En este artículo, encontrará varios métodos para convertir PDF a Hojas de cálculo de Google.
También aprenderá cómo Nanonets puede automatice todo el flujo de trabajo de conversión de PDF a Hojas de cálculo de Google en línea.
Antes de ver cómo convertir PDF a Hojas de cálculo de Google, echemos un vistazo a por qué es importante hacer esto.
¿Por qué convertir archivos PDF a hojas de cálculo de Google?
De acuerdo con esta Google Blog publicación de la página oficial del blog de Google, más de 5 millones de empresas están utilizando su solución G Suite. Al mismo tiempo, una gran cantidad de empresas también han comenzado a utilizar integraciones de Google Sheets para automatizar tareas.
Consideremos un caso de uso típico. Su equipo de Cuentas por pagar recibe una factura en formato PDF estándar. Alguien revisa manualmente la factura y escribe la información requerida en un documento de Hojas de cálculo de Google antes de reenviarlo a la sección Finanzas. La sección Finanzas paga a su proveedor y realiza una entrada en el libro mayor de la empresa.
Además de ser un proceso prolongado, es propenso a errores y tendría mucho más sentido simplemente automatizarlo.
Ahora que la necesidad de convertir archivos PDF a un formulario de hoja de Google es clara, echemos un vistazo a cómo se estructuran los documentos PDF y cuáles son los desafíos para analizarlos.
Quiere convertir (PDF) a archivos Google Sheets ? Revisa Nanorred gratuita, Conversor de PDF a CSV. O descubre cómo automatice todo su flujo de trabajo de PDF a Hojas de cálculo de Google con Nanonets.
Desafíos al analizar un documento PDF
El formato de documento portátil era un formato de archivo desarrollado inicialmente por Adobe y luego lanzado como estándar abierto. Desde entonces, ha sido ampliamente adoptado ya que es independiente del sistema operativo subyacente.
Entonces, ¿por qué es tan difícil analizar un PDF y convertir su contenido a otro formato? Las siguientes imágenes hablan más que mil palabras y llevarán el punto a casa.
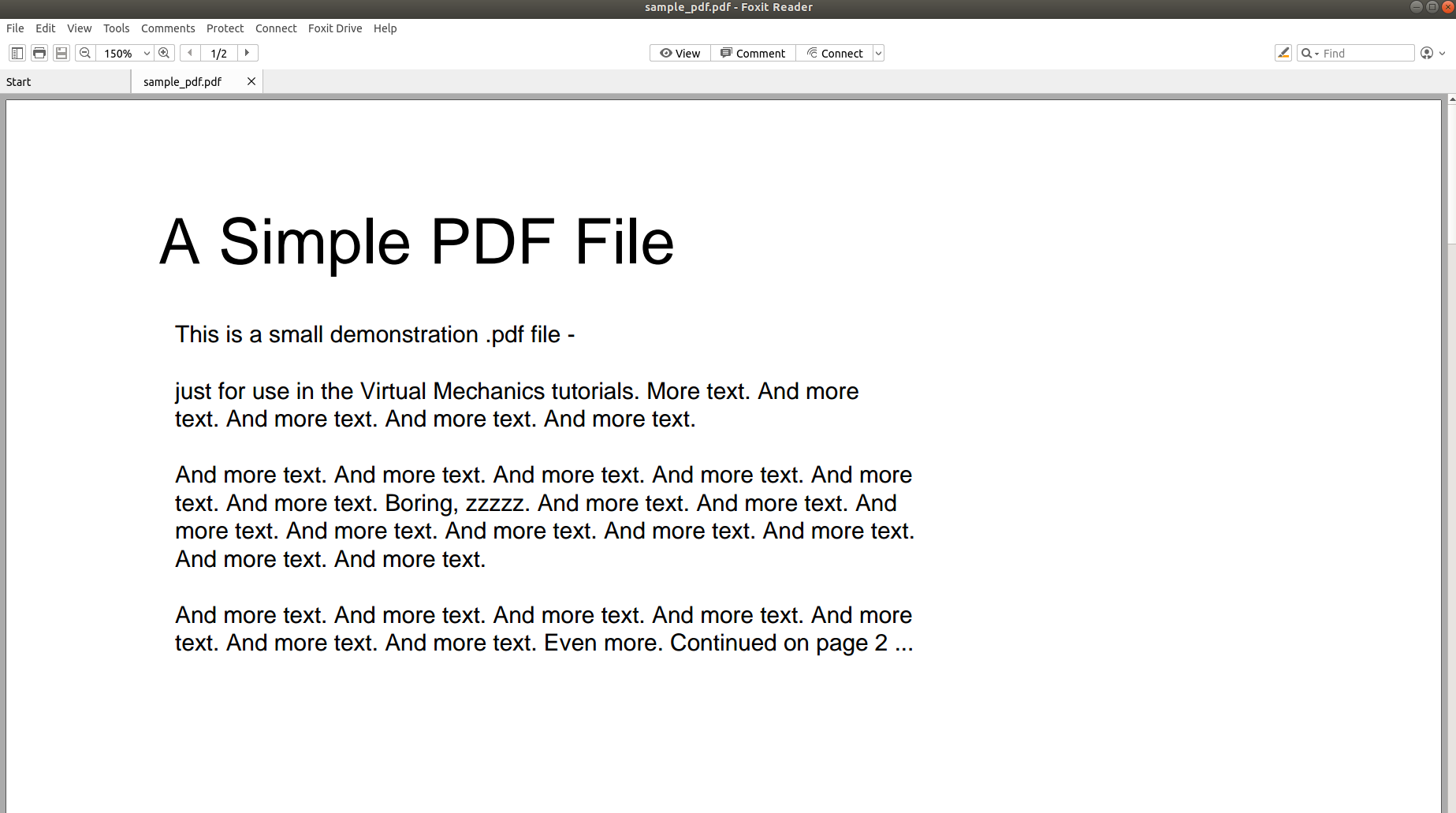
La imagen de arriba muestra la captura de pantalla de un documento PDF que se abre con un lector de PDF. Intentemos abrir el mismo documento PDF con un editor de texto.
