo se marcará como fallido después de que intente procesar el resto de las tablas detectadas en la fuente de datos sin procesar. De esta forma, las tablas sin errores no tienen que esperar hasta que el usuario identifique y resuelva el problema en las tablas en conflicto. El usuario puede detectar rápidamente las ejecuciones de trabajos que tuvieron problemas con el estado de ejecución del trabajo de AWS Glue e identificar qué tablas específicas están causando el problema mediante los registros de CloudWatch para la ejecución del trabajo.
- El script de trabajo implementa esta función con el siguiente código de Python:
# Performed for every table try: # Table processing logic except Exception as e: logger.info(f'There is an issue with table: {tableName}') logger.info(f'The exception is : {e}') errored_table_list.append(tableName) continue job.commit()
if (len(errored_table_list)): logger.info('Total number of errored tables are ',len(errored_table_list)) logger.info('Tables that failed during processing are ', *errored_table_list, sep=', ') raise Exception(f'***** Some tables failed to process.')La siguiente captura de pantalla muestra cómo los registros de CloudWatch buscan tablas que provocan errores en el procesamiento.

Alineado con el Lente de análisis de datos del marco de buena arquitectura de AWS prácticas, puede adaptar mecanismos de control más sofisticados para identificar y notificar a las partes interesadas cuando aparecen errores en las canalizaciones de datos. Por ejemplo, puede utilizar un Amazon DynamoDB tabla de control para almacenar todas las tablas y ejecuciones de trabajos con errores, o usando Servicio de notificación simple de Amazon (Amazon SNS) a enviar alertas a los operadores cuando se cumplen ciertos criterios.
Programe la carga de datos por lotes incrementales
La pila de CloudFormation implementa un Puente de eventos de Amazon regla (deshabilitada de forma predeterminada) que puede activar el trabajo de AWS Glue para que se ejecute según un cronograma. Para proporcionar su propio horario y habilitar la regla, complete los siguientes pasos:
- En la consola de EventBridge, elija Reglas en el panel de navegación.
- Busque la regla con el prefijo del nombre de su pila de CloudFormation seguida de
JobTrigger(por ejemplo,transactionaldl-postgresql-JobTrigger-randomvalue). - Elige la regla.
- under Horario, escoger Editar.
El programa predeterminado está configurado para activarse cada hora.
- Proporcione la programación en la que desea ejecutar el trabajo.
- Además, puede utilizar un Expresión cron de EventBridge seleccionando Un horario detallado.

- Cuando termine de configurar la expresión cron, elija Siguiente tres veces, y finalmente elige Regla de actualización para guardar cambios
La regla se crea deshabilitada de forma predeterminada para permitirle ejecutar primero la carga de datos inicial.
- Active la regla eligiendo permitir.
Puede utilizar el Monitoreo pestaña para ver las invocaciones de reglas, o directamente en AWS Glue Ejecutar trabajo Detalles.
Conclusión
Después de implementar esta solución, ha automatizado la ingesta de sus tablas en una única fuente de datos relacionales. Las organizaciones que utilizan un lago de datos como su plataforma de datos central generalmente necesitan manejar múltiples, a veces incluso decenas de fuentes de datos. Además, cada vez más casos de uso requieren que las organizaciones implementen capacidades transaccionales en el lago de datos. Puede usar esta solución para acelerar la adopción de tales capacidades en todas sus fuentes de datos relacionales para habilitar nuevos casos de uso comercial, automatizando el proceso de implementación para obtener más valor de sus datos.
Acerca de los autores
 luis gerardo baeza es Arquitecto de Big Data en el Laboratorio de Datos de Amazon Web Services (AWS). Tiene 12 años de experiencia ayudando a organizaciones en los sectores de salud, finanzas y educación a adoptar programas de arquitectura empresarial, computación en la nube y capacidades de análisis de datos. Luis actualmente ayuda a organizaciones de América Latina a acelerar iniciativas de datos estratégicos.
luis gerardo baeza es Arquitecto de Big Data en el Laboratorio de Datos de Amazon Web Services (AWS). Tiene 12 años de experiencia ayudando a organizaciones en los sectores de salud, finanzas y educación a adoptar programas de arquitectura empresarial, computación en la nube y capacidades de análisis de datos. Luis actualmente ayuda a organizaciones de América Latina a acelerar iniciativas de datos estratégicos.
 SaiKiran Reddy Aenugu es arquitecto de datos en el laboratorio de datos de Amazon Web Services (AWS). Cuenta con 10 años de experiencia implementando procesos de carga, transformación y visualización de datos. SaiKiran actualmente ayuda a las organizaciones en América del Norte a adoptar arquitecturas de datos modernas, como lagos de datos y redes de datos. Tiene experiencia en los sectores minorista, aéreo y financiero.
