Las investigaciones de los últimos años han demostrado que los modelos de aprendizaje automático (ML) son vulnerables a aportaciones adversas, donde un adversario puede crear entradas para alterar estratégicamente la salida del modelo (en clasificación de imágenes, reconocimiento de vozo detección de fraude). Por ejemplo, imagine que ha implementado un modelo que identifica a sus empleados en función de las imágenes de sus rostros. Como se demuestra en el documento técnico Accesorizar a un crimen: Ataques reales y sigilosos contra el reconocimiento facial de última generación, los empleados maliciosos pueden aplicar modificaciones sutiles pero cuidadosamente diseñadas a su imagen y engañar al modelo para autenticarlos como otros empleados. Obviamente, tales aportes contradictorios, especialmente si hay una cantidad significativa de ellos, pueden tener un impacto comercial devastador.
Idealmente, queremos detectar cada vez que se envía una entrada contradictoria al modelo para cuantificar cómo las entradas contradictorias están afectando su modelo y negocio. Con este fin, una amplia clase de métodos analizan las entradas de modelos individuales para verificar el comportamiento adversario. Sin embargo, la investigación activa en el ML adversario ha llevado a entradas adversarias cada vez más sofisticadas, muchas de las cuales se sabe que hacen que la detección sea ineficaz. La razón de esta deficiencia es que es difícil sacar conclusiones de una entrada individual en cuanto a si es contradictorio o no. Con este fin, una clase reciente de métodos se enfoca en verificaciones a nivel de distribución mediante el análisis de múltiples entradas a la vez. La idea clave detrás de estos nuevos métodos es que considerar múltiples entradas a la vez permite un análisis estadístico más poderoso que no es posible con entradas individuales. Sin embargo, frente a un adversario determinado con un profundo conocimiento del modelo, incluso estos métodos de detección avanzados pueden fallar.
Sin embargo, podemos derrotar incluso a estos adversarios decididos proporcionando información adicional a los métodos de defensa. Específicamente, en lugar de solo analizar las entradas del modelo, analizar las representaciones latentes recopiladas de las capas intermedias en una red neuronal profunda fortalece significativamente la defensa.
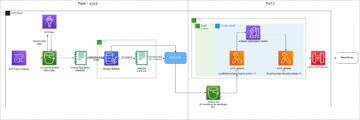
En esta publicación, lo guiaremos a través de cómo detectar entradas adversarias usando Monitor de modelo de Amazon SageMaker y Depurador de Amazon SageMaker para un modelo de clasificación de imágenes alojado en Amazon SageMaker.
Para reproducir los diferentes pasos y resultados enumerados en esta publicación, clone el repositorio detección-de-muestras-adversarias-usando-sagemaker en su instancia de cuaderno de Amazon SageMaker y ejecute el cuaderno.
Detección de entradas adversarias
Le mostramos cómo detectar entradas adversarias utilizando las representaciones recopiladas de una red neuronal profunda. Las siguientes cuatro imágenes muestran la imagen de entrenamiento original a la izquierda (tomada del conjunto de datos de Tiny ImageNet) y tres imágenes producidas por el ataque de descenso de gradiente proyectado (PGD) [1] con diferentes parámetros de perturbación ϵ. El modelo utilizado aquí fue ResNet18. El parámetro ϵ define la cantidad de ruido adverso agregado a las imágenes. La imagen original (izquierda) se predice correctamente como clase 67 (goose). Las imágenes modificadas adversariamente 2, 3 y 4 se predicen incorrectamente como clase 51 (mantis) por el modelo ResNet18. También podemos ver que las imágenes generadas con ϵ pequeño son perceptualmente indistinguibles de la imagen de entrada original.

A continuación, creamos un conjunto de imágenes normales y antagónicas y usamos Incrustación de vecinos estocásticos distribuidos en t (t-SNE [2]) para comparar visualmente sus distribuciones. t-SNE es un método de reducción de dimensionalidad que mapea datos de alta dimensión en un espacio de 2 o 3 dimensiones. Cada punto de datos en la siguiente imagen presenta una imagen de entrada. Los puntos de datos naranjas presentan las entradas normales tomadas del conjunto de prueba, y los puntos de datos azules indican las imágenes antagónicas correspondientes generadas con un épsilon de 0.003. Si las entradas normales y antagónicas son distinguibles, esperaríamos grupos separados en la visualización de t-SNE. Debido a que ambos pertenecen al mismo grupo, esto significa que una técnica de detección que se centre únicamente en los cambios en la distribución de entrada del modelo no puede distinguir estas entradas.

