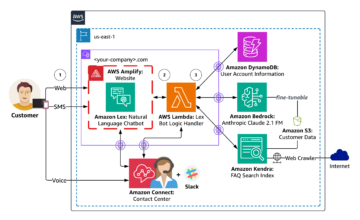
Amazon SageMaker es un servicio de aprendizaje automático (ML) completamente administrado. Con SageMaker, los científicos de datos y los desarrolladores pueden crear y entrenar modelos de aprendizaje automático de forma rápida y sencilla, y luego implementarlos directamente en un entorno alojado listo para la producción. Proporciona una instancia de notebook de creación de Jupyter integrada para acceder fácilmente a sus fuentes de datos para exploración y análisis, de modo que no tenga que administrar servidores. También proporciona común Algoritmos ML que están optimizados para ejecutarse de manera eficiente contra datos extremadamente grandes en un entorno distribuido.
La inferencia en tiempo real de SageMaker es ideal para cargas de trabajo que tienen requisitos de baja latencia, interactivos y en tiempo real. Con la inferencia en tiempo real de SageMaker, puede implementar puntos finales REST que están respaldados por un tipo de instancia específico con una cierta cantidad de cómputo y memoria. La implementación de un terminal en tiempo real de SageMaker es solo el primer paso en el camino hacia la producción para muchos clientes. Queremos poder maximizar el rendimiento del punto final para lograr un objetivo de transacciones por segundo (TPS) mientras cumplimos con los requisitos de latencia. Una gran parte de la optimización del rendimiento para la inferencia es asegurarse de seleccionar el tipo de instancia adecuado y contar para respaldar un punto final.
Esta publicación describe las mejores prácticas para realizar pruebas de carga en un extremo de SageMaker a fin de encontrar la configuración adecuada para la cantidad de instancias y el tamaño. Esto puede ayudarnos a comprender los requisitos mínimos de instancias aprovisionadas para cumplir con nuestros requisitos de latencia y TPS. A partir de ahí, nos sumergimos en cómo puede rastrear y comprender las métricas y el rendimiento del punto final de SageMaker utilizando Reloj en la nube de Amazon métrica.
Primero comparamos el rendimiento de nuestro modelo en una sola instancia para identificar el TPS que puede manejar según nuestros requisitos de latencia aceptables. Luego, extrapolamos los hallazgos para decidir la cantidad de instancias que necesitamos para manejar nuestro tráfico de producción. Finalmente, simulamos el tráfico de nivel de producción y configuramos pruebas de carga para un punto final de SageMaker en tiempo real para confirmar que nuestro punto final puede manejar la carga de nivel de producción. El conjunto completo de código para el ejemplo está disponible en el siguiente Repositorio GitHub.
Resumen de la solución
Para esta publicación, desplegamos un Cara abrazadora modelo DistilBERT del desplegable abrazando la cara hub. Este modelo puede realizar una serie de tareas, pero enviamos una carga útil específicamente para el análisis de opiniones y la clasificación de textos. Con esta carga útil de muestra, nos esforzamos por lograr 1000 TPS.
Implementar un punto final en tiempo real
Esta publicación asume que está familiarizado con la implementación de un modelo. Referirse a Cree su punto final e implemente su modelo para comprender los aspectos internos detrás del alojamiento de un punto final. Por ahora, podemos apuntar rápidamente a este modelo en Hugging Face Hub e implementar un punto final en tiempo real con el siguiente fragmento de código:
Probemos nuestro punto final rápidamente con la carga útil de muestra que queremos usar para la prueba de carga:

Tenga en cuenta que estamos respaldando el punto final usando un único Nube informática elástica de Amazon (Amazon EC2) instancia de tipo ml.m5.12xlarge, que contiene 48 vCPU y 192 GiB de memoria. La cantidad de vCPU es una buena indicación de la simultaneidad que puede manejar la instancia. En general, se recomienda probar diferentes tipos de instancias para asegurarnos de que tenemos una instancia que tiene recursos que se utilizan correctamente. Para ver una lista completa de las instancias de SageMaker y su potencia informática correspondiente para la inferencia en tiempo real, consulte Precios de Amazon SageMaker.
