Las redes neuronales aprenden a través de números, por lo que cada palabra se asignará a vectores para representar una palabra en particular. La capa de incrustación se puede considerar como una tabla de búsqueda que almacena incrustaciones de palabras y las recupera mediante índices.
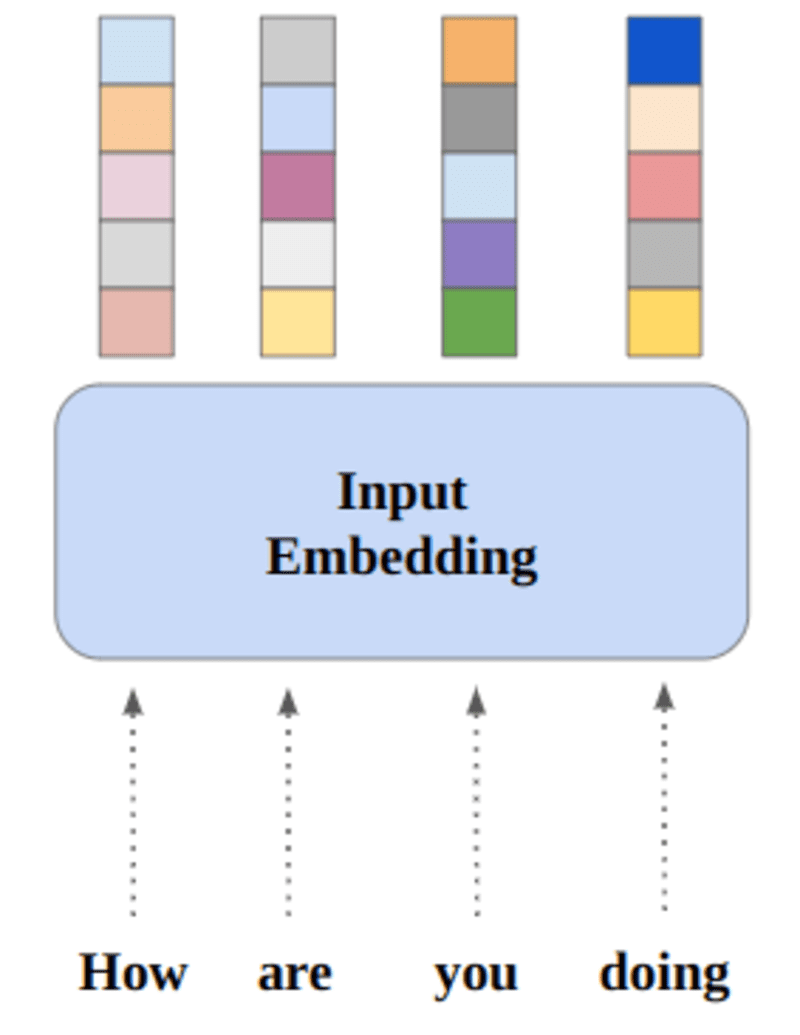
Las palabras que tienen el mismo significado estarán cerca en términos de distancia euclidiana/similitud de coseno. por ejemplo, en la siguiente representación de palabras, "sábado", "domingo" y "lunes" están asociados con el mismo concepto, por lo que podemos ver que las palabras están resultando similares.

La determinación de la posición de la palabra, ¿Por qué necesitamos determinar la posición de la palabra? Debido a que el codificador del transformador no tiene recurrencia como las redes neuronales recurrentes, debemos agregar información sobre las posiciones en las incrustaciones de entrada. Esto se hace usando codificación posicional. Los autores del artículo utilizaron las siguientes funciones para modelar la posición de una palabra.
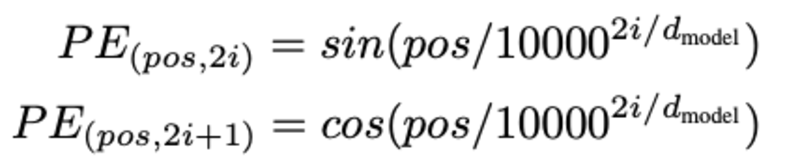
Intentaremos explicar la codificación posicional.
