Introducción
Embárquese en un viaje a través de la evolución de la inteligencia artificial y los asombrosos avances logrados en Procesamiento natural del lenguaje (PNL). En un abrir y cerrar de ojos, la IA ha surgido y está dando forma a nuestro mundo. El impacto sísmico del ajuste de grandes modelos lingüísticos ha transformado por completo la PNL, revolucionando nuestras interacciones tecnológicas. Retroceda hasta 2017, un momento crucial marcado por "La atención es todo lo que necesita", que dio origen a la innovadora arquitectura "Transformer". Esta arquitectura constituye ahora la piedra angular de la PNL, un ingrediente irreemplazable en toda receta de modelo de lenguaje grande, incluido el renombrado ChatGPT.

Imagine generar texto coherente y rico en contexto sin esfuerzo: esa es la magia de modelos como GPT-3. Potencias para chatbots, traducciones y generación de contenido, su brillantez surge de la arquitectura y la intrincada danza del entrenamiento previo y el ajuste. Nuestro próximo artículo profundiza en esta sinfonía, descubriendo el arte detrás del aprovechamiento de los modelos de lenguaje grandes para tareas, ejerciendo el dúo dinámico de preentrenamiento y ajuste para lograr un efecto magistral. ¡Únase a nosotros para desmitificar estas técnicas transformadoras!
OBJETIVOS DE APRENDIZAJE
- Comprenda las diferentes formas de crear aplicaciones LLM.
- Aprenda técnicas como extracción de características, ajuste de capas y métodos de adaptador.
- Ajuste LLM en una tarea posterior utilizando la biblioteca de transformadores Huggingface.
Tabla de contenidos.
Comenzando con los LLM
LLM significa Grandes modelos de lenguaje. Los LLM son modelos de aprendizaje profundo diseñados para comprender el significado de texto similar a un humano y realizar diversas tareas, como análisis de sentimientos, modelado de lenguaje (predicción de la siguiente palabra), generación de texto, resumen de texto y mucho más. Están entrenados con una gran cantidad de datos de texto.
Utilizamos aplicaciones basadas en estos LLM a diario sin siquiera darnos cuenta. Google utiliza BERT (Representaciones de codificador bidireccional para transformadores) para diversas aplicaciones, como completar consultas, comprender el contexto de las consultas, generar resultados de búsqueda más relevantes y precisos, traducción de idiomas y más.
Estos modelos se basan en técnicas de aprendizaje profundo, redes neuronales profundas y técnicas avanzadas como la autoatención. Están capacitados con grandes cantidades de datos de texto para aprender los patrones, estructuras y semántica del idioma.
Dado que estos modelos se entrenan en conjuntos de datos extensos, se necesita mucho tiempo y recursos para entrenarlos, y no tiene sentido entrenarlos desde cero.
Existen técnicas mediante las cuales podemos utilizar directamente estos modelos para una tarea específica. Así que analicémoslos en detalle.
Descripción general de diferentes formas de crear aplicaciones LLM
A menudo vemos interesantes aplicaciones de LLM en la vida cotidiana. ¿Tiene curiosidad por saber cómo crear aplicaciones LLM? Estas son las 3 formas de crear aplicaciones LLM:
- Formación de LLM desde cero
- Ajuste de modelos de lenguaje grandes
- Incitación
Formación de LLM desde cero
La gente suele confundirse entre estas dos terminologías: formación y perfeccionamiento de LLM. Ambas técnicas funcionan de manera similar, es decir, cambian los parámetros del modelo, pero los objetivos de entrenamiento son diferentes.
La formación de LLM desde cero también se conoce como formación previa. El preentrenamiento es la técnica en la que se entrena un modelo de lenguaje grande en una gran cantidad de texto sin etiquetar. Pero la pregunta es: "¿Cómo podemos entrenar un modelo con datos sin etiquetar y luego esperar que el modelo prediga los datos con precisión?". De aquí surge el concepto de “Aprendizaje Autosupervisado”. En el aprendizaje autosupervisado, un modelo enmascara una palabra e intenta predecir la siguiente palabra con la ayuda de las palabras anteriores. Por ejemplo, supongamos que tenemos una oración: "Soy un científico de datos".
