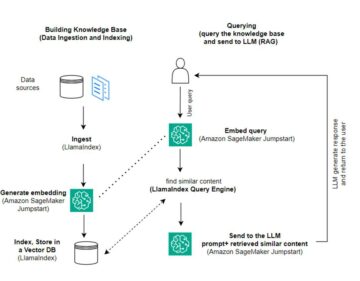
Piloto automático Amazon SageMaker lo ayuda a completar un flujo de trabajo de aprendizaje automático (ML) de extremo a extremo al automatizar los pasos de ingeniería de funciones, capacitación, ajuste e implementación de un modelo de ML para inferencia. Proporciona a SageMaker Autopilot un conjunto de datos tabulares y un atributo objetivo para predecir. Luego, SageMaker Autopilot explora automáticamente sus datos, entrena, sintoniza, clasifica y encuentra el mejor modelo. Finalmente, puede implementar este modelo en producción para la inferencia con un solo clic.
¿Qué hay de nuevo?
La característica recién lanzada, Informes de calidad del modelo de piloto automático de SageMaker, ahora informa las métricas de su modelo para proporcionar una mejor visibilidad del rendimiento de su modelo para problemas de regresión y clasificación. Puede aprovechar estas métricas para recopilar más información sobre el mejor modelo en la tabla de clasificación de modelos.
Estas métricas e informes que están disponibles en una nueva pestaña "Rendimiento" en "Detalles del modelo" del mejor modelo incluyen matrices de confusión, un área bajo la curva característica operativa del receptor (AUC-ROC) y un área bajo la curva de recuperación de precisión (AUC-PR). Estas métricas lo ayudan a comprender los falsos positivos/falsos negativos (FP/FN), las compensaciones entre verdaderos positivos (TP) y falsos positivos (FP), así como las compensaciones entre precisión y recuperación para evaluar las mejores características de rendimiento del modelo.
Ejecución del experimento de piloto automático de SageMaker
El conjunto de datos
Utilizamos Conjunto de datos de marketing bancario de UCI para demostrar los informes de calidad del modelo de piloto automático de SageMaker. Estos datos contienen atributos del cliente, como edad, tipo de trabajo, estado civil y otros que usaremos para predecir si el cliente abrirá una cuenta en el banco. El conjunto de datos se refiere a esta cuenta como un depósito a plazo. Esto hace que nuestro caso sea un problema de clasificación binaria: la predicción será "sí" o "no". SageMaker Autopilot generará varios modelos en nuestro nombre para predecir mejor a los clientes potenciales. Luego, examinaremos el Informe de calidad del modelo para SageMaker Autopilot mejor modelo.
Requisitos previos
Para iniciar un experimento de SageMaker Autopilot, primero debe colocar sus datos en un Servicio de almacenamiento simple de Amazon (Amazon S3) cubeta. Especifique el depósito y el prefijo que desea usar para el entrenamiento. Asegúrese de que el depósito esté en la misma región que el experimento de SageMaker Autopilot. También debe asegurarse de que el rol Autopilot de Administración de acceso e identidad (IAM) tenga permisos para acceder a los datos en Amazon S3.
Creando el experimento
Tiene varias opciones para crear un experimento de SageMaker Autopilot en SageMaker Studio. Al abrir un nuevo iniciador, es posible que pueda acceder directamente a SageMaker Autopilot. De lo contrario, puede seleccionar el ícono de recursos de SageMaker en el lado izquierdo. A continuación, puede seleccionar Experimentos y ensayos En el menú desplegable.
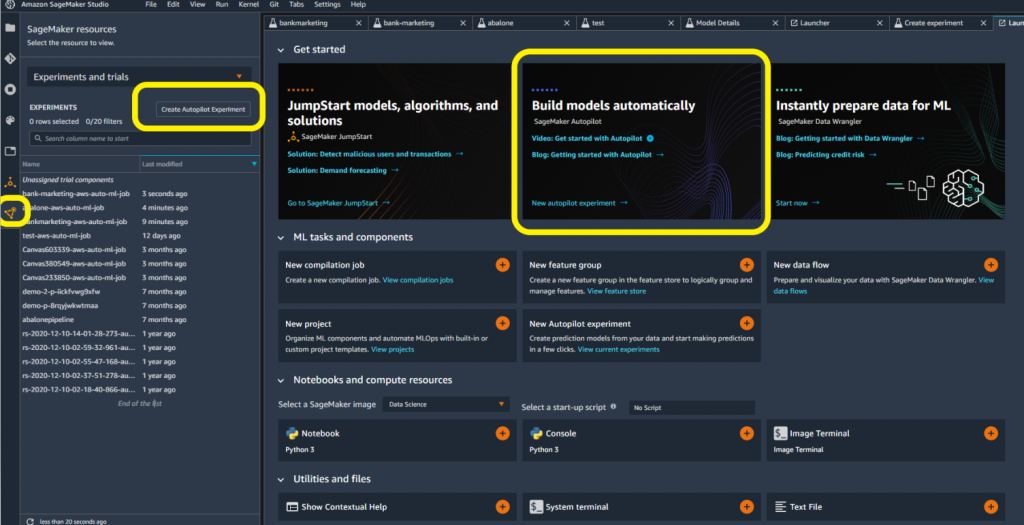
- Dale un nombre a tu experimento.
- Conéctese a su fuente de datos seleccionando el depósito de Amazon S3 y el nombre del archivo.
- Elija la ubicación de los datos de salida en Amazon S3.
- Seleccione la columna de destino para su conjunto de datos. En este caso, apuntamos a la columna "y" para indicar sí/no.
- Opcionalmente, proporcione un nombre de punto final si desea que SageMaker Autopilot implemente automáticamente un punto final modelo.
- Deje todas las demás configuraciones avanzadas como predeterminadas y seleccione Crear experimento.