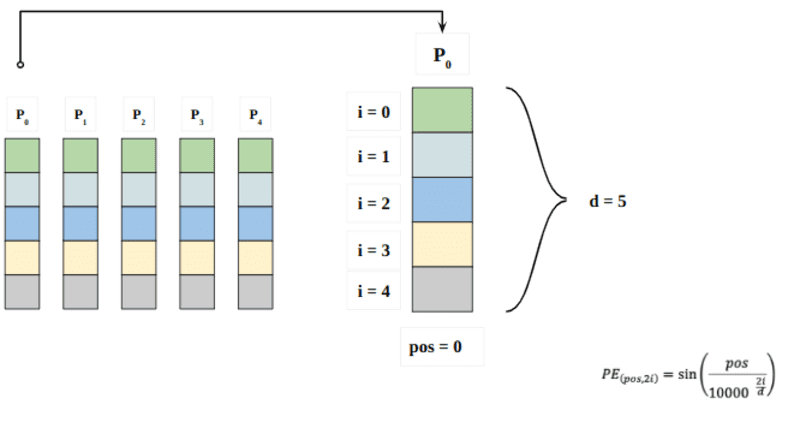
Aquí “pos” se refiere a la posición de la “palabra” en la secuencia. P0 se refiere a la posición de incrustación de la primera palabra; "d" significa el tamaño de la incrustación de palabra/token. En este ejemplo d=5. Finalmente, "i" se refiere a cada una de las 5 dimensiones individuales de la incrustación (es decir, 0, 1,2,3,4)
si "i" varía en la ecuación anterior, obtendrá un montón de curvas con frecuencias variables. Lectura de los valores de incrustación de posición frente a diferentes frecuencias, dando diferentes valores en diferentes dimensiones de incrustación para P0 y P4.
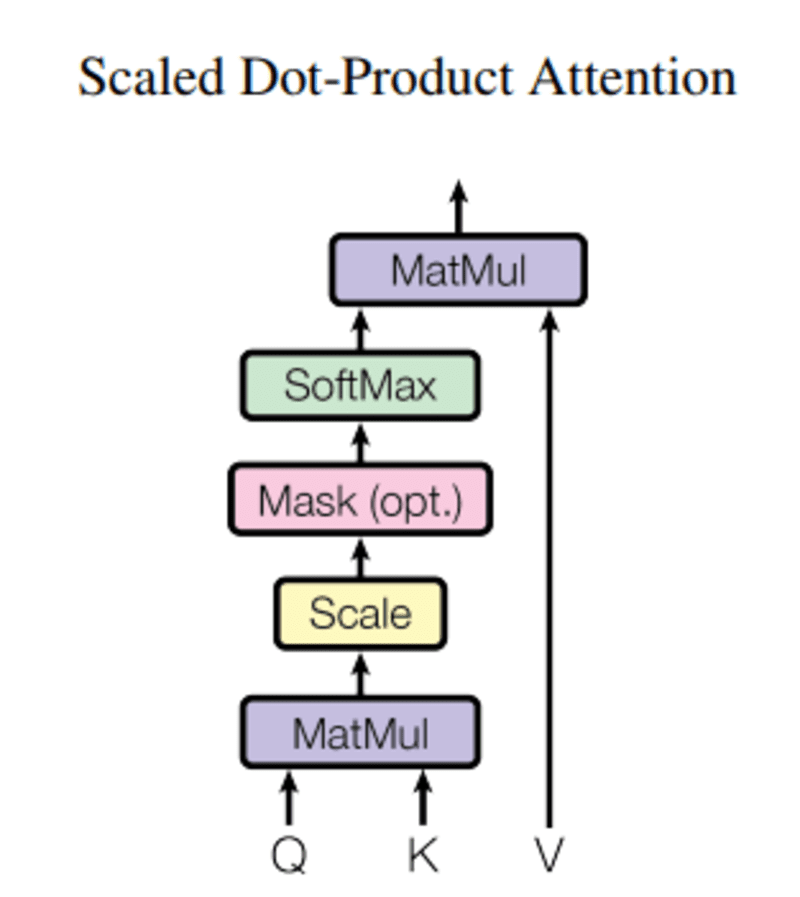
En este consulta, q representa una palabra vectorial, la teclas k son todas las demás palabras en la oración, y valor V representa el vector de la palabra.
El propósito de la atención es calcular la importancia del término clave en comparación con el término de consulta relacionado con la misma persona/cosa o concepto.
En nuestro caso, V es igual a Q.
