En el dinámico mundo de la computación en la nube, garantizar la resiliencia y la disponibilidad de las aplicaciones críticas es primordial. Recuperación de desastres (DR) es el proceso mediante el cual una organización anticipa y aborda desastres relacionados con la tecnología. Para organizaciones que implementan la orquestación de cargas de trabajo críticas utilizando Flujos de trabajo administrados por Amazon para Apache Airflow (Amazon MWAA), es fundamental contar con un plan de recuperación ante desastres para garantizar la continuidad del negocio.
En esta serie, exploramos la necesidad de recuperación ante desastres de Amazon MWAA y prescribimos soluciones que sostendrán los entornos de Amazon MWAA contra interrupciones no deseadas. Esto le permite definir, evitar y gestionar riesgos de interrupción como parte de su plan de continuidad empresarial. Esta publicación se centra en el diseño de la arquitectura general de DR. Una publicación futura de esta serie se centrará en la implementación de los componentes individuales utilizando los servicios de AWS.
La necesidad de la recuperación ante desastres de Amazon MWAA
Amazon MWAA, un servicio totalmente administrado para Flujo de aire Apache, aporta un valor inmenso a las organizaciones al automatizar la orquestación del flujo de trabajo para cargas de trabajo de extracción, transformación y carga (ETL), DevOps y aprendizaje automático (ML). Amazon MWAA tiene una arquitectura distribuida con múltiples componentes como programador, trabajador, servidor web, cola y base de datos. Esto dificulta la implementación de una estrategia integral de recuperación ante desastres.
Un entorno activo de Amazon MWAA analiza continuamente Airflow Gráficos acíclicos dirigidos (DAG), leyéndolos desde un dispositivo configurado Servicio de almacenamiento simple de Amazon (Amazon S3) cubo. La falta de disponibilidad de la fuente DAG debido a la inaccesibilidad de la red, corrupción no intencionada o eliminaciones provoca un tiempo de inactividad prolongado e interrupción del servicio.
Dentro de Airflow, la base de datos de metadatos es un componente central que almacena variables de configuración, roles, permisos e historiales de ejecución de DAG. Por lo tanto, una base de datos de metadatos en buen estado es fundamental para su entorno de Airflow. Al igual que con cualquier componente central de Airflow, es esencial contar con un plan de respaldo y recuperación ante desastres para la base de datos de metadatos.
Amazon MWAA implementa componentes de Airflow en múltiples Zonas de disponibilidad dentro de su VPC en su preferencia Región de AWS. Esto proporciona tolerancia a fallos y recuperación automática frente a un único fallo de zona de disponibilidad. Para cargas de trabajo de misión crítica, ser resiliente a las deficiencias de una región unitaria a través de implementaciones en varias regiones es además importante para garantizar una alta disponibilidad y continuidad del negocio.
Equilibrar los costos de mantener infraestructuras redundantes, la complejidad y el tiempo de recuperación es esencial para los entornos de Amazon MWAA. Las organizaciones buscan soluciones rentables que minimicen sus Objetivo de tiempo de recuperación (RTO) y Objetivo de punto de recuperación (RPO) para cumplir con sus acuerdos de nivel de servicio, ser económicamente viables y satisfacer las demandas de sus clientes.
Detectar desastres en el entorno primario: Monitoreo proactivo a través de métricas y alarmas
La detección rápida de desastres en el entorno primario es crucial para una recuperación oportuna. Seguimiento de la Reloj en la nube de Amazon Métrica SchedulerHeartbeat proporciona información sobre el estado del flujo de aire de un entorno activo de Amazon MWAA. Puede agregar otras métricas de verificación de estado a los criterios de evaluación, como verificar la disponibilidad de sistemas ascendentes o descendentes y la accesibilidad de la red. Combinado con Alarmas de CloudWatch, puede enviar notificaciones cuando no se cumplan estos umbrales durante varios períodos de tiempo. Puede agregar alarmas a los paneles para monitorear y recibir alertas sobre sus recursos y aplicaciones de AWS en varias regiones.
AWS publica nuestra información más actualizada sobre la disponibilidad del servicio en el Panel de estado del servicio. Puede verificar en cualquier momento para obtener información sobre el estado actual o suscribirse a una fuente RSS para recibir notificaciones sobre las interrupciones de cada servicio individual en su región operativa. El Panel de estado de AWS proporciona información sobre los eventos de AWS Health que pueden afectar su cuenta.