Una vez que se completa el experimento, puede ver los resultados en SageMaker Studio. SageMaker Autopilot presentará el mejor modelo entre los diferentes modelos que entrena. Puede ver los detalles y los resultados de diferentes ensayos, pero usaremos el mejor modelo para demostrar el uso de los informes de calidad del modelo.
- Seleccione el modelo y haga clic derecho para Abrir en detalles del modelo.
- Dentro de los detalles del modelo, seleccione el Rendimiento pestaña. Esto muestra las métricas del modelo a través de visualizaciones y gráficos.
- under Rendimiento, seleccione Descargar informes de rendimiento como PDF.


Interpretación del informe de calidad del modelo de piloto automático de SageMaker
El Informe de calidad del modelo resume el trabajo de SageMaker Autopilot y los detalles del modelo. Nos centraremos en el formato PDF del informe, pero también puede acceder a los resultados como JSON. Debido a que SageMaker Autopilot determinó nuestro conjunto de datos como un problema de clasificación binaria, SageMaker Autopilot pretendía maximizar la Métrica de calidad F1 para encontrar el mejor modelo. SageMaker Autopilot elige esto de forma predeterminada. Sin embargo, hay flexibilidad para elegir otras métricas objetivas, como la precisión y el AUC. La puntuación F1 de nuestro modelo es 0.61. Para interpretar una puntuación F1, es útil comprender primero una matriz de confusión, que se explica en el Informe de calidad del modelo en el PDF generado.
Matriz de confusión
Una matriz de confusión ayuda a visualizar el rendimiento del modelo comparando diferentes clases y etiquetas. El experimento de SageMaker Autopilot creó una matriz de confusión que muestra las etiquetas reales como filas y las etiquetas predicadas como columnas en el Informe de calidad del modelo. El cuadro superior izquierdo muestra los clientes que no abrieron una cuenta con el banco que el modelo predijo correctamente como 'no'. Estos son verdaderos negativos (TENNESSE). El cuadro inferior derecho muestra los clientes que sí abrieron una cuenta con el banco que el modelo predijo correctamente como 'sí'. Estos son verdaderos positivos (TP).

La esquina inferior izquierda muestra el número de falsos negativos (FN). El modelo predijo que el cliente no abriría una cuenta, pero el cliente sí lo hizo. La esquina superior derecha muestra el número de falsos positivos (FP). El modelo predijo que el cliente abriría una cuenta, pero el cliente no no en realidad hacerlo.
Métricas del informe de calidad del modelo
El Informe de calidad del modelo explica cómo calcular el tasa de falsos positivos (FPR) y del Tasa de verdaderos positivos (TPR).
Tasa de recuperación o falsos positivos (FPR) mide la proporción de negativos reales que se predijeron falsamente al abrir una cuenta (positivos). El rango es de 0 a 1, y un valor menor indica una mejor precisión predictiva.

Tenga en cuenta que el FPR también se expresa como 1-Especificidad, donde la Especificidad o Tasa de Negativos Verdaderos (TNR) es la proporción de los TN correctamente identificados como que no abren una cuenta (negativos).