El modelo puede crear sus propios datos etiquetados a partir de esta oración como:
| Texto | Label |
| I | am |
| Soy | a |
| Soy un | datos |
| soy un dato | Científico |
Esto se conoce como predicción del próximo trabajo, realizada por un MLM (Modelo de lenguaje enmascarado). BERT, un modelo de lenguaje enmascarado, utiliza esta técnica para predecir la palabra enmascarada. Podemos pensar en MLM como un concepto de "completar espacios en blanco", en el que el modelo predice qué palabra cabe en el espacio en blanco.
Hay diferentes formas de predecir la siguiente palabra, pero en este artículo solo hablamos de BERT, el MLM. BERT puede observar las palabras anteriores y siguientes para comprender el contexto de la oración y predecir la palabra enmascarada.
Entonces, como descripción general de alto nivel del preentrenamiento, es solo una técnica en la que el modelo aprende a predecir la siguiente palabra del texto.
Ajuste de modelos de lenguaje grandes
El ajuste fino consiste en modificar los parámetros del modelo para que sea adecuado para realizar una tarea específica. Después de entrenar previamente el modelo, se afina o, en palabras simples, se entrena para realizar una tarea específica como análisis de sentimientos, generación de texto, búsqueda de similitudes de documentos, etc. No tenemos que entrenar el modelo nuevamente en un texto grande; más bien, utilizamos el modelo entrenado para realizar una tarea que queremos realizar. Analizaremos en detalle cómo ajustar un modelo de lenguaje grande más adelante en este artículo.
Incitación
Las indicaciones son la más fácil de las tres técnicas, pero un poco complicadas. Implica darle al modelo un contexto (solicitud) basado en el cual el modelo realiza tareas. Piense en ello como enseñarle a un niño un capítulo de su libro en detalle, siendo muy discreto acerca de la explicación y luego pidiéndole que resuelva el problema relacionado con ese capítulo.
En el contexto de LLM, tomemos, por ejemplo, ChatGPT; Establecemos un contexto y le pedimos al modelo que siga las instrucciones para resolver el problema dado.
Supongamos que quiero que ChatGPT me haga algunas preguntas de la entrevista solo sobre Transformers. Para una mejor experiencia y resultados precisos, debe establecer un contexto adecuado y brindar una descripción detallada de la tarea.
Ejemplo: Soy Científico de Datos con dos años de experiencia y actualmente me estoy preparando para una entrevista de trabajo en tal o cual empresa. Me encanta resolver problemas y actualmente trabajo con modelos de PNL de última generación. Estoy al día de las últimas tendencias y tecnologías. Hágame preguntas muy difíciles sobre el modelo Transformer que el entrevistador de esta empresa pueda hacer en función de la experiencia previa de la empresa. Hazme diez preguntas y también da las respuestas a las preguntas.
Cuanto más detallada y específica solicite, mejores serán los resultados. La parte más divertida es que puedes generar el mensaje a partir del propio modelo y luego agregar un toque personal o la información necesaria.
Comprender diferentes técnicas de ajuste
Hay diferentes formas de ajustar un modelo de forma convencional y los diferentes enfoques dependen del problema específico que se desea resolver.
Analicemos las técnicas para ajustar un modelo.
Hay 3 formas de perfeccionar convencionalmente un LLM.