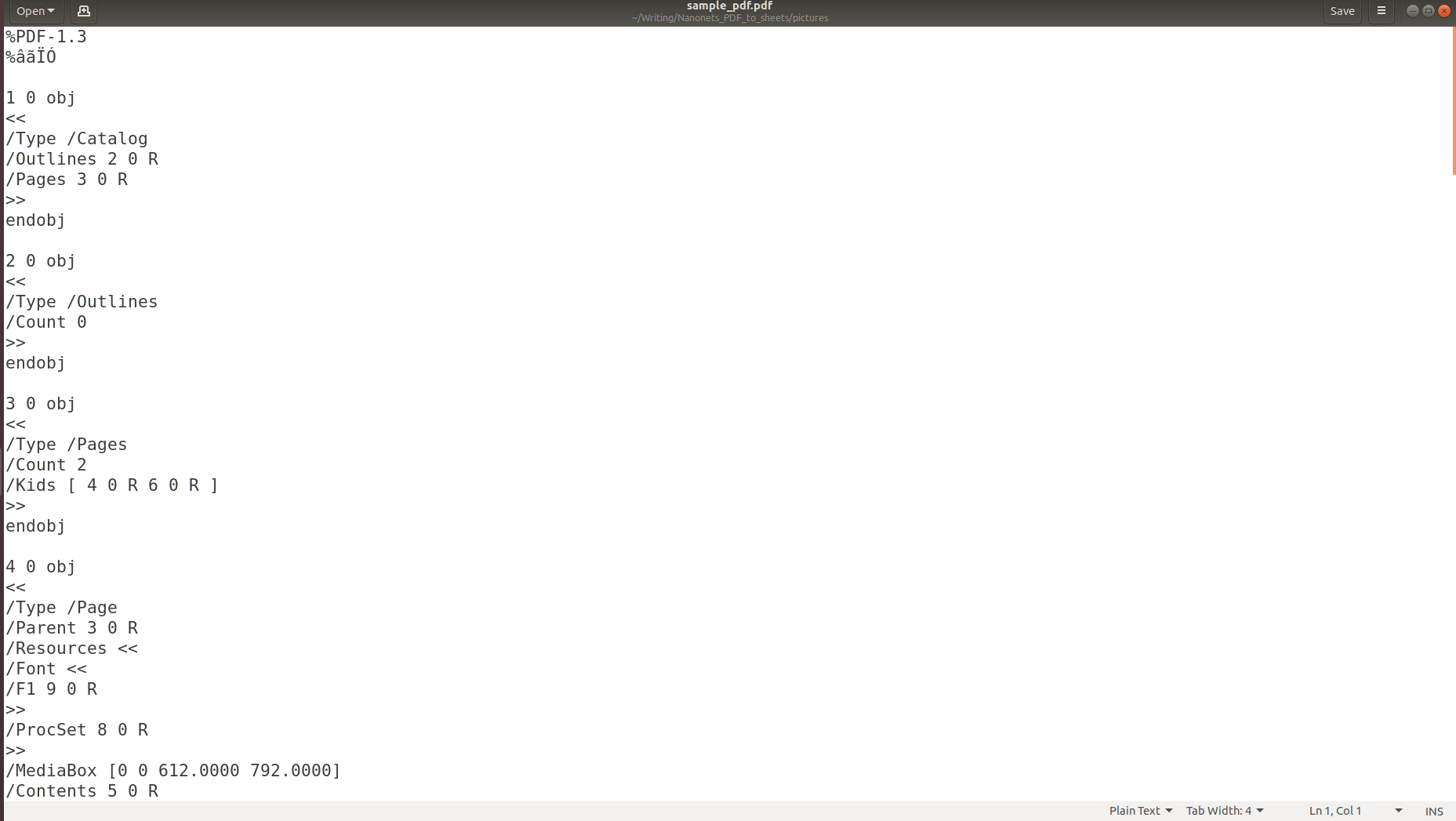
Las imágenes de arriba dejan en claro que cuando la información se almacena en un PDF, su estructura original se pierde por completo. Esto se debe a que el formato PDF simplemente consta de instrucciones sobre cómo imprimir / dibujar una secuencia de caracteres en una página.
Si cree que la extracción de texto es difícil, la extracción de los datos presentes en las tablas es aún más desafiante debido a la gran variedad de formatos tabulares que se utilizan.
Con suerte, está convencido de que convertir un documento PDF en un formulario de Hojas de cálculo de Google no es un paseo por el parque. La siguiente sección habla sobre el enfoque adoptado por la mayoría de los analizadores de PDF modernos para reconocer / analizar información de un documento PDF.
El enfoque moderno para analizar documentos PDF
La mayoría de los analizadores de PDF modernos utilizan el flujo que se describe a continuación para analizar datos no estructurados de documentos PDF.
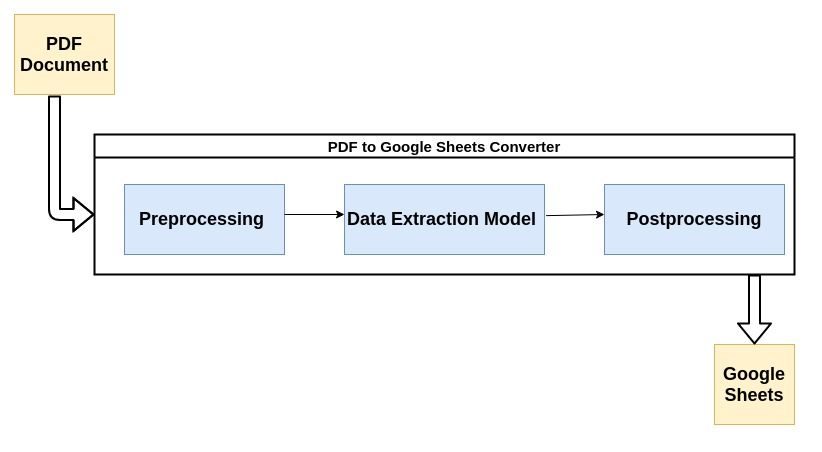
Echemos un vistazo breve a cada paso del proceso:
1. Preprocesamiento o limpieza de datos:
Cuanto mejor se vea su PDF, más fácil será para su modelo de Machine Learning extraer o captura de datos de eso. Por ejemplo, si el documento PDF ha sido escaneado, es probable que contenga algunos artefactos de escaneo que podrían afectar el rendimiento del convertidor.
La eliminación de ruido mediante el uso de filtros adecuados, binarización, corrección de sesgo, etc. son algunos de los pasos de preprocesamiento más comunes. La siguiente publicación de Nanonets Poste Tesseract de nanorred contiene algunos excelentes ejemplos de cómo se pueden preprocesar los documentos antes Reconocimiento óptico de caracteres(OCR) se ejecuta en ellos.
Aquí es donde ocurre la mayor parte de la magia. La extracción de datos generalmente se lleva a cabo mediante un modelo de aprendizaje automático (ML). La mayoría de los modelos ML utilizados para la extracción de datos de archivos PDF contienen una combinación de herramientas de reconocimiento óptico de caracteres, herramientas de reconocimiento de texto y patrones, etc.
Para el propósito de esta publicación, podemos tratar el modelo como una caja negra que toma su documento PDF como entrada y escupe la información analizada. Además, dado que emplea ML en su núcleo, se puede volver a capacitar con datos personalizados para adaptarse al caso de uso de su empresa.
