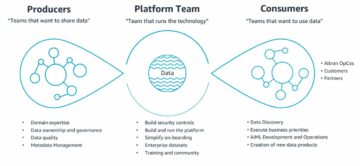
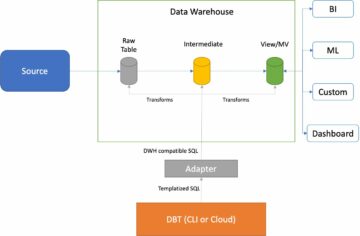
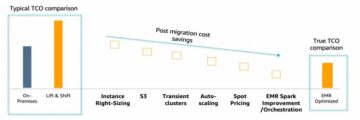
Hoy en día, cientos de miles de clientes utilizan lagos de datos para análisis y aprendizaje automático. Sin embargo, los ingenieros de datos tienen que limpiar y preparar estos datos antes de que puedan usarse. Los datos subyacentes deben ser precisos y recientes para que el cliente pueda tomar decisiones comerciales seguras. De lo contrario, los consumidores de datos pierden la confianza en los datos y toman decisiones subóptimas o incorrectas. Es una tarea común para los ingenieros de datos evaluar si los datos son precisos y recientes o no. Hoy en día existen diversas herramientas de calidad de datos. Sin embargo, las herramientas comunes de calidad de datos generalmente requieren procesos manuales para monitorear la calidad de los datos.
AWS Glue Data Quality es una función de vista previa de Pegamento AWS que mide y monitorea la calidad de los datos de Servicio de almacenamiento simple de Amazon (Amazon S3) lagos de datos y en trabajos de extracción, transformación y carga (ETL) de AWS Glue. Esta es una función de vista previa abierta, por lo que ya está habilitada en su cuenta en el Regiones disponibles. Puede definir y medir fácilmente las comprobaciones de calidad de los datos en la consola de AWS Glue Studio sin escribir códigos. Simplifica su experiencia en la gestión de la calidad de los datos.
Esta publicación es la Parte 2 de una serie de cuatro publicaciones para explicar cómo funciona AWS Glue Data Quality. Echa un vistazo a la publicación anterior de esta serie:
En esta publicación, mostramos cómo crear un trabajo de AWS Glue que mide y monitorea la calidad de los datos de una canalización de datos. También mostramos cómo tomar medidas en función de los resultados de calidad de los datos.
Resumen de la solución
Consideremos un caso de uso de ejemplo en el que un ingeniero de datos necesita crear una canalización de datos para ingerir los datos de una zona sin procesar a una zona seleccionada en un lago de datos. Como ingeniero de datos, una de sus responsabilidades clave, junto con la extracción, transformación y carga de datos, es validar la calidad de los datos. La identificación de problemas de calidad de datos por adelantado lo ayuda a evitar colocar datos incorrectos en la zona seleccionada y evitar incidentes de corrupción de datos arduos.
En esta publicación, aprenderá cómo configurar fácilmente incorporado y personalizado verificaciones de validación de datos en su trabajo de AWS Glue para evitar que los datos incorrectos dañen los datos de alta calidad posteriores.
El conjunto de datos utilizado para esta publicación se genera sintéticamente; la siguiente captura de pantalla muestra un ejemplo de los datos.

Configurar recursos con AWS CloudFormation
Esta publicación incluye un Formación en la nube de AWS plantilla para una configuración rápida. Puede revisarlo y personalizarlo para que se adapte a sus necesidades.
La plantilla de CloudFormation genera los siguientes recursos:
- Un depósito de Amazon Simple Storage Service (Amazon S3) (
gluedataqualitystudio-*). - Los siguientes prefijos y objetos en el depósito de S3:
datalake/raw/customer/customer.csvdatalake/curated/customer/scripts/sparkHistoryLogs/temporary/
- Gestión de identidades y accesos de AWS (IAM) usuarios, roles y políticas. El rol de IAM (
GlueDataQualityStudio-*) tiene permiso para leer y escribir desde el depósito S3. - AWS Lambda funciones y políticas de IAM requeridas por esas funciones para crear y eliminar esta pila.
Para crear sus recursos, complete los siguientes pasos:
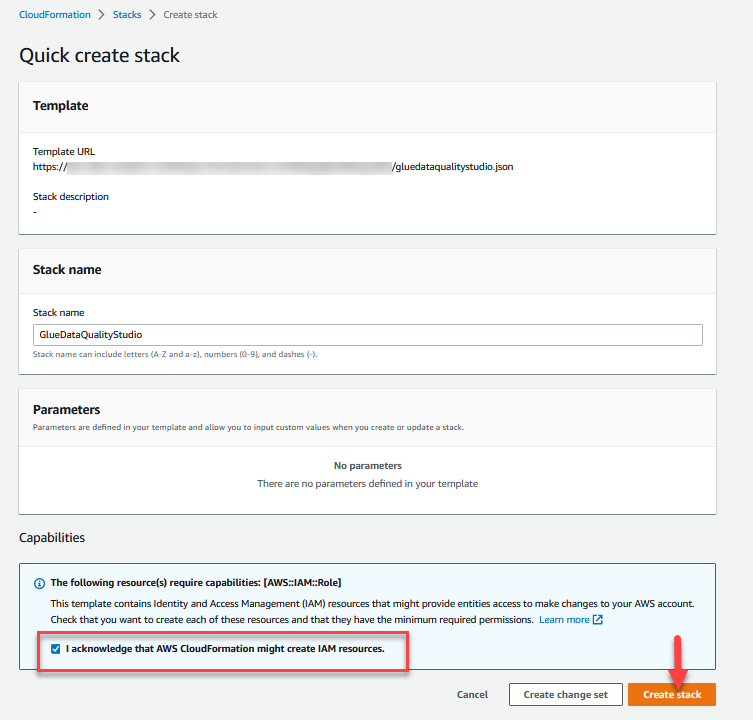
- Inicia sesión en el Consola de AWS CloudFormation existentes
us-east-1Región. - Elige Pila de lanzamiento:

- Seleccione Reconozco que AWS CloudFormation podría crear recursos de IAM.