Métricas a seguir
Antes de que podamos entrar en las pruebas de carga, es esencial comprender qué métricas rastrear para comprender el desglose del rendimiento de su terminal de SageMaker. CloudWatch es la principal herramienta de registro que utiliza SageMaker para ayudarlo a comprender las diferentes métricas que describen el rendimiento de su terminal. Puede utilizar registros de CloudWatch para depurar sus invocaciones de punto final; todas las declaraciones de registro e impresión que tiene en su código de inferencia se capturan aquí. Para obtener más información, consulte Cómo funciona Amazon CloudWatch.
Hay dos tipos diferentes de métricas que cubre CloudWatch para SageMaker: métricas de nivel de instancia y de invocación.
Métricas a nivel de instancia
El primer conjunto de parámetros a considerar son las métricas a nivel de instancia: CPUUtilization y MemoryUtilization (para instancias basadas en GPU, GPUUtilization). por CPUUtilization, es posible que vea porcentajes superiores al 100 % al principio en CloudWatch. Es importante darse cuenta por CPUUtilization, se muestra la suma de todos los núcleos de la CPU. Por ejemplo, si la instancia detrás de su endpoint contiene 4 vCPU, esto significa que el rango de utilización es de hasta 400 %. MemoryUtilization, por otro lado, está en el rango de 0-100%.
Específicamente, puede usar CPUUtilization para obtener una comprensión más profunda de si tiene suficiente o incluso una cantidad excesiva de hardware. Si tiene una instancia infrautilizada (menos del 30 %), podría reducir potencialmente su tipo de instancia. Por el contrario, si tiene una utilización de alrededor del 80-90 %, sería beneficioso elegir una instancia con mayor cómputo/memoria. De nuestras pruebas, sugerimos alrededor de 60-70% de utilización de su hardware.
Métricas de invocación
Como sugiere el nombre, las métricas de invocación es donde podemos rastrear la latencia de extremo a extremo de cualquier invocación a su punto final. Puede utilizar las métricas de invocación para capturar recuentos de errores y qué tipo de errores (5xx, 4xx, etc.) puede experimentar su terminal. Más importante aún, puede comprender el desglose de latencia de sus llamadas de punto final. Mucho de esto se puede capturar con ModelLatency y OverheadLatency métricas, como se ilustra en el siguiente diagrama.

El ModelLatency La métrica captura el tiempo que toma la inferencia dentro del contenedor del modelo detrás de un punto final de SageMaker. Tenga en cuenta que el contenedor del modelo también incluye cualquier código de inferencia personalizado o secuencias de comandos que haya pasado para la inferencia. Esta unidad se captura en microsegundos como una métrica de invocación y, por lo general, puede graficar un percentil en CloudWatch (p99, p90, etc.) para ver si está alcanzando su latencia objetivo. Tenga en cuenta que varios factores pueden afectar la latencia del modelo y del contenedor, como los siguientes:
- Guión de inferencia personalizado – Ya sea que haya implementado su propio contenedor o haya usado un contenedor basado en SageMaker con controladores de inferencia personalizados, es una buena práctica crear un perfil de su secuencia de comandos para detectar cualquier operación que agregue específicamente mucho tiempo a su latencia.
- Protocolo de comunicación – Considere las conexiones REST frente a gRPC al servidor modelo dentro del contenedor modelo.
- Optimizaciones del marco del modelo – Esto es específico del marco, por ejemplo con TensorFlow, hay una serie de variables de entorno que puede ajustar que son específicas de TF Serving. Asegúrese de verificar qué contenedor está utilizando y si hay optimizaciones específicas del marco que puede agregar dentro del script o como variables de entorno para inyectar en el contenedor.
OverheadLatency se mide desde el momento en que SageMaker recibe la solicitud hasta que devuelve una respuesta al cliente, menos la latencia del modelo. Esta parte está en gran parte fuera de su control y cae dentro del tiempo que tardan los gastos generales de SageMaker.
La latencia de extremo a extremo en su conjunto depende de una variedad de factores y no es necesariamente la suma de ModelLatency más OverheadLatency. Por ejemplo, si su cliente está haciendo la InvokeEndpoint Llamada API a través de Internet, desde la perspectiva del cliente, la latencia de extremo a extremo sería Internet + ModelLatency + OverheadLatency. Por lo tanto, cuando realice una prueba de carga de su punto final para comparar con precisión el propio punto final, se recomienda centrarse en las métricas del punto final (ModelLatency, OverheadLatencyy InvocationsPerInstance) para comparar con precisión el extremo de SageMaker. Cualquier problema relacionado con la latencia de un extremo a otro se puede aislar por separado.