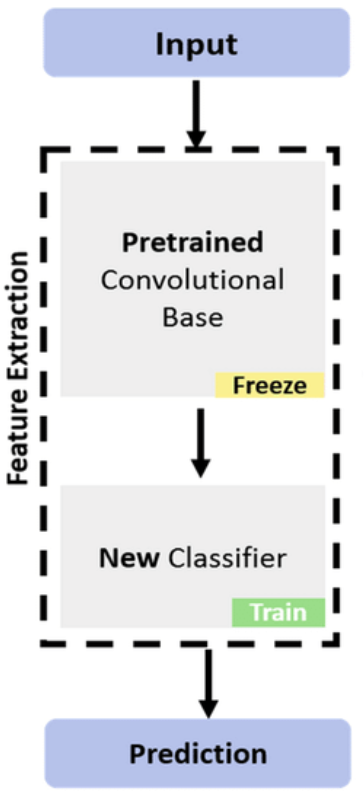
La gente usa esta técnica para extraer características de un texto determinado, pero ¿por qué queremos extraer incrustaciones de un texto determinado? La respuesta es sencilla. Debido a que las computadoras no comprenden texto, es necesario que haya una representación del texto que podamos usar para realizar diversas tareas. Una vez que extraemos las incrustaciones, son capaces de realizar tareas como análisis de sentimientos, identificar similitudes de documentos y más. En la extracción de características, bloqueamos las capas principales del modelo, lo que significa que no actualizamos los parámetros de esas capas; solo se actualizan los parámetros de las capas del clasificador. Las capas clasificadoras involucran las capas completamente conectadas.
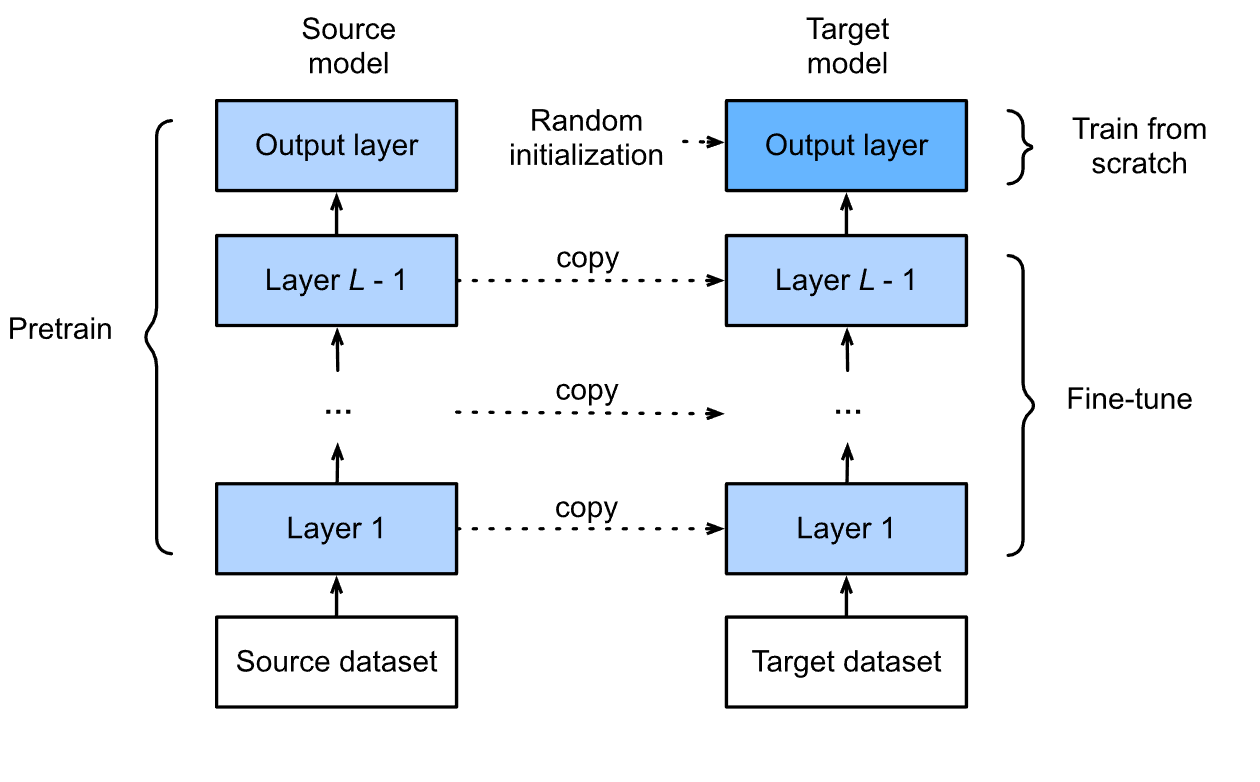
Ajuste completo del modelo
Como sugiere el nombre, entrenamos cada capa del modelo en el conjunto de datos personalizado para una cantidad específica de épocas en esta técnica. Ajustamos los parámetros de todas las capas del modelo de acuerdo con el nuevo conjunto de datos personalizado. Esto puede mejorar la precisión del modelo sobre los datos y la tarea específica que queremos realizar. Es computacionalmente costoso y lleva mucho tiempo entrenar el modelo, considerando que hay miles de millones de parámetros en el ajuste de los modelos de lenguajes grandes.