- Elige Crear pila y espere a que se complete el paso de creación de la pila.
Implementar la solución
Para comenzar a configurar su solución, complete los siguientes pasos:
- En Consola de AWS Glue Studio, escoger Empleo en el panel de navegación.
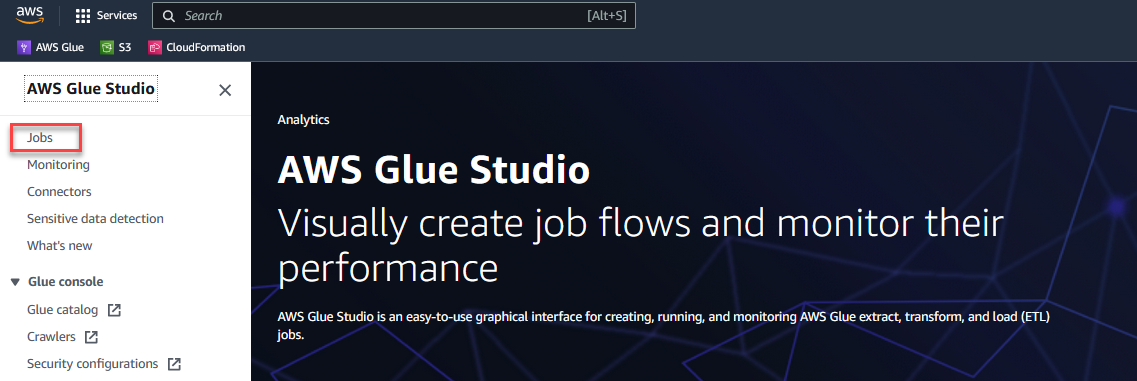
- Seleccione Visual con un lienzo en blanco y elige Crear.
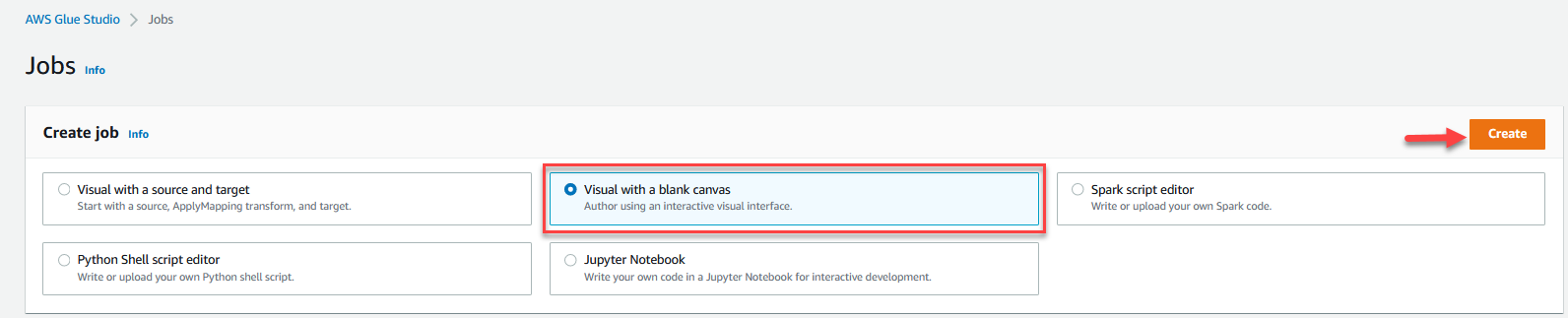
- Elija el Detalles del trabajo pestaña para configurar el trabajo.
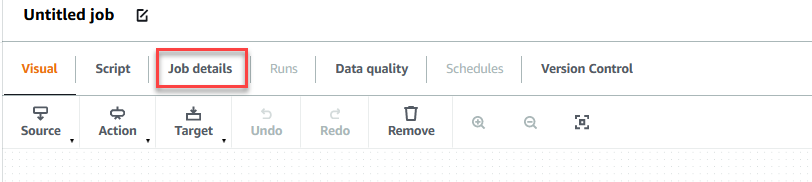
- Nombre, introduzca
GlueDataQualityStudio. - Rol de IAM, elige el rol que comienza con
GlueDataQualityStudio-*. - Versión con pegamento, escoger Pegamento 3.0.