El mecanismo de atención nos da la importancia de la palabra en una oración.
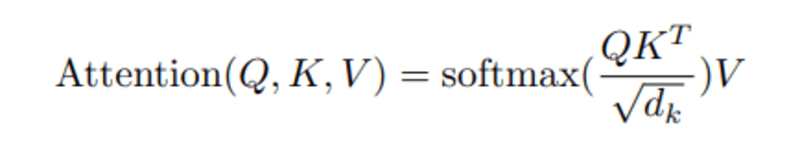
Cuando calculamos el producto escalar normalizado entre la consulta y las claves, obtenemos un tensor que representa la importancia relativa de cada palabra para la consulta.
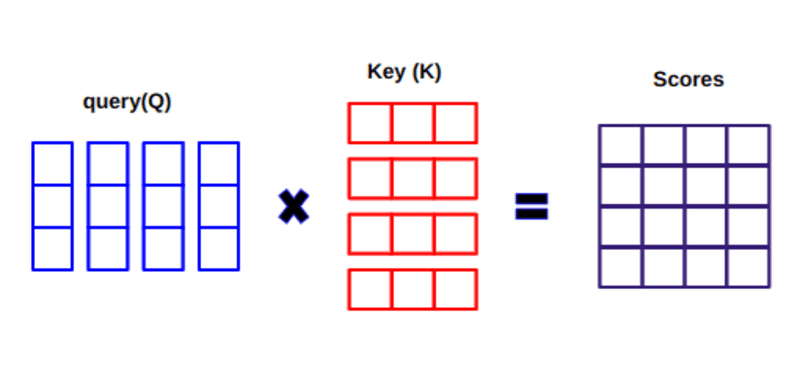
Al calcular el producto escalar entre Q y KT, tratamos de estimar cómo se alinean los vectores (es decir, las palabras entre la consulta y las claves) y devolvemos un peso para cada palabra de la oración.
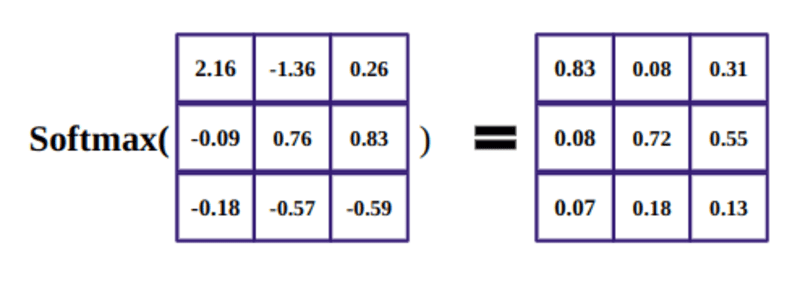
Luego, normalizamos el resultado al cuadrado de d_k y la función softmax regulariza los términos y los reescala entre 0 y 1.
Finalmente, multiplicamos el resultado (es decir, pesos) por el valor (es decir, todas las palabras) para reducir la importancia de las palabras no relevantes y centrarnos solo en las palabras más importantes.
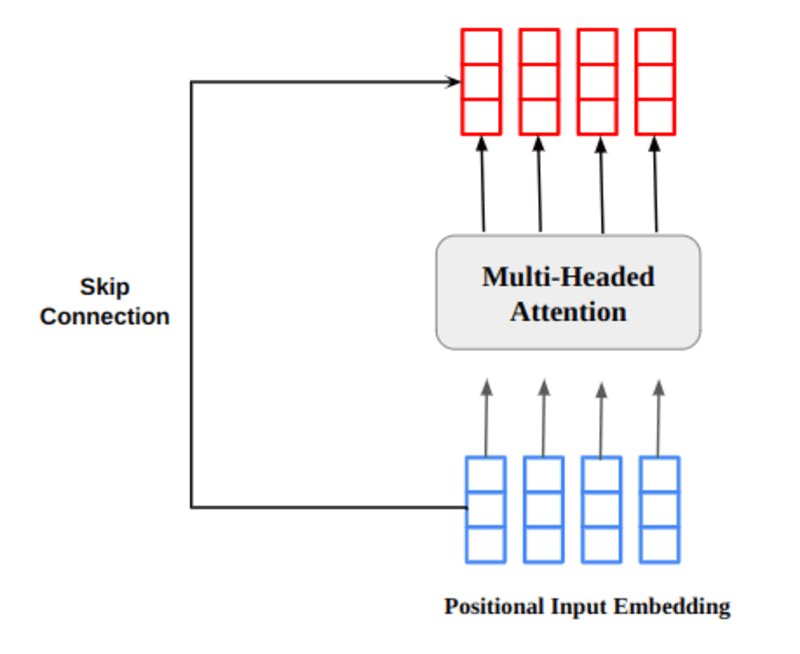
El vector de salida de atención de múltiples cabezas se agrega a la incrustación de entrada posicional original. Esto se denomina conexión residual/conexión de salto. La salida de la conexión residual pasa por la normalización de capas. La salida residual normalizada se pasa a través de una red de alimentación directa puntual para su posterior procesamiento.