Recuperación/Sensibilidad/Tasa de verdaderos positivos (TPR) mide la fracción de positivos reales que se predijeron al abrir una cuenta. El rango también es de 0 a 1, y un valor mayor indica una mejor precisión predictiva. Esto también se conoce como Recuperación/Sensibilidad. Esta medida expresa la capacidad de encontrar todas las instancias relevantes en un conjunto de datos.
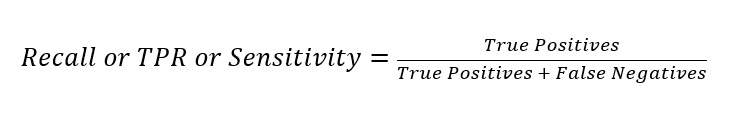
Precisión mide la fracción de positivos reales que se pronosticaron como positivos de todos los pronosticados como positivos. El rango es de 0 a 1, y un valor mayor indica una mayor precisión. La precisión expresa la proporción de los puntos de datos que nuestro modelo dice que eran relevantes y que realmente lo eran. La precisión es una buena medida a considerar, especialmente cuando los costos de FP son altos, por ejemplo, con la detección de correo no deseado.

Nuestro modelo muestra una precisión de 0.53 y una recuperación de 0.72.
Puntuación F1 demuestra nuestra métrica objetivo, que es la media armónica de precisión y recuperación. Debido a que nuestro conjunto de datos está desequilibrado a favor de muchas predicciones negativas, F1 tiene en cuenta tanto FP como FN para otorgar el mismo peso a la precisión y la recuperación.
El informe explica cómo interpretar estas métricas. Esto puede ayudar si no está familiarizado con estos términos. En nuestro ejemplo, la precisión y la recuperación son métricas importantes para un problema de clasificación binaria, ya que se utilizan para calcular la puntuación F1. El informe explica que una puntuación de F1 puede variar entre 0 y 1. El mejor rendimiento posible tendrá una puntuación de 1, mientras que 0 indicará el peor. Recuerda que la puntuación F1 de nuestro modelo es de 0.61.

Puntuación Fβ es la media armónica ponderada de precisión y recuperación. Además, la puntuación F1 es la misma que Fβ con β=1. El informe proporciona la puntuación Fβ del clasificador, donde β toma 0.5, 1 y 2.

Tabla de métricas
Según el problema, es posible que SageMaker Autopilot maximice otra métrica, como la precisión, para un problema de clasificación de varias clases. Independientemente del tipo de problema, los informes de calidad del modelo producen una tabla que resume las métricas de su modelo disponibles tanto en línea como en el informe PDF. Puede obtener más información sobre la tabla de métricas en el documentación.