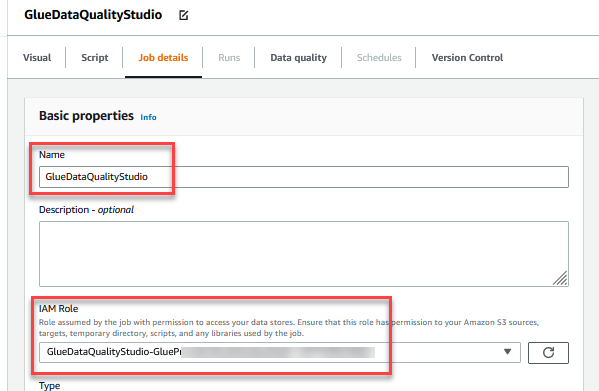
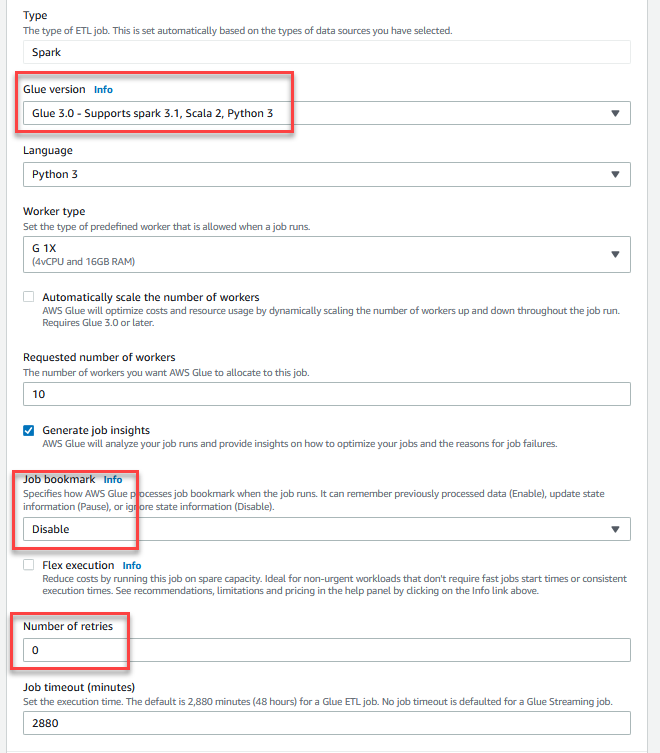
- Marcador de trabajo, escoger Deshabilitar. Esto le permite ejecutar este trabajo varias veces con el mismo conjunto de datos de entrada.
- Número de reintentos, introduzca
0.
- En Propiedades avanzadas sección, proporcione el depósito S3 creado por la plantilla de CloudFormation (comenzando con
gluedataqualitystudio-*).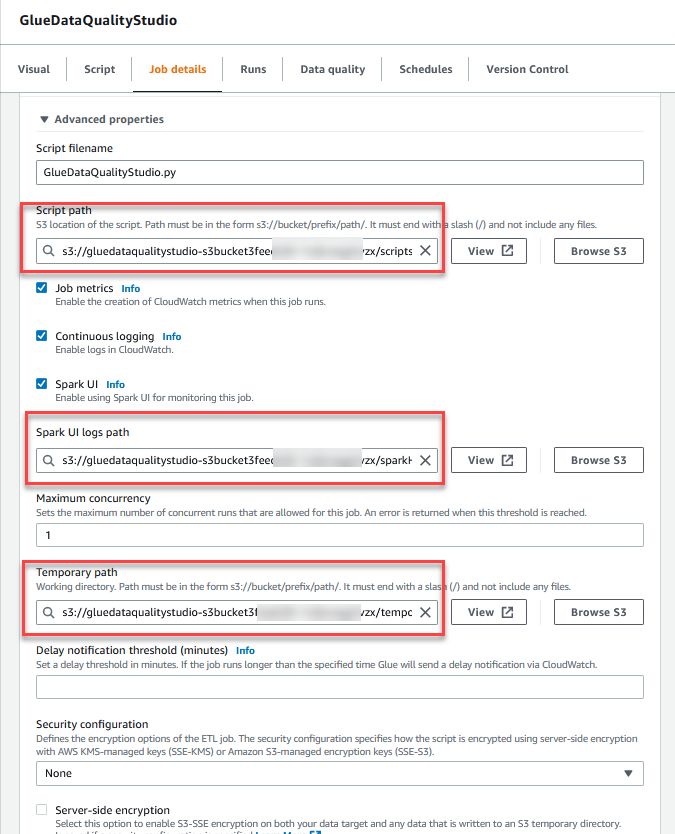
- Elige Guardar.
- Después de guardar el trabajo, elija el Visual pestaña y en la Fuente menú, seleccione Amazon S3.
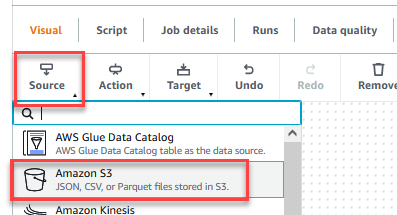
- En Propiedades de la fuente de datos: S3 pestaña, para Tipo de fuente S3, seleccione Ubicación S3.
