Los datos de series temporales, recopilados casi cada segundo de una multiplicidad de fuentes, a menudo están sujetos a varios problemas de calidad de datos, entre los cuales faltan datos.
En el contexto de datos secuenciales, la información faltante puede surgir debido a varias razones, a saber, errores que ocurren en los sistemas de adquisición (por ejemplo, mal funcionamiento de los sensores), errores durante el proceso de transmisión (p. ej., conexiones de red defectuosas) o errores durante la recopilación de datos (p. ej., error humano durante el registro de datos). Estas situaciones a menudo generan valores faltantes esporádicos y explícitos en nuestros conjuntos de datos, correspondientes a pequeñas lagunas en el flujo de datos recopilados.
Además, información faltante También puede surgir de forma natural debido a las características del propio dominio, creando mayores lagunas en los datos. Por ejemplo, una característica que deja de recopilarse durante un cierto período de tiempo, generando datos faltantes no explícitos.
Independientemente de la causa subyacente, la falta de datos en nuestras secuencias de series temporales es muy perjudicial para los pronósticos y los modelos predictivos y puede tener consecuencias graves tanto para los individuos (por ejemplo, una evaluación de riesgos equivocada) como para los resultados comerciales (por ejemplo, decisiones comerciales sesgadas, pérdida de ingresos y oportunidades).
Por lo tanto, a la hora de preparar los datos para los enfoques de modelización, un paso importante es poder identificar estos patrones de información desconocida, ya que nos ayudarán a decidir sobre el mejor enfoque para manejar los datos eficientemente y mejorar su consistencia, ya sea a través de alguna forma de corrección de alineación, interpolación de datos, imputación de datos o, en algunos casos, eliminación caso por caso (es decir, omitir casos con valores faltantes para una característica utilizada en un análisis particular).
Por esa razón, realizar un análisis de datos exploratorio y un perfilado de datos exhaustivos es indispensable no sólo para comprender las características de los datos sino también para tomar decisiones informadas sobre cómo preparar mejor los datos para el análisis.
En este tutorial práctico, exploraremos cómo ydata-perfilado puede ayudarnos a solucionar estos problemas con las funciones introducidas recientemente en la nueva versión. Usaremos el Conjunto de datos de contaminación de EE. UU., Disponible en Kaggle (Licencia DBCL v1.0), que detalla información sobre los contaminantes NO2, O3, SO2 y CO en los estados de EE. UU.
Para iniciar nuestro tutorial, primero debemos instalar la última versión de ydata-profiling:
pip install ydata-profiling==4.5.1