Echemos un vistazo más de cerca a las representaciones de capas producidas por diferentes capas en el modelo ResNet18. ResNet18 consta de 18 capas; en la siguiente imagen, visualizamos las incrustaciones de t-SNE para las representaciones de seis de estas capas.

Como muestra la figura anterior, las entradas naturales y antagónicas se vuelven más distinguibles para las capas más profundas del modelo ResNet18.
Con base en estas observaciones, utilizamos un método estadístico que mide la distinguibilidad con pruebas de hipótesis. El método consiste en un prueba de dos muestras usando discrepancia media máxima (MMD). MMD es una métrica basada en kernel para medir la similitud entre dos distribuciones que generan los datos. Una prueba de dos muestras toma dos conjuntos que contienen entradas extraídas de dos distribuciones y determina si estas distribuciones son iguales. Comparamos la distribución de las entradas observadas en los datos de entrenamiento y la comparamos con la distribución de las entradas recibidas durante la inferencia.
Nuestro método usa estas entradas para estimar el valor p usando MMD. Si el valor p es mayor que un umbral de significancia específico del usuario (5% en nuestro caso), concluimos que ambas distribuciones son diferentes. El umbral ajusta el equilibrio entre falsos positivos y falsos negativos. Un umbral más alto, como el 10 %, disminuye la tasa de falsos negativos (hay menos casos en los que ambas distribuciones eran diferentes pero la prueba no lo indicó). Sin embargo, también da como resultado más falsos positivos (la prueba indica que ambas distribuciones son diferentes incluso cuando ese no es el caso). Por otro lado, un umbral más bajo, como el 1%, da como resultado menos falsos positivos pero más falsos negativos.
En lugar de aplicar este método únicamente en las entradas del modelo sin procesar (imágenes), usamos las representaciones latentes producidas por las capas intermedias de nuestro modelo. Para dar cuenta de su naturaleza probabilística, aplicamos la prueba de hipótesis 100 veces en 100 entradas naturales seleccionadas al azar y 100 entradas contradictorias seleccionadas al azar. Luego informamos la tasa de detección como el porcentaje de pruebas que resultaron en un evento de detección de acuerdo con nuestro umbral de significación del 5 %. La tasa de detección más alta es una indicación más fuerte de que las dos distribuciones son diferentes. Este procedimiento nos da las siguientes tasas de detección:
- Capa 1: 3%
- Capa 4: 7%
- Capa 8: 84%
- Capa 12: 95%
- Capa 14: 100%
- Capa 15: 100%
En las capas iniciales, la tasa de detección es bastante baja (menos del 10 %), pero aumenta hasta el 100 % en las capas más profundas. Usando la prueba estadística, el método puede detectar con confianza entradas adversarias en capas más profundas. A menudo es suficiente simplemente usar las representaciones generadas por la penúltima capa (la última capa antes de la capa de clasificación en un modelo). Para entradas adversarias más sofisticadas, es útil usar representaciones de otras capas y agregar las tasas de detección.
Resumen de la solución
En la sección anterior, vimos cómo detectar entradas adversarias usando representaciones de la penúltima capa. A continuación, mostramos cómo automatizar estas pruebas en SageMaker mediante Model Monitor y Debugger. Para este ejemplo, primero entrenamos un modelo ResNet18 de clasificación de imágenes en el pequeño conjunto de datos de ImageNet. A continuación, implementamos el modelo en SageMaker y creamos un programa personalizado de Model Monitor que ejecuta la prueba estadística. Luego, ejecutamos la inferencia con entradas normales y antagónicas para ver qué tan efectivo es el método.
Capturar tensores usando Debugger
Durante el entrenamiento del modelo, usamos Debugger para capturar representaciones generadas por la penúltima capa, que luego se usan para derivar información sobre la distribución de entradas normales. El depurador es una característica de SageMaker que le permite capturar y analizar información, como parámetros del modelo, gradientes y activaciones durante el entrenamiento del modelo. Estos tensores de parámetro, gradiente y activación se cargan en Servicio de almacenamiento simple de Amazon (Amazon S3) mientras el entrenamiento está en curso. Puede configurar reglas que los analicen en busca de problemas como el sobreajuste y la desaparición de gradientes. Para nuestro caso de uso, solo queremos capturar la penúltima capa del modelo (.*avgpool_output) y los resultados del modelo (predicciones). Especificamos una configuración de enlace de depurador que define una expresión regular para que se recopilen las representaciones de capa. También especificamos un save_interval que indica a Debugger que recopile estos datos durante la fase de validación cada 100 pases hacia adelante. Ver el siguiente código:
Ejecute la capacitación de SageMaker
Pasamos la configuración del Depurador al estimador de SageMaker e iniciamos el entrenamiento:
Implementar un modelo de clasificación de imágenes
Una vez completada la capacitación del modelo, implementamos el modelo como punto final en SageMaker. Especificamos un guion de inferencia que define el model_fn y transform_fn funciones Estas funciones especifican cómo se carga el modelo y cómo se deben preprocesar los datos entrantes para realizar la inferencia del modelo. Para nuestro caso de uso, permitimos que Debugger capture datos relevantes durante la inferencia. En el model_fn función, especificamos un enlace Debugger y un save_config que especifica que para cada solicitud de inferencia, se registran las entradas del modelo (imágenes), las salidas del modelo (predicciones) y la penúltima capa (.*avgpool_output). Luego registramos el gancho en el modelo. Ver el siguiente código:
Ahora desplegamos el modelo, que podemos hacer desde el cuaderno de dos formas. Podemos llamar pytorch_estimator.deploy() o cree un modelo de PyTorch que apunte a los archivos de artefactos del modelo en Amazon S3 que ha creado el trabajo de entrenamiento de SageMaker. En este post, hacemos lo último. Esto nos permite pasar variables de entorno al contenedor Docker, que SageMaker crea e implementa. Necesitamos la variable de entorno. tensors_output para decirle a la secuencia de comandos dónde cargar los tensores que recopila SageMaker Debugger durante la inferencia. Ver el siguiente código:
A continuación, implementamos el predictor en un tipo de instancia ml.m5.xlarge:
Cree un programa de Monitor de modelo personalizado
Cuando el punto final está en funcionamiento, creamos un programa personalizado de Model Monitor. Esto es un Trabajo de procesamiento de SageMaker que se ejecuta en un intervalo periódico (como por hora o por día) y analiza los datos de inferencia. Model Monitor proporciona un contenedor preconfigurado que analiza y detecta la deriva de datos. En nuestro caso, queremos personalizarlo para obtener los datos del depurador y ejecutar la prueba de dos muestras de MMD en las representaciones de capa recuperadas.
Para personalizarlo, primero definimos el objeto Model Monitor, que especifica en qué tipo de instancia se ejecutarán estos trabajos y la ubicación de nuestro contenedor Model Monitor personalizado:
Queremos ejecutar este trabajo cada hora, por lo que especificamos CronExpressionGenerator.hourly() y las ubicaciones de salida donde se cargan los resultados del análisis. Para eso tenemos que definir ProcessingOutput para la salida de procesamiento de SageMaker:
Echemos un vistazo más de cerca a lo que se está ejecutando en nuestro contenedor Model Monitor personalizado. Creamos un guión de evaluación, que carga los datos capturados por Debugger. También creamos un objeto de prueba, que nos permite acceder, consultar y filtrar los datos que guardó Debugger. Con el objeto de prueba, podemos iterar sobre los pasos guardados durante las fases de inferencia y entrenamiento. trial.steps(mode).
Primero, buscamos los resultados del modelo (trial.tensor("ResNet_output_0")) así como la penúltima capa (trial.tensor_names(regex=".*avgpool_output")). Hacemos esto para las fases de inferencia y validación del entrenamiento (modes.EVAL y modes.PREDICT). Los tensores de la fase de validación sirven como estimación de la distribución normal, que luego usamos para comparar la distribución de los datos de inferencia. Creamos una clase LADIS (Detección de distribuciones de entrada antagónicas a través de estadísticas por capas). Esta clase proporciona las funcionalidades relevantes para realizar la prueba de dos muestras. Toma la lista de tensores de las fases de inferencia y validación y ejecuta la prueba de dos muestras. Devuelve una tasa de detección, que es un valor entre 0 y 100 %. Cuanto mayor sea el valor, más probable es que los datos de inferencia sigan una distribución diferente. Además, calculamos una puntuación para cada muestra que indica la probabilidad de que una muestra sea contradictoria y se registran las 100 mejores muestras, para que los usuarios puedan seguir inspeccionándolas. Ver el siguiente código:
Prueba contra entradas adversarias
Ahora que se implementó nuestro programa personalizado Model Monitor, podemos producir algunos resultados de inferencia.
Primero, ejecutamos con datos del conjunto reservado y luego con entradas adversarias:
A continuación, podemos comprobar la pantalla del monitor del modelo en Estudio Amazon SageMaker vea la sección Reloj en la nube de Amazon registros para ver si se encontró un problema.