- Elige Examinar S3 y navegue hasta el prefijo
/datalake/raw/customer/en el cubo S3 comenzando congluedataqualitystudio-*. - Elige Inferir esquema.
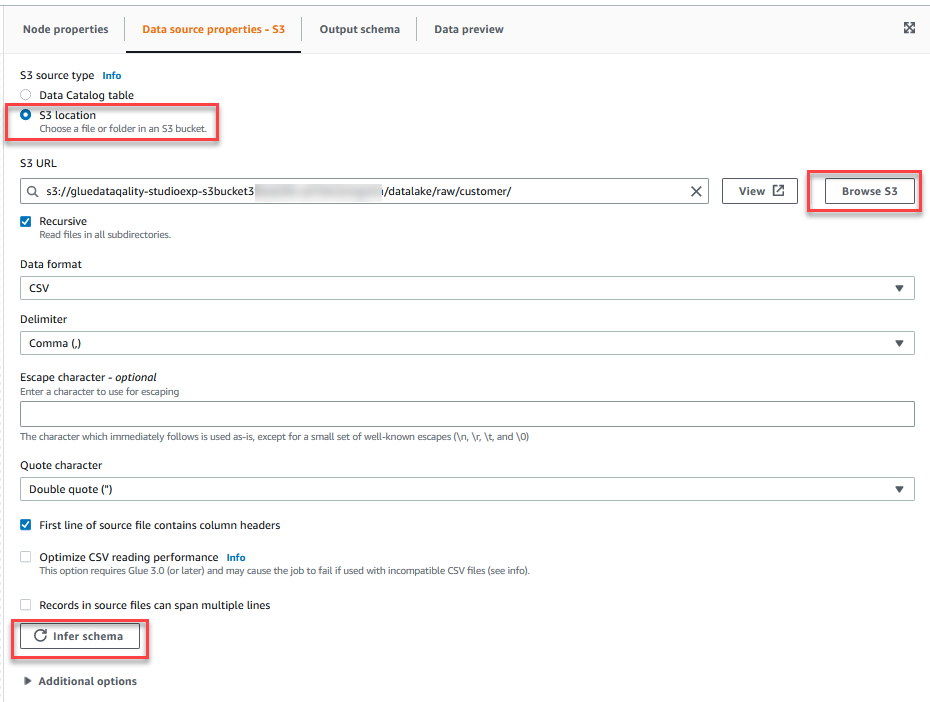
- En la columna Acción menú, seleccione Evaluar la calidad de los datos.
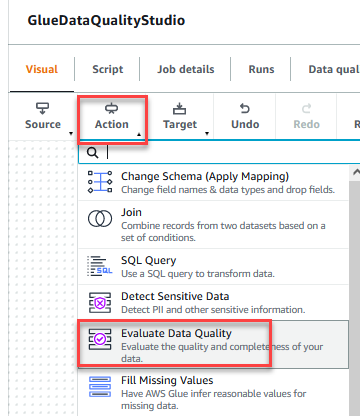
- Elija el Evaluar la calidad de los datos nodo.
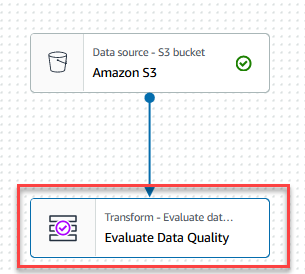
En Transformar pestaña, ahora puede comenzar a crear reglas de calidad de datos. La primera regla que creas es comprobar siCustomer_IDes único y no nulo usando elisPrimaryKeyregla. - En Tipos de reglas pestaña del Generador de reglas DQDL, buscar
isprimarykeyy elija el signo más.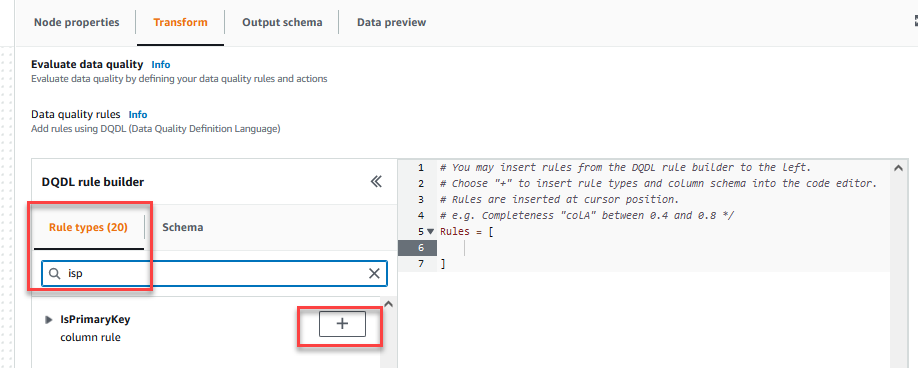
- En Esquema pestaña del Generador de reglas DQDL, elija el signo más junto a
Customer_ID. - En el editor de reglas, elimine
id.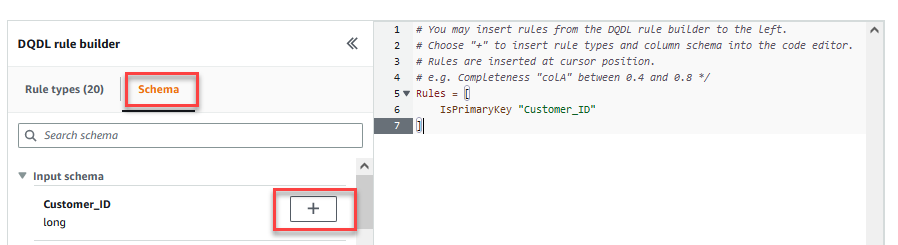
La siguiente regla que añadimos comprueba que elFirst_Nameel valor de la columna está presente para todas las filas. - También puede ingresar las reglas de calidad de datos directamente en el editor de reglas. Agregue una coma (,) e ingrese
IsComplete "First_Name",después de la primera regla.