3. Posprocesamiento:
En este paso, los datos extraídos se convierten al formato requerido, como CSV, XML, JSON, etc. Además, se agregan reglas adicionales definidas por el usuario además de las predicciones realizadas por AI. Esto podría incluir reglas para formatear la salida, restricciones adicionales sobre la información que se extrae, etc.
La siguiente sección analiza algunas métricas que podríamos utilizar para medir el rendimiento de un analizador de PDF.
Quiere convertir (PDF) a archivos Google Sheets ? Revisa Nanorred gratuita, Conversor de PDF a CSV. Descubra cómo automatizar todo su flujo de trabajo de PDF a Hojas de cálculo de Google con Nanonets.

Métricas para medir el rendimiento de un convertidor de PDF
Dado que la mayoría de los convertidores de PDF se utilizarán para el procesamiento de facturas o tareas relacionadas, la precisión y velocidad de la extracción de tablas de un documento PDF es un factor crítico para juzgar el rendimiento del convertidor de PDF.
2. Capacidad multilingüe:
La mayoría de las grandes empresas están obligadas a recibir facturas en varios idiomas diferentes. El analizador de PDF debe admitir el análisis multilingüe listo para usar o debe proporcionar una opción mediante la cual los usuarios puedan entrenar el modelo utilizando datos personalizados.
