Desplazamiento al rojo de Amazon es un almacén de datos rápido, escalable, seguro y completamente administrado que le permite analizar todos sus datos utilizando SQL estándar de manera fácil y rentable. Desplazamiento al rojo de Amazon Compartir datos permite a los clientes compartir de forma segura datos transaccionales coherentes en vivo en un clúster de Amazon Redshift con otro clúster de Amazon Redshift entre cuentas y regiones sin necesidad de copiar o mover datos de un clúster a otro.
El uso compartido de datos de Amazon Redshift se lanzó inicialmente en Marzo 2021, y se agregó soporte para compartir datos entre cuentas en Agosto 2021. El soporte entre regiones estuvo disponible en general en Febrero 2022. Esto proporciona total flexibilidad y agilidad para compartir datos entre clústeres de Redshift en la misma cuenta de AWS, diferentes cuentas o diferentes regiones.
El uso compartido de datos de Amazon Redshift se utiliza para redefinir fundamentalmente las arquitecturas de implementación de Amazon Redshift en un modelo de malla de datos centralizado para cumplir mejor con los SLA de rendimiento, proporcionar aislamiento de cargas de trabajo, realizar análisis entre grupos, incorporar fácilmente nuevos casos de uso y, lo que es más importante, hacer todo lo posible. esto sin la complejidad del movimiento de datos y las copias de datos. Algunas de las preguntas más comunes que se hacen durante la implementación del uso compartido de datos son: "¿Qué tamaño deberían tener mis clústeres de consumidores y clústeres de productores?" y "¿Cómo obtengo el mejor rendimiento de precio para el aislamiento de la carga de trabajo?". Dado que las características de la carga de trabajo, como el tamaño de los datos, la tasa de ingesta, el patrón de consulta y las actividades de mantenimiento, pueden afectar el rendimiento del intercambio de datos, se debe implementar una estrategia continua para dimensionar los clústeres de consumidores y productores para maximizar el rendimiento y minimizar los costos. En esta publicación, proporcionamos un enfoque paso a paso para ayudarlo a determinar los tamaños de sus grupos de productores y consumidores para obtener el mejor rendimiento de precio en función de su carga de trabajo específica.
Guía genérica de tallas para el consumidor