Al combinar el monitoreo de métricas, los paneles disponibles y las alarmas automáticas, puede detectar rápidamente la falta de disponibilidad de su entorno principal, lo que permite tomar medidas proactivas para la transición a su plan de recuperación ante desastres. Es fundamental tener en cuenta la detección, notificación, escalamiento, descubrimiento y declaración de incidentes en su planificación e implementación de recuperación ante desastres para proporcionar objetivos realistas y alcanzables que proporcionen valor comercial.
En las siguientes secciones, analizamos dos soluciones de estrategia de recuperación ante desastres de Amazon MWAA y su arquitectura.
Solución de estrategia de recuperación ante desastres 1: copia de seguridad y restauración
La estrategia de copia de seguridad y restauración implica generar copias de seguridad del componente Airflow en la misma región o en una región diferente que su entorno principal de Amazon MWAA. Para garantizar la continuidad, puede replicarlos de forma asíncrona en su región de recuperación ante desastres, con un impacto mínimo en el rendimiento de su entorno principal de Amazon MWAA. En caso de que se produzca un deterioro regional primario poco común o una interrupción del servicio, esta estrategia creará un nuevo entorno Amazon MWAA y recuperará datos históricos a partir de las copias de seguridad existentes. Sin embargo, es importante tener en cuenta que durante el proceso de recuperación, habrá un período en el que ningún entorno Airflow estará operativo para procesar flujos de trabajo hasta que el nuevo entorno esté completamente aprovisionado y marcado como disponible.
Esta estrategia proporciona una solución de bajo costo y baja complejidad que también es adecuada para mitigar la pérdida o corrupción de datos dentro de su región principal. La cantidad de datos de los que se realiza una copia de seguridad y el tiempo para crear un nuevo entorno de Amazon MWAA (normalmente entre 20 y 30 minutos) afectan la rapidez con la que se puede realizar la restauración. Para permitir que la infraestructura se vuelva a implementar rápidamente sin errores, implemente usando infraestructura como código (IAC). Sin IaC, puede resultar complejo restaurar un entorno de recuperación ante desastres análogo, lo que aumentará los tiempos de recuperación y posiblemente superará su RTO.
Exploremos la configuración necesaria cuando su entorno principal de Amazon MWAA se está ejecutando activamente, como se muestra en la siguiente figura.
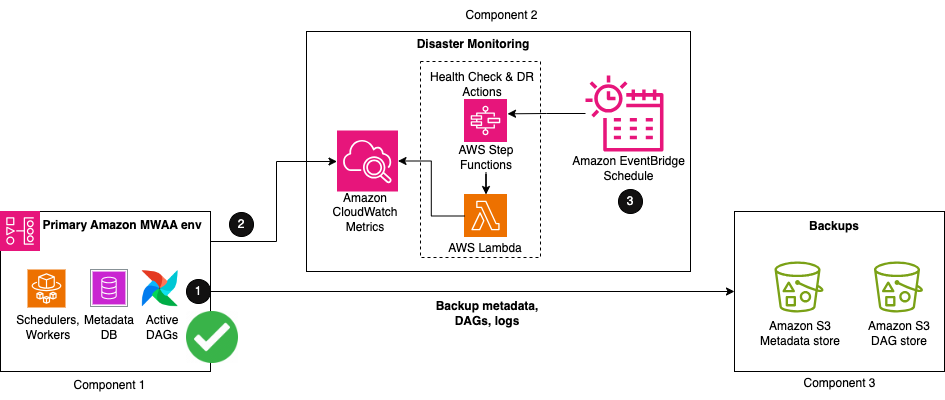
La solución consta de tres componentes clave. El primer componente es el entorno principal, donde los flujos de trabajo de Airflow se implementan inicialmente y se ejecutan activamente. El segundo componente es el componente de monitoreo de desastres, compuesto por CloudWatch y una combinación de un Funciones de paso de AWS máquina de estados y AWS Lambda función. El tercer componente sirve para crear y almacenar copias de seguridad de todas las configuraciones y metadatos que se requieren para restaurar. Esto puede estar en la misma región que su principal o replicarse en su región DR usando Replicación entre regiones de S3 (RRC). Para CRR, también paga por la transferencia de datos entre regiones desde Amazon S3 a cada región de destino.