Luego, podemos cargar los datos, eliminar funciones innecesarias y centrarnos en lo que pretendemos investigar. A los efectos de este ejemplo, nos centraremos en el comportamiento particular de las mediciones de contaminantes del aire tomadas en la estación de Arizona, Maricopa, Scottsdale:
import pandas as pd data = pd.read_csv("data/pollution_us_2000_2016.csv")
data = data.drop('Unnamed: 0', axis = 1) # dropping unnecessary index # Select data from Arizona, Maricopa, Scottsdale (Site Num: 3003)
data_scottsdale = data[data['Site Num'] == 3003].reset_index(drop=True)
¡Ahora estamos listos para comenzar a perfilar nuestro conjunto de datos! Recuerde que, para utilizar el perfil de series temporales, debemos pasar el parámetro tsmode=True para que ydata-profiling pueda identificar características que dependen del tiempo:
# Change 'Data Local' to datetime
data_scottsdale['Date Local'] = pd.to_datetime(data_scottsdale['Date Local']) # Create the Profile Report
profile_scottsdale = ProfileReport(data_scottsdale, tsmode=True, sortby="Date Local")
profile_scottsdale.to_file('profile_scottsdale.html')Descripción general de series temporales
El informe de salida resultará familiar a lo que ya sabemos, pero con una experiencia mejorada y nuevas estadísticas resumidas para datos de series temporales:
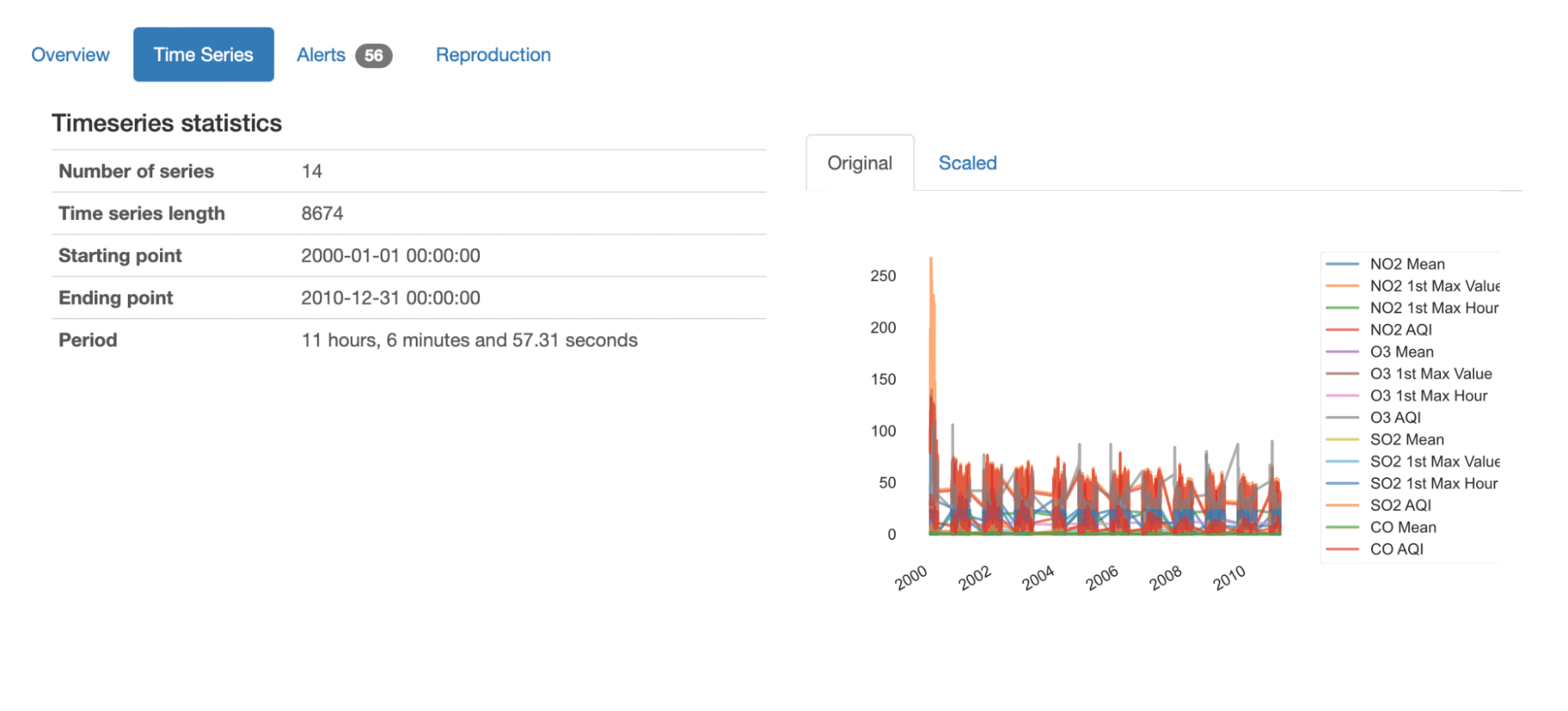
Inmediatamente después de la descripción general, podemos obtener una comprensión general de este conjunto de datos al observar las estadísticas resumidas presentadas:
- Contiene 14 series temporales diferentes, cada una con 8674 valores registrados;
- El conjunto de datos informa sobre 10 años de datos desde enero de 2000 hasta diciembre de 2010;
- El período medio de secuencias de tiempo es de 11 horas y (casi) 7 minutos. Esto significa que, en promedio, se toman medidas cada 11 horas.
También podemos obtener un gráfico general de todas las series en datos, ya sea en sus valores originales o escalados: podemos captar fácilmente la variación general de las secuencias, así como los componentes (NO2, O3, SO2, CO) y las características (media , 1er valor máximo, 1ra hora máxima, AQI) que se está midiendo.
Inspeccionar datos faltantes
Después de tener una visión general de los datos, podemos centrarnos en los detalles de cada secuencia de tiempo.
En la última versión de ydata-perfilado, el informe de elaboración de perfiles se mejoró sustancialmente con un análisis dedicado a los datos de series temporales, es decir, informes sobre las métricas "Serie temporal" y "Análisis de brechas". La identificación de tendencias y patrones faltantes se ve extremadamente facilitada por estas nuevas características, donde ahora están disponibles estadísticas resumidas específicas y visualizaciones detalladas.