Los siguientes pasos muestran la estrategia genérica para dimensionar sus clústeres de productores y consumidores. Puede usarlo como punto de partida y modificarlo en consecuencia para satisfacer su escenario de caso de uso específico.
Dimensione su grupo de productores
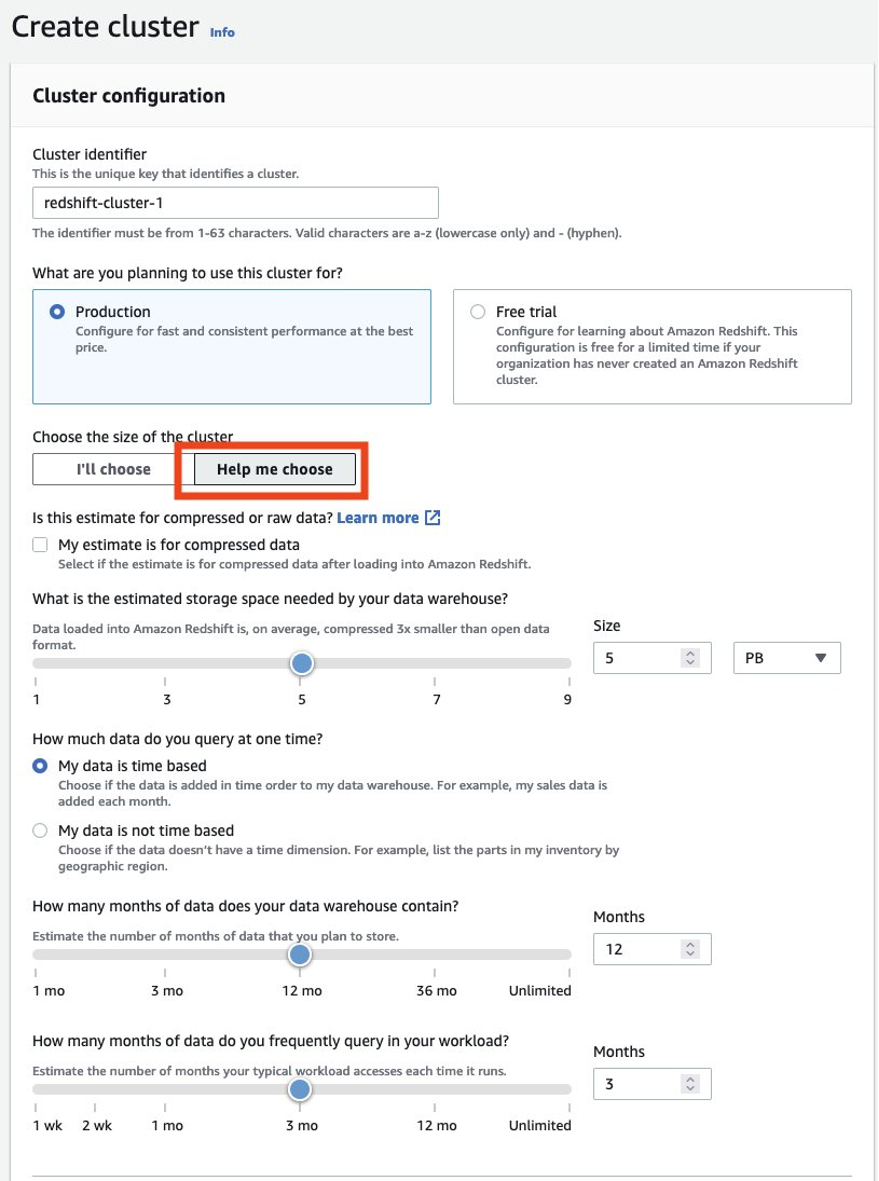
Siempre debe asegurarse de dimensionar correctamente su clúster de productores para obtener el rendimiento que necesita para cumplir con su SLA. Puede aprovechar la calculadora de tamaño de la consola de Amazon Redshift para obtener una recomendación para el clúster de productores según el tamaño de sus datos y la característica de la consulta. Buscar Ayúdeme a elegir en la consola en las regiones de AWS que admiten tipos de nodos RA3 para usar esta calculadora de tamaño. Tenga en cuenta que esta es solo una recomendación inicial para comenzar, y debe probar la ejecución de su carga de trabajo completa en el clúster de tamaño inicial y cambiar el tamaño elástico del clúster hacia arriba y hacia abajo en consecuencia para obtener el mejor rendimiento de precio.
Tamaño y configuración del clúster de consumidores inicial
Siempre debe dimensionar su clúster de consumidores en función de sus necesidades informáticas. Una forma de comenzar es seguir la guía de dimensionamiento de clústeres genéricos similar al clúster de productores anterior.
Configurar el uso compartido de datos de Amazon Redshift
Configure el uso compartido de datos del productor al consumidor una vez que haya configurado tanto el clúster del productor como el del consumidor. Consulte esto post para obtener orientación sobre cómo configurar el uso compartido de datos.
Probar la carga de trabajo solo del consumidor en el clúster de consumidores inicial
Pruebe la carga de trabajo solo del consumidor en el nuevo clúster de consumidores inicial. Esto se puede hacer señalando las aplicaciones del consumidor, por ejemplo, herramientas ETL, aplicaciones de BI y clientes SQL, al nuevo clúster del consumidor y volviendo a ejecutar la carga de trabajo para evaluar el rendimiento con respecto a sus requisitos.
Pruebe la carga de trabajo solo del consumidor en diferentes configuraciones de clústeres de consumidores
Si el clúster de consumidor de tamaño inicial cumple o supera los requisitos de rendimiento de su carga de trabajo, entonces puede continuar usando esta configuración de clúster o puede probar en configuraciones más pequeñas para ver si puede reducir aún más el costo y aún así obtener el rendimiento que necesita.