Ajuste fino basado en adaptador
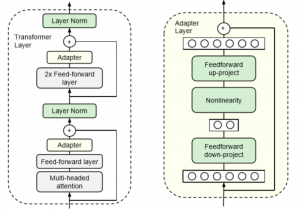
El ajuste fino basado en adaptadores es un concepto comparativamente nuevo en el que se agrega a la red una capa adicional inicializada aleatoriamente o un módulo y luego se entrena para una tarea específica. En esta técnica, los parámetros del modelo no se modifican, o podemos decir que los parámetros del modelo no se cambian ni se ajustan. Más bien, se entrenan los parámetros de la capa del adaptador. Esta técnica ayuda a ajustar el modelo de una manera computacionalmente eficiente.
Implementación: ajuste de BERT en una tarea posterior
Ahora que conocemos las técnicas de ajuste, realicemos un análisis de sentimiento en las reseñas de películas de IMDB utilizando BERT. BERT es un modelo de lenguaje grande que combina capas transformadoras y es solo codificador. Google lo desarrolló y ha demostrado funcionar muy bien en diversas tareas. BERT viene en diferentes tamaños y variantes, como BERT-base-uncased, BERT Large, RoBERTa, LegalBERT y muchos más.
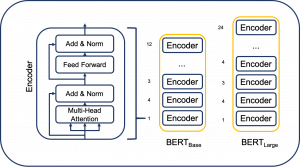
Modelo BERT para realizar análisis de sentimiento
Utilicemos el modelo BERT para realizar un análisis de sentimiento en reseñas de películas de IMDB. Para disponibilidad gratuita de GPU, se recomienda utilizar Google Colab. Comencemos la capacitación cargando algunas bibliotecas importantes.
Dado que BERT (Representaciones de codificador bidireccional para codificadores) se basa en Transformers, el primer paso sería instalar transformadores en nuestro entorno.
! pip instalar transformadores
Carguemos algunas bibliotecas que nos ayudarán a cargar los datos según lo requiere el modelo BERT, tokenizar los datos cargados, cargar el modelo que usaremos para la clasificación, realizar train-test-split, cargar nuestro archivo CSV y algunas funciones más.
import pandas as pd
import numpy as np
import os
from sklearn.model_selection import train_test_split
import torch
import torch.nn as nn
from transformers import BertTokenizer, BertModel
Para un cálculo más rápido, tenemos que cambiar el dispositivo de CPU a GPU.
device = torch.device("cuda")El siguiente paso sería cargar nuestro conjunto de datos y observar los primeros 5 registros del conjunto de datos.