Algunas preguntas a tener en cuenta para la latencia de extremo a extremo:
- ¿Dónde está el cliente que está invocando su punto final?
- ¿Existen capas intermedias entre su cliente y el tiempo de ejecución de SageMaker?
Escalado automático
No cubrimos específicamente el escalado automático en esta publicación, pero es una consideración importante para aprovisionar la cantidad correcta de instancias según la carga de trabajo. Dependiendo de sus patrones de tráfico, puede adjuntar un política de escalado automático a su terminal de SageMaker. Hay diferentes opciones de escalado, como TargetTrackingScaling, SimpleScalingy StepScaling. Esto permite que su punto final se escale hacia adentro y hacia afuera automáticamente en función de su patrón de tráfico.
Una opción común es el seguimiento de objetivos, donde puede especificar una métrica de CloudWatch o una métrica personalizada que haya definido y escalar en función de eso. Una utilización frecuente del escalado automático es el seguimiento de InvocationsPerInstance métrico. Una vez que haya identificado un cuello de botella en un determinado TPS, a menudo puede usarlo como una métrica para escalar a una mayor cantidad de instancias para poder manejar cargas máximas de tráfico. Para obtener un desglose más detallado de los extremos de SageMaker con escalado automático, consulte Configuración de puntos de enlace de inferencia de ajuste de escala automático en Amazon SageMaker.
Prueba de carga
Aunque utilizamos Locust para mostrar cómo podemos cargar la prueba a escala, si está tratando de dimensionar correctamente la instancia detrás de su punto final, Recomendador de inferencia de SageMaker es una opción más eficiente. Con las herramientas de prueba de carga de terceros, debe implementar puntos finales manualmente en diferentes instancias. Con el Recomendador de inferencias, simplemente puede pasar una matriz de los tipos de instancias contra los que desea cargar la prueba, y SageMaker se activará recibas nuevas vacantes en tu correo para cada una de estas instancias.
Langosta
Para este ejemplo, usamos Langosta, una herramienta de prueba de carga de código abierto que puede implementar con Python. Locust es similar a muchas otras herramientas de prueba de carga de código abierto, pero tiene algunos beneficios específicos:
- Fácil de configurar – Como demostramos en esta publicación, pasaremos una secuencia de comandos de Python simple que se puede refactorizar fácilmente para su punto final y carga útiles específicos.
- Distribuido y escalable – Locust se basa en eventos y utiliza evento bajo el capó. Esto es muy útil para probar cargas de trabajo altamente simultáneas y simular miles de usuarios simultáneos. Puede lograr un TPS alto con un solo proceso que ejecuta Locust, pero también tiene un generación de carga distribuida característica que le permite escalar horizontalmente a múltiples procesos y máquinas cliente, como exploraremos en esta publicación.
- Interfaz de usuario y métricas de Locust – Locust también captura la latencia de extremo a extremo como una métrica. Esto puede ayudar a complementar sus métricas de CloudWatch para obtener una imagen completa de sus pruebas. Todo esto se captura en la interfaz de usuario de Locust, donde puede realizar un seguimiento de los usuarios simultáneos, los trabajadores y más.
Para comprender mejor a Locust, echa un vistazo a su documentación.
Configuración de Amazon EC2
Puede configurar Locust en cualquier entorno que sea compatible para usted. Para esta publicación, configuramos una instancia EC2 e instalamos Locust allí para realizar nuestras pruebas. Usamos una instancia EC5.18 c2xlarge. La potencia de cómputo del lado del cliente también es algo a considerar. A veces, cuando se queda sin poder de cómputo en el lado del cliente, esto a menudo no se captura y se confunde con un error de punto final de SageMaker. Es importante colocar a su cliente en una ubicación con suficiente poder de cómputo que pueda manejar la carga en la que está probando. Para nuestra instancia EC2, usamos una AMI de aprendizaje profundo de Ubuntu, pero puede utilizar cualquier AMI siempre que pueda configurar Locust correctamente en la máquina. Para comprender cómo iniciar y conectarse a su instancia EC2, consulte el tutorial Comience con las instancias Linux de Amazon EC2.
Se puede acceder a la interfaz de usuario de Locust a través del puerto 8089. Podemos abrir esto ajustando nuestras reglas de grupo de seguridad de entrada para la instancia EC2. También abrimos el puerto 22 para que podamos SSH en la instancia EC2. Considere reducir el alcance de la fuente a la dirección IP específica desde la que accede a la instancia EC2.