A continuación, agrega una regla personalizada para validar que no existe ninguna fila sinTelephoneorEmail. - Introduzca la siguiente regla personalizada en el editor de reglas:

La función Evaluar la calidad de los datos proporciona acciones para administrar el resultado de un trabajo en función de los resultados de la calidad del trabajo. - Para esta publicación, seleccione Trabajo fallido cuando la calidad de los datos falla y elige Trabajo fallido sin destino de carga datos comportamiento. En el Configuración de salida de calidad de datos sección, elija Examinar S3 y navegue hasta el prefijo
dqresultsen el cubo S3 comenzando congluedataqualitystudio-*.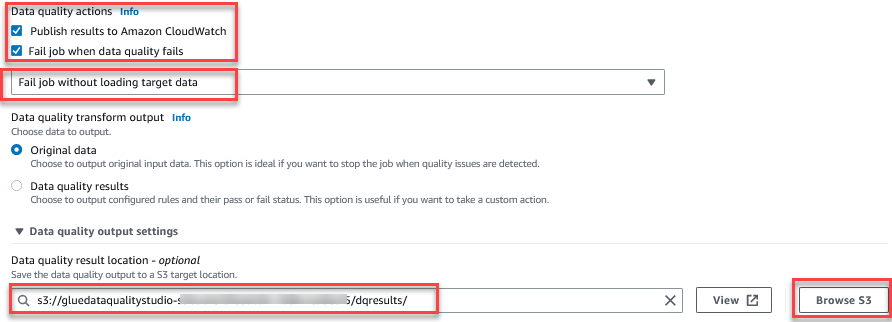
- En Target menú, seleccione Amazon S3.
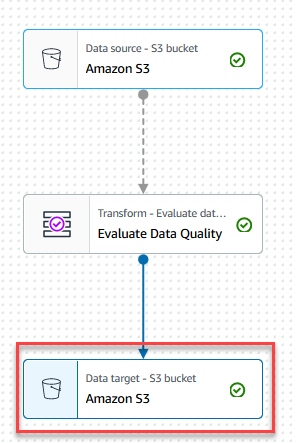
- Elija el Objetivo de datos: depósito de S3 nodo.
- En Propiedades de destino de datos - S3 pestaña, para Formato, escoger parquet, Y para Tipo de compresión, escoger Rápido.
- Ubicación de destino S3, escoger Examinar S3 y navegue hasta el prefijo
/datalake/curated/customer/en el cubo S3 comenzando congluedataqualitystudio-*.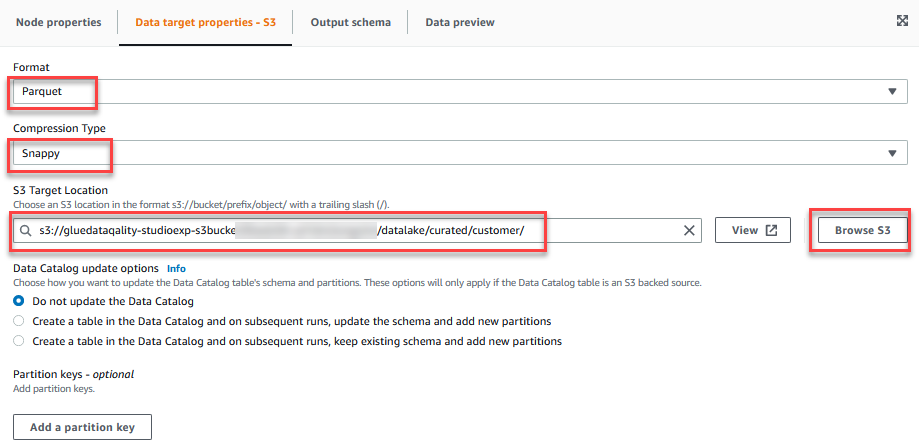
- Elige Guardar, A continuación, elija Ejecutar.
 Puede ver los detalles de la ejecución del trabajo en la pestaña Ejecuciones. En nuestro ejemplo, el trabajo falla con el mensaje de error "AssertionError: El trabajo falló debido a reglas DQ fallidas para el nodo: .”