Por otro lado, si el clúster de consumo de tamaño inicial no cumple con los requisitos de rendimiento de la carga de trabajo, puede probar configuraciones más grandes para obtener la configuración que cumpla con su SLA.
Como regla general, aumente el tamaño del clúster de consumidores al doble de la configuración inicial del clúster de forma incremental hasta que cumpla con los requisitos de su carga de trabajo.
Una vez que planee qué configuración desea probar, use el cambio de tamaño elástico para cambiar el tamaño del clúster inicial a la configuración del clúster de destino. Después de completar el cambio de tamaño elástico, realice la misma prueba de carga de trabajo y evalúe el rendimiento con respecto a su SLA. Seleccione la configuración que cumpla con su objetivo de rendimiento de precio.
Probar la carga de trabajo solo del productor en diferentes configuraciones de clústeres de productores
Una vez que mueva su carga de trabajo del consumidor al clúster de consumidores con el rendimiento de precio óptimo, podría haber una oportunidad de reducir el recurso informático en el productor para ahorrar costos.
Para lograr esto, puede volver a ejecutar la carga de trabajo del productor solo en 1/2x del tamaño del productor original y evaluar el rendimiento de la carga de trabajo. Cambiar el tamaño del clúster hacia arriba y hacia abajo en consecuencia depende del resultado, y luego selecciona la configuración mínima del productor que cumple con los requisitos de rendimiento de su carga de trabajo.
Vuelva a evaluar después de una ejecución de carga de trabajo completa a lo largo del tiempo
A medida que Amazon Redshift continúa evolucionando y hay lanzamientos continuos de mejora del rendimiento y la escalabilidad, el rendimiento del intercambio de datos seguirá mejorando. Además, numerosas variables pueden afectar el rendimiento de las consultas de intercambio de datos. Los siguientes son solo algunos ejemplos:
- Tasa de ingestión y cantidad de cambio de datos
- Patrón de consulta y característica
- Cambios en la carga de trabajo
- Concurrencia
- Actividades de mantenimiento, por ejemplo, vacío, análisis y ATO
Esta es la razón por la que debe volver a evaluar el tamaño del clúster productor y consumidor usando la estrategia anterior en ocasiones, especialmente después de una implementación de carga de trabajo completa, para obtener el mejor rendimiento de precio nuevo de la configuración de su clúster.
Soluciones de dimensionamiento automatizadas
Si su entorno involucraba una arquitectura más compleja, por ejemplo, con múltiples herramientas o aplicaciones (BI, ingesta o transmisión, ETL, ciencia de datos), entonces podría no ser factible usar el método manual de la guía genérica anterior. En su lugar, puede aprovechar las soluciones de esta sección para reproducir automáticamente la carga de trabajo de su clúster de producción en los clústeres de consumidores y productores de prueba para evaluar el rendimiento.
Utilidad de reproducción simple se aprovechará como la solución automatizada para guiarlo a través del proceso de obtener el tamaño correcto de grupos de productores y consumidores para obtener el mejor rendimiento de precio.
Simple Replay es una herramienta para realizar un análisis hipotético y evaluar el rendimiento de su carga de trabajo en diferentes escenarios. Por ejemplo, puede usar la herramienta para comparar su carga de trabajo real en un nuevo tipo de instancia como RA3, evaluar una nueva característica o evaluar diferentes configuraciones de clúster. También incluye compatibilidad mejorada para reproducir canalizaciones de ingesta y exportación de datos con instrucciones COPY y UNLOAD. Para comenzar y reproducir sus cargas de trabajo, descargue la herramienta desde el Repositorio GitHub de Amazon Redshift.