Los primeros tres pasos del flujo de trabajo son los siguientes:
- Como parte del proceso de creación de copias de seguridad, los metadatos de Airflow se replican en un depósito de S3 mediante un exportar DAG utilidad, ejecútela periódicamente según su intervalo de RPO.
- Su entorno principal de Amazon MWAA existente emite automáticamente el estado de salud de su programador a CloudWatch. ProgramadorHeartbeat métrico.
- Un paso de varios pasos Funciones máquina estatal se activa de forma periódica Puente de eventos de Amazon programa para monitorear el estado de salud del programador. Como paso principal de la máquina de estado, una función Lambda evalúa el estado de la ProgramadorHeartbeat métrico. Si la métrica se considera correcta, no se toma ninguna medida.
La siguiente figura ilustra los pasos adicionales en el flujo de trabajo de la solución.
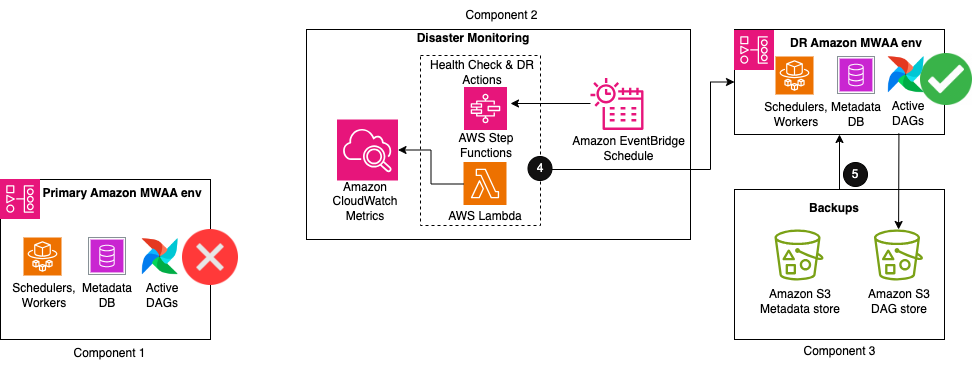
- Cuando el recuento de latidos se desvía del recuento normal durante un período de tiempo, se inicia una serie de acciones para recuperarse en un nuevo entorno de Amazon MWAA en la región DR. Estas acciones incluyen iniciar la creación de un nuevo entorno de Amazon MWAA, replicar las configuraciones del entorno principal y luego esperar a que el nuevo entorno esté disponible.
- Cuando el entorno está disponible, un importar DAG La utilidad se ejecuta para restaurar el contenido de los metadatos de las copias de seguridad. Cualquier ejecución de DAG que se haya interrumpido durante el deterioro del entorno primario debe volver a ejecutarse manualmente para mantener los acuerdos de nivel de servicio. Las ejecuciones futuras de DAG se ponen en cola para ejecutarse según su próxima programación configurada.
Solución de estrategia de recuperación ante desastres 2: entornos activo-pasivo con sincronización periódica de datos
Los entornos activo-pasivo con estrategia de sincronización de datos periódica se centran en mantener la sincronización de datos recurrente entre un entorno de DR de Amazon MWAA primario activo y uno pasivo. Al actualizar y sincronizar periódicamente los almacenes DAG y las bases de datos de metadatos, esta estrategia garantiza que el entorno de recuperación ante desastres permanezca actualizado o casi actualizado con el principal. La región de recuperación ante desastres puede ser la misma región o una diferente que su entorno principal de Amazon MWAA. En caso de un desastre, hay copias de seguridad disponibles para volver a un buen estado anterior conocido para minimizar la pérdida o corrupción de datos.
Esta estrategia proporciona RTO y RPO bajos con sincronización frecuente, lo que permite una recuperación rápida con una pérdida de datos mínima. Los costos de infraestructura y las implementaciones de código se combinan para mantener los entornos primario y de recuperación ante desastres de Amazon MWAA. Su entorno de recuperación ante desastres está disponible de inmediato para ejecutar DAG.
La siguiente figura ilustra la configuración necesaria cuando su entorno principal de Amazon MWAA se está ejecutando activamente.