Puede ver los detalles de la ejecución del trabajo en la pestaña Ejecuciones. En nuestro ejemplo, el trabajo falla con el mensaje de error "AssertionError: El trabajo falló debido a reglas DQ fallidas para el nodo: .”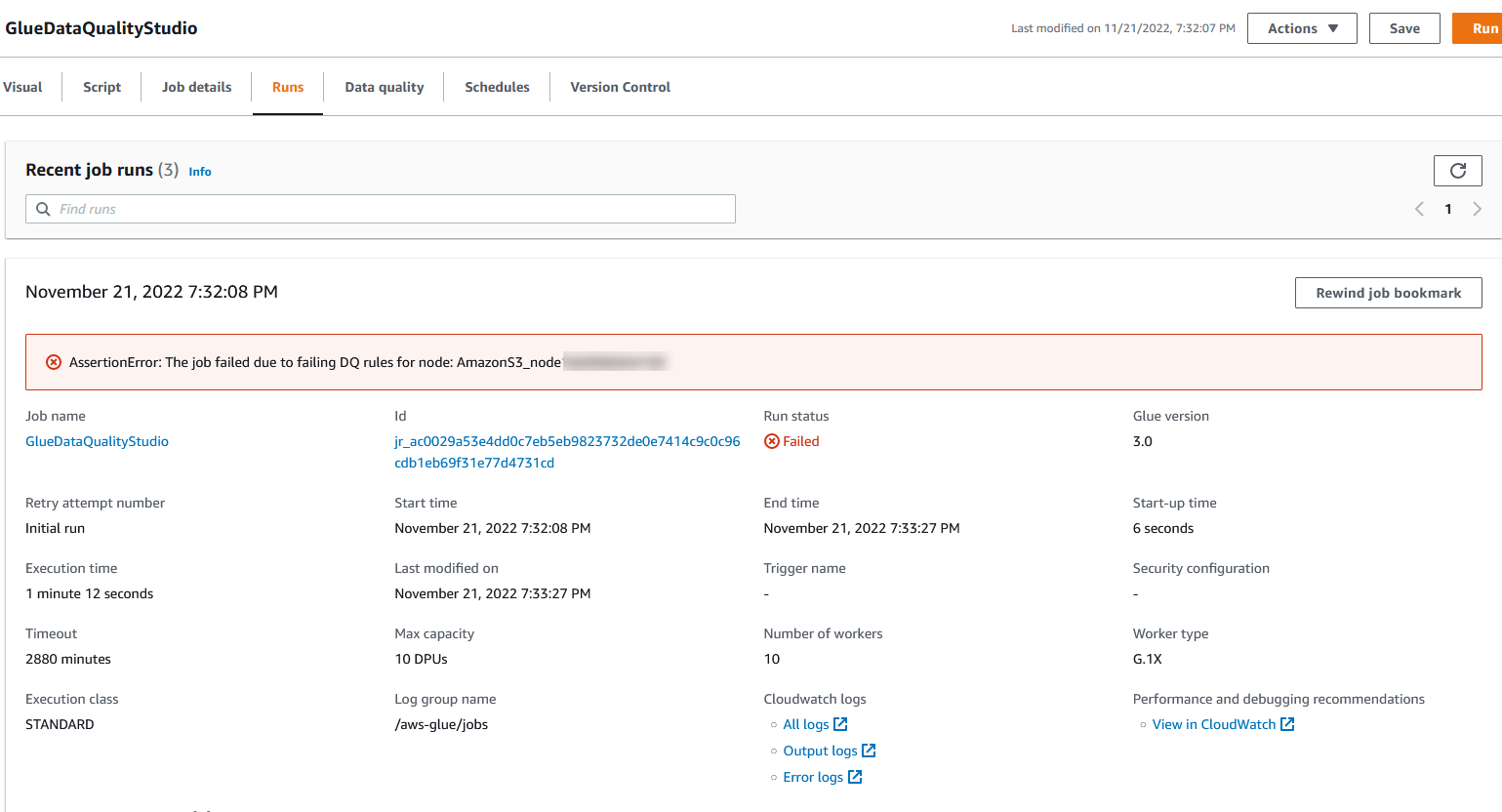 Puede revisar el resultado de la calidad de los datos en la pestaña Calidad de los datos. En nuestro ejemplo, la validación de la calidad de los datos personalizados falló porque una de las filas del conjunto de datos no tenía
Puede revisar el resultado de la calidad de los datos en la pestaña Calidad de los datos. En nuestro ejemplo, la validación de la calidad de los datos personalizados falló porque una de las filas del conjunto de datos no tenía TelephoneorEmail. Los resultados de Evaluate Data Quality también se escriben en el depósito de S3 en formato JSON en función del parámetro de ubicación de resultados de calidad de datos del nodo.