La máscara es una matriz del mismo tamaño que las puntuaciones de atención llenas de valores de 0 e infinitos negativos.
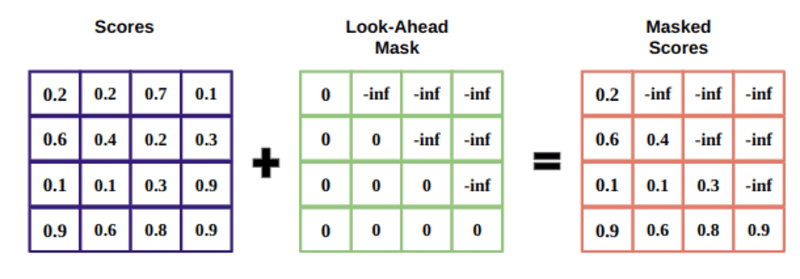
El motivo de la máscara es que una vez que toma el softmax de las puntuaciones enmascaradas, los infinitos negativos se vuelven cero, dejando cero puntuaciones de atención para tokens futuros.
Esto le dice al modelo que no se centre en esas palabras.
El propósito de la función softmax es tomar números reales (positivos y negativos) y convertirlos en números positivos que suman 1.
Ravikumar Naduvin está ocupado construyendo y comprendiendo tareas de PNL usando PyTorch.
Original. Publicado de nuevo con permiso.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.kdnuggets.com/2023/01/concepts-know-getting-transformer.html?utm_source=rss&utm_medium=rss&utm_campaign=concepts-you-should-know-before-getting-into-transformer
- 1
- a
- Sobre
- arriba
- adicional
- en contra
- alineado
- Todos
- y
- asociado
- Autorzy
- porque
- antes
- a continuación
- entre
- Construir la
- Manojo
- , que son
- case
- Cerrar
- en comparación con
- Calcular
- informática
- concepto
- conceptos
- conexión
- Determinar
- determinar
- una experiencia diferente
- dimensiones
- DOT
- cada una
- estimación
- ejemplo
- Explicar
- lleno
- Finalmente
- Nombre
- Focus
- siguiendo
- función
- funciones
- promover
- futuras
- obtener
- conseguir
- GitHub
- da
- Diezmos y Ofrendas
- Va
- agarrar
- Cómo
- HTTPS
- importancia
- importante
- in
- Indices
- INSTRUMENTO individual
- información
- Las opciones de entrada
- nuggets
- Clave
- claves
- Saber
- .
- APRENDE:
- dejarlo
- Etiqueta LinkedIn
- búsqueda
- máscara
- Matrix
- sentido
- significa
- mecanismo
- modelo
- MEJOR DE TU
- ¿ Necesita ayuda
- negativas
- del sistema,
- telecomunicaciones
- Neural
- redes neuronales
- nlp
- números
- reconocida por
- Otro
- Papel
- particular
- pasado
- permiso
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- posición
- abiertas
- positivo
- tratamiento
- Producto
- propósito
- poner
- piñón
- Reading
- real
- razón
- reaparición
- reducir
- se refiere
- relacionado
- representar
- representación
- representa
- resultado
- resultante
- volvemos
- mismo
- sentencia
- Secuencia
- tienes
- similares
- Tamaño
- So
- algo
- Squared
- tiendas
- mesa
- ¡Prepárate!
- tareas
- decirles
- términos
- El
- pensamiento
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- a
- Tokens
- transformers
- GIRO
- comprensión
- us
- propuesta de
- Valores
- peso
- que
- seguirá
- Palabra
- palabras
- zephyrnet
- cero