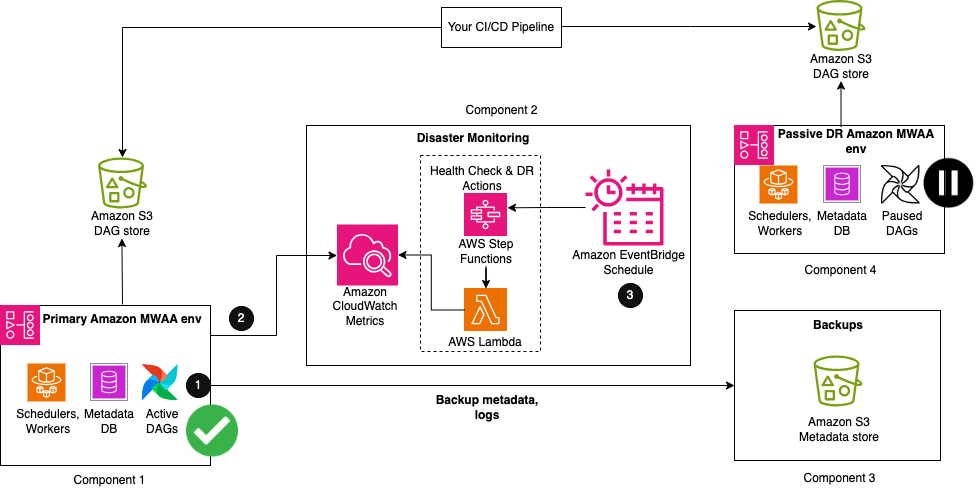
La solución consta de cuatro componentes clave. De manera similar a la solución de copia de seguridad y restauración, el primer componente es el entorno principal, donde el flujo de trabajo se implementa inicialmente y se ejecuta activamente. El segundo componente es el componente de monitoreo de desastres, que consta de CloudWatch y una combinación de una máquina de estado de Step Functions y una función Lambda. El tercer componente crea y almacena copias de seguridad de todas las configuraciones y metadatos necesarios para la sincronización de la base de datos. Esto puede estar en la misma región que su región principal o replicarse en su región de recuperación ante desastres mediante la replicación entre regiones de Amazon S3. Como se mencionó anteriormente, para CRR, también paga por la transferencia de datos entre regiones desde Amazon S3 a cada región de destino. El último componente es un entorno pasivo de Amazon MWAA que tiene el mismo código de Airflow y configuraciones de entorno que el principal. Los DAG se implementan en el entorno de recuperación ante desastres utilizando el mismo proceso de integración y entrega continuas (CI/CD) que el principal. A diferencia del principal, los DAG se mantienen en estado de pausa para no provocar ejecuciones duplicadas.
Los primeros pasos del flujo de trabajo son similares a la estrategia de copia de seguridad y restauración:
- Como parte de su proceso de creación de respaldo, los metadatos de Airflow se replican en un depósito de S3 mediante una utilidad DAG de exportación, que se ejecuta periódicamente según su intervalo de RPO.
- Su entorno principal de Amazon MWAA existente emite automáticamente el estado de salud de su programador a CloudWatch ProgramadorHeartbeat métrico.
- Una máquina de estado de Step Functions de varios pasos se activa a partir de una programación periódica de Amazon EventBridge para monitorear el estado de salud del programador. Como paso principal de la máquina de estado, una función Lambda evalúa el estado de la ProgramadorHeartbeat métrico. Si la métrica se considera correcta, no se toma ninguna medida.
La siguiente figura ilustra los pasos finales del flujo de trabajo.