Los resultados de Evaluate Data Quality también se escriben en el depósito de S3 en formato JSON en función del parámetro de ubicación de resultados de calidad de datos del nodo. - Navegue hasta
dqresultsprefijo bajo el comienzo del depósito S3gluedataqualitystudio-*. Verá que el resultado de la calidad de los datos se divide por fecha.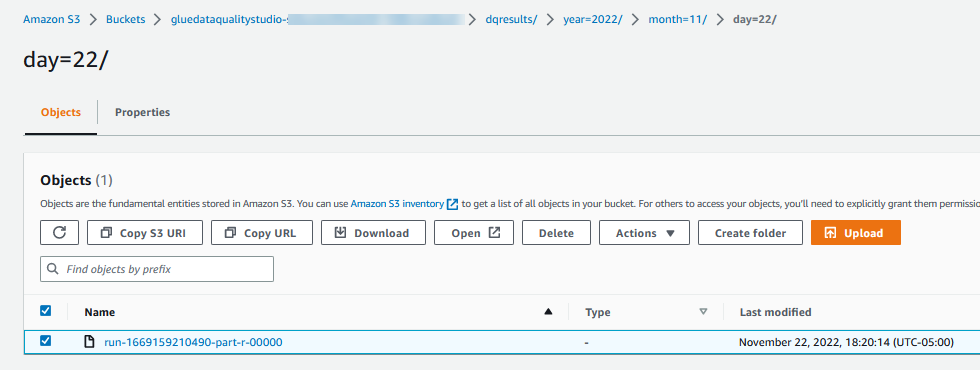
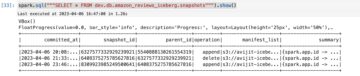
El siguiente es el resultado del archivo JSON. Puede usar esta salida de archivo para crear paneles de visualización de calidad de datos personalizados.

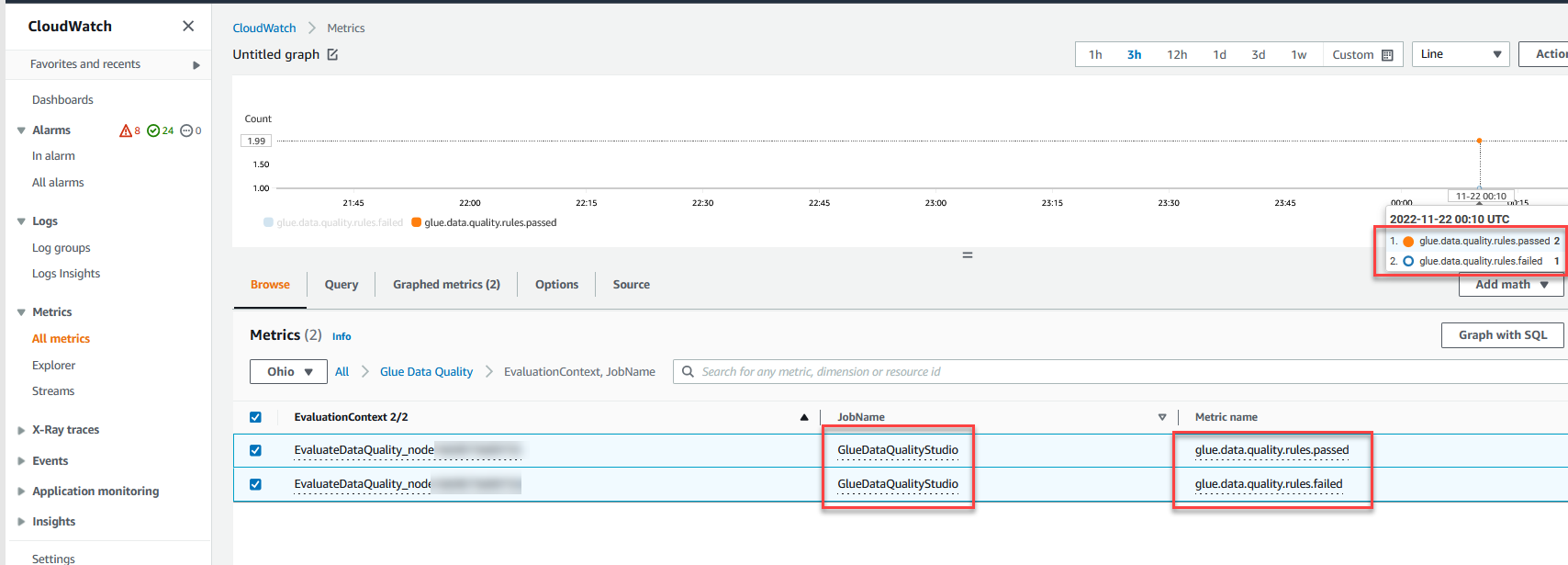
También puede monitorear el Evaluar la calidad de los datos nodo a través Reloj en la nube de Amazon métricas y configurar alarmas para enviar notificaciones sobre los resultados de calidad de los datos. Para obtener más información sobre cómo configurar las alarmas de CloudWatch, consulte Uso de alarmas de Amazon CloudWatch.
Limpiar
Para evitar incurrir en cargos futuros y limpiar roles y políticas no utilizados, elimine los recursos que creó:
- Eliminar el
GlueDataQualityStudiotrabajo que creaste como parte de esta publicación. - En la consola de AWS CloudFormation, elimine el
GlueDataQualityStudioasociación.
Conclusión
AWS Glue Data Quality ofrece una manera fácil de medir y monitorear la calidad de los datos de su canalización de ETL. En esta publicación, aprendió cómo tomar las medidas necesarias en función de los resultados de la calidad de los datos, lo que lo ayuda a mantener altos estándares de datos y tomar decisiones comerciales seguras.