El mejor clasificador constante, un clasificador que sirve como una línea de base simple para comparar con otros clasificadores más complejos, siempre predice una etiqueta de mayoría constante proporcionada por el usuario. En nuestro caso, un modelo 'constante' predeciría 'no', ya que esa es la clase más frecuente y se considera una etiqueta negativa. Las métricas de los modelos de clasificador entrenados (como f1, f2 o recuperación) se pueden comparar con las del clasificador constante, es decir, la línea de base. Esto asegura que el modelo entrenado funcione mejor que el clasificador constante. Las puntuaciones Fβ (f0_5, f1 y f2, donde β toma los valores de 0.5, 1 y 2 respectivamente) son la media armónica ponderada de precisión y recuperación. Esta alcanza su valor óptimo en 1 y su peor valor en 0.
En nuestro caso, el mejor clasificador constante siempre predice 'no'. Por lo tanto, la precisión es alta en 0.89, pero las puntuaciones de recuperación, precisión y Fβ son 0. Si el conjunto de datos está perfectamente equilibrado donde no hay una sola clase mayoritaria o minoritaria, habríamos visto posibilidades mucho más interesantes para la precisión, recuperación, y puntuaciones Fβ del clasificador constante.
Además, puede ver estos resultados en formato JSON como se muestra en el siguiente ejemplo. Puede acceder a los archivos PDF y JSON a través de la interfaz de usuario, así como SDK de Amazon SageMaker Python utilizando el elemento S3OutputPath en Configuración de datos de salida estructura en el Crear trabajo AutoML/DescribirAutoMLJob Respuesta de la API.
{ "version" : 0.0, "dataset" : { "item_count" : 9152, "evaluation_time" : "2022-03-16T20:49:18.661Z" }, "binary_classification_metrics" : { "confusion_matrix" : { "no" : { "no" : 7468, "yes" : 648 }, "yes" : { "no" : 295, "yes" : 741 } }, "recall" : { "value" : 0.7152509652509652, "standard_deviation" : 0.00439996600081394 }, "precision" : { "value" : 0.5334773218142549, "standard_deviation" : 0.007335840278445563 }, "accuracy" : { "value" : 0.8969624125874126, "standard_deviation" : 0.0011703516093899595 }, "recall_best_constant_classifier" : { "value" : 0.0, "standard_deviation" : 0.0 }, "precision_best_constant_classifier" : { "value" : 0.0, "standard_deviation" : 0.0 }, "accuracy_best_constant_classifier" : { "value" : 0.8868006993006993, "standard_deviation" : 0.0016707401772078998 }, "true_positive_rate" : { "value" : 0.7152509652509652, "standard_deviation" : 0.00439996600081394 }, "true_negative_rate" : { "value" : 0.9201577131591917, "standard_deviation" : 0.0010233756436643213 }, "false_positive_rate" : { "value" : 0.07984228684080828, "standard_deviation" : 0.0010233756436643403 }, "false_negative_rate" : { "value" : 0.2847490347490348, "standard_deviation" : 0.004399966000813983 },
………………….
República de China y ABC
Dependiendo del tipo de problema, puede tener diferentes umbrales para lo que es aceptable como FPR. Por ejemplo, si está tratando de predecir si un cliente abrirá una cuenta, entonces puede ser más aceptable para la empresa tener una tasa de FP más alta. Puede ser más arriesgado pasar por alto las ofertas a los clientes a los que se predijo incorrectamente "no", en lugar de ofrecer a los clientes a los que se predijo incorrectamente "sí". Cambiar estos umbrales para producir diferentes FPR requiere que cree nuevas matrices de confusión.
Los algoritmos de clasificación devuelven valores continuos conocidos como probabilidades de predicción. Estas probabilidades deben transformarse en un valor binario (para la clasificación binaria). En problemas de clasificación binaria, un umbral (o umbral de decisión) es un valor que dicotomiza las probabilidades a una decisión binaria simple. Para probabilidades proyectadas normalizadas en el rango de 0 a 1, el umbral se establece en 0.5 de manera predeterminada.
Para los modelos de clasificación binaria, una métrica de evaluación útil es el área bajo la curva de características operativas del receptor (ROC). El Informe de calidad del modelo incluye un gráfico ROC con la tasa de TP como el eje y y el FPR como el eje x. El área bajo la característica operativa del receptor (AUC-ROC) representa el compromiso entre los TPR y los FPR.
Una curva ROC se crea tomando un predictor de clasificación binaria, que utiliza un valor de umbral, y asignando etiquetas con probabilidades de predicción. A medida que varía el umbral de un modelo, cubre desde los dos extremos. Cuando tanto el TPR como el FPR son 0, implica que todo está etiquetado como "no", y cuando tanto el TPR como el FPR son 1, implica que todo está etiquetado como "sí".
Un predictor aleatorio que etiquete "Sí" la mitad de las veces y "No" la otra mitad de las veces tendría una ROC que es una línea diagonal recta (línea de puntos rojos). Esta línea corta el cuadrado unitario en dos triángulos de igual tamaño. Por lo tanto, el área bajo la curva es 0.5. Un valor AUC-ROC de 0.5 significaría que su predictor no fue mejor para discriminar entre las dos clases que adivinar al azar si un cliente abriría una cuenta o no. Cuanto más cerca esté el valor AUC-ROC de 1.0, mejores serán sus predicciones. Un valor por debajo de 0.5 indica que en realidad podríamos hacer que nuestro modelo produzca mejores predicciones invirtiendo la respuesta que nos da. Para nuestro mejor modelo, el AUC es 0.93.

Curva de recuperación de precisión
El informe de calidad del modelo también creó una curva de recuperación de precisión (PR) para trazar la precisión (eje y) y la recuperación (eje x) para diferentes umbrales, muy similar a la curva ROC. Las curvas PR, a menudo utilizadas en la recuperación de información, son una alternativa a las curvas ROC para problemas de clasificación con un gran sesgo en la distribución de clases.
Para estos conjuntos de datos de clase desequilibrada, las Curvas PR se vuelven especialmente útiles cuando la clase positiva minoritaria es más interesante que la clase negativa mayoritaria. Recuerda que nuestro modelo muestra una precisión de 0.53 y una recuperación de 0.72. Además, recuerda que el mejor clasificador constante no puede discriminar entre 'sí' y 'no'. Predeciría una clase aleatoria o una clase constante cada vez.
La curva para un conjunto de datos equilibrado entre 'sí' y 'no' sería una línea horizontal en 0.5 y, por lo tanto, tendría un área bajo la curva PR (AUPRC) de 0.5. Para crear el PRC, trazamos varios modelos en la curva en diferentes umbrales, de la misma manera que la curva ROC. Para nuestros datos, el AUPRC es 0.61.