3. Integración con software de contabilidad:
El conversor de PDF ideal debe ser un módulo plug and play que pueda agregarse fácilmente a su flujo de trabajo del documento. Debería admitir la integración con software de contabilidad popular como QuickBooks, Xero, Wave, etc.
4. Fácil e intuitivo:
Lo más probable es que la herramienta sea operada por usuarios no técnicos. Sería ventajoso si se pudiera operar con un mínimo de conocimientos técnicos.
Varios métodos para convertir archivos PDF a hojas de cálculo de Google
1. Uso de Documentos de Google para convertir PDF a Hojas de cálculo de Google
Google Drive tiene una capacidad incorporada para reconocer tablas y texto dentro de documentos PDF simples. Simplemente necesitas:
-
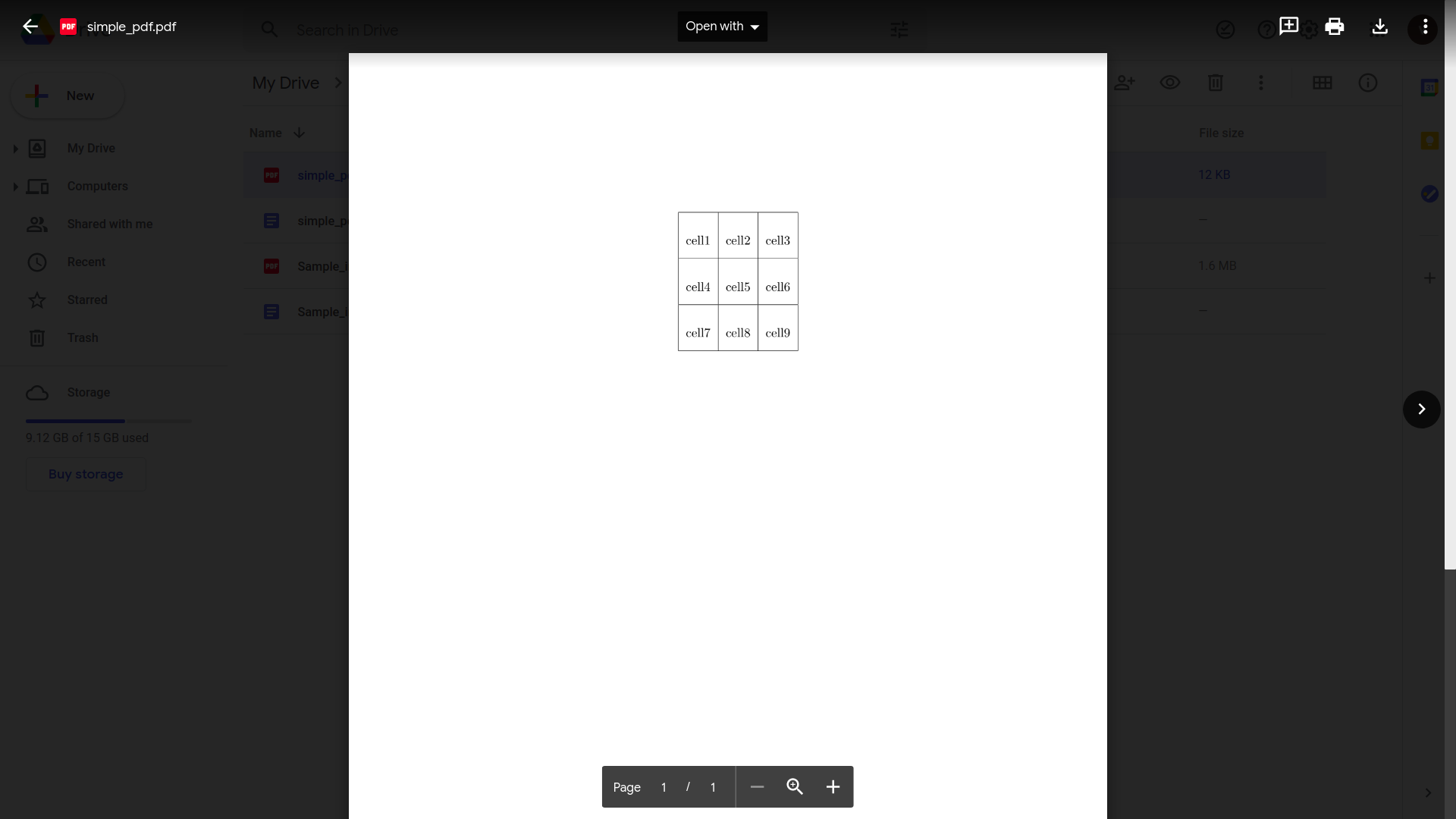
Sube tu archivo PDF a Google Drive
-
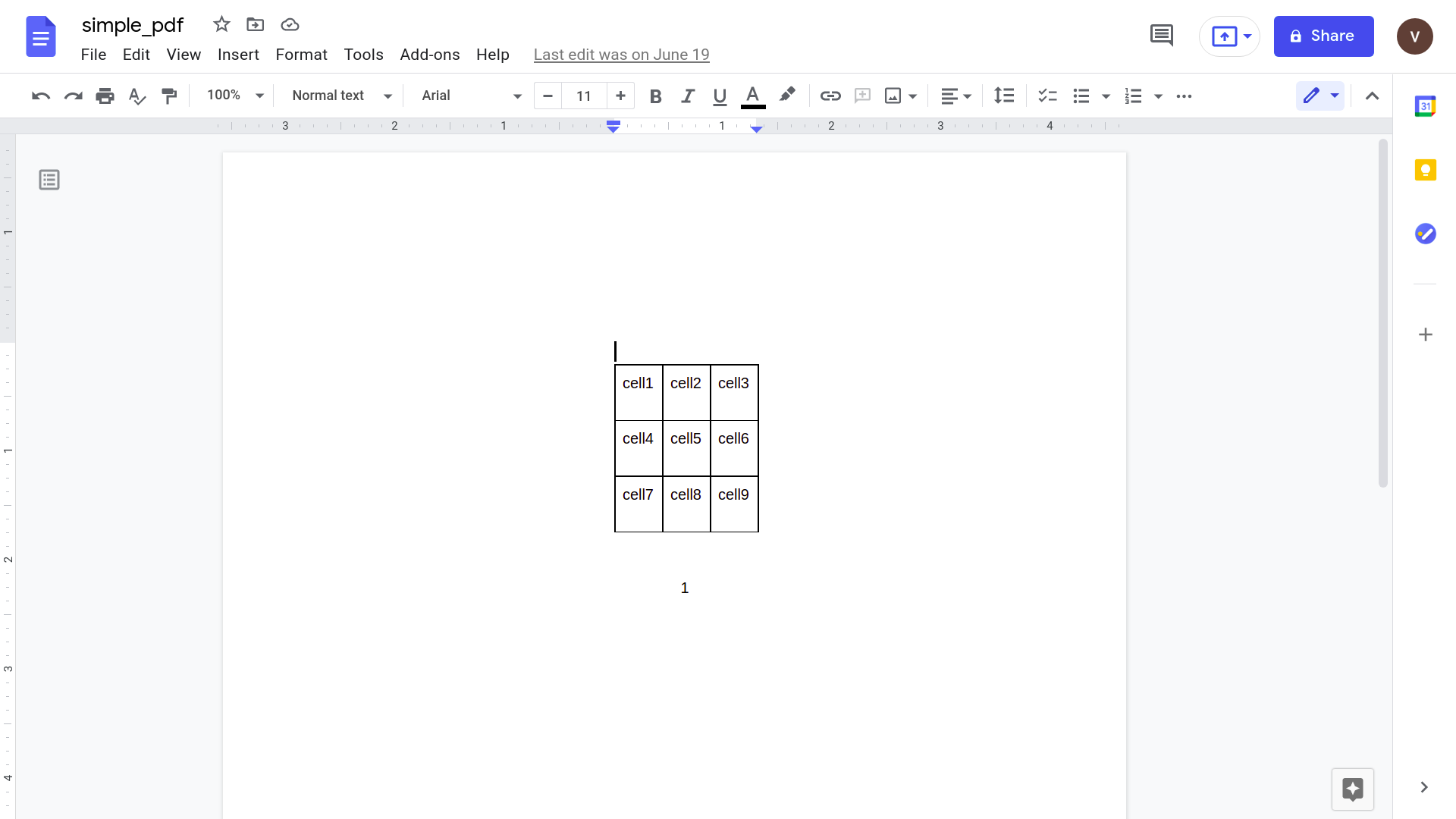
Haga clic en "Abrir con Google Docs"
-
Copie los datos que desee y péguelos en Hojas de cálculo de Google
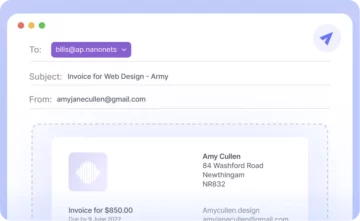
Aunque eso parece funcionar bien, intentemos algo un poco más práctico. Considere esta simple factura.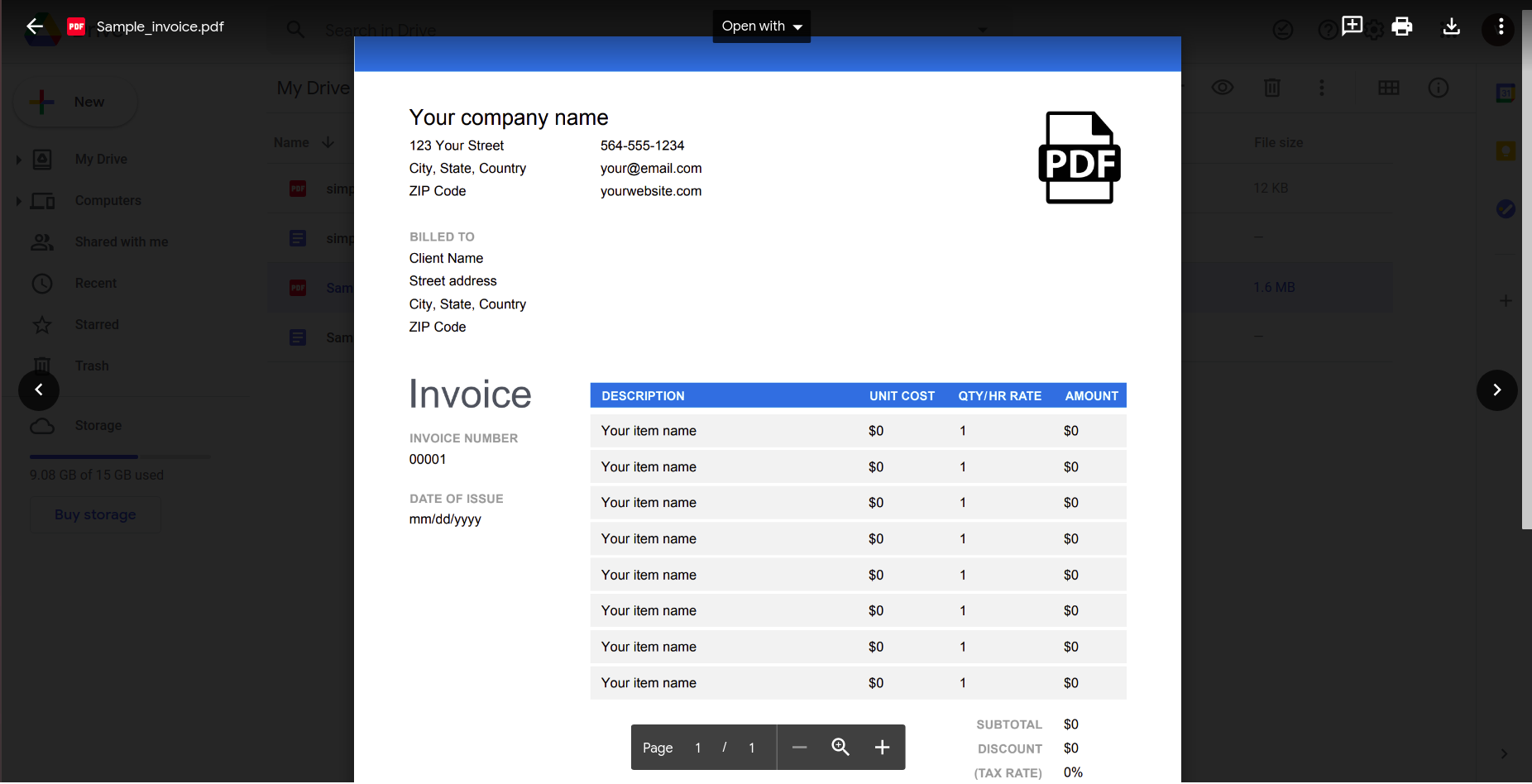
Abrir esto usando la aplicación Google docs da el siguiente resultado.