SaiKiran Reddy Aenugu es arquitecto de datos en el laboratorio de datos de Amazon Web Services (AWS). Cuenta con 10 años de experiencia implementando procesos de carga, transformación y visualización de datos. SaiKiran actualmente ayuda a las organizaciones en América del Norte a adoptar arquitecturas de datos modernas, como lagos de datos y redes de datos. Tiene experiencia en los sectores minorista, aéreo y financiero.
 Narendra Merla es arquitecto de datos en el laboratorio de datos de Amazon Web Services (AWS). Tiene 12 años de experiencia en el diseño y la producción de canalizaciones de datos orientadas a lotes y en tiempo real y en la creación de lagos de datos en entornos locales y en la nube. Narendra actualmente ayuda a las organizaciones en América del Norte a construir y diseñar arquitecturas de datos sólidas y tiene experiencia en los sectores de telecomunicaciones y finanzas.
Narendra Merla es arquitecto de datos en el laboratorio de datos de Amazon Web Services (AWS). Tiene 12 años de experiencia en el diseño y la producción de canalizaciones de datos orientadas a lotes y en tiempo real y en la creación de lagos de datos en entornos locales y en la nube. Narendra actualmente ayuda a las organizaciones en América del Norte a construir y diseñar arquitecturas de datos sólidas y tiene experiencia en los sectores de telecomunicaciones y finanzas.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/automate-replication-of-relational-sources-into-a-transactional-data-lake-with-apache-iceberg-and-aws-glue/
- 1
- 10
- 100
- 102
- 107
- 7
- a
- Sobre
- acelerar
- de la máquina
- Conforme
- reconocer
- a través de
- adaptar
- adicional
- Adicionales
- Adicionalmente
- Añade
- Admin
- administración
- adoptar
- Adopción
- Después
- línea aérea
- Todos
- ya haya utilizado
- Amazon
- Atenea amazónica
- RDS de Amazon
- Amazon Web Services
- Servicios Web de Amazon (AWS)
- America
- análisis
- Analytics
- y
- Angeles
- APACHE
- Aparecer
- Aplicación
- aplicada
- La aplicación de
- enfoque
- aproximadamente
- arquitectura
- Formación
- asociado
- autenticado
- automatizado
- Confirmación de Viaje
- automáticamente
- automatizar
- promedio
- evitar
- AWS
- Formación en la nube de AWS
- Pegamento AWS
- basado
- murciélagos
- porque
- a las que has recomendado
- antes
- Comienzo
- Big
- Big Data
- build
- constructor
- Construir la
- Puede conseguir
- capacidades
- tapas
- capturar
- Capturando
- case
- cases
- catalogar
- lucha
- Causar
- causas
- causando
- CDC
- central
- a ciertos
- el cambio
- Cambios
- manera?
- Elige
- la elección de
- elegido
- Soluciones
- la computación en nube
- código
- Columna
- Columnas
- compañía
- completar
- informática
- Configuración
- externa (Biomet XNUMXi)
- Confirmar
- Contradictorio
- CONTACTO
- conexión
- consideraciones
- Consola
- Clientes
- consumo
- contiene
- continue
- continuo
- control
- podría
- Para crear
- creado
- crea
- Creamos
- creación
- criterios
- En la actualidad
- personalizado
- cliente
- personalizan
- datos
- Data Analytics
- Lago de datos
- Plataforma de datos
- Base de datos
- bases de datos
- Fecha
- Predeterminado
- se define
- desplegar
- desplegado
- Desplegando
- despliegue
- despliega
- Diseño
- diseñado
- diseño
- detalles
- detectado
- Desarrollo
- una experiencia diferente
- directamente
- discapacitados
- dividido
- No
- dominio
- dominios
- No
- durante
- cada una
- Más temprano
- pasan fácilmente
- Educación
- esfuerzo
- ya sea
- habilitar
- facilita
- cifrado
- cifrado
- Punto final
- Motor
- Participar
- Empresa
- ambientes
- Errores
- Éter (ETH)
- Incluso
- Cada
- ejemplo
- excede
- Excepto
- excepción
- existente
- existe
- esperado
- espera
- experience
- explorar
- extensiones
- extraerlos
- Fallidos
- familiar
- Moda
- Feature
- pocos
- Archive
- archivos
- Finalmente
- financiar
- financiero
- Encuentre
- acabado
- Nombre
- seguido
- siguiendo
- Para consumidores
- formulario
- formación
- Marco conceptual
- en
- ser completados
- función
- generado
- generación de AHSS
- obtener
- conceder
- subvenciones
- Creciendo
- encargarse de
- la salud
- ayudando
- ayuda
- jerarquía
- historia
- tenencia
- Cómo
- Como Hacer
- HTML
- HTTPS
- enorme
- AMI
- no haber aun identificado una solucion para el problema
- identificador
- identifica
- Identifique
- implementar
- implementación
- implementado
- implementación
- implementos
- es la mejora continua
- in
- incluir
- incluye
- Incluye
- Entrante
- Indica
- INSTRUMENTO individual
- información
- inicial
- iniciativas
- Insertos
- penetración
- ejemplo
- Instrucciones
- Intermedio
- cuestiones
- IT
- iteración
- Trabajos
- Empleo
- json
- Guardar
- Clave
- claves
- Saber
- el lab
- lago
- latín
- América Latina
- .