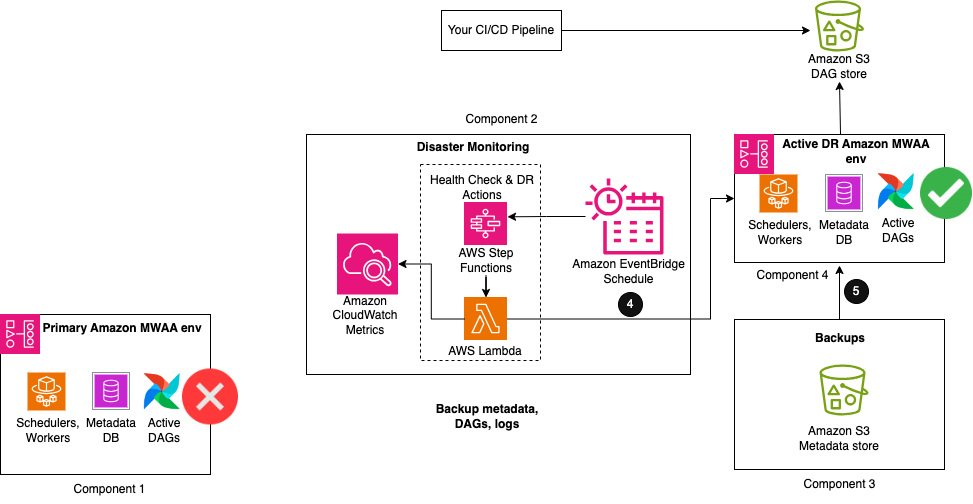
- Cuando el recuento de latidos se desvía del recuento normal durante un período de tiempo, se inician acciones de recuperación ante desastres.
- Como primer paso, una función Lambda activa una utilidad DAG de importación para restaurar el contenido de los metadatos de las copias de seguridad en el entorno pasivo de DR de Amazon MWAA. Cuando se completan las importaciones, el mismo DAG puede reanudar la pausa de los otros DAG de Airflow y activarlos para ejecuciones futuras. Cualquier ejecución de DAG que se haya interrumpido durante el deterioro del entorno primario debe volver a ejecutarse manualmente para mantener los acuerdos de nivel de servicio. Las ejecuciones futuras de DAG se ponen en cola para ejecutarse según su próxima programación configurada.
Mejores prácticas para mejorar la resiliencia de Amazon MWAA
Para mejorar la resiliencia de su entorno de Amazon MWAA y garantizar una recuperación ante desastres sin problemas, considere implementar las siguientes mejores prácticas:
- Robustos mecanismos de copia de seguridad y restauración – Es esencial implementar mecanismos integrales de copia de seguridad y restauración de los datos de Amazon MWAA. La eliminación periódica de metadatos existentes según las políticas de retención de su organización reduce los tiempos de respaldo y hace que su entorno de Amazon MWAA tenga más rendimiento.
- Automatización usando IaC – Utilizar herramientas de automatización y orquestación como Formación en la nube de AWS, el Kit de desarrollo en la nube de AWS (CDK de AWS), o Terraform puede optimizar la administración de implementación y configuración de entornos Amazon MWAA. Esto garantiza coherencia, reproducibilidad y una recuperación más rápida durante escenarios de recuperación ante desastres.
- DAG y tareas idempotentes – En Airflow, un DAG se considera idempotente si volver a ejecutar el mismo DAG con las mismas entradas varias veces tiene el mismo efecto que ejecutarlo solo una vez. Diseñar DAG idempotentes y mantener las tareas atómicas reduce el tiempo de recuperación de fallas cuando tiene que volver a ejecutar manualmente un DAG interrumpido en su entorno recuperado.
- Pruebas y validaciones periódicas – Una estrategia sólida de recuperación ante desastres de Amazon MWAA debe incluir ejercicios periódicos de prueba y validación. Al simular escenarios de desastre, puede identificar cualquier brecha en sus planes de recuperación ante desastres, ajustar los procesos y garantizar que sus entornos de Amazon MWAA sean completamente recuperables.
Conclusión
En esta publicación, exploramos los desafíos para la recuperación ante desastres de Amazon MWAA y analizamos las mejores prácticas para mejorar la resiliencia. Examinamos dos soluciones de estrategia de recuperación ante desastres: respaldo y restauración y entornos activo-pasivo con sincronización periódica de datos. Al implementar estas soluciones y seguir las mejores prácticas, puede proteger sus entornos de Amazon MWAA, minimizar el tiempo de inactividad y mitigar el impacto de los desastres. Las pruebas, la validación y la adaptación periódicas a los requisitos cambiantes son cruciales para una estrategia eficaz de recuperación ante desastres de Amazon MWAA. Al evaluar y perfeccionar continuamente sus planes de recuperación ante desastres, puede garantizar la resiliencia y el funcionamiento ininterrumpido de sus entornos Amazon MWAA, incluso ante eventos imprevistos.