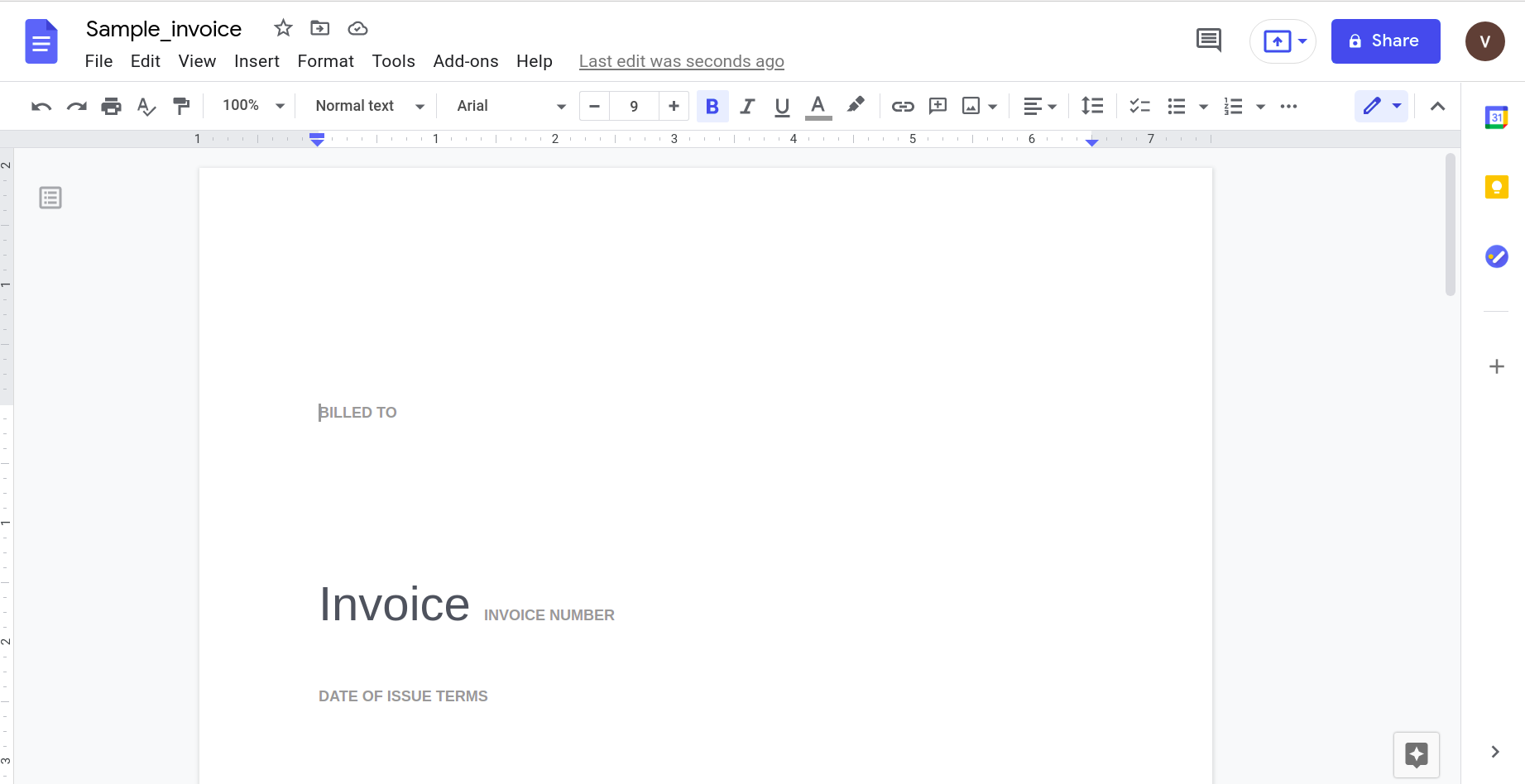
Claramente, a medida que aumenta la complejidad del documento, debemos confiar en herramientas más sofisticadas para reconocer datos.
2. Uso de herramientas en línea:
Varias herramientas en línea, como el extractor de tablas PDF, Online2PDF, etc., se integran directamente con Google Drive y brindan la capacidad lista para usar para convertir documentos PDF a Hojas de cálculo de Google.
Sin embargo, cuando estas herramientas se probaron con el PDF de factura de muestra que se muestra arriba, las tablas no se detectaron en la mayoría de los casos.
Quiere convertir (PDF) a archivos Google Sheets ? Revisa Nanorred gratuita, Conversor de PDF a CSV. Descubra cómo automatizar todo su flujo de trabajo de PDF a Hojas de cálculo de Google con Nanonets, como se muestra a continuación.
Automatización del proceso de conversión de PDF a Hojas de cálculo de Google
Podemos automatizar completamente el proceso de analizar el PDF y extraer los datos en un formulario de Hojas de cálculo de Google utilizando las siguientes herramientas.
1. Uso de webhooks:
Los webhooks son solicitudes HTTP definidas de forma personalizada. Por lo general, se activan en un evento, es decir, cuando ocurre un evento, la aplicación envía información a una URL predefinida.
¿Cómo puede utilizar esto para automatizar su flujo de trabajo? Consideremos el caso de uso típico del procesamiento de facturas. Recibe una serie de facturas de sus proveedores y las introduce en su convertidor de PDF a Google Sheets que reside en la nube. ¿Cómo saber cuando el modelo ha terminado de procesar los documentos?
En lugar de verificar manualmente si se completó la conversión, simplemente puede usar un webhook que le notifica cuando los datos en el PDF se han extraído a un documento de Google Sheets.
2. Uso de API
API significa Interfaz de programación de aplicaciones. Con las llamadas a la API adecuadas, la conversión de documentos PDF a Hojas de cálculo de Google puede resultar tan fácil como escribir las siguientes líneas de código:
#Feed the PDF documents into the PDF to Google sheets converter
Success_code, unique_id = NanonetsAPI.uploaddata(PDF_documents)
Si su empresa ya ha configurado la integración con Webhooks, recibirá una notificación cuando sus documentos PDF se hayan convertido correctamente. Luego puede descargar el formulario de Hojas de cálculo de Google utilizando la API que se muestra a continuación.