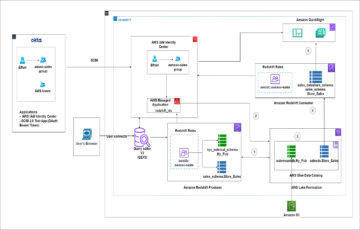
Aquí recorremos los pasos para extraer sus registros de carga de trabajo del clúster de producción de origen y reproducirlos en un entorno aislado. Esto le permite realizar una comparación directa entre estos clústeres de Amazon Redshift sin problemas y seleccionar la configuración de clústeres que mejor se adapte a su objetivo de rendimiento de precio.
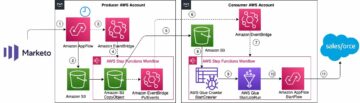
El siguiente diagrama muestra la arquitectura de la solución.
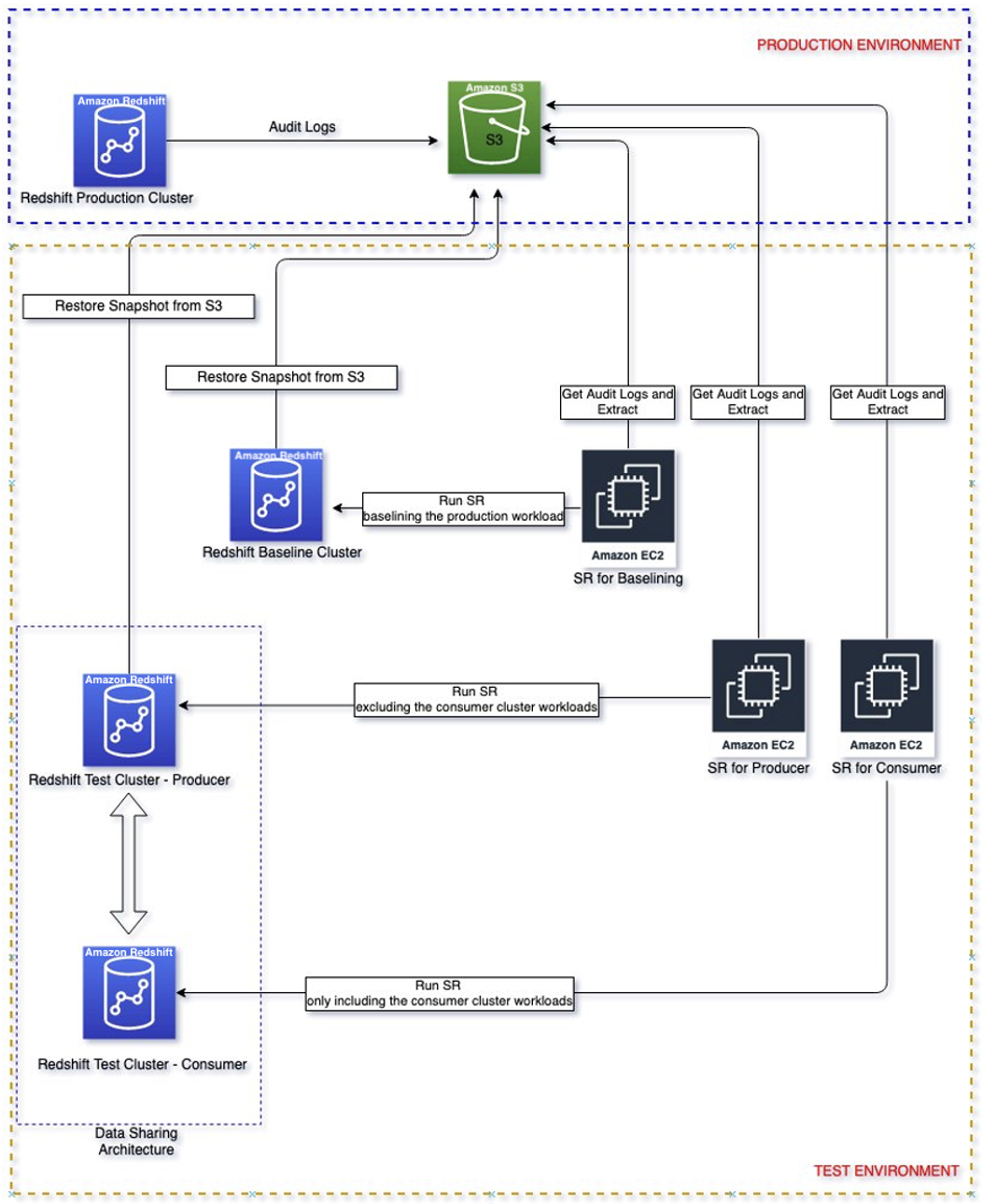
Tutorial de la solución
Siga estos pasos para recorrer la solución y dimensionar sus clústeres de consumidores y productores.