Una vez que esté conectado a su instancia EC2, configuramos un entorno virtual de Python e instalamos la API Locust de código abierto a través de la CLI:
Ahora estamos listos para trabajar con Locust para realizar pruebas de carga en nuestro punto final.
Prueba de langosta
Todas las pruebas de carga de Locust se realizan en base a un Archivo de langosta que proporcionas. Este archivo Locust define una tarea para la prueba de carga; aquí es donde definimos nuestro Boto3 llamada a la API de invocar_punto final. Ver el siguiente código:
En el código anterior, ajuste sus parámetros de llamada de punto final de invocación para adaptarse a su invocación de modelo específico. usamos el InvokeEndpoint API usando la siguiente pieza de código en el archivo Locust; este es nuestro punto de ejecución de prueba de carga. El archivo Locust que estamos usando es langosta_script.py.
Ahora que tenemos nuestro script de Locust listo, queremos ejecutar pruebas de Locust distribuidas para hacer una prueba de esfuerzo de nuestra única instancia para averiguar cuánto tráfico puede manejar nuestra instancia.
El modo distribuido Locust tiene un poco más de matices que una prueba Locust de un solo proceso. En el modo distribuido, tenemos un trabajador principal y múltiples. El trabajador principal instruye a los trabajadores sobre cómo generar y controlar los usuarios simultáneos que envían una solicitud. En nuestro distribuido.sh script, vemos por defecto que 240 usuarios se distribuirán entre los 60 trabajadores. Tenga en cuenta que el --headless El indicador en la CLI de Locust elimina la función de interfaz de usuario de Locust.
./distributed.sh huggingface-pytorch-inference-2022-10-04-02-46-44-677 #to execute Distributed Locust test
Primero ejecutamos la prueba distribuida en una sola instancia que respalda el punto final. La idea aquí es que queremos maximizar por completo una sola instancia para comprender el recuento de instancias que necesitamos para lograr nuestro TPS objetivo mientras nos mantenemos dentro de nuestros requisitos de latencia. Tenga en cuenta que si desea acceder a la interfaz de usuario, cambie el Locust_UI variable de entorno a True y tome la IP pública de su instancia EC2 y asigne el puerto 8089 a la URL.
La siguiente captura de pantalla muestra nuestras métricas de CloudWatch.

Eventualmente, notamos que aunque inicialmente logramos un TPS de 200, comenzamos a notar errores 5xx en nuestros registros del lado del cliente de EC2, como se muestra en la siguiente captura de pantalla.
También podemos verificar esto observando nuestras métricas a nivel de instancia, específicamente CPUUtilization.
 Aquí nos damos cuenta
Aquí nos damos cuenta CPUUtilization en casi 4,800%. Nuestra instancia ml.m5.12x.large tiene 48 vCPU (48 * 100 = 4800~). Esto está saturando toda la instancia, lo que también ayuda a explicar nuestros errores 5xx. También vemos un aumento en ModelLatency.
Parece como si nuestra única instancia se estuviera derrumbando y no tuviera el cómputo para sostener una carga más allá de los 200 TPS que estamos observando. Nuestro objetivo de TPS es 1000, así que tratemos de aumentar nuestro recuento de instancias a 5. Esto podría ser aún mayor en una configuración de producción, porque observábamos errores a 200 TPS después de cierto punto.

Vemos tanto en la interfaz de usuario de Locust como en los registros de CloudWatch que tenemos un TPS de casi 1000 con cinco instancias que respaldan el punto final.

 Si comienza a experimentar errores incluso con esta configuración de hardware, asegúrese de monitorear
Si comienza a experimentar errores incluso con esta configuración de hardware, asegúrese de monitorear CPUUtilization para comprender la imagen completa detrás de su alojamiento de punto final. Es crucial comprender la utilización de su hardware para ver si necesita escalar hacia arriba o incluso hacia abajo. A veces, los problemas a nivel de contenedor conducen a errores 5xx, pero si CPUUtilization es bajo, indica que no es su hardware sino algo a nivel de contenedor o modelo que podría estar provocando estos problemas (la variable de entorno adecuada para la cantidad de trabajadores no establecida, por ejemplo). Por otro lado, si nota que su instancia se está saturando por completo, es una señal de que necesita aumentar la flota de instancias actual o probar una instancia más grande con una flota más pequeña.