#Download Google Sheets forms
Google_sheets_data = NanonetsAPI.downloaddata(unqiue_id)
PDF a Hojas de cálculo de Google con Nanonets
El analizador de PDF de Nanonets hace que el análisis y la conversión sean fáciles y precisos. El analizador de PDF se utilizó para analizar una factura de muestra. Esta sección demuestra la facilidad de uso y la precisión de la herramienta. En lugar de hablar de lo grandioso que es, las siguientes imágenes ilustran adecuadamente el punto.
La imagen que se muestra a continuación es una captura de pantalla de la factura de muestra que se envió al analizador de PDF de Nanonets.
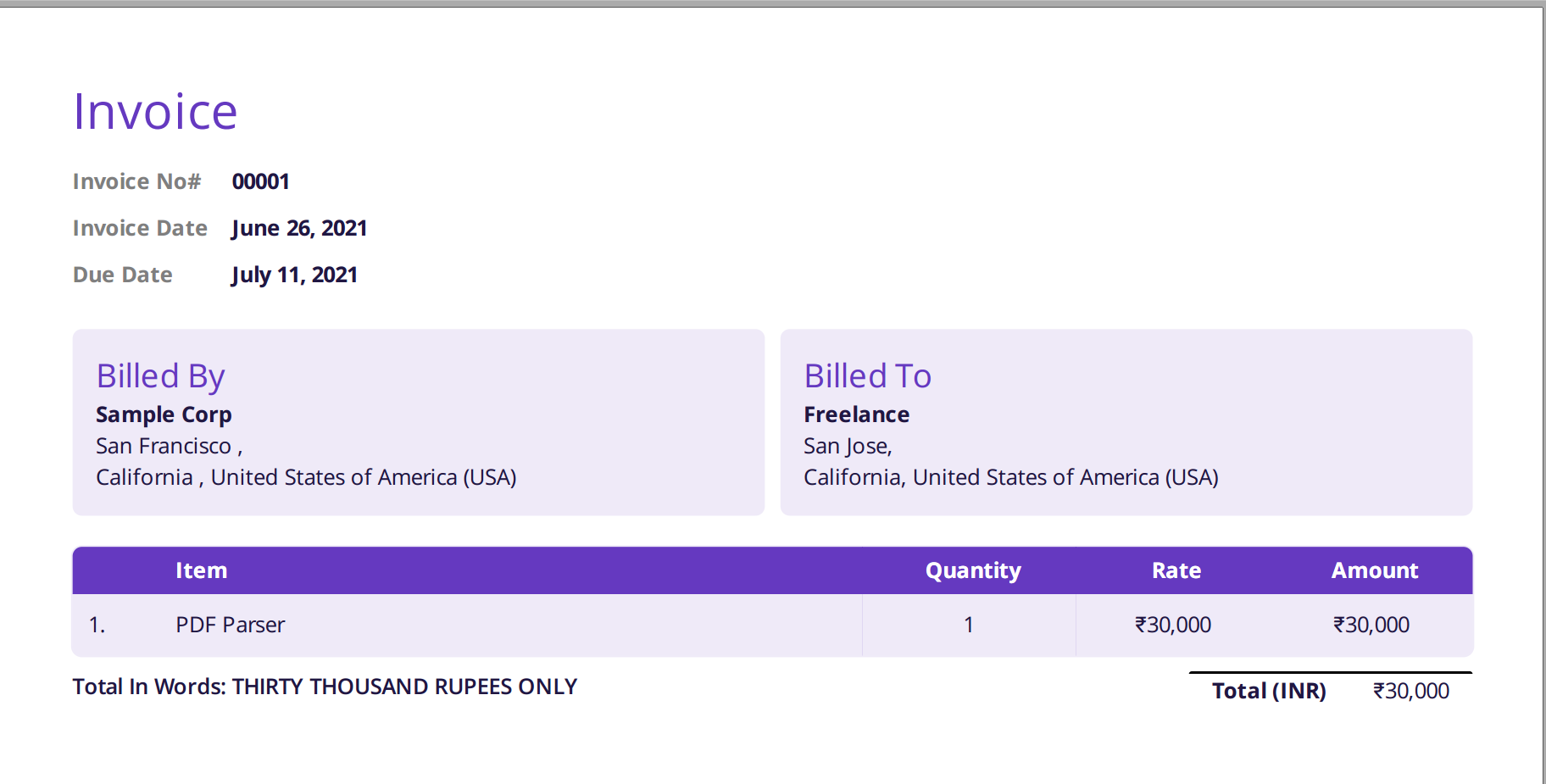
Simplemente navegue al sitio web de Nanonets y cargue la factura. La conversión tarda solo unos segundos, después de lo cual los datos analizados se pueden descargar en una variedad de formatos, como CSV, XLSX, etc. (ver Nanonets' Conversor de PDF a CSV)
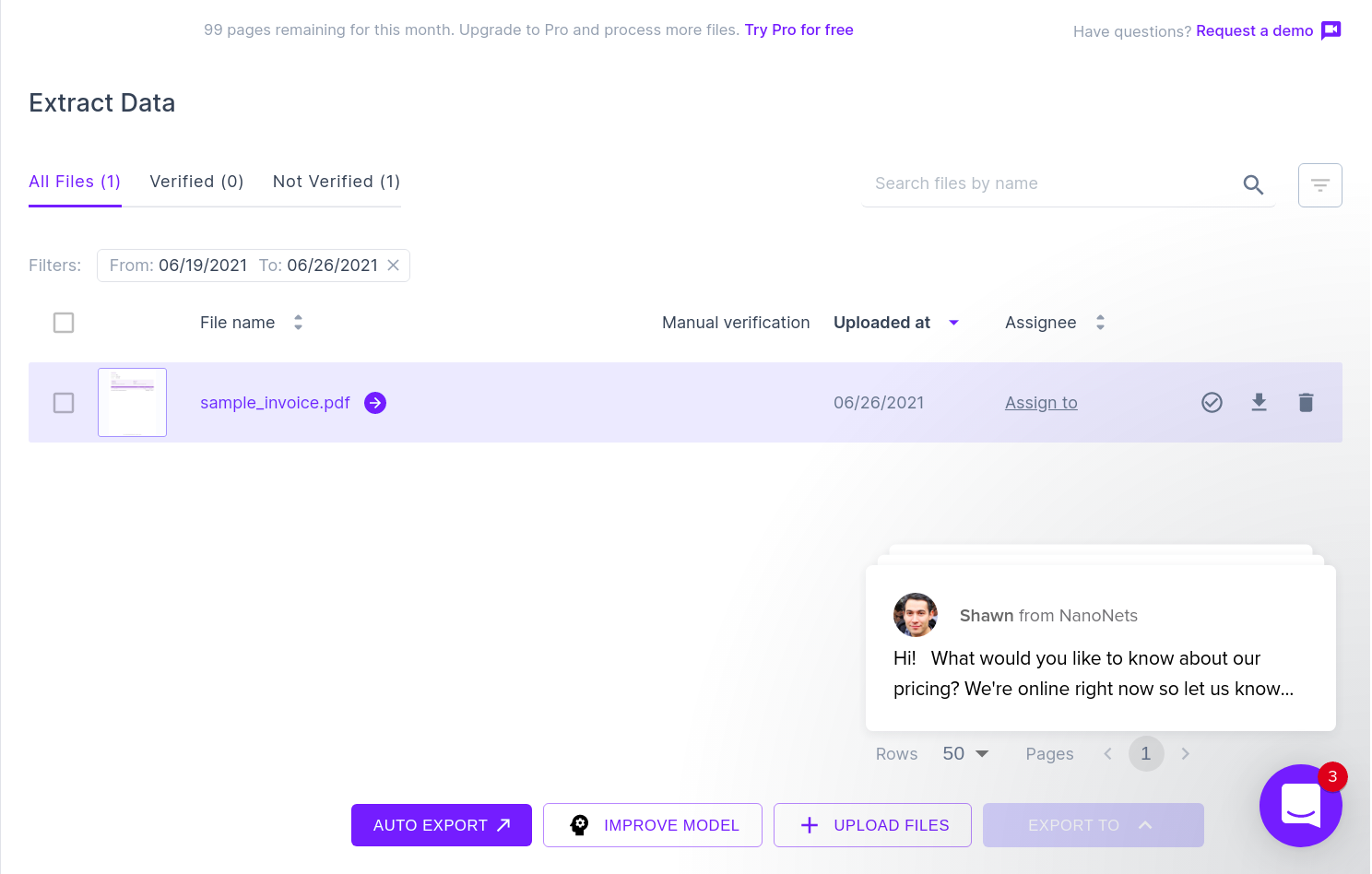
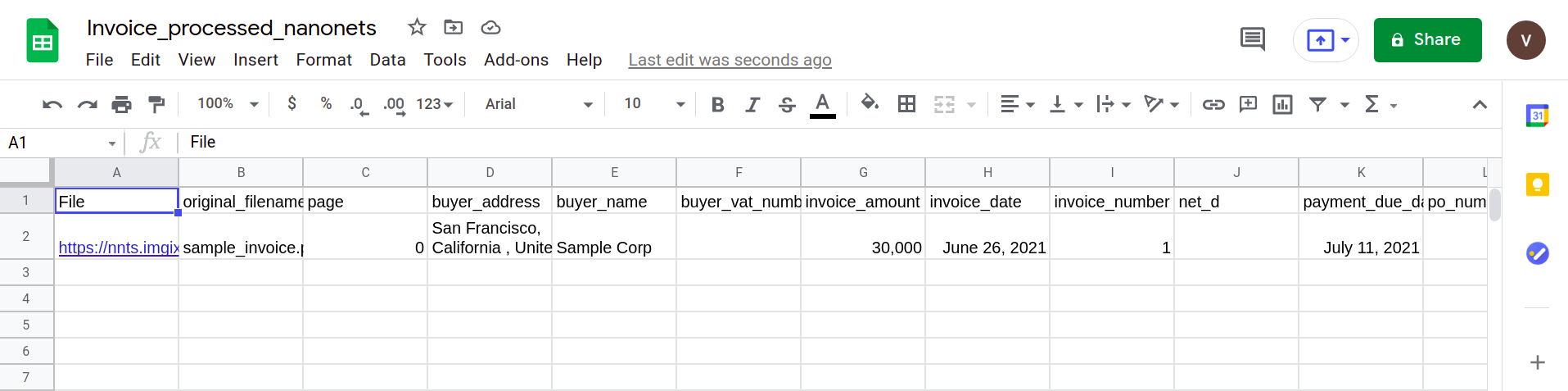