Dimensione su clúster de producción
Siempre debe asegurarse de dimensionar correctamente su clúster de producción existente para obtener el rendimiento que necesita para cumplir con los requisitos de su carga de trabajo. Puede aprovechar la calculadora de tamaño de la consola de Amazon Redshift para obtener una recomendación sobre el clúster de producción según el tamaño de sus datos y la característica de consulta. Buscar Ayúdeme a elegir en la consola en las regiones de AWS que admiten tipos de nodos RA3 para usar esta calculadora de tamaño. Tenga en cuenta que esta es solo una recomendación inicial para comenzar. Debe probar la ejecución de su carga de trabajo completa en el clúster de tamaño inicial y cambiar el tamaño elástico del clúster hacia arriba y hacia abajo en consecuencia para obtener el mejor rendimiento de precio.
Identificar la carga de trabajo que se va a aislar
Es posible que tenga diferentes cargas de trabajo ejecutándose en su clúster original, pero el primer paso es identificar la carga de trabajo más crítica para el negocio que queremos aislar. Esto se debe a que queremos asegurarnos de que la nueva arquitectura pueda cumplir con sus requisitos de carga de trabajo. Este post es una buena referencia sobre un caso de uso de aislamiento de carga de trabajo de intercambio de datos que puede ayudarlo a decidir qué carga de trabajo se puede aislar.
Configurar reproducción simple
Una vez que conozca su carga de trabajo crítica, debe habilitar el registro de auditoría en su clúster de producción donde se ejecuta la carga de trabajo crítica identificada anteriormente para capturar actividades de consulta y almacenar en Servicio de almacenamiento simple de Amazon (Amazon S3). Tenga en cuenta que los registros de auditoría pueden tardar hasta tres horas en enviarse a Amazon S3. Una vez que el registro de auditoría esté disponible, proceda a configurar reproducción simple y luego extraerlos la carga de trabajo crítica del registro de auditoría. Tenga en cuenta que start_time y end_time podrían usarse como parámetros para filtrar la carga de trabajo crítica si esas cargas de trabajo se ejecutan en ciertos períodos de tiempo, por ejemplo, de 9 am a 11 am. De lo contrario, extraerá todas las actividades registradas.
Carga de trabajo de referencia
Cree un clúster de referencia con la misma configuración que el clúster de productor mediante la restauración desde la instantánea de producción. El propósito de comenzar con la misma configuración es establecer una línea de base del rendimiento con un entorno aislado.
Una vez que el clúster de referencia esté disponible, reproducir la carga de trabajo extraída en el clúster de referencia. El resultado de esta reproducción será la línea de base utilizada para comparar con las repeticiones posteriores en diferentes configuraciones de consumidores.
Configurar clústeres de prueba de productores y consumidores iniciales
Cree un clúster de producción con la misma configuración de clúster de producción restaurando desde la instantánea de producción. Cree un clúster de consumidores con el tamaño de consumidor inicial recomendado de la guía anterior. Además, configure el intercambio de datos entre el productor y el consumidor.
Carga de trabajo de reproducción en el productor y el consumidor inicial
Repetir la carga de trabajo solo del productor en el clúster de productores de tamaño inicial. Esto se puede lograr utilizando el parámetro de filtro "Excluir" para excluir consultas de consumidores, por ejemplo, el usuario que ejecuta consultas de consumidores.