df = pd.read_csv('/content/drive/MyDrive/movie.csv')
df.head()
Dividiremos nuestro conjunto de datos en conjuntos de entrenamiento y validación. También puede dividir los datos en conjuntos de entrenamiento, validación y prueba, pero en aras de la simplicidad, solo estoy dividiendo el conjunto de datos en entrenamiento y validación.
x_train, x_val, y_train, y_val = train_test_split(df.text, df.label, random_state = 42, test_size = 0.2, stratify = df.label)
Importar y cargar el modelo BERT
Importemos y carguemos el modelo BERT y el tokenizador.
from transformers.models.bert.modeling_bert import BertForSequenceClassification
# import BERT-base pretrained model
BERT = BertModel.from_pretrained('bert-base-uncased')
# Load the BERT tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
Usaremos el tokenizador para convertir el texto en tokens con una longitud máxima de 250 y relleno y truncamiento cuando sea necesario.
train_tokens = tokenizer.batch_encode_plus(x_train.tolist(), max_length = 250, pad_to_max_length=True, truncation=True)
val_tokens = tokenizer.batch_encode_plus(x_val.tolist(), max_length = 250, pad_to_max_length=True, truncation=True)
El tokenizador devuelve un diccionario con tres pares clave-valor que contienen input_ids, que son los tokens relacionados con una palabra en particular; token_type_ids, que es una lista de números enteros que distinguen entre diferentes segmentos o partes de la entrada. Y atención_mask que indica a qué token atender.
Convirtiendo estos valores en tensores
train_ids = torch.tensor(train_tokens['input_ids'])
train_masks = torch.tensor(train_tokens['attention_mask'])
train_label = torch.tensor(y_train.tolist())
val_ids = torch.tensor(val_tokens['input_ids'])
val_masks = torch.tensor(val_tokens['attention_mask'])
val_label = torch.tensor(y_val.tolist())
Cargando TensorDataset y DataLoaders para preprocesar aún más los datos y hacerlos adecuados para el modelo.
from torch.utils.data import TensorDataset, DataLoader
train_data = TensorDataset(train_ids, train_masks, train_label)
val_data = TensorDataset(val_ids, val_masks, val_label)
train_loader = DataLoader(train_data, batch_size = 32, shuffle = True)
val_loader = DataLoader(val_data, batch_size = 32, shuffle = True)
Nuestra tarea es congelar los parámetros de BERT usando nuestro clasificador y luego ajustar esas capas en nuestro conjunto de datos personalizado. Entonces, congelemos los parámetros del modelo.
para parámetro en BERT.parameters():
param.requires_grad = Falso
Ahora tendremos que definir el paso hacia adelante y hacia atrás para las capas que hemos agregado. El modelo BERT actuará como un extractor de características, mientras que tendremos que definir explícitamente los pases hacia adelante y hacia atrás para la clasificación.
class Model(nn.Module): def __init__(self, bert): super(Model, self).__init__() self.bert = bert self.dropout = nn.Dropout(0.1) self.relu = nn.ReLU() self.fc1 = nn.Linear(768, 512) self.fc2 = nn.Linear(512, 2) self.softmax = nn.LogSoftmax(dim=1) def forward(self, sent_id, mask): # Pass the inputs to the model outputs = self.bert(sent_id, mask) cls_hs = outputs.last_hidden_state[:, 0, :] x = self.fc1(cls_hs) x = self.relu(x) x = self.dropout(x) x = self.fc2(x) x = self.softmax(x) return x
Movamos el modelo a GPU.
model = Model(BERT)
# push the model to GPU
model = model.to(device)
Definición del optimizador
# optimizer from hugging face transformers
from transformers import AdamW
# define the optimizer
optimizer = AdamW(model.parameters(),lr = 1e-5)
Hasta ahora, hemos preprocesado el conjunto de datos y definido nuestro modelo. Ahora es el momento de entrenar el modelo. Tenemos que escribir un código para entrenar y evaluar el modelo.