Algo que destaca de inmediato es el patrón escamoso que presentan todas las series temporales, donde parecen ocurrir ciertos “saltos” entre mediciones consecutivas. Esto indica la presencia de datos faltantes (“lagunas” de información faltante) que deberían estudiarse más de cerca. Echemos un vistazo a la S02 Mean como ejemplo.
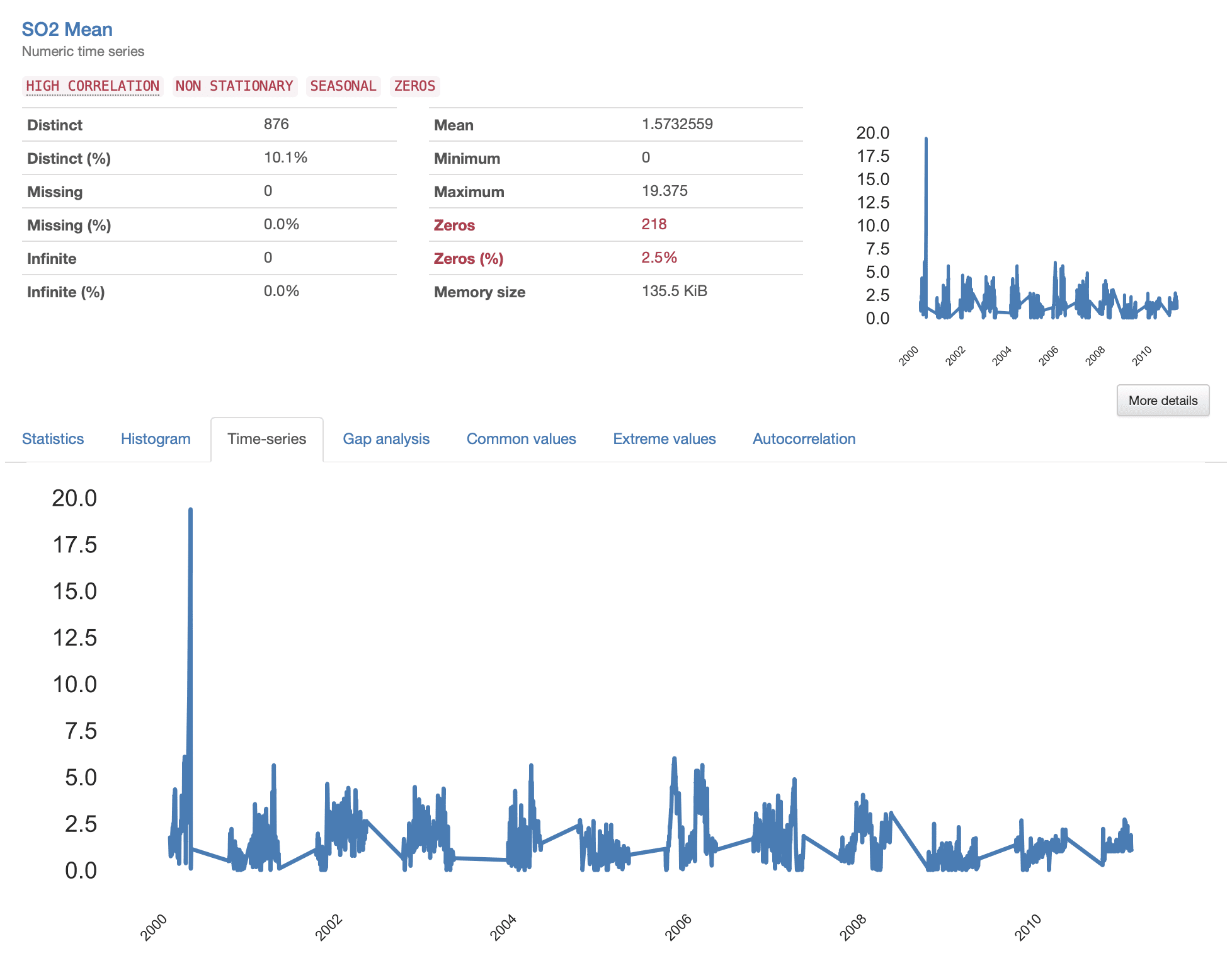
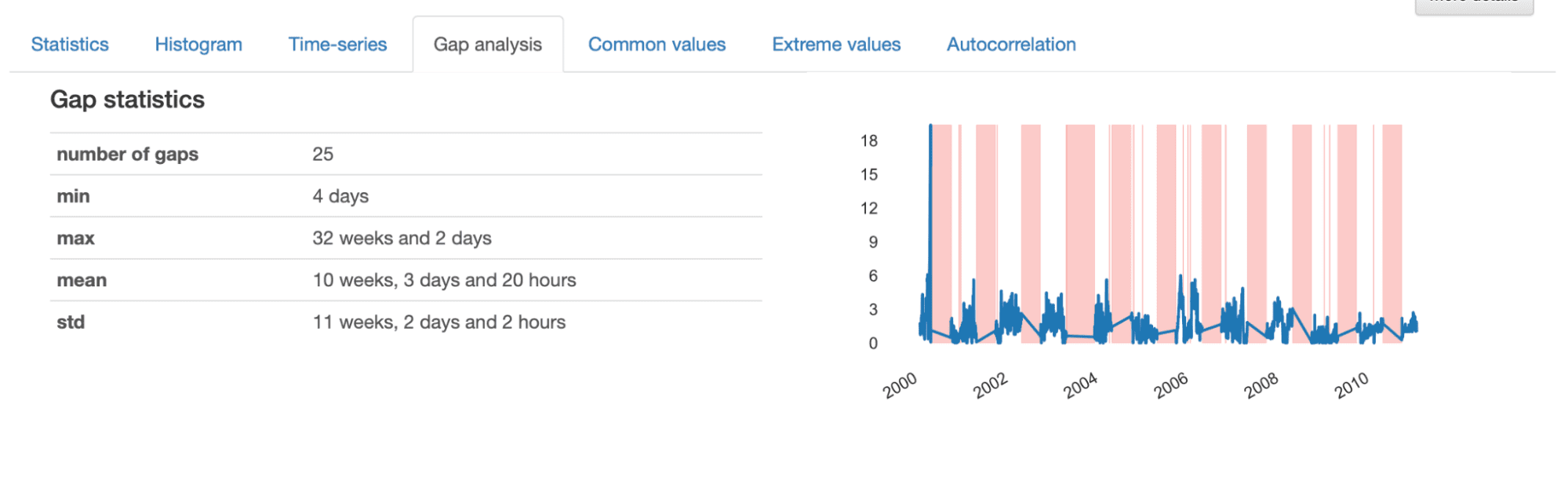
Al investigar los detalles proporcionados en el Análisis de Brechas, obtenemos una descripción informativa de las características de las brechas identificadas. En total, hay 25 lagunas en la serie temporal, con una duración mínima de 4 días, una máxima de 32 semanas y una media de 10 semanas.
En la visualización presentada, observamos espacios algo “aleatorios” representados por franjas más delgadas y espacios más grandes que parecen seguir un patrón repetitivo. Esto indica que parecemos tener dos patrones diferentes de datos faltantes en nuestro conjunto de datos.
Las brechas más pequeñas corresponden a eventos esporádicos que generan datos faltantes, que probablemente ocurren debido a errores en el proceso de adquisición y, a menudo, pueden interpolarse o eliminarse fácilmente del conjunto de datos. A su vez, las brechas más grandes son más complejas y deben analizarse con más detalle, ya que pueden revelar un patrón subyacente que debe abordarse más a fondo.