A continuación, usamos las entradas adversarias contra el modelo alojado en SageMaker. Usamos el conjunto de datos de prueba del conjunto de datos Tiny ImageNet y aplicamos el ataque PGD, que introduce perturbaciones a nivel de píxel de manera que el modelo no reconoce las clases correctas. En las siguientes imágenes, la columna de la izquierda muestra dos imágenes de prueba originales, la columna del medio muestra sus versiones adversariamente perturbadas y la columna de la derecha muestra la diferencia entre ambas imágenes.

Ahora podemos comprobar el estado del monitor de modelo y ver que algunas de las imágenes de inferencia se extrajeron de una distribución diferente.

Resultados y acción del usuario
El trabajo de Model Monitor personalizado determina puntuaciones para cada solicitud de inferencia, lo que indica la probabilidad de que la muestra sea contradictoria según la prueba de MMD. Estas puntuaciones se recopilan para todas las solicitudes de inferencia. Su puntuación con el número de paso del depurador correspondiente se registra en un archivo JSON y se carga en Amazon S3. Una vez que se completa el trabajo de monitoreo del modelo, descargamos el archivo JSON, recuperamos los números de paso y usamos el depurador para recuperar las entradas del modelo correspondientes para estos pasos. Esto nos permite inspeccionar las imágenes que fueron detectadas como adversarias.
El siguiente bloque de código traza las dos primeras imágenes que se han identificado como las que tienen más probabilidades de ser antagónicas:
En nuestra ejecución de prueba de ejemplo, obtenemos el siguiente resultado. La imagen de la medusa se predijo incorrectamente como una naranja y la imagen del camello como un panda. Obviamente, el modelo falló en estas entradas y ni siquiera predijo una clase de imagen similar, como un pez dorado o un caballo. A modo de comparación, también mostramos las muestras naturales correspondientes del conjunto de prueba en el lado derecho. Podemos observar que las perturbaciones aleatorias introducidas por el atacante son muy visibles en el fondo de ambas imágenes.


El trabajo de Model Monitor personalizado publica la tasa de detección en CloudWatch, por lo que podemos investigar cómo ha cambiado esta tasa con el tiempo. Un cambio significativo entre dos puntos de datos puede indicar que un adversario estaba tratando de engañar al modelo en un marco de tiempo específico. Además, también puede trazar la cantidad de solicitudes de inferencia que se procesan en cada trabajo de Model Monitor y la tasa de detección de referencia, que se calcula sobre el conjunto de datos de validación. La tasa de referencia suele estar cerca de 0 y solo sirve como métrica de comparación.
La siguiente captura de pantalla muestra las métricas generadas por nuestras ejecuciones de prueba, que ejecutaron tres trabajos de Monitoreo de modelos durante 3 horas. Cada trabajo procesa aproximadamente de 200 a 300 solicitudes de inferencia a la vez. La tasa de detección es del 100 % entre las 5:00 p. m. y las 6:00 p. m., y cae después.

Además, también podemos inspeccionar las distribuciones de representaciones generadas por las capas intermedias del modelo. Con Debugger, podemos acceder a los datos de la fase de validación del trabajo de entrenamiento y los tensores de la fase de inferencia, y usar t-SNE para visualizar su distribución para ciertas clases predichas. Ver el siguiente código:
En nuestro caso de prueba, obtenemos la siguiente visualización de t-SNE para la segunda clase de imagen. Podemos observar que las muestras adversarias se agrupan de manera diferente a las naturales.