Repetir la carga de trabajo solo del consumidor en el clúster de consumidores de tamaño inicial. Esto se puede lograr utilizando el parámetro de filtro "Incluir" para excluir consultas de consumidores, por ejemplo, el usuario que ejecuta consultas de consumidores.
Evalúe el rendimiento de estas repeticiones con respecto a los requisitos de rendimiento de carga de trabajo y de referencia.
Reproduzca la carga de trabajo del consumidor en diferentes configuraciones
Si el clúster de consumidores de tamaño inicial cumple o supera los requisitos de rendimiento de su carga de trabajo, entonces puede usar esta configuración de clúster o puede seguir estos pasos para probar configuraciones más pequeñas para ver si puede reducir aún más los costos y seguir obteniendo el rendimiento que necesita.
Compare los resultados iniciales de rendimiento del consumidor con los requisitos de su carga de trabajo:
- Si el resultado supera los requisitos de rendimiento de su carga de trabajo, entonces puede reducir el tamaño del clúster de consumidores de forma incremental, comenzando con 1/2x, vuelva a intentar la reproducción y evalúe el rendimiento, luego cambie el tamaño hacia arriba o hacia abajo según el resultado hasta que cumpla con su carga de trabajo. requisitos El objetivo es conseguir un punto ideal en el que se sienta cómodo con los requisitos de rendimiento y obtener el precio más bajo posible.
- Si el resultado no cumple con los requisitos de rendimiento de su carga de trabajo, puede aumentar el tamaño del clúster de forma incremental, comenzando con el doble del tamaño original, vuelva a intentar la reproducción y evalúe el rendimiento hasta que cumpla con los requisitos de rendimiento de su carga de trabajo.
Carga de trabajo del productor de reproducción en diferentes configuraciones
Una vez que divida sus cargas de trabajo en clústeres de consumidores, la carga en el clúster de productores debe reducirse y debe evaluar el rendimiento de la carga de trabajo de su clúster de productores para buscar la oportunidad de reducir el tamaño para ahorrar costos.
Los pasos son similares a la reproducción del consumidor. Elastic cambia el tamaño del clúster de productores de forma incremental comenzando con 1/2 veces el tamaño original, reproduce la carga de trabajo solo del productor y evalúa el rendimiento, y luego cambia el tamaño hacia arriba o hacia abajo hasta que cumpla con los requisitos de rendimiento de la carga de trabajo. El propósito es obtener un punto ideal en el que se sienta cómodo con los requisitos de rendimiento de la carga de trabajo y obtenga el precio más bajo posible. Una vez que tenga la configuración de clúster de productor deseada, vuelva a intentar reproducir las cargas de trabajo del consumidor en el clúster de consumidor para asegurarse de que el rendimiento no se vio afectado por los cambios en la configuración del clúster de productor. Finalmente, debe reproducir las cargas de trabajo del productor y del consumidor al mismo tiempo para asegurarse de que el rendimiento se logre en un escenario de carga de trabajo completa.
Vuelva a evaluar después de una ejecución de carga de trabajo completa a lo largo del tiempo
De manera similar a la guía genérica, debe volver a evaluar el tamaño de los clústeres de productores y consumidores usando la estrategia anterior de vez en cuando, especialmente después de la implementación completa de la carga de trabajo para obtener el nuevo mejor rendimiento de precio de la configuración de su clúster.
Limpiar
La ejecución de estas pruebas de dimensionamiento en su cuenta de AWS puede tener algunas implicaciones de costos porque aprovisiona nuevos clústeres de Amazon Redshift, que pueden cobrarse como instancias bajo demanda si no tiene instancias reservadas. Cuando complete sus evaluaciones, le recomendamos que elimine los clústeres de Amazon Redshift para ahorrar costos. También recomendamos pausar sus clústeres cuando no estén en uso.