En nuestro ejemplo, si investigáramos las brechas más grandes, de hecho descubriríamos que reflejan un patrón estacional:
df = data_scottsdale.copy()
for year in df["Date Local"].dt.year.unique(): for month in range(1,13): if ((df["Date Local"].dt.year == year) & (df["Date Local"].dt.month ==month)).sum() == 0: print(f'Year {year} is missing month {month}.')
# Year 2000 is missing month 4.
# Year 2000 is missing month 5.
# Year 2000 is missing month 6.
# Year 2000 is missing month 7.
# Year 2000 is missing month 8.
# (...)
# Year 2007 is missing month 5.
# Year 2007 is missing month 6.
# Year 2007 is missing month 7.
# Year 2007 is missing month 8.
# (...)
# Year 2010 is missing month 5.
# Year 2010 is missing month 6.
# Year 2010 is missing month 7.
# Year 2010 is missing month 8.
Como se sospechaba, la serie temporal presenta grandes lagunas de información que parecen ser repetitivas, incluso estacionales: en la mayoría de los años, los datos no se recopilaron entre mayo y agosto (meses 5 a 8). Esto puede haber ocurrido debido a razones impredecibles o decisiones comerciales conocidas, por ejemplo, relacionadas con la reducción de costos, o simplemente relacionadas con variaciones estacionales de contaminantes asociados con patrones climáticos, temperatura, humedad y condiciones atmosféricas.