La función del tren:
def train(): model.train() total_loss, total_accuracy = 0, 0 total_preds = [] for step, batch in enumerate(train_loader): # Move batch to GPU if available batch = [item.to(device) for item in batch] sent_id, mask, labels = batch # Clear previously calculated gradients optimizer.zero_grad() # Get model predictions for the current batch preds = model(sent_id, mask) # Calculate the loss between predictions and labels loss_function = nn.CrossEntropyLoss() loss = loss_function(preds, labels) # Add to the total loss total_loss += loss.item() # Backward pass and gradient update loss.backward() optimizer.step() # Move predictions to CPU and convert to numpy array preds = preds.detach().cpu().numpy() # Append the model predictions total_preds.append(preds) # Compute the average loss avg_loss = total_loss / len(train_loader) # Concatenate the predictions total_preds = np.concatenate(total_preds, axis=0) # Return the average loss and predictions return avg_loss, total_preds
La función de evaluación
def evaluate(): model.eval() total_loss, total_accuracy = 0, 0 total_preds = [] for step, batch in enumerate(val_loader): # Move batch to GPU if available batch = [item.to(device) for item in batch] sent_id, mask, labels = batch # Clear previously calculated gradients optimizer.zero_grad() # Get model predictions for the current batch preds = model(sent_id, mask) # Calculate the loss between predictions and labels loss_function = nn.CrossEntropyLoss() loss = loss_function(preds, labels) # Add to the total loss total_loss += loss.item() # Backward pass and gradient update loss.backward() optimizer.step() # Move predictions to CPU and convert to numpy array preds = preds.detach().cpu().numpy() # Append the model predictions total_preds.append(preds) # Compute the average loss avg_loss = total_loss / len(val_loader) # Concatenate the predictions total_preds = np.concatenate(total_preds, axis=0) # Return the average loss and predictions return avg_loss, total_preds
Ahora usaremos estas funciones para entrenar el modelo:
# set initial loss to infinite
best_valid_loss = float('inf')
#defining epochs
epochs = 5
# empty lists to store training and validation loss of each epoch
train_losses=[]
valid_losses=[]
#for each epoch
for epoch in range(epochs): print('n Epoch {:} / {:}'.format(epoch + 1, epochs)) #train model train_loss, _ = train() #evaluate model valid_loss, _ = evaluate() #save the best model if valid_loss < best_valid_loss: best_valid_loss = valid_loss torch.save(model.state_dict(), 'saved_weights.pt') # append training and validation loss train_losses.append(train_loss) valid_losses.append(valid_loss) print(f'nTraining Loss: {train_loss:.3f}') print(f'Validation Loss: {valid_loss:.3f}')
Y ahí lo tienes. Puede utilizar su modelo entrenado para inferir cualquier dato o texto que elija.
Conclusión
Este artículo exploró el mundo del ajuste de los modelos de lenguaje grande (LLM) y su impacto significativo en el procesamiento del lenguaje natural (NLP). Analice el proceso de formación previa, en el que los LLM se capacitan en grandes cantidades de texto sin etiquetar mediante el aprendizaje autosupervisado. También profundizamos en el ajuste, que implica adaptar un modelo previamente entrenado para tareas específicas e indicaciones, donde los modelos reciben contexto para generar resultados relevantes. Además, examinamos diferentes técnicas de ajuste, como la extracción de características, el ajuste de modelo completo y el ajuste basado en adaptadores. Los modelos de lenguaje grandes han revolucionado la PNL y continúan impulsando avances en diversas aplicaciones.
Preguntas frecuentes
R. Los LLM emplean técnicas de aprendizaje autosupervisadas como el modelado de lenguaje enmascarado, donde predicen la siguiente palabra en función del contexto de las palabras circundantes, creando efectivamente datos etiquetados a partir de texto sin etiquetar.
R. El ajuste permite a los LLM adaptarse a tareas específicas ajustando sus parámetros, haciéndolos adecuados para tareas de análisis de sentimientos, generación de texto o similitud de documentos. Se basa en el conocimiento previamente entrenado del modelo.