Aplicación de las mejores prácticas de uso compartido de datos y Amazon Redshift
El dimensionamiento adecuado de sus clústeres de productores y consumidores le brindará un buen comienzo para obtener el mejor rendimiento de precios de su implementación de Amazon Redshift. Sin embargo, el tamaño no es el único factor que puede maximizar su rendimiento. En este caso, comprender y seguir las mejores prácticas es igualmente importante.
Las mejores prácticas generales de ajuste del rendimiento de Amazon Redshift son aplicables a la implementación de uso compartido de datos. Asegúrese de que su implementación siga estos y las mejores prácticas.
Existen numerosas prácticas recomendadas específicas para compartir datos que debe seguir para asegurarse de maximizar el rendimiento. Consulte esto post para más información.
Resumen
No existe una recomendación única para todos los tamaños de grupos de productores y consumidores. Varía según las cargas de trabajo y su SLA de rendimiento. El propósito de esta publicación es brindarle una guía sobre cómo puede evaluar el rendimiento específico de su carga de trabajo de intercambio de datos para determinar los tamaños de clúster de consumidores y productores para obtener el mejor rendimiento de precio. Considere probar sus cargas de trabajo en el productor y el consumidor utilizando la reproducción simple antes de adoptarla en producción para obtener el mejor rendimiento de precio.
Acerca de los autores
 BP Yu es gerente de producto sénior en AWS. Le apasiona ayudar a los clientes a diseñar soluciones de big data para procesar datos a escala. Antes de AWS, ayudó a Amazon.com Supply Chain Optimization Technologies a migrar su almacén de datos de Oracle a Amazon Redshift y a construir su plataforma de análisis de big data de próxima generación utilizando tecnologías de AWS.
BP Yu es gerente de producto sénior en AWS. Le apasiona ayudar a los clientes a diseñar soluciones de big data para procesar datos a escala. Antes de AWS, ayudó a Amazon.com Supply Chain Optimization Technologies a migrar su almacén de datos de Oracle a Amazon Redshift y a construir su plataforma de análisis de big data de próxima generación utilizando tecnologías de AWS.
 Sidhanth Muralidhar es un administrador técnico principal de cuentas en AWS. Trabaja con clientes de grandes empresas que ejecutan sus cargas de trabajo en AWS. Le apasiona trabajar con clientes y ayudarlos a diseñar cargas de trabajo para costos, confiabilidad, rendimiento y excelencia operativa a escala en su viaje a la nube. También tiene un gran interés en el análisis de datos.
Sidhanth Muralidhar es un administrador técnico principal de cuentas en AWS. Trabaja con clientes de grandes empresas que ejecutan sus cargas de trabajo en AWS. Le apasiona trabajar con clientes y ayudarlos a diseñar cargas de trabajo para costos, confiabilidad, rendimiento y excelencia operativa a escala en su viaje a la nube. También tiene un gran interés en el análisis de datos.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/how-to-get-best-price-performance-from-your-amazon-redshift-data-sharing-deployment/
- 100
- a
- Sobre
- arriba
- en consecuencia
- Mi Cuenta
- Cuentas
- Lograr
- alcanzado
- a través de
- actividades
- adicional
- La adopción de
- Después
- en contra
- Todos
- permite
- hacerlo
- Amazon
- Amazon.com
- cantidad
- análisis
- Analytics
- analizar
- y
- Otra
- aplicable
- aplicaciones
- enfoque
- arquitectura
- auditoría
- Confirmación de Viaje
- automáticamente
- Hoy Disponibles
- AWS
- basado
- Base
- porque
- antes
- MEJOR
- y las mejores prácticas