Para obtener detalles adicionales y ejemplos de código en Amazon MWAA, consulte la Guía del usuario de Amazon MWAA y del Ejemplos de repositorio de GitHub de Amazon MWAA.
Acerca de los autores
 Parnab Basak es arquitecto senior de soluciones y especialista sin servidor en AWS. Se especializa en la creación de nuevas soluciones nativas de la nube utilizando prácticas modernas de desarrollo de software como sin servidor, DevOps y análisis. Parnab trabaja estrechamente en el espacio de servicios de integración y análisis ayudando a los clientes a adoptar los servicios de AWS para sus necesidades de orquestación de flujo de trabajo.
Parnab Basak es arquitecto senior de soluciones y especialista sin servidor en AWS. Se especializa en la creación de nuevas soluciones nativas de la nube utilizando prácticas modernas de desarrollo de software como sin servidor, DevOps y análisis. Parnab trabaja estrechamente en el espacio de servicios de integración y análisis ayudando a los clientes a adoptar los servicios de AWS para sus necesidades de orquestación de flujo de trabajo.
 Chandan Rupakheti es arquitecto de soluciones y especialista sin servidor en AWS. Es un apasionado líder técnico, investigador y mentor con una habilidad especial para crear soluciones innovadoras en la nube y unir a las partes interesadas en su viaje a la nube. Fuera de su vida profesional, le encanta pasar tiempo con su familia y amigos además de escuchar y tocar música.
Chandan Rupakheti es arquitecto de soluciones y especialista sin servidor en AWS. Es un apasionado líder técnico, investigador y mentor con una habilidad especial para crear soluciones innovadoras en la nube y unir a las partes interesadas en su viaje a la nube. Fuera de su vida profesional, le encanta pasar tiempo con su familia y amigos además de escuchar y tocar música.
 Vinod Jayendra es líder de soporte empresarial en cuentas ISV en Amazon Web Services, donde ayuda a los clientes a resolver sus desafíos arquitectónicos, operativos y de optimización de costos. Con un enfoque particular en tecnologías sin servidor, aprovecha su amplia experiencia en desarrollo de aplicaciones para ofrecer soluciones de primer nivel. Más allá del trabajo, disfruta del tiempo de calidad en familia, de embarcarse en aventuras en bicicleta y de entrenar equipos deportivos juveniles.
Vinod Jayendra es líder de soporte empresarial en cuentas ISV en Amazon Web Services, donde ayuda a los clientes a resolver sus desafíos arquitectónicos, operativos y de optimización de costos. Con un enfoque particular en tecnologías sin servidor, aprovecha su amplia experiencia en desarrollo de aplicaciones para ofrecer soluciones de primer nivel. Más allá del trabajo, disfruta del tiempo de calidad en familia, de embarcarse en aventuras en bicicleta y de entrenar equipos deportivos juveniles.
 Rupesh Tiwari es arquitecto senior de soluciones en AWS en la ciudad de Nueva York, con especialización en servicios financieros. Tiene más de 18 años de experiencia en TI en los ámbitos de las finanzas, los seguros y la educación, y se especializa en la arquitectura de aplicaciones a gran escala y cargas de trabajo de big data nativas de la nube. En su tiempo libre, a Rupesh le gusta cantar karaoke, ver series de televisión de comedia y crear momentos alegres con su familia.