La siguiente imagen muestra una captura de pantalla del archivo CSV que contiene los datos analizados del documento PDF.

Finalmente, para convertir el archivo CSV a un formulario de hojas de Google, es simplemente una cuestión de cargar el archivo XLSX / CSV en su unidad de Google. Este paso se puede automatizar haciendo uso de las API de Google Drive.
La siguiente sección muestra cómo se puede crear una canalización simple haciendo uso del analizador de PDF Nanonets.
¿Quiere extraer información de documentos PDF y convertirlos / agregarlos en un documento de Google Sheets? Echa un vistazo a Nanonets™ para automatizar la exportación de cualquier información de cualquier documento PDF a Google Sheets.
Creación de una tubería simple
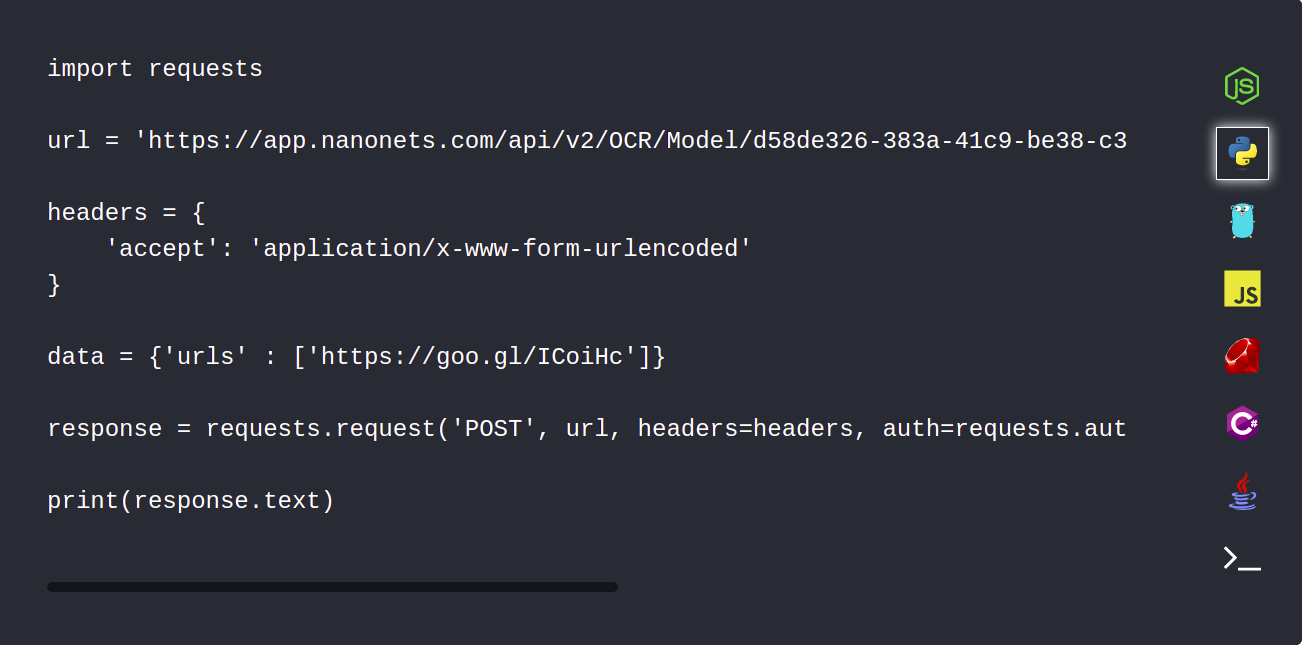
1. Cargue automáticamente sus documentos PDF utilizando la API de Nanonets
La API de Nanonets le permite cargar automáticamente sus documentos que deben analizarse. El siguiente fragmento de código muestra cómo se puede hacer esto usando Python.