- ponedoras
- Lead
- APRENDE:
- bibliotecas
- LIMITE LAS
- línea
- Lista
- carga
- carga
- cargas
- Ubicación
- Mira
- MIRADAS
- los
- Los Ángeles
- Lote
- Inicio
- mantiene
- para lograr
- gestionado
- Management
- gerente
- administrar
- a mano
- muchos
- cartografía
- marcado
- Menú
- ir
- mensaje
- podría
- migración
- mínimo
- minuto
- minutos
- Moderno
- modificar
- Monitorear
- monitoreo
- más,
- MEJOR DE TU
- Más popular
- múltiples
- nombre
- Llamado
- nombres
- Navegar
- Navegación
- ¿ Necesita ayuda
- Nuevo
- Next
- North
- América del Norte
- .
- número
- objeto
- objetos
- ONE
- en marcha
- OP
- Inteligente
- optimizado
- Opciones
- organizativo
- para las fiestas.
- Organizado
- reconocida por
- de otra manera
- afuera
- EL DESARROLLADOR
- propietario
- cristal
- parámetro
- parámetros
- parte
- partes
- camino
- Patrón de Costura
- (PDF)
- realizar
- realizar
- realiza
- período
- permisos
- fase
- plataforma
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- Popular
- Publicación
- Postgresql
- prácticas
- preferido
- requisitos previos
- presente
- primario
- Problema
- en costes
- tratamiento
- producido
- Programas
- proporcionar
- previsto
- proporciona un
- Python
- con rapidez
- aumento
- Rate
- Crudo
- datos en bruto
- Leer
- en tiempo real
- grabar
- archivos
- reemplazar
- replicado
- replicación
- exigir
- Requisitos
- Recurso
- Recursos
- RESTO
- Resultados
- el comercio minorista
- volvemos
- devoluciones
- una estrategia SEO para aparecer en las búsquedas de Google.
- robusto
- Función
- Regla
- reglas
- Ejecutar
- correr
- mismo
- Guardar
- guión
- programa
- alcance
- guiones
- Buscar
- Segundo
- Sectores
- ver
- seleccionado
- seleccionar
- selección
- separado
- Servicios
- set
- pólipo
- ajustes
- tienes
- Mostrar
- Shows
- similares
- sencillos
- desde
- soltero
- So
- a medida
- Resuelve
- algo
- sofisticado
- Fuente
- Fuentes
- espacios
- Spark
- soluciones y
- especificación
- especificado
- Deportes
- SQL
- montón
- Stacks
- Etapa
- las partes interesadas
- comienzo
- fundó
- Comience a
- comienza
- Zonas
- statistics
- Estado
- paso
- pasos
- detenido
- STORAGE
- tienda
- almacenados
- tiendas
- Estratégico
- estructura
- estructurado
- estudio
- Con éxito
- tal
- súper
- SOPORTE
- Todas las funciones a su disposición
- mesa
- Target
- Tarea
- tareas
- equipo
- equipos
- telecom
- plantilla
- terminal
- El
- La Fuente
- su
- miles
- Tres
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- equipo
- calendario
- veces
- fecha y hora
- a
- del IRS
- parte superior
- Total
- Seguimiento
- tradicional
- transaccional
- Transformar
- detonante
- tutoriales
- tipos
- bajo
- entender
- único
- Actualizar
- Actualizaciones
- utilizan el
- caso de uso
- Usuario
- usuarios
- generalmente
- propuesta de
- verificando
- Ver
- visualización
- volumen
- esperar
- Manejo de
- web
- servicios web
- que
- seguirá
- dentro de
- sin
- funciona
- escribir
- escrito
- yaml
- año
- años
- tú
- zephyrnet