- mejores
- entre
- Big
- Big Data
- build
- capturar
- case
- cases
- a ciertos
- cadena
- Cambios
- característica
- características
- cargado
- clientes
- Soluciones
- Médico
- COM
- cómodo
- Algunos
- comparar
- comparación
- completar
- Completado
- integraciones
- complejidad
- Calcular
- conductible
- Configuración
- Considerar
- consistente
- Consola
- consumidor
- continue
- continúa
- continuo
- Cost
- Precio
- podría
- Para crear
- crítico
- Clientes
- datos
- Data Analytics
- Ciencia de los datos
- compartir datos
- liberado
- depende
- despliegue
- detalles
- Determinar
- una experiencia diferente
- de reservas
- No
- DE INSCRIPCIÓN
- descargar
- durante
- pasan fácilmente
- ya sea
- permite
- mejorado
- Empresa
- Entorno
- igualmente
- especialmente
- Éter (ETH)
- evaluar
- evaluaciones
- evolución
- ejemplo
- ejemplos
- excede
- Excelencia
- existente
- exportar
- extraerlos
- falla
- RÁPIDO
- factible
- Feature
- filtrar
- Finalmente
- Nombre
- Flexibilidad
- seguir
- siguiendo
- siguiente
- en
- ser completados
- fundamentalmente
- promover
- Además
- Obtén
- en general
- generación de AHSS
- obtener
- conseguir
- GitHub
- Donar
- Go
- candidato
- guía
- ayuda
- ayudado
- ayudando
- HORAS
- Cómo
- Como Hacer
- Sin embargo
- HTTPS
- no haber aun identificado una solucion para el problema
- Identifique
- Impacto
- impactados
- implementado
- implicaciones
- importante
- es la mejora continua
- la mejora de
- in
- incluye
- aumente
- inicial
- posiblemente
- ejemplo
- intereses
- involucra
- aislado
- solo
- IT
- Keen
- Saber
- large
- mayores
- lanzado
- Permíteme
- Apalancamiento
- para vivir
- carga
- Mira
- un mejor mantenimiento.
- para lograr
- gerente
- manual
- Maximizar
- Conoce a
- Cumple
- Método
- podría
- migrado
- mínimo
- modelo
- más,
- MEJOR DE TU
- movimiento
- movimiento
- múltiples
- ¿ Necesita ayuda
- necesidad
- Nuevo
- Next
- nodo
- numeroso
- ocasión
- A bordo
- ONE
- operativos.
- Oportunidad
- optimización
- óptimo
- oráculo
- reconocida por
- Otro
- de otra manera
- parámetro
- parámetros
- apasionado
- Patrón de Costura
- realizar
- actuación
- realiza
- períodos
- plan
- plataforma
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- punto
- posible
- Publicación
- prácticas
- anterior
- precio
- Director de la escuela
- productor
- Producto
- gerente de producto
- Producción
- correctamente
- proporcionar
- proporciona un
- propósito
- Preguntas
- Rate
- recomiendan
- Recomendación
- recomendado
- reducir
- Reducción
- regiones
- Estrenos
- fiabilidad
- Requisitos
- reservados
- Recurso
- restauración
- resultado
- Resultados
- Regla
- Ejecutar
- correr
- mismo
- Guardar
- Escalabilidad
- escalable
- Escala
- escenarios
- Ciencia:
- sin problemas
- Sección
- seguro
- segura
- EL EQUIPO
- de coches
- Configure
- Compartir
- compartir
- tienes
- Mostrar
- Shows
- similares
- sencillos
- Tamaño
- tamaños
- menores
- Instantánea
- a medida
- Soluciones
- algo
- Fuente
- soluciones y
- dividido
- Spot
- estándar
- comienzo
- fundó
- Comience a
- declaraciones
- paso
- pasos
- Sin embargo
- STORAGE
- tienda
- Estrategia
- en streaming
- posterior
- suministro
- cadena de suministro
- Optimización de la cadena de suministro
- SOPORTE
- dulce
- ¡Prepárate!
- Target
- Técnico
- Tecnologías
- test
- Pruebas
- pruebas
- El
- La Fuente
- su
- Tres
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- equipo
- a
- del IRS
- tipos
- comprensión
- utilizan el
- caso de uso
- Usuario
- Aspiradora
- ¿
- que
- QUIENES
- seguirá
- sin
- trabajando
- funciona
- tú
- zephyrnet