Con base en estos hallazgos, podríamos investigar por qué sucedió esto, si se debe hacer algo para evitarlo en el futuro y cómo manejar los datos que tenemos actualmente.
A lo largo de este tutorial, hemos visto lo importante que es comprender los patrones de datos faltantes en series temporales y cómo una elaboración de perfiles eficaz puede revelar los misterios detrás de las lagunas de información faltante. Desde las telecomunicaciones, la atención sanitaria, la energía y las finanzas, todos los sectores que recopilan datos de series temporales se enfrentarán en algún momento a datos faltantes y tendrán que decidir la mejor manera de manejarlos y extraer todo el conocimiento posible de ellos.
Con un perfil de datos integral, podemos tomar una decisión informada y eficiente dependiendo de las características de los datos disponibles:
- Los vacíos de información pueden ser causados por eventos esporádicos que se derivan de errores en la adquisición, transmisión y recopilación. Podemos solucionar el problema para evitar que vuelva a suceder e interpolar o imputar los espacios faltantes, dependiendo de la longitud del espacio;
- Las lagunas de información también pueden representar patrones estacionales o repetidos. Podemos optar por reestructurar nuestro canal para comenzar a recopilar la información que falta o reemplazar las brechas que faltan con información externa de otros sistemas distribuidos. También podemos identificar si el proceso de recuperación no tuvo éxito (tal vez una consulta complicada en el lado de la ingeniería de datos, ¡todos tenemos esos días!).
Espero que este tutorial haya arrojado algo de luz sobre cómo identificar y caracterizar adecuadamente los datos faltantes en sus datos de series temporales y no puedo esperar a ver qué encontrará en su propio análisis de brechas. Escríbeme en los comentarios para cualquier pregunta o sugerencia o encuéntrame en Comunidad de IA centrada en datos!
Fabiana Clemente es cofundadora y CDO de YData, y combina la comprensión de los datos, la causalidad y la privacidad como sus principales campos de trabajo e investigación, con la misión de hacer que los datos sean procesables para las organizaciones. Como entusiasta profesional de los datos, presenta el podcast When Machine Learning Meets Privacy y es oradora invitada en los podcasts Datacast y Privacy Please. También habla en conferencias como ODSC y PyData.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- ChartPrime. Eleve su juego comercial con ChartPrime. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://www.kdnuggets.com/how-to-identify-missing-data-in-timeseries-datasets?utm_source=rss&utm_medium=rss&utm_campaign=how-to-identify-missing-data-in-time-series-datasets
- :posee
- :es
- :no
- :dónde
- 1
- 10
- 11
- 12
- 13
- 14
- 1
- 2000
- 2010
- 25
- 32
- 7
- 8
- a
- Poder
- adquisición
- a través de
- dirigido
- de nuevo
- AI
- objetivo
- AIRE
- Todos
- ya haya utilizado
- también
- entre
- an
- análisis
- analizo
- y
- cualquier
- enfoque
- enfoques
- adecuadamente
- somos
- surgir
- Arizona
- AS
- evaluación
- asociado
- At
- atmosférico
- AGOSTO
- Hoy Disponibles
- promedio
- Eje
- BE
- comportamiento
- detrás de
- "Ser"
- MEJOR
- entre
- parcial
- ambas
- pero
- by
- PUEDEN
- Puede conseguir
- cases
- Causa
- causado
- a ciertos
- el cambio
- características
- caracterizar
- Elige
- de cerca
- CO
- cofundador
- El cobro
- --
- combinar
- comentarios
- integraciones
- componentes
- exhaustivo
- condiciones
- conferencias
- Conexiones
- consecutivo
- Consecuencias
- contiene
- contexto
- Correspondiente
- Precio
- podría
- Para crear
- Creamos
- En la actualidad
- corte
- datos
- análisis de los datos
- calidad de los datos
- conjuntos de datos
- Fecha
- datetime
- Días
- Diciembre
- Diciembre 2010
- decidir
- Koops
- decisiones
- a dedicados
- Dependiente
- descripción
- detalle
- detallado
- detalles
- una experiencia diferente
- descrubrir
- distribuidos
- sistemas distribuidos
- dominio
- hecho
- Soltar
- Dejar caer
- dos
- durante
- e
- cada una
- pasan fácilmente
- Eficaz
- eficiente
- eficiente.