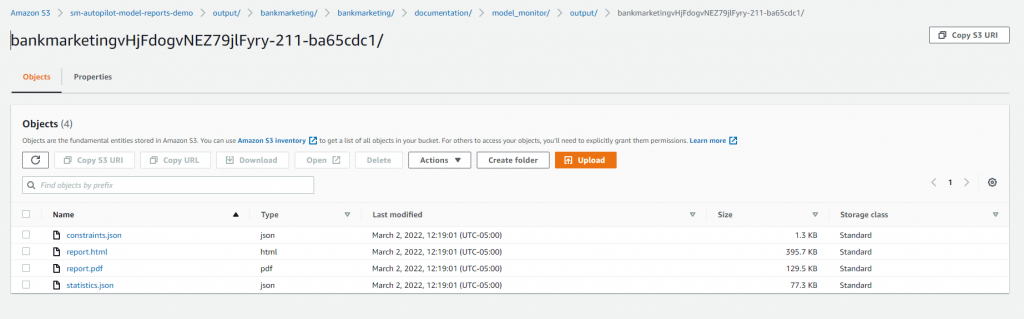
Salida del informe de calidad del modelo
Puede encontrar el Informe de calidad del modelo en el depósito de Amazon S3 que especificó al designar la ruta de salida antes de ejecutar el experimento de SageMaker AutoPilot. Encontrará los informes bajo el documentation/model_monitor/output/<autopilot model name>/ prefix guardado como PDF.
Conclusión
Los informes de calidad del modelo de SageMaker Autopilot le permiten ver y compartir rápidamente los resultados de un experimento de SageMaker Autopilot. Puede completar fácilmente la capacitación y el ajuste del modelo con SageMaker Autopilot y luego hacer referencia a los informes generados para interpretar los resultados. Ya sea que termine usando el mejor modelo de SageMaker Autopilot u otro candidato, estos resultados pueden ser un punto de partida útil para evaluar un trabajo preliminar de entrenamiento y ajuste del modelo. Los informes de calidad del modelo de SageMaker Autopilot ayudan a reducir el tiempo necesario para escribir código y producir imágenes para evaluar y comparar el rendimiento.
Puede incorporar fácilmente autoML en sus casos comerciales hoy sin tener que crear un equipo de ciencia de datos. SageMaker documentación proporciona numerosas muestras para ayudarle a empezar.
Acerca de los autores
 Pedro Chung es un arquitecto de soluciones para AWS y le apasiona ayudar a los clientes a descubrir información de sus datos. Ha estado creando soluciones para ayudar a las organizaciones a tomar decisiones basadas en datos tanto en el sector público como en el privado. Posee todas las certificaciones de AWS, así como dos certificaciones de GCP. Le gusta el café, cocinar, mantenerse activo y pasar tiempo con su familia.
Pedro Chung es un arquitecto de soluciones para AWS y le apasiona ayudar a los clientes a descubrir información de sus datos. Ha estado creando soluciones para ayudar a las organizaciones a tomar decisiones basadas en datos tanto en el sector público como en el privado. Posee todas las certificaciones de AWS, así como dos certificaciones de GCP. Le gusta el café, cocinar, mantenerse activo y pasar tiempo con su familia.
 Arunprasath Shankar es un arquitecto de soluciones especializado en inteligencia artificial y aprendizaje automático (AI / ML) en AWS, que ayuda a los clientes globales a escalar sus soluciones de inteligencia artificial de manera efectiva y eficiente en la nube. En su tiempo libre, a Arun le gusta ver películas de ciencia ficción y escuchar música clásica.
Arunprasath Shankar es un arquitecto de soluciones especializado en inteligencia artificial y aprendizaje automático (AI / ML) en AWS, que ayuda a los clientes globales a escalar sus soluciones de inteligencia artificial de manera efectiva y eficiente en la nube. En su tiempo libre, a Arun le gusta ver películas de ciencia ficción y escuchar música clásica.
 Ali Takbiri es un arquitecto de soluciones especialista en AI/ML y ayuda a los clientes mediante el uso de Machine Learning para resolver sus desafíos comerciales en la nube de AWS.
Ali Takbiri es un arquitecto de soluciones especialista en AI/ML y ayuda a los clientes mediante el uso de Machine Learning para resolver sus desafíos comerciales en la nube de AWS.