Rupesh Tiwari es arquitecto senior de soluciones en AWS en la ciudad de Nueva York, con especialización en servicios financieros. Tiene más de 18 años de experiencia en TI en los ámbitos de las finanzas, los seguros y la educación, y se especializa en la arquitectura de aplicaciones a gran escala y cargas de trabajo de big data nativas de la nube. En su tiempo libre, a Rupesh le gusta cantar karaoke, ver series de televisión de comedia y crear momentos alegres con su familia.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/disaster-recovery-strategies-for-amazon-mwaa-part-1/
- :posee
- :es
- :no
- :dónde
- $ UP
- 1
- 100
- 110
- 400
- a
- Nuestra Empresa
- Mi Cuenta
- Cuentas
- realizable
- a través de
- la columna Acción
- acciones
- lector activo
- activamente
- acíclico
- adaptaciónes
- add
- Adicionales
- Adicionalmente
- direcciones
- adoptar
- aventuras
- afectar
- afecta
- en contra
- acuerdos
- objetivo
- Alertas
- Todos
- Permitir
- también
- Amazon
- Amazon Web Services
- cantidad
- an
- Analytics
- y
- anticipa
- cualquier
- APACHE
- Aplicación
- Desarrollo de aplicaciones
- aplicaciones
- arquitectónico
- arquitectura
- somos
- AS
- At
- Automático
- automáticamente
- automatizar
- Automatización
- disponibilidad
- Hoy Disponibles
- evitar
- AWS
- Respaldados
- fondo
- Backup
- copias de seguridad
- basado
- BE
- a las que has recomendado
- "Ser"
- además de
- MEJOR
- y las mejores prácticas
- entre
- Más allá de
- Big
- Big Data
- ambas
- Trayendo
- Trae
- Construir la
- continuidad del negocio
- by
- PUEDEN
- Causa
- retos
- comprobar
- comprobación
- Ciudad
- de cerca
- Soluciones
- la computación en nube
- nativo de la nube
- ENTRENAMIENTO
- código
- combinación
- combinado
- combinar
- Comedia
- completar
- integraciones
- complejidad
- componente
- componentes
- agravado
- exhaustivo
- Compuesto
- incluido
- informática
- Configuración
- externa (Biomet XNUMXi)
- configurado
- Considerar
- considerado
- Que consiste
- contenido
- continuidad
- continuo
- continuamente
- Core
- Corrupción
- Cost
- rentable
- Precio
- Para crear
- crea
- Creamos
- creación
- criterios
- crítico
- crucial
- Current
- Clientes
- DÍA
- de los tableros
- datos
- De pérdida de datos
- Base de datos
- bases de datos
- declaración
- disminuye
- juzgado
- definir
- entregamos
- entrega
- demandas
- desplegar
- desplegado
- despliegue
- Despliegues
- despliega
- diseño
- destino
- detalles
- detectar
- Detección
- Desarrollo
- DevOps
- una experiencia diferente
- difícil
- desastre
- desastres
- descubrimiento
- discutir
- discutido
- Interrupción
- interrupciones
- dominios
- el tiempo de inactividad
- dr
- dibujos
- dos
- durante
- lugar de trabajo dinámico
- cada una
- Más temprano
- Educación
- efecto
- Eficaz
- embarcarse
- habilitar
- permitiendo
- mejorar
- garantizar
- asegura
- asegurando que
- Empresa
- Entorno
- ambientes
- Errores
- escalada
- esencial
- Éter (ETH)
- evaluación
- evaluación
- Incluso
- Evento
- Eventos
- evolución
- ejemplos
- exceden
- ejercicios
- existente
- experience
- explorar
- explorado
- exportar
- extendido
- en los detalles
- extraerlos
- Cara
- factor
- Fracaso
- fallas
- familia
- más rápida
- Figura
- final
- financiar
- financiero
- servicios financieros
- encuentra
- Nombre
- primeros pasos
- Focus
- se centra
- siguiendo
- siguiente
- Digital XNUMXk
- frecuente
- amigos
- Desde
- completamente
- función
- funciones
- futuras
- lagunas
- la generación de
- obtener
- GitHub
- candidato
- encargarse de
- suceder
- Tienen
- es
- he
- Salud
- saludable
- ayudando
- ayuda
- Alta
- su
- histórico
- historias
- Cómo
- Sin embargo
- HTML
- http
- HTTPS
- IAC
- Identifique
- if
- ilustra
- inmediatamente
- inmenso
- Impacto
- discapacidad
- implementar
- implementación
- implementación
- importar
- importante
- importaciones
- mejorar
- in
- incidente
- incluir
- aumentado
- INSTRUMENTO individual
- información
- EN LA MINA
- infraestructura
- posiblemente
- iniciado
- originales
- entradas
- Insights
- aseguradora
- integración
- interrumpido
- dentro
- implica
- Isv
- IT
- SUS
- alegría
- jpg
- acuerdo
- mantenido
- Clave
- conocido
- Gran escala
- Apellido
- Lead
- líder
- Prospectos
- aprendizaje
- Permíteme
- Nivel
- Vida
- como
- Escucha Activa
- carga
- de
- ama
- Baja
- de bajo costo
- máquina
- máquina de aprendizaje
- mantener
- el mantenimiento de
- HACE
- Realizar
- gestionado
- Management
- a mano
- marcado
- Puede..