2. Utilice la integración de webhooks para recibir una notificación al finalizar el análisis.
Los webhooks se pueden configurar para que le notifiquen automáticamente una vez que se hayan analizado los documentos.
3. Revisar y subir a Hojas de cálculo de Google.
Descargue y revise los archivos CSV para asegurarse de que todo esté en orden y cargue los datos en Hojas de cálculo de Google utilizando la API de Google Drive.
El borde de las nanoredes
Estas son algunas de las características del analizador de PDF de Nanonets que lo convierten en la herramienta ideal para su negocio.
1.Integraciones externas:
El modelo de nanorredes se puede integrar fácilmente con MySql, Quickbooks, Salesforce, etc. Esto significa que su flujo de trabajo actual permanece inalterado y el convertidor de nanorredes se puede conectar simplemente como un módulo adicional.
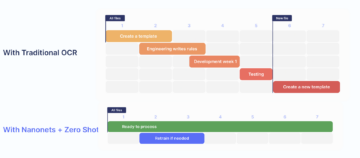
2. Alta precisión y tiempos de procesamiento reducidos:
La herramienta de análisis de PDF Nanonets tiene una precisión de más del 95%, que es mucho mayor en comparación con sus competidores.
3. Características geniales de posprocesamiento:
Suponga que su base de datos se ha integrado con el modelo de nanorred. El modelo completa automáticamente algunos campos (con datos de su base de datos) en función de los datos extraídos del documento. Por ejemplo:
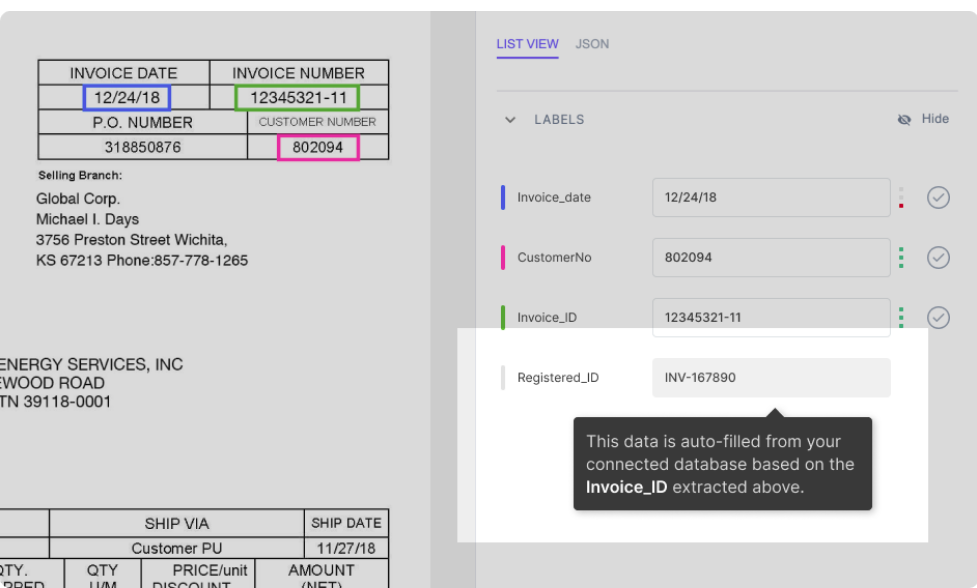
Como se muestra en la figura, el campo Registered_ID se completa automáticamente (mediante una búsqueda en la base de datos) según el Invoice_ID que se extrae del PDF.
4. Interfaz sencilla e intuitiva
Si bien esta función está subestimada, encontré que la interfaz de usuario y la experiencia de usuario son acertadas. Todo el proceso de registro, carga del documento y análisis de los datos tomó menos de 5 minutos. ¡Eso es casi igual al tiempo que tarda mi computadora portátil en iniciarse!
5. Gran base de clientes
En caso de que todavía tenga reservas sobre el uso de Nanonets para automatizar su flujo de trabajo, solo eche un vistazo a algunas de las empresas que utilizan sus servicios.
- Deloitte
- Sherwin Williams
- DoorDash
- P & G
¿Quiere extraer información de documentos PDF y convertirlos / agregarlos en un documento de Google Sheets? Echa un vistazo a Nanonets™ para automatizar la exportación de cualquier información de cualquier documento PDF a Google Sheets.
Conclusión
En esta publicación, analizamos cómo puede automatizar su flujo de trabajo utilizando un convertidor de PDF a Google Sheets. Inicialmente, aprendimos sobre la necesidad de convertir documentos PDF a Google Sheets, seguido de los desafíos que enfrentamos durante este proceso. Luego nos sumergimos en los enfoques adoptados por los analizadores sintácticos modernos para analizar documentos PDF y también implementamos algunos de los enfoques comunes. También aprendimos cómo podemos automatizar completamente la conversión utilizando integraciones externas como webhooks y API. Finalmente, usamos la herramienta Nanonets para analizar una factura de muestra, extraer los datos en un formulario de Hojas de cálculo de Google y también exploramos algunas de sus interesantes funciones de posprocesamiento.
¿Le has dado una oportunidad al modelo Nanonets? Si es así, deje un comentario a continuación sobre su experiencia con la herramienta. Si no, adelante y pruébalo. ¡Podría alegrarte el día!
- AI
- IA y aprendizaje automático
- arte ai
- generador de arte ai
- robot ai
- inteligencia artificial
- certificación de inteligencia artificial
- inteligencia artificial en banca
- robots de inteligencia artificial
- robots de inteligencia artificial
- software de inteligencia artificial
- blockchain
- conferencia blockchain ai
- Coingenius
- inteligencia artificial conversacional
- criptoconferencia ai
- de dall
- deep learning
- google ai
- máquina de aprendizaje
- pdf a hojas de google
- Platón
- platón ai
- Inteligencia de datos de Platón
- Juego de Platón
- PlatónDatos
- juego de platos
- escala ia
- sintaxis
- zephyrnet