Para obtener más información sobre AWS Glue Data Quality, consulte la documentación:
Acerca de los autores
 Deen Bandhu Prasad es especialista sénior en análisis en AWS y se especializa en servicios de big data. Le apasiona ayudar a los clientes a crear una arquitectura de datos moderna en la nube de AWS. Ha ayudado a clientes de todos los tamaños a implementar soluciones de administración de datos, almacenamiento de datos y lago de datos.
Deen Bandhu Prasad es especialista sénior en análisis en AWS y se especializa en servicios de big data. Le apasiona ayudar a los clientes a crear una arquitectura de datos moderna en la nube de AWS. Ha ayudado a clientes de todos los tamaños a implementar soluciones de administración de datos, almacenamiento de datos y lago de datos.
 Yannis Mentekidis es ingeniero sénior de desarrollo de software en el equipo de AWS Glue.
Yannis Mentekidis es ingeniero sénior de desarrollo de software en el equipo de AWS Glue.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/getting-started-with-aws-glue-data-quality-for-etl-pipelines/
- 1
- 100
- 7
- a
- Sobre
- de la máquina
- Mi Cuenta
- preciso
- reconocer
- la columna Acción
- acciones
- Después
- Todos
- permite
- ya haya utilizado
- Amazon
- Analytics
- y
- arquitectura
- AWS
- Formación en la nube de AWS
- Pegamento AWS
- Malo
- datos malos
- basado
- porque
- antes
- Big
- Big Data
- build
- Construir la
- case
- cargos
- comprobar
- Cheques
- Elige
- Soluciones
- Columna
- Algunos
- completar
- seguros
- Considerar
- Consola
- Clientes
- Corrupción
- Para crear
- creado
- creación
- comisariada
- personalizado
- cliente
- Clientes
- personalizan
- datos
- Lago de datos
- datos de gestión
- Fecha
- decisiones
- detalles
- Desarrollo
- directamente
- documentación
- pasan fácilmente
- editor
- ingeniero
- certificados
- Participar
- error
- Éter (ETH)
- evaluar
- ejemplo
- existe
- experience
- Explicar
- extraerlos
- Fallidos
- falla
- Feature
- Archive
- Nombre
- siguiendo
- formato
- en
- funciones
- futuras
- generado
- genera
- conseguir
- ayudado
- ayudando
- ayuda
- Alta
- alta calidad
- Cómo
- Como Hacer
- Sin embargo
- HTML
- HTTPS
- Cientos
- identificar
- Identidad
- implementar
- in
- incluye
- Las opciones de entrada
- cuestiones
- IT
- Trabajos
- Empleo
- json
- Clave
- lago
- APRENDE:
- aprendido
- aprendizaje
- carga
- carga
- Ubicación
- perder
- máquina
- máquina de aprendizaje
- mantener
- para lograr
- gestionan
- Management
- administrar
- manual
- medir
- medidas
- Menú
- mensaje
- Métrica
- podría
- Moderno
- Monitorear
- monitores
- más,
- múltiples
- Navegar
- Navegación
- necesario
- Next
- nodo
- notificaciones
- objetos
- Ofertas
- ONE
- habiertos
- de otra manera
- cristal
- parámetro
- parte
- apasionado
- permiso
- industrial
- colocación
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- más
- políticas
- Publicación
- Preparar
- presente
- evitar
- Vista previa
- anterior
- primario
- en costes
- propiedades
- proporcionar
- proporciona un
- calidad
- Búsqueda
- Crudo
- Leer
- reciente
- región
- exigir
- Requisitos
- Recursos
- resultado
- Resultados
- una estrategia SEO para aparecer en las búsquedas de Google.
- Función
- También soy miembro del cuerpo docente de World Extreme Medicine (WEM) y embajadora europea de igualdad para The Transformational Travel Council (TTC). En mi tiempo libre, soy una incansable aventurera, escaladora, patrona de día, buceadora y defensora de la igualdad de género en el deporte y la aventura. En XNUMX, fundé Almas Libres, una ONG nacida para involucrar, educar y empoderar a mujeres y niñas a través del deporte urbano, la cultura y la tecnología.
- FILA
- Regla
- reglas
- Ejecutar
- mismo
- Buscar
- Sección
- Serie
- de coches
- Servicios
- set
- pólipo
- Configure
- Mostrar
- Shows
- firmar
- sencillos
- tamaños
- So
- Software
- Desarrollo de software ad-hoc
- a medida
- Soluciones
- Fuente
- especialista
- especializada
- montón
- estándares de salud
- comienzo
- fundó
- Comience a
- paso
- pasos
- STORAGE
- estudio
- siguiente
- sintéticamente
- ¡Prepárate!
- Target
- Tarea
- equipo
- plantilla
- El
- miles
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- veces
- a
- hoy
- Transformar
- transformadora
- Confía en
- bajo
- subyacente
- único
- no usado
- utilizan el
- caso de uso
- usuarios
- generalmente
- VALIDAR
- validación
- propuesta de
- diversos
- Ver
- visualización
- esperar
- sean
- que
- seguirá
- sin
- funciona
- escribir
- la escritura
- escrito
- tú
- zephyrnet