R. Las indicaciones implican proporcionar contexto o instrucciones a los LLM para generar resultados relevantes. Los usuarios pueden guiar el modelo para responder preguntas, generar texto o realizar tareas específicas según el contexto dado configurando un mensaje específico.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- ChartPrime. Eleve su juego comercial con ChartPrime. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/08/finetuning-large-language-models-llms/
- :posee
- :es
- :no
- :dónde
- $ UP
- 1
- 11
- 12
- 14
- 167
- 2017
- 225
- 250
- 300
- 32
- a
- Nuestra Empresa
- Conforme
- la exactitud
- preciso
- precisamente
- Actúe
- adaptar
- add
- adicional
- Adicionales
- Adicionalmente
- avanzado
- avances
- Después
- de nuevo
- AI
- Todos
- permite
- también
- am
- cantidad
- cantidades
- an
- análisis
- y
- https://www.youtube.com/watch?v=xB-eutXNUMXJtA&feature=youtu.be
- respuestas
- cualquier
- aplicaciones
- enfoques
- arquitectura
- somos
- Formación
- artículo
- artificial
- inteligencia artificial
- arte
- AS
- preguntaron
- At
- asistir
- disponibilidad
- Hoy Disponibles
- promedio
- Columna vertebral
- basado
- BE
- porque
- Principiantes
- detrás de
- "Ser"
- MEJOR
- mejores
- entre
- miles de millones
- Poco
- Blink
- primer libro
- ambas
- build
- construye
- construido
- pero
- by
- calcular
- calculado
- PUEDEN
- capaz
- llevar
- el cambio
- cambiado
- Capítulo
- Chatbots
- ChatGPT
- sus hijos
- Elige
- clasificación
- limpiar
- código
- COHERENTE
- combina
- proviene
- compañía
- De la empresa
- relativamente
- terminación
- comprender
- cálculo
- Calcular
- computadoras
- concepto
- confundido
- conectado
- en vista de
- contenido
- contexto
- continue
- convertir
- piedra angular
- CPU
- Para crear
- Creamos
- curioso
- Current
- En la actualidad
- personalizado
- todos los días
- danza
- datos
- científico de datos
- conjuntos de datos
- Fecha
- día
- profundo
- deep learning
- definir
- se define
- descripción
- diseñado
- detalle
- detallado
- desarrollado
- dispositivo
- una experiencia diferente
- directamente
- discutir
- distinguir
- do
- documento
- sí
- hecho
- el lado de la transmisión
- lugar de trabajo dinámico
- e
- cada una
- fácil
- efecto
- de manera eficaz
- eficiente
- sin esfuerzo
- Entorno
- época
- épocas
- etc.
- Éter (ETH)
- evaluar
- evaluación
- Incluso
- Cada
- evolución
- ejemplo
- emocionante
- esperar
- costoso
- experience
- explicación
- explorado
- en los detalles
- extraerlos
- Extracción
- Cara
- más rápida
- Feature
- Caracteristicas
- Archive
- la búsqueda de
- Nombre
- cómodo
- seguir
- Formularios
- adelante
- Gratis
- Congelar
- Desde
- ser completados
- completamente
- diversión
- función
- funciones
- promover
- generar
- la generación de
- generación de AHSS
- obtener
- Donar
- dado
- Diezmos y Ofrendas
- GPU
- gradientes
- innovador
- guía
- Tienen
- ayuda
- ayuda
- esta página
- de alto nivel
- Cómo
- Como Hacer
- HTTPS
- enorme
- AbrazandoCara
- i
- identificar
- if
- Impacto
- implementación
- importar
- importante
- mejorar
- in
- Incluye
- Indica
- información
- inicial
- Las opciones de entrada
- entradas
- instalar
- Instrucciones
- Intelligence
- interacciones
- Entrevista
- preguntas de entrevista
- Entrevistadora
- dentro
- Introducción
- involucrar
- implica
- IT
- SUS
- sí mismo
- Trabajos
- únete
- Unáse con nosotros
- solo
- Saber
- especialistas
- conocido
- Label
- Etiquetas
- idioma
- large
- luego
- más reciente
- .