Resumen
En esta publicación, mostramos cómo usar una prueba de dos muestras usando la máxima discrepancia media para detectar entradas adversarias. Demostramos cómo puede implementar tales mecanismos de detección usando Debugger y Model Monitor. Este flujo de trabajo le permite monitorear sus modelos alojados en SageMaker a escala y detectar entradas adversas automáticamente. Para obtener más información al respecto, consulte nuestro Repositorio GitHub.
Referencias
[1] Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras y Adrian Vladu. Hacia modelos de aprendizaje profundo resistentes a los ataques adversarios. En Conferencia internacional sobre representaciones de aprendizaje, 2018.
[2] Laurens van der Maaten y Geoffrey Hinton. Visualización de datos usando t-SNE. Revista de investigación sobre aprendizaje automático, 9:2579–2605, 2008. URL http://www.jmlr.org/papers/v9/vandermaaten08a.html.
Acerca de los autores
 Nathalie Rauschmayr es científica aplicada sénior en AWS, donde ayuda a los clientes a desarrollar aplicaciones de aprendizaje profundo.
Nathalie Rauschmayr es científica aplicada sénior en AWS, donde ayuda a los clientes a desarrollar aplicaciones de aprendizaje profundo.
 Yigitcan Kaya es un estudiante de doctorado de quinto año en la Universidad de Maryland y un pasante científico aplicado en AWS, que trabaja en la seguridad del aprendizaje automático y las aplicaciones del aprendizaje automático para la seguridad.
Yigitcan Kaya es un estudiante de doctorado de quinto año en la Universidad de Maryland y un pasante científico aplicado en AWS, que trabaja en la seguridad del aprendizaje automático y las aplicaciones del aprendizaje automático para la seguridad.
 Bilal Zafar es científico aplicado en AWS y trabaja en equidad, explicabilidad y seguridad en el aprendizaje automático.
Bilal Zafar es científico aplicado en AWS y trabaja en equidad, explicabilidad y seguridad en el aprendizaje automático.
 sergul aydore es un científico aplicado sénior en AWS que trabaja en privacidad y seguridad en el aprendizaje automático
sergul aydore es un científico aplicado sénior en AWS que trabaja en privacidad y seguridad en el aprendizaje automático
- Coinsmart. El mejor intercambio de Bitcoin y criptografía de Europa.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. ACCESO LIBRE.
- CriptoHawk. Radar de altcoins. Prueba gratis.
- Fuente: https://aws.amazon.com/blogs/machine-learning/detect-adversarial-inputs-using-amazon-sagemaker-model-monitor-and-amazon-sagemaker-debugger/
- "
- 10
- 100
- 67
- 9
- Nuestra Empresa
- de la máquina
- Conforme
- Mi Cuenta
- lector activo
- Adicionales
- avanzado
- Todos
- Amazon
- cantidad
- análisis
- aplicaciones
- La aplicación de
- aproximadamente
- AWS
- fondo
- Base
- base
- a las que has recomendado
- "Ser"
- Bloquear
- llamar al
- capturar
- cases
- el cambio
- Cheques
- clase
- privadas
- clasificación
- más cerca
- código
- recoger
- Columna
- Calcular
- Congreso
- Configuración
- Envase
- contribuir
- creado
- Delito
- personalizado
- Clientes
- datos
- más profundo
- Defensa
- demostrado
- desplegar
- desplegado
- detectado
- Detección
- desarrollar
- una experiencia diferente
- difícil
- Pantalla
- Docker
- No
- Eficaz
- personas
- habilitar
- Punto final
- Entorno
- estimación
- Evento
- ejemplo
- esperar
- Cara
- caras
- Feature
- Figura
- Nombre
- se centra
- siguiendo
- adelante
- encontrado
- FRAME
- ser completados
- función
- promover
- la generación de
- va
- mayor
- ayuda
- esta página
- más alto
- Cómo
- Como Hacer
- HTTPS
- idea
- imagen
- Impacto
- índice
- INSTRUMENTO individual
- información
- Las opciones de entrada
- investigar
- cuestiones
- IT
- Trabajos
- Empleo
- revista
- Clave
- especialistas
- conocido
- Etiquetas
- large
- APRENDE:
- aprendizaje
- LED
- Nivel
- que otros
- Lista
- Listado
- Ubicación
- .
- máquina
- máquina de aprendizaje
- Mapas
- Maryland
- Métrica
- MIT
- ML
- modelo
- modelos
- Monitorear
- monitoreo
- más,
- MEJOR DE TU
- múltiples
- Natural
- Naturaleza
- del sistema,
- ruido
- normal
- cuaderno
- número
- números
- Otro
- (PDF)
- porcentaje
- fase
- punto
- posible
- poderoso
- predecir
- predicción
- Predicciones
- presente
- política de privacidad
- Privacidad y Seguridad
- en costes
- producir
- producido
- proporciona un
- proporcionando
- Tarifas
- Crudo
- reconocer
- registrarte
- regular
- reporte
- repositorio
- solicita
- solicitudes
- la investigación
- Resultados
- devoluciones
- reglas
- Ejecutar
- correr
- Escala
- Científico
- EN LINEA
- seleccionado
- set
- importante
- similares
- sencillos
- SEIS
- chica
- So
- algo
- sofisticado
- Espacio
- específicamente
- comienzo
- el estado de la técnica
- estadístico
- statistics
- estadísticas
- Estado
- STORAGE
- Estudiante
- test
- Pruebas
- pruebas
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- equipo
- parte superior
- hacia
- Formación
- juicio
- universidad
- us
- utilizan el
- usuarios
- generalmente
- propuesta de
- visibles
- visualización
- Vulnerable
- ¿
- sean
- mientras
- Blackpaper
- Wikipedia
- trabajando
- se
- año
- años