Aunque aumentamos el recuento de instancias a 5 para manejar 100 TPS, podemos ver que el ModelLatency la métrica sigue siendo alta. Esto se debe a que las instancias están saturadas. En general, sugerimos tratar de utilizar los recursos de la instancia entre 60 y 70 %.
Limpiar
Después de la prueba de carga, asegúrese de limpiar los recursos que no utilizará a través de la consola de SageMaker o del eliminar_punto final Llamada a la API de Boto3. Además, asegúrese de detener su instancia EC2 o cualquier configuración de cliente que tenga para no incurrir en cargos adicionales allí también.
Resumen
En esta publicación, describimos cómo puede cargar la prueba de su terminal en tiempo real de SageMaker. También discutimos qué métricas debe evaluar al realizar pruebas de carga en su terminal para comprender el desglose de su rendimiento. Asegúrate de revisar Recomendador de inferencia de SageMaker para comprender mejor el tamaño adecuado de las instancias y más técnicas de optimización del rendimiento.
Acerca de los autores
 marc karp es un Arquitecto de ML con el equipo de Servicio de SageMaker. Se enfoca en ayudar a los clientes a diseñar, implementar y administrar cargas de trabajo de ML a escala. En su tiempo libre le gusta viajar y explorar nuevos lugares.
marc karp es un Arquitecto de ML con el equipo de Servicio de SageMaker. Se enfoca en ayudar a los clientes a diseñar, implementar y administrar cargas de trabajo de ML a escala. En su tiempo libre le gusta viajar y explorar nuevos lugares.
 Ram Vegiraju es un arquitecto de ML en el equipo de servicio Sagemaker. Se enfoca en ayudar a los clientes a construir y optimizar sus soluciones AI/ML en Amazon Sagemaker. En su tiempo libre, le encanta viajar y escribir.
Ram Vegiraju es un arquitecto de ML en el equipo de servicio Sagemaker. Se enfoca en ayudar a los clientes a construir y optimizar sus soluciones AI/ML en Amazon Sagemaker. En su tiempo libre, le encanta viajar y escribir.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/best-practices-for-load-testing-amazon-sagemaker-real-time-inference-endpoints/
- 1
- 10
- 100
- 11
- 9
- a
- Poder
- arriba
- aceptable
- de la máquina
- accesible
- el acceso
- precisamente
- Lograr
- a través de
- adición
- dirección
- Después
- en contra
- AI / ML
- Con el objetivo
- Todos
- permite
- Aunque
- Amazon
- Amazon EC2
- Amazon SageMaker
- cantidad
- análisis
- y
- abejas
- en torno a
- Formación
- adjuntar
- autoría
- auto
- automáticamente
- Hoy Disponibles
- AWS
- Atrás
- Respaldados
- apoyo
- basado
- porque
- detrás de
- "Ser"
- es el beneficio
- beneficios
- MEJOR
- y las mejores prácticas
- entre
- cuerpo
- Breakdown
- build
- C + +
- llamar al
- Calls
- Puede conseguir
- capturar
- capturas
- lucha
- a ciertos
- el cambio
- cargos
- comprobar
- clase
- clasificación
- cliente
- código
- Algunos
- compatible
- Calcular
- competidor
- Conducir
- Configuración
- Confirmar
- CONTACTO
- conectado
- Conexiones
- Considerar
- consideración
- Consola
- Envase
- contiene
- contexto
- control
- Correspondiente
- podría
- Protectora
- cubre suministros para
- CPU
- Para crear
- crucial
- Current
- personalizado
- Clientes
- datos
- profundo
- deep learning
- más profundo
- Predeterminado
- Define
- demostrar
- Dependiente
- depende
- desplegar
- Desplegando
- describir
- descrito
- Diseño
- desarrolladores
- una experiencia diferente
- directamente
- discutido
- Pantalla
- distribuidos
- No
- No
- DE INSCRIPCIÓN
- cada una
- pasan fácilmente
- eficiente
- eficiente.