- medidas
- los mecanismos de
- Conoce a
- mencionado
- mentor
- las etiquetas
- metadatos
- métrico
- Métrica
- mínimo
- minimizar
- minutos
- Mitigar las
- mitigar
- ML
- Moderno
- Momentos
- Monitorear
- monitoreo
- más,
- MEJOR DE TU
- múltiples
- Música
- nativo
- hace casi
- ¿ Necesita ayuda
- del sistema,
- Nuevo
- nuevas soluciones
- New York
- Ciudad de Nueva York
- Next
- no
- normal
- nota
- .
- notificaciones
- número
- ,
- of
- on
- una vez
- , solamente
- funcionamiento
- Inteligente
- operativos.
- optimización
- or
- orquestación
- organización
- para las fiestas.
- Otro
- nuestros
- salir
- afuera
- Más de
- total
- supremo
- parte
- particular
- apasionado
- pasivo
- pausa
- Pagar
- para
- actuación
- período
- periódico
- períodos
- permisos
- industrial
- Colocar
- plan
- planificar
- jubilación
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- jugando
- punto
- políticas
- posiblemente
- Publicación
- prácticas
- pre
- preferido
- prescribir
- anterior
- primario
- Proactiva
- en costes
- Profesional
- proteger
- proporcionar
- proporciona un
- Publica
- calidad
- Búsqueda
- con rapidez
- RARO
- Reading
- realista
- recepción
- Recuperar
- recuperable
- recuperación
- recurrente
- reduce
- redundante
- remitir
- refinación
- región
- regional
- regiones
- regular
- regularmente
- permanece
- replicado
- replicación
- Requisitos
- Requisitos
- investigador
- resiliencia y se la estamos enseñando a nuestro hijos e hijas.
- resistente
- Recursos
- restauración
- restaurar
- retención
- revertir
- riesgos
- robusto
- También soy miembro del cuerpo docente de World Extreme Medicine (WEM) y embajadora europea de igualdad para The Transformational Travel Council (TTC). En mi tiempo libre, soy una incansable aventurera, escaladora, patrona de día, buceadora y defensora de la igualdad de género en el deporte y la aventura. En XNUMX, fundé Almas Libres, una ONG nacida para involucrar, educar y empoderar a mujeres y niñas a través del deporte urbano, la cultura y la tecnología.
- rss
- Ejecutar
- correr
- corre
- Rupesh
- mismo
- escenarios
- programa
- Segundo
- (secciones)
- envío
- mayor
- Serie
- servidor
- Sin servidor
- de coches
- Servicios
- Configure
- tienes
- mostrado
- similares
- sencillos
- soltero
- sencillo.
- Software
- Desarrollo de software ad-hoc
- a medida
- Soluciones
- Resolver
- Fuente
- Espacio
- especialista
- se especializa
- Gastos
- Deportes
- las partes interesadas
- Comience a
- Estado
- Estado
- paso
- pasos
- STORAGE
- tiendas
- estrategias
- Estrategia
- aerodinamizar
- Suscríbase
- tal
- adecuado
- SOPORTE
- sincronización
- Todas las funciones a su disposición
- toma
- tareas
- equipo
- Técnico
- Tecnologías
- Terraform
- Pruebas
- que
- esa
- La
- El Estado
- su
- Les
- luego
- Ahí.
- por lo tanto
- Estas
- Código
- así
- Tres
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- equipo
- oportuno
- veces
- a
- juntos
- tolerancia
- transferir
- Transformar
- transición
- desencadenados
- tv
- Series de TV
- dos
- típicamente
- imprevisto
- ininterrumpido
- diferente a
- hasta
- actualización
- Usuario
- usando
- utilidad
- validación
- propuesta de
- las variables
- y
- Esperando
- ver
- we
- web
- servidor web
- servicios web
- tuvieron
- cuando
- que
- seguirá
- dentro de
- sin
- Actividades:
- obrero
- flujo de trabajo
- flujos de trabajo
- funciona
- mundo
- años
- york
- Usted
- tú
- juventudes
- zephyrnet