- ya sea
- energía
- Ingeniería
- entusiasta
- error
- Errores
- Éter (ETH)
- Incluso
- Eventos
- Cada
- ejemplo
- experience
- Análisis exploratorio de datos
- explorar
- externo
- extraerlos
- extremadamente
- Cara
- facilitado
- hecho
- familiar
- defectuoso
- Feature
- Caracteristicas
- Terrenos
- financiar
- Encuentre
- Los resultados
- Nombre
- Fijar
- Focus
- seguir
- formulario
- Desde
- futuras
- brecha
- lagunas
- generar
- la generación de
- obtener
- dado
- agarrar
- Invitad@s
- mano
- encargarse de
- emprendedor
- pasó
- En Curso
- Tienen
- es
- la salud
- ayuda
- aquí
- altamente
- esperanza
- anfitriones
- horas.
- HORAS
- Cómo
- Como Hacer
- HTML
- HTTPS
- humana
- i
- Identificación
- no haber aun identificado una solucion para el problema
- Identifique
- if
- inmediatamente
- importante
- mejorar
- mejorado
- in
- índice
- Indica
- individuos
- información
- informativo
- informó
- instalar
- ejemplo
- Introducido
- investigar
- investigar
- cuestiones
- IT
- SUS
- sí mismo
- Enero
- nuggets
- Saber
- especialistas
- large
- mayores
- más reciente
- último lanzamiento
- aprendizaje
- Longitud Mínima
- Licencia
- luz
- que otros
- línea
- Etiqueta LinkedIn
- carga
- local
- registro
- Mira
- mirando
- de
- máquina
- máquina de aprendizaje
- Inicio
- para lograr
- Realizar
- max
- máximas
- Puede..
- Quizas
- me
- personalizado
- significa
- mesurado
- medidas
- medidas
- se une a la
- Métrica
- mínimo
- minutos
- que falta
- Misión
- modelado
- Mes
- meses
- más,
- MEJOR DE TU
- a saber
- naturalmente
- hace casi
- ¿ Necesita ayuda
- del sistema,
- Nuevo
- Nuevas características
- nota
- ahora
- ocurrir
- se produjo
- ocurriendo
- of
- a menudo
- on
- , solamente
- Del Mañana
- or
- para las fiestas.
- reconocida por
- Otro
- "nuestr
- salir
- resultados
- salida
- total
- visión de conjunto
- EL DESARROLLADOR
- Los pandas
- parámetro
- particular
- pass
- Patrón de Costura
- .
- realizar
- período
- industrial
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- Por favor
- Podcast
- Pódcasts
- punto
- Pollution
- posible
- profético
- Preparar
- preparación
- presencia
- presente
- presentó
- regalos
- evitar
- política de privacidad
- Mi Perfil
- perfiles
- propósito
- calidad
- Preguntas
- ready
- razón
- razones
- recientemente
- grabado
- reflejar
- con respecto a
- relacionado
- ,
- remove
- repetido
- repetitivo
- reemplazar
- reporte
- Informes
- Informes
- representar
- representado
- la investigación
- reestructurar
- género
- ingresos
- Riesgo
- evaluación de riesgos
- s
- estacional
- Segundo
- Sectores
- ver
- parecer
- visto
- sensor
- Secuencia
- Serie
- grave
- Varios
- ella
- cobertizo
- tienes
- lado
- simplemente
- página web
- circunstancias
- chica
- So
- algo
- algo
- algo
- Fuentes
- Speaker
- Habla
- soluciones y
- detalles específicos
- es la
- comienzo
- Zonas
- estación
- statistics
- paso
- Paradas
- stream
- Rayas
- estudiado
- sustancialmente
- tal
- RESUMEN
- sospecha
- Todas las funciones a su disposición
- ¡Prepárate!
- toma
- telecom
- esa
- La
- El futuro de las
- su
- Les
- luego
- Ahí.
- por lo tanto
- Estas
- ellos
- así
- a fondo
- aquellos
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- equipo
- Series de tiempo
- a
- Tendencias
- GIRO
- tutoriales
- dos
- nosotros
- subyacente
- entender
- comprensión
- desconocido
- SIN NOMBRE
- innecesario
- imprevisible
- us
- utilizan el
- usado
- usando
- v1
- propuesta de
- Valores
- variaciones
- versión
- Ver
- visualización
- esperar
- fue
- Camino..
- we
- Tiempo
- patrones meteorológicos
- Semanas
- WELL
- tuvieron
- ¿
- cuando
- que
- porque
- seguirá
- Actividades:
- se
- año
- años
- tú
- zephyrnet