- ya sea
- permite
- de extremo a extremo
- Punto final
- Todo
- Entorno
- error
- Errores
- esencial
- Éter (ETH)
- Incluso
- ejemplo
- excepción
- ejecutar
- experimentando
- Explicar
- exploración
- explorar
- Explorar
- exportar
- extremadamente
- Cara
- factores importantes
- Caídas
- familiar
- Feature
- pocos
- Archive
- Finalmente
- Encuentre
- Nombre
- FLOTA
- Focus
- se centra
- siguiendo
- formato
- Marco conceptual
- frecuente
- en
- ser completados
- completamente
- promover
- General
- en general
- obtener
- conseguir
- candidato
- gráfica
- mayor
- Grupo procesos
- Grupo
- encargarse de
- Ahorrar
- Materiales
- ayuda
- ayudando
- ayuda
- esta página
- Alta
- altamente
- capucha
- fortaleza
- organizado
- hosting
- Cómo
- Como Hacer
- HTML
- HTTPS
- Bujes
- idea
- ideal
- no haber aun identificado una solucion para el problema
- Identifique
- Impacto
- implementar
- implementado
- importar
- importante
- in
- incluye
- aumente
- aumentado
- Indica
- indicación
- información
- posiblemente
- instalar
- ejemplo
- COMPLETAMENTE
- interactivo
- Internet
- invoca
- IP
- Dirección IP
- aislado
- cuestiones
- IT
- sí mismo
- json
- large
- principalmente
- mayores
- Estado latente
- lanzamiento
- ponedoras
- Lead
- líder
- aprendizaje
- Nivel
- Linux
- Lista
- pequeño
- carga
- cargas
- Ubicación
- Largo
- mirando
- Lote
- Baja
- máquina
- máquina de aprendizaje
- Máquinas
- para lograr
- Realizar
- gestionan
- gestionado
- a mano
- muchos
- mapa
- Maximizar
- significa
- Conoce a
- reunión
- Salud Cerebral
- métrico
- Métrica
- podría
- mínimo
- ML
- Moda
- modelo
- modelos
- Monitorear
- más,
- más eficiente
- múltiples
- nombre
- hace casi
- necesariamente
- ¿ Necesita ayuda
- Nuevo
- cuaderno
- número
- ONE
- habiertos
- de código abierto
- Operaciones
- optimización
- Optimización
- optimizado
- Optión
- Opciones
- solicite
- Otro
- afuera
- EL DESARROLLADOR
- PINTURA
- parámetros
- parte
- pasado
- pasado
- camino
- Patrón de Costura
- .
- En pleno
- realizar
- actuación
- la perspectiva
- recoger
- imagen
- pieza
- Colocar
- Lugares
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- más
- punto
- Publicación
- la posibilidad
- industria
- prácticas
- Predictor
- primario
- Imprimir
- problemas
- en costes
- Producción
- Mi Perfil
- apropiado
- correctamente
- proporcionar
- proporciona un
- provisión
- público
- Python
- Preguntas
- con rapidez
- distancia
- ready
- en tiempo real
- darse cuenta de
- recibe
- recomendado
- región
- relacionado
- solicita
- Requisitos
- Recursos
- respuesta
- RESTO
- resultado
- Resultados
- devoluciones
- reglas
- Ejecutar
- correr
- sabio
- Inferencia de SageMaker
- Escala
- la ampliación
- los científicos
- Alcance
- guiones
- Segundo
- EN LINEA
- parece
- AUTO
- enviando
- sentimiento
- de coches
- servicio
- set
- pólipo
- ajustes
- Configure
- Varios
- tienes
- mostrado
- Shows
- firmar
- similares
- sencillos
- simplemente
- soltero
- Tamaño
- menores
- So
- Soluciones
- algo
- Fuente
- Fuentes
- Desovar
- soluciones y
- específicamente
- Girar
- estándar
- comienzo
- fundó
- declaraciones
- paso
- Sin embargo
- Detener
- estrés
- esforzarse
- tal
- suficiente
- siguiente
- súper
- complementar
- ¡Prepárate!
- toma
- Target
- Tarea
- tareas
- equipo
- técnicas
- test
- Prueba de ejecución
- Pruebas
- pruebas
- Clasificación de texto
- El
- La Fuente
- su
- terceros.
- miles
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- equipo
- veces
- a
- del IRS
- TPS
- seguir
- Seguimiento
- tráfico
- Entrenar
- Transacciones
- Viajar
- verdadero
- tutoriales
- tipos
- Ubuntu
- ui
- bajo
- entender
- comprensión
- unidad
- Enlance
- us
- utilizan el
- usuarios
- utilizar
- utilizado
- utiliza
- Utilizando
- variedad
- verificar
- vía
- Virtual
- ¿
- sean
- que
- mientras
- seguirá
- dentro de
- Actividades:
- obrero
- los trabajadores.
- se
- la escritura
- tú
- zephyrnet