- ponedoras
- APRENDE:
- aprendizaje
- izquierda
- Longitud Mínima
- dejar
- aprovechando
- bibliotecas
- Biblioteca
- Vida
- como
- Lista
- Listas
- carga
- carga
- Mira
- de
- Lote
- amar
- hecho
- magic
- para lograr
- Realizar
- manera
- muchos
- marcado
- máscara
- Mascarillas
- max-ancho
- máximas
- me
- sentido
- mero
- métodos
- modelo
- modelado
- modelos
- módulo
- momento
- más,
- MEJOR DE TU
- movimiento
- película
- mucho más
- nombre
- Natural
- Lenguaje natural
- Procesamiento natural del lenguaje
- ¿ Necesita ayuda
- del sistema,
- telecomunicaciones
- Neural
- redes neuronales
- Nuevo
- Next
- nlp
- ahora
- número
- numpy
- ,
- of
- a menudo
- on
- una vez
- , solamente
- or
- OS
- "nuestr
- salir
- salida
- visión de conjunto
- EL DESARROLLADOR
- pares
- Los pandas
- parámetros
- parte
- particular
- partes
- pass
- pasa
- .
- realizar
- realizar
- realiza
- con
- esencial
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- potencias
- predecir
- predicción
- Predicciones
- Predice
- preparación
- anterior
- previamente
- Problema
- la resolución de problemas
- tratamiento
- un profundo
- apropiado
- probado
- previsto
- proporcionando
- propósito
- Push
- consultas
- pregunta
- Preguntas
- más bien
- realización
- recetas
- recomendado
- archivos
- relacionado
- Renombrado
- representación
- Requisitos
- Recursos
- Resultados
- volvemos
- devoluciones
- Reseñas
- revolucionado
- Revolucionando
- Rewind
- sake
- dices
- Científico
- rayar
- Buscar
- ver
- segmentos
- AUTO
- semántica
- sentido
- sentencia
- sentimiento
- set
- Sets
- pólipo
- la formación
- barajar
- significado
- importante
- similares
- sencillos
- sencillez
- tamaños
- So
- RESOLVER
- algo
- soluciones y
- dividido
- es la
- comienzo
- fundó
- el estado de la técnica
- deriva
- paso
- tienda
- sencillo
- zancadas
- estructuras
- tal
- Sugiere
- adecuado
- Surged
- Rodeando
- sinfonía
- mesa
- ¡Prepárate!
- toma
- escuchar
- Tarea
- tareas
- Educación
- técnicas
- tecnológico
- Tecnologías
- diez
- test
- generación de texto
- esa
- La
- la información
- el mundo
- su
- Les
- luego
- Ahí.
- Estas
- ellos
- Pensar
- así
- aquellos
- Tres
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- equipo
- a
- ficha
- tokenize
- Tokens
- antorcha
- Total
- contacto
- difícil
- Entrenar
- entrenado
- Formación
- transformador
- transformado
- transformador
- transformers
- Traducción
- Traducciones
- Tendencias
- verdadero
- truncamiento
- pellizcar
- dos
- entender
- comprensión
- próximos
- Actualizar
- actualizado
- a
- us
- utilizan el
- usuarios
- usos
- usando
- validación
- Valores
- diversos
- Vasto
- muy
- quieres
- Camino..
- formas
- we
- webp
- WELL
- ¿
- Que es
- cuando
- que
- mientras
- porque
- seguirá
- sin
- Palabra
- palabras
- Actividades:
- trabajando
- mundo
- se
- escribir
- X
- años
- Usted
- tú
- zephyrnet