 Pradeep Reddy es gerente sénior de productos en el equipo de aprendizaje automático de código bajo/sin código de SageMaker, que incluye SageMaker Autopilot, SageMaker Automatic Model Tuner. Fuera del trabajo, a Pradeep le gusta leer, correr y divertirse con computadoras del tamaño de la palma de la mano como raspberry pi y otras tecnologías de automatización del hogar.
Pradeep Reddy es gerente sénior de productos en el equipo de aprendizaje automático de código bajo/sin código de SageMaker, que incluye SageMaker Autopilot, SageMaker Automatic Model Tuner. Fuera del trabajo, a Pradeep le gusta leer, correr y divertirse con computadoras del tamaño de la palma de la mano como raspberry pi y otras tecnologías de automatización del hogar.
- Coinsmart. El mejor intercambio de Bitcoin y criptografía de Europa.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. ACCESO LIBRE.
- CriptoHawk. Radar de altcoins. Prueba gratis.
- Fuente: https://aws.amazon.com/blogs/machine-learning/automatically-generate-model-evalue-metrics-using-sagemaker-autopilot-model-quality-reports/
- "
- 100
- 7
- Nuestra Empresa
- de la máquina
- Mi Cuenta
- lector activo
- avanzado
- AI
- algoritmos
- Todos
- Amazon
- entre
- Otra
- abejas
- Reservada
- artificial
- inteligencia artificial
- Inteligencia Artificial y Aprendizaje Automático
- atributos
- Automatización
- Hoy Disponibles
- AWS
- Banca
- Base
- a las que has recomendado
- MEJOR
- frontera
- Box
- build
- Construir la
- cases
- retos
- Elige
- clase
- privadas
- clasificación
- más cerca
- Soluciones
- código
- CAFÉ
- Columna
- en comparación con
- integraciones
- computadoras
- confusión
- contiene
- Precio
- podría
- creado
- Creamos
- curva
- Clientes
- datos
- Ciencia de los datos
- conjunto de datos
- demostrar
- desplegar
- Desplegando
- Detección
- HIZO
- una experiencia diferente
- directamente
- pasan fácilmente
- Punto final
- Ingeniería
- especialmente
- todo
- ejemplo
- experimento
- familia
- Feature
- Finalmente
- encuentra
- Nombre
- Flexibilidad
- Focus
- siguiendo
- formato
- generar
- Buscar
- candidato
- es
- ayuda
- serviciales
- ayuda
- Alta
- más alto
- mantiene
- Inicio
- Automatización del hogar
- Cómo
- Como Hacer
- HTTPS
- ICON
- Identidad
- importante
- incluir
- información
- Insights
- Intelligence
- IT
- Trabajos
- conocido
- Etiquetas
- large
- mayores
- APRENDE:
- aprendizaje
- Apalancamiento
- línea
- Escucha Activa
- Ubicación
- máquina
- máquina de aprendizaje
- Mayoría
- HACE
- Management
- gerente
- Marketing
- Matrix
- medir
- Métrica
- minoría
- ML
- modelo
- modelos
- más,
- MEJOR DE TU
- Películas
- Música
- número
- numeroso
- que ofrece
- Ofertas
- habiertos
- apertura
- funcionamiento
- Opciones
- para las fiestas.
- Otro
- apasionado
- (PDF)
- actuación
- punto
- positivo
- POSIBILIDADES
- posible
- posible
- predecir
- predicción
- Predicciones
- presente
- privada
- Problema
- problemas
- producir
- Producto
- Producción
- proporcionar
- proporciona un
- público
- calidad
- con rapidez
- distancia
- Reading
- reducir
- reporte
- Informes
- representa
- Recursos
- respuesta
- Resultados
- correr
- Escala
- Ciencia:
- Sectores
- set
- Compartir
- sencillos
- So
- Soluciones
- RESOLVER
- correo no deseado (spam)
- Gastos
- cuadrado
- fundó
- Estado
- STORAGE
- estudio
- Target
- equipo
- tecnología
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- equipo
- hoy
- TPR
- Formación
- trenes
- ui
- descubrir
- entender
- us
- utilizan el
- propuesta de
- diversos
- Ver
- la visibilidad
- sean
- QUIENES
- sin